
基于电信位置数据的人群流量预测
2018-07-13 03:28卢光跃李四维赵宇翔王天赐
西安邮电大学学报 2018年2期
卢光跃,李四维,赵宇翔,王天赐
(西安邮电大学 陕西省信息通信网络及安全重点实验室,陕西 西安 710121)
随着移动互联网的快速发展、基于位置服务的广泛应用,电信运营商收集了大量用户位置数据,这些位置数据具有丰富的时间和空间信息,对其进行深入有效的挖掘进而准确预测人群流量,可为电信运营商网络结构优化、网络资源合理配置等应用提供有效参考。
区域人群流量预测是指,采用时间序列预测方法对代表该区域人群流量的时间序列进行预测。传统的时间序列预测方法主要有线性回归[1]和自回归(auto regressive,AR)模型法[2-3]。这些方法对线性时间序列有较好的预测效果,但对非线性时间序列的预测效果不佳,而从电信位置数据中提取出的时间序列具有非线性特征,故需采用非线性时间序列预测方法对其进行预测[4]。常用的非线性时间序列预测方法,包括基于支持向量回归(support vector regression,SVR)的预测方法[5-7]、基于神经网络的预测方法[8-10]和经验模态分解(empirical mode decomposition,EMD)方法[11]等。基于神经网络的预测方法,有较强的非线性拟合能力,可映射任意复杂的非线性关系,且学习规则简单,便于计算机实现[12],若针对区域人群流量数据,引入人群流量时间序列的横向变化趋势[13],预测准确率还可以更最。
实际数据分析显示,当前时刻人群流量既与其横向变化趋势关联,还与前若干个自然日同一时刻的值(即纵向变化趋势)有关。本文综合考虑人群流量变化的横向和纵向趋势,同时考虑使用遗传算法(genetic algorithm,GA)对SVR算法的参数进行寻优,给出一种基于综合特征和GA的SVR区域人群流量预测算法,即对原始电信位置数据进行预处理,提取出反映区域人群流量的时间序列,综合考虑其横向变化趋势和纵向变化趋势,建立基于GA与SVR的融合算法GA-SVR模型,对区域人群流量进行预测。
1 区域人群流量时间序列预测模型
1.1 数据预处理
基于电信位置数据预测人群流量,首先需要从原始电信位置数据中提取中反映人群流量的时间序列。选用国内某市持续时间为1个月的电信位置数据,共包含5个字段:时间字段记录数据采集的时间;区域代码字段记录基站覆盖区域的代码;经纬度字段记录数据采集时设备的位置;MAC地址字段记录对应设备的MAC地址。
设备MAC地址唯一,可用于代表用户。故只需选定某个区域,选择时间范围和采样时间间隔,统计采样时间间隔内此区域中不同MAC地址出现的次数,由此即可得到反映该区域人群流量的时间序列。
1.2 初步建立预测模型
为了对区域人群流量时间序列进行建模,选择其中的m天数据,将其中前t天的数据作为训练样本,后m-t天作为测试样本。
当前时刻人群流量xs(k)与其横向变化趋势关联,即与人群流量时间序列中的前p个时刻的值xs(k-1),xs(k-2),…,xs(k-p)有关[13],据此可建立预测模型

此外,当前时刻人群流量还与其纵向变化趋势相关联,即与前q个自然日同一时刻的值xs-q(k),xs-q+1(k),…,xs-1(k)有关。为了提升预测精度,综合考虑该时间序列的横向变化趋势和纵向变化趋势,修订预测模型为
1.3 使用GA-SVR算法建立预测模型
支持向量机(support vector machine,SVM)作为一种机器学习算法,可用于模式分类和非线性回归,即建立一个分类超平面做为决策曲面,使得样本之间的隔离边缘被最大化[14]。回归是SVM的一个重要应用,SVR即是利用非线性映射φ(x),将原始空间中的量x变换到高维空间,然后在高维空间中进行线性回归,再将结果反过来映射到低维度空间中,如此间接实现低维空间中无法实现的非线性回归。以下选取SVR作为预测算法f。
g(x)=ωTφ(x)+b。
其中φ:n→F,ω∈F,F为向量集,ω的维数与特征空间维数相等,b为偏置。
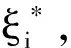
s.t.
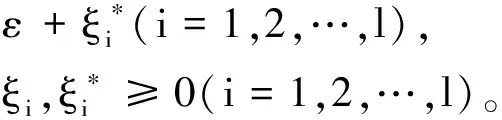
其中,C>0为惩罚系数,ε为敏感系数。数据样本满足ε-不敏感损失函数,即
|yi-g(xi)|ε=
max {0,|yi-g(xi)|-ε}。
由拉格朗日乘子法可得
根据卡鲁什-库恩-塔克(Karush-Kuhn-Tucker,KKT)条件,得对偶优化问题
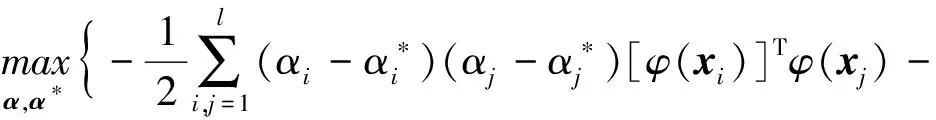
ωTφ(xi)+b-yi+ε=0,
所以有
其中K(xj,xi)=[φ(xj)]Tφ(xi)为核函数,满足Mercer条件[14],SSV是支持向量集。
综上得区域人群流量预测的支持向量回归模型
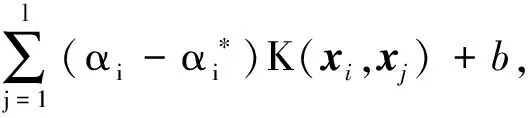
它依赖于核函数和参数的选择。
在此选择高斯径向