
基于差分隐私的数据匿名化隐私保护方法
2018-07-25 12:09陈晓宇黄树成
计算机技术与发展 2018年7期
陈晓宇,韩 斌,黄树成
(江苏科技大学 计算机学院,江苏 镇江 212000)
0 引 言
随着互联网技术的飞速发展,以数据发布[1]和数据挖掘[2]为主的数据共享模式正逐步成为信息化时代的发展潮流。但是,数据共享带来便捷的同时也伴随着个人隐私数据泄露[3]的风险。如何确保隐私数据的安全性同时又不降低数据的可利用价值,成为当前隐私保护[4]领域研究工作的重点。
目前的隐私保护方法可以分为三种:匿名隐私保护[5-6],采用隐匿标识符属性[7](identity attribute,身份证号码、姓名等可以标识个体信息的属性)和泛化准标识符属性(quasi-identifier attribute,年龄、性别、生日、邮编等可以推演出标识个体信息的属性)的方式达到保护敏感属性(sensitive attribute,疾病、薪资等用户不愿透露的属性)不被泄露的目的;差分隐私保护[8],顾名思义就是为了防止差分攻击[9]的隐私保护方法。差分隐私保护通过扰乱、混淆、随机化等方式给数据添加噪声[10],使得在查询统计有且只有一条记录之差的两个数据集时,获得相同值的概率非常接近;基于密码学的隐私保护,通过数据加密达到隐私保护的目的。但是这类方法需要消耗过多的计算资源,所以很少被应用于数据发布和数据挖掘中。
在现有隐私保护方法的基础上了,提出了一种新的匿名化隐私保护方法。该方法通过引入差分隐私技术,有效地防止了匿名隐私保护中存在的背景知识攻击。同时,该方法设计了新的数据匿名化过程,经过构造具有单调性的泛化层次结构、压缩泛化后的数据等一系列措施获取到局部最优泛化过程,并通过实验验证该方法的性能。
1 理论基础
1.1 差分隐私保护
差分隐私保护通过对原始数据进行随机扰动,最终达到攻击者无法利用已知数据推测出更多数据内容的效果。
定义1:给定只相差一条记录的两个数据集D1和D2,Range(K)表示随机算法K的取值范围,若数据集在K中的任意结果S∈Range(K)都满足式1,则称算法K满足ε-差分隐私[5]。
Pr[K(D1)∈S]≤exp(ε)×Pr[K(D2)∈S]
(1)
其中,K(D1)、K(D2)是以D1、D2为输入,经由K得到的输出结果;Pr[K(D1)∈S]表示结果为S的概率,也称作隐私被泄露的风险[11];ε表示大于零的任意参数,由数据拥有者公开制定,值越小表示差分隐私保护级别越高。
函数K满足定义1时,数据的隐私就可以得到保证,与攻击者掌握的背景知识程度无关。实现差分隐私保护的主要方法是添加噪声,常用的两种噪声机制分别为拉普拉斯机制和指数机制。其中拉普拉斯机制适用于对数值型数据的保护。拉普拉斯机制通过向确切的查询结果中加入服从拉普拉斯分布的随机噪声来实现ε-差分隐私保护。记位置参数为0,尺度参数为b的拉普拉斯分布为Lap(b),那么其概率密度函数为:
(2)
设查询函数为f,数据集为D,真实的查询结果为f(D),函数K则可以表示为:
K(D)=f(D)+(Lap(Δf/ε))
(3)
其中,Lap(Δf/ε)为随机噪声,服从尺度参数为Δf/ε的拉普拉斯分布;Δf为查询函数f的全局敏感度,全局敏感度只与查询函数本身有关,与数据集的大小无关。查询函数的敏感度越大,则需要添加更多的噪声。
1.2 k-匿名
目前的数据匿名化方案主要有泛化隐匿技术[12]和基于微聚集匿名化技术两种。其中泛化隐匿技术被广泛使用,而k-匿名又是泛化隐匿技术中最具代表性的方法之一。
定义2:给定数据表T(A1,A2,…,An),QI是与T相关联的准标识符,当且仅当在T[QI]中出现的每个值序列至少要在T[QI]中出现k次,则T满足k-匿名。
如表1所示,该实例表中准标识符QI为{Race,Birth,Sex,Zip,Marital status},T[QI]中出现的任一有序元组值在T[QI]重复至少两次以上,t1[QI]=t2[QI]=t3[QI],t4[QI]=t5[QI]。则该实例表满足k=2的k-匿名保护,攻击者利用外部数据源推导出的个体元组数据不能指向任一特定个体。
