
基于多维标签的信息流转双重管控模型与算法
2018-07-19 12:53李龚亮敬思远文泽鹏
计算机工程与设计 2018年7期
李龚亮,敬思远,文泽鹏,梁 燕
(1.中国工程物理研究院 计算机应用研究所,四川 绵阳 621000;2.乐山师范学院 计算机科学学院,四川 乐山 614000)
0 引 言
信息流转管控主要有基于标签的方法和基于内容的方法。基于标签的方法主要用于涉密网或单位内网环境,当前主流文档防扩散系统均采用此方法,仅在标签设计和算法上略有区别。此类方法存在两个明显缺陷:一是无法管控非文件形式的信息流,例如用户访问服务器时的http请求;二是必须信赖信息标识者是完全可靠的,无法防止恶意标识而导致的管控漏洞[1]。基于内容的方法主要用于互联网舆情监控[2]、文本安全审计[3]等领域,此类方法的不足之处在于,难以适应多对多复杂访问控制要求下的信息管控需求。本文以涉密网或单位内网的信息流转管控为目标,综合以上两类方法,提出一种基于多维标签的信息流转双重管控模型与算法。
1 基于多维标签的信息流转双重管控模型
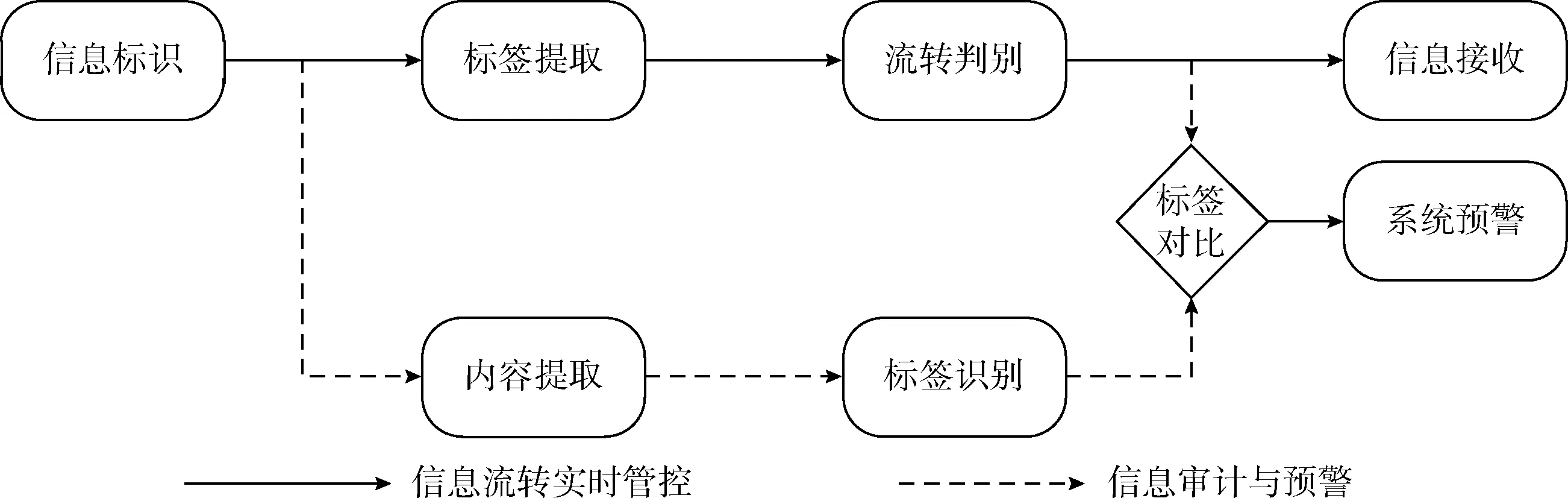
图1 基于多维管控标签的信息流转双重管控模型
信息流转双重管控的核心思路在于,以多维标签为核心,将基于标签的信息流转实时判别与基于内容的信息审计与预警结合起来,实现两种方法的优势互补。其总体模型结构如图1所示。
在信息流转的过程中,首先由发送方进行信息标识。数据流经管控环节时进行标签提取,同时将内容保存到本地用于信息审计。管控程序按照发送方、接收方和信息三者的标签,依据实时判别算法判断是否进行流转;若通过判别则将信息流转到接收方。与此同时,管控程序以异步的方式,采用自然语言处理和机器学习方法对信息进行自动标签标识,并将算法标识的标签与用户标识的标签进行一致性对比,若不一致则将进行系统预警。
按照该模型的设计,将有效杜绝用户恶意错误标识的问题。因为错误的标识有较大的概率被发现,且发现一次用户就将面临高惩罚的风险,从而形成威慑。另一方面,由于信息审计预警是异步的,系统仍然可以基于标签的机制进行高速、细粒度的流转权限判定。
要实现这个模型,有3个问题需要解决。一是如何对数据流和文件进行统一标识,这种标识模型要具有多个维度描述信息的流转控制权限,同时也能支撑快速的权限判别。二是采取何种方法来对信息标签进行自动标识。三是如何对标签进行一致性对比,并实现正确预警。下面三节将分别讨论这几个问题。
2 多维标签模型
2.1 信息统一标识方法
