
基于改进数据挖掘Apriori算法的软件风险管理分析
2018-08-08 10:33梁祥波夏子厚
信阳师范学院学报(自然科学版) 2018年2期
梁祥波 , 夏子厚
(1.信阳师范学院 数学与统计学院,河南 信阳464000;2.信阳职业技术学院 数学与计算机科学学院,河南 信阳464000)
0 引言
软件开发生命周期有许多阶段,例如软件需求收集与分析、软件设计、软件编写、调度、存储与维护等.软件风险在软件开发的不同阶段都会出现[1].降低软件风险的策略就是分析风险和缓解因素之间的联系,对风险因素进行有效管理,降低软件风险发生的概率[2].
有研究说明数据挖掘和人工智能技术可以解决软件风险这类问题.ASIF利用被称为规则库系统的人工智能技术[3]建立了一个规则库作为决策支持系统,该规则库是以软件风险因素及其缓解的相互关系形成的.因此,将人工智能和数据挖掘技术结合起来,应用到软件工程的风险分析中[4],是降低软件风险的有效方法.
文献[5]中将数据挖掘关联规则Apriori算法应用到软件工程,分析软件风险因素和软件风险缓解因素之间的联系.但是,传统的数据挖掘关联规则Apriori算法导致生成大量的候选项集和长子集,因此,影响软件工程中风险与缓解因素关系分析结果.本文通过结合粗糙集理论(RST),提出了基于属性相关的关联规则挖掘算法来处理风险中的数据.
本文研究主要有以下三个步骤:
1. 提出一种改进的数据挖掘关联规则Apriori算法;
2. 运用改进的数据挖掘Apriori算法来追踪软件风险因素和软件风险缓解之间的关联规则[6];
3. 提出新的适应性数据结构.
1 数据挖掘特征相关关联规则Apriori算法(ARApriori)
1.1 特征相关关联规则
关联规则(ARM)挖掘目的旨在检测事务数据库中的元组和服务器决策的关系.本质上,采用关联规则挖掘来找到满足最小支持度和最小置信度阈值的数据集.经典关联规则数据挖掘过程如图1.
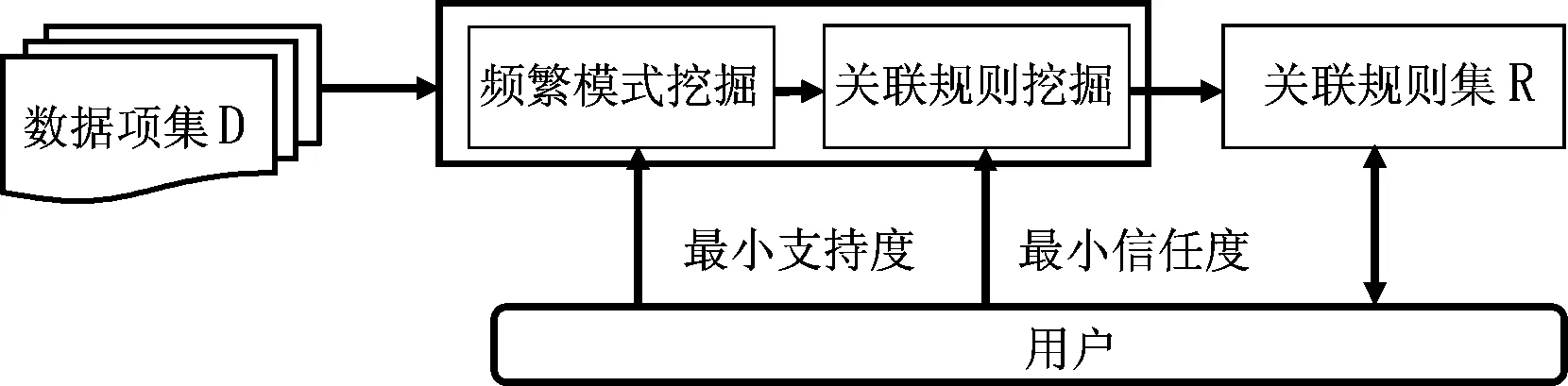
图1 ARM过程Fig. 1 ARM process
与传统的关联规则挖掘方法相比,特征相关关联规则对关联规则增加了属性约束.具有特征相关信息的事务可以记为T{TIDT1T2…TnCmaxCmin},|Cmax|和|Cmin|分别表示特征相关项集模的最大值和最小值.根据关联规则“满足最小支持度阈值和最小置信度阈值”的定义,我们可以给出特征相关关联规则的定义.
