
基于植被分布特征的森林景观建模方法
2018-08-27 03:25:00李佳祺高亦远佘江峰
测绘学报 2018年8期
李佳祺,高亦远,佘江峰
南京大学地理与海洋科学学院江苏省地理信息技术重点实验室,江苏 南京 210023
作为新一代的地理语言,虚拟地理环境结合了计算机科学、虚拟现实、知识发现等技术与方法,对地理过程进行模拟、对地理规律进行总结以认识现实地理世界,在地理知识的表达与共享方面具有优势[1-4]。随着其快速的发展,虚拟地理环境逐渐在林业科学上应用实践,通过构建、表达、分析森林景观对象,能够帮助理解复杂的森林生态系统,以支持林业规划与决策[5]。其中,森林景观的建模与可视化表达一直是该领域的研究热点,在园林与景观设计[6]、森林景观可视化与空间格局表达[7]、生态研究和教育[8]等方面具有广泛应用。目前大部分的研究主要关注于两个方面:单株树木的自动化建模[9]与大规模森林的真实感和实时渲染[10-11],侧重于从视觉角度展现森林景观的模拟效果。然而,如何在一个三维场景中进行植物位置的合理布局并确定植物属性(种类、冠幅、高度)以反映森林景观的空间格局,对这一问题的研究尚不充分。现有的森林景观的构建方法通常只关注树木个体间的作用关系,而忽略了整体空间格局的表达,尚无法保证植被空间分布特征的准确性。
森林景观的构建方法可分为两类:自底向上的模拟方法和自顶向下的随机方法。模拟方法将树木个体抽象为按照一定速率生长的圆形,当发生重叠时出现资源竞争,优胜劣汰。每种树木具有特定的生长属性(生长速率、成熟时的死亡概率、资源竞争条件下的生存概率等),通过迭代地模拟树木个体间的交互作用最终确定每棵树木的位置[12-13]。一些学者考虑了环境因素对树木生长的影响,包括湿度、风、光照、坡度等[14-16],使得植被分布更加融入地形与环境。模拟方法考虑了基本的生态学规律,在展现植被演替和自稀疏等动态过程方面具有优势。然而较高的时间成本是这类方法的不足,模拟消耗的时间受到模拟步长、场景规模、植物总数等因素的影响,即使采用了邻域缓存,模拟千米级别的场景时仍需花费数十分钟[16]。与模拟方法不同,自顶向下的随机方法需要先给定植被分布的统计特征,在此约束条件下随机地生成植物生长点,每确定一个点位会对其周围空间的植被分布概率产生影响。常见的方法有半色调法[8]、投标法[17]和Wang Tiles方法[18],用于生成单种植被的简单分布。形变核方法首次考虑了多个树种间的相互影响[12],将树种间的作用关系划分为抑制与促进,利用形变核函数调整新点位周围的树木种植概率。文献[19]利用径向分布函数描述某棵树木周围其他树木的分布概率,以此生成相互聚集的植被分布。与此类似,文献[20]利用关联直方图描述种内和种间的空间分布特征。相比模拟方法,随机方法不需要迭代计算,具有更高的时间效率,适用于大规模植被分布的生成。
然而,模拟方法和随机方法生成的植被分布与真实的森林景观之间存在差异,无法反映每种植被的分布特征,即植被在景观尺度上的空间格局。森林景观的空间格局能反映森林的组成和树种的空间配置,在看似无序的景观中归纳出潜在的秩序与规律,为研究格局与过程之间的关系、优化森林空间配置提供参考[7]。在生态景观学中,中性景观模型可以生成具有特定统计特征的空间格局,而不涉及任何具体的生态学过程[21],这与自顶向下随机方法的思想是相一致的。目前,已有的中性景观模型包括基于渗透理论的随机二分模型[22]、等级中性景观模型[23]、基于分形的中性景观模型[24-25]和随机聚类模型[26]。然而上述模型只能反映景观组成和破碎度等总体特征,无法对组成景观的每种类型的分布特征进行区别化表达。
图论在区域的拓扑关系表达和网络分析方面具有优势,逐渐在景观连通性分析、景观规划和设计等方面得到应用[27-28]。本文提出一种基于图的中性景观模型,并将该模型应用于虚拟环境中森林景观的生成过程。借助图结构的拓扑分析功能,该模型能根据设定的类型景观指数生成特定数量、大小和形状的图斑。基于该模型生成栅格形式的景观图,建立空间位置与树种的对应关系。最后随机生成树木的生长位置,并根据树种赋予树木高度和冠幅大小属性。本文方法不仅能快速生成具有真实感的森林景观,而且可以表达特定的空间分布特征,为虚拟森林环境中的林业的规划决策以及植被分布规律的认知提供支持。
1 基于图的中性景观模型
随机聚类模型[26]首次引入了随机簇的思想,将二维格网随机地划分为若干破碎的、形状不规则的多边形(后文称为簇),并在组成比例的约束条件下对每个簇随机赋予类型值。然而该模型的随机性过强,无法对每个类型的图斑形状特征进行控制。本文提出的中性景观模型在前者的基础上将随机簇转化为相应的图结构,以区域生长的方式生成特定形状的图斑,相邻簇的查询与合并都是基于图的数据结构实现。具体分为3个步骤:①生成随机簇,将二维格网随机划分为若干形状不规则的簇;②根据簇之间的邻接关系生成区域邻接图,图结构中每个节点保存簇的大小与周长属性,每个边保存相邻簇的共享边界长度;③选择一个节点作为源节点开始受限生长,通过合并相邻节点中的最优节点生成特定大小、特定形状的图斑,重复此过程为每个类型生成特定数量的图斑。图1展示了类型i图斑的生成过程,其中n表示该类型的图斑数。对所有类型执行该流程即可得到最终的景观图。

