
大众点评数据下的城市场所范围感知方法
2018-08-27 03:26:36王圣音陈泽东
测绘学报 2018年8期
王圣音,刘 瑜,陈泽东,施 力,张 晶
1. 首都师范大学资源环境与旅游学院,北京 100048; 2. 北京大学遥感与地理信息系统研究所,北京 100871
虚拟地理环境作为发展地理信息表达与处理的新一代平台,探索如何将人类对于地理环境概念的认知模型和语义模型转化为数学或逻辑模型,如何将人类对于时间空间过程推理融合在虚拟地理环境中[1-3]。在虚拟地理环境中,场所是地理空间知识表达的核心要素,也是表达人类活动与地理环境耦合关系的重要纽带,与虚拟地理环境一同继承地理学沟通自然科学与人文社会科学的“桥梁”的特征,从而为深入理解和表达人类主观认知中的地理环境,以及基于虚拟地理环境的分析模拟提供支持[4-7]。“场所”(place)是被赋予了个体经验、活动与情感意义的空间位置或区域[8],是理解地理环境的重要途径之一[9-10]。
文献[11]指出场所研究需在对概念场所的位置及范围(footprint)进行形式化的基础上开展,以深入探究场所界域内所承载的活动、交互、情感等社会经济属性及特征。场所范围的表达作为场所建模的基础与核心,其本质是模糊区域建模问题。由于场所的范围具有模糊性,其认知往往因人而异,且根据特定的描述情境而变化,因而相比于具有明确边界的行政区、建筑物、普查小区等区域,有关场所的地理信息难以表达于地理信息系统中[12]。为此,许多研究者针对不同类型的模糊区域范围进行提取试验。传统认知试验是划定模糊区域边界的有效方法,其原理是集合大众的认知划定普遍共识中的区域范围及边界[13-14]。然而,认知实验虽能直接反映大众的空间认知,却由于实验成本高,难以满足对多个场所建模的需求。
随着基于位置的服务的广泛应用,研究者可借助各类海量时空数据探究人们对地理环境的认知,为场所的感知提供了丰富的属性内容[15],也涌现许多模糊区域(场所)范围的感知方法[16-25]。其中,文献[17]提取网页文本中的共现地名及其地理位置,采用核密度估计方法(kernel density estimation,KDE)对模糊地名的近似空间范围进行建模;文献[21]提出了适用于Flickr照片的城市场所提取流程,采用DBSCAN方法进行点集聚类,并通过Chi-Shape算法得到多边形以表征场所;文献[22]从多源社交媒体数据中提取“南加州”“北加州”相关的点数据,采用DBSCAN探寻其边界,结果显示与Montello的传统认知实验方法下的结果较为一致,继而总结了基于众源数据的场所建模方法具有样本量大、可重复、尺度适应等优势[23]。
总结现有的模糊区域建模方法,包括认知试验与模糊集方法[13-14,22]、基于几何体的方法(如Voronoi图[17]、凸包[18])、基于插值的方法(如核密度估计[19-20])、基于空间聚类或分类的方法(如DBSCAN[21,23],支持向量机[24-25])等。其中,几何体方法最为简便,空间聚类和分类方法也体现出较高精度,但这两种方法对边界的划定过于武断而忽略场所模糊特性。并且值得指出的是,现有的研究仅对单个或少数几个模糊区域进行表达,不能够很好地回答以下几个问题:城市中存在哪些场所?能否从众源数据中提取更多场所,从而反映人们对城市的基本认知和空间结构?如何在同时构建多场所时,有效处理场所尺度、样本量及点集分布的差异性所带来的阈值选取问题?
