
基于遗传BP神经网络的耙吸挖泥船产量预测研究∗
2018-08-28 02:50李建祯
舰船电子工程 2018年8期
孙 健 李建祯 苏 贞
(1.江苏科技大学电子信息学院 镇江 212003)(2.江苏科技大学海洋装备研究院 镇江 212003)
1 引言
随着世界化石燃料的逐渐减少和世界各地气温的上升,越来越多地关注节能减排和低碳化。然而,耙吸挖泥船对化石燃料的需求却在不断地增加,所以如何使挖泥船能耗低,效率高的工作已经成为挖掘行业研究方向的重点[1]。近年来,出现了大量关于耙吸挖泥船疏浚作业能耗分析和效率优化的研究。耙吸挖泥船干土方生产率是挖泥船性能的最重要指标,因此干土方的生产率预测是效率优化过程中的重要工作[2]。
耙吸挖泥船疏浚过程模式是一种复杂的非线性动力学模型,模型是受各种因素的影响,包括:船舶设备参数,土壤类型参数和施工控制参数[3]。J.Braaksma建立了耙吸挖泥船动态模型,并采用预测控制算法优化整体性能[4]。Rhee,C.van详细分析了沉淀过程溢流损失模型[5]。王培生等阐述了主要的数学模型独立开发,用于耙吸挖泥船,根据沙床的变化提高工作效率以优化其生产[6]。倪福生等研究了利用神经网络预测绞吸挖泥船的性能[7]。耙吸挖泥船疏浚模型主要包括泥泵管线模型和泥舱沉积模型。在耙吸挖泥船泥泵—管线模型中,存在许多因素影响其准确性,而且各个因素之间的相互影响并不能够准确地知道[8]。在进行溢流装舱时,泥沙通过耙头、泥泵、管线进入泥舱,由于溢流筒高度低于泥舱液面使得部分泥沙流出泥舱。在进行干土方生产率预测时不可避免地需要对溢流损失进行计算,但是溢流密度和溢流流量不能通过传感器得到可靠的测量,并且历来没有很好的模型计算方法。因此急需一种可以解决以上问题的模型算法。
近年来,神经网络算法和进化算法的结合受到了人们的广泛关注,形成了一个称为进化神经网络的领域(Yao 1999)。由于这一领域的研究非常活跃,得到了许多有价值的结论和结果,其中一些已经成功应用。鉴于以上原因,通过应用遗传BP神经网络直接构建输入为控制参数,输出为干土方生产率的预测模型是极佳的选择。输入的控制参数包括:船舶的速度、耙头对地角度、波浪补偿压力、泵速、船舶吃水、溢流桶高度。
2 遗传算法优化BP神经网络研究
反向传播(BP)神经网络在自学习,自适应和泛化能力上表现出良好的性能,但是却具有容易陷入局部最小,收敛速度差的缺点[9]。为了克服BP神经网络的不足,在神经网络的研究和设计中引入了许多优化算法,如构建基于粒子群优化算法的神经网络(Chen和Yu 2005),并使用进化算法优化神经网络(Eysa and Saeed 2005;Harpham 2004;Ven⁃katesan 2009;Yao and Islam 2008),这被证明是可行和有效的。遗传算法(GA)是启发式随机搜索算法,也是进化算法之一。比之其他优化算法,GA的全局搜索能力具有一定优越性,可以在没有误差函数的梯度信息的情况下学习近最优解,是优化,搜索和机器学习的强大工具(Yao 2004)。
2.1 BP神经网络算法
