
基于网络搜索数据的游客量组合预测模型①
2018-07-18 06:07谢天保
计算机系统应用 2018年7期
谢天保, 赵 萌
(西安理工大学 经济与管理学院, 西安 710054)
近年来, 伴随旅游业蓬勃发展的同时, 游客普遍反映旅游体验在逐渐变差. 究其根本, 主要源于在旅游高峰期, 景点接待能力与涌入的游客量不匹配. 各地著名景区在节假日期间往往游客爆棚、人满为患, 管理难度大幅度提升导致超出了景区管理人员的可控范围,使得游客的游玩体验受到严重影响, 游客的人身财产安全也难以保证. 因此, 如果能实现对未来一段时间尤其是旅游旺季的游客量预测, 管理者就可以结合实际的承载能力提前制定有效的防范措施, 确保服务质量和景区安全, 具有极强的现实意义.
1 研究现状分析
传统的旅游人数预测研究采用的主要方法有时间序列模型[1]、灰色系统理论[2]以及人工神经网络[3]等,但这些研究采用的历史数据存在较大延迟性, 时间粒度也很大, 大都集中于国家或省级层面的年度入境人数预测. 随着大数据时代的到来以及基于网络数据的经济社会类行为预测研究的广泛开展, 在研究旅游行为相关问题时, 越来越多的研究人员将目光投向了网络搜索数据. 文献[4]发现我国部分3A级旅游景区客流量与网络关注度密度具有明显呼应的关系; 文献[5]证实网络关注度和旅游人数存在长期均衡关系和Granger因果关系; 文献[6–10]等关系研究均表明网络搜索数据包含着许多有价值的行为信息, 对现实游客量存在前兆效应, 具有一定的预测能力. 文献[11]基于谷歌趋势构建了一般的ARIMA模型及加入网络数据作为自变量的预测模型, 发现后者拟合效果和预测精度更高, 但关注的仍是全国入境人数这种大范围预测;文献[12]发现加入百度关键词作为解释变量的模型相比传统的ARMA模型, 预测精度提高了14.5%, 但依然存在较大误差; 文献[13]采用直接取词法选取5个关键词数据作为解释变量分别建立了向量自回归和BP神经网络模型, 发现神经网络比回归法预测精度略高, 但关键词过少, 难免会因信息遗漏使模型与实际有一定偏离.
为实现更准确、更具有时效性、地域针对性更强的预测, 本文拟基于网络搜索数据, 结合多种机器学习算法建立游客量预测模型, 时间粒度选取为月度, 以提高预测的及时性和实用性, 同时考虑到组合预测法的思想, 即在诸种单一预测模型各异的情况下, 组合预测模型可能会得到比任何一个独立预测值更好的预测值,显著改进预测效果[14], 进一步构建组合模型以优化预测结果.
2 网络搜索关键词的选取
首都北京在我国旅游城市排行中首屈一指, 本文选取北京市游客量作为研究对象, 收集了2011年1月至2016年12月期间, 每个月北京市所有旅游景区、景点接待的全部游客总量, 但模型也可推广应用至其他地区和省市.
搜索引擎能够帮助游客从数以亿计的网页中快速定位到所需要的信息, 而关键词搜索是游客在线信息搜索时最常用的策略[15], 所以基于网络搜索数据的预测研究的第一步就是选取相关搜索关键词. 本文中所用到的关键词网络搜索量来源于国内应用最为官方的搜索引擎的百度指数.
2.1 选定核心关键词
本文采用文本挖掘的方法, 结合旅游六要素, 即食、住、行、游、购、娱, 对网络上与北京旅游相关的新闻、文章、点评、分享交流等信息进行查找收集,剔除掉一些无用信息后, 再使用NLPIR汉语分词系统对原始文本集合进行处理, 得到关键词列表及其权重,权重越高, 越应被选为核心关键词. 最终选定了6个核心关键词: “北京小吃”、“北京住宿”、“北京旅游地图”、“北京旅游”、“北京特产”及“北京景点”.
2.2 核心关键词搜索指数的预测能力分析
显然网络搜索数据和实际游客量数据都属于时间序列, 平稳性是时间序列数据统计推断的基础. 检查序列平稳性的标准方法是各种单位根检验, 本文采用ADF (Augmented Dickey-Fuller Test)检验对6个核心关键词的搜索指数序列和实际游客人数序列的平稳性进行检验, 结果表明原序列中部分为非平稳序列, 但在一阶差分下所有变量均在1%的显著性水平上拒绝原假设(原假设为序列至少有一个单位根, 即不平稳), 即均为一阶单整序列, 符合协整检验的前提条件.
