
增强变分自编码器做非平行语料语音转换
2018-07-26 05:40黄国捷俞一彪
信号处理 2018年10期
黄国捷 金 慧 俞一彪
(苏州大学电子信息学院,江苏苏州 215006)
1 引言
语音转换就是保持语义信息不变,仅改变一个说话人的语音个性特征(称为源说话人),使其听起来像是另一个说话人(称为目标说话人)的语音个性特征[1]。通过对语音转换的研究,可以进一步加强对语音相关参数的研究,探索人类的发音机理,控制语音信号的个性特征参数,对语音信号转换的研究可推动其他领域如:语音合成、语音识别、说话人识别等的发展,在文语转换、说话人伪装身份通信、多媒体娱乐、医学领域的语音增强、极低速率的语音编码方案[2]等领域有广泛应用价值。
语音转换最基本的内容有两个方面:韵律信息的转换和频谱特征参数的转换,国内外的研究主要集中在频谱参数的转换方法上,现有的绝大多数算法基于统计模型[3-5]。这些算法中很多需要源和目标说话人的足量平行语料,这带来了很多具体应用限制和问题,比如,训练的数据对两个说话人必须是相同的,训练的模型只能被应用到特定的一对组合,说话人的语料不充足,对齐时可能会出现的帧间错误匹配等等。21世纪以来,一些学者积极探索基于非平行语料的语音转换算法。其克服了平行语料语音转换的部分问题,如不需要相同的训练数据,模型可以被应用于多对一的组合。2006年,Geoffery Hinton在Science发表文章[6],提出基于深度信念网络(Deep Belief Networks, DBN)可使用非监督的逐层贪心训练算法,掀起了深度学习理论在语音转换上的研究浪潮[7- 8]。2015年香港中文大学的学者Lifa Sun利用自动语音识别系统对长短时记忆递归神经网络模型训练,实现了多对一的语音转换[9]。2016年,Hsu等人使用变分自编码器进行非平行语料的语音转换[10]。该方法将源语音经过编码网络生成服从高斯分布的语音编码,再经过解码网络将其重构为指定的目标语音,取得了较好的结果。
本文提出了一个增强变分自编码器,通过在变分自编码器中增加一个增强网络,由于增强网络是一个输入对应一个输出的,这使得增强变分自编码器有较好的去噪能力,从而可以部分克服变分自编码器的缺点,得到更好的语音转换效果。此外,本文还引入了循环训练方法以改善转换语音的目标倾向性。本文的其余部分安排如下:第2部分简要介绍基于变分自编码器的语音转换原理,第3部分阐述了如何改进变分自编码器,并介绍增强变分自编码器结构和训练流程,第4部分通过实验数据来验证本文提出的模型。最后,对本文的工作进行了总结。
2 变分自编码器
变分自编码器是一种生成模型,它将深度学习的观点与统计学习结合在一起。变分自编码器运用了贝叶斯的方法,它是在概率图模型上执行高效的近似推理和学习,并且涉及到对后验概率的近似优化[11]。

图1 变量x产生过程Fig.1 The process of generating a variable x
则有:
(1)
由于KL散度是大于0的,则有:
(2)
其中:
(3)



图2 变分自编码器语音转换过程Fig.2 The process of voice conversion based on variation auto-encoder
3 增强变分自编码器


图3 增强变分自编码器Fig.3 Enhanced variation auto-encoder
3.1 增强网络
本文在变分自编码器上加入了增强网络,将编码网络的输出均值直接输入到解码网络中,再经过增强网络对转换后的语音进行一对一的训练,这使得增强网络的训练目标是稳定的,从而使增强网络拥有较好的去噪能力。

(4)
首先,建立一个编码网络fØ(·),此时可以记输入xs,n,xt,m为xn。它将输入的帧编码成均值变量μ和方差变量ε有:
μ,ε=fØ(xn)
(5)

(6)

(7)
之后,把(5)中得到的均值变量μ与标签变量yn联合成向量(μ,yn)以重建源语音:
(8)

