
课程知识本体自动构建方法研究
2018-08-15 08:02:32吕健颖尚福华曹茂俊
计算机应用与软件 2018年8期
吕健颖 尚福华 曹茂俊
(东北石油大学计算机与信息技术学院 黑龙江 大庆 163318)
0 引 言
信息化教育下课程资源的建设取得了一定的成就,产生了数量可观、门类齐全的课程教学资源。课程学习平台中资源数量巨大,缺乏有效的资源获取途径,构建有效的个性化资源推送系统具有重要意义[1]。学科知识点之间相互关联构成的知识系统是资源推荐、智能导学的基础,而现有的在线教育平台推出的知识体系描述相对粗略,缺乏教学信息的描述,知识点之间只是单一维度的上下位线性关系,缺乏知识之间多维度逻辑关系的体现[2]。课程教学资源都是按照课本教材章节顺序进行设计的,缺乏对知识的有效组织,阻碍了信息化、智能化教学的发展。本体是关于概念模型的明确的规范说明,能够对知识进行很好地组织[3]。基于本体的知识模型,在知识获取中具有重要意义。
有关本体构建方法,岳丽欣等[4]将8 种国外较为成熟的本体构建方法以及国内的领域本体构建方法进行系统总结进行介绍分析和对比总结,得出目前国内领域本体构建方法存在的主要问题是本体转换效率低,转换质量也得不到保证; 领域本体构建方法的发展趋势将逐渐转向半自动化或自动化构建。国外相关研究对50多个本体构建系统及方法进行了分析,得出大部分的本体研究主要关注领域相关的本体构建,而较少关注采用自动的方法进行通用领域本体构建;本体构建过程中概念关系获取的研究,主要集中在层次类关系的获取,对非层次类关系获取的研究较少[5]。在教育领域中,有关课程知识本体的构建,许多研究者进行了相关的研究,高丹丹[6]提出一种依据学科知识地图与知识字典进行本体构建的方法,并在领域专家的指导下,构建了“离散数学”课程知识本体。刘光蓉[7]按照“C程序设计”课程的相关教学步骤以及教学过程中的知识规律,将课程知识点中具有代表性的知识概念进行提取,形成了该课程的知识本体。邢科云[8]依据框架树的教学知识结构与知识点网的大脑认知方式,将二者相结合形成课程知识组织模型,并依据该模型构建了“计算机组成与结构”课程知识本体。由此可见,在教育领域中,有关课程知识本体的构建大部分基于具体课程教材,虽然依据一定的教学原理,但主要凭借开发者的主观经验,存在费时、费力,易受构建者主观意识限制的问题。
知识点是在进行教学活动时的基本单位,在新知识的教授与学习过程中,必须按照教学目标逐个知识点地进行[9]。基于知识点蕴含在课程教学资源中的共识,本文提出一种课程知识本体自动构建的方法,从课程教学材料中获取课程知识点及知识点间的关系,并利用本体将课程知识点及其关系进行组织,形成课程知识本体。
1 课程知识本体概述
本体是一种能在语义和知识层次上描述或表达某一领域知识的概念模型,是信息系统与人工智能领域的研究热点,并在许多领域得到广泛应用,如知识工程、自然语言理解等,特别是在信息抽取中具有重要意义。
知识是人对客观事物的认识与规律的总结[10]。知识蕴含在课程中,课程中的基本观念、相关的概念原理、基本法则以及知识间所存在的内在规律构成了课程知识的基本结构[8]。课程知识本体可以被定义为“课程中一套得到认同的、关于概念体系明确、正式的规范说明”,课程知识本体主要由课程中的有关知识以及知识间的内在关系组成,构建课程知识本体的目标是要对该课程知识进行有效组织,形成对该课程知识结构的共同理解与认识[11]。
课程的学习由许多章节教学目标构成,一个学习目标包含一个或多个知识点,同一个知识点可以由多个教学目标所共有。知识点分为教学元知识点和教学复合知识点两种基本类型,元知识点在教学上具有不可划分性,而复合知识点由两个或两个以上的知识点组成[12]。一门课程的知识由许多教学知识点构成,从课程教学资源中获取课程知识点并从中抽取知识点间的关系。最终将知识点及知识点间的关系进行本体表示,形成课程知识本体,实现课程知识的有效组织。
2 课程知识本体构建
