
基于深度神经网络的行人及骑车人联合检测∗
2018-07-24 06:20陈文强李克强李晓飞张德兆
汽车工程 2018年6期
陈文强,熊 辉,李克强,李晓飞,张德兆
(1.清华大学,汽车安全与节能国家重点实验室,北京 100084; 2.北京智行者科技有限公司,北京 100085)
前言
正面碰撞预警或自动紧急制动等驾驶辅助系统的研究开发中,行人和骑车人等易受伤害道路使用者的保护是系统的首要任务,对行人及骑车人的有效识别是保护他们的基础。
虽然基于视觉的行人识别已经过多年的研究,但实际道路环境中由行人姿态、光照、遮挡和尺度变化等带来的挑战问题还依然存在[1-2]。相对于行人识别,关于骑车人识别的研究很少,其面临的挑战也更多[3]:包括自行车类型和骑车人衣着式样的繁多导致目标较大的外表变化;骑车人的姿态变化导致目标整体外形的姿态变化和不同的观察角度导致目标高宽比的变化等。
传统的行人或骑车人识别方法一般将两者分开处理[4-6],这会导致两类目标识别结果混淆不清,如将骑车人识别为行人,或将行人识别为骑车人。这是因为行人和骑车人的主体都是人,某些角度具有相似的外观特性。单独训练的行人或骑车人识别模型包括人工神经网络(artificial neural network,ANN)、支持向量机(support vector machine, SVM),及AdaBoost等传统机器学习的方法[7-8]和以卷积神经网络R-CNN,Fast R-CNN(FRCN)为代表的深度学习方法[9-10]。这些网络无法有效学习两者的类间差异,导致行人及骑车人目标的错误分类现象时常出现。
上述目标识别方法的模型分辨能力有限,难以有效地解决行人和骑车人识别面临的个体识别精度有限和两者区分能力不足的问题,因此需要研究一种模型分辨能力更强的深度学习网络,来解决行人和骑车人的目标识别问题。故本文中在已有研究[11]的基础上,设计了难例提取、多层特征融合和多目标候选区域输入等多种深度神经网络优化方案,提出基于深度神经网络的行人和骑车人联合检测方法,在已公开行人和骑车人数据库[5]上进行的对比试验说明该方法能有效识别并清楚地区分行人和骑车人目标。
1 方法概述
为克服现有深度学习方法用于行人和骑车人检测的缺陷,聚焦行人和骑车人目标误检漏检频繁、小尺寸目标检测效果不佳和背景环境复杂多变等诸多挑战性问题,本文中提出适用于行人及骑车人联合检测的深度神经网络方法,该方法的框架结构设计可分为3部分:考虑难例提取的网络结构设计、考虑多层特征融合的网络结构设计和候选区域选择的网络结构设计。其中,考虑难例提取的网络结构设计部分用于优化模型训练过程,提高模型的分辨能力;考虑多层特征融合的网络结构设计部分用于融合不同卷积层的特征,提高小尺寸目标检测的精度;候选区域选择的网络结构设计部分在文献[10]的基础上结合候选区域选择网络(region proposal network,RPN)生成候选区域(rois),进一步提高后续目标检测的效果。本文中提出的方法的网络结构如图1所示。其中,conv1~conv5分别代表第1至第5层卷积层,fc6和fc7分别代表第6和第7层全连接层,cls和reg分别表示类别和回归输出,rois表示输出的候选区域,loss表示损失函数。

