
北大荒米业竞争对手产品评论数据挖掘
2018-08-01 11:11李世鑫杜禹墨
北方经贸 2018年8期
安 翔,李世鑫 ,白 雪 ,杜禹墨
(哈尔滨商业大学a.基础科学学院;b.经济学院,哈尔滨150028)
一、研究的背景与意义
随着电子商务的快速发展,使得网络购物成为人们选购商品的重要途径之一京东、淘宝、天猫等电商平台崛起,使得互联网上集中出现大量的商品评论信息。与线下实体店购物不同,网络购物时人们会更关注网络上的商品评价信息。这些信息包含了已购买者对商品各方面的主观评价,对商品的褒贬评价在很大程度上影响着人们的购买决策。
北大荒米业智淘电子商务有限公司为黑龙江省北大荒米业集团有限公司下属子公司,业务范围涉及京东、淘宝、天猫超市、苏宁、一号店等国内主流电子商务平台,以及跨境电商等业务。该公司分析了2017年销售收入增长较慢的主要原因,并提出相应对策:“指定主要竞争对手:中粮和十月稻田,针对其主打产品,调整产品包装和品类,抢占市场份额,调整产品结构。”
本项目针对以上对策,从相应电商平台爬取上述竞争对手产品的评论数据,进行文本挖掘,为北大荒米业提供决策依据。
二、网络爬虫
(一)传统网络爬虫
网络爬虫又称作网络蜘蛛或者网页追逐者等,其主要负责网络上的数据的收集工作。网络爬虫为人们批量获取互联网信息提供了可能性。
在本文中,网络爬虫的任务是从天猫超市和京东商城网页中把海量的消费者文本评论数据提取下来,为本文的情感分析提供最原始的分析数据。而传统的爬虫方式存在后期处理任务冗余、目的性不强、资源浪费等缺点。因此,笔者引入了现代网络爬虫方式。
(二)现代网络爬虫
现代网络爬虫技术大多可以自动生成爬虫,节省时间。但就操作性而言,集搜客爬虫网站专注于网页数据采集,它能比较方便地爬取网页数据,它是先通过MS谋数台是用来制作网页抓取规则,包括模拟点击、翻页规则、抓取内容等,再利用DS打数机根据建立的规则采集网页数据。所以集搜客属于“易用型”,它主要通过模仿用户的网页操作进行数据采集,只需要指定数据采集逻辑和可视化选择采集的数据,即可完成采集规则的制定。
三、评论文本的采集与预处理
(一)数据的采集
1.数据来源
参考2017年电商平台大米销量的综合排名,以北大荒米业主要竞争对手为主,选择出了三种具有代表性的大米产品,它们分别是:中粮出品的苏软香、十月稻田出品的长粒香以及稻花香。本项目分别在天猫超市和京东商城中抓取了以上三种大米产品的消费者文本评论,每种大米产品的约在五千条评论,以此作为研究对象。
2.使用工具
