
海量地形数据组织与调度策略研究
2018-07-21 02:56:24袁松鹤靳海亮耿文轩
测绘工程 2018年8期
袁松鹤,靳海亮,耿文轩
(河南理工大学,河南 焦作 454000)
随着数字地球的不断发展,全球地形数据的组织与管理受到越来越多的关注。如何构建一个具有高度真实感的地形可视化场景成为一个非常关键的问题。由于受计算机内存容量的限制,系统所能管理的数据量、显示效果的逼真性和交互响应的实时性是评价一个可视化系统是否实用的3个重要指标。面对几百个TB的数据,更甚至PB级的数据,不可能将全部海量数据一次性全部加入内存,此时必须寻求针对于外存的数据组织与存储策略[1]。目前,最常用的是基于外存(Out-of-Core)的方法,当外存中的数据需要绘制时再进行实时的读取。Out-of-Core方法的思想是在1998年Pajarola[2]等提出的,将分块后的地形数据按编码规则进行排序存储在外存中。Vitter[3]在2001年在分块的基础上提出层次设计,大大提高了性能。Lindstrom等[4-5]在前人基础上在外存上建立文件,实现与内存的映射关系,加快数据的调度效率。
本文针对海量地形数据的组织与调度方面的问题,采用规则格网数字高程模型(Digital Elevation Model)构建四叉树多分辨率模型,并提出一种高效的数据检索方式。另外本文在实时绘制阶段,针对与需要绘制的地形数据构建连续LOD模型。为大规模地形数据的绘制提出一种针对于外存的实时绘制方法。
1 基于四叉树的海量地形数据组织方式
1.1 基于四叉树海量地形数据表示
近年来计算机软、硬件等技术有了飞速发展,但要实现地形可视化的数据量过于庞大,无法一次性的对这些地形数据进行处理。由于传统的地形数据组织与调度方式不但占用计算机大量的内存,而且渲染帧率也无法满足视觉需要。本文将采用四叉树结构来管理地形数据,鉴于四叉树组织方式的灵活性,通过四叉树结构来管理地形几何数据,从而构建出多分辨率层次结构。
首先将研究区域地形数据划分为大小相同的m行m列,每个子块边长为2n+1,左上角为第0行第0列,对于最后边和最下边不满足大小相同要求的块,以无效数据填充。根据分块后的地形数据在原始地形中所处的行、列位置进行编号,其编号为i-j,表示处于第i行、第j列的数据。地形分块的数据文件格式如表1所示。

表1 地形块文件格式
将分块后的地形数据以四叉树的数据结构进行组织[6]。一棵四叉树,每2×2个点合成为一个上层点。如图1所示,设第r行的初始分辨率为r0,则第L层的分辨率rL为
