基于改进K均值聚类的银行客户分类算法*
2018-07-20 09:05于化龙韩雪峰
湘潭大学自然科学学报 2018年3期
于化龙, 韩雪峰
(沈阳化工大学 经济与管理学院,辽宁 沈阳 110142)
近年来,金融改革和外资银行的引入在我国加入WTO后对本地银行产生了巨大的影响.不同类型的客户对银行利益的影响是不同的,各个银行的主要竞争点是吸引优质客户.通过合理地区分客户类型,银行能够更加理性地配置管理资源,服务大众,用较少的投入博取更多的利益,此时,银行客户细分就显得尤为重要[1].客户细分,即指银行在固定的市场条件下,制定合理的战略并开展相应的业务,根据客户的行为、偏好以及对银行的价值等对客户实施精确的分类[2].常用的客户细分方法包括基于经验和基于统计的分类方法.其中,经验法具有较强的主观性,通常是由决策者按照自己对客户的了解进行分类,说服力不够[3];统计法则是在分析了客户的属性后,得出分类结果的方法,当参照不同的属性时,分类结果也不尽相同[4-5].随着人工智能技术以及数据挖掘技术的发展,人们逐渐将智能算法,比如K均值聚类算法应用在银行客户细分中[6].但该算法在运行时,容易陷入局部最优[7],使得分类结果不能达到预期的要求.因此,本文提出一种基于改进K均值聚类的银行客户分类算法,利用最佳聚类数和初始聚类中心实现银行客户的细分,提升收益.

1 K均值聚类算法在银行客户细分中的应用
1.1 银行客户细分
信息化的发展使得银行能够获取大量的数据资源以及数据信息,但是数据之间的内在联系却无从得知,这对于银行的营销策略的制定有非常大的影响.因此,可以利用数据挖掘技术从数据库中寻找出有用的信息,并对客户详细分类,由分类结果为不同的客户推出相应的金融产品,并制定一系列相关服务,以吸引更多的优质客户,提高利益.根据K均值聚类算法实施的客户分类步骤如图1所示.
1.2 K均值聚类算法简述
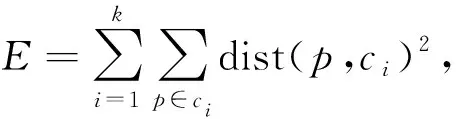
2 K均值聚类算法的改进
2.1 改进的K均值聚类算法
本节提出一种改进的K均值聚类算法,改进算法提供了一种确定最佳聚类数的方法,并找到最佳聚类中心.首先,算法在高密度的数据点中选出一个和聚类中心的距离最远的点,并把它看作一个新的聚类中心,放置到聚类中心的集合中.对某个数据集来说,当最佳聚类数确定时,根据改进算法求出的聚类中心也是确定的,这样,算法的稳定性就会大大提高.
下面给出相关的概念定义.点密度:处在点xi的r邻域内的点的数量.
Density(xi)={p∈c|dist(xi,p)≤r}.
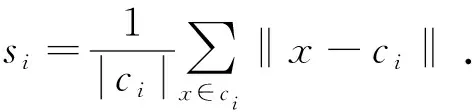
当AMS的取值最小时,表明算法的聚类效果最好,这时最佳聚类数就是K.
改进的K均值聚类算法的具体过程如下:(1) 计算点密度,然后在备选点集合D中添加点密度较大的M个数据点.(2) 在D中根据密度值大小排序,挑选出前两个密度最大的点当作算法的初始聚类中心,并且把它们从D中删除.(3) 从D中选出和步骤(2)初始聚类中心距离最远的点当作新的聚类中心,并且把该点从D中删除.(4) 利用迭代算法对N个数据点进行以上操作,计算AMS值.(5) 当计算出的当下AMS值比前一次的AMS值小时,继续执行算法,并转到步骤(6);当计算出的当下AMS值比前一次的AMS值大时,把该最小AMS值相对应的聚类中心看作K均值聚类算法的初始聚类中心,并转到步骤(7).(6) 按照公式(2)所示更新聚类中心,然后在集合D中挑选出一个数据点,使它和新的聚类中心间的最小距离有最大值,并把它看作下一个聚类中心,且从D中将其删除,转到步骤(4).(7) 执行K均值聚类算法.
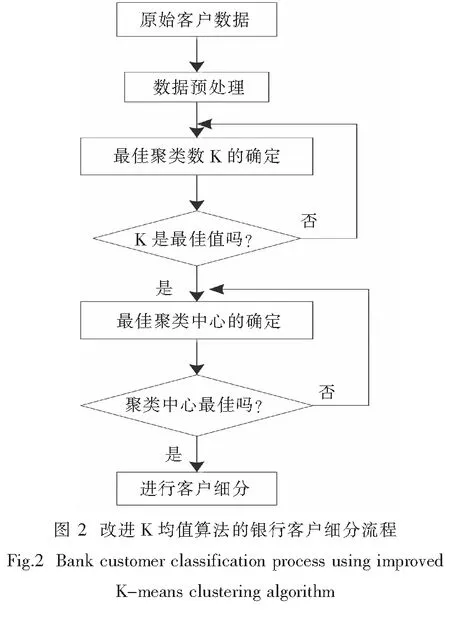
2.2 改进K均值算法的银行客户细分流程
对K均值聚类算法进行改进,并将其应用在银行客户细分中,图2为改进K均值算法的银行客户细分流程.
3 仿真分析
3.1 仿真数据
利用某市银行系统中的客户分类数据作为本文的仿真实验数据集,首先对该数据集进行预处理,得到2 000个客户的信息,每个信息包含的字段内容有:编号、薪资情况、存款情况、借贷状况等,并根据以上信息将客户分成4个大类,如表1所示.