k-匿名主要通过泛化技术实现。表2展示了疾病为皮肤过敏,年龄为29,邮编为212000的这组数据的泛化等级。

表1 k-匿名实例表
用三维向量(x,y,z)表示一个转换过程。x,y,z的值分别对应着疾病、年龄和邮编的泛化等级。该样例数据最高泛化等级为(2,1,3)。泛化等级越高,表示泛化程度越强,但同时信息丢失量也会跟着变大。
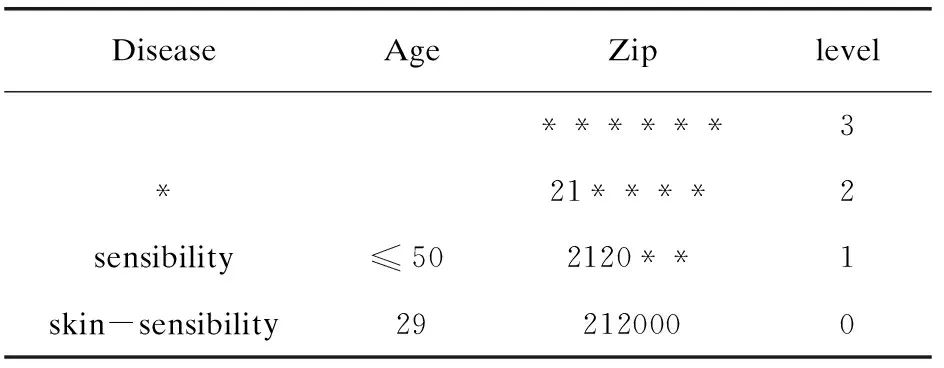
表2 泛化等级
2 基于差分隐私的数据匿名化保护方法
2.1 隐私保护方法
提出的匿名化隐私保护方法是一个将数据集里的属性进行划分,然后区别处理的过程。对布尔型的敏感属性添加符合差分隐私的拉普拉斯噪声[8]的过程,提高了敏感信息的安全性。
2.2 算法设计与实现
文中提出的基于差分隐私的数据匿名化隐私保护算法的步骤如下:
输入:原始数据集T(O1,O2,…,On)=T[O];
输出:隐私保护下的数据集T[O']。
步骤1:将输入数据集T[O]分为属性值为布尔型数据集T(A1,A2,…,Am)=T[A]及补集T(B1,B2,…,Bn-m)=T[B]。记合并T[A]和T[B]得到的数据集为T[A,B],即有T[O]=T[A,B]。用T[S]表示T[A]中属性为敏感属性的数据集。
步骤2:采用优化后的数据匿名化过程处理数据集T[B]得到T[B'],使其满足k-匿名保护的要求。
步骤3:合并T[A]和T[B']得到数据集T[D]=T[A,B']。
步骤4:转换T[D]中T[A]的存储方式,将T[A]中T[S]转换后的结果记作T[S'],同时压缩数据得到数据集T[D']。
步骤5:向T[D']中的T[S']加入符合差分隐私保护要求的拉普拉斯噪声,得到数据集T[O']。
步骤6:返回数据集T[O']。
2.2.1 优化数据匿名化过程
步骤2中提到的数据匿名化的对象T[B]是非布尔型的属性值。T[B]中的数据属性又可以分为准标识符属性和敏感属性。对数据匿名化过程的优化主要体现在以下两点:设计具有单调性的泛化层次结构,采用低级别泛化等级处理敏感属性。以表2中数据为例,具有单调性的泛化层次结构如图1所示。
每一个转换过程都可以由低一级别的转换过程得到。整个转换过程中的任意一条由底端最低泛化节点到顶端最高泛化节点的路径都具有单调性。
图1(2,1,1),(1,1,2),(2,0,2),(0,1,3),(1,0,3)这一层次中,当疾病属性,即向量中x属于敏感属性时,取x为不为0的最小值,得(1,1,2),(1,0,3),去除含有0的非匿名转换(1,0,3)得(1,1,2)。此时(1,1,2)就是这个层级中最优的泛化过程。若满足敏感属性泛化等级是不为0的最小值、且转换过程对应的向量中不含0的泛化过程不唯一,则接着比较这些转换过程的次节点的个数。(1,1,2)指向(2,1,2)和(1,1,3),有两个次节点。次节点个数越多,表示在该节点基础上提高泛化层次的选择性越多,该节点对应的转换过程将在步骤2中被使用。
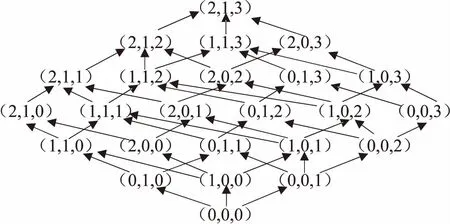
图1 单调泛化层次结构
2.2.2 转换和压缩数据
步骤4中转换和压缩处理的对象是数据集T[D]=T[A,B'],其中T[B']是符合k-匿名保护的数据集。压缩T[B'],将T[B']中相同的元组只保存一条,在表中添加一个数量(Number)属性,用来记录该相同元组存在的个数。同时,转换T[A]中的属性的表达方式。例如关于是否患有HIV属性,属性值是Y和N两种情况,将该属性转换为HIV(Y)得到T[D'],HIV(Y)表示对应数量中患有HIV的人数。结合数量属性,可知在关于是否患有HIV属性转换过程中不存在信息丢失。
2.2.3 添加拉普拉斯噪声
