
基于舞台说明挖掘的亚线性角色网络抽取方法
2018-07-19 13:02李建敦罗宜元
计算机工程与设计 2018年7期
李建敦,罗宜元,吕 品
(上海电机学院 电子信息学院,上海 201306)
0 引 言
对于剧本中的角色网络(character network)挖掘问题来讲,角色发现较直观,因此判定角色之间关联与否及关联强弱是关键[1]。鉴于语料库的规模及其在行文风格、所属流派等方面的不确定性,致使裸眼分析、手工构建、定性分析或纯粹的语义类方案[2],如基于自然语言处理(na-tural language processing,NLP)[3]等算法,在可靠性、可扩展性与效率等方面表现不佳。相比之下,统计分析类方法在计算精度的保证下,算法效率更高。目前,主流的统计类方法基本上围绕两个指标来刻画角色关系,即引用距离与对白距离。
角色引用距离类方法假设,如果多个角色同时出现在一个时空内,如连续剧、剧本的连续几幕、单独场次、小说的章节或段落、预定义的文本窗口(宽度为阈值θ)等[4-7],那么他们两两之间就应该有直接关系,权重为他们协同出现次数或引用距离的反比例函数[8,9]。此类方法对角色协同出现的时空采用阈值估计方法,精度无法保障;同时,协同在场的角色语义上并非一定有关系,因此该基本假设适用面有限;最后,连接也未能反映角色间的偏序关系。
围绕剧本的主体元素,即对白来刻画角色间关系,较引用距离类方法更优。基本思路是将前后相继对白的主体(即隶属角色)进行有序关联(who-talk-to-whom),其权重可以是对白规模(如行数、字数等)、对白中某角色被提及次数等[10,12]。该类方法实现了连接的有向性,而且围绕剧本主体(平均占比>80%)的对白进行分析,较好提升了模型的可靠性与精度[13]。然而,相邻对白并非一定有关系,且其偏序关系在非语义分析下较难确定,因此该类方法依然存在过度关联的问题。再者,以提及某角色频次为连接权重与实际往往并不相符,因为除了问候、命令等特殊场合外,社交场合中我们几乎不会直呼对方姓名。
通过上述分析发现,无论是围绕引用距离还是对白距离开展的角色网络建模,都存在噪声过多(引入过多冗余连接)、精度不高的问题。为此,围绕剧本中广泛存在但并不占主体地位的舞台说明元素,以65部西方经典戏剧为语料库,本文提出了一种亚线性角色网络抽取方法。总体上,该方法综合了上述两个指标的优势,并在精度与效率上有较大提升。具体来说,该方法通过解析舞台说明文字来确定两两角色是否协同在场;另外,同时在场仅仅构成了直接关系的必要条件,连接的最终生成还需来自对白上下文的舞台说明来佐证。与全文扫描相比,该方法视对白段落为整体,仅仅针对剧本中的辅助文本,即舞台说明,进行线性扫描,遍历规模远低于剧本长度N,因此是亚线性算法。
1 数据集
本文的语料库由65部欧洲多幕剧构成,出自3位不同时代的剧作家,即威廉·莎士比亚(William Shakespeare),亨利克·易卜生(Henrik Ibsen)与乔治·萧伯纳(George Bernard Shaw)。所有剧本数据均为HTML格式,来源于麻省理工大学在线经典文献项目(Internet Classic Archive)[14]与Gutenberg项目[15],剧本目录详见表1。下节将面向此数据集,进行角色网络的深度高效挖掘。
2 聚焦舞台说明的角色网络提取方法
总体来讲,本文主要面向剧本文本,特别是其中的舞台说明部分进行统计分析。详细地,该方法由预处理、识别角色与关联角色3个步骤组成,重点是有向含权连接的建模。相关源代码,参见作者在Github上发布的classicPlayParsing项目[16]。
2.1 预处理
鉴于语料库中不同剧本在元素到样式的映射上存在异构性,从提高方法可扩展性的思路出发,非常有必要对其进行标准化处理。本文关注3种元素,即角色(protagonists)、对白(dialogues)与舞台说明(stage directions),而如何识别并标记它们是预处理阶段的主要工作。通过将异构的HTML文件转化为标准的XML文件格式,剧本元素就可以通过样式来辨识(参见表2)。

表1 语料库详情

表2 语料库详情
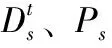
Algorithm I: 预处理与标记
