
大数据平台中关联挖掘算法及发展趋势探讨
2018-09-03 05:43喜艺
数字通信世界 2018年8期
喜 艺
(公诚管理咨询有限公司,广州 510610)
在信息化时代,云计算和大数据技术为我们的生活、工作提供着重要支撑。面对庞大的数据规模,如何对其进行挖掘和运用是人们所要考虑的。云计算能够有效结合大数据挖掘的特点,不但能够有效缓解数据存储的压力,同时还能够将多个用户的数据进行融合存储并实现快速访问,Apriori算法就可以依据用户的兴趣内容对存储于云端的大数据进行挖掘。
1 关联规则概述
关联规则挖掘是从事务数据库中发现支持度和置信度都大于给定阈值的各数据项之间的相互关联。关联规则问题的形式化描述是:设I={i1,i2,i3,…,im}是m 个不同项目的集合,其中元素称为项(Item)。给定一个事务数据库D,其中每一个事务T 是I 中一组项的集合,即TI。关联规则就是形如AB的蕴含式,其中AB,BI,并且A∩B=。A 为规则的前件,B 为规则后件。关联规则AB 成立的条件:1)关联规则的支持度Support(AB)是D 中事务包含A∪B 的百分比,即Support(AB)=P(A∪B)。2)关联规则的置信度Con fidence(AB)是D 中包含A 的事务同时也包含B 的百分比,即Con fidence(AB)=P(B|A)。。
2 大数据内涵及其常见用法
大数据的内涵非常丰富,对其概念的定义也存在着各种不同的看法。在笔者看来,大数据挖掘技术是通过技术手段,对海量信息进行采集、整理、归类、分析、建模、总结,然后挖掘出潜藏于数据背后的价值的过程。大数据挖掘技术在近几年诞生并得到了飞速发展,在我国的一二线城市,其从业人员的平均工资已经远超其他行业,这更说明大数据挖掘技术已经逐渐的渗透到各行各业,其自身的发展也日趋成熟,应用前景之广也可见一斑。大数据在数据挖掘中常用的方法如下:
(1)数据关联分析:数据的关联分析,顾名思义,就是通常目标数据的特征,寻找数据和数据之间的内在关系,并对这种数据关系作出分析。
(2)聚类集合:聚类概念就是将一系列无规律的、没有任何关联的数据,通过一定的规则进行分类,形成不同的类群,集合则是类群的统称。
(3)趋势预估:趋势预估的一个重要前提,就是要在海量数据中寻找可以预测性信息,或是可以包含预测性信息的其他信息集合。
(4)数据特征总结:数据特征总结在一定程度上来说就是对数据进行概念上的描述和区分,通过对数据特征的总结归纳,形成一条数据的概念。
(5)误差分析:大数据挖掘技术对于误差的分析,往往是通过对数据库中的异常信息进行检测,从而找到其与参照对象之间的差异。
3 关联规则挖掘过程
在对大数据进行挖掘的过程中,根据关联规则的概述可知,关联规则挖掘问题就是在事务数据库D 中寻找满足最小支持度和最小置信度的关联规则。第一步找出所有的频繁项集,即发现所有的事务支持度大于最小支持度的项集。第二步由频繁项集产生强关联规则,即关联规则必须满足最小支持度和最小置信度。
4 经典 Apriori 算法
4.1 Apriori 算法的基本思想
Apriori 算法是挖掘布尔型关联规则频繁项集的经典算法,这种算法实际使用中最基本的一个思想就是合理使用逐层迭代的手段来实现对于数据库中相关内容的挖掘,也就是使用k_项集去探索(k+1)_项集。该算法在第一趟扫描数据库时,对项集中的每一个数据项计算其支持度,确定出满足最小支持度的频繁1_项集,记作L1。第二趟扫描时,首先以第一趟扫描得到的频繁1_项集作为候选项集Ck,之后通过对数据库中的相关数据进行扫描计算出候选集各自的支持度,最后从候选项集Ck 中确定出满足最小支持度的频繁2_项集。以此类推迭代,直至不再有新的频繁项集产生为止。
4.2 Apriori 算法的具体实现过程
Apriori 算法的具体实现过程:①通过扫描事务数据库D,计算出项集Ci 的支持度,得到频繁项集的集合Li;②为了得到频繁k_项集Lk,先将频繁k-1_项集Lk-1 与自身进行笛卡尔乘积连接,产生候选k_项集Ck;③候选k_项集Ck 是频繁k_项集Lk 的超集,所有的Lk 都包含在Ck 中。剪枝的工作就是将Ck中的非频繁项集删去,从而得出Lk。对数据库中的数据进行扫描,明确每一个候选项集各自的支持度,只有支持度不小于给定阈值的才是频繁项集,将非频繁项集从Ck 中删掉得到频繁k_项集Lk。即若某候选非空子集不是频繁的,则该候选项集肯定也不是频繁的,可将其删除;④通过迭代扫描事务数据库D,从而计算出各个项集支持度,并将不满足的项集去掉,如图1所示:
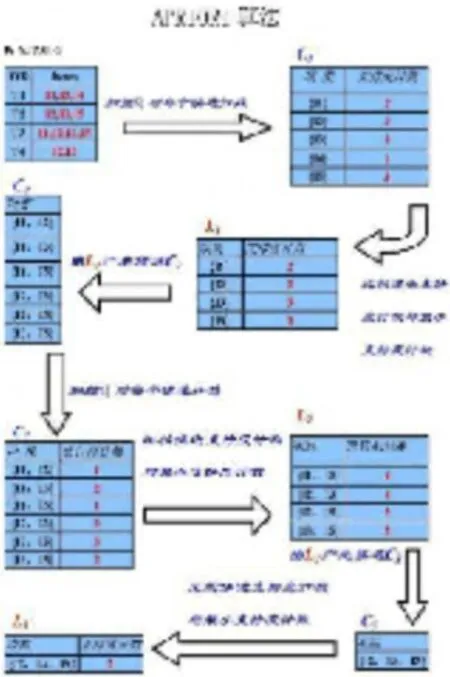
图1 APRIORI 算法示意图
4.3 Apriori 算法的性能分析
只有置信度和支持度都满足一定阈值时,所挖掘出来的关联规则才能够称作有效地规则。另外,随着处理的数据规模逐渐变大,假如仅仅开展简要的搜索那么就会形成非常多的规则,而这些规则中中有许多规则是无效的。基于频繁项集Apriori 算法的优点是思路简单清晰,易于理解,通过递归,连接,剪枝操作生成频繁项集。但会存在以下缺点:
(1)Apriori 算法是一种基于向下封闭属性的原理来获取频繁项集的手段,也就是说如果一个项集能够满足要求的支持度,那么这一项目中所包含的所有的非空子集都应该能够满足这一支持度要求。但是如果数据规模比较大,算法的效率就会降低。
(2)算法在执行过程中需要多次扫描数据库,对于数据量较小的数据库其性能降低的不是很明显。但是对于数据量较大的数据库,对于系统内存和I/O 负载较重。
(3)算法通过设置支持度与置信度来控制挖掘出来的规则数量,若把支持度设置得过低,虽能够较完整地挖掘到有效的关联规则,但开销过大;若把支持度设置得过高,则无法保证算法的完整性。
4.4 Apriori 算法的优化
针对经典Apriori 算法的性能缺点,根据其原理分析发现当进行扫描事务时可先删除其中不需要的候选项集、并实时进行数据压缩,这样可使扫描的效率更高,降低对计算机资源开销。
(1)基于减少扫描数据量的算法
AprioriTid 算法、Sampling 算法。AprioriTid 算法是在Apriori算法的基础上演化得来的,该算法在每产生候选项集后构造一个Tid 表,用来记录每条事务包含的候选项集,因此之后只是扫描上次生成的候选项集Tid 表,同时还会计算出频繁项集的支持度,以减少扫描数据库的时间来提高算法的效率。AprioriTid 算法的优点就是使用逐渐减小的Tid 表替代原来的事务数据库。但是该算法的缺点是在循环的初始阶段,候选项集的个数是可能还大于数据项的个数,从而导致Tid 表比原来的事务数据库还要大。
(2)基于减少候选项集数量的算法
DHP 算法、FP-growth 算法。DHP 算法采用哈希表对候选项集修剪来降低算法的时间和空间开销。具体是利用哈希函数在计算k-1_项集时先粗略计算出k_项集的支持度,减少候选k_项集的数量,尤其是对候选2_项集的数量控制的较为明显,有效缩减了候选2_项集的规模和扫描事务数。FP-growth 算法是先将数据库中的事务压缩到一颗频繁模式数FP-tree 中,然后将这种压缩后的FP-tree 分成一些条件数据库并分别挖掘。FP-growth 算法的最大优点是只扫描一次数据库并且不产生庞大的候选项集,但对存储空间的要求比较高。
(3)基于数据集划分的算法
DIC 算法也是采用分区的方法,将数据库划分成若干个分区并做标记,在计算项集时并行计算候选项集的支持度,因此就大大减少了I/O 操作从而提高了算法效率。
5 结束语
在大数据时代,市场需求多数情况下都以数据形式呈现,若不及时对这一部分数据信息进行有效处理,就会导致工作处在困境之中。原因在于对市场需求数据挖掘不能实现科学解读,使得工作与市场实际需求不相符;除此之外,对市场需求信息不能够正确判断辨析,就会导致工作成效与市场需求完全脱离。综上所述,大数据的挖掘具有非常重要意义,然而现有的针对Apriori算法的优化算法还无法有效满足人们的需求,在数据挖掘中,如何进一步提升数据挖掘效率,提升与用户的交互都是未来研究的难点和重点,因此,对关联挖掘算法进行研究并探讨其发展趋势具有非常重要的意义。
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
河南水利年鉴(2020年0期)2020-06-09
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
轴承(2015年2期)2015-07-25
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