一是集搜客。GooSeeker是一个集Web网页抓取、数据抽取、提取页面信息等功能于一体的工具包,主要由 MetaStudio、DataScraper、MetaCamp、DataStore构成。该工具能依照操作人的意愿,从网页页面上筛选出所需信息,并输出含有语义结构的提取结果文件。鉴于集搜客目前的功能较为稳定,使用面较广,而且操作上较为简易。因此,本项目选用的抓取工具是集搜客。
二是R语言。在数据挖掘分析中,本项目选择使用R语言实现。相比于其他专业统计分析软件,R语言使用免费且不失专业性。可以大幅度降低成本、提高数据分析效率。
(二)数据的预处理
得到产品评论数据之后,由于大多评论数据是用户的口语化表达,不乏错别字以及冗余的信息存在。因此,需要对抓取的数据进行预处理。本项目根据实际需求和查阅相关文献,得到以下数据预处理的具体方法。数据预处理模块主要由两个部分组成:对评论数据进行文本去重和压缩去词。
1.文本去重
先对测试数据集进行数据去重与清洗,去重是指去除数据中重复或广告等恶意评论;清洗是为了清除数据中基于特定模板的垃圾信息,从而得到较为纯净的无歧义的评论集。文本去重的方法有很多,包括编辑距离去重、Simhash算法去重等,但是大多都存在一些缺陷,经过研究对比后,本文采用比较删除法这种相对简单的文本去重思路。文本去重过程主要针对以下三类评论。
一是电商系统自动评论。一些电商平台往往会在客户长时间不进行评论时,会有系统自动替客户做出评论,这种评论没有任何意义并且完全相同,所以有必要对这些数据进行去重处理。
二是同一个人可能会出现重复的评论。可能会出现相同的顾客购买多种大米,然后在进行评论的过程在多个大米中采用同样或相近的评论。
三是存在无意义数据。除了上述恶意重复的数据外,一些其他无意义的数据也要进行删除。如广告链接和标签等,广告通常都是一条网址链接形式,可能存在符号、文字等无意义的信息。标签中含有的无法匹配的情感词也会对后续数据分析工作产生影响。
2.压缩去词
压缩去词主要针对含有冗余的信息、语法错误及成分残缺的句子进行人工的滤除和修正。为了更好的提高数据的准确性,本文有必要对评论句子进行压缩去词。例如,评论:“好吃好吃好吃好吃好吃好吃好吃”经过压缩去词处理,就变成:“好吃”。
四、评论的特征分析与主题词提取
(一)基于词云的可视化分析
为了探索上述三种不同大米的评论文本集包含的信息,进而挖掘出这三种不同大米的特征,从中更好地提炼出大米的卖点,本文基于R语言统计高频词并且制作词云,通过可视化技术进行分析,将评论文本数据转换成直观的、可交互的展现形式,以利于更好的发现数据中隐藏的特征、关系和模式。本文将每种品牌大米预处理得到的评论看做一个整体,作为初始文本数据,利用R语言进行编程设计,得到结果如下表。

表1 对稻花香评论的词频统计结果(前30个特征词)