定义1 设min_sup和min_conf分别表示最小支持阈值和最小置信度阈值,当且仅当在条件Cmax>Cmin,支持度C≥min_sup并且支持度C≥min_conf规则下,P⟹R是一个特征相关关联规则,记为P⟹R={T_sup,T_conf,Cmin,Cmax}.

conf(P⟹R)[Cmin,Cmax]=
(1)
1.2 数据挖掘特征相关关联规则Apriori算法(ARApriori)
在数据预处理阶段,首先对特征相关的数据进行组合,组成特性相关的集合I.然后,在特征相关关联规则生成的过程中,采用频繁树增长模式来获得最小支持度阈值.具体算法描述如下:
输入:特征相关项集I,特征约束[Cmin,Cmax];
输出:特征相关关联规则集R;
步骤1 根据初始项集Ti中的每个元素组成特征相关项集I并构造支持度计数Vc的矩阵;

步骤3 始化节点null()作为模式树的根节点,将Ii按降序插入到频繁树(PT)中,获得在根部在k,所有长度作为频繁模式的树Fk;
步骤4 通过执行Lk=Fk-1ΛFk-1来获取所有长度的候选项集;
步骤5 执行步骤2迭代地找到所有候选项集;
步骤6 当特征约束[Cmin,Cmax]在Fk满足约束Cmax>Cmin,C≥Cmin和C≤Cmax时,将频繁模式Fk添加到特征相关项集;否则,删除频繁模式Fk;
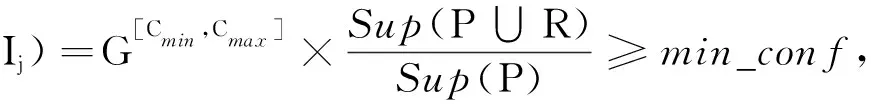
ARApriori数据挖掘算法能有效地找出特征相关的项集,降低对初始项集的依赖程度,提高数据挖掘的精度.
2 数据挖掘ARApriori算法追踪
本节把软件风险因素和风险缓解因素抽象为初始项集,然后用ARApriori数据挖掘算法对这两类因素进行分析.
在软件开发过程中,找出软件风险因素和软件风险缓解因素之间的潜在联系,以此作为软件开发的依据,能够提高软件开发的成功率.因此,利用ARApriori数据挖掘算法,找出这两种因素的关联,为设计软件工程新型适应新结构提供了支撑.表1是这两种因素的条件.
表1列举了软件开发过程中的风险因素和风险缓解因素,具体解释如下:
软件风险缓解因素为:一贯承诺(M50),影响评估(M49),项目追踪控制(M48),可重用性(M47),问题解答(M46),应急计划(M45),评估过去的通信(M44),定期更新(M43),压力测试(M42),设置关键绩效指标 (M41),安全检查表和认证过程(M40),积极的行为和解决问题的技巧(M39),直觉和创造性(M38),中心化(M37),便利的应用规约技术(M36), 管理高层承诺 (M35),次等的要求(M34),政策环境和执行(M33),成功标准的鉴定(M32),恰当的销售营销团队(M31),恰当的测试技术 (M30),人力资源角色(M29),在彻底的研究可用的工具和技术之后对技术的选择(M28),运用统计方法(M27), 用户参与(M26), 原型法(M25),项目进度安排 (M24),连续检查(M23),雇员意识(M22),雇员技能(M21), 雇员态度(M20),尊重雇员 (M19),在职培训和脱产培训(M18), 工作单元文化(M17), 适当运用方法论和软件模式(M16), 过去的经验(M15),领导力(M14), 确保通信和里程碑(M13), 定义目标(M12), 适当的备份计划(M11), 适当的团队结构(M10), 开发者的忠实度(M9), 吸引人的包装 (M8), 奖金(M7), 留住好员工(M6), 恰当的沟通渠道(M5), IT顾问(M4), 需求规格说明(M3), 恰当的可行性报告制作(M2), 清晰的诉求(M1).