Input:HF,LL,I,R,S
Output:XF
Begin:
(1) ScanHFto initializell,i,rands;
(2) Compare withLL,I,R,Sto identifyHF’s style;
(3) For line inHF:
(4) If this is a character line and ‘but’ in line:
(5) Truncate words from ‘but’ to the end line;
(6) Write line intoXF;
End
2.2 角色识别
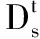
算法Ⅱ以标准文件XF为输入,并通过搜索舞台说明中的有向指示词汇,完成含时舞台的增量枚举,从而将不定代词解析为具体角色名。具体地,如果当前为开场行(算法Ⅱ第2至4行),那么基于键值对新建一个含时舞台对象
Algorithm Ⅱ: 含时舞台迭代
Input:XF
Output:RXF,DS
Begin:
(1) Forln,line inXF:
(2) If ‘Scene’ in line:
(3) Append
(4) pre_stage =Null;
(5) temp = []
(6) If this is a stage direction line:
(7)cur_stage=pre_stage;
(8) If ‘Enter’ in line:
(9) Append followed characters to temp;
(10) Append temp tocur_stage;
(11) If ‘Exit’ in line:
(12) Truncate characters fromcur_stage;
(13) Elif ‘Exeunt’ in line:
(14) Append
(15)pre_stage=Null;
(16) Ifpre_stage!=cur_stage:
(17) Append
(18)pre_stage=cur_stage;
(19) If this is a character line:
(20) Substitute indefinite pronouns with names;
(21) write revision toRXF;
(22) returnDS;
End
算法Ⅲ通过扫描改进标准版RXF中的角色行,生成了角色全集U。具体地,视行中角色数量来定,如果仅含有一个角色名,那么考虑直接添加至全集U(第(8)、(9)行),否则需要在拆分后再逐个考虑加入(第(3)至(7)行)。最后,U被返回以作后续之用。
Algorithm III: 角色识别
Input:RXF
Output:CS
Begin:
(1) For line inRXF:
(2) If this is a character line:
(3) If it has multiple characters:
(4) Split it into temp;
(5) For t in temp:
(6) If t not inCS:
(7) Append character names toCS;
(8) Elif line not inCS:
(9) Append line toCS;
(10) returnCS;
End
2.3 角色关联
为角色全集U中的节点添加有向含权连接,是生成角色网络的最后一步,也是算法核心。为了有效克服对白距离类方法精度不足的问题,此处着力挖掘对白间的指向关系,即谁对谁讲的偏序关系。思路源于剧本中元素间的极端不平衡关系,即对白段落占比高、具有内在指向性与语言异构性,而舞台说明元素围绕对白展开,占比低却具有鲜明的指向性。鉴于语料库中剧本间的异构特征,此处尽量不涉及对白文本的语义理解,仅围绕对白的辅助部分,如舞台说明、标点符号等搜集角色间交流的偏序线索。
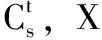
(1)X∈DSs且Y∈DSs;
(2)至少满足以下一种情况:
当然,其中的方向性介词“to”可替换为“toward(s)”,“address”,“tell” or “order”等同义词。同时,我们也认识到,在不利用语义解析对白的情况下,仅依靠舞台说明的指示来建立节点间联系并不完备,故而此处引入问号做补充。考虑到反问句的可能性,我们将问号的优先级降至最低。此外,X→Y的权重wXY也可以面向上述3种情况分别计算,其最大值为对白总行数t-s。
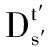
Case 3:因为在此情境下没有具体地“XtoY”或“toY”指示,因此权重直接取最大值t-s。
连接X→Y的最终权重是针对X各对白分量上结果的积聚,并以剧本总行数为基进行归一化(normalization)处理。至此,给定剧本的角色网络已经完成建模,具体见算法Ⅳ。
算法Ⅳ以RXF为输入,通过一次扫描实现含权连接集合(ES)的输出。具体地,第(3)至(6)行定位Case 1情况下的对话双方,并标记当前情境为Case 1。第(7)行至(12)行处理角色行,如果情境上下文为Case 3,那么直接将上段对白长度作为变量speaker至本角色间的权重,并更新spea-ker。第(13)至第(16)行处理对白首行,分别为Case 3与Case 1更新变量start3_line与start_line。第(17)行至第(24)行试图枚举Case 2,如果命中,那么结束上一个情境并将结果写入ES(第(19)、(20)行),并更新相关变量为Case 2做准备(第(21)-(24)行)。当扫描至对白段末行(第(25)行),完成Case 1或Case 2情境并写入ES(第(26)-(28)行);最后辨别结束标点是否为问号,如果是,则设定当前的情境为Case 3,并由下一次迭代在算法Ⅳ第(9)行处理完成。为了逻辑连贯性,算法Ⅳ并未考虑多角色同行情况,可用集合替换单个角色从而实现全覆盖。
Algorithm Ⅳ: 连接发现及其权重计算
Input:RXF
Output:ES
Begin:
(1)speaker=",listener=",case=0,line_count=0;
(2) Forln,line inRXF:
(3) If this is stage direction line and ‘to’ spotted:
(4)speaker= character preceded to ‘to’;
(5)listener= character succeeded to ‘to’;
(6)case= 1;
(7) Elif this is a character line:
(8) Ifcase==3:
(9) Write ‘speaker,line,end_line-start3_line’;
(10)case=0;
(11)q_line=end_line= 0;
(12)speaker= line;
(13) Elif this is the starting of a speech section:
(14)start3_line=ln;// starting line for case-3
(15) ifcase==1:
(16)start_line=ln;
(17) If this is one line of a speech section:
(18) If an embedded direction with‘To’spotted:
(19) Ifcase==1 orcase==2:
(20) Write ‘speaker,listener,ln-start_line’;
(21)case=2;
(22)listener= character succeeded to ′To′;
(23)start_line=ln;
(24)q_line=ln;
(25) If this is the end line of a speech section:
(26) Ifcase==1 orcase==2:
(27) Write ‘speaker,listener,ln-start_line’;
(28)case=0;
(29) Elif line end with ‘?’:
(30)case=3;
(31)end_line=ln;
(32) returnES;
End
2.4 算法复杂性分析