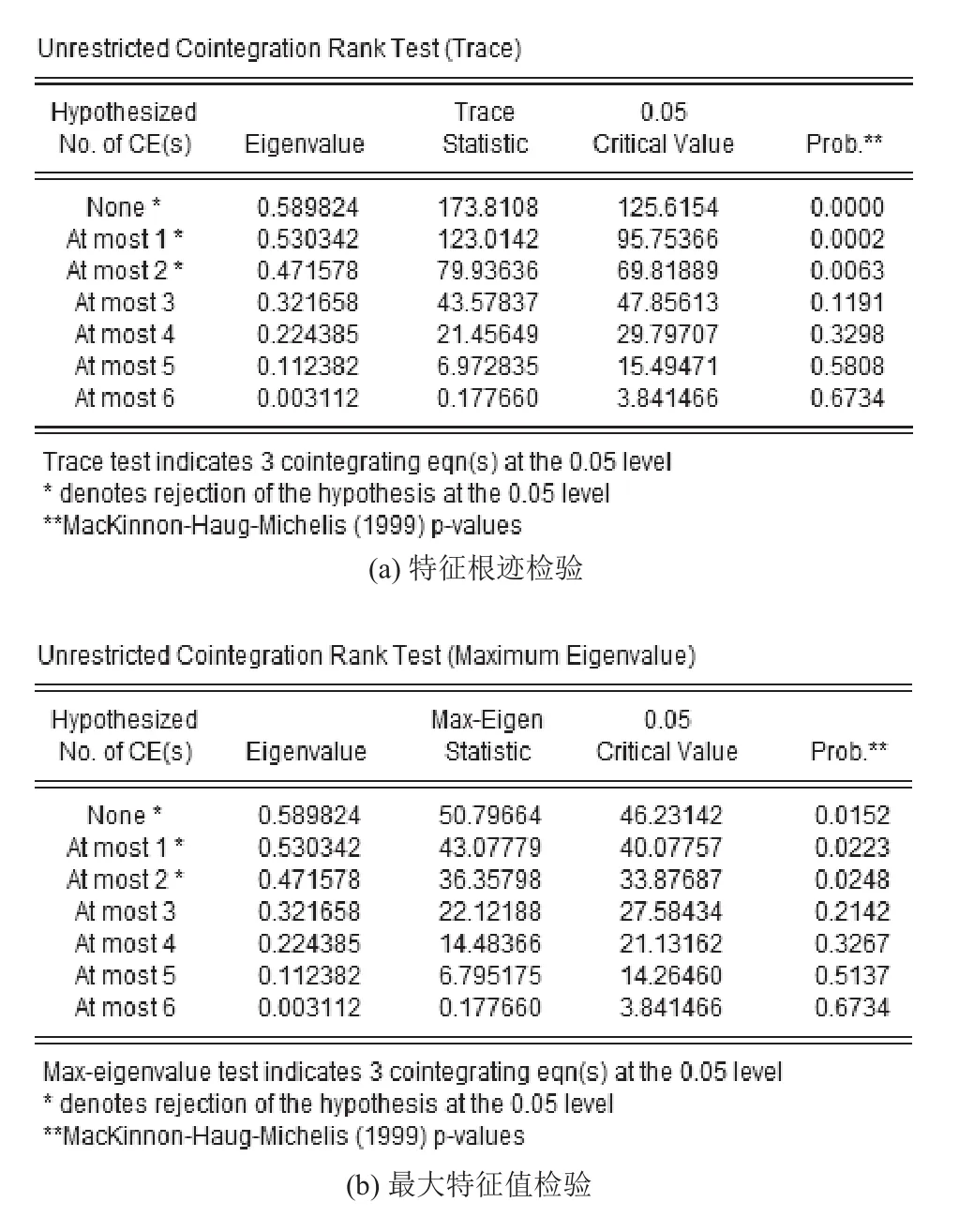
图1 Johansen协整检验结果
本文通过Johansen协整检验来考察变量间的协整关系, 检验结果如图1所示, 可以发现特征根迹检验和最大特征值检验在5%的显著性水平上都是拒绝原假设的, 说明协整关系存在, 依据现代协整理论, 对于非平稳时间序列, 只要各变量之间存在协整关系, 就可以直接建立VAR模型[16].实验收集了2011年至2016年共计72个月的月度数据, 选取前5年(即前60个)数据作为样本集用于建模, 2016年1月至12月的数据则作为测试集用于模型验证. 建立VAR模型需要确定滞后阶数, 本文结合似然比LR、AIC、SC准则等多种检验方法, 最终确定建立VAR(3)模型. 如图2所示, 该VAR模型所有特征根的倒数均落于单位圆内, 即均小于1, 模型稳定. 应用该模型预测样本集外数据, 结果如图3所示.