软件风险因素为:项目的大小(SOTP), 不当的营销技巧(IMT), 过时的市场需求(MDO),不当的可行性报告(IF), 高级管理决策(HMD), 了解顾客的问题(UPOC), 了解开发者的问题(UPOD),不当计划(IP), 不当范围定义(ISD), 缺乏项目经理的经验(LOEPM) , 实施(IMP),政府因素 (GF), 文化多样性(CDR), 缺乏动机(LOM), 不切实际的期限(UD), 人员聘用(PH), 不当设计(ID) , 不当预算(IB),不当技术(IT), 缺乏资源(LOR).
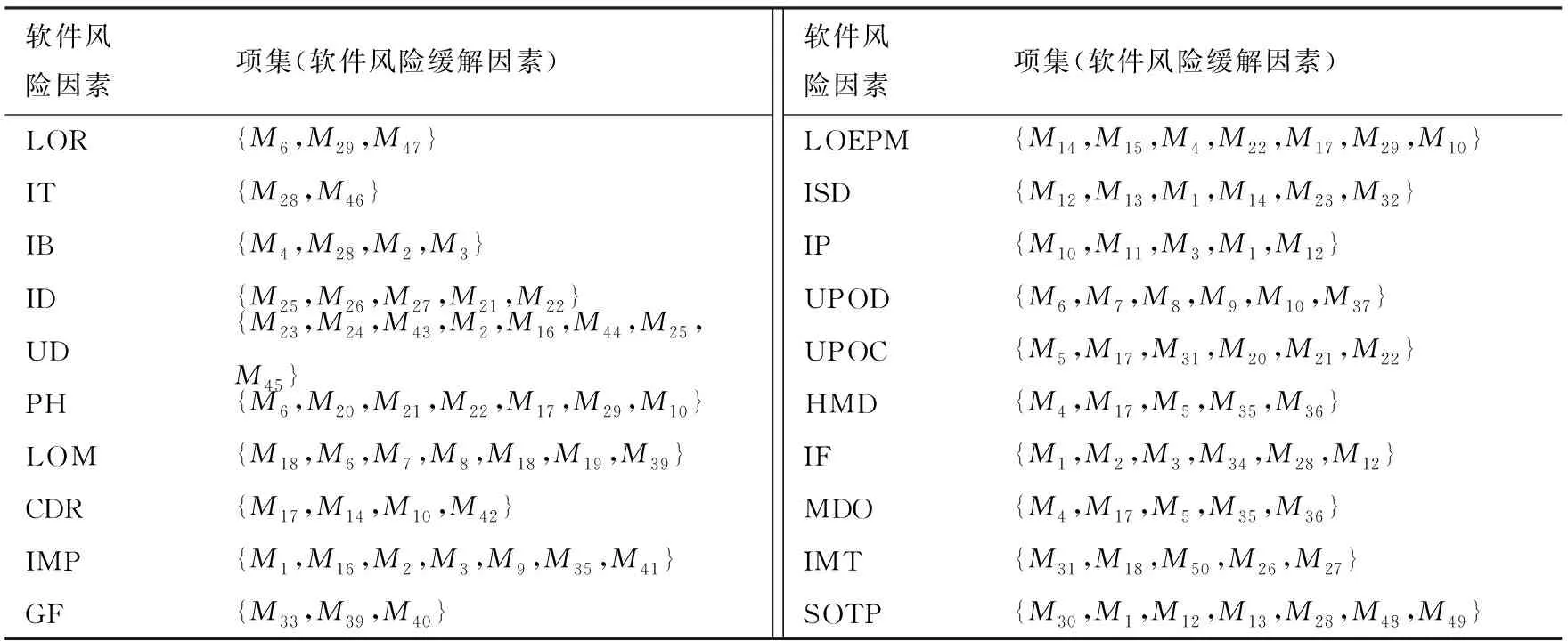
表1 主要数据集Tab. 1 The main data set
根据ARApriori数据挖掘算法,软件风险因素和风险缓解因素挖掘步骤如下:
第一步计算最小支持度,对候选项集和频繁项集进行优化.
我们设置数据挖掘ARApriori算法有15%的最小支持度,通过在ARApriori算法的应用方程,我们得到结果0.3.因此,只有大于或者等于0.3的项集会在频繁项集中被选中,即在表1的第一部分中那些频繁集大于或者等于0.3的发生概率.