BP网络基本上是一个渐进式算法,旨在最小化权重空间中的误差函数。在训练神经网络时,调整权重以减少总误差。通过证明,针对一些复杂的非线性函数,原则上已经证明,具有一个隐藏层的BP网络模型也是可以满足需求的。因此,我们的研究中采用了三层BP模型。在应用过程中,输入层的神经元个数和输出层神经元个数根据实际需求确定。假设BP神经网络的输入神经元个数为m、隐藏层神经元个数为p,输出神经元个数为1,则其隐藏层各节点的输入为
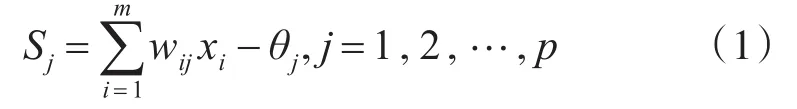
式中,wij为输入层至隐藏层的连接权值;θj为隐藏层节点的阈值。
BP神经网络转移函数采用Sigmoid函数f(x)=1/(1+e-x),则隐藏层节点的输出为
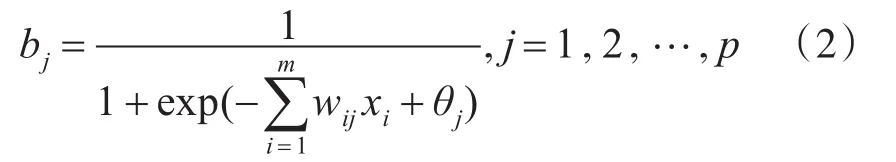
输出层节点的输入、输出分别为

式中,vj为隐藏层的连接权值;γ为输出层的阈值。
2.2 遗传算法
1)遗传算法原理
遗传算法是进化算法之一,它包含着由一群染色体构成的种群,其中染色体是我们想要解决的问题的候选解决方案。染色体通常被称为遗传算法语境中的字符串。一个字符串反过来讲是由许多基因组成,而这些基因可能带有一些数值,称为等位基因。与每个字符串相关联的是适应度值,它决定了一个字符串的“好”。适应度值由适应度函数确定,可以将其视为我们想要最大化的一些利润或最小化的误差。
2)遗传算法实现步骤
种群初始化:遗传算法对优化的问题进行编码,在编码中,可以采用实数进行编码,也可以采用二进制编码,并对交叉规模、交叉概率、突变概率、初始种群数、遗传代数进行初始化。
适应度函数:计算出个体的适应度值,根据适应度值判断个体优劣,我们采用实际值与预测值之间的差值作为适应度,适应度越小则该个体的适应能力越强。

式中,n为网络输出个数;yi期望输出;oi预测输出;k为系数。
选择:这是一个将染色体复制到下一代的过程。具有较高适应度值的染色体有更多的机会进入下一代。可以使用不同的方案来确定哪些染色体存活到下一代。经常使用的方法是轮盘赌轮选择,其中轮盘赌轮分成多个时隙,每个染色体一个。插槽的大小根据字符串的适应度而定。因此,当我们旋转车轮时,最好的染色体是最有可能被选中的。染色体被选择的概率 pi为

式中,fi为染色体适应度;N为种群大小;k为系数。
交叉:一个染色体的一部分与另一个染色体的一部分组合。这样,我们希望将一个染色体的良好部分与另一个染色体的良好部分相结合,在操作后产生更好的染色体。这个操作需要两个染色体,即父母,并生成两个新的,即后代。ak和al交叉方法为
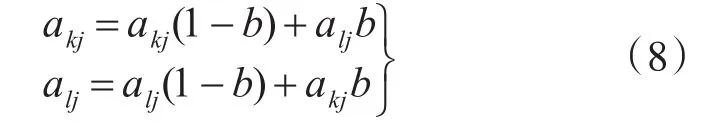
式中,b为[0,1]内的任意数。
变异:染色体中随机选择的基因将获得一个新值。目标是在种群中引入新的遗传物质,或至少防止其遗失。在突变下,一个基因可以获得一个在种群之前没有发生过的或由于繁殖而丢失的值,变异方法为
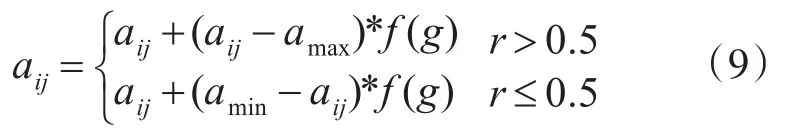
式中,amax为 aij的上限;amin为 aij的下限;为随机数;g为进化次数;Gmax为最大迭代次数;r是在[0,1]内的任意数。
2.3 遗传算法优化BP神经网络方法和步骤
