
融合深度学习特征的汉维短语表过滤研究
2018-07-25 12:09朱顺乐
计算机技术与发展 2018年7期
朱顺乐
(浙江海洋大学,浙江 舟山 316000)
1 概 述
随着经济全球化的不断深入,国家与国家之间、民族与民族之间交流时的语言障碍突显,已成为经济发展、文化交流的不利因素。机器翻译技术的发展为缓解这一障碍提供了契机。统计机器翻译(statistical machine translation,SMT)是目前学术界研究的主流方法。它是非限定领域机器翻译中性能较佳的一种方法。其基本思想,是通过对大量的平行语料进行统计分析,构建翻译模型(translation model,TM),对目标语言单语语料进行统计建模,构建语言模型(language model,LM),进而使用上述模型对输入源语言句子进行翻译。
统计机器翻译模型又分为基于词的翻译模型、基于短语的翻译模型以及基于句法的翻译模型三类。其中,基于短语的翻译模型既在翻译过程中考虑到了局部上下文信息,又不需要句法标注语料,并且能取得较好的翻译效果,因而广受学术界与工业界的青睐。
(1)

汉维翻译模型训练架构如图1所示。
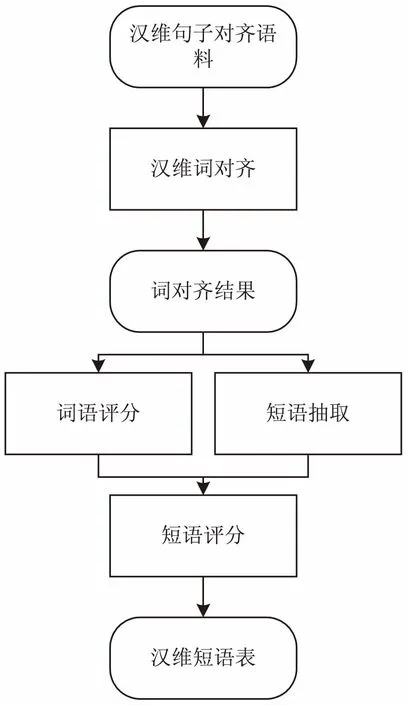
图1 汉维翻译模型训练架构
作为基于短语机器翻译模型框架的核心部分,翻译模型提供短语表、调序规则表等重要知识。短语表中包含双语短语的互译信息,其质量直接影响机器翻译模型的性能。然而,以下两个因素会对短语表的质量以及后期解码效率产生影响。(1)短语表抽取位于统计机器翻译框架的中间环节,前期的词对齐阶段产生的错误会延续到短语表生成阶段;(2)统计机器翻译模型性能很大程度上依赖于双语句子平行语料。目前,日益丰富的网络资源使得大规模语言资源的获取成为可能,然而大规模语料使得双语短语表规模呈指数级增长,从而减缓了解码速度。因此,对短语表中的噪音短语进行过滤,增大了解码阶段解码器检索到更为准确的翻译片段的概率;非法短语对的过滤可以减小短语表的规模,一定程度上提升了解码效率。
针对短语表过滤这一任务,国内外学者进行了一些研究。Nishino等提出一种基于子模函数最大化的短语表过滤方法,采用贪心的启发式算法策略实现[1];Wang等提出一种面向短语表过滤的相对熵模型,并用其衡量用小概率的翻译事件推导出短语对表示翻译事件的概率[2];Azadi等使用主题模型进行短语表的剪枝[3];Zens等首先比较了多种短语表过滤方法,并提出了基于语音理论的短语表过滤框架[4];Torr提出了一种基于句法的短语表过滤模型,该模型依赖于句法分析的结果[5]。
针对汉维机器翻译的相关研究开展较晚,前期的研究主要集中在语言的分析[6-8]、语料库建设[9]、命名实体识别[10-12]以及翻译系统构建[13-16]等方面。对于短语表的过滤及其相关工作的研究较少。
前期的研究工作并没有考虑短语的上下文信息以及双语的语义关系,即使有基于句法的模型,也要依赖于大规模的句法标注语料。文中提出一种新颖的汉维短语表过滤方法,将短语表的过滤看作分类问题:基于朴素贝叶斯(Naïve Bayes,NB)模型,融合了短语对循环神经网络(recurrent neural network,RNN)特征、上下文特征等深度学习特征,以及平均词共现特征等浅层特征,获得汉维短语对是否保留的概率值,并通过实验对其进行验证。
2 短语表生成
基于短语翻译模型中的短语表依赖于词对齐阶段产生的对齐文件以及汉维平行语料构建。因此短语表的创建可分为两个阶段:词对齐矩阵生成和短语表抽取。