图2 VAR模型特征根位置图
总体来说, 预测值与实际值的趋势基本保持了一致, 说明模型具有一定的预测能力, 关键词指数的前期变化的确有助于解释实际游客量的变化. 但是预测误差明显较大, 平均绝对百分比误差(MAPE)高达12.24%,具体到每一个月的相对误差基本在几百万人次(图3中游客人数单位为万人次), 显然达不到精准预测的要求.
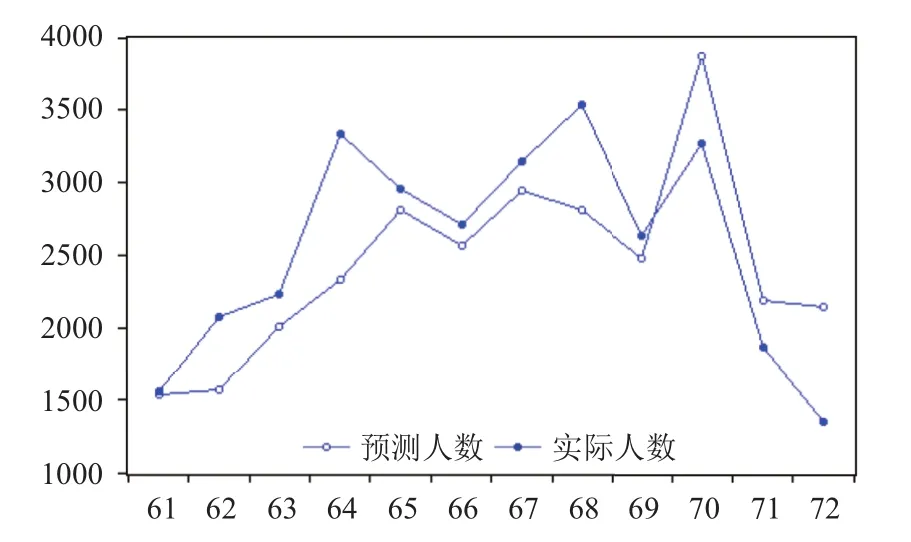
图3 2016年北京市实际旅游人数和预测人数的对比图
因此, 仅仅基于这6个核心关键词对游客人数进行预测是不科学的, 选取核心关键词的方法不完善或是核心关键词的数量过少, 都会导致信息覆盖不全面从而影响研究结果. 为了提高研究结果的准确性, 应该对核心关键词进行大范围拓展和进一步择优, 才能保障模型中所加入的自变量能尽可能的涵盖会影响到因变量变化的所有信息.
2.3 关键词的拓展与择优
拓展的目标是围绕少数的核心关键词, 拓展出数量更多的相关关键词. 拓展的依据和方法有多种, 本文综合使用了长尾关键词拓展法、百度需求图谱以及网页相关搜索推荐, 建立了一个包含79个关键词的初始词库.
通过判定各个关键词与研究对象的关联关系, 筛选出合适数目的最优关键词是提升模型预测准确度的关键. 因为并不是每个关键词都与实际游客量存在相关关系, 多个词之间也可能存在共线性, 导致信息重叠,不利于模型建立. 本文首先根据Spearman秩相关检验筛选出相关系数大于0.6的搜索关键词, 共计38个. 然后采用时差相关分析确定上一步筛选出的关键词搜索指数与北京市游客量的时滞阶数, 并选取同行关键词指标(网络搜索作为一种即时性行为, 游客一般都会在出行当月搜索相关的旅游信息). 最后筛选出的同行关键词及其相关系数, 共计25个. 如表1所示.