因此,本文针对众源数据,提出基于自适应核密度估计的模糊集方法,以构建城市内多场所(multi-places)的模糊表达。由于传统模糊集方法被认为在函数选取上较为主观,本文通过点集局部密度表征人们对场所位置的认同程度,从而保留场所模糊特性。最终,以北京市五环区域内的场所为研究对象,从大众点评网采集带有场所名称的兴趣点(POI),实现针对城市多场所的多尺度空间范围自动构建与可视化。本文所表达的场所均为城市居民普遍熟知和频繁使用的地理区域名称,旨在提供可反映城市空间认知的场所分析单元,为进一步感知场所的活动和情感语义提供支持。
1 研究方法
由于基于众源数据的点密度可反映公众对该场所的认同度,本文运用点集生成多边形的思路确定该场所范围[13,16],即针对每一个场所的点集分别进行离群点去除与核密度估计,并以核密度值为模糊隶属度函数(fuzzy membership function)的自变量,从而定义与概率密度值相对应的模糊隶属度,使之以[0,1]范围内的数值表示某一区域范围内不同位置对该场所的隶属程度,进而通过等值线截取模糊集,构建多场所范围的多尺度表达,流程如图1所示。
1.1 自适应核密度估计和标准化
核密度估计法是采用平滑的峰值函数对空间中离散点xi(i=1,2,…,n)进行平滑扩展,将各个点拟合为连续光滑的概率密度曲面。假设每个点xi为一个事件,则以xi为中心,h为半径(或称带宽)的区域内各位置发生该事件的概率随距离衰减,使得与要素距离近的位置将被赋予更高概率,并在边缘处概率衰减为0,通过叠加空间中所有点要素所对应的概率密度函数,呈现出点要素聚集区域密度高,离散区域密度低,从而展现某一空间范围内密度的连续变化特征,其公式为
(1)
式中,距离衰减的幅度由核函数K决定,本文采用Silverman提出的二次核函数[26]
核密度带宽h代表每一个点的平滑范围,其取值对核密度计算结果影响较大,若带宽选取过小,将得到离散的面域单元,过分突出点集的局部聚集区域;若带宽选取过大,所得到的场所将被过度概化,其结果趋近于圆形。在多场所生成过程中,若采用固定带宽,则无法适应各场所的尺度和疏密程度差异。如图2(b)所示,统一采用600 m带宽时,可适应右侧两个尺度较小且密集的点集,却无法适应左侧两个尺度大且稀疏的点集,因而得到离散面域;采用1500 m带宽时,将使得图2(c)中右侧点集被过度概化为圆形面域。
