
融合稀疏度加权的协同过滤算法研究
2018-07-25 12:08:38孔广黔
计算机技术与发展 2018年7期
钱 刃,吴 云,孔广黔
(贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
1 概 述
在互联网高速发展的当代,互联网为每个人带来的信息量也在高速增长,人们面对海量信息时很难从其中提取出对自己最有用的信息,就如在电商网站中用户面对海量商品,很难选择出最适合自己的商品,这样既浪费了用户的时间,也使得网站的利益受损。为了使电商网站更好地销售物品,方便用户,推荐系统在各大电商网站得到了应用,其中协同过滤算法是广泛应用的一种推荐算法。
协同过滤算法由Goldberg等提出[1],研究者将该算法应用在一个文档过滤系统中,系统要求用户对文档评分,其他用户浏览时可以输入查询语句来过滤自己需要的文档。之后协同过滤算法被GroupLens用于新闻推荐[2],极大地促进了协同过滤算法的发展,也迅速推动了协同过滤算法在Internet上的应用及其相关研究。
协同过滤拥有如下优势:
(1)算法可以推荐任何资源,而不仅限于文本或者网站等。这是因为协同过滤算法需要考虑的只是用户间对物品的评价,而无需关注资源的特性,这使得协同过滤算法的适用范围变得十分宽广,可以为用户推荐任何资源。
(2)模型简单,易于实现,各大网站可以方便地使用协同过滤算法来实现推荐,而不需要为此付出过高的代价。
(3)对用户的推荐具有新颖性,不在是根据用户历史来重复推荐一个类别或几个类别的物品。协同过滤算法因为是从相似用户中寻找物品进行推荐,所以算法可能会为用户推荐该用户历史上从未接触到的物品,并且该物品也符合用户的喜好。这样可以挖掘出更多的推荐项,不仅对用户友好,而且有利于挖掘长尾物品[3]。
协同过滤算法在现阶段的主要问题是稀疏性问题。由于网站特别是大型网站拥有大量的用户和物品数量,而绝大多数用户只会对极少的一些物品进行评价,因此评分矩阵非常稀疏,在这种稀疏矩阵中,协同过滤算法很难准确地找到相似用户或者找到的相似用户的评分稀少,最终使得推荐效率低下。
为了解决协同过滤算法由于稀疏性带来的性能低下问题,提出了融合稀疏度加权的协同过滤算法。首先,对稀疏矩阵的稀疏度进行计算评估;然后,在寻找相似用户阶段通过用户密度与矩阵稀疏度对两两用户间进行稀疏度加权,这样寻找的相似用户更加准确。
2 已有算法分析
目前,为了解决协同过滤算法中的稀疏度问题,研究人员提出了许多解决方法,大致分为三类:填充类、降维类和改进相似度计算类。
填充类方法[4]通过在稀疏矩阵中添加数据从而使得矩阵不再稀疏,降低稀疏性对协同过滤算法的影响。最基本的填充方法是在稀疏矩阵中添加均值或者中位数等等。例如,李灿等在IALM和填充可信度的协同过滤算法及其并行化研究[5]中提出利用可扩充的拉格朗日乘法对评分矩阵进行填充;郝立燕等在基于填充和相似性信任因子的协同过滤推荐算法[6]中提出通过SOFT-IMPUTE算法[7]对矩阵进行填充;Zheng L等提出建立一个兴趣强度的时间衰减模型,并以此预测评分来填充矩阵[8];康钟荣提出通过贝叶斯模型预估评分来填充矩阵[9]。稀疏矩阵在经过填充之后的确可以在一定程度上解决稀疏性所带来的问题,但是填充算法大部分较为复杂,这样就使得改进后的协同过滤算法在效率上受到限制,不能为用户频繁更新推荐列表。
降维类方法[10]通过对稀疏矩阵进行降维达到缓解矩阵稀疏度的目的。例如,Sarwar B等提出使用SVD算法将原始矩阵M分解成为三个矩阵U,Σ,VT:M≈UΣVT,然后在低阶矩阵UΣ1/2上运行协同过滤算法[11];孙光福等引入用户与物品间的时序关系,然后将时序关系融入到概率矩阵分解算法中,最后将矩阵分解降维[12]。降维类算法虽然降低了矩阵的稀疏度,但是在降维的过程中损失掉了更多相似信息,使算法更加难以找到相似用户。
