
基于云计算的混合超混沌分组密码方案研究
2018-07-27 05:15,,
计算机测量与控制 2018年7期
,,
(东莞职业技术学院 信息与教育技术中心,广东 东莞 523808)
0 引言
云计算是以计算机网络、服务器虚拟化、大规模数据处理等技术为基础,具备按需分配、资源共享、分布式处理等特点,是一种能够适应于当今网络通信环境的主流计算模式[1]。随着计算机网络、移动互联网、物联网等技术的发展,全球入网的终端和用户激增,云计算技术在工业、金融、政府、医疗、教育等各个行业和领域得到了广泛的应用。但是,由于云计算安全架构尚存在不够完善的地方,伴随着云计算技术的普及和推广,在云计算环境中的各种安全问题逐渐显露出来,引起了各界人士的广泛关注[2]。
密码技术作为一种传统的安全防护手段,具有悠久的发展历史。在云计算环境中,密码技术作为数据安全防护的一种基本的手段和方法,被许多专家和学者广泛讨论,且已经取得了一定的研究成果[3-5]。文献[3]针对云计算环境中数据存储安全问题,提出了一种基于HDFS的数据安全防护方案,在传输和存储环节,采用AES和RSA加密的方法提高云数据的安全性;文献[4]提出了一种面向云计算环境的并行AES加密算法,利用云计算MapReduce框架,采用并行数据处理模式,提高了加密算法的执行效率;最近,文献[5]在文献[4]的基础上,对密码算法进行改进和优化,混合三维连续混沌系统和二维离散混沌系统,提出了一种基于云计算MapReduce并行架构的混沌密码方案,进一步减少了密码方案的运行时间。然而,现有的基于云计算的密码方案仍然存在一些不足之处:一是随着量子计算机等新兴技术的发展,密钥空间的安全性问题将面临更加严峻的考验[6];二是现有的混沌密码算法中均采用低维混沌系统,容易被黑客采用系统重构等方法攻击和破解,安全性还有待提高[7]。为了进一步提高云计算环境中的数据安全性,融合现有的研究方法的优良特性,进而改善和提高密码方案的安全性、可靠性和可行性,本文对一种基于云计算的混合超混沌密码方案进行分析和研究。首先,选取三个超混沌系统的初始值作为密钥参数,利用超混沌系统更加复杂的动力学行为产生随机特性良好的混沌序列;然后,对三个超混沌系统进行预处理后,进而设计一个混合超混沌分组加密方案;最后,基于云计算分布式编程模型MapReduce,设计并实现了混合超混沌分组密码方案,并对其安全性和运行效率进行分析。