图1 提出的行人及骑车人联合检测方法的网络结构图
首先利用文献[11]的基于上半身的多候选区域选择方法UB-MPR(upper body-based multiple proposal regions)从输入图像提取一组目标候选区域,然后通过计算RPN提取另一组目标候选区域,最后将这两组目标候选区域经过包含难例提取层的Fast R-CNN的分类与优化定位,即可实现目标的联合检测。其中,后两个步骤实现了卷积层网络参数的共享,只须计算一次深度神经网络的卷积特征图,即可同时保证行人和骑车人联合检测的精度和效率。
2 行人与骑车人联合检测的网络结构设计
2.1 考虑难例提取的网络结构设计
经典的Fast R-CNN方法使用成批的样本进行训练,其正样本(即待检测的目标类别样本)要求与真实目标重叠率不低于50%,负样本(即待检测的非目标类别样本)的重叠率要求在10%~50%之间。有研究证明,在相同数目的训练样本设置下,上述方法选择的负样本确实比随机选取的效果好[12]。但对于那些与真实目标重叠率小于10%的复杂背景目标,就无法使用这种负样本的选择方法,这对于具有复杂背景的行人和骑车人目标,其训练模型将会出现大量的误检测。
为解决上述问题,模型训练中常用的手段就是选取负样本中难以区分的样本加入到训练集中,而非随机选取负样本,这个过程一般称为难例提取。针对Fast R-CNN目标检测方法中难例提取的问题,文献[12]中提出了在线的难例提取方法,该方法在每批训练图像包含的很多样本中提取难例,而非简单的随机选择训练样本,被选择的难例立即用于本次迭代的网络训练。
该方法可在增加少许训练时间的前提下,取得比传统Fast R-CNN更好的效果。借鉴该方法的思路,本文中也针对Fast R-CNN目标检测方法设计了相应的难例提取方法。本文中使用一个原始的全连接层与输出层取代了文献[12]中设计的两个共享的全连接层和输出层。虽然提出的方法训练过程耗时有所增加,但保证了模型的直观与简练,方便与后续其他改进方法相结合。提出的考虑难例提取的用于训练过程的网络结构图如图2所示。
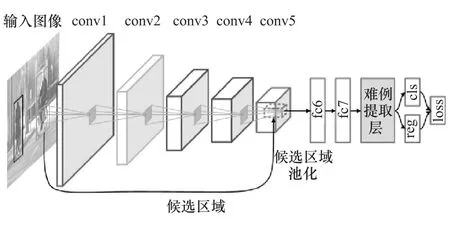
图2 考虑难例提取的训练网络结构图
与原始Fast R-CNN网络结构相比,该网络仅在计算损失函数前增加了难例提取层。图3为与难例提取层相关的网络示意图,设计的难例提取层的输入包括3部分:样本分类分数、真实的标签和包围框回归的外层权重,简称外参。其中,样本分类分数是深度网络fc7对样本的分类输出结果,而后两者是网络的输入;而输出为难例提取层修正后的样本标签与包围框回归的外层权重。