第二步最小置信度下产生的规则
我们设置最小置信度的值为60%,根据式(1),求出ARApriori挖掘算法的置信度.
第三步执行ARApriori算法
通过ARApriori挖掘算法,得到特征相关项集R.
3 分析ARApriori算法数据挖掘结果
本节对ARApriori挖掘软件开发中的两个风险因素结果进行分析.
1)通过执行ARApriori挖掘算法,数据库已经被扫描了三次.第一次扫描得出了每一个候选项的概率次数(50个候选项),即在最小支持率15%的基础上从M1到M50.第二次扫描有91对候选项,即{M1M10}、{M1M2}等,第三次产生了两个候选集,它们是{M1M3M12}、{M1M2M3}.
2)ARApriori挖掘算法共产生了143个候选项,并能够产生一个频繁模式树(FP-Tree),如图2所示.
3)图2中所有的项集都按照降序排列,这样可以尽可能地节省存储空间.
4)ARApriori挖掘算法是基于“自下而上/横向优先搜索”的方法,产生候选项集.
5) Apriori挖掘算法并不是记忆有效的算法,因为它很难存储大量的候选项集,不适于处理大规模数据.但是ARApriori挖掘算法是特征相关的,因此,产生的候选项集相对较小,具有处理大规模数据的能力.
6)关联规则的产生与ARApriori算法的支持度和置信度有关.根据第二节的支持度和置信度的产生策略,总共有8条规则产生并选中:规则1、M1→M3(60%),规则2、M3→M1(75%),规则3、M1→M12(60%),规则4、M12→M1(75%),规则5、M2→M3(75%),规则6、M3→M2(75%),规则7、M21→M22(100%),规则8、M22→M21(100%).通过对比Apriori挖掘算法,产生了相同的关联规则.
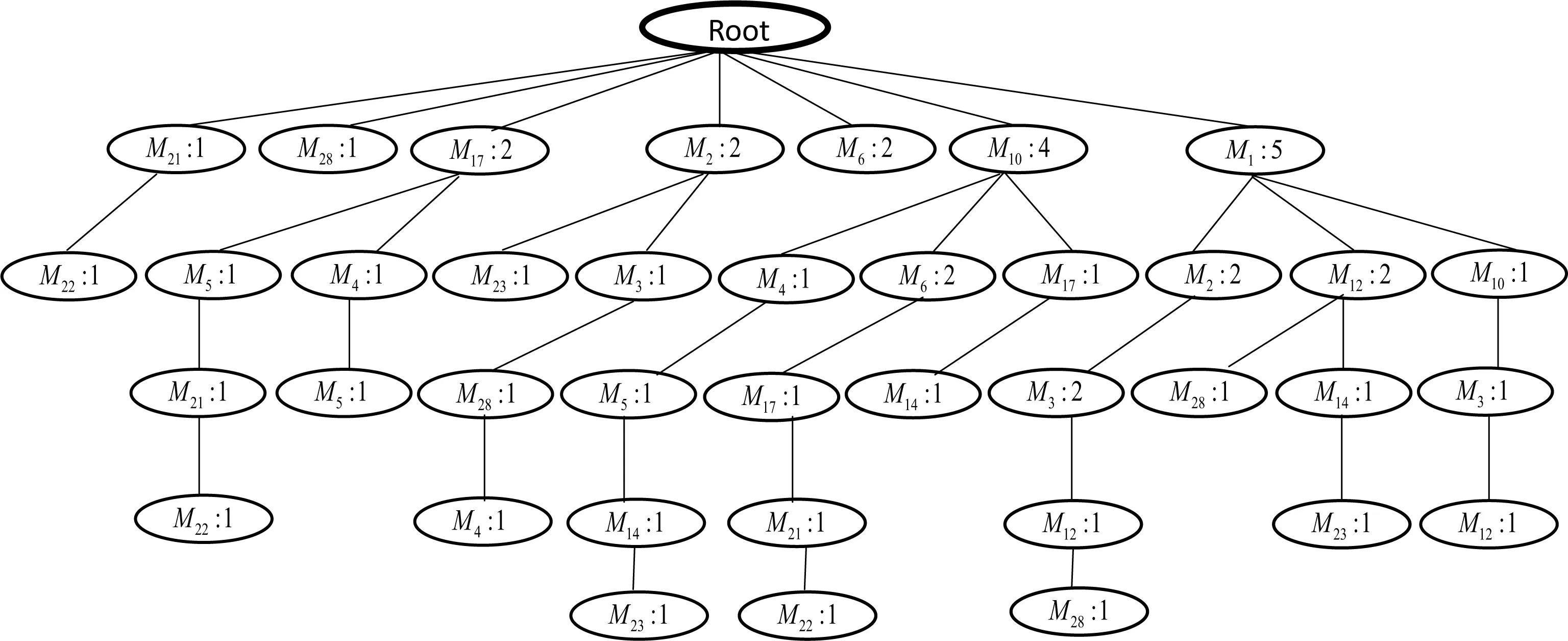
图2 软件风险缓解FP-TreeFig. 2 Software Risk Mitigation FP-Tree
根据挖掘结果,M22→M21(100%),雇员意识(M22)决定雇员技能(M21)的水平,即只要增强软件开发成员的主动意识,就能够不断提高该成员在软件开发中的技术水平.其他规则也显示了软件开发中风险缓解因素的联系,在一定程度上为软件开发的成功提供了有效参考.