rL=r0x2L.
(1)

图1 四叉树分层结构
利用多分辨率金字塔模型对地形数据进行组织管理,在进行地形绘制时,离视点近的区域采用分辨率高的数据进行表示,离视点远的区域采用较低的分辨率进行绘制,从而构建地形数据LOD模型,并且利用四叉树的索引方式进行地形数据的组织管理。如图2、图3所示:第0层的数据为四叉树的根节点,覆盖地形的整个区域,但分辨率最低。从树的根节点往下,每一层所代表的地形范围不变,但地形数据的分辨率逐渐变大,树中的每个节点都对应地形中的一块。四叉树结构一般由一个根结点、若干个非叶结点和叶结点组成,如果某个结点的4个子结点指针不为空,则为非叶结点,否则为叶结点,如果结点的父结点指针为空,则该结点为根结点。
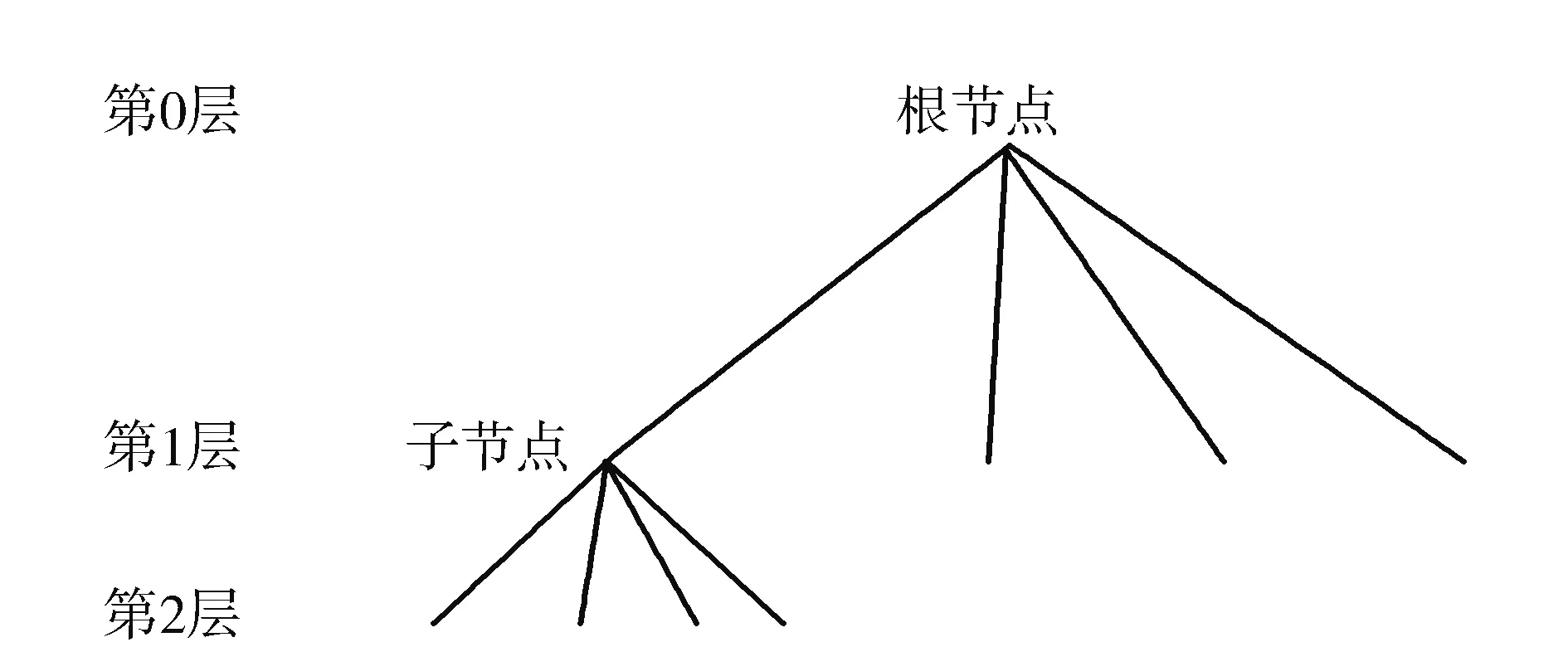
图2 对应的四叉树结构

图3 四叉树分割
1.2 改进的四叉树瓦片索引
在对原始地形数据进行分层操作时,主要工作是对数据的重采样,利用四叉树数据结构来对各层数据进行存储。传统的基于瓦片金字塔模型的四叉树结构对于数据的存储采用分层方式,对于每一层的数据按从左到右的顺序依次编码存储。
根据相应的改进方法,每个节点数据只在树中存储一次,有效地避免存储空间的浪费。构造一种地形块内无数据冗余的外存模型,并进行索引文件的生成。为了避免在新节点插入时进行内存的重新分配内存,首先生成满四叉树结构,这样可以加快节点插入的进度,最后释放掉空的节点所占内存空间[7]。一般根据经验值四叉树的深度4~7之间为最佳。
为了实现对外存中高程点数据的快速查询,故将索引文件常驻内存,而且索引文件所占内存较小,只需构造完整的索引方式,就可实现对外存地形数据的有序查找。本文将地形数据按照逐层从上到下从左到右的方式进行存储。在第0层存储数据点0123,从第0层到第1层新增顶点为45678,故为了减少数据的重复存储,本层只存储新增数据点,同理,第3层也只存储新增数据点,依次实现数据的完整存储。
对存储的数据点进行编号(L-N-i-j),L代表此数据点所在的层号,N代表该顶点在该层新增数据点的序号。i表示此点在该层的横坐标,j表示此点在该层的纵坐标。坐标系的建立选择从左上角开始,从左到右,从上到下,每个数据块左上角起始坐标为(0,0),故该点的索引号为(L-N-0-0)。如图4所示,数据点19的索引号为(2-10-1-3)。根据式(2)、式(3)即可在地形文件中找到所要读取的数据:
offset(n)begin=
(2)
offset(n)end=(3n+1)X(3n+1)-1.