信息通常以文件与流的形式进行存储和流转处理[4]。现有的数字签名技术很容易对文件进行签名标识,而对于数据流如何处理却成为难题。从信息流转管控需求分析出发,可以发现最易于导致信息扩散的数据流是用户访问应用服务器所产生的。在企业应用环境中,这种流的主要形式是http(含web service)的response和request。不失一般性,本文重点分析如何针对http流进行标识。
http流信息的核心部分是业务数据,而非http标签,而业务数据的来源主是数据库记录,因此对http流的标识应以数据库为源头。在重要业务系统设计时对需要管控的业务对象均会明确标识,那么在业务对象转化为http流时,可以以统一的方式将标识注入请求或响应流的头部,如图2所示。
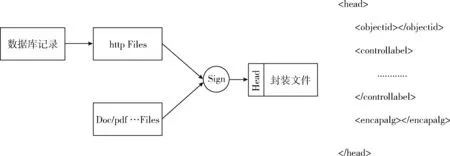
图2 数据流与文档文件统一标示模型
为统一模型并兼顾http流处理的需求,将所有标识标签都放置在文件前的“
”部分,以XML格式存储。“”中至少包含3部分内容,信息摘要标识、信息流转管控标识、信息封装算法标识。其中信息摘要标识用于标识信息的唯一性,可以是通过哈希算法求得的信息摘要,也可以是信息承载主对象的ID;信息封装算法标识用于对文件进行加密时封装所采用的算法,由于http文件具有时效性且在传输过程中可通过SSL技术进行加密,可不使用任何信息封装算法。需要特别注意的是http文件与普通文件的存在转换关系,即当以http格式上传下载普通文件时,不同的应用程序将采用不同的断点续传和分片方法将文件切分为多个数据段并封装为http格式多线程传输,从而导致监控单一的http流难以获得信息内容。针对此类问题,考虑到传输中的数据片段难以识别管控,需将管控位置前移到文件上传下载之前;若在企业内部网络中文件上传下载的算法是统一或可数的,也可开发针对性的http多线程数据片段归并程序在传输时实现http流到原始文件的归回。
2.2 多维标签模型
传统的管控标签通常是一维的,例如BLP(Bell_Lapa-dula)模型的绝密、机密、秘密、非密四分法[5],并规定低密人员不能访问高密信息,这样的分类方法相当粗略。例如,对某位机密级授权用户,他是不能访问所有机密级数据的。
为了建立信息系统访问控制的基础,本文综合业务实际提出了包含多个维度的管控标签模型,文中统称为多维标签,形式化表示为Tag=(L,P,A,B,D)。 其中,L表示密级,P表示保密期限,A表示定密依据,B表示知悉范围,D表示业务领域。多维标签模型如图3所示。
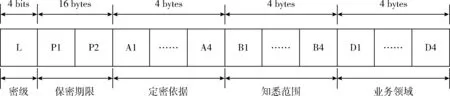
图3 多维标签模型设计