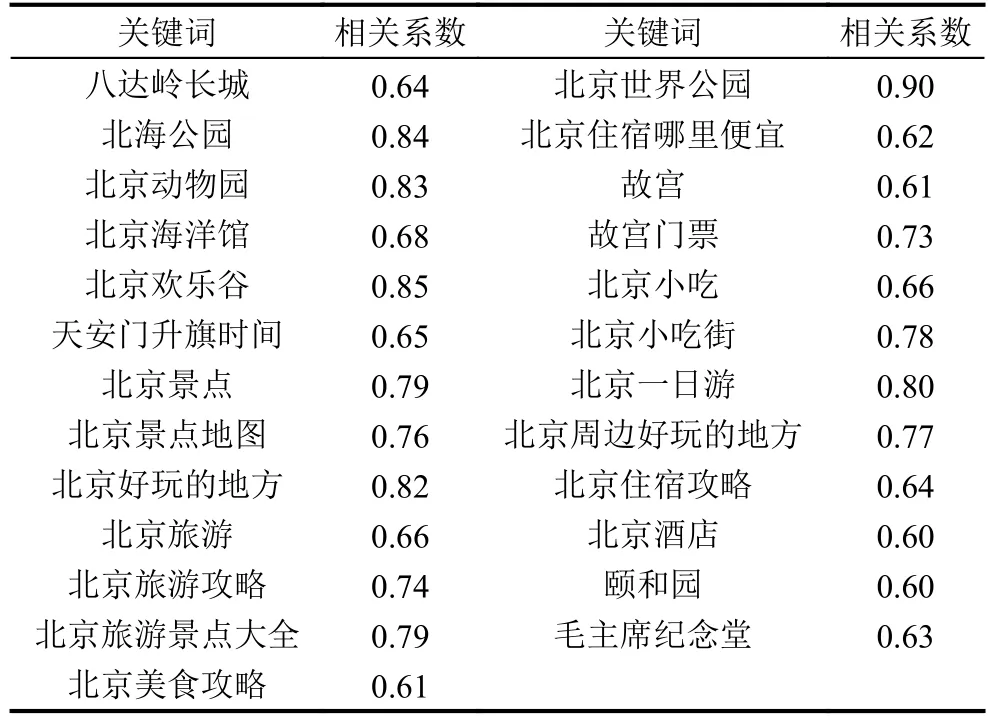
表1 同行关键词spearman秩相关系数
VAR模型本质就是把系统中每一个变量描述为系统中所有变量的滞后值的线性函数, 当变量多达25个时, 难以保证各变量之间仅仅存在线性关系. 因此, 对于解释变量众多、平稳性和协整关系难以保证、可能存在非线性关系等情况, 应用适应性更为广泛的机器学习算法建立预测模型比传统的VAR模型更为合适.
3 单一预测模型的构建
3.1 BP神经网络模型
理论上已经证明三层神经网络可以无限逼近任意连续函数, 本文建立单隐藏层的BP神经网络模型, 再对模型隐藏层的节点数目和迭代次数进行优化, 以确定出最优的模型误判率.
实验发现, 训练集误差跟随隐藏层节点数的增加而下降, 但测试集误差先下降后面反而上升, 这是由于模型中隐藏层节点数增加而引起的模型过度拟合导致的, 考虑到预测模型应注重模型的推广能力, 当隐藏层节点数为4时, 测试集MAE值最小且训练集误差也在接受范围内, 因此确定最优的隐藏层节点数为4. 同时,当训练周期达到300以后, 训练集和测试集的MAE均趋于平稳且已经达到了较小的值, 因此最终确定出一个隐藏层节点数为4, 训练周期为300的单隐藏层BP神经网络模型.
3.2 支持向量回归模型
支持向量机最初是根据分类问题发展起来的, 但也可应用于回归问题. 建立SVR(支持向量回归机)模型, 需要确定分类方式和核函数的组合方式, 针对数值型变量的分类方式主要有两种(eps-regression和nuregression), 核函数则有四类(linear, polynomial,radial和sigmoid).
实验发现, 按照MAE值最小原则无论是测试集预测还是训练集拟合均应选择eps-regression和radial的组合. 在此基础上对惩罚因子cost和gamma参数进行优化, 同样按照MAE值最小原则确定出测试集cost取1, gamma取0.1, 训练集则cost取10, gamma取1.
3.3 随机森林模型
在构建随机森林模型的过程中有两个重要参数:一是树节点预选的变量个数mtry, 决定着单棵决策树的情况; 二是随机森林中树的个数ntree, 决定着整片森林的总体规模.
实验发现当mtry= 5时, 模型对变量的解释率最高, 为86.05%, 残差平方均值最小, 所以节点上变量个数确定为5. 接着确定整片森林的规模, 实验发现模型误差随决策树数量的增多逐渐降低并趋于平稳, 当决策树数量约大于1300之后, 模型误差基本稳定, 因此将ntree值确定为1300.