(3)

图4 数据索引结构
2 地形数据的调度
本文采用视点与视线相结合的方式进行LOD的选择,对目标瓦片进行由粗到细、层层推进的策略。对于在视域外的节点的判断和剔出,传统的裁剪算法是解一个方程组[],将与视锥体的6个裁剪面进行比较,这样会消耗大量的处理时间,导致渲染的速度非常慢,本文通过求取视锥与水平面的交面来作为视锥体裁剪面,进行第一次可见性的剔出。通过引入节点包围圆实现两次数据的选取。
2.1 地形节点评价
由于通过视锥体交面获得的地形块根据视觉原理不能采用全分辨率模式进行绘制。必须采用LOD原理对地形模型进行简化。本文通过计算视点、视线与节点的位置关系,建立一个节点评价系统,决定节点是否进行分割[8]。
首先计算地形的静态误差(简化模型与原始模型顶点间的高程差)。为了防止简化过度、简化模型精度不准确等问题,将顶点间的依赖关系考虑在内。由于相邻层间节点误差会出现传递,故在地形模型中父节点间的静态误差(粗糙度)不小于其子节点间的静态误差(粗糙度)。因此选取本身节点与子节点中的最大值作为当前节点误差,如图5所示。
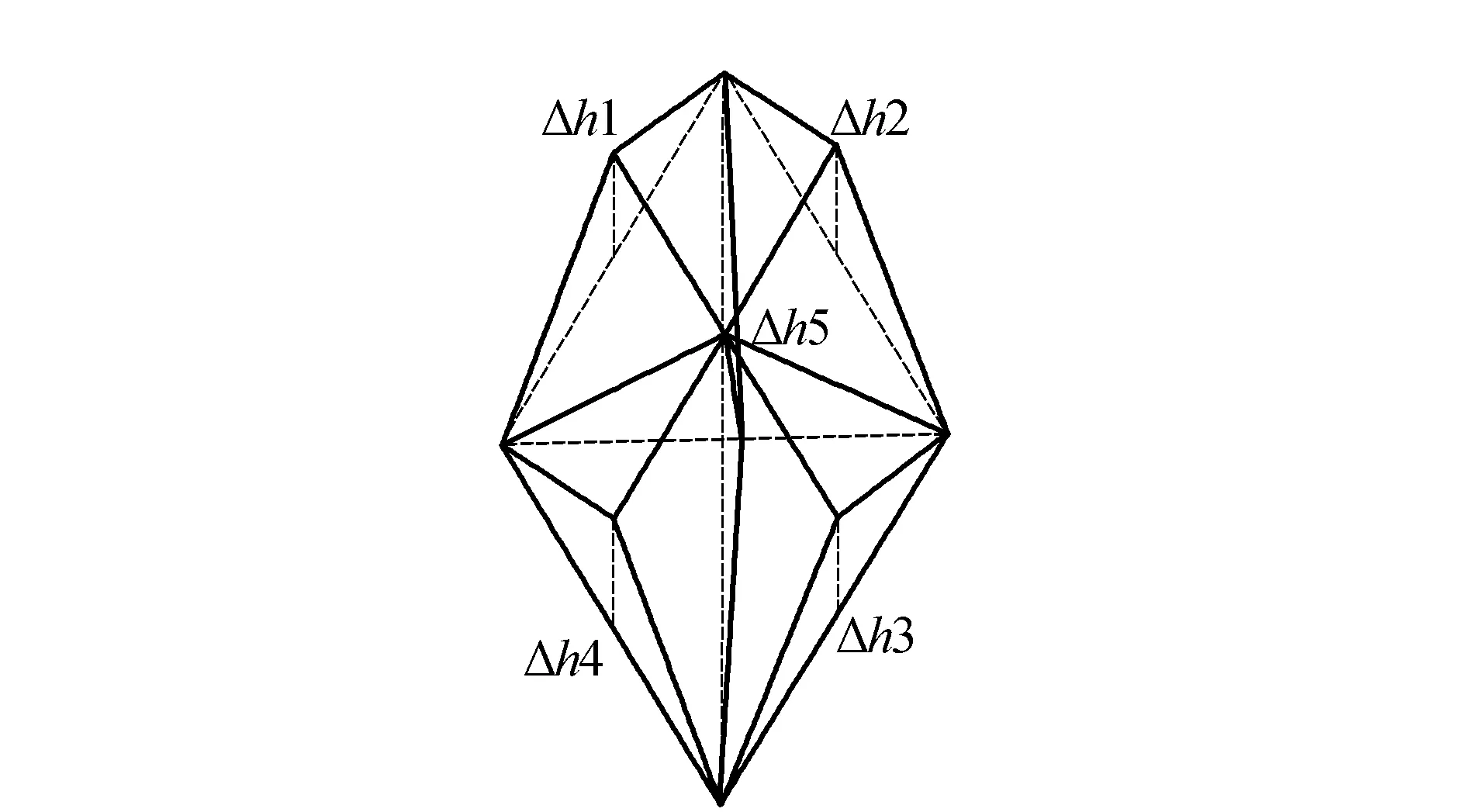
图5 节点静态误差
根据视点到节点的距离,及节点与视线方向位置关系,采用屏幕误差来衡量一个LOD层次。最终的节点评价算式为
(4)
式中:δ为节点静态误差;H为屏幕垂直高度;θ为视点的下视角;α为视点的垂直张角;D为视点到节点的距离;β为视线与视点到节点的方向向量之间的夹角。通过式(4)求取屏幕误差来确定节点的分割情况。
2.2 连续LOD模型动态构建
对于采用视觉原理相关的LOD[9]技术的地形可视化系统,要求不同的区域由不同分辨率的地形数据来表示。根据视锥体裁剪与地形节点评价来构建LOD模型。判断某一时刻与视锥体相交的地形块,分别为地形块2、4构建LOD模型。将屏幕误差与所设置的误差阈值进行比较,判断节点剖分情况。然后对剖分后的子节点,根据节点包围圆的方法判断该子节点是否可见,若可见进行绘制,否则不参与绘制。
判断地形数据是否在可视范围内,以及可视范围内的瓦片是否满足分辨率要求的算法步骤如下:
第1步:判断地形数据是否在视锥体内,如果在,转到第2步;否则,算法结束。