上述多维标签模型中,密级和保密期限相对容易理解。密级是一个0-n的整数,标定了该信息受保护程度的强弱;保密期限是两个时间戳标定的受控时间范围。而定密依据、知悉范围和业务领域相对比较复杂。定密依据指出了信息受控的原因,知悉范围指出了信息应在何种范围内传播,业务领域标识了信息内容的业务属性。
本文中,多维标签中的定密依据、知悉范围、业务领域均设计为包含有4个节点的树形结构,每一节点长度为1字节,用以存储真实标签对应的代码。以定密依据为例,该结构可以支持最多255种不同的定密依据标签(0表示未标识)。而用户最多可以选择4个标签进行标识。模型从标识空间规模上已能够支撑真实需求,通过增加字段长度也能够易于扩展。在工程实现时,网络环境中应存在统一的状态代码服务来负责管理代码与真实定密依据、知悉范围、业务领域的映射关系。
3 基于多维标签的信息流转实时判别算法
信息流转过程可以形式化描述为一个三元组IT=〈S,R,I〉, 其中S表示发送方,R表示接收方,I表示流转的信息。S,R,I均采用上节介绍的多维标签。换句话说,S与R的标签与信息I的标签是一致的。无论S和R是真实的用户还是信息系统,其都应该具有定密依据A、密级L、保密期限P、知悉范围B、业务领域D这5种属性。在实际业务中,信息流转并非刚性的禁止高密低流,而是允许一定程度上的超越权限访问。本文提出的在信息流转实时判别算法如下所示。在该判别算法中,如果发送方、信息和接收方三者的密级和期限不符合高密不低流原则,则禁止流转;否则,算法根据发送方、信息和接收方在其余3个标签维度上的标签包含情况进行打分,若最终分值低于给定阈值,则禁止流转。由于每个单位实际应用环境不同,如文献[4]中提出信息常出现从高安全级别流向低安全级别情况,因此本文提出算法可根据实际业务进行调整。
基于多维标签的信息流转实时判别算法
输入:IT=〈S,R,I〉
输出: pass // 0≤pass≤1,若pass低于设定阈值,则禁止流转
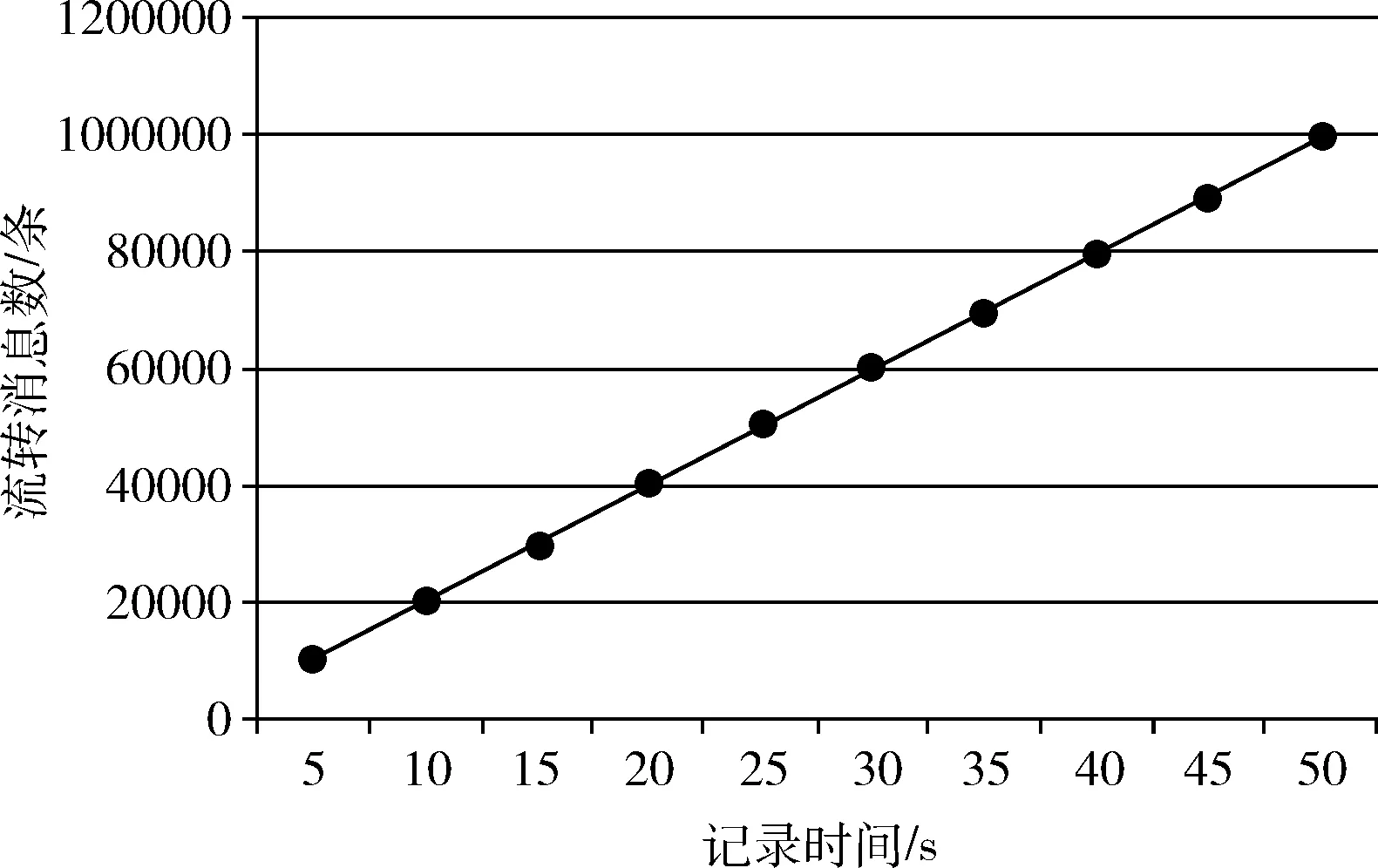
(1)if(S.Tag.L (2) pass=0; //若密级和期限不符合高密不低流原则,则禁止流转 (3)else (4) pass=λ1×Φ(S.Tag.A,I.Tag.A,R.Tag.A); (5) pass+=λ2×Φ(S.Tag.B,I.Tag.B,R.Tag.B); (6) pass+=λ3×Φ(S.Tag.D,I.Tag.D,R.Tag.D); (7)end (8) return pass; 说明: (1)⊄运算符:计算两个保密期限是否存在包含关系,存在则返回1,否则返回0; (2)Φ(·)函数:计算参数(即标签集合)之间的包含程度,计算公式如下 (3)card(·)运算符:计算集合中元素的个数。 