遗传算法优化神经网络的可分为三个阶段。第一阶段是决定连接权重和阈值的表示,即我们是使用二进制字符串形式还是直接使用实数形式来表示连接权重和阈值。由于本文使用实数编码遗传算法,我们要做的只是将每个神经元的连接权重和阈值设置为其对应的基因片段。然而,使用二进制编码的简单遗传算法(SGA)来解决具有太多设计变量的优化问题难以达到收敛[10]。因此,使用实数编码遗传算法来克服SGA的缺点。第二阶段是通过构建相应的神经网络来评估这些连接权重、阈值的适应性。目标函数(如式(5)所示)被直接选择为适应度函数。由于ANN的泛化,其模型可以作为优化算法的知识源。该方法可以实时计算目标函数。第三阶段是根据遗传算法的适应度,应用遗传算法进行选择、交叉和变异操作等进化过程。当适应度小于预定义值时,进化就停止了。
优化神经网络学习过程包括两个阶段:首先使用GA搜索网络的最优或近似最优连接权重和阈值,然后使用BP神经网络调整最终权重。使用GA-BP算法来实现网络权重和阈值的学习最优值的步骤,如图1所示。首先,种群初始化完成,然后通过测量总均方误差的值来评估每个染色体的适应度,参见方程式(2)~(5)。在评估所有染色体后,通过使用繁殖(选择)算子从当前群体中提取染色体来创建中间种群。在本研究中,基于排序算法的轮盘选择被应用于选择算子。根据轮盘运算符排列后的相对适合度,选择染色体,并将其置入中间种群。最后,通过将交叉和突变算子应用于中间群体的染色体来形成下一代群体。然后评估通过选择,交叉和突变算子新建的新染色体,并重复所有染色体的评估和创建程序,直到满足停止标准。GA的基础是随着个体从一代传递到下一代,通过遗传算子不断改进种群的适应度。以这种方式,ANN权重和阈值被初始化为最佳种群成员的染色体。该过程通过对GA建立的初始连接权重和阈值应用BP算法来完成。如果BP停止条件为假,则更新权重和阈值;否则,它们被保存并提供用于将来的干土方生产率预测。
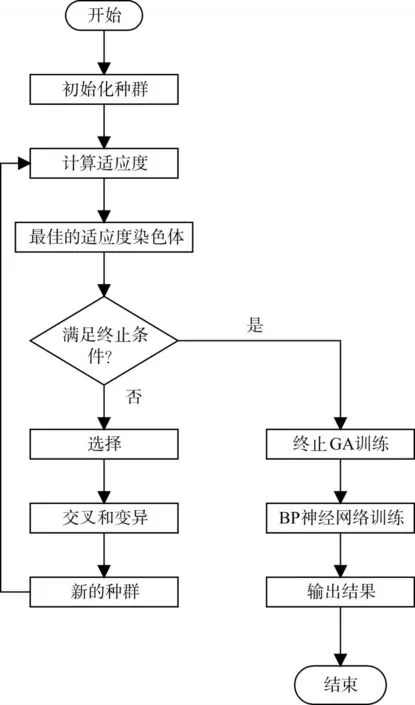
图1 遗传算法优化BP神经网络流程图
3 预测模型建立及验证
3.1 模型建立
耙吸挖泥船干土方生产率预测网络如图3所示,影响模型的参数有很多,选取船舶的速度、耙头对地角度、波浪补偿压力、泵速、船舶吃水、溢流桶高度作为模型的输入。耙吸挖泥船的泥泵吸入泥沙密度会随着航速的增加而减少,从而导致疏浚效率降低、能耗增大[11]。在一定范围内,耙头对地角度越大泥沙吸入量就越大。对于不同的土质对高压冲水泵的需求不同,使用高压冲水泵能够提高耙头的破土能力和泥沙在混合物中的浓度。溢流筒高度的有效调节使得溢流损失减少,提高疏浚效率,减少疏浚时间。耙头的对地压力可以通过波浪补偿器压力来进行调整,合适的对地压力可以减少对耙头的损伤,并且对有效疏浚起到很重要的作用[12]。实验为了突显预测模型的性能,分别建立了两个预测模型:BP神经网络预测模型、遗传算法优化BP神经网络预测模型。对同一周期疏浚数据进行预测,并进行对比实验。实验的误差评价体系采用平均绝对误差MAE,平均相对误差 perror,即
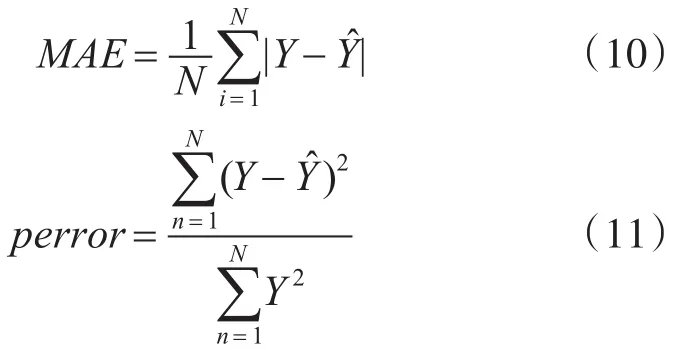
1)遗传算法参数选择:遗传算法种群数目和遗传代数太小则很难找到最优解,过大则增加了算法寻优的时间,因此论文中种群大小为10,遗传代数为20;交叉概率和变异率过大则会破坏优化的个体,过小又很难产生新的个体,文中交叉概率设为0.4,变异率设为0.1。
