
基于离群因子的不确定数据生成算法
2018-07-19 02:31唐东凯王红梅
吉林大学学报(理学版) 2018年4期
刘 钢, 唐东凯, 王红梅, 胡 明
(1. 长春工业大学 计算机科学与工程学院, 长春 130012; 2. 长春工程学院 计算机技术与工程学院, 长春 130012)
在对不确定数据进行分析、融合与挖掘前, 首先要获得不确定数据. 目前, 现有的不确定数据主要从两方面生成不确定数据集: 1) 从模拟数据集出发, 由于没有真实数据集, 所以先人工产生确定的模拟数据集, 再采用相应的转化策略生成不确定数据; 2) 从真实数据集出发, 如UCI机器学习数据集, 根据生成算法得到不确定数据集. 对于第一种方式, Chau等[1]首先在100×100的二维空间中随机生成一系列点, 然后对每个点选择一个不确定模型产生不确定性数据; 文献[2-4]在此基础上增加了一个大小随机且位置固定的矩形MBR(minimum bounding rectangle), 然后将不确定对象均匀分布在MBR内, 并将MBR内的每个样本点随机产生一个概率值, 使概率值之和为1. 对于第二种方式, 金萍等[5]先在UCI数据集Glass,Iris,Wine的每一维上设置一个扰动区间, 然后使用扰动因子β(0<β<1)控制每个数据对象对应的MBR大小; 文献[6-7]在确定数据集上添加了一个不确定数据生成策略, 为每个数据源中的样本数据定义了一个概率密度函数fi, 使每个样本对象由一组样本点表示, 每个样本点都对应一个概率值, 且概率之和为1; 文献[8-10]使用不同的分布函数作为概率密度函数生成不确定数据.
目前不确定数据集的生成方法主要存在两方面的不足: 1) 几乎所有的不确定数据生成算法都未考虑原始数据集的数据分布特征, 如数据集中存在离群点, 离群点的存在会影响最后的挖掘结果; 2) 在上述生成方法中, 存在扰动因子β(0<β<1), 且其值在整个算法过程中固定不变, 不能很好地反映数据的分布特征. 为了解决目前不确定数据集生成方法存在的不足, 本文通过分析不确定数据的模型, 针对属性级不确定数据, 先通过引入局部离群点检测算法计算每个对象的离群因子, 然后使用离群因子的值产生扰动因子, 自动控制MBR的大小, 提出了AC-UDGen(attribute level continuous uncertain data set generation algorithm)算法. 实验结果表明, AC-UDGen算法生成的不确定数据集在聚类时具有更好的聚类效果.
1 不确定数据模型
不确定数据模型的表示方式有多种, 较常见的是概率分布模型[11-12]. 概率分布模型由一个[0,1]间的概率值及确定的元组属性值表示. 在实际应用中, 将不确定性数据分为存在级不确定性(也称元组不确定性)和属性级不确定性(也称值不确定性)两种.
1) 存在级不确定性. 一个事件在每次测试中是否发生都以一定的可能性存在, 而这个可能性的大小即为对应该事件发生的概率, 存在级不确定性是指一个数据对象存在与否用一个概率值的大小表示. 例如, 数据库中有两个不确定对象A和B, 其中A存在的概率为65%, 而B存在的概率为70%.A和B之间可能是相互独立也可能存在依赖关系.
2) 属性级不确定性. 数据对象是确定存在的, 但其属性值具有不确定性. 一般采用概率值或概率密度函数表示属性的不确定性[13]. 例如, 在位置服务中, 数据对象属性A存在的情况是:i位置概率35%,k位置概率53%,j位置概率12%, 可见属性A的值是不确定的, 但其所有可能值的概率之和为1.
2 AC-UDGen算法
针对属性级不确定数据, 王建荣[14]进一步将属性级不确定性数据分为属性级离散不确定性和属性级连续不确定性数据. 本文主要考虑属性级连续不确定性数据, 定义为: 在m维空间m中, 给定不确定数据集O={o1,o2,…,on}和概率密度函数fi:m→, 如果将不确定数据对象ou的属性Ai值记为ou[Ai], 用概率密度函数fi表示, 且满足
则属性Ai称为不确定连续属性.
由定义可知, 连续属性级不确定数据的概率密度函数满足一定的分布, 如均匀分布、高斯分布等. 针对属性级连续不确定数据, 目前的生成算法[1-10]都未考虑到原始数据的分布特征, 如离群点等. 按目前算法进行转化时, 不确定数据集的离群点数量会相应增加, 从而对不确定数据的挖掘带来困扰; 此外, 在不确定数据生成过程中引入的扰动因子是固定不变的, 不能很好地体现数据的分布特征, 因此, 本文提出一种AC-UDGen算法, 该算法分为4步: 1) 在输入的确定数据集上运行基于密度的局部离群点检测-LOF算法[15], 计算出每个点的离群因子; 2) 由离群因子的大小判断出该点周围的密度大小, 并根据离群因子产生扰动因子; 3) 将扰动因子作为参数, 计算MBR值的大小; 4) 输出不确定数据集. AC-UDGen算法流程如图1所示.