图1 生成类型i图斑的流程Fig.1 The generation process of patches of class i
1.1 模型参数
景观指数通常作为中性景观模型的输入参数,能够高度浓缩景观格局信息,是反映景观结构组成和空间配置特征的定量指标。景观指数可以在3个层次上分析计算:景观水平、类型水平和图斑水平。图斑水平指数一般作为计算其他层次景观指数的基础,而本身对了解整个景观格局并不具有很大的解释价值[29]。在类型水平上同类型的植被具有若干图斑,可相应地计算一些统计学指标,包括图斑数和平均形状指数,以描述不同植被类型的空间分布特征。模型使用树种所占比例描述森林景观的组成,使用类型水平的图斑数和平均形状指数描述每种植被的空间配置特征,参数详见表1。平均图斑面积受到图斑数的间接控制,在面积一定时,图斑越多平均面积就越小。形状指数以圆作为参照几何形状,其值大于等于1。趋近于1时图斑形状接近圆形,该值越大图斑形状就越复杂或越扁长。

表1 模型参数及其计算公式
注:i为组成景观的类型;j为景观中某一类型的图斑序号;αij为第i种类型第j个图斑的面积;pij为第i种类型第j个图斑的周长;ni为第i种类型的斑块数量;A为景观的总面积
1.2 随机簇生成
生成随机簇的过程如图1所示。以5×5的格网为例,首先对格网中的每个单元随机赋值(0~1)。设置临界值c为0.45,大于c值的单元格标记为白色(图2(a))。以四邻域作为相邻标准,如果白色单元相邻则视作同一个簇,并用唯一标识标记。对尚未标记的黑色单元格,寻找距离其最近的簇,并将该簇的标记赋给单元格,如果距离最近的簇存在多个则随机选择(图2(b))。根据渗透理论,当c大于阈值0.59时最大簇的面积将急剧增加。为了防止某个簇的面积过大,尽量使每个簇的大小均匀,根据多次试验c取0.45能得到较好的效果。该步骤的结果是将二维的格网划分为若干个形状不规则的簇(图2(c))。