表 1 客户类型及其聚类正确率
3.2 数据预处理

经过预处理,各个字段的基点和变化范围都变得相同,且它的均值是1,标准差是0.
3.3 结果分析
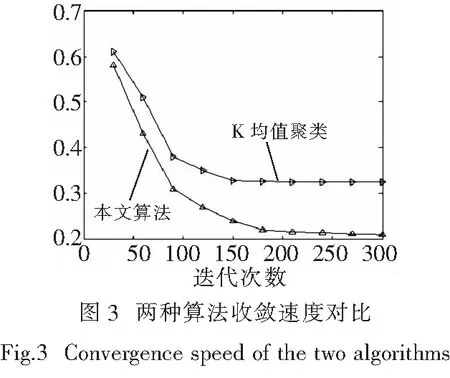
利用C语言编程验证算法性能,比较本文算法和K均值聚类算法的收敛速度,如图3所示.从图3可以看出,本文算法的收敛速度相比于K均值聚类算法而言明显更快,且本文算法结果较稳定,能够得到全局最优解.其原因是本文算法获得了最佳聚类数以及确定了最佳的初始聚类中心,跳出局部最优.
接下来,把客户数据集分成两部分,分别是训练数据集和测试数据集.表1为客户的四种类型.在K均值聚类算法中,设置其聚类数目k=5;在本文改进的K均值聚类算法中,设置最大的聚类数目为kmax=6.两种算法的聚类结果如表1所示.从表1可以看出,根据K均值聚类算法得到的聚类效果并不理想,甚至出现某些客户不能被正确聚类的情况.例如,当客户类型是重点客户时,由K均值聚类算法得到的聚类正确率是79.72%,由本文改进算法得到的聚类正确率是91.55%,两者相差了将近16个百分点,即改进算法将重点客户的比例提高了16%,这对于银行来说,是一笔重要的财富来源.因此,利用改进后的算法对客户进行分类,其效果更能满足银行的需求,这为银行的客户分类问题提供了极大的便利.
4 结 论
本文对传统K均值聚类算法进行了改进,并将改进后的算法应用到银行客户细分中.算法根据类间最大相似度均值AMS确定最佳聚类数,并对计算出的当下AMS值和前一次的AMS值大小,根据不同的原则选择初始聚类中心,利用最佳聚类数和初始聚类中心实现银行客户的细分.由对改进前后两种算法的仿真结果可知,改进算法能够提高客户细分的正确性,并加快收敛速度,为银行策略的制定提供相应的依据.
猜你喜欢
华人时刊(2020年23期)2020-04-13
铁道通信信号(2019年6期)2019-10-08
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
专用汽车(2016年9期)2016-03-01
智能系统学报(2015年4期)2015-12-27
专用汽车(2015年2期)2015-03-01
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01