以上三种模型预测误差如表2(见4.2节)所示, 从MAPE值来看, 支持向量回归最优, 随机森林次之,BP神经网络则相对较差. 但总体来说, 这三种单一模型的预测准确度和稳定性都优于前述的VAR模型, 这一方面说明了关键词拓展的必要性, 另一方面也说明网络搜索指数与实际游客量之间存在部分非线性关系,因此机器学习在这种预测方面更具优势.
4 基于机器学习算法的组合预测模型
4.1 建立GBDT组合预测模型
以往研究中使用频率较高的是简单便捷的定权组合法(如等权平均法、方差倒数法), 但其实笼统的赋予定值权重, 对于提高预测准确度是不理想的, 因为不同单一模型在不同时刻的预测误差是不一样的, 如果按照时刻和预测误差的变化赋予各个模型动态变化的权值, 效果会更佳, 本文提出基于GBDT的组合预测模型.
GBDT (Gradient Boosting Decision Tree)是一种梯度提升的决策树算法, 核心思想是将损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值, 拟合一个回归数. 将三种单一模型训练集的拟合序列作为新的训练集, 将单一模型测试集的预测序列作为新的测试集建立GBDT模型, 模型中赋予各个单一模型的权重系数应是随时间点不同而变化的.算法流程如下文.
(b) 对rmi拟合一个回归树, 得到第m棵树的叶节点区域为
Step 4. 得到回归树:
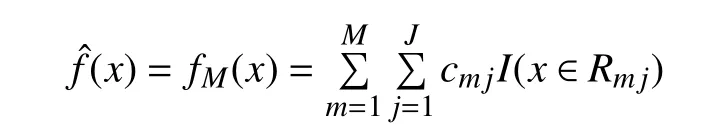
要对各参数进行优化, 包括损失函数、学习速率、迭代次数等. 损失函数选择回归问题中最常用的Gaussian分布, 学习速率取0.05, 使用交叉验证确定最佳迭代次数为2518. 最终根据此模型得到一组新的组合预测结果.
4.2 模型预测结果评价
为了有效和直观的衡量不同模型的预测能力, 本文选取均方误差(MSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)这三个指标来评估预测结果,各模型预测结果如表2.
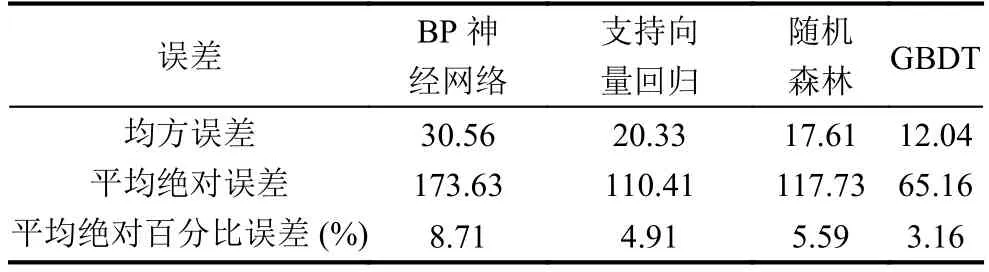
表2 各模型预测结果比较
从表2可以看出, 无论从MSE、MAE还是MAPE来说, 组合模型的预测效果均有显著优势, 相比单一模型大幅度提高了预测准确度. 各模型的预测值与实际值对比如图4所示.
由图4可知, 其中图4(a)和图4(d)清晰直观的表现出了效果最差的单一模型与效果最好的组合模型在预测准确度上的明显差异(由于游客量数据周期性很强, 每一年走势基本一致, 因此仅展示2014~2016年的数据), BP神经网络模型通过学习训练基本能预测出游客量一年的走势, 但对峰值敏感度较低, 训练集拟合效果也较差, 而GBDT组合模型的训练集拟合效果很好,峰值敏感度和测试集预测效果也更优.
5 结束语
本文以北京市游客量为研究对象, 选定核心关键词后, 对其进行数据检验和预测能力分析, 证明网络搜索数据的确有助于预测实际游客量, 为提高预测的科学性和自变量信息的完善性, 进一步拓展核心关键词并择优筛选, 基于同行相关关键词的百度搜索指数, 分别建立了三种单一预测模型, 为提高预测准确度又建立了基于GBDT的组合模型, 模型预测结果显著体现出了组合预测的优越性. 统计局统计数据的发布至少存在两个月的滞后期, 而本文提出的基于同行网络数据的组合预测模型可以即时预测当月人数, 具有很强的现实意义. 模型的进一步推广应用与可靠性检验是接下来的研究方向.