1 Hadoop云计算平台
Hadoop是Apache基金会一个开源的分布式计算平台,包括两个核心组件:HDFS和MapReduce。HDFS为海量数据提供存储,MapReduce则为海量数据提供计算[8]。Hadoop在存储和处理大量数据时效率很高,并且与其他平台相比更经济。
1.1 云存储HDFS
HDFS是Hadoop中的分布式文件系统(Hadoop Distributed File System)的缩写,具有着高容错性的特点,通常部署在低廉的硬件上。它提供高传输率来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS采用主从架构,由两个基本基本组件构成:名称节点NameNode和数据节点DataNode。
1.2 云计算框架MapReduce
MapReduce是一种专门面向云计算的编程模型和实现框架,具有简单、高效、易伸缩以及高容错性等特点。它是与HDFS相应的数据处理部分,提供最基本的数据批处理机制。与HDFS类似,MapReduce也是采用主从架构,包括两个主要部分:主节点JobTracker和从节点TaskTracker。MapReduce将作业分解成顺序执行的Map阶段和Reduce阶段,Map/Reduce任务的实例部署到Map/Reduce节点并行执行。
2 超混沌系统及其密码方案设计
2.1 超混沌系统
自从1963年气象学家洛伦兹发现第一个混沌系统以来,混沌理论方面的研究得到了深入而广泛的推进。超混沌系统及其在混沌密码中的应用是近年来混沌领域研究的热门方向之一。超混沌系统是指具有两个或两个以上的正Lyapunov指数,具有比一般的混沌系统更为复杂的动力学行为[9-11]。在此引进入三个经典的四维超混沌系统:Lorenz、Chen和Lü超混沌系统。为方便叙述,分别将Lorenz超混沌系统[9]、Chen超混沌系统[10]和Lü超混沌系统[11]简记为超混沌系统Ⅰ、Ⅱ和Ⅲ,其数学模型分别为:
其中:xi,yi,zi,wi,i=1,2,3是三个超混沌系统的状态变量,ai,bi,ci,di,ei是系统的控制参数。当系统Ⅰ、Ⅱ和Ⅲ为参数要求分别满足:
则系统Ⅰ、Ⅱ和Ⅲ处于超混沌态。三个超混沌系统的的吸引子相图及时域波形图如图1所示。可以看出,三个超系统具有复杂的动力学行为,并且所产生的混沌伪随机序列具有长期不可预测性、周期点稠密、对初始和参数高度敏感等混沌特性,与密码学中的混淆和扩散等特性具有许多相似之处,非常适合应用于数据加密中。
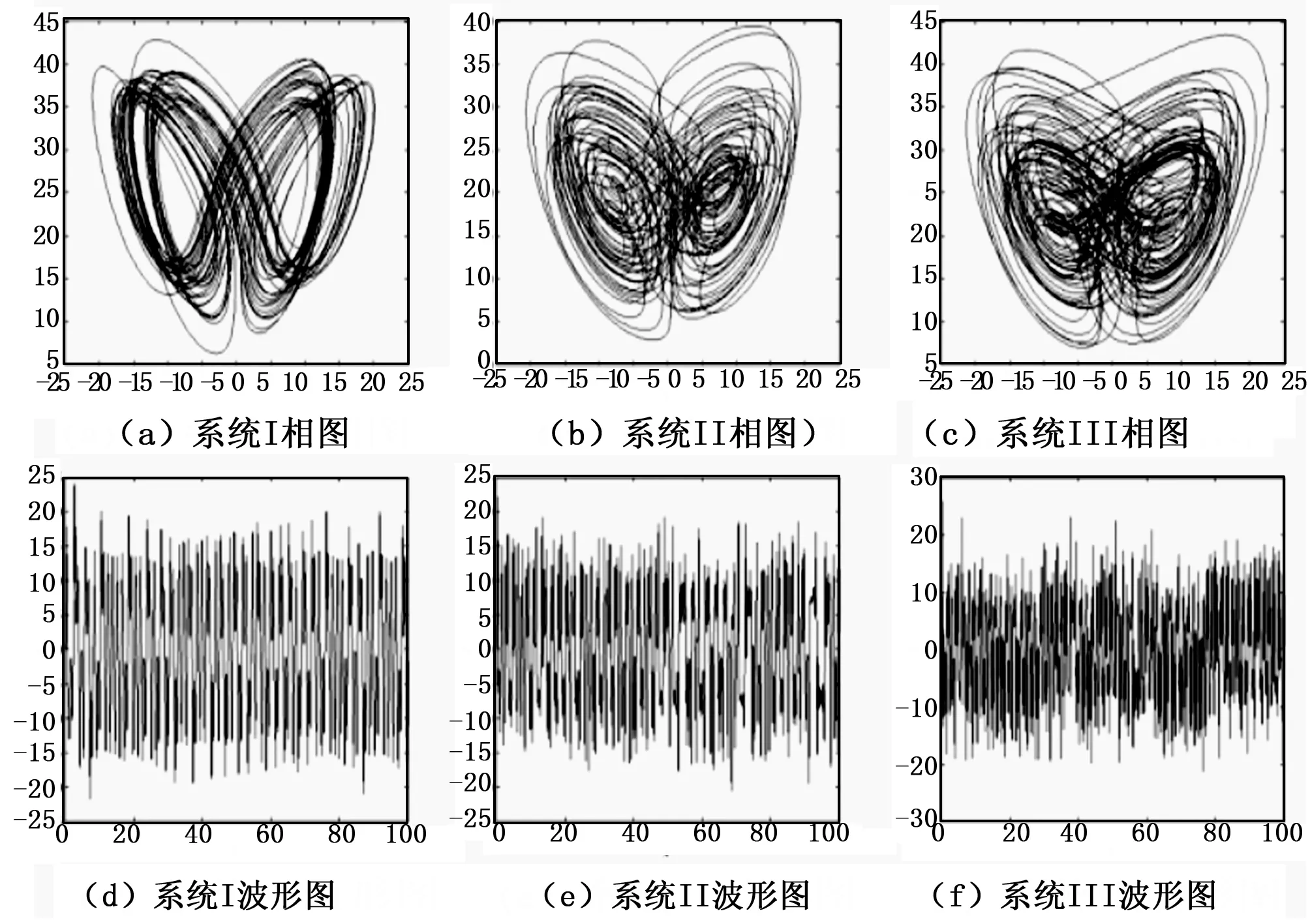
图1 三个超混沌系统的吸引子相图及时域波形图
2.2 混合超混沌分组密码方案设计
对称混沌密码包括流密码和分组密码两种,为了融合多个超混沌系统所产生的混沌序列的随机特性,提高算法的安全性,本文所设计的密码方案采用分组密码。值得指出的是,超混沌系统产生的各个状态变量之间存在一定的关联性,这种关联性导致产生的混沌序列之间可能存在一定的互相关性,在密码攻击中存在容易被辨识或预估的风险。为了解决这个问题,对三个超混沌系统的状态变量混合异或的方法进行混淆,从而进一步提高混沌序列的随机特性。混合超混沌分组加密方案的具体步骤如下:
1) 对连续混沌系统产生混沌序列预处理。首先,采用四阶Runge-Kutta法对连续时间超混沌系统进行离散化处理,丢弃前面l=200个迭代序列的值,得到12个混沌序列:xi(n),yi(n),zi(n),wi(n),i=1,2,3;接着,对混沌序列进行小数点移位、取模等运算,处理为适合于按照字节加密的混沌序列,处理方法为:
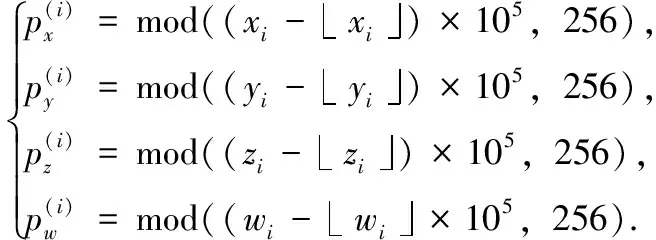
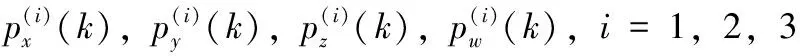
2) 混淆三个超混沌系统产生的随机序列。将经过预处理的三个超混沌系统产生的混沌序列按照状态变量进行对应的异或操作,从而使得各混沌序列之间的互关联性降低。
3) 超混沌序列数据加密操作。将这4个混沌序列按照每4个字节为一组进行分组数据加密。超混沌分组加密方案如图2所示。
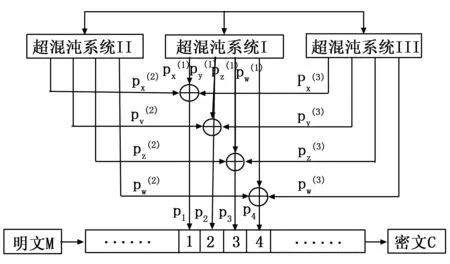
图2 混合超混沌分组加密方案
其中,“⊕”表示按位异或运算,经过混合超混沌分组加密后的明文M将变成密文C。