改进相似度的方法[13]通过改进相似度计算使得稀疏性对协同过滤算法的影响降低。这类方法既避免了填充类方法带来的代价过大问题,也不像降维类方法那样降低推荐性能。例如,张光卫等提出的基于云模型的相似度计算方法[14],算法避免使用传统向量来计算相似度,因此在稀疏矩阵中改进了协同算法的性能;Luo等提出全局相似度和局部相似度[15],文中分别计算各个用户间的局部相似度与全局相似度,然后将两个相似度融合成最终的相似度来寻找相似用户;Kaleli C等首先将用户评分信息加入信息熵,然后在计算用户相似度时加入信息熵来确定差异,衡量每个相似用户的不确定性,从而改进相似度计算公式[16]。在这些研究的基础上,文中提出了融合稀疏度加权的协同过滤算法。算法通过矩阵稀疏度进行加权来改进相似度的计算,可以让稀疏矩阵中的相似信息得到更有效的利用,从而提高协同过滤算法的性能。
3 模型定义
3.1 稀疏度加权
在协同过滤算法中,稀疏性问题严重制约着协同过滤算法的性能。由于稀疏矩阵中所包含的用户相似信息十分有限,因此更有效地利用这些信息成为了提高协同算法性能的关键。对此,文中提出在计算用户相似度时对稀疏度进行加权。
首先,对稀疏度加权需要更准确地计算稀疏度。传统计算矩阵稀疏度的方法是将矩阵中未评价的评分单元数比上矩阵总单元数。然而这样计算得到的矩阵稀疏度并不能准确表示矩阵真实的稀疏度。因为影响矩阵稀疏度的因素并不是仅仅包含数据本身的稀疏度,它还包括用户间的关系密度。关系密度是指用户在各个项目上评价的集中程度,如果用户在各个项目上的评价很分散,就会导致用户间的关系密度很低,即原始评分矩阵中所包含的有效相似信息很少,就认定矩阵十分稀疏。所以提出一个矩阵稀疏度的计算公式:
(1)
式1表示任意两个用户间共同评价的项目与两个用户评价项目总数的比值,在计算出所有比值后取平均值,利用平均值来衡量矩阵的稀疏度。
在得出矩阵的稀疏度以后,再计算其中任意两个用户i,j之间的关系密度与整个矩阵的稀疏度的比值并归一化得到稀疏度加权项:
(2)
如果某两个用户之间的关系密度很大,那么这个权值就会很大,最终用户间的相似度计算结果就能更准确地表示这两个用户的相似度。
3.2 改进后的协同过滤算法
文中在协同过滤算法中融入上述稀疏度加权项,从而更有效地利用评分矩阵中的有限信息。
首先建立用户评分字典Dict_rt与用户关系字典dict_rs。Dict_rt的结构为{用户ID:{物品ID:用户评分,…},…},文中将所有原始数据结构化存储在用户评分字典Dict_rt中。dict_rs的结构为{用户ID:{用户ID:关系密度,…},…},文中在用户评分字典Dict_rt的基础上利用式1得出整个矩阵的稀疏度,然后对所有二元组合的用户使用式2得到用户间的关系密度,将所有关系密度存储在字典dict_rs中。
接下来计算用户相似度,相似度计算方法有许多,其中比较常用的有:
(1)余弦距离。
余弦距离通过计算用户之间的余弦值来衡量用户之间的相似性,在评分矩阵中每个用户被看作一个向量,向量的维度就是物品数,用户对各个物品的评分就是用户向量在相应维度上的值,计算公式如下:
(3)
(2)皮尔逊相关系数。
通过协方差与标准差来评判两个向量的相似性,计算公式如下:
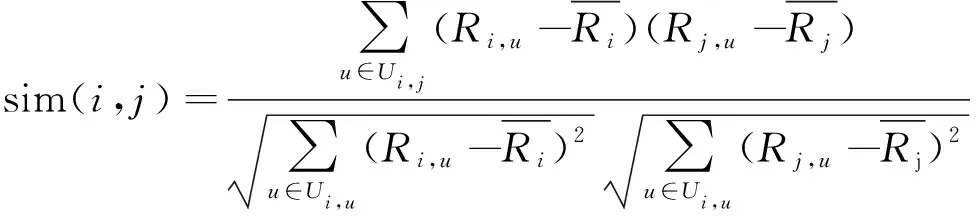
(4)
在计算用户相似度时,利用融合稀疏度加权项来改进相似度计算公式,因此改进后的余弦距离相似度计算公式为:

(5)
改进后的皮尔逊相关系数相似度计算公式为:
sim(i,j)=
(6)
算法建立用户相似度字典Dict_s存储用户相似度,字典结构为{用户ID:{用户ID:相似度,…},…},利用式5或式6计算用户相似度,将计算得到的相似度存入用户相似度字典Dict_s中。对用户相似度排序后就可以进行评分预测与推荐。
具体算法步骤如下:
(1)根据式1计算矩阵稀疏度;
(2)根据式2计算用户间关系密度与整个矩阵的稀疏度的比值,并归一化得到稀疏度加权项;
(3)使用式5和式6计算各个用户间的相似度;
(4)找到相似用户后,预测评分,进行推荐;
(5)计算推荐结果的准确率和覆盖率。
4 实 验
4.1 数据集