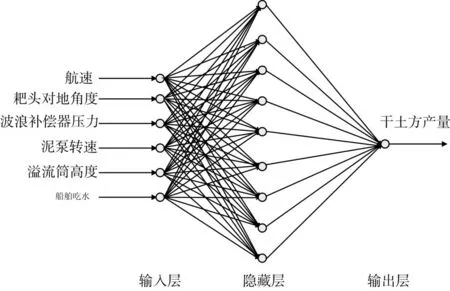
图2 BP神经网络模型拓扑
2)BP神经网络参数选择:输入层有6个节点,输出层有1个节点,隐含层节点数为9个,输入层和隐含层之间有6*9=54个权值,隐含层和输出层之间有1*9=9个权值,隐含层有9个阈值,输出层阈值为1个,所以遗传算法优化参数为54+9+9+1=73个。神经网络迭代次数设为200,学习效率为0.24,目标误差为0.0001。
3.2 耙吸挖泥船干土方生产率预测的验证
数据来自于2016年4月厦门港兴建的“新海虎8”号耙吸挖泥船收集。“新海虎8”号是一艘10000立方米的自航耙吸挖泥船,满载吃水8m,最大挖深达35m。数据包含船舶的速度、耙头对地角度、波浪补偿压力、泵速、船舶吃水、溢流桶高度、干土方生产率。我们收集了有5船周期数据。前4船数据用于训练网络,最后一船数据用于预测。为了评估遗传算法神经网络的性能,本文将BP神经网络与遗传BP神经网络预测结果进行对比。图3为BP神经网络预测干土方生产率结果、遗传BP神经网络预测干土方生产率结果和希望值。图4为两种预测方法产生的干土方生产率相对误差。
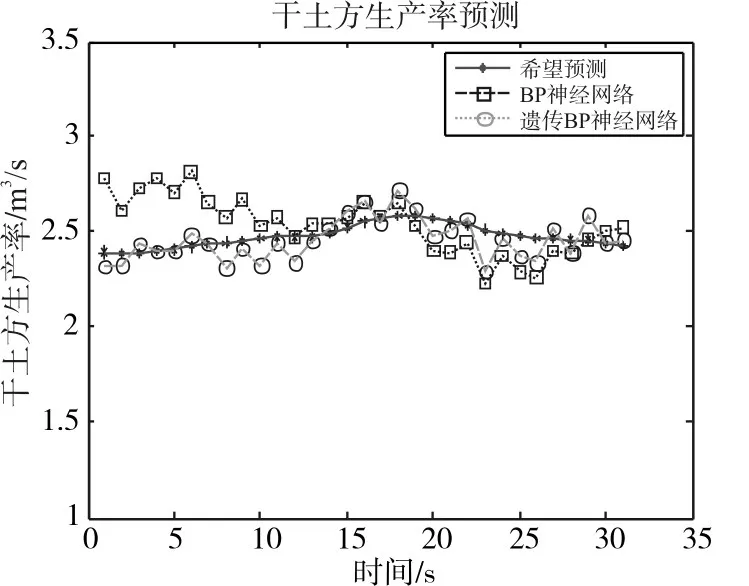
图3 干土方生产率预测结果比较
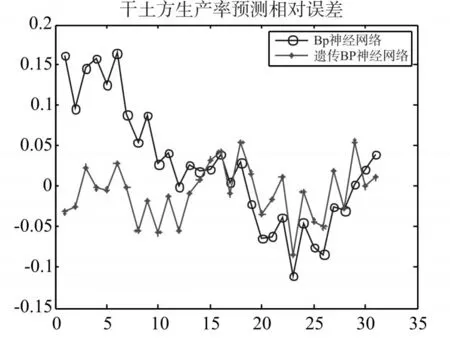
图4 干土方生产率预测相对误差
从图3可以看出两种预测模型都能够很好地反映干土方生产率的变化趋势和规律,说明两种预测模型都能较好预测干土方生产率。结合图4和表1可以得出,经过遗传算法优化后的BP神经网络预测结果更加精确。

表1 干土方生产率预测误差
4 结语
在文中,遗传算法优化的神经网络的优点和关键问题已经被提出来,对耙吸挖泥船干土方生产率和控制参数关系进行建模。我们的方法采用实数编码的GA策略,与反向传播算法混合。遗传算子被精心设计,以优化神经网络,避免问题过早收敛和置换。实验表明,该模型的预测性能优于传统BP神经网络,具有全局优化能力,并且拥有了更好的非线性拟合能力,使得预测结果的准确性更高。该算法可根据当前施工条件和给定的参数对耙吸挖泥船干土方生产率进行预测,提高疏浚产能。同时,有助于开发耙吸挖泥船的智能疏浚系统。考虑神经网络和遗传算法组合干土方生产率预测的一个问题是确定最优神经网络拓扑,本实验中描述的神经网络拓扑结构是手动确定的。一种替代方法是将遗传算法应用于神经网络结构优化,这将是我们未来工作的一部分。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
建材发展导向(2022年10期)2022-07-28
知识就是力量(2022年6期)2022-06-16
建材发展导向(2022年4期)2022-03-16
中国船检(2019年4期)2019-05-30
当代旅游(2016年10期)2017-04-17
环球人文地理·评论版(2016年10期)2017-03-20
发明与创新·大科技(2016年11期)2016-11-19
财经理论与实践(2015年2期)2015-04-16
中华建设科技(2009年9期)2009-12-31