图2 随机簇的生成过程Fig.2 The generation process of clusters
1.3 邻接图转化
利用步骤1中生成的随机簇构建区域邻接图,每个簇可看作图中的一个节点。具体方法为:使用图3所示的边探测滤波器(虚线框)从左至右地逐行扫描格网,每次访问中心单元及其右侧和下方的单元。如果中心单元和相邻的单元同属一簇,则不进行操作。若分别属于两个不同的簇,则说明这两个簇相连,滤波器探测到边缘。需要先判断邻接图中是否存在连接这两个簇的边。如果这条边存在,则将边的值加1;若不存在,则为这两个簇节点建立一条边,并将边的值赋为1。图3展示了随机簇及其对应的区域邻接图。
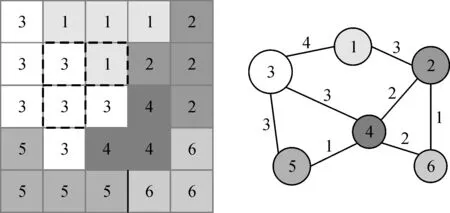
图3 将随机簇转化为区域邻接图Fig.3 Converting random clusters into region adjacency graph
边的值实际上代表两个簇的相邻边界长度,其目的是为了快速计算每个簇的周长。簇的周长只需要将经过该节点的所有边值相加即可得到,例如簇4的周长等于相邻4个簇的4段共享边界之和。另一个非常重要的目的是为了快速计算两个节点合并后的周长,以计算合并后图斑的形状指数。在对L×L的格网遍历一次的情况下,就能建立起区域邻接图并计算得到每个簇的周长和面积。所有节点的类型属性设为0,表示簇尚未被分配植被类型。如果一个节点被赋予植被类型值,说明该节点是一个已生成的图斑,不能被其他节点合并。
1.4 图斑生长
景观图是以图斑为单位生成的,每一个图斑由多个相邻的簇合并而成。在这个过程中首先需要选择一个源节点作为初始节点,从与该节点相邻的候选节点中选择最优节点进行合并,使得合并后图斑的形状指数最接近目标值,合并后的节点作为新的源节点重复上述操作,直到图斑大小落在目标值±5%时停止生长(见图1)。图斑的目标形状指数为所属类型的平均形状指数,图斑的目标大小为所属类型的平均图斑面积(见表1)。
源节点与可合并候选节点的选择需满足如下条件:
(1) 源节点,未赋类型值,且相邻节点中不存在同类型的图斑节点。
(2) 可合并节点,与源节点相邻,且相邻节点中不存在与源节点同类型的图斑节点。
下面以图4为例具体说明生成一个树种A的图斑时应如何选择源节点与相邻候选节点。图4 左侧表示节点合并前的图结构,其中节点1和节点3分别代表类型A和类型B的图斑,现要生成树种A的图斑,可作为源节点的节点有节点4、6、7、8、9。节点2和节点5不能作为源节点,因为这些节点与树种A的图斑相邻,将造成当前生长的图斑与已有图斑相连,会导致错误的图斑数。假设通过随机选择节点4成为源节点,与其相邻的四个节点中节点3已赋类型值,不能被合并;节点5与树种A的图斑相连,若合并也将造成错误的图斑数,因此只有节点6和节点8是可合并的相邻节点。

图4 源节点与相邻候选节点的选择Fig.4 The selection of source node and neighbor candidates
在确定源节点与可合并的候选节点后,需计算源节点与每个候选节点所构成图斑的周长、面积与形状指数,以从中选择最优节点不断逼近目标形状指数,计算方法为
式中,Ps代表源节点的周长;Pi代表第i个候选节点的周长;Esi代表两个簇的相邻边界长度。由此可见,记录相邻边界长度可以简便快速地计算合并后图斑的周长。源节点合并最优节点后需更新周长和面积属性,成为一个新的源节点。需要注意的是,节点合并后图的拓扑关系发生了变化,应及时更新图的结构,如图4所示。不断重复节点合并操作,当前图斑大小落在目标值±5%时停止生长,一个图斑生成完毕。实际上,图斑形状指数和面积的实际值与目标值之间存在一定的偏差,为了保证最终的类型景观指数符合模型的设定值,每生成一个图斑都将误差平均补偿给尚未生成的同类型图斑,更新其目标值。
2 结果与讨论
2.1 森林景观的建模与可视化结果
利用本文提出的中性景观模型合成单一树种的虚拟森林景观(图5),红色代表生成的图斑,背景中每个颜色代表一个簇,图中3个景观的生成过程使用了同一个随机簇。3幅图中,树种的图斑数为2,目标图斑大小为1000,而目标形状指数分别为2.0、3.0和4.0。实际的MPS和MSI相对于目标值存在一定的误差,但误差较小,在可接受的范围内。随着平均形状指数的增加,图斑的形状越来越复杂,蜿蜒曲折,表明模型对图斑的形状具有可控性。在景观图的基础上随机生成树木的生长位置及其属性。为了模拟不同植被混合生长的过渡带,使用一个n×n的窗口统计生长点附近的植被类型及其所占比例,比例代表可能成为该树种的概率,根据这一概率随机地确定植被类型。n为1时树木的边界最清晰,n越大树种间的过渡带就越宽。最后赋予树木符合该树种统计特征的高度和冠幅属性。
本文研究使用黑龙江凉水国家级自然保护区内一块2.5 km×2.5 km样地的森林资源调查数据作为试验数据,对模型的结果进行了验证。样地内的树种由云杉、冷杉、白桦和落叶松组成(图6(a)),所占比例分别为40.2%、14.7%、10.0%、24.5%。经统计计算,每个类型的图斑数分别为4、7、8、5,平均形状指数分别为2.10、1.63、1.56、1.50。将以上数据作为模型的输入参数,得到的结果如图6(b)所示。可以观察到,结果图中每个类型的图斑数与实际情况一致,这是因为模型以图斑为单位生成森林景观,可以精确控制图斑数。模拟结果中植被所占比例分别为38.6%、14.9%、10.2%、25.3%,模拟值与实际值基本一致;平均形状指数分别为2.27、1.54、1.55、1.64,与目标值的误差在±0.2以内。在图6(b)的基础上,使用相应的树木模型构建了一个秋季的森林景观(如图6(c))。可以观察到,云杉的分布主要呈条带状(平均形状指数最大),而白桦的分布主要呈团状,且较为分散;每种植被的分布特征各有差异且符合样地的实际情况,能反映森林景观的真实空间格局。