实验使用MovieLens公开数据集作为实验数据集,该数据集中包含1 000个用户对3 900部电影的10万条评分记录,其中每个用户的评价记录在20条以上,用户评分范围在1~5之间。
4.2 实验环境与步骤
实验采用的计算机配置为I5处理器,2 GB内存,500 GB硬盘,Win7操作系统,步骤如下:
(1)将数据集分为两部分,一部分作为测试数据集,占比为五分之一,剩下的为训练数据集。
(2)应用文中算法,分别通过式5与式6进行改进加权,以推荐准确率和推荐覆盖率作为评价标准。
(3)实验结果取相似用户的数量为变量,以10个相似用户为基础,以5个相似用户为梯度增加到50个。计算推荐准确率与覆盖率。
4.3 实验评估标准
准确率是指在推荐条目中,用户喜欢的条目数量与推荐的条目总数量的比值,其计算公式如下:
(7)
其中,R(u)为向用户推荐的条目总数;T(u)为推荐条目中用户喜欢的条目。
覆盖率可以反映出算法发现长尾物品的能力。长尾物品指在物品中用户较少评价的一些物品,覆盖率越高,算法发现长尾物品的能力越强,具体是指在推荐条目中用户喜欢的条目数量与所有用户喜欢的条目数量之比,计算公式如下:
(8)
其中,R(u)为向用户推荐的推荐条目总数;I为整个数据集中的物品数。
4.4 实验结果的比较与分析
实验首先对余弦相似度进行加权改进,和传统协同过滤算法进行比较,以验证文中算法的有效性,实验结果如图1和图2所示。
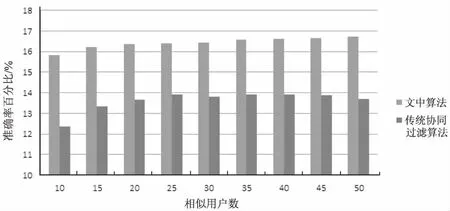
图1 采用余弦相似度时推荐准确率的比较

图2 采用余弦相似度时推荐覆盖率的比较
从结果可以看出,改进后的协同过滤算法的准确率和召回率相对传统的协同过滤算法都得到了提高。当取得相似用户增加时,两种算法的覆盖率有所降低,这是因为在取得更多用户之后,得到的推荐列表中的物品将更加集中在热度很高的物品上,但是改进后的协同过滤算法的召回率依然高于传统协同过滤算法。实验说明经过稀疏度加权之后,算法更有效地利用了原始稀疏矩阵中的信息,使得在计算寻找相似用户时更加准确有效。而寻找到相似用户是协同过滤算法的核心,协同过滤算法正是在相似用户间进行推荐。算法保证了寻找到相似用户的有效性,因此提高了准确率和覆盖率。
实验继续对皮尔逊相关系数相似度进行加权改进,同样与传统协同过滤算法进行比较,实验结果如图3和图4所示。
结果表明,算法同样提高了推荐准确率和覆盖率,证明通过矩阵稀疏度加权来寻找相似用户是行之有效的。通过矩阵稀疏度加权,使协同过滤算法在稀疏矩阵中更有效地利用评分信息来找到相似用户,从而提高了改进算法的准确率和覆盖率。

图3 采用皮尔逊相似系数时推荐准确率的比较
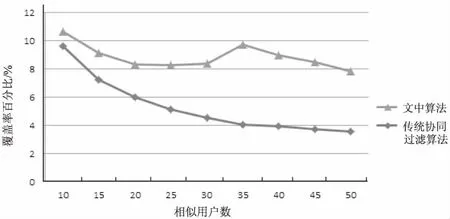
图4 采用皮尔逊相似系数时推荐覆盖率的比较
5 结束语
协同过滤算法的性能受到评分矩阵稀疏度问题的制约,稀疏的评分矩阵导致寻找相似用户困难或寻找到的相似用户不准确,最终影响协同过滤算法的性能。文中通过矩阵稀疏度加权来改进协同过滤算法,从而更有效地利用了用户评价信息,避免了稀疏性带来的问题,推荐结果可以更准确地体现用户的喜好程度。实验结果表明,该算法可以有效提高推荐的准确率与覆盖率。
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16
防爆电机(2022年4期)2022-08-17 05:59:50
今日农业(2021年21期)2021-11-26 05:07:00
中国眼镜科技杂志(2019年9期)2019-11-11 12:15:26
神州·下旬刊(2019年1期)2019-02-11 06:03:50
中国神经再生研究(英文版)(2017年10期)2017-11-08 11:48:42
西南交通大学学报(2016年6期)2016-05-04 04:13:05
计算机工程(2014年6期)2014-02-28 01:28:03
城市道桥与防洪(2014年5期)2014-02-27 07:26:16
中国工程咨询(2014年3期)2014-02-16 06:24:18