上述方法不能防止用户恶意标识而导致的管控漏洞,例如发送方故意降低信息密级。因此,本文引入一种“事后审计”方法对其进行补充。传统基于内容的安全审计一般采用的是字符串匹配方法[3,6]。但是这种方法难以适应当前的安全需求。本文采用基于机器学习的方法,该方法基于多标签学习理论,结合领域知识,对信息进行多维标签自动标识。进一步,将算法自动标识的标签和用户标识的标签进行一致性对比,若经过模型判断后不匹配,则进行预警以及时防止信息扩散。图4为多维标签自动标识过程。 图4 多维标签自动识别过程 接下来,本文将介绍多维标签自动标识过程中的文本预处理、特征表示和提取、标签标识器的训练以及最后的标签对比模型。 本文方法中的文本预处理主要是中文分词。中文分词是将输入的文字序列,切分成一个一个单独的词,目前比较常用的方法有基于词典的最大匹配法、全切分路径选择方法、基于字序列标注的方法以及基于转移的分词方法[7]。 本文研究问题中需要重点考虑一些具有敏感信息的词。本研究依据已经有的业务经验由业务部门整理形成一个敏感词列表,作为本文的领域词典,下文中表示为SW={sw1,sw2,…,swm}。 为了防止用户在信息流中恶意嵌入涉密内容,本文采用一种二阶段的中文分词策略。其基本思路为,首先采用基于词典的最大匹配法筛选出信息中的敏感词,然后再以这些敏感词为边界,采用全切分路径选择方法,对剩余内容进行分词处理。这样处理的好处在于:①首先保证了敏感词的正确切分,这对最终标签判别结果是否准确非常重要;②其次,该策略无需构造大规模的词典;③能够对未登录词进行处理。 文本特征表示一般采用词袋模型(Bag-of-Word,BOW模型),即将信息文本表示为一个一维的特征向量V=[w1,w2,…,wn]。 其中n是文本特征的大小,wi是文本特征fi在文本中出现的频次,其中fi是本文特征集合F中的第i个元素。一般来说,文本特征可以采用统计的方法进行选择。常用的方法有TF-IDF、信息增益法、χ2统计量法、互信息法等[8,9]。 遗憾的是,传统的BOW模型表达能力非常有限。本文采用了领域词典来增强文本特征的表达能力,即文本特征集合F=SW∪W。 其中SW是领域词典中敏感词的集合,W是一般词的集合。本文采用χ2统计量法对W进行选择。 标签标识器训练是系统的核心模块,是实现多维标签自动标识的关键环节。本文需对密级、定密依据、知悉范围、业务领域4个维度进行自动标签标识。其中,密级标签仅需要标识1次,需要的标签标识器实际上是一种多分类器。另外3个维度可能会进行多次标签标识,因此需要一个多标签标识器(即多标签分类器)。本文重点介绍多标签标识器的学习问题。 