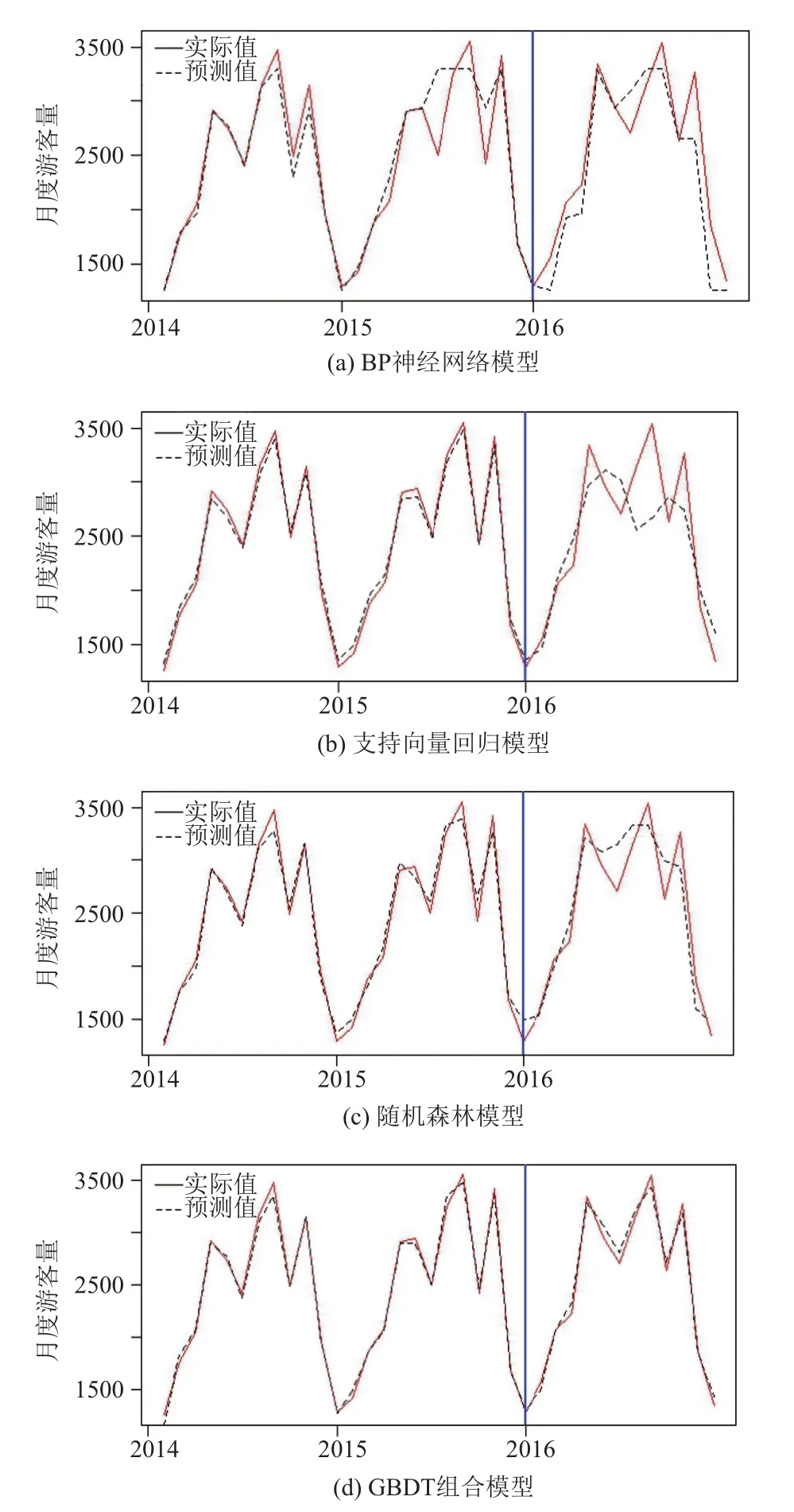
图4 各模型预测效果图
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
北方经贸(2017年4期)2017-06-30
人间(2016年27期)2016-11-11
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
山东青年(2016年2期)2016-02-28
新高考·高二数学(2014年7期)2014-09-18
海峡科学(2013年3期)2013-10-21
福建中学数学(2011年9期)2011-11-03