由此可知,带宽h的选择应与每一场所的点集离散程度呈正相关,对于稀疏型的点集应采用较大的带宽,而对于密集型点集应采用较小的带宽[26],因而本文通过各点集的外包矩形面积S与点集总数N评估每一场所点集的疏密程度,并乘以系数k以计算自适应的带宽h,具体公式如下
由此得到适应于不同点集的带宽,可基本适应尺度不同的点集(如图2(d)所示),所得到面域范围能够较好地体现点集的可能性范围。此后,为使各场所的计算结果处于同一量纲下,需对原始数据进行线性变换,将其映射到[0,1]之间。公式如下
1.2 利用模糊集方法计算隶属度
文献[27]根据边界将地理实体分为两个类型,一类是具有真实边界的对象(bona fide object),如湖泊、土地利用类型、建筑等;另一类是需要制定或划分的对象(fiat object),通常是基于认知或法令规定的。由于大部分场所属于fiat对象,具有边界不确定、可认知、渐变的特点,通常可采用模糊集方法表达模糊地物的边界[28],即通过建立相应的隶属度函数(membership function)[29],为空间中每一个位置赋予[0,1]之间的数值以表征其隶属于某一场所的程度,这一方法在模糊地物边界表达方面得到广泛的应用。
根据文献[30]的观点,概率理论与模糊理论在表达不确定性时具有不同的解释能力,概率是从事件发生的频率来评估其发生的可能性,而模糊集是描述事件属于“发生”这一范畴的程度。本文1.1中采用核密度估计方法计算空间中每一个位置属于某一场所的密度概率,根据“点集密度越高,表示公众对该位置隶属于该场所的认同度越高”的假设,核密度值与隶属度本应呈正比,然而密度的差异一方面来自公众的认同度,另一方面则来源于商铺分布的不均匀性,即少数区域的核密度值由于商铺点的过度聚集而极其显著,而核密度较高值与低值相比,由于其差异不显著,在取截集时易被忽视。为进一步定义核密度值所对应的隶属程度,本文对核密度值进行模糊函数变换,以归一化后的核密度值作为自变量x,定义高于概率密度m的区域为隶属于场所的区域(μ(x)>0.5),从而平滑核密度较高值与极端高值区域在隶属程度上的差异,所采用的模糊函数如图3所示,公式为
式中,s是散度,散度越大,曲线越陡峭;m是中点,即隶属度为0.5时自变量的取值。图3为m取值0.2时的模糊隶属度函数。
1.3 方法验证
由于模糊区域缺少相应的真实边界,对建模方法的验证通常采用准确率(precision)、召回率(recall)、F1等指标对具有真实边界的区域(如行政区域)进行提取与计算[24-25]。行政区域与模糊区域虽在本质上不同,但仍可在一定程度上验证方法的可行性与提取精度。假设R为行政区的真实范围,R′为试验所得的范围,则准确率为提取结果中的正确范围占真实范围的比例,召回率为提取结果中的正确范围占所提取结果的比例,F1为准确率与召回率的调和分数。3个指标的计算方法如下
