
大数据环境下一种基于模式匹配的实体统一方法
2018-08-15 08:02:32熊安萍龙林波
计算机应用与软件 2018年8期
熊安萍 詹 妮 邹 毅 龙林波
1(重庆邮电大学计算机科学与技术学院 重庆 400065)2(重庆邮电大学软件学院 重庆 400065)3(重庆市公安局网安总队 重庆 401121)
0 引 言
随着互联网、移动互联网、物联网的蓬勃发展,数据产生的方式不断在扩展,数据之间的关系变得千丝万缕,呈现出大规模数据关联、交叉和融合的局面[1]。数据融合的概念最初来源于多传感器数据融合,主要集中于军事领域。在信息检索领域也存在数据融合的概念,旨在将多个独立的数据集上的检索结果合并成一个统一的结果,使得合并后的检索效果尽可能接近在一个集中数据集上进行检索的效果。大数据融合更为具体和形象的解读在于:通过对融合数据进行实体统一、冲突解决、数据关联,形成以目标实体为中心的多侧面全景视图[2]。实体统一一直以来都是数据融合和数据清洗中的重点研究内容,是指将表示同一现实世界实体的不同记录识别出来,并进行合并,从而达到消除数据冗余,提高数据质量的目的,其结果影响着数据质量[3-4]。
1 相关概念
当前实体统一主要有三种基本的解决思路,第一种是穷尽式的实体统一即传统的实体统一方法,通过两两比较数据集中的所有实体即实体匹配操作,判断两个实体是否为同一个实体。这种传统实体统一算法计算代价是相当高的,其主要针对小数据集,重点关注统一结果的准确性。随着大数据时代的到来,传统的实体统一方法由于时间复杂度较高,难以处理大规模数据。
第二种思路是基于分块[5]的实体统一,例如标准分块(Standard Blocking)[6]方法定义了块的键值,具有相同块键值的实体同属于一个块中,初步将较为相似的实体划分到同一个块中,大大减少了匹配次数,时间复杂度由O(n2)降低为O(θ×n),但其匹配操作仅在块内进行,忽略了块间存在同属于一个实体的实体。近邻排序(Sorted Neighborhood Blocking)[7]的分块方法解决了块间匹配的问题,先将记录按照特定的属性值进行排序,然后对排序的记录利用固定长度的滑动窗口进行扫描,只有在同一窗口中的记录才进行匹配。该方法的一个主要不足在于滑动窗口的大小是固定的,如何确定窗口的大小成为一个关键的问题。如果窗口较大会影响效率,如果窗口较小又会导致相似但距离较远的实体无法被包括在同一个滑动窗口下。Yan等[8]对近邻排序法进行了优化,提出一种动态改变滑动窗口大小的算法。Baxter等[9]运用基于q-gram的索引方法,将每个实体根据它的块键值所生成的变形被插入到多个块中。Canopy聚类[10]算法通过快速计算块键值的距离,将每条记录插入到一个或多个重叠的块中。该算法虽然精度较低,但在速度上具有很大优势,适用于对待实体统一数据的预处理。
第三种则是基于分布式架构的实体统一,采用MapReduce模型提高实体统一计算效率成为目前较为流行的研究方向[11-12]。文献[11]提出依赖度的概念,筛选出与原分块中依赖度较低的实体进行二次匹配,并通过设定跨度距离来控制二次匹配的实体数量,虽然能有效提高时间效率,但在二次匹配中若设置较大的跨度距离,则会忽略需要二次匹配的实体对。
综上所述,现有的实体统一算法往往统一结果准确性高则时间开销就会较大,且大规模数据下仍然时间效率不高。而基于分布式架构的实体统一方法尽管还不够成熟,但已成为海量数据环境下数据融合处理的有效途径。本文提出一种大数据环境下基于模式匹配的实体统一方法,在一定程度上确保结果有效性的同时,提高实体统一计算效率,能够从大规模数据中更快速地筛选出有价值的数据。
2 实体统一算法模型
在大数据平台下如何高效实现实体统一往往成为某些业务应用的重要标准。Spark是一个分布式并行处理模型,有效结合了Hadoop和自身的优点,能够快速地进行迭代计算。本文提出的算法模型以Spark集群为基础,结合分块计算、块内实体迭代匹配计算,并考虑到块间存在同一实体的情况,从这三个方面来控制和减少匹配的计算量,并保持实体统一结果的精度。
2.1 算法模型
本文实体统一算法模型包括3个模块——数据分块模块、模式匹配和抽取模块、模式合并模块,如图1所示。