第2步:将节点屏幕误差与误差阈值进行比较,若节点屏幕误差小于误差阈值,将其插入到绘制链表,否则,按照四叉树剖分规则剖分地形块,得到对应的4个子节点,将4个子节点插入到测试链表1。
第3步:判断测试链表1是否为空。如果为空,算法结束;否则,转到第4步。
第4步:利用节点包围圆逐个判断测试链表1中的节点是否在可见区内,如果在,将其插入到测试链表2;否则,将其舍弃。
第5步:将测试链表1进行清空,转到第6步。
第6步:对测试链表2中的瓦片数据进行逐个判断,看是否满足分辨率的要求。如果满足,将其插入到绘制链表;否则,按照四叉树剖分规则剖分地形块,得到对应的4个子节点,将4个子节点插入到测试链表1。
第7步:将测试链表2进行清空,转到第3步。
2.3 基于多线程的数据调度策略
本文利用基于视景体与地形求交的视景体裁切方法来计算地形的可见区,引入数据预取策略,来实现数据的实时动态调度,同时利用多线程技术[10],将绘制线程和数据调度线程并行化处理。此方法有效地提高了所有数据加载完成的时间,便于每一帧的实时绘制。
2.3.1 基于视域扩展的数据预取策略
在根据视觉原理及视点运动预测的前提下,提出如图6所示的地形子块数据预取调度方案。

图6 数据预加载策略
图6中每一个小方格代表地形字块,蓝色线框是可视区域,红色线框是预加载区域,小的三角形是视域区域,大的三角形是视阈扩展。
在第1帧中将地形覆盖区域分为视域、视域扩展、可视区域、调度区域以及预加载区域。视域为根据视觉原理当前用户能够观察到的区域,即视锥范围;将地形分块区域与视域相交的部分当作可视区域,并将可视区域包含的分块集合用集合M表示,这些地形块数据将在构建地形LOD模型时使用;将以R为半径的所涉及的半圆区域作为视域扩展区域,需加载的地形块数据量就由视域扩展区域的大小决定;将地形分块区域与视域扩展相交的部分称作调度区域,并将调度区域包含的分块集合用集合N表示,这些数据将被载入到内存中;假如N和N′分别表示相邻两帧调度区域包含的地形分块集合,则预加载区域就是N′N=M对应的地形分块集合,表示当前帧需要预先加载到内存的地形数据,这些数据是对下一帧的预测,并不需要立即绘制。
2.3.2 多线程的数据调度
为了使数据调度与绘制同时进行,采用多线程[11]来加速调度过程,主线程为每一个需要调度的地形块开启一个子线程。图7是多线程的实现流程。