2.1 词对齐矩阵生成
统计机器翻译中的词对齐,是基于统计学习的相关算法,从大规模的双语句子平行语料中自动获取词语共现等信息的过程。使用较多的词对齐算法包括IBM Model 1-5[16-17]以及基于(hidden Markov model,HMM)的词对齐模型[18]。Och基于上述模型,设计开发了广泛使用的词对齐开源工具GIZA++[19]。词对齐矩阵[20-21]即是根据词对齐结果生成的,见图2。
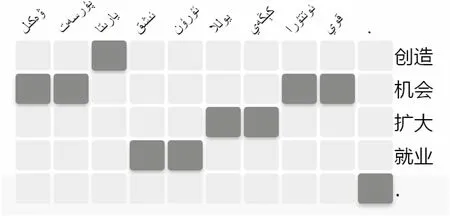
图2 汉维机器翻译词对齐矩阵
2.2 短语抽取
汉维短语抽取是短语表创建的基础。基于词对齐矩阵获取汉维双语短语对的方法如下:若与矩形所在行范围内的汉语词对齐的维吾尔语词也在当前子矩形内,提取对齐矩阵中所有以对齐点为顶点矩形区域所表示的汉维短语对。其核心思想,即是首先穷举汉语句子中所有可能的短语,根据词对齐矩阵,检索对应维吾尔语句子中的短语。抽取的部分汉维短语表如图3所示。
上述过程抽取到的只是候选短语。在添加至短语表之前,还应对其进行校验。校验遵循的原则有两个:

图3 汉维短语表(局部)
(1)候选汉语端的单词在汉语句子中的位置必须连续;
统计词对齐模型基于大规模的平行语料。然而,由于平行语料规模的局限性以及汉语、维吾尔语的差异性,汉维词对齐过程中会出现数据稀疏问题,影响了词对齐的准确性,进而导致汉维短语抽取过程中出现偏差,影响后续的翻译模型训练以及机器翻译系统的解码效率。
3 特征描述
为了对汉维短语表进行过滤,从双语短语对循环神经网络特征(RNN)、上下文特征(BIT)以及短语对中平均词共现次数(ACC)等特征出发,分别构建相应的特征函数。
3.1 短语对循环神经网络特征
为了最大限度获取汉维短语表中候选双语短语的对应关系,以便更好地对短语表进行过滤,基于RNN[21-22]获取维吾尔语和汉语短语之间的互译概率。RNN的主要优势在于处理序列数据。与以往的模型不同,基于RNN处理序列预测问题时,该序列当前的输出与之前的输出也有关系,即网络会对前面的信息进行记忆并应用于当前序列输出的计算中;RNN网络中,隐藏层之间的节点是有连接的,当前隐藏层的输入不仅包括输入层的内容,还包括上一时刻隐藏层的输出。
根据短语表过滤这一应用,文中使用RNN的编码器-解码器架构。基于该网络结构可以同步获得短语表中汉维短语对的对齐及翻译概率值,将其作为该短语是否保留的重要特征之一。
将双语短语之间的对应概率进行转换,用以预测汉维短语词之间的对应关系。使用RNN方法预测i时刻的词对应概率可形式化地表示如下:
(2)
其中,si表示RNN模型时刻t的隐藏状态;上下文向量ci依赖于输入短语映射的标记序列,ci可被定义为对标记hi的加权求和,标记的权值计算如下:
(3)
3.2 短语上下文特征
统计机器翻译模型训练过程中存在较为严重的数据稀疏问题。造成数据稀疏的原因是复杂的,即使使用超大规模的语料库也不能获取每个词组成的所有字符串。训练过程中的数据稀疏问题也会对短语表的过滤产生影响。针对该问题,提出一种缓解数据稀疏的策略,即基于Skip-gram[23-24]获取双语短语中的上下文特征,计算相应的概率值,并将其作为短语表过滤模型的特征之一。
Skip-gram是n-gram的泛化。与n-gram类似,也是使用n-gram的方式对语言建模,但允许n-gram语法中跳过若干词。Skip-gram可定义如下:
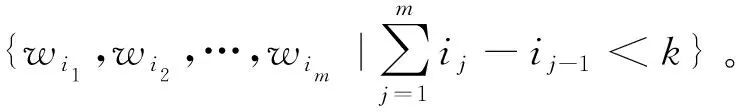
文中的当前词设定为词对齐阶段准确率较高的词,根据该汉维词对,预测其上下文信息,进而获得双语上下文信息中存在的有对齐关系词对的对齐概率。将此概率作为最终的双语短语上下文特征。
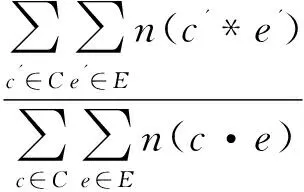
(4)
其中,C和E是根据Skip-gram算法得到的对应位置元素有语义关系的子短语集合;c'*e'表明两个单词的对齐概率大于某个阈值t(经验值)。
3.3 短语对平均词共现特征
汉维双语平行语料包含大量的词对应信息。文中提出的短语表过滤模型中第三个重要的特征即是充分利用汉维平行语料中的词共现信息,提取汉维短语之间的对应关系。具体做法如下:根据词对齐阶段统计的汉维词共现信息,计算得到当前汉语短语对中有互译关系词在短语对中所占比例。
(5)
其中,CoNUM(ci,ej)表示根据汉维词共现信息,短语对中的汉语词c和维吾尔语词ej之间存在对应关系;Lens表示汉语短语长度;Lent表示维吾尔语短语长度。
4 汉维短语表过滤模型
根据上述短语对循环神经网络特征、汉维双语短语上下文特征以及汉维短语对平均词共现特征以及朴素贝叶斯分类模型,构建面向汉维机器翻译的短语表过滤模型。
4.1 朴素贝叶斯分类器
朴素贝叶斯分类模型[25]是一种基于特征独立假设贝叶斯定律的简单概率分类器。该分类器可以更加精确地描述特征之间潜在的概率关系。朴素贝叶斯模型基于概率推理过程,即各个条件均存在一定概率的不确定性,在仅仅知道其出现概率的情况下,如何完成分类过程。朴素贝叶斯分类模型基于独立假设,即分类假设样本特征之间是相互独立的。
朴素贝叶斯模型依赖精确的概率推理,因此,与其他分类算法相比,其在有监督学习的样例集合上能获得较好的分类效果,广泛应用于文本分类、数据挖掘等领域。
通过对汉维短语表中抽取出的三个特征进行分析,发现三个特征之间不存在直接的相关性,短语对循环神经网络特征依赖于当前短语所在句子的全局信息;短语上下文特征考虑当前短语对中词在大规模单语语料中的语义关系;平均词共现特征仅仅考虑当前短语对中词之间的对齐信息。因此,文中选择朴素贝叶斯模型作为短语对过滤模型的基线算法。
4.2 短语表过滤模型
文中提出的汉维短语表过滤模型主要由以下三部分组成:原始汉维短语表获取;汉维短语对特征抽取;汉维短语对平均词共现特征。
汉维短语表过滤模型的输入为特征向量f,输出为类标记c。其中,特征向量包括三类特征:汉维短语对循环神经网络特征、汉维短语对上下文特征以及汉维短语对平均词共现特征。文中提出的短语表过滤模型构成的特征向量可以形式化地表示为:T={(f1,c1),(f2,c2),…,(fn,cn)},其中的特征由三元组组成:
5 实 验
5.1 实验设置
5.1.1 实验数据
为了验证提出的短语表过滤模型的有效性,实验使用了三类语料:汉维双语句子平行语料(训练集:300 000,开发集:700,测试集:1 500)、汉维词典(24万词)以及人工筛选的汉维短语对正反例(正例1 000短语对,反例1 000短语对)。其中双语句子平行语料主要用于统计机器翻译模型训练及其双语特征抽取;汉维词典用于双语短语特征获取;汉维短语对正反例用于训练短语对过滤模型。
5.1.2 实验装置