本文采用M.R.Boutell等提出的Binary Relevance多标签学习算法(简称BR方法)[10]来训练多标签标识器。BR方法基本思想是,将多标签识别器的学习问题分解为若干个二分类器(即单标签标识器)的学习问题。换句话说,即是学习一个单标签标识器的集合,集合中每一个单标签标识器都对应一个标签。在训练过程中,BR方法采用交叉训练的方式,即对每一个训练样本,如果该样本带有该单标签标识器对应的标签,则该样本对于该单标签标识器为正样本,否则为负样本。选择BR方法的原因在于,首先该方法能够取得较好的实验结果;其次,该方法是一种one-to-rest方法,需要训练的单标签标识器较少,在时间上更能满足实际业务需要。 本文中的多维标签标识问题可以形式化表示为式(1)。该公式并运算符∪左边表示通过标签标识器得到第j维的标签集合,j的取值范围为1-3,分别对应于定密依据、知悉范围和业务领域(此处多维标签的表示符号与前文中略有差异);gj,k(x) 是第j维第k个标签的标识器,标识器返回值大于0,则将该标签加入到标签集合;Nj为第j维的标签总数。右边是文献[11]中采用的T-Criterion策略,它的作用是避免得到的标签集合为空集 Tagj(x)={tagj,k|gj,k(x)>0,1≤j≤3,1≤k≤Nj} (1) 本文采用4.3节中得到的多维标签标识器对消息文本x进行自动标识。其中,对于“密级”维度,本文通过标签标识器得到唯一的标识结果,形式化表示为L(x)。对于另外3个维度,得到的则是3个标签的集合,表示为Tagj(x)。基于得到的自动标识结果,本文提出一种标签一致性判定模型,如式(2)所示。 (2) 本文研制了系统原型对本文提出的管控模型进行了验证。原型的硬件平台为3 GHZ处理器+32 GB内存。实验数据采用的是10万条本单位的历史消息数据,并且经过严格的标签标识。多维标签中的密级为0~9之间的整数,数字越高,密级越高。涉密依据、知悉范围、业务领域3个维度标签则是通过专家知识进行定制。领域词典同样是由专家知识进行定制,其中包含了278个敏感词(例如本单位涉及的特有实体名词)。原型系统中的标签识别器(包括密级标签识别器和多标签识别器)均采用SVM(support vector machine)[11,12]。SVM采用线性核。 实验分为3个部分。第一部分是对基于多维标签的信息流转实时判别算法进行测试。第二部分是对多维标签自动标识算法进行测试。第三部分是对系统预警能力进行测试。 第一部分实验的目的是验证信息流转判别算法的效率。信息流转存在时限要求。本文将10万条数据同时输入到原型系统,并记录每一时刻系统吞吐量。实验结果如图5所示。从图中可以看到,系统吞吐量随时间呈线性增长,其性能可以达到约2000条数据/s。