
模型地质信息提取及在不同网格系统间的转换
2018-07-23 07:13:04叶小明
西安石油大学学报(自然科学版) 2018年4期
叶小明
(中海石油(中国)有限公司 天津分公司,天津 300459)
引 言
目前三维空间建模技术都是基于特定的网格剖分方法,根据所要描述的具体对象,用足够小的多个网格单元来逼近对象的体积和边界轮廓。理论上只要网格单元足够小,对目标对象的描述就能达到完美[1-2]。然而由于计算机的性能及容量的限制,网格不可能无限小,地质模型往往需要进行粗化后才能开展油藏数值模拟研究,因此,很多目标对象的细小特征就不得不丢失掉[3-5]。而大量油田开发实践表明,储层内部发育的各类较小规模的隔夹层对于油藏内部的流体运动具有重要的影响,目前国内外学者针对如何在地质模型中对各类小尺度地质体进行建模开展了大量研究,但针对如何将其与油藏数值模拟结合的研究却相对较少[6-8]。如何在不影响数值模拟运算效率的同时,将更多精细的地质认识表征到模型中去是当前研究的难点,也是开发中后期油田精细地质建模和油藏数值模拟研究中亟待解决的问题。
本文通过三维空间地质信息提取及其在不同网格系统的转换方法研究,从地质模型中提取小尺度的地质现象,并根据数值模拟技术规范输出对数值模拟历史拟合具有约束指导意义的描述性控制文件和数据,在不增加网格规模的条件下提供油藏数值模拟更加精细完整的地质模型参数,从而提高油藏数值模拟运算速度和精度。
1 研究思路
在微观多孔介质渗流力学所建立的数学模型中,油藏数值模拟中网格单元的传导率决定了网格之间流体是否流动。在数值模拟软件中传导率的定义是指网格与网格之间界面的流动性。可以用网格界面传导率乘数来等效描述复杂的小尺度地质现象所引起的砂体内部连通性变化,从而在地质模型粗化到油藏模型过程中保留更多精细的地质认识。
根据渗流特征,把复杂或小尺度地质信息进行简化和等效,这种等效简化不是在地质模型里而是在油藏数值模拟模型中进行的,通过采用符合数值模拟数据规范的描述方法将复杂或小尺度地质信息反映在数值模拟的数据卡片中。这需要以下两步工作来完成:
(1)复杂或小尺度地质信息的简化和等效
井间存在砂体叠置界面所导致连通性变差的状况可视为在这两个砂体叠置的边界间沿着横向接触的网格和垂直方向的网格之间传导率很小或者为零,也就是把砂体叠置这种复杂的地质现象简化为如何定义相关网格的传导率乘数的问题。
(2)基于油藏数值模拟网格系统提取等效边界
由于前述复杂的地质问题被简化为油藏模拟网格系统的传导率乘数问题,所以在判断和提取边界信息时应该直接在粗化后的数值模拟网格系统进行。通过采用三维空间数据统计及匹配技术,在地质模型中识别出不同砂体的地质边界,将这些边界信息转换为空间三维曲面,在粗化后的油藏模型三维空间计算穿过边界的网格,从而根据数值模拟要求的数据规范产生传导率乘数数据。
2 技术流程
2.1 三维模型地质信息提取
通过采用低通滤波算法,结合井点解释数据对三维地质模型中的复杂或小尺度地质信息(比如沉积微相数据)进行平滑,在此基础上追踪成因单元(各个微相)界面的空间位置,形成构型界面的三维空间离散数据。通过基于井点约束的空间离散点曲面拟合对构型界面进行曲面重构,建立描述各复杂或小尺度地质信息三维空间几何形态的包络面。