汉维机器翻译实验使用开源的机器翻译工具集Moses,分别在基于短语模型以及基于层次短语模型上进行实验。语言模型选用SRLM,使用五元语言模型。参数调整使用MERT算法[26]。机器翻译性能打分使用BLEU[27]。汉语端分词工具使用NLPIR。汉维短语对循环神经网络特征抽取基于开源的工具集DeepLearning4j实现。短语对上下文特征抽取,使用word2vec工具实现。汉维短语表过滤模型采用自主实现的naivebayes4j训练。
5.2 实验过程
首先,对汉语和维吾尔语语料进行全半角转换、分词、Tokenization操作;其次,采用双语语料获取原始短语表;再次,抽取汉维正反例语料中的汉维短语对循环神经网络特征、汉维短语对上下文特征以及汉维双语短语平均词共现特征,将其作为输入进行短语表过滤模型训练;最后,采用训练得到的模型在不同短语长度限制下进行短语表过滤实验。
5.3 实验结果与分析
分别从对短语表规模、翻译解码效率以及翻译性能的影响进行分析。
5.3.1 对汉维短语表的影响
根据提出的短语表过滤模型,基于短语汉维机器翻译短语表的规模在最大短语长度分别取7,9,11时均有较大幅度减小(见表1)。为了验证文中方法的泛化功能,也在汉维层次短语模型上进行了实验,在最大规则长度分别取上述值时,规则表规模也有所减小。分析原因,提出的方法过滤了大量的不合理短语(规则)对。

表1 对汉维短语表(规则表)规模的影响
5.3.2 对机器翻译效率的影响
从表1可以看出,由于大量不合理短语(规则)对被文中提出的模型过滤,短语(规则)表规模有了明显减小。因此,解码的效率也有所提高(见表2)。
表2 对汉维翻译解码效率的影响

s
5.3.3 对模型性能的影响
由于提出的短语表过滤模型一定程度上减少了不合理短语对的数量,过滤后的汉维机器翻译质量总体高于过滤前。对比短语模型和层次短语模型,在规则长度不少于9时,层次短语模型翻译质量高于短语翻译模型。其中,最大规则长度为9时,基于层次短语的汉维机器翻译模型在过滤后翻译性能达到最优(见表3)。分析原因,与基于短语的模型相比,层次短语模型中的非终结符有一定的泛化能力及局部调序能力。

表3 对汉维机器翻译模型性能的影响
6 结束语
由于汉语和维吾尔语在构词及形态上存在较大差异性,模型训练过程中存在较严重的数据稀疏问题,致使汉维词对齐出现偏差;这一偏差又会传递至短语表生成阶段,产生不合理的短语对,最终影响翻译质量机器解码效率。综合考虑汉、维吾尔语言特征及汉维短语表中存在的问题,提出了一种融合深度学习特征的汉维短语表过滤模型,该模型基于短语对循环神经网络特征、上下文特征以及平均词共现特征,并将各个特征概率及训练实例输入到基于朴素贝叶斯分类器的短语表过滤模型进行训练。该模型结合了汉维候选短语之间更为丰富的语义及上下文信息。实验结果表明,该方法有效提升了汉维机器翻译性能,解码效率也有了显著提高。
在下一步的工作中,将在该模型的基础上融入更多的语言学信息,如词性标注、句法标注等,以更大幅度地改善汉维机器翻译质量及其翻译效率。
猜你喜欢
厦门大学学报(自然科学版)(2021年4期)2021-06-22
法律方法(2021年4期)2021-03-16
法律方法(2021年4期)2021-03-16
南方周末(2019-12-19)2019-12-19
中国外汇(2019年19期)2019-11-26
电脑知识与技术(2019年23期)2019-11-03
南方周末(2019-07-18)2019-07-18
南方周末(2019-05-09)2019-05-09
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