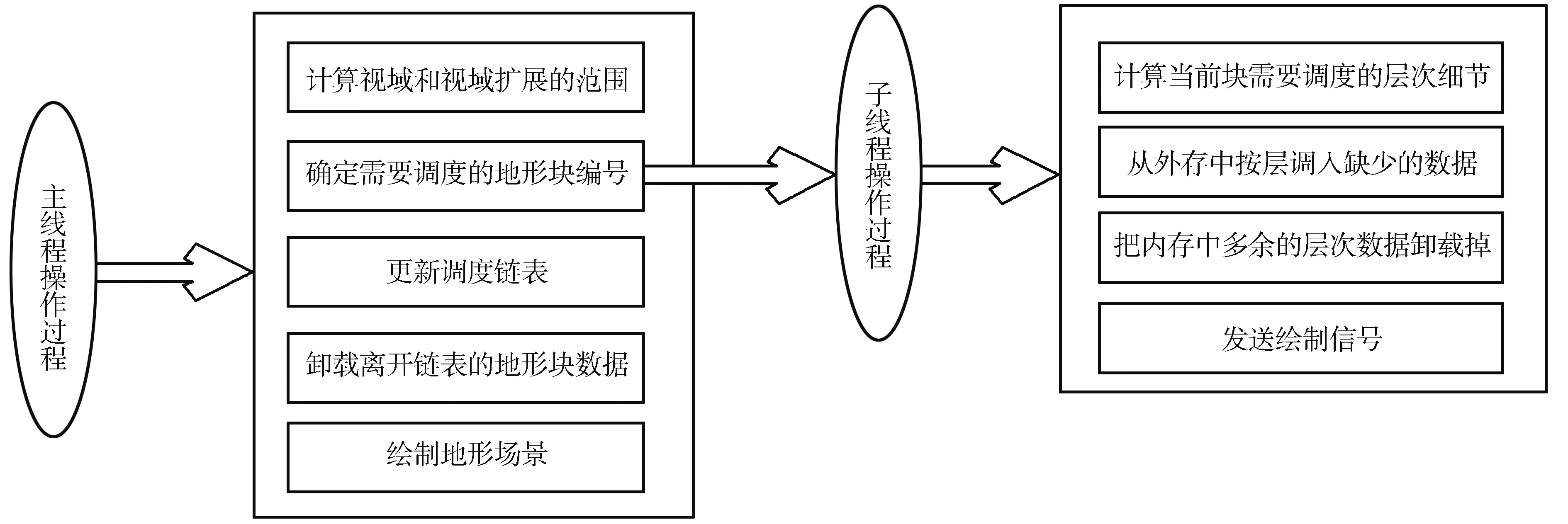
图7 多线程处理机制
3 实验结果分析
为了检测本算法的实用性,将其在PC机上用VC++6.0和OpenGL进行测试,本文所利用的地形数据为在地理空间数据云所下载的DEM数据,实验所使用的硬件设备配置为:Inter(R) Core i5-3340 3.10 GHZ CPU,内存4.0 GB,显卡为Inter(R) HD,操作系统为Windows 7,屏幕分辨率为1 440 pixels×900 pixels。不同数据组织方式效果对比如表2所示。
在预处理阶段,利用四叉树结构对地形高程数据进行分块多分辨率组织,采用本文的数据存储方法,本实验地形的分块大小为1025×1025,并将纹理数据进行分块编号索引处理,处理后的地形线框显示如图8、图9所示。

表2 不同数据组织方式的效果对比列表

图8 线框模式的三维地形图

图9 添加纹理的三维地形图
4 结 论
本文针对海量地形数据无法一次性载入内存进行绘制的问题,采用经典的四叉树方法来进行数据的组织,对于分块的地形数据构建层次分辨率模型,采用无冗余的数据存储方式,降低内存的消耗,减少计算量。在实时处理阶段,引入视阈扩展的数据预取策略,加快数据的调度速度,保证两相邻帧数之间的流畅。
[1] 陈怀友.大规模作战仿真平台可视化关键技术研究[D].哈尔滨:哈尔滨工程大学,2010.
[2] PAJAROLA R. Large scale terrain visualization using the restricted quadtree triangulation[C]. In Visualization '98. Proceedings. 1998.
[3] VITTER J S. External Memory Algorithms and Data Structures: Dealing with Massive Data[J]. ACM Computing Surveys 33(2), 209-271.
[4] LINDSTROM P, PASCUCCI V. Visualization of Large Terrains Made Easy[C]. in Visualization, 2001. VIS '01. Proceedings. 2001.