本文采用大众点评网中商户自行标定的商铺POI坐标及其行政区属性,在10个行政区以不同的核密度系数k进行面域构建试验,并对比传统凸包算法,所得结果如表 1 所示。由于准确率(precision)高度依赖于点集覆盖程度,而本试验所采集的点集在除东城区和西城区以外的8个行政区内未能全面覆盖,使得传统的凸包方法因其易使范围估值过大的特点,在准确率和F1值高于本文的方法。召回率是评价结果的正确率的指标,因此在评价方法时,应重点考察召回率。表 1 中,本文方法的召回率平均值达到0.9以上,而凸包算法远低于本文的方法,且当点集全面覆盖全行政区时,观察到东城区和西城区的准确率与F1值整体略高于凸包算法。因此,本文的方法对模糊认知区域的提取具有一定优势。

表1 本文方法与凸包方法试验结果对比
2 研究数据与预处理
2.1 研究数据
本文选取北京市五环区域作为研究区,通过大众点评网API接口获取79 863条商铺点数据,共涉及120个“商圈”名称标签。所获取的POI属性信息均为商户自行填写,包含名称、地址、坐标、所属商圈、类别等信息,其中,“所属商圈”是由商户从大众点评网所提供的商圈名称列表中自行选择。该数据具有以下几个特点:①具有认知性。数据产生于商户,因而代表了商户对商铺所属场所的认知,点集的疏密程度能够体现商户对商铺所属场所的认同程度。其中,部分商圈标签由两个名称组成,例如“西直门-动物园”,也反映出这一名称具有其特定含义并被广泛接受,因此在本文中算为一个场所。②层级一致性。商圈名称列表中的场所名称在尺度、层级等具有一致性,不存在一名多地、一地多名的情况,以及两个地名之间的包含、被包含关系。③数据偏向性。由于单一数据源仅代表特定人群和特定语义情境下的观点,相比于更侧重体现游客在旅游行为下的场所认知的Flickr数据[21],大众点评数据集则能够更好地揭示商户在餐饮消费行为下的场所认知。
2.2 数据预处理
由于数据中存在少量人工标定误差和认知误差造成的离群点,为避免每一个点集之内的少量离群点对自适应核密度带宽的计算造成影响,本文采用了kNN(k-nearest neighbor)算法,设定一定的距离阈值去除离群点。首先,计算点集的全局平均距离L,以及点集之中的每个点i到距其最近的k个点之间的平均距离Li,若Li>nL(n为任意常数),则判定点i为噪声点。本文设定k=5,n=5,图4为去除离群点前后的“安定门”点集分布。