国外目前比较流行的领域本体构建方法有:TOVE、METHONTOLOGY、骨架法、KACTUS、SENSUS、IDEF5、七步法等。国内则主要是基于需求分解的本体模型构建、基于描述逻辑的本体模型以及知识工程的方法[11]。课程知识本体作为一种教育领域的本体,其构建中的核心是知识点及知识点间关系的获取。
2.1 课程知识本体构建框架
主要包括四个部分,即“文本材料预处理”、“知识点获取”、“知识点关系抽取”、“本体知识组织”,具体如图1所示。
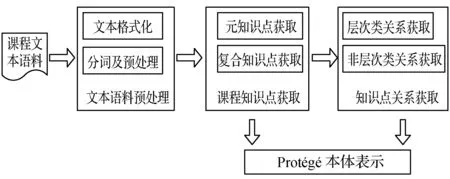
图1 课程知识本体构建框架
从图中我们可以看出一个课程知识本体构建过程包含以下步骤:
1) 课程材料文本预处理及分词:收集课程相关资源,对收集到的课程资料进行预处理,转换格式,去除停用词,并进行分词。
2) 课程知识点获取:课程知识点蕴含在课程资源文本中,通过对预处理后的文本课程资源进行分析,通过统计目标词汇在某文档以及在整个资源文档集中出现的频率判定目标词汇是否为课程知识点。复合知识点的获取则通过互信息值的大小来判断。
3) 课程知识点关系获取:包含两个部分,一是层次类知识点关系的获取,二是非层次类知识点关系的获取。
4) 本体课程知识组织:利用protégé本体构建工具构建课程知识本体。对课程知识点及知识点间的关系进行组织。
2.2 课程材料选取及语料预处理
收集课程有关教学资源,包括有关教材目录、教学课件、课程教学大纲等,将收集到的课程教学资源汇入csv格式的语料库中并进行预处理,去除课程资源中的无用信息,进而将课程资源处理为txt文本格式,为下一步的分词做准备。
分词系统中,分词结果的优化方向主要是对未登录词以及新词的识别[13]。本文利用R语言环境下的Rwordseg分词工具进行分词,Rwordseg引用Java分词工具Ansj。Ansj是李舰于中科院的ICTCLAS中文分词算法所撰写出的开源Java分词工具。利用Rwordseg自带词典进行分词,存在无法识别专业领域新词以及专业术语的问题,通过自定义词典的方式将专业新词和专业术语加入分词词典,重新进行分词,以提高分词的准确性。图2为语料预处理过程。
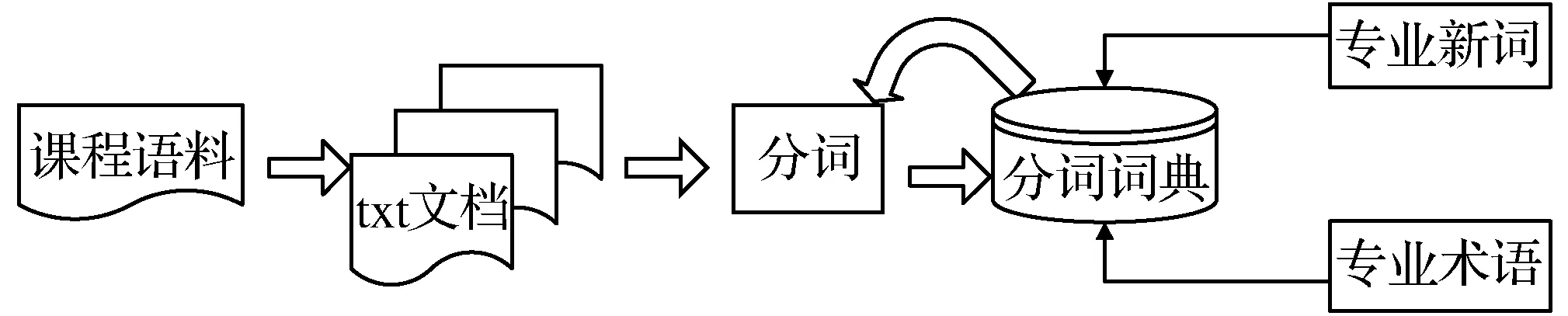
图2 语料预处理
R语言中加入自定义的词典,语句如下:
>installDict(“new.txt”,dictname=“new”,dicttype=“text”,load=TRUE)
本文对收集到的“C语言程序设计”课程的相关语料进行分词及词性标注,处理的部分结果如图3所示。

图3 分词及词性标注
其中,m:数词;v:动词;n:名词 ;vn:名动词;en:英文; c:连词; p:介词。
2.3 课程知识点获取
本体术语抽取方法主要有两种:基于规则的方法和基于统计的方法,前者是一种确定性的信息抽取模型,而在目前语言学理论水平和计算技术条件下,无法使用确定的规则描述所有的自然语言现象,因此,概率统计模型适合大规模语料信息的抽取[14]。
向量空间模型VSM(Vector Space Model)是最流行的文本表示模型,VSM将一篇文档表示为特征空间中的一个向量,向量中每一维对应于文档中的一个词,它的权值为该向量维对应的特征在文档集中的权值。假定特征t在文档k中的词频为ftk,权值为dtk,N表示文档集中的文档数,nt表示特征t在整个文档集中的出现频率。常见的权值计算方法包括:布尔权值法、词频权值法以及TF-IDF权值法等。其中TF-IDF(Term Frequency Inverted Document Frequency)权值法由Salton 和Buckley提出,作为词语领域相关性的评价标准,己经被公认为是一种标准的文本向量表示方法[15]。本文通过统计分析分词后得到的词汇频率,利用TF-IDF权值法获取课程语料中蕴含的知识点。
2.3.1TF-IDF权值法:获取课程知识点
TF表示分词后获取的某个目标词汇在某课程资源文档中的出现频率;IDF表示该词汇在整个课程资源文档集中的出现频率。
根据TF-IDF的定义与公式表示可知:目标词汇t在给定的某课程文档k中出现的频率越高,dtk值越大;而该目标词汇在整个课程资源文档集中出现的频率越高,dtk值越小。dtk值越大,该目标词汇成为课程知识点的概率也越大。