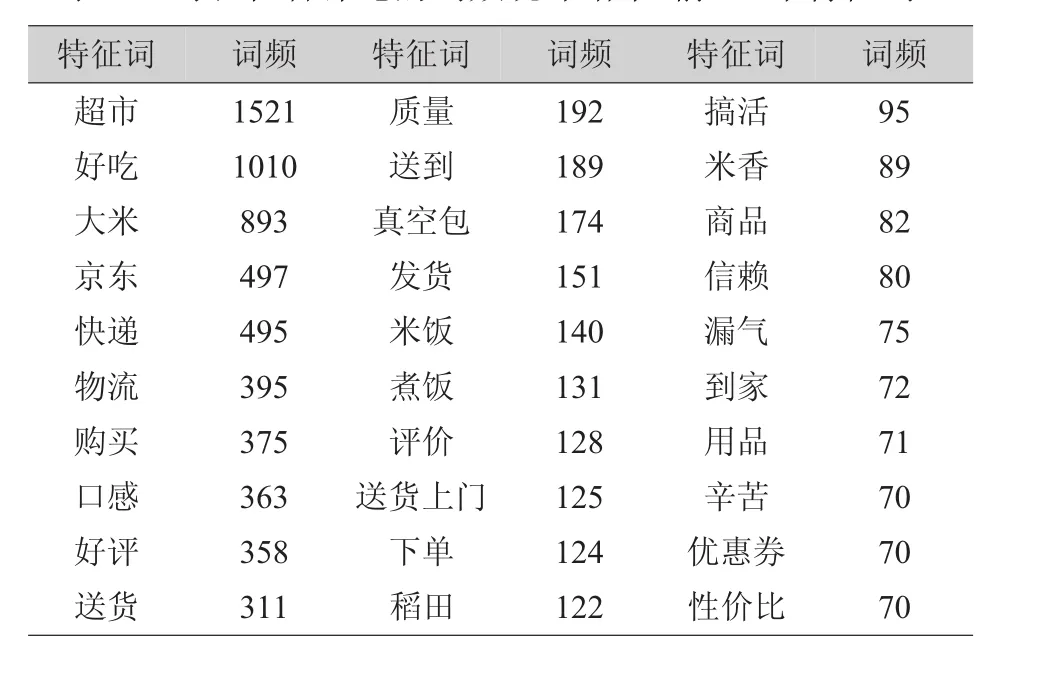
表2 对长粒香评论的词频统计结果(前30个特征词)
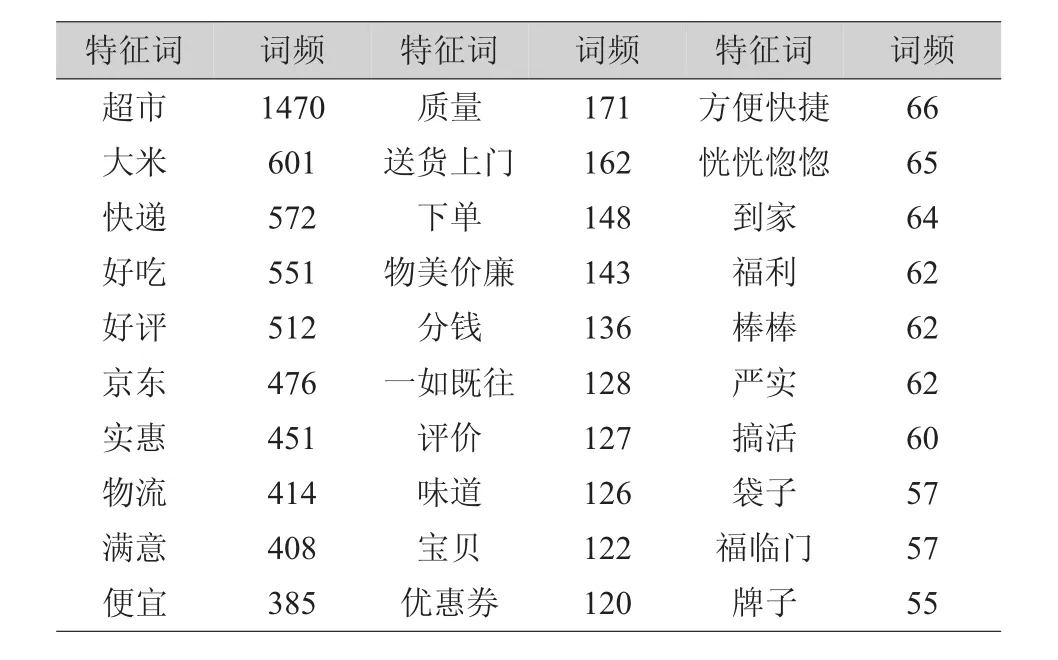
表3 对苏软香评论的词频统计结果(前30个特征词)
至此,已经由R语言分词,去除无用词后,统计词频得到了三种品牌大米的特征词,可以看到,提取的特征词包括了大米的各个方面,因为本文中评论都来自于电商平台,自然地“物流”一次成为最主要的关注点,但值得注意的是,这并不属于大米的特征词;除此之外,味道、质量、包装、优惠活动都是消费者较为关注的特征。但是这些特征词一共有几百多个不同的词语,十分分散,无法直接利用这些分散的特征词作为评价大米的指标。为了明确在所有的评论中消费者具体关注了大米的哪些方面的问题,本文接下来考虑采用LDA主题模型,提取大米电商评论中的共同主题,通过评论中包含的共同主题反映消费者的关注点,并以此作为下文情感倾向标注的指标体系。
(二)基于LDA模型提取主题词
如果一篇文档有多个主题,则一些特定的可代表不同主题的词语会反复出现,此时,运用主题模型,能够发现文本中使用词语的规律,并且把规律相似的文本联系到一起,以寻求非结构化的文本集中的有用信息。例如,对于大米的商品评论,代表大米特征的词语如“口感”、“包装”、“质量”等会频繁地出现在评论中,运用主题模型,将与大米代表性特征相关的情感描述性词语,同相应的特征词语联系起来,从而深入了解大米评价的聚焦点即生成相应的主题词。LDA模型作为其中一种主题模型,属于无监督的生成式主题概率模型。
本文使用LDA模型的目的在于,从网络评论中发现消费者主要关注的大米属性,并找出属性包含的大米特征词,以便将分散的大米特征词归并为少数几个大米属性之中,即主题词。
本文实现LDA模型采用的是R语言中lda程序包。类似K-Mean方法,LDA模型也要预先设定提取的主题个数。由于三种不同品牌的大米特点各不相同,销售方式也略有差别,消费者对于不同品牌的大米评论可能存在较大差异,因此本文查阅相关资料,经过多次试验对比,将提取的主题个数设置为5个的提取效果最佳,这样提取主题词,更有利于后期情感倾向标注。利用R语言进行编程设计,得到的主题词如下表。

表4 所有消费者评论的前五个主题结果
物流——指消费者通过电商平台购买某种大米之后,对于发货速度以及到货所需时间的满意程度,虽然该词不属于大米的特征,但由于网购的自身特点,该词也是影响评论情感倾向的一个重要因素。该主题词涉及的评论如:“物流快,非常好!”“物流快。购物方便。”