[5] LINDSTROM P, PASCUCCI V.Terrain Simplification Simplified: A General Framework for View-Dependent Out-of-Core Visualization[C]. IEEE Transaction on Visualization and Computer Graphics, 8(3): 239-254. 2002.
[6] 张启鑫.面向数字海洋应用的全球地形数据组织与可视化技术研究[D].山东青岛:中国海洋大学,2015.
[7] 邱航. 虚拟战场中复杂场景建模与绘制若干关键技术研究[D].成都:电子科技大学,2011.
[8] 吕梦雅.大规模战场地形的实时可视化算法的研究[J].小型微型计算机系统, 2010,31(8): 1578-1581.
[9] 王丽君.大规模战场地形多分辨率建模及实时可视化的研究[D].河北秦皇岛:燕山大学,2009.
[10] 左志权,陈媛.TB级地形数据实时漫游核心算法研究[J]. 中国图像图形学报, 2010,15(9): 1411-1415.
[11] 靳海亮.海量三维地形数据实时绘制技术研究[M].北京:中国矿业大学出版社,2009.
猜你喜欢
山东农业工程学院学报(2020年12期)2020-03-19 01:58:44
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
第二课堂(课外活动版)(2019年12期)2019-02-10 03:59:37
成都信息工程大学学报(2018年1期)2018-05-31 08:40:25
科技创新与应用(2017年35期)2017-12-19 08:33:36
智富时代(2017年6期)2017-07-05 16:37:15
湖州师范学院学报(2016年2期)2016-08-21 13:50:52
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:19
地理与地理信息科学(2015年4期)2015-10-13 08:29:16
建筑材料学报(2015年3期)2015-02-28 02:36:27