(1)三维空间离散属性模型的数据平滑
地质网格数据来自于其他算法的处理结果或者基于实际探测后对实际地质分布的模拟,算法误差或者机械误差等因素必然会产生不符合实际情况或者符合实际情况但对算法本身而言意义不大的网格,即噪音网格或者高频网格。因此,在执行其他步骤前需要消除这些噪音网格。本次研究采用低通滤波器来消除噪音网格。
本算法的基本原理为,定义一个N×N×N的窗口以及一个阈值,N通常小于等于9且为奇数。该窗口从需要进行平滑处理的数据集空间范围的左上角开始,依次按照X、Y、Z方向逐格移动。每次移动完毕后,以窗口的中心为平滑对象,并统计窗口内网格的某项指定属性值。如果目标网格所属的属性值集合占全窗口属性值之和的比例超过指定的阈值,则保留该网格,否则该目标网格被视为噪音网格,将被标记,在全部遍历后,统一清除所有的噪音网格。
(2)基于井点属性约束的网格重建
地质网格数据有可能来自于其他算法的处理结果,但其空间范围并未包含井轨迹的位置,因此,需要通过修改网格的空间范围使其包含井点信息,以便真实反映地质的实际情况。井点属性约束算法根据井点空间位置,通过重建地质网格,使空间网格能覆盖所有的井点,使地质网格数据能正确反映地质状态,为后续算法提供更为准确的地质网格数据。
本算法的基本思路为,遍历每个井轨迹数据,对于每个井点的空间坐标,判断是否有地质网格包含该井点,如果有,则说明网格已正确反映井点位置,否则需要找到离该井点最近的地质网格,并选择距离该点最近的面,通过移动该面,使该网格能包含井点。本算法需要注意的是,在寻找最近面时,距离不能成为唯一的依据,否则会产生对面倒置的情况。
(3)三维空间离散网格数据的空间包络面生成
包络面生成算法是在指定的层将具有相同属性以及相同属性值的网格找出,并判断哪些是完全包含在内部的网格,哪些是最表面的网格,最表面的网格就是该层的包络面。包络面生成算法是锯齿化算法的基础,最终将利用包络面与网格求交,得到网格锯齿。
本算法基本原理为,分别按照地质网格是否左右相接、前后相接和上下相接3种情况去遍历地质网格,如果不相接,则表示该网格面是包络面,并标识。地质网格的遍历是按照Z、Y和X方向依次进行。因为实际地质模型数据中,有存在多个包络面群的可能,因此,需要将包络面群进行标识编号。该过程的核心在于如何遍历,基本思路为:按照Z、Y和X方向依次遍历包络面,对于每一个包络面,按照6个方向去判断相接网格是否同样是包络面网格。如果不是,需要中断该方向的遍历,并回退到上一步,开始从另外一个方向遍历;如果是,则从新的网格开始从6个方向判断。该步骤采用递归算法进行。
2.2 不同网格系统转换
将重建的复杂或小尺度地质信息包络面与粗化网格进行空间几何交切计算,得到网格模型中的空间位置,并将空间位置信息以网格界面传导率乘数的格式输出给油藏数值模拟器,实现复杂或小尺度地质信息在任意网格尺度油藏模型中的定量表征。
(1)三维空间任意包络面的网格锯齿化