3 试验结果与分析
3.1 单一场所范围划定示例
为比较各参数下场所范围划定情况,本节以安定门点集为例,展示了模糊隶属度参数m=0.2,s=3,自适应核密度带宽系数分别取值为1、3、5、10时,“安定门”场所范围划定结果。绘制不同隶属度的等值曲线可多尺度表达场所范围,等值线所围成的区域称为模糊截集σ,其中σ>0.9可被认为是公众认同度较高的场所核心区域,σ=0.5可认为是场所外围区域,而σ<0.5的区域则可被认为是非场所区域。根据“鸡蛋/蛋黄(Egg/Yolk)”模型[31],σ=0.9和σ=0.5以内的区域可被分别认为是“蛋黄”与“鸡蛋”。
由图5可知,随着核密度带宽系数k取值的增大,空间范围划定结果由离散面域逐渐形成连续面域。当k取值过小,使得密度分析结果过分突出局部聚集区域,却忽略了场所的全局特征;当k取值过大时,过度平滑将使场所面域范围过度概化为一个圆形面域,造成范围估值过大。
3.2 城市多场所范围划定结果
为简化计算,本文根据3.1中的安定门点集所呈现的范围划定结果,统一选取核密度带宽系数k=5,模糊函数参数s=3,m=0.2,对大众点评数据下120个场所范围进行提取试验,图6(a)以三维图形展示了各场所的模糊认知,红色峰值代表模糊隶属度高值区域,蓝色代表未被本文所提取的场所覆盖的隶属度低值区域;图6(b)分别截取了0.9与0.5截集,以矢量形式对场所范围进行多尺度表达,分别定义其为“核心区”与“外围区”,以满足对模糊场所进行精确化构建的需求。
以下将从结果中随机选取14个场所,将大众点评数据的提取结果与百度地图所提供的场所范围截图进行对比,并做简要分析与讨论。
图7中紫色区域为大众点评数据所表达的该场所核心区(σ>0.9),黄色区域为该场所外围区(σ>0.5),由图可知,三里屯、西单、崇文门、什刹海、紫竹桥、前门等场所范围提取结果与百度地图显示范围分歧较少,而对于其余场所则有较大差异。总体而言,语义相似性或差异性主导了模糊范围划定结果的差异:

图1 方法流程Fig.1 Workflow of multi-places generation
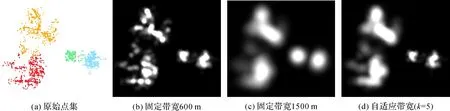
图2 不同带宽下对不同场所范围表达结果Fig.2 Representation place footprints with different scales under different bandwidths