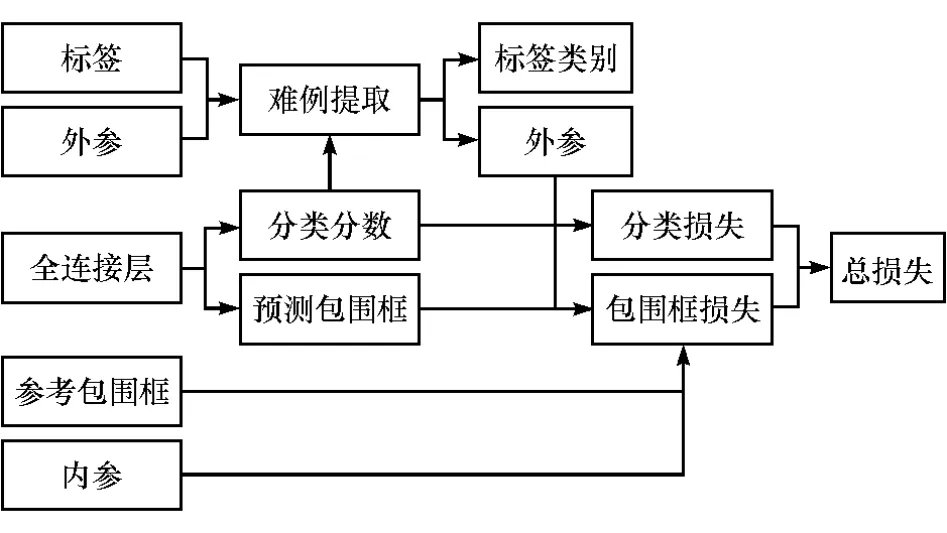
图3 与难例提取层相关的网络连接图
上述难例提取层在进行难例提取的批训练时,首先在每批训练样本中随机选取大量样本(至多2 000个)输入到网络中,再由难例提取层提取10%的样本(至多200个)作为难例计算网络损失函数,进而实现网络参数的修正。在选取难例时,至多选取三分之一的正样本,其余再根据样本分值选择最难区分的负样本。未被选取的样本标签设置为-1,包围框回归的外层权重设置为0,这保证了这些被忽略的样本不会参与分类损失函数和包围框回归损失函数的计算。其中,分类损失函数为

其中,SL1(x)定义为

而包围框回归损失函数为

式中:Wt和Wt+1分别为t和t+1时刻的网络权重;Vt和Vt+1分别为t和t+1时刻网络权重更新量;ΔWt为t时刻得到后向传播权重梯度;μ为t时刻网络权重更新量的惯性系数;α为学习率。由上式可知,当训练考虑难例提取的网络时,因后向传播的权重梯度缩小10倍,故须适当提高学习率α以得到合适的训练效果。
2.2 考虑多层特征融合的网络结构设计
针对PASCAL VOC数据库设计的Fast R-CNN方法及VGG和ZF,不直接适用于目标尺寸普遍较小的行人及骑车人检测的问题,本节介绍融合多层特征的网络结构设计方法。
借鉴文献[13]中融合多层特征的方法,本文中提出的多层特征融合方法主要融合第3与第5层的卷积特征图输出(conv-ml1),网络结构图如图4所示。融合两层而非3层或4层特征图的主要原因是本文中输入的原始图像尺寸太大,GPU内存占用情况严重。另外,相邻特征图的相关性较大,融合后对性能提升效果并不明显,故选用不相邻的两层特征
式中:N为每批训练样本中输入到网络中的样本个数,文中设为 2 000;lcls(pi,ui)为对数损失函数,lcls(p,u)=-log(pu);α和β分别为包围框回归的外层和内层权重;ti和vi分别为包围框回归偏移量和对应真实包围框回归量。由上式可知,在计算每批训练样本的损失函数时仅考虑提取的难例,而忽略未被选择的样本。由于N代表的是每批训练样本中输入到网络中的样本个数,而有效的难例个数为N/10,故相对难例样本的损失函数,由式(1)和式(2)计算的损失函数均缩小10倍。同样,在后向传播梯度计算时,也仅对提取的难例有影响,且梯度的大小也相应地缩小10倍。随机梯度下降的后向传播权重更新计算公式为图进行融合。
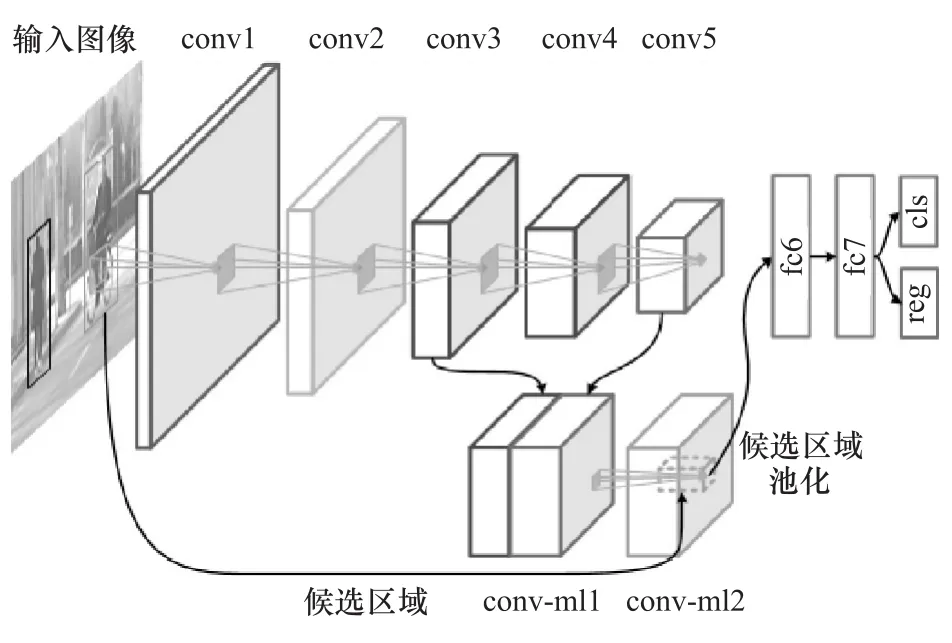
图4 考虑多层特征融合的网络结构图