图5 单种植被的森林景观及其可视化结果Fig.5 Three landscapes of single tree species and their visualization results

图6 包含4种植被的森林景观及其植被分布的可视化结果Fig.6 The forest landscape with four tree species and the visualization of its tree distribution
2.2 模型效率分析
本模型的算法是基于图结构实现的,需要执行大量的节点操作,因此节点数量对模型的性能存在负面的影响。在步骤1中格网被随机划分为若干个簇,其中有很多面积较小的簇,通常仅占几个单元。这些簇对图斑形状构成的贡献并不大,而且对应的节点加入到图结构中使得图的网络更加复杂,对频繁的相邻节点查询操作带来较大的负担。以k作为最小簇的大小,将图2(b)中面积小于k的簇重新标记为黑色,以去掉过小的簇,并对其所包含的单元格按照最近簇的标记赋值。图7(a)展示了簇的数量(100次试验的平均值)随着格网大小和k值的变化情况。当格网的边长一定时,随着k的增加簇的数量明显减少,减少趋势逐渐变缓。当k一定时,随着格网尺寸的增加簇的数量增加。簇的数量决定图结构的复杂度,直接影响模型的运行时间。图7(b)中的每个点代表在特定格网大小和k值下模型运行100次的平均时间(模型输入参数与图6的景观相同),曲线的走势与前者一致。当L=100,k≥1时模型的平均运行时间在1 s以内。虽然较大的k值可以提高运行效率,但簇数量的减少使得图斑难以通过合并破碎的簇节点对自身属性进行修正,将导致模拟结果存在较大的误差。通过多次试验,k取2时能在效率和准确性之间达到平衡。

图7 k值与模型运行效率的关系Fig.7 The relations of k value and the efficiency of the proposed model
本文提出的方法通过Python语言实现,试验环境为:2.3 GHz Intel Xeon CPU,8 GB内存。文中的森林场景图片由Terragen软件渲染生成。
3 结 论
本文提出了一种基于图的中性景观模型,根据输入的植被组成比例、图斑数量以及平均形状指数,能生成具有特定植被分布特征的森林景观。该模型将随机簇转化为图结构,以图斑为单位从源节点开始受限生长,每次生长时合并相邻节点中的最优节点使得图斑的形状指数逼近目标值。试验结果表明,模型可以精确地控制图斑数,景观类型的组成比例和平均形状指数虽然存在一些误差,但误差在可接受范围内,对最终的树木分布影响较小。与其他中性景观模型相比,本文提出的模型在可控性和灵活性上具有优势,可对景观中的每一种类型区别化表达。最后在景观图的约束下确定树木的位置、类型和属性,生成的大规模植被场景符合设定的类型景观指数。
实际上,中性景观模型只是对已有的景观格局进行复制,生成相似的空间格局,而没有考虑地形等非生物因素对植被生长的影响。例如,坡度较大的山坡上难以生长高大的树木,超过一定海拔有些树种不宜生存。进一步的研究中可考虑这些非生物因素,例如为簇节点增加用于描述植被生长适宜度的属性,利用地形坡度和海拔高程对其进行评价,以生成与环境更加融合的森林景观。
猜你喜欢
中学生天地(A版)(2022年11期)2022-11-25 07:43:16
北京测绘(2022年9期)2022-10-11 12:25:14
绿色科技(2021年5期)2021-11-28 14:57:37
空间科学学报(2020年6期)2020-07-21 05:36:46
计算机技术与发展(2020年4期)2020-04-30 04:36:30
新世纪智能(英语备考)(2018年11期)2018-12-29 10:56:52
小学生学习指导(低年级)(2016年10期)2016-12-01 06:10:42
江西理工大学学报(2015年3期)2015-12-22 05:26:18
中国土地科学(2014年4期)2014-03-01 03:25:07
测绘科学与工程(2014年4期)2014-02-27 07:06:03