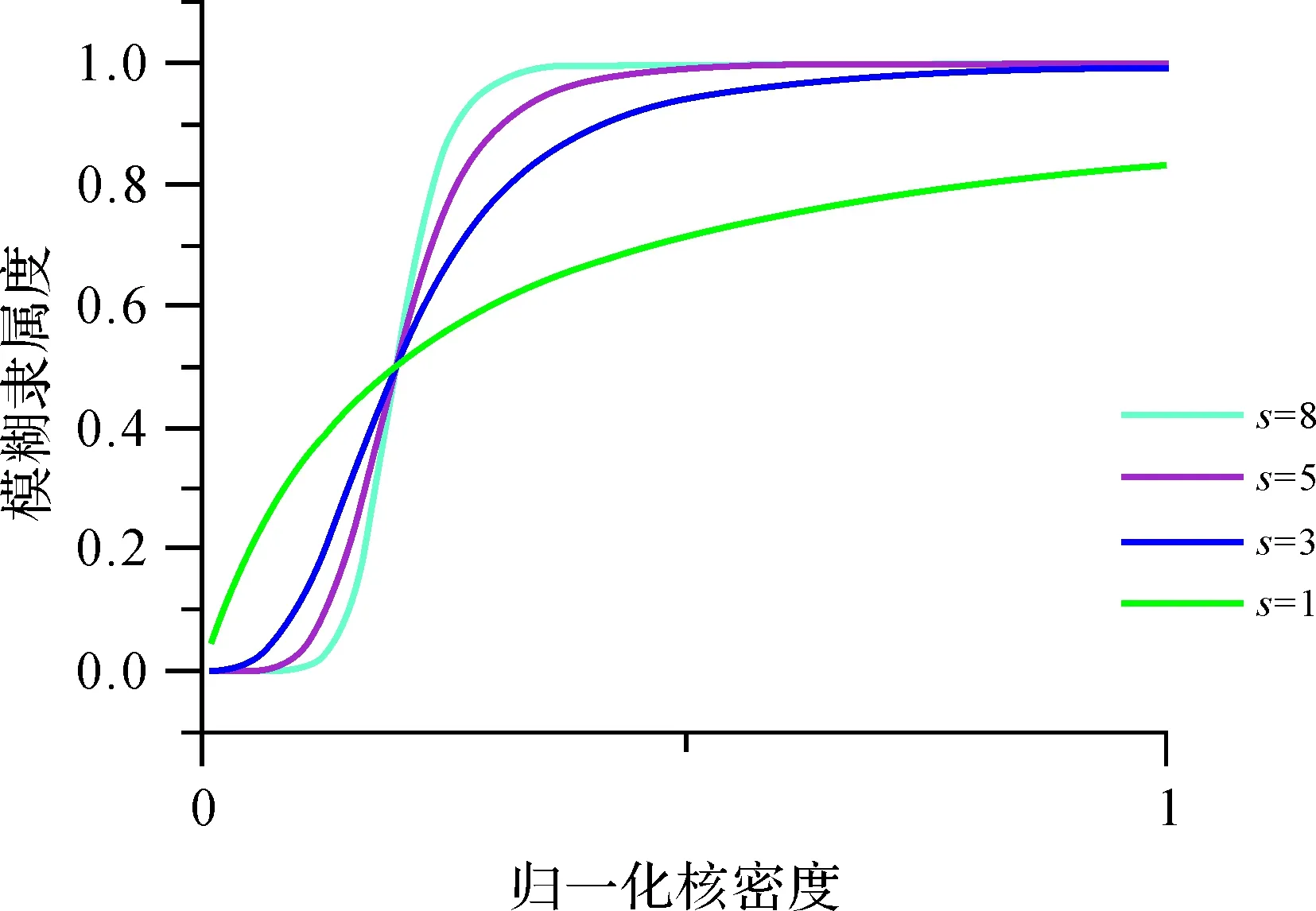
图3 模糊隶属度函数曲线Fig.3 The function curve of fuzzy membership
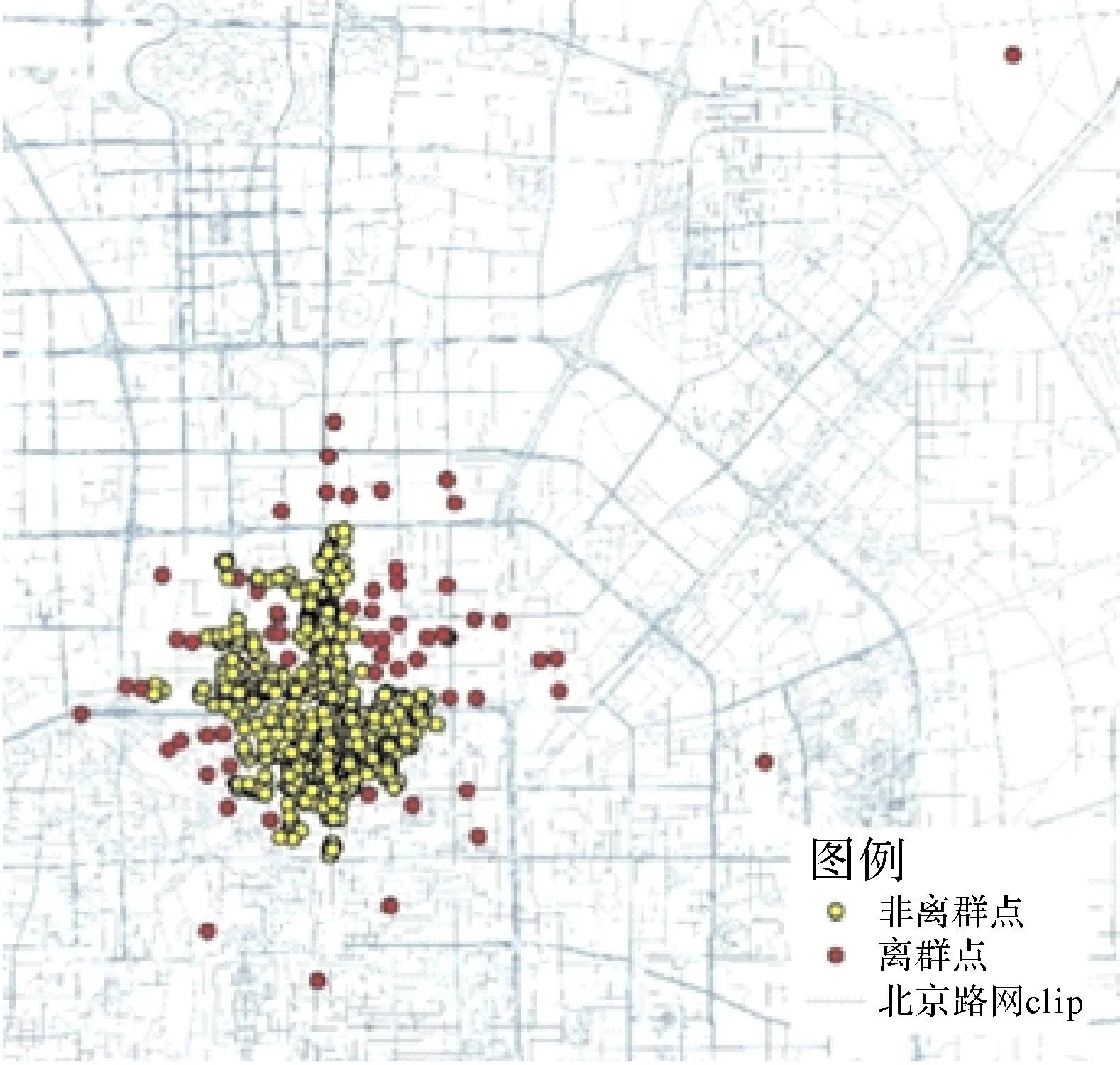
图4 离群点识别与清除Fig.4 Identification and clearance of outliers
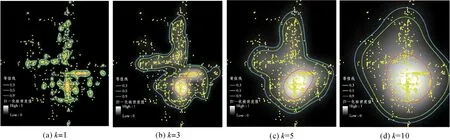
图5 大众点评“安定门”点集场所边界表达结果Fig.5 The point set boundaries of Andingmen

图6 五环内场所范围提取结果Fig.6 The distribution of place footprints inside the 5th ring road of Beijing

图7 部分场所范围提取结果Fig.7 The footprints of sample places
(1) 语义(名称或语义情境)的相似性导致某一场所名称所对应的覆盖范围向外扩展延伸,大于行政定义的场所范围(如紫竹桥、学院桥、牛街等路段被扩展为新的场所区域;位于北四环的学院桥由于包含“学院”二字,且隐含高等教育语义,其认知范围被扩展至北五环以南的学院路及其周边的多所大学;位于西三环北路的紫竹桥路段,其模糊范围包括了紫竹院公园和紫竹院街道所管辖的区域;牛街由于隐含回族聚居区语义,其范围向北延伸至长椿街,向南延伸至右安门内大街的北段,涵盖了回族居民的生活范围)。
(2) 同一场所名称下,语义内涵的差异导致某一场所范围在某一数据下未能包含不同语义情境下的范围,如大众数据的核心区范围注重对商圈语义下的前门、天坛、动物园、望京、双榆树、中关村、人民大学等场所的表达,使旅游语义下的前门城门楼、天坛公园园区、动物园园区,职住语义下的望京和双榆树,以及高科技与高等教育语义下的中关村区域、人民大学校园等被弱化表达,由此可知,大众点评作为面向消费者的信息服务应用,其数据中潜在的商圈语义较强,因而着重表现了该场所名称下的商圈范围。同时也反映出单一数据源对于场所范围的界定缺乏完整性。
4 结 论