对于VGG16网络,假设网络输入图像大小为224×224,第3层卷积层(conv3-3)的特征图大小为56×56,而第5层卷积层(conv5-3)的特征图大小为14×14。为了让不同大小的两个特征图结合,权衡考虑网络规模与特征信息量大小,可将第3层卷积层降采样到28×28,将第5层卷积层上采样到28×28,接着即可实现不同特征图的融合(conv-ml2)。第3层卷积层降采样的方法使用最大池化层来实现。最大池化层可用=down()来表示,即第l+1层中的值使用第l层中对应区域的最大值来填充,从而实现了降采样操作。这里的最大池化层卷积核大小为2,移动步长也是2。设计的第5层卷积层上采样使用直接上采样方法。特征图直接上采样的操作可用=up()来表示,即第l+1层中xj的值直接使用第l层中对应位置的值来填充,从而实现了上采样操作。该方法完全保留了原来特征图的值,操作简单且没有需要学习的参数。
考虑到不同深度卷积层的激活值幅值不尽一致,直接将不同层上采样或降维的特征图连接到一起可能会造成某些信息被抑制或被增强。使用局部响应归一化操作平滑不同特征图间的激活值。表示某一原始特征图上的激活值,则归一化后的激活值为
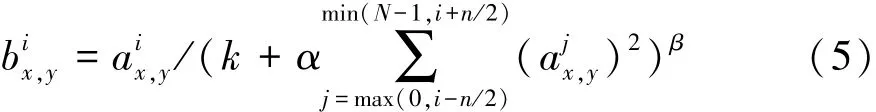
2.3 候选区域选择网络的设计
针对行人和骑车人目标检测的候选区域选择网络,如图5所示。图中的RPN用于提取卷积特征图的卷积层和池化层与Fast R-CNN中使用的网络一致,这有助于在后续的训练和检测过程中共享两种网络的计算结果。
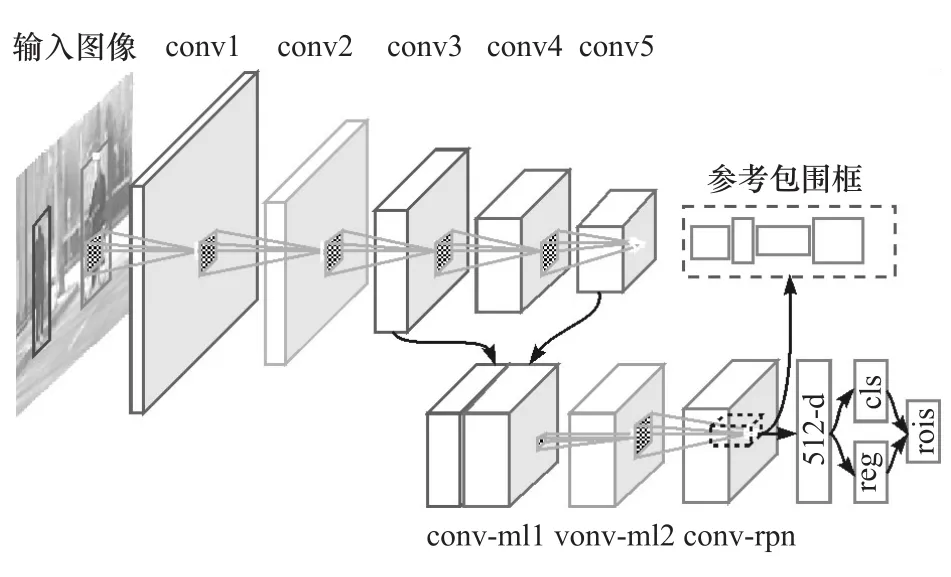
图5 设计的候选区域选择网络结构图
文献[10]中针对PASCAL VOC数据集中的检测目标,设计了3个不同的高宽比和3个不同的尺度大小,考虑行人和骑车人目标的特点,本文中设计了包含3个高宽比和5个尺度大小的参考包围框:3个高宽比分别为1∶1,2∶1和3∶1,5个尺度大小分别为32×32,64×64,128×128,256×256 和 512×512。根据上述设定的参考包围框参数,特征图中的每个位置可生成15个参考包围框。
VGG网络包含5组卷积层和池化层,RPN遍历的最后一层卷积层降采样幅度为16,在特征图上的遍历对应输入图像中的最小步长为16像素。稀疏的遍历步长导致RPN生成的目标候选区域对行人和骑车人真实目标的覆盖不够理想,因为尺度较小的目标可能出现在两个参考包围框中心之间。上节介绍的考虑多层特征融合的网络结构可生成结合第3层和第5层卷积层的卷积特征图,该特征图综合了不同深度卷积层的优点,降采样幅度为8,对应遍历的最小步长为8像素,适合行人和骑车人候选区域的提取。因此,本文中设计的行人及骑车人候选区域选择网络采用上节提出的考虑多层特征融合的卷积神经网络结构。当输入图像尺寸为1024×2048时,本网络生成的卷积特征图大小为128×256,特征图中的每个位置对应15个参考包围框,因此RPN总共可遍历491 520个目标候选区域。