图1 AC-UDGen算法流程Fig.1 Flow chart of AC-UDGen algorithm
2.1 计算离群因子
离群因子是指数据集中每个对象的偏离程度, 根据每个对象的偏离程度可确定该对象是否为离群点. 实质上一个数据对象的偏离程度正是数据对象分布的表达, 偏离程度越高说明该对象周围数据对象越少, 就最可能是离群点; 而偏离程度越低, 则该数据对象分布在较集中的局部区域中, 就不会是离群点. 本文采用LOF算法计算离群因子, 设D表示数据集,o,p分别为数据集D中的对象,k为正整数, 则离群因子的计算过程可分为3步, 下面以对象p为例进行说明.
1) 构建对象p的第k距离邻域. 对象p的第k距离邻域是指小于等于对象p最近的第k距离内的所有对象组成的集合. 实际上该集合反映了数据对象的偏离程度. 如果该集合较大, 说明该对象的第k距离邻域较大, 则它的偏离程度就较大; 反之, 若集合较小, 则偏离程度就小. 其计算公式为
Nk(p)={q∈D{p}|d(p,q)≤k-dis(p)},
(1)
其中:d(p,q)表示数据对象p和数据对象q之间的欧氏距离;k-dis(p)表示对象p的第k近的距离,k为正整数.
2) 计算对象p的局部可达密度. 对象p的局部可达密度是指对象p的Nk(p)内所有对象平均可达密度的倒数, 计算公式为
(2)
如果至少有k个对像和p有相同的坐标值, 却是不同的数据对象, 则式(2)的分母将趋近于0, 而对象p的局部可达密度将趋于∞; 相反, 如果数据对象p距离聚类簇较远, 则其Nk(p)领域内所有对象的可达距离之和就会较大, 相应的lrdk(p)值则较小.
3) 计算对象p的离群因子. 结合式(1)和式(2)计算p的离群因子, 计算公式为
(3)
由式(3)可知, LOFk(p)的大小反映了数据对象p的第k距离范围内空间点的平均分布密度, 易见, 若p的局部可达密度越小,p的Nk(p)内对象可达密度越大, 则对象p的LOF值越大. 即一个对象的LOF值越大, 则该对象是离群点的概率越大.
由式(1)~(3)可知, 离群因子的值反映了一个数据对象与其他对象间的分布关系, 并可根据其值的大小删除异常点, 因此, 本文使用LOF的值经过适当处理作为不确定数据生成算法的参数.
2.2 计算扰动因子
结合离群因子确定β(0<β<1)的值. 在离群因子计算过程中, 如果一个对象的LOF值越大, 则其离群概率越大, 周围的密度就较小, 落在其周围的数据对象就较稀疏, 在AC-UDGen算法中, 其MBR值较大; 相反, 若一个对象的LOF值越小, 则该对象周围区域就有更多的数据对象, 即落在其周围的对象较密集, 在AC-UDGen算法中, 其MBR值较小. 所以, 本文使用下列公式计算扰动因子的值:
(4)
其中:βi表示第i个元组的扰动因子; LOFi表示每个对象的离群因子.
2.3 计算MBR值的大小
在原始数据集上, 先计算出每个数据对象的离群因子, 然后计算出每个对象的扰动因子β, 最后在数据对象的每一维上设置一个扰动区间,Ih=β×max_length, max_length表示所有对象在该维上的最大距离, 并使用扰动因子β控制每个数据对象对应的MBR值, 在每个MBR中随机分布服从同一分布的固定数目的数据对象.
2.4 算法描述
AU-UDGen算法.
输入: 确定数据集D,S(每条原始记录所生成的不确定对象的个数);
输出: 不确定数据集U.
1) 在D上运行LOF算法, 根据式(3)计算出每个数据对象的离群因子LOFi;
2) 根据LOFi及式(4), 计算出每个对象的扰动因子;
3) ① 对于数据集的每一维j;
② 对于数据集的每个对象i;