2.3.2 互信息:获取复合知识点
基于TF-IDF的文本向量表示在构造时假设目标词汇之间相互独立,使词汇之间的关系丢失,互信息MI(Mutual Information)用于衡量两个概念间的相互依赖程度,能有效地弥补VSM模型的不足。而在课程知识中,有很大一部分知识点是复合知识点,利用自然语言处理中的互信息得出知识点间结合的紧密程度,通过互信息值的大小判断复合知识点。假设有复合知识点AB,那么知识点A和B之间的互信息可以表示为:
p(A,B)表示知识点A与知识点B组合作为复合知识点AB在文档中出现的概率,p(A)表示知识点A在文档中出现的概率,p(B)表示知识点B在文档中出现的概率。
互信息值MI(A,B)用于定量估计知识点A与知识点B之间成为复合知识点的概率。互信息越大,知识点A与知识点B之间结合的紧密程度越高,两个知识点成为复合知识点的概率越大;互信息越小,结合的紧密程度越低,两个知识点成为复合知识点的概率越小。
2.4 课程知识点间关系获取
课程知识点间关系可分为两大类:层次类关系与非层次类关系。层次类关系实际上是一种上下位的关系,即课程知识点关系中父知识点与子知识点间的关系。
本文采用聚类的方法获取知识点间层次类的关系,非层次类的关系则通过知识点同时出现概率从而进行关联分析获得。
2.4.1 层次类关系获取
一门具体的课程中,父知识点是子知识点的概述,如,“数组”是“字符数组”的父知识点,它们之间按课程知识点划分为父子关系,具有层次关系的特征。
本文采用聚类分析的方法获取课程知识点间的层次关系,聚类分析是将相似的数据分为同一集群,使集群与集群之间有显著的差异性。在进行层次聚类前需要计算类间的距离,基于知识点获取中所构建的VSM模型,将文档集作为概念的向量,从而构建“概念-文档”矩阵,计算概念词矩阵向量之间的相似度。本文利用余弦系数获取向量间的相似度,余弦系数公式如下:
式中:x=(x1,x2,…,xp),y=(y1,y2,…,yp)为两个p维度变量。
在获取类间距离后,本文采用自下而上的方法进行层次聚类,在未对对象做聚类之前,将每个对象当作单独的一个集群,然后根据集群之间距离大小去合并相近的集群,一直到所有的集群合为一个集群。集群间距离计算公式有三种方法:最短距离,最长距离以及平均连接。
(1) 最短距离(单一连接,single linkage):A和B两群距离为A群内每个元素到B群内每个元素的距离的最小值。
(2) 最长距离(完全连接,complete linkage):A和B两群距离为A群内每个元素到B群内每个元素的距离的最大值。
(3) 平均连接(average linkage):A和B两群距离为A群内每个元素到B群内每个元素的距离的平均值。
从以上定义中可以看出,平均连接法考虑到集群内所有元素,不易受单个元素影响。本文利用平均连接法进行层次聚类,图4是部分知识点的聚类树状图。

图4 聚类树状图
2.4.2 非层次类关系获取
利用关联分析获取课程知识本体,其基本思想是如果两个概念经常出现在同一个句子、同一段落或者整个文档中,则这两个概念之间必定存在着某种联系,而它们之间联系的紧密程度取决于所在的语法单元包括句子、段落、甚至整个文档的内在聚合度,聚合度越紧,则两个概念之间的紧密程度越高[16]。同理,从课程知识处理文档中,分析课程知识点间的联系,若两个课程知识点存在于同一文档中,则这两个课程知识点存在关系,按知识点间关系划分,若两个课程知识点间存在一定关联,且这两个课程知识点具有同一个父知识点,则这两个课程知识点间的关系为兄弟关系;若两个课程知识点虽然存在关联,但拥有不同的父知识点,则这两个课程知识点间的关系为依赖关系。
在进行关联分析时,首先要判断与某个知识点具有相关性的知识点,利用R语言tm包中findAssocs进行相关度判断。核心语句如下:
〉findAssocs(d.dtm, “数组”,0.7)
如图5所示,对“数组”进行相关度分析,得出与其相关度大于0.7的知识点。

图5 相关度分析