在设计好RPN网络结构后,需要分配每个目标候选区域的类别后才能训练网络。对于近50万个由参考包围框生成的目标候选区域,需要根据它们与真实目标的重叠情况分为正样本、负样本和忽略的样本,其中正、负样本分别代表该样本为目标还是背景。在两种情况下,可将某个目标候选区域归为正样本:与任意一个真实目标重叠率超过0.7;与某个真实目标重叠率最大的候选区域。一般情况下第1个条件即可获得足够的正样本,第2个条件用来避免一些特殊情况下获取不了正样本。将与任意一个真实目标重叠率都不超过0.3的目标候选区域归为负样本。其他不满足正样本和负样本条件的目标候选区域归为忽略的样本,在网络训练时不予考虑。
在分配好样本类别后,设定支持多任务的损失函数。候选区域训练网络包含两个共生的输出层,一个代表该样本为正样本的估计概率pi;另一个代表该样本对应的包围框回归偏移量ti。第i个真实目标的类别记为(正样本为1,负样本为0),真实包围框偏移量记为对应 x,y,w,h 4 个参数)。 其多任务损失函数可定义为

式中:lcls(·)为分类损失函数,见式(1)定义;lreg(·)为包围框回归损失函数(smooth L1),见式(2)定义;λ为调节分类损失函数与定位损失函数的权重;Ncls和Nloc分别为批训练和所有目标候选区域的规模。
为避免不同样本来自不同的图像会造成图像卷积特征图的重复计算,本文中仅从一幅图中随机选取256个样本进行网络批训练,仅计算一幅图的卷积特征图,实现不同样本的卷积特征图共享。每批样本中正负样本的比例原则上保持1∶1,若正样本数量不够128个,则用更多负样本补充。
3 网络训练
为验证上述针对行人及骑车人检测设计的网络结构合理性,除了 VGG8,VGG11,VGG16和ZF 4种基础的网络外,本文中还训练了大量的网络模型,如图6所示。图中相互连接的上下层网络模型表示上层的网络模型是在下层的网络模型基础上训练的。每个网络的后缀代表不同的含义:bl代表基础网络,不考虑任何改进方法,仅修改了输出层以适应行人和骑车人的检测;hm表示考虑难例提取的网络;ml表示考虑多层特征融合的网络;ml-hm表示同时考虑多层特征融合和难例提取的网络;faster表示Faster R-CNN;final表示最终得到的综合考虑多种改进方法的总体网络。

图6 训练网络的流程、关系及主要参数
在训练VGG8-faster时,第1阶段和第2阶段的RPN网络均训练4万次(iter),基础学习率(lr)为0.001,在训练3万次后缩小至0.000 1;第1阶段和第2阶段的Fast R-CNN网络均训练两万次,基础学习率为0.001,在训练1.5万次后缩小至0.000 1。在训练 VGG8-final和 VGG16-final时,第1阶段的RPN网络训练4万次,基础学习率为0.001,在训练3万次后缩小至0.000 1;第2阶段的RPN网络训练2万次,基础学习率为0.001,在训练1.5万次后缩小至0.000 1;第1阶段和第2阶段的Fast R-CNN网络均训练2万次,训练Fast R-CNN时使用了难例提取的方法,学习率都固定为0.001。