4) ① 对于每个数据对象i;
② repeat;
③ 对于每一维j;
④ 根据该维确定的值, 随机生成满足某个分布的不确定值Uij;

⑥ until每个数据对象都生成S条记录;
5) 输出不确定数据集U.

3 实验结果分析
本文使用Python语言实现所提算法及涉及的相关算法, 版本为Python2.7.0. 运行环境为: Intel(R) Core(TM) i5-3470 CPU, 3.20 GHz, 8.00 GB内存, 操作系统为Windows8.1系统, 64位.
实验分为3部分: 第一部分验证AC-UDGen算法的准确率; 第二部分验证不同概率密度函数对聚类结果的影响; 第三部分验证AC-UDGen算法的时间效率. 实验整体框架如图2所示. 由图2可见, 算法共分为5个过程, 由1)输入确定数据集, 由2)运行本文算法, 将其变为3)中不确定数据集, 然后再统一使用4)中UK-means聚类算法进行聚类, 对结果使用5)中的评价标准, 分别从准确率和时间两个维度验证本文算法的有效性.

图2 实验整体框架Fig.2 Overall framework of experiment
1) 选取UCI机器学习数据集中的4种数据集作为原始确定数据集, 数据集属性列于表1.
2) 对确定数据集, 运行本文提出的AC-UDGen算法, 将其变为不确定数据;
3) 得到不确定数据集;
4) 在不确定数据集上统一使用文献[3]提出的不确定聚类算法UK-means进行聚类;

(5)


表1 UCI实验数据集
F-measure针对的只是聚类结果, 而内部评价标准考虑到了聚类过程, 类内距表示聚类簇之间的紧密度, 类间距表示聚类簇间的分离程度. 类内距的计算公式为
(6)
类间距的计算公式为
(7)
其中, D(o,o′)表示数据对象o和o′的期望距离.
令Q(C)=inter(C)-intra(C)作为内部评价标准,intra(C)越小,inter(C)越大, 则聚类质量Q(C)越好. 由于intra(C)和inter(C)的值在[0,1]内, 则Q的范围是[-1,1].
3.1 验证AC-UDGen算法的准确率
采用文献[6]和文献[8]提出的不确定数据生成算法, 分别记为ABRAC算法和UK-medoids算法作为对比算法. 涉及的参数设S=100(S表示每个MBR内的样本数),β=0.5. 对比算法只取其不确定生成算法, 聚类过程统一使用UK-means算法进行聚类. 概率密度函数采用uniform,normal,exponential,Laplace 4种分布. 在4种数据集上分别进行10次独立实验, 记录每次的实验结果, 并求出均值进行对比, 使用F-measure作为评价标准.
在不确定数据生成过程中, ABRAC算法首先在原始数据集的每一维上设置一个扰动区间Ih=0.1×max_length, 其中max_length表示所有点在该维上的最大距离, 然后使用扰动因子β(0<β<1)控制每个数据对象对应的MBR值大小, 且每个MBR内服从同一分布.