该性能可以满足大多数单位内部信息流转要求。 图5 信息流转吞吐量 第二部分实验的目的是验证结合领域知识的多维标签自动标识算法的有效性。本文将基于传统文本特征表示方法的多维标签标识器作为实验基线。实验指标采用的是多维标签自动标识召回率,如式(3)所示,其中p表示测试样本空间的大小。本实验采用十折交叉验证,实验结果见表1。从实验结果来看,本文提出方法的平均召回率指标为88.1%,说明该方法是有效的 (3) 表1 多维标签自动标识实验结果比较/% 第三部分实验的目的是验证系统预警能力。本文构建了120个测试样本进行测试。测试样本中包含80个错误标识的样本和40个正确标识的样本。实验指标采用的是准确率和召回率,如式(4)、式(5)所示。其中TP表示正确预警的错误样本数,FN表示未进行预警的错误样本数,FP表示错误预警的正确样本数。从实验结果来看,召回率指标为93.75%,准确率指标为89.3% (4) (5) 本文提出了一种基于多维标签的信息流转双重管控模型和算法。设计的多维标签能够实现细粒度的信息流转管控需求。基于该多维标签,提出了一种信息流转实时判别算法,经测试算法平均吞吐量能达到约2000条/s,能够满足大多数单位内部的信息流转要求。提出了一种结合领域知识的多维标签自动标识算法,该算法在实验中达到了88.1%的平均召回率,说明算法是有效的。进一步将算法自动标识标签与用户标识标签进行一致性对比,并通过决策模型进行预警。经测试,系统预警的召回率指标和准确率指标均达到了较高水平。4 结合领域知识的多维标签标识算法
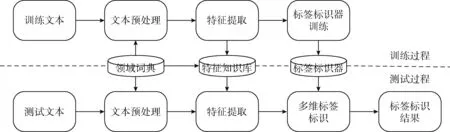
4.1 文本预处理与领域词典
4.2 特征表示与特征知识库
4.3 多标签标识器训练
∪{tagj,k*|k*=arg max1≤k≤Nigj,k(x)}4.4 多维标签一致性判定模型
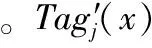
5 实 验

6 结束语
猜你喜欢
工程与试验(2022年3期)2022-09-27
中国特种设备安全(2022年3期)2022-07-08
中国交通信息化(2022年12期)2022-02-11
建材发展导向(2021年9期)2021-07-16
中国外汇(2019年22期)2019-05-21
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
公民与法治(2016年10期)2016-05-17
少儿科学周刊·少年版(2015年2期)2015-07-07
池州学院学报(2014年6期)2014-03-29