口感——指消费者食用了该大米之后,作出的相关评价。相当于是实际使用之后,再进行的一种评论,所以参考价值较高。并且,该词本身也是食品类商品的重要特征词,自然地,该词出现的频率也较高。该主题词涉及的评论如下:“半年多以来,一直买这种大米,家人都说好吃,口感好,又是2017年的新米,好评!”“经常吃这大米,很香,熬粥粘稠,特好吃。”
品质——指大米产品的综合指标,包括大米是否新鲜、包装是否完好等,一系列大米产品的特征。该主题词涉及的评论如下:“喜欢,质量好,包装好,一直很满意。”“一直吃这款大米,质量好,味道香,日期新鲜,东北大米,香好吃。”
价格——指消费者对某种大米价格的看法。因为价格是与商品联系最为紧密的一个属性,该词包含的特征词出现的频率也较高,但大体上只分为两种“物有所值”或“质次价高”。该主题词涉及的评论如下:“很好,比超市便宜很多,经常买,值得推荐。”“不怎么好吃,但是价格也不便宜”
活动——指电商平台或者商家自身推出的优惠活动、节日促销活动等,有些消费者若是正好赶上某种优惠活动,可能就会作出更多的积极评价。而且,对于商家,也是一个增加销量的机会。该主题词涉及的评论如下:“搞活动时很便宜,实惠”“米的味道不错,吃起来口感挺好的,有优惠下次还买。”“活动买的,价格便宜。品质好,效率高。”
五、情感倾向标注
结合上文的结果,本小节对五个大米主题词进行情感标注,据此可以判断主题词包含特征词的情感倾向,进而得到积极评论所占百分比,即消费者对于某个主题的满意度。分别得到三种不同品牌大米在同一主题词下的消费者满意度,观察彼此之间的异同,就可以对比得出不同品牌大米的特点。
本文采用了基于情感词典的方法对大米特征词的情感倾向进行判断。借鉴目前极性词典建设过程中的成功做法,本文着手构建一部满足该研究需要的情感词典,该词典包括:知网(HowNet)词典、大连理工大学的情感本体词汇、程度词词典、同义词词林。
基于情感词典方法的主要思想如下。
一是对于情感词典内包含的词语,直接依靠情感词典进行标注。
二是对于情感词典内未包含的词语,利用同义词林,计算其与HowNet中词语的相似度,据此对该词进行标注。
三是否定词处理,一句话中若出现奇数次否定词,则该句话的情感倾向应发生转变。所以,统计出否定词出现次数的奇偶性判断是否需要转变情感倾向。
在R语言中进行编程设计之后,得到三种不同品牌大米在同一主题词下的消费者满意度,如图所示。
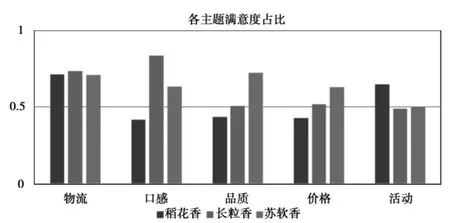
图 消费者对各主题满意度的直方图
由上图可知:
一是在物流方面,由于抓取的评论来源于不同的电商平台,在某种程度上,物流之间的评论并不能完全体现出差别,所以三种不同品牌的大米消费者对于物流之间的差距甚微、满意度基本持平,各品牌之间的差异不大,均在72.5%。