图1 实体统一算法模型
(1) 数据分块模块 由于标准分块算法[6]能大大控制后续计算量,因此该模块利用标准分块算法初步将较为相似的数据划分到同一个块中。输入为待统一数据,输出为实体集合R={R1,R2,…,Ri,…,Rn},1≤i≤n,每个实体集合对应到相应的块集B中B={B1,B2,…,Bi,…,Bn},1≤i≤n。
(2) 模式匹配和抽取模块 本文在基于编辑距离的模式匹配算法IterER[15]基础上提出一种基于模式快速扫描的实体统一算法 PRSER (Entity Resolution Based on Pattern Rapid Scanning)来计算实体对相似度。首先运用PRSA算法(Pattern Rapid Scanning Algorithm)对实体对进行快速扫描,再利用模式抽取算法PEA(Pattern Extract Algorithm),即将匹配的实体对通过IterER算法进行回溯,得到相似实体的模式。输入为记录集合R,输出每块中的模式集合,例如块Bi内模式集M={Mi1,Mi2,…,Mix},x∈C。
(3) 模式合并模块 该模块再次利用PRSER算法,将块间的模式进行匹配,并对相似的模式进行合并。输入为每块中的模式集合,输出为匹配后的模式集合,每一个匹配后的模式集合对应一个实体。
2.2 相似度计算
判断两个实体是否为同一个实体,通常需要计算实体间的相似度。一般而言,一个实体包含多个属性,而每个属性可能存在不同的数据类型,针对不同类型的数据其相似度计算方法也有所不同,比如数值型数据间相似度计算可以利用数学公式设计相应的相似度函数。大数据环境下,文本型数据居多且相比于其他类型属性相似度计算困难,因此本文将重点讨论基于文本类型的实体相似度计算方法。然后,通过各属性相似度加权求和的方式得出一个综合相似度值,并与设定阈值相比较,各属性权值可以由领域内专家分配,也可以通过机器学习获得。常见的基于文本类型相似度计算方法有编辑距离算法、Jaro-Winkler算法、TF-IDF算法等。其中编辑距离算法[13]广泛应用于实体统一。该算法通过插入、替换和删除操作将一个字符串转化为另一个字符串所需要的最少操作次数,即两个字符串的距离。文献[14]对传统的编辑距离算法进行了优化,提出Damerau-Levenshtein编辑距离增加了一个相邻字符调换的操作。

(1)
式中:

(2)
(3)

(4)
2.3 模式快速扫描算法(PRSA)
每一个块中的实体之间都有一定相似性。首先通过标准分块算法进行预处理,将较为相似的实体划分到了一个块中。基于这种特性,可以对块内实体相同的部分进行统一,不同的部分进行保留,从而形成特定的涵盖具有相似性实体的一个模式。例如利用文献[15]中基于编辑距离的模式生成算法使得块内实体集合R:{halloword,helloworld}的对应模式为M:h{e,a}llowor{l,ε}d。
现在可以将实体间的匹配操作转换成其对应的模式之间的匹配操作。设两个模式M1=M1[1],M1[2],…,M1[x]和M2=M2[1],M2[2],…,M2[y],其中,x和y分别为M1和M2的长度,且x≥y。首先将它们进行快速扫描,算法描述如算法1所示。
算法1模式快速扫描算法PRSA。
输入:两个不同的模式M1、M2和各自的长度x、y,且x≥y;
1.初始化i和index
/*假设数组下标i从1开始,下标数组index*/
2.whilei<=ydo
3. ifM1[i]∩M2[i]≠φthen
/*两个模式对应位置元素存在交集*/
4.M12[i]←M1[i]∪M2[i]
/*将对应位置元素的并集插入合并模式M12对应位置元素中*/
5. else
6. 将i插入index中

8.i←i+1
9.fori←y+1 toxdo
10.M12[i]←M1[i]∪ε
/*将不与M2对应的元素
/与ε求并集,并插入合并模式M12对应位置元素中*/
11.returnM

2.4 模式抽取算法(PEA)

(5)

算法2模式抽取算法PEA。

输出:模式M1、M2的共同模式M12;
1.初始化i
/*假设数组下标i从1开始*/
2.ifsim(M1,M2)>=ζthen
4. fori←index.lengthto 1 do
6.endif
7.returnM12