本节所述通过分析舞台说明中的提示信息来建立角色网络的方法,是轻量级的。虽然该方法的建立至少需要扫描剧本3次,即预处理、角色识别与角色关联,但是考虑到其关注核心并非剧本的主体——角色对白段落,而仅监听剧本的辅助元素,即舞台说明、角色行与对白尾行,而这些辅助元素之和在剧本中的平均占比不足20%。因此本文所述方法是轻量级算法,属于亚线性算法范畴,复杂度为o(N),其中N为剧本规模(如行数)。
3 实验与讨论
面向65部西方经典戏剧的剧本,基于Python(V2.7)对进行了实现,其中的3个角色网络(来自不同作家)如图1所示。网络节点代表剧中人物,连接表示直接对话关系,连接粗度表示关系亲密度。比如从剧本Hamlet的角色网络中不难发现,王子Hamlet对Horatio讲话最多,因此关系最密切(图1)。
在角色网络生成基础上,利用Gephi[17]对网络进行了系统全面的分析,得出一系列统计量,比如平均路径长度、聚类系数与度分布(详见表3)。就节点的无权度分布而言,绝大多数角色网络符合Zipf法则(呈L型),图2 展示了其中的3个。在语料库上的多次实验结果显示,网络的平均度分布服从无标度的幂律函数P(x)=k-r, 其中r≈2.87。
聚焦经典悲剧Hamlet,在其所对应的无差别连接网络中,有对白的角色共26名,由65条连接成为社交网络。在平均度为2.5的情况下,其中19个节点的度不超过5.0,因此它是典型的“小世界”网络。同时,与真实的社交网络相似,该网络围绕个别“热点”,如Hamlet、Horatio与国王,形成了广泛分布的社团结构,参见图1与表4。
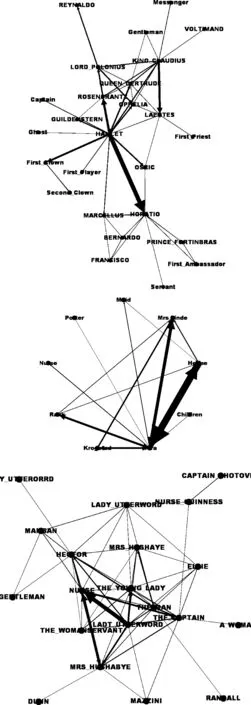
图1 角色网络示例:Hamlet(a)、A Doll’s House(b)、Heartbreak House(c)
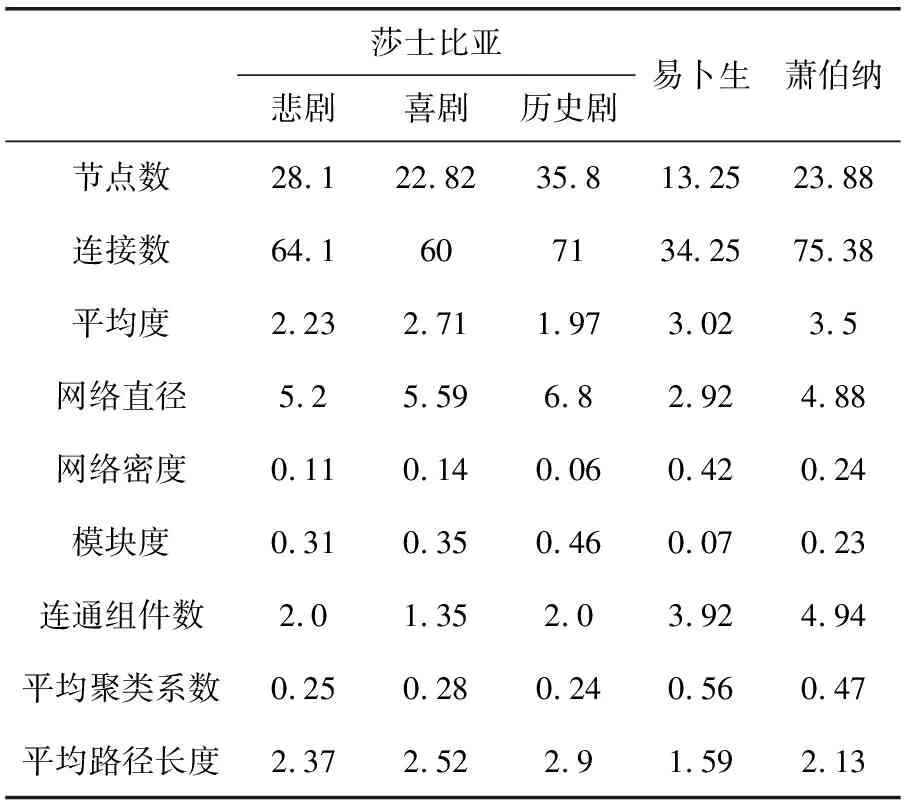
莎士比亚悲剧喜剧历史剧易卜生萧伯纳节点数28.122.8235.813.2523.88连接数64.1607134.2575.38平均度2.232.711.973.023.5网络直径5.25.596.82.924.88网络密度0.110.140.060.420.24模块度0.310.350.460.070.23连通组件数2.01.352.03.924.94平均聚类系数0.250.280.240.560.47平均路径长度2.372.522.91.592.13
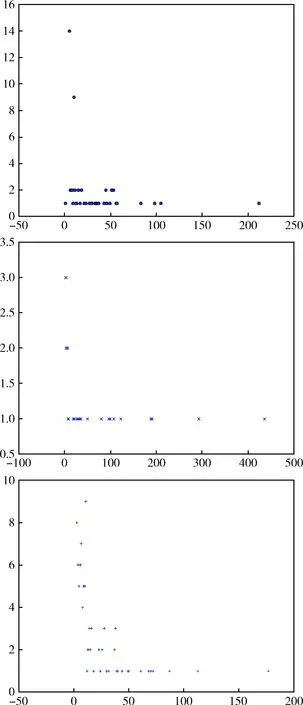
图2 无差别度分布示例:Hamlet(a)、A Doll’sHouse(b)、Heartbreak House(c)
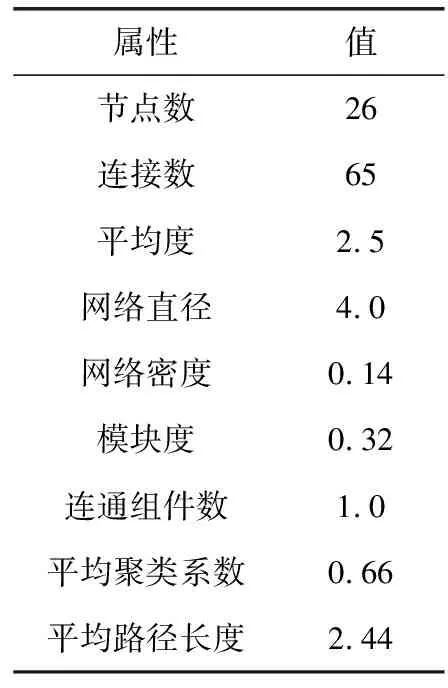
属性值节点数26连接数65平均度2.5网络直径4.0网络密度0.14模块度0.32连通组件数1.0平均聚类系数0.66平均路径长度2.44
结合角色网络的建模结果与分析发现,利用本文所提出的基于舞台说明的抽取方法,能够在有效降低噪声的基础上精准地挖出剧本中的虚拟网络。多次实验下平均耗时<1.0 s,因此方法是高效的。
4 结束语
随着计算语言学与数字人文研究的持续发展,展望未来我们期待网络科学在其中继续发挥更大的作用。比如给定一个语料库,文学评论家仅需几次鼠标单击,就可实现定量比较与实时分析,本文便是推动当前研究向此方向发展的重要一步。
面向由65部经典多幕剧构成的语料库,围绕剧本舞台说明分析,抽象出含时舞台的动态概念,并基于此给出了角色网络建模的亚线性方法。与角色引用距离或对白距离类算法相比,降低了噪声,提高了建模精度与收敛效率。同时,本文所述方法面向标准交换格式,并不局限于特定的戏剧作品,在对预处理做必要修改后,可以应用于任何给定的英文剧本中,因而通用性较好。
猜你喜欢
凤凰动漫(军事大王)(2022年3期)2022-06-17
凤凰动漫(军事大王)(2022年1期)2022-04-19
天津外国语大学学报(2020年1期)2020-03-25
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
现代防御技术(2016年1期)2016-06-01
语言与翻译(2015年4期)2015-07-18
当代外语研究(2010年3期)2010-03-20
当代贵州(2009年8期)2009-05-31