在对课程知识点进行关联分析时,必须通过判断知识点间的支持度与可信度以确定它们之间的关系。
(1) 支持度(Support):若存在两个课程知识点,课程知识点A与课程知识点B,若在课程资源文档集中有S%的文档中,同时存在课程知识点A与课程知识点B,则S%称为课程知识A→B点的支持度,即支持度表示课程知识点A伴随知识点B在课程资源文档集中出现的概率,即Suppor(A→B)=P(A∪B)。那么对于支持度有Support(A→B)=P(CAB/T)×100%,如果课程资源文档集的总数为T,CAB代表两个知识点A和B在课程资源文档集中的数量。
(2) 可信度(Confidence):CA代表课程知识点A在课程文档集合中的出现频次;CB代表课程知识点B在课程文档集合中的出现频次。在所有包括有课程知识点A的文献中,同时C%的文档中包含有课程知识点B。则C%称为课程知识点A→B的可信度。可信度表示在包含课程知识点A的课程资源文档中,课程知识点B也同时包含在该课程资源文档中的概率,即在知识点A出现的前提下,知识点B出现的概率P(B|A)。则关于课程知识点关系关联分析中可信度的表示为:
Confidence(A→B)=(CAB/CA)×100%
通过关联规则构建课程知识点间的非分类关系时,只能获得具有关联关系的知识点,无法得出具体的关系。根据语言学可以知道,动词是句子的核心,具有相关关系的课程知识点间的动词,可以判断知识点间的语义关系。因此,通过统计文本中具有关联关系的知识点间的动词,从而获取课程知识点间的非分类关系。
2.5 课程知识本体表示
本体必须用预先定义的语言来描述。目前本体描述语言可分为三类:基于逻辑的(first-order logic)、基于框架的(frame logic)和基于Web的(RDF,XML,HTML)。主要的本体描述语言有:DAML+OIL、OWL、KIF、CYCL、Loom、CML等[17]。其中,OWL的使用最为广泛,并成为W3C官方推荐标准。
斯坦福大学开发的 Protégé本体构建工具支持多种本体表示语言,包括OWL。Protégé中类、关联、关联约束和推理机制四个要素提供了有关本体概念、类、属性的构建。本文以“C语言程序设计课程”为例,收集该课程相关资源,利用本文所述方法从中获取该课程的知识点及知识点间的关系,进而用Protégé本体构建工具将获取的课程知识点及知识点间的关系进行本体表示,如图6所示为该课程部分知识点的本体表示。

图6 课程知识本体表示
3 结 语
课程知识本体作为一种重要的课程知识组织技术,在智能学习系统应用中具有重要意义。人工构建课程知识本体需要借助领域专家,因而受专家的影响较大。
本文利用文本分析相关技术从课程语料中获取课程知识本体。首先对收集到的课程资源进行预处理,从中获取课程的知识点,进而利用关联聚类等方法分析知识点间的层次类关系以及非层次类关系,最后利用Protégé本体构建工具对课程知识点及知识点间的关系进行组织。
课程知识本体的构建的应用是知识的推理与知识的有效推送,如何将本体的构建与知识的推理有效结合,以及在智能教学系统中将知识精准地推送给学生,需要进一步探索。
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
中国新闻周刊(2021年26期)2021-07-27 04:02:12
中国音乐学(2020年4期)2020-12-25 02:58:06
智富时代(2019年6期)2019-07-24 10:33:16
信息安全研究(2016年4期)2016-12-01 06:06:54
高中生·天天向上(2016年9期)2016-11-22 09:10:34
文学教育(2016年27期)2016-02-28 02:35:15
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
卷宗(2013年6期)2013-10-21 21:07:52
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