4 一种新的适应性结构
软件风险因素对于软件开发成功率的影响是很大的,通过ARApriori挖掘的关联规则,我们提出了一种新的软件工程适应性数据结构,降低风险因素对软件工程的影响.
这种适应性结构的主体思想是综合运用Apriori和ARApriori挖掘算法.数据挖掘Apriori算法对小型数据集的处理有比较好的效果,容易产生最小数目候选项集.而ARApriori挖掘算法则更适用于数据规模很大的数据集.这种新的适应性结构会让软件工程中的数据处理变得更为简单,每次事务处理都可以设定一个最低值和最高值.如果事务处理的数据规模超过了最高值,ARApriori挖掘算法就会被使用.如果事务处理低于最低值,Apriori算法则会被使用.图3为软件项目管理者提供的决策使用的新型结构.
5 实验结果及分析
5.1 实验设置与结果
通过实验验证Apriori 算法的性能,把软件风险因素和软件风险缓解因素抽象为初始项集,应用新型适应性结构[7].该数据集可用于检验频繁项集算法的效率,而且由于其项集特征相关较大,对分析软件风险因素和软件风险缓解因素有着重要作用.
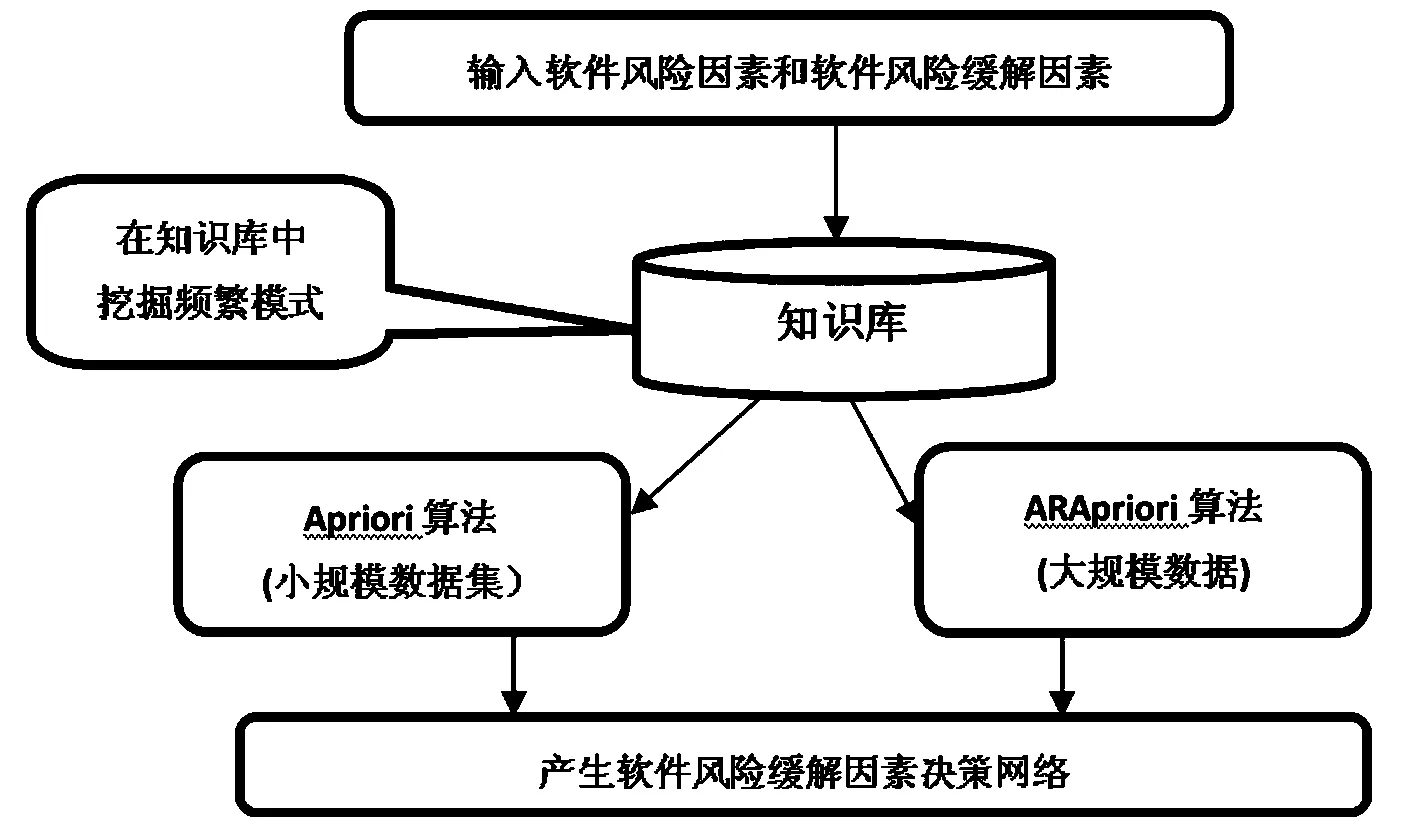
图3 一个新型的适应性结构Fig. 3 A new type of adaptive structure
实验环境为: CPU 为 Intel Pentium T4200、2 GB 内存、Windows7 操作系统.采用 Weka 软件作为实验工具,Apriori 算法由Weka 软件提供,由 Java 编写并由 Weka 调用运行.实验方法为采用相同的数据集,在相同的实验环境下用不同置信度阈值和不同的支持度阈值对Apriori算法的运行效率进行测试.实验结果如图4所示.