上述网络均在公开的VRU(vulnerable road users)数据库训练集上训练得到,更多数据库细节参见文献[5]。
由于不完全标记训练集上有很多行人和骑车人目标没有标记出来,大量的负样本不能在该训练集上提取。因此,在训练上述Fast R-CNN网络模型时,要求每批训练样本来自两张图像,其中第1张图像来自不完全标记训练集,第2张图像来自完全标记训练集。在第1张图像上选取至多16个正样本和16个负样本,不足的样本由第2张图像补充,其中正样本要求与真实目标重叠率不低于50%,负样本的重叠率要求在30%~50%之间。当训练不考虑难例提取的网络时,每批训练样本包含128个样本,除去第1张图像上的32个样本,第2张图像要提取32个正样本和64个负样本,其中正样本要求与真实目标重叠率不低于50%,负样本的重叠率要低于50%,但负样本优先在10%~50%之间选择。当训练考虑难例提取的网络时,每批训练样本中需选取至多2 000个样本输入到网络中,再由难例提取层提取10%的样本(至多200个)作为难例,去计算网络损失函数,进而实现网络参数的修正。同样,除去第1张图像上的32个样本,其余样本均从第2张图像上随机选取。在训练RPN网络时,每批训练样本仅从一幅图中随机选取256个样本进行网络的批训练,每批样本中正负样本的比例为1∶1,若正样本数量不够128个,则用更多的负样本补充。需要说明的是,在上述训练过程及后续的测试过程中,输入图像的尺寸均为原始图像尺寸1024×2048。
4 试验结果分析
4.1 试验结果
本文中使用精度 召回率曲线和平均精度[1]在VRU数据库验证集上,对比评价本文中提出的适用于行人及骑车人检测的深度神经网络模型。为直观地对比各网络模型在验证集上的检测结果与平均检测时间,将图6中训练得到的所有网络模型的结果汇总到表1中。在统计检测结果时,行人和骑车人的检测结果分别在不同难度等级的验证集下评测,并忽略干扰类别的影响。
为更清晰直观地比较本文涉及到的几个主要网络模型在中等难度等级验证集上的检测结果,使用PR曲线,见图7和图8,图中每个方法名称前的数字表示该方法的平均精度。
4.2 结果分析
由试验结果可知,考虑多种改进方法的总体网络模型的性能优于表1中第一大列(-bl)的基准网络模型。
表1的VGG8改进模型中,VGG8-final在不同难度等级验证集上行人检测的平均精度略高于VGG8-ml-hm,而骑车人检测的平均精度基本持平;但VGG8-final相对于VGG8-faster的优势明显,在不同难度等级上行人检测的平均精度分别高出2.4%,2.2%和4.7%,骑车人检测的平均精度分别高出0.2%,4.8%和 5.8%。另外,VGG16-final明显比VGG16-ml-hm更好,在不同难度等级上行人检测的平均精度分别高出1.7%,4.1%和6.6%,骑车人检测的基本持平。