三维空间任意包络面的网格锯齿化是将已经得到的包络面与新的网格数据相切,与包络面相切的面构建成新的包络面。网格锯齿化算法原理较为简单,即遍历每个包络面,求与当前包络面相交的地质网格面,并将该面标识为锯齿面。当地质网格出现锯齿面不连通的情况时,需要根据切割后形成的面与2个对面分别形成的体求体积,参与构建体积较小的体的对面将成为锯齿面,以保证该网格的锯齿面的连通性。
如图1所示,为一个X、Y和Z这3个方向均为5 m的网格,A和B是两个对面,C是包络面。假设包络面和网格除了A和B外,与其他4个面都相交,此时需要让A或者B成为锯齿面。在这个示意图中,由于A和C构成的新的体的体积小于C和B构成的体的体积,因此,A将成为锯齿面。

图1 连通面判定示意图Fig.1 Schematic diagram for determination of connected surface
(2)网格界面传导率乘数数据卡输出
完成三维空间任意包络面的网格锯齿化后,便将从地质模型中提取出来的地质信息转化到粗化后的油藏模型中。将该锯齿化后的网格界面以网格界面传导率乘数数据卡的形式输出,即可用来等效描述各类复杂的小尺度地质现象引起的砂体内部连通性变化。
传导率乘数数据卡中即包含了地质界面在粗化模型中的位置,同时在卡片中对初始传导率乘数进行了定义,传导率乘数具体数值需要在数值模拟过程中根据注采井组的注采动态通过井组之间的历史拟合分析确定。图2所示即为在某油田B1井区P3层提取的传导率乘数数据卡示意图,第2列为软件设置的初始传导率乘数(值为0.000 1),后面6列为地质界面两侧网格的坐标。利用该传导率乘数数据卡就实现了在油藏数值模拟过程中复杂或小尺度地质信息的等效表征,通过对传导率乘数具体数值的设置便可将其对流体渗流的影响表征到模型中。

图2 传导率乘数数据卡示意图Fig.2 Schematic diagram of conductivity factor data card
3 应用实例
3.1 研究区概况
Q油田位于渤海中部海域,主要含油目的层为新近系明化镇组下段曲流河沉积。油田为边底水油藏合采,油水关系非常复杂、层间矛盾突出,目前已进入综合调整开发阶段,对储层研究的精细程度要求也越来越高。
该油田针对曲流河点坝砂体开展了精细构型研究,在点坝砂体内部识别出一系列侧积层及侧积体。岩心观察表明:本区常见的侧积层岩性有含粉砂泥岩、粉砂岩及泥质粉砂岩,大部分侧积层厚0.2~0.3 m,最厚的达1 m。侧积层水平间距70~200 m,大部分在80 m左右。由于油田范围较大,前期建立的精细地质模型需要经过粗化后才能开展油藏数值模拟,但模型粗化后,这种小尺度的侧积层便无法体现到油藏模型中,对流体渗流的影响便无法进行定量表征。图3(a)为该油田B20井的初始含水率与实际生产含水率曲线,采用常规修改物性参数的方法来进行历史拟合,从拟合结果(图3(b))可以看出,基于粗化后的模型开展历史拟合,由于损失了一些小尺度的地质信息,使得历史拟合精度大幅降低。
3.2 应用效果