5.2 实验结果分析
从实验结果中能够发现,随着最小支持度与最小置信度的增加,Apriori算法的运算时间不断增加.而且,当最小支持度与最小置信度分别为50%以上时,Apriori算法的运算时间急剧增加.这种现象的原因是Apriori算法对于特征相关的数据具有较强的处理能力,当最小支持度与最小置信度设置在50%以下时,不会影响算法的挖掘结果.
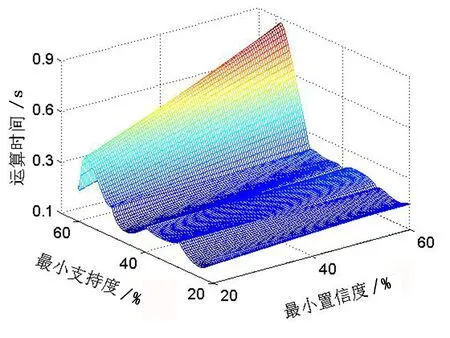
图4 实验结果Fig. 4 Experimental results
因此,设置最小支持度和最小置信度在50%以下时,实验能够挖掘出和Apriori算法分析同样的结果,证明了Apriori 算法对于特征相关的数据在软件风险管理分析中的有效性.在软件开发过程中,找出软件风险因素和软件风险缓解因素之间的潜在联系,以此作为软件开发的依据,能够提高软件开发的成功率,为设计软件工程提供了新的思路.
6 结论
根据改进的Apriori挖掘算法能够准确分析软件开发风险因素和软件风险缓解因素之间的联系,并提出了一种新型的软件工程适应性结构,为项目经理在软件开发实施过程中提供了决策依据.因此,把数据挖掘技术添加到智能系统中,为决策过程的研究提供了新的研究方向,并为包含关联知识库的发展提供了更为简单、系统的方法.
猜你喜欢
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
机电产品开发与创新(2020年2期)2020-05-07
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
信息通信技术(2015年6期)2015-12-26
智能系统学报(2013年1期)2013-01-28