(9)
3.2 循环训练
Zhud等人在2018年提出了一个cyclegan网络用于图像翻译[12]。其基本思想是:如果图像A被成功翻译成假图像B′,那么假图像B′同样可以再次被翻译成A′,且A′与A是完全相同的。
本文的循环训练的方法采用了与此相似的优化策略:一段源语音x被转化成目标语音x′,当x′通过增强网络再次变为源语音x时,可以被无失真复原,以此为优化目标来更新增强网络的参数[13-14]。
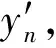
语音转换阶段,将源语音的标签替换为目标语音的标签,增强变分自编码器会输出一个目标语音。
3.3 网络损失函数
本文使用KL散度来衡量编码网络的输出与理想高斯分布的距离:
(10)
解码网络的损失为:
(11)
增强网络的重建损失为:
(12)
增强网络的循环损失为:
(13)
3.4 网络参数


表1 网络结构与参数
注:解码网络最后一层不使用激活函数和Batchnorm操作。
3.5 训练流程


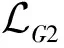
不断循环,当所有损失函数的值不再有明显变化则停止训练。
4 实验结果与分析
本文使用CMU ARCTIC语料库[15]进行跨性别语音转换实验(男性对女性,女性对男性)。语音信号在16 kHz单声道采样,每一帧的长度为1024,帧移为256。从CMU ARCTIC语料库用选取一个男生和女生的声音,分别有1132条语音,每段语音时长约为3 s。其中一半划分为非平行的训练语音,另一半划分为测试语音。STRAIGHT(Speech Transformation And Representation and Interpolation Using Weighted Spectrogram,自适应加权谱内插)工具包提取语音参数并合成语音[16]。
4.1 客观评价

(14)
此外,需要对目标语音和转换语音做归一化处理,以减少语音强度对谱失真的影响。将测试集上每一段语音的谱失真取平均值得到平均谱失真。谱失真数值越小表示该方法越好。结果如图4所示。

图4 谱失真测度Fig.4 Spectral distortion measure
由图4可以看出,与变分自编码器语音转换系统相比,本文的语音转换系统在谱失方面有所改善。且女性转男性比男性转女性效果更好,这也与听觉效果是一致的。
4.2 主观评价
首先从测试集中随机抽取10个样本,5个为男性转女性,5个为女性转男性。每一个样本包含4个文件:源语音,目标语音,转换语音T1,转换语音T2。T1,T2是被随机打乱的,一个是本文的转换语音,另一个是变分自编码器转换的语音。每个测试者需要将T1,T2与目标语音比较,T1,T2哪一个更接近目标语音,T1,T2哪一个清晰度更好。测试者有三个选项供选择:T1更好,T2更好,T1和T2一样好。本文记优胜的方法得2分,失败的方法得0分,两种方法一样好各得1分。主观评价分数越高,那么该方法越好。参与本次测试的共有17人。两种方法得到的平均分如图5所示。

图5 相似度与清晰度比较Fig.5 Comparison of similarity and clearness
由图5可以看出,本文的方法在相似度和清晰度指标上都优于变分自编码器,在清晰度方面改善尤为明显。
此外,可以在https:∥github.com/huangguojie880/EVAE听到变分自编码器与增强变分自编码器的语音转换效果。
5 结论
本文提出了一个基于增强变分自编码器的非平行语料语音转换系统,对变分自编码器做出了进一步的改进。从跨性别语音转换的客观评价标准和主观评价标准上看,本文的改进工作颇有成效。但是,实验得到的语音转换效果与理想的非平行语料语音转换还存在一定的差距。增强变分自编码器可以克服变分自编码器本身的一些缺点,这种改进可以扩展到其他领域,如图像处理中。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
新高考·高一数学(2022年3期)2022-04-28
思维与智慧·上半月(2022年4期)2022-04-08
通信技术(2021年12期)2022-01-25
小哥白尼(神奇星球)(2021年4期)2021-07-22
制造技术与机床(2017年7期)2018-01-19
汽车观察(2016年3期)2016-02-28
探测与控制学报(2015年4期)2015-12-15
中国光学(2015年5期)2015-12-09
民族古籍研究(2014年0期)2014-10-27