面对倔强的女儿,母亲扔下一句:“想学表演就要靠你自己,不要靠我们。”倔强的巩俐没有被母亲的话吓到,她开始一边工作,一边准备第三次艺考。自从母亲说让她独立后,巩俐仿佛一夜之间就长大了,她说:“那时候什么都不怕,没遇到困难怎么能成长呢。”她每次都是一个人连夜坐火车到北京、上海参加考试。两年后,终于如愿以偿地被中戏特批录取。
3 基于云计算的混沌加密算法设计
基于云计算的混沌加密算法是基于云存储HDFS和云计算模型MapReduce共同实现的。其中MapReduce函数的设计是混沌加密算法实现的关键步骤。首先,从HDFS读取数据,并对数据进行分片处理;接着,设计MapReduce函数,Map函数实现分片数据块的混合超混沌分组加密操作,Reduce函数完成加密后的数据块的合并;最后,将加密后的数据存储到HDFS上。加密算法的具体步骤如下:
1)从HDFS读取数据。
读取存储在HDFS上数据,并进行分片处理,为MapReduce并行处理做准备。值得注意的是,在HDFS的分片操作是由Hadoop根据系统参数设置自动完成的逻辑数据分块,并不需要设计额外的算法及编程代码进行实现。在Hadoop2.0中,数据块的大小默认设置为128MB。
2)MapReduce函数程序设计。
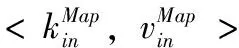
3)将加密后的数据写入到HDFS中,将经过Reduce合并后的分片密文大数据存储在HDFS上。这样,即完成整个加密的过程。
4 实验结果与分析
4.1 云计算实验环境
云计算实验环境采用一台高性能PC服务器,安装虚拟机软件VMware workstation 12,部署1至8个集群计算节点数,每个计算节点均配置为单核CPU和1 G内存,云计算软件平台采用Hadoop2.7.3版本。实验数据集采用两个大小分别为1 GB和2 GB的文本数据文件。根据Hadoop2.7.3的默认设置,Map分块数大小根据默认设置为dfs.block.size=128MB。
4.2 加密算法执行效率
执行效率是衡量密码算法优劣的一个重要指标,也是算法是否具有实用价值的必要条件。文中算法与AES算法执行效率比较情况如图3所示。实验结果表明,基于云计算的混沌密码算法具有较好的并行度,随着集群计算节点的增加,加密时间逐渐减少;此外,在相同的云计算环境中,文中算法具有比AES加密算法更快的执行速度,验证了本文所提算法的有效性。