从上述两种算法的生成过程可见, 在整个聚类过程中,β一旦选中就不再改变, 即β是固定不变的(UK-medoids中随机选择后也不再改变), 也即每个不确定数据对象的分布区域是确定的, 并未反映出数据对象周围密度空间的分布情况, 如数据对象分布较密集, 则MBR的值也应该变小, 但由于β不变,Ih就不变, 导致MBR值也不变. 反之, 如果数据对象分布较稀疏, MBR值应该变大, 但由于β, MBR值不变. 所以β固定无法反应数据对象的分布特征. 而在AC-UDGen算法中, 首先对每个数据对象计算出其离群因子, 离群因子大表示数据整体分布稀疏,β也会变大, MBR值变大. 离群因子小, 表示密度大, 数据分布密集,β会变小, MBR值也变小, 更贴合数据的实际分布情况, 从而减少聚类的迭代次数, 提高运行效率. 图3为3种不同算法在不同分布上的F-measure值比较. 由图3可见, AC-UDGen算法的F-measure值, 除了在图3(B)中的Wine数据集上与UK-medoids算法的F-measure值相同外, 在其他情况下AC-UDGen算法均优于ABRAC和UK-medoids算法.

图3 3种不同算法在不同分布上的F-measure值比较Fig.3 Comparison of F-measure values of three different algorithms on different distributions
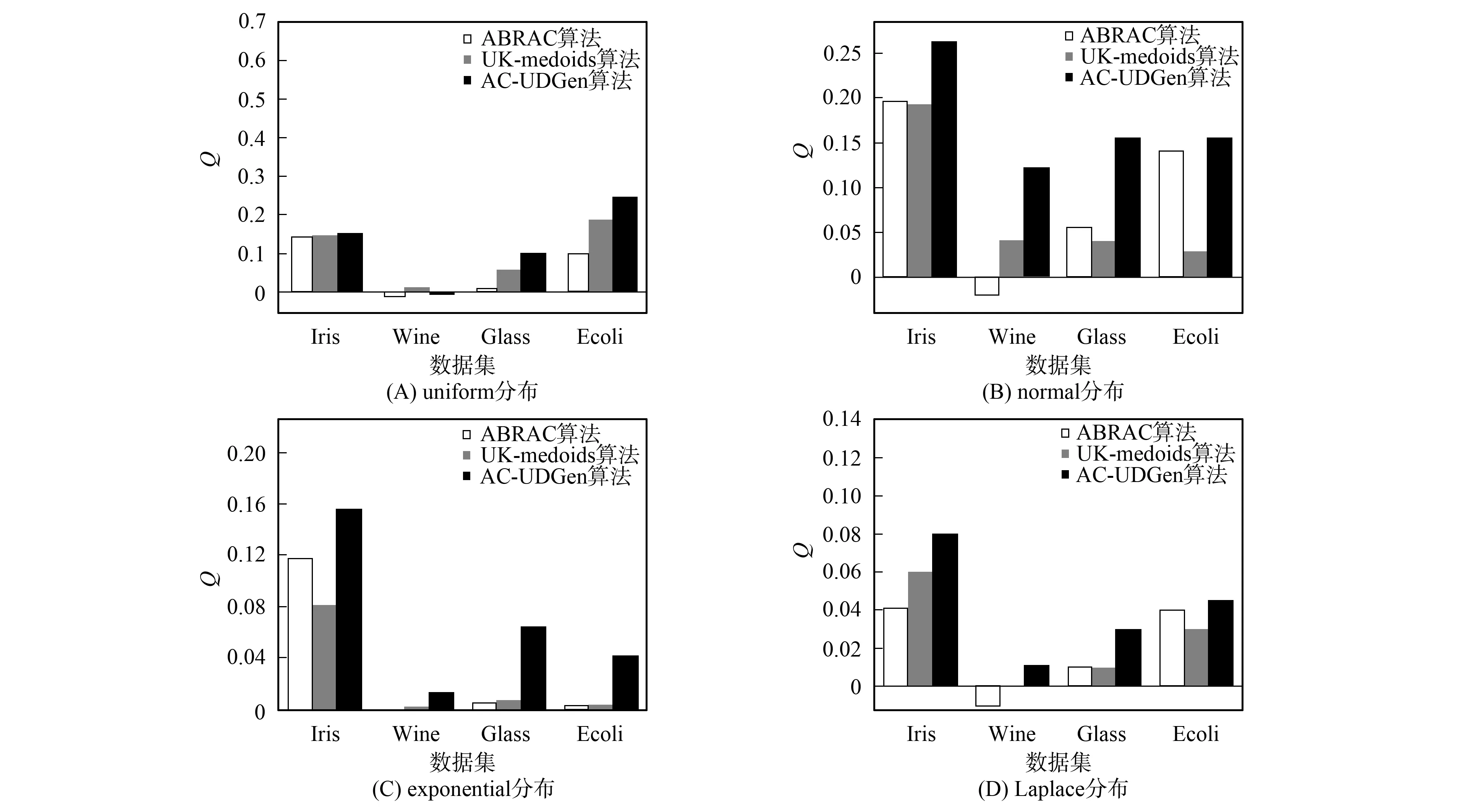
图4 3种不同算法在不同分布上的Q值比较Fig.4 Comparison of Q values of three different algorithms on different distributions
F-measure是外部评价标准, 下面从内部评价标准出发, 比较各算法的Q值, 运行10次, 取均值, 结果如图4所示. 由图4可见, 在Wine数据集上, 采用uniform作为概率密度函数时, AC-UDGen算法的Q值低于UK-medoids算法, 但在其他情况下显然高于另外两种算法. 综合F-measure和Q值两种评价标准, 可知在多数情况下, AC-UDGen算法的聚类效果都优于其他两种对比算法, 因此本文提出的算法是有效的.
3.2 不同概率密度函数对结果的影响
上述实验结果表明, 不同概率密度函数会对聚类结果产生不同的影响. 下面选用normal, uniform,exponential,Laplace 4种分布进行实验验证, 在同一数据集上, 采用不同的概率密度函数, 分别运行10次, 结果如图5所示. 由图5可见, 在Iris数据集上, 采用uniform分布时结果波动较大, Laplace分布不适合Wine和Glass数据集, 而exponential分布也不适合于Glass和Ecoli数据集. 可见, 同一数据集采用不同分布时, 聚类结果不同; 在分布相同时, 数据集不同, 聚类结果也不同. 因此, 在生成不确定数据集时, 应对具体数据具体分析, 采用合适的概率密度函数.