3 实验及结果分析
实验部署的Spark集群环境由6个节点(1个主节点)构成,每个节点的内存为6 GB,Intel(R) Xeon(TM) CPU X5560@2.80 GHz,实验程序运用Scala编写。本文使用DBLP数据集和CiteSeer数据集作为实验数据。其中DBLP数据集是公用的实体统一测试数据集,且数据集中对需要被识别出的同一篇论文的不同记录作了标注,有助于对实验结果进行有效评价。CiteSeer论文数据库包含近1 400万条文献引用,包括作者、标题、出版社、日期、卷号等属性,为了方便,设置标题属性作为一个实体。实验中实体对个数达到107数量级。本文从算法的有效性和效率两方面与IterER算法进行比较,验证其在保证实体统一精度的情况下的计算量。由于DBLP拥有标准的匹配准则,因此采用准确率(Precision)、召回率(Recall)和F-值(F-measure)来评估算法的有效性。效率方面,通过算法执行的记录比较次数和运行时间来比较其性能。
图2、图3所示是本文提出的基于模式快速扫描的实体统一PRSER算法与IterER算法分别在DBLP和CiteSeer上比较的结果。可看出在不同数据集上,随着阈值的变化两个算法的有效性即准确率、召回率、F-值曲线图非常接近。PRSER算法的F-值普遍略低于IterER算法的F-值,这是由于PRSER算法在进行模式抽取的时候会引入更多不相关的实例,从而使得PRSER算法的准确率略低于IterER算法,但是在可接受范围内。从结果可以看出随着阈值越来越低,不匹配的实体就越来越容易被合并在一起,使得召回率不断升高的同时准确率不断降低,当阈值取0.3和0.4时,其召回率趋近于1,而准确率也变得非常低,使得F-值也随之降低。由此可推断出当阈值继续降低趋近于0时,F-值会越来越低,实体统一的效果也变得越来越差,不具有参考意义。在DBLP上阈值取0.5和0.6时,CiteSeer上阈值取0.6和0.7时,F-值相对最高。

图2 DBLP数据量为1 GB,有效性随阈值变化情况对比

图3 CiteSeer实体对数为1×107,有效性随阈值变化情况对比
图4、图5为PRSER算法与IterER算法分别在DBLP和CiteSeer上运行时间的比较结果,可以看出在不同数据集上,随着阈值的变化两个算法的运行时间的走势较为相似,随着阈值的降低运行时间有所下降,这是因为阈值的减小导致模式的合并操作有所增加,使得形成的实体集共同模式的总数减少,因此比较次数也会减少。但随着阈值的继续降低,每轮需要迭代合并的实体增多,迭代的轮数也有可能增加,实体集的共同模式也会变得更加繁琐,导致模式间的相似度计算变得更复杂,从而使得运行时间产生回升。当在DBLP上阈值降低到0.3和0.4时,CiteSeer上阈值降低到0.3时,运行时间下降比较明显,这是因为模式中引入了较多不相关的实例,使得实体集共同模式的总数明显减少。从图4、图5中可以看出,由于本文提出的PRSER算法在相似度计算时节省了一定的时间计算开销,所以其运行时间总体来说比IterER算法要少。
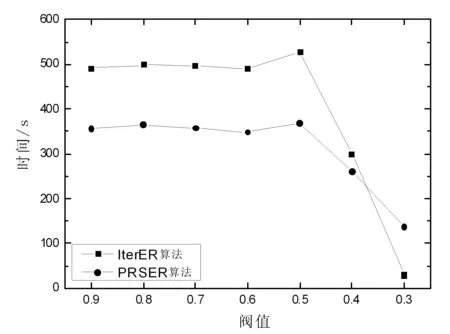
图4 DBLP数据量为1 GB,运行时间随阈值变化情况对比

图5 CiteSeer实体对数为1×107,运行时间随阈值变化情况对比
通过增加数据量,并选取各数据量下最高的F-值,得到两个算法分别在DBLP和CiteSeer上F-值和运行时间的比较,如图6、图7所示。从图6中可以看出,在不同数据集上随着数据量大小不断扩大,PRSER算法的F-值总体略微低于IterER算法,但两个算法均保持在0.9以上。图7反映了两算法随着数据量大小的增加,迭代次数也急剧增加,图7(a)运行时间呈指数级的增长,图7(b)呈线性增长,但PRSER算法的增长速度始终小于IterER算法,同时也说明PRSER算法在处理大数据的实体统一更有优势。

(a) DBLP

(b) CiteSeer图6 F-值随数据量大小变化情况对比

(a) DBLP
上述实验表明,本文提出的实体统一算法模型能够有效处理大数据下的实体统一,同时基于模式快速扫描的实体统一算法能够在尽量保证统一结果准确性的前提下,提高实体统一的效率。
4 结 语
在大数据环境下,实体统一算法对时间效率的要求越来越高。本文在一定程度上确保结果有效性的同时,重点关注如何更快速地从大数据集中得到我们需要的数据实体。因此提出了一种大数据环境下实体统一算法模型,在现有方法的基础上提高实体统一的效率。通过在Spark平台进行实验,验证了该方法在确保实体统一有效性的同时,获得了良好的时效性。在模块负载平衡策略基础上,进一步提高实体统一效率是本文的下一步工作。
猜你喜欢
活力(2021年6期)2021-08-05 07:23:54
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
艺术品鉴(2020年6期)2020-08-11 09:36:34
山东农业工程学院学报(2020年12期)2020-03-19 01:58:44
电子制作(2019年13期)2020-01-14 03:15:18
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:42
湖州师范学院学报(2016年2期)2016-08-21 13:50:52
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:19