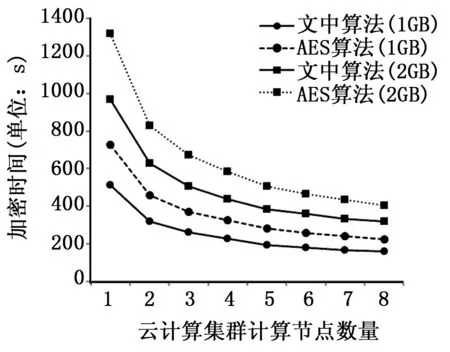
图3 算法效率比较
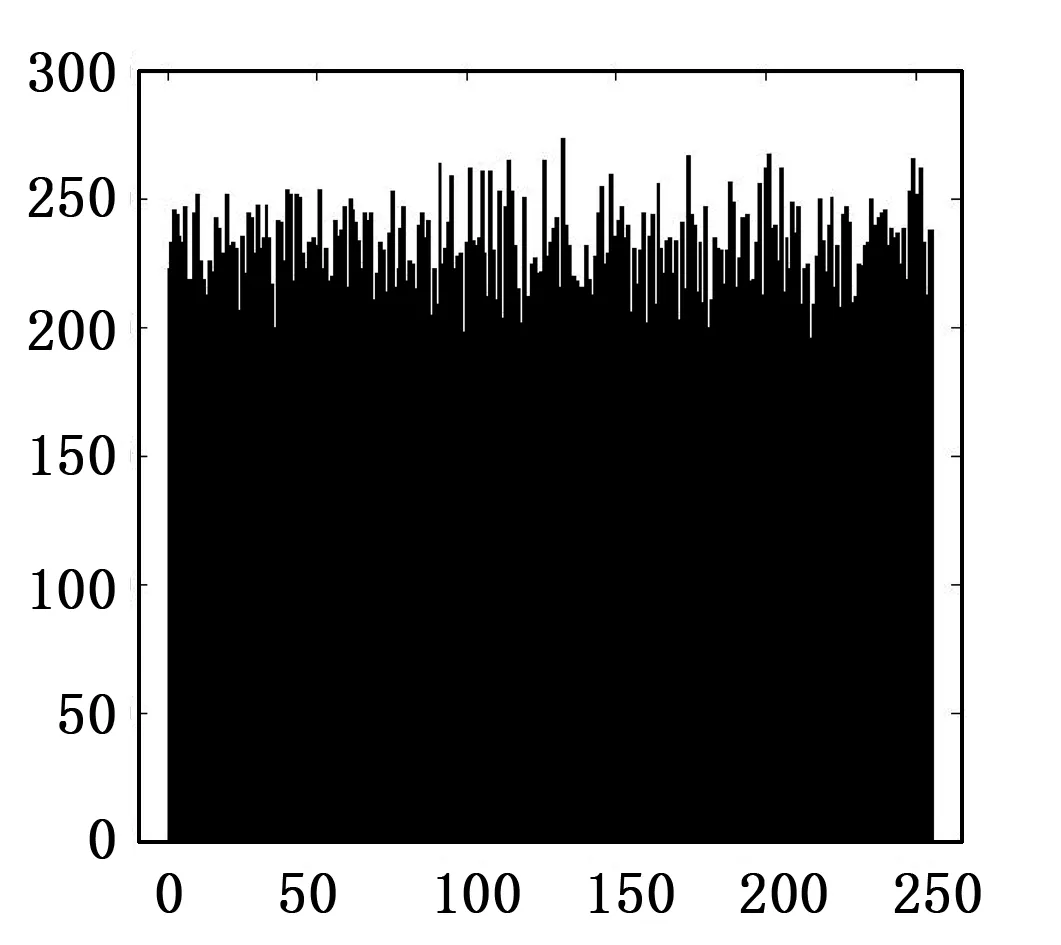
图4 密钥失配直方图
4.3 密钥空间
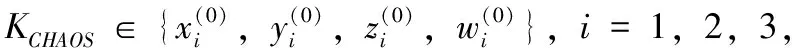

表1 几种加密算法密钥空间对比
可以看出,本文算法的密钥空间显著大于其他同类方法。如果将超混沌系统的控制参数也作为密钥参数,密钥长度还有扩容的可能。因此,本文所提的算法具有充分大的密钥空间,足以抵御暴力攻击。
4.4 密钥敏感性分析
选取其中一个超混沌系统的初始值作为密钥参数,当解密密钥参数失配10-14时,密文的文本统计直方图如图4所示。从实验结果可知,仅仅是微小的密钥失配,仍然无法正确还原原始明文,且产生与明文差距巨大的密文,说明密钥对解密密文具有雪崩效应,验证了算法具有良好的密钥敏感性,可抵御差分攻击。
5 结论
针对当今云计算环境中存在的数据安全问题,综合利用云计算MapReduce的并行编程架构及混沌密码算法的优点,提出了一种基于Hadoop云计算平台的混合超混沌分组密码方案。实验结果和数据分析表明,在运行效率方面,本文所设计的密码算法具有优于同样实验环境下的AES算法。在安全性方面,密钥空间显著增大,足以对抗暴力攻击;密钥参数对密文具有雪崩效应,可有效抵抗差分攻击。此外,本文所提的密码方案是基于云计算环境进行开发和设计,因此,能够很好地适应于当前的网络通讯环境,对于应当和解决移动互联网、网络大数据下的数据安全及隐私保护等问题具有潜在的应用价值。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
消费电子(2022年7期)2022-10-31
北京航空航天大学学报(2022年2期)2022-03-08
故事作文·低年级(2022年2期)2022-02-23
故事作文·低年级(2022年1期)2022-02-03
北京电子科技学院学报(2020年2期)2020-11-20
数码世界(2020年4期)2020-06-18
网络安全技术与应用(2019年7期)2019-07-10
电子制作(2019年9期)2019-05-30
小型微型计算机系统(2018年9期)2018-10-26