图5 不同数据集不同分布的聚类结果Fig.5 Clustering results of different data sets with different distributions
3.3 验证AC-UDGen算法的时间效率

图6 3种算法的运行时间对比Fig.6 Comparison of running time of three algorithms
图6为3种算法的运行时间对比. 由图6可见, AC-UDGen算法的执行时间比其他两种方法长, 且对于3种算法随着实验数据集的规模增大, 执行时间也随着延长. 虽然AC-UDGen算法有较高的时间代价, 但在可接受的范围内, 获得了较好的聚类结果.
综上所述, 本文提出了一种属性级连续不确定数据生成算法AC-UDGen, 通过引入离群点检测算法, 计算每个数据对象的离群因子, 并将离群因子作为控制数据分布范围的参数产生扰动因子, 降低了离群点对聚类结果的影响, 使每个数据对象MBR的值均可根据自身的分布特征自适应的变化, 可用于产生满足任何已知分布的不确定数据对象. 通过实验对比AC-UDGen算法与其他算法生成数据集上的准确率、聚类精度和执行时间, 也验证了选择不同的概率密度函数对聚类结果会有不同的影响, AC-UDGen算法可较好地弥补传统算法的不足, 在可接受的时间内取得了较好的聚类精度.
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
广西民族大学学报(自然科学版)(2022年1期)2022-05-18
四川大学学报(自然科学版)(2021年6期)2021-12-27
山东警察学院学报(2021年2期)2021-08-24
唐山师范学院学报(2018年6期)2018-12-25
小型微型计算机系统(2018年8期)2018-09-07
当代旅游(2018年8期)2018-02-19
数学学习与研究(2018年2期)2018-02-09
阅读(中年级)(2016年4期)2016-11-19
文苑(2015年9期)2015-09-10