基于以上流程,通过对各算法进行整合,编制了配套软件,应用到Q油田地质建模及油藏数值模拟过程中。图4为采用该方法等效表征Q油田点坝砂体侧积层示意图,地质模型中侧积层等小尺度的地质信息均被提取出来,并在粗化后的油藏模型中锯齿化,从而实现其在不同网格系统间的转换。首先在前期精细地质模型中提取侧积面(将侧积层用面来代替),然后将该侧积面投放到粗化后的地质模型中进行界面锯齿化,最后提取出侧积面两侧网格间传导率乘数数据卡。该传导率乘数数据卡中即包含了侧积面在粗化模型中的位置,同时在卡片中对初始传导率乘数进行了定义,传导率乘数具体数值需要在数值模拟过程中根据注采井组的注采动态通过井组之间的历史拟合分析来进一步确定。利用该传导率乘数数据卡就实现了在油藏数值模拟过程中侧积夹层的等效表征,通过对传导率乘数具体数值的设置即将其对流体渗流的影响表征到了模型中。采用此方法进行历史拟合后与常规方法进行的历史拟合结果进行对比(图3(c)),B20井经过等效表征方法历史拟合以后历史拟合精度大幅提高,特别是在开发中期,模型含水率与实际生产含水率符合程度得到显著提升。

图3 常规方法与新方法历史拟合结果对比Fig.3 Contrast of history fitting results by using conventional method with new method
基于该方法除了提高历史拟合精度以外,同时也有效提高了井间剩余油分布预测精度。在新打调整井处水淹层测井解释的基础上,进行新老模型在井点处主力砂体水淹层解释符合率的对比,发现新模型比老模型对水淹层解释更加准确(表1)。
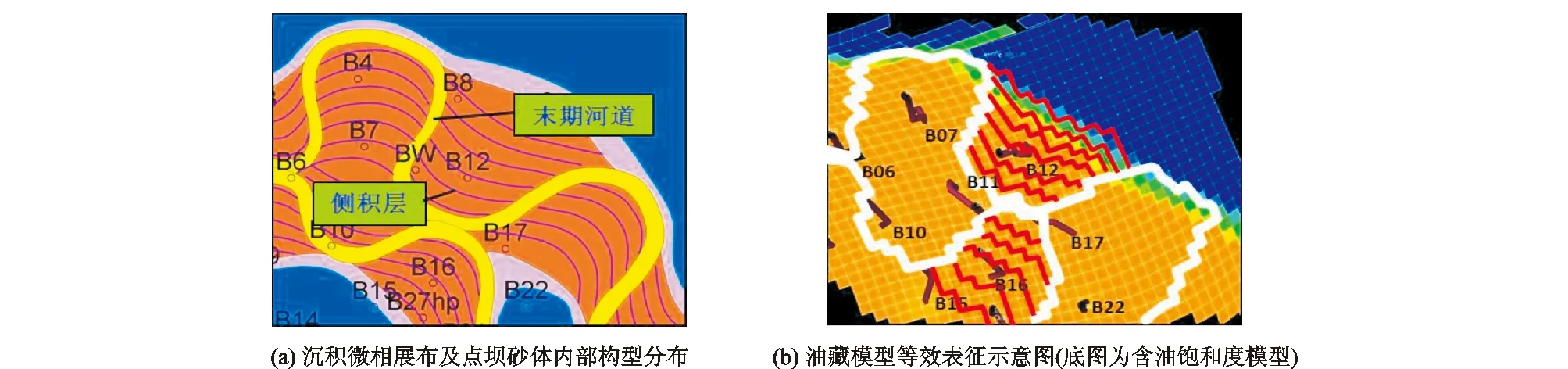
图4 Q油田点坝砂体侧积层等效表征示意图Fig.4 Equivalent characterization of point bar lateral alluvium in Q oilfield

垂顶深/m垂底深/m垂厚/m测井解释结论老模型新模型1 145.921 146.921.0弱水淹层弱水淹层弱水淹层1 146.921 148.421.5中水淹层弱水淹层中水淹层1 148.421 150.822.4强水淹层中水淹层强水淹层
4 结 论
(1)针对地质模型粗化到油藏数值模拟模型中存在的地质信息丢失的问题,提出一种模型地质信息提取及在不同网格系统间的转换新方法。
(2)在渤海Q油田油藏数值模拟模型中,利用该方法等效表征了点坝砂体内部的小尺度侧积夹层,在实际应用中取得了良好效果,同时验证了该方法的可行性。
猜你喜欢
中国人口·资源与环境(2024年3期)2024-05-29 12:00:26
石油化工高等学校学报(2021年1期)2021-04-06 11:47:08
重庆科技学院学报(自然科学版)(2018年5期)2018-11-15 03:24:24
中国港湾建设(2017年11期)2017-12-19 12:27:05
化学工程师(2017年8期)2017-08-28 14:05:11
中国水能及电气化(2016年11期)2016-02-28 11:28:40
石油化工建设(2016年4期)2016-02-27 15:03:18
石家庄铁路职业技术学院学报(2015年3期)2015-11-30 08:41:07
西南石油大学学报(自然科学版)(2015年3期)2015-04-16 05:12:11
城市道桥与防洪(2013年1期)2013-09-28 02:23:50