二是在口感方面,三种品牌大米就有了较为明显的差异。其中,属于东北米的长粒香大米获得了83.3%消费者的青睐,反观稻花香和苏软香大米,在口感方面,消费者满意度分别为41.8%与63.2%。
三是在品质方面,苏软香大米获得消费者满意度最高,为72.1%,主要体现在该类评论中:“包装是真空袋,不易破损、漏气”由于包装好,所以大米新鲜,消费者满意度自然就提高了。反观,稻花香大米,它获得的满意度最低,为43.5%,与苏软香大米相比较,主要是由于包装不好,导致破损,漏气,从而影响消费者的满意度。虽然长粒香大米的口感最好,但在综合品质方面,其消费者满意度也仅为一半。
四是在价格方面,呈现出与在品质方面类似的趋势。苏软香大米满意度仍为最高,为62.9%。稻花香大米依然最低,为42.6%。长粒香大米表现也中规中矩,为51.8%。
五是在活动方面,出现了反常的态势,稻花香大米满意度最高,长粒香与苏软香相差无几,均在一半左右。
六、结论
对北大荒米业提出以下建议。
一是作为东北地区的米业公司,必须要牢固把握自身产品的特色。重所周知,东北米晶莹剔透、颗粒饱满。无论是煮粥还是做米饭,都软糯香甜。所以,东北米的质量无论是在口感还是外观上,都是苏北米以及其它地区的大米不能比拟的。强调这一事实,符合消费者购物的求实心理,从而在竞争激烈的米业市场能拥有一片天地。
二是产品的包装不容忽视。上文曾提到,虽然苏软香大米口感欠佳,但它的包装做的好,所以也能更多地吸引消费者的注意。故本文建议北大荒米业在原有的包装技术基础上,尽可能地提升自己产品的包装质量,以及美观程度,从求异心理的角度深深吸引消费者的眼光。
三是同种产品价格越低满意度越高,企业应想尽方法降低成本、压低价格为消费者提供更大的优惠,薄利多销实现双赢。
四是对于产品的相关促销活动也不能少,无论是线下,还是线上,都应适量举行促销活动,提高产品知名度和影响力,从而一定程度上提升产品竞争软实力。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
计算机技术与发展(2022年8期)2022-08-23
计算机系统应用(2021年9期)2021-10-11
现代信息科技(2021年21期)2021-05-07
现代信息科技(2020年18期)2020-02-22
汽车文摘(2019年3期)2019-03-04
智能计算机与应用(2018年5期)2018-10-20
电脑知识与技术·经验技巧(2018年1期)2018-05-30
档案管理(2014年6期)2014-10-30
商品与质量·消费研究(2013年7期)2013-08-29