本文提出了基于自适应核密度的模糊集方法,构建了场所范围自动化提取流程,并利用大众点评兴趣点(POI)数据对北京市五环内的热门场所及其范围进行提取与可视化表达。试验结果表明,该方法能够:①有效处理多场所(multi-places)点集,对不同分布情况的点集具有良好自适应性,解决了多场所构建过程中的阈值选取问题;②同时支持模糊集(栅格)和矢量两种形式的表达,即矢量形式的多尺度、多层次表达结果可为今后的城市场所研究提供可用的场所单元;模糊集表达结果弥补了传统的凸包、Voronoi多边形等矢量表达形式对场所渐变边界的过度简化,且能够表达一个位置隶属于多个场所的情况。该方法所提取的结果能够为理解城市空间提供新的分析单元,以进一步探究场所中人的活动与移动、情感与交互等特征,并能够与重视人文过程、公众参与、地理知识获取与表达、人机交融与虚拟地理试验的虚拟地理环境研究产生新的结合点,为地理信息科学对于人文地理现象与过程的研究提供新的思路、技术与手段,从而促进人地关系理论的发展[5-7]。
场所的认知范围与人们的认知背景(个体的经验与情感)和上下文语境(如教育、居住、商业等特定活动)紧密联系,基于不同语义所提取的场所将有所差异。例如,“人民大学”可以指代大学校园,也可以指代周边的居民生活区;“前门”既可以指代古城门楼,也可以指代前门大街的商圈。通过观察本文的场所提取结果,发现大众点评数据集所提取场所范围更侧重于体现商圈语义下的场所认知。为使所获取的各场所范围更具普遍性和全面性,可在今后的工作中考虑多源数据融合,以在一定程度上消除单一数据源(或主体)对特定语义情境的偏向性。另外,由于本文数据中所提供的商圈名称极少涉及包含、重叠等层级关系,可反映出大部分场所名称都属于空间认知的同一层级,因此本文未涉及对场所层级性特征的探讨,未来可进一步提取不同层级的场所名称及其范围,以研究场所层级关系的表达方法。
猜你喜欢
中学生数理化·八年级物理人教版(2021年12期)2021-12-31 03:23:08
中学生数理化·八年级物理人教版(2021年12期)2021-12-31 03:23:02
现代装饰(2020年7期)2020-07-27 01:28:32
开放教育研究(2020年2期)2020-03-31 01:54:14
中学生数理化·八年级物理人教版(2019年12期)2019-05-21 07:26:36
中学生数理化·八年级物理人教版(2019年12期)2019-05-21 07:26:36
小学生必读(中年级版)(2019年6期)2019-01-11 09:17:10
中国现当代社会文化访谈录(2016年0期)2016-09-26 08:46:13
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