步骤5中利用差分隐私技术添加拉普拉斯噪声的对象是T[D']中的T[S'],T[S']中都是转换了存储方式的敏感属性。还是以关于是否患有HIV的属性为例,T[S']对应的数据属性为HIV(Y)。记HIV(Y)属性对应的值为n,则添加噪声后的输出数据为n+Lap(1/ε)。其中隐私保护预算ε可以根据需求所要的保护程度自主设定,添加噪声的过程则是对式2进行积分,求得拉普拉斯累积分布函数,再由累积分布函数求得噪声值Lap(1/ε)。
Lap(1/ε)=-b*sgn(p-0.5)*In(1-2*
|p-0.5|)
(4)
其中,p为在0.0到1.0之间均匀分布的随机数,尺度参数b满足b≥1/ε。
2.3 性能分析
2.3.1 可用性分析
文中提出的匿名化隐私保护方法通过采用低级别泛化过程处理部分敏感属性,最大可能地降低了这些敏感属性的信息丢失率[13]。同时,相比较现有匿名化隐私保护方法中直接隐匿布尔型的准标识符属性(例如:性别)的方式,通过转变存储方式,有效保障了这类属性的可用性。
2.3.2 安全性分析
文中提出的方法利用差分隐私技术,在部分敏感属性中添加拉普拉斯噪声,有效地防止了传统匿名化隐私保护方法中存在的背景知识攻击。同时,在泛化匿名过程中,采用低级别泛化过程处理敏感属性,保证了在相同的泛化层级中,准标识符属性获得更高泛化级别的保护,降低了被链接攻击的风险。
3 实验与分析
实验使用Java语言编程,编程环境为MyEclipse10,实验的环境配置为2.40GHz i5-2430M、4 GB内存、Windows7 32位操作系统。实验所采用的数据集为“ADULT”,来源于美国成年人口普查。该数据集拥有30 162个实例,9个属性值。为了验证文中方法在安全性和数据可用性方面的优势,下面将直方图发布和数据安全风险评估几个实验的结果进行分析。
3.1 直方图发布
快速而准确地获取数据分布[14]的梗概是数据分析与查询的主要任务,直方图[15]是近似估计数据分布的主要技术之一。以布尔型的敏感属性婚姻状况(Marital-status,取值:Spouse-present或Spouse-not-present)为对象,发布不同年龄阶段中婚姻状态为有配偶(Spouse-present)的人数统计数据,实验分析文中隐私保护方法的发布精度。图2展示了原始数据与输出的保护数据的直方图发布结果对比。

图2 各年龄段有配偶人数统计结果发布对比图
由图可知,文中提出的隐私保护方法下的数据仍具有较高的可用性,直方图发布具有很高的精度。
3.2 安全风险分析
在安全风险分析过程中,为验证文中方法在安全性方面的优势,假设两种攻击者模型。模型1假设攻击者已经知道了数据集中的准标识符属性数据;模型2则假设攻击者没有任何背景知识。表3展示了这两种攻击者模型下,实验数据集在k-匿名、差分隐私保护和提出的隐私保护方法下被攻击的成功率。
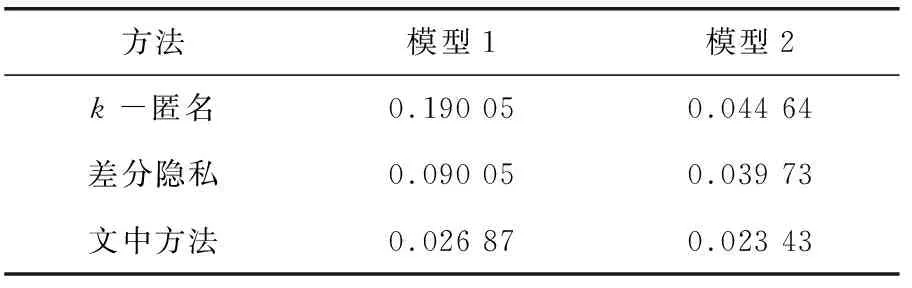
表3 风险评估 %
由实验结果可知,提出的基于差分隐私的数据匿名化隐私保护方法在这两种攻击模型下对数据集的保护强度优于k-匿名、差分隐私保护。
4 结束语
在现有隐私保护技术的基础上设计了一种新的数据匿名化隐私保护方法。该方法结合了拉普拉斯噪声机制与泛化匿名机制。优化后的数据匿名化过程降低了数据信息的丢失率,同时该方法通过将拉普拉斯噪声机制引入到数据匿名化过程中,有效防止了背景知识攻击。实验结果表明,提出的基于差分隐私的数据匿名化隐私保护方法在提高数据安全性的同时,有效保证了数据的可用性。
猜你喜欢
计算机应用(2022年8期)2022-08-24
现代电子技术(2022年11期)2022-06-14
现代职业教育·高职高专(2021年11期)2021-08-27
兰州理工大学学报(2021年3期)2021-07-05
新世纪图书馆(2021年12期)2021-01-19
台湾农业探索(2020年4期)2020-10-29
卷宗(2020年2期)2020-03-23
计算机系统应用(2020年8期)2020-03-22
台湾农业探索(2019年5期)2019-09-10
爱你·心灵读本(2018年6期)2018-09-10