表1 验证集上各网络结构的检测效果汇总
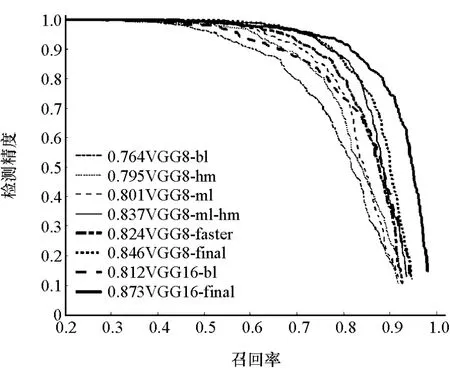
图7 中等难度等级的验证集上行人检测的效果

图8 中等难度等级的验证集上骑车人检测的效果
VGG8-final的检测效果大幅度领先于基础网络模型VGG8-bl,在不同难度等级验证集上行人检测的平均精度分别高出7.4%,8.2%和9.7%,骑车人的平均精度分别高出 1.3%,5.2%和 6.9%。VGG16-final的检测效果比基础网络VGG-16-bl显著提升,特别是行人检测效果,在不同难度等级验证集上行人检测的平均精度分别高出3.9%,6.1%和6.1%,骑车人检测的分别高出 0.1%,0.7%和4.0%,平均精度已经接近饱和,进一步证明了本文中针对行人及骑车人检测提出的网络模型的有效性。而综合考虑多种改进方法的总体网络模型VGG16-final的检测效果明显优于VGG8-final,不同难度等级验证集上行人检测的平均精度分别高出1.5%,2.7%和4.3%,骑车人检测的平均精度分别高出0.2%,1.5%和5.6%。这说明较深的网络深度有助于提高最终目标检测的效果。
5 结论
针对现有深度学习方法用于行人和骑车人检测的缺陷,即目标误检漏检频繁、小尺寸目标检测效果不佳和背景环境复杂多变等挑战性问题,本文中基于FRCN目标检测框架,设计了综合难例提取、多层特征融合和多目标候选区域输入等多种改进方法的网络结构模型,大幅度改善了行人及骑车人目标的检测效果。结论如下:
(1)在网络训练过程中,采用提出的难例提取方法代替随机抽样来选取负样本,能有效改善行人和骑车人目标检测的效果,减少因行驶道路环境复杂导致的行人和骑车人目标误检;
(2)融合不同深度的卷积特征图可综合局部与全局特性,获得表达能力更强的特征信息,显著提升行人和骑车人目标检测效果,对于小尺寸的行人及骑车人目标,效果更为明显;
(3)结合多种目标候选区域方法的输入可弥补单一目标候选区域选择方法的缺陷,实现UB-MPR和RPN方法的优势互补,能进一步改善行人和骑车人目标检测效果,有助于减少行人和骑车人目标的漏检。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
意林(2021年5期)2021-04-18
汽车技术(2020年11期)2020-11-27
电子制作(2019年11期)2019-07-04
新传奇(2019年51期)2019-05-13
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
发明与创新·大科技(2017年5期)2017-05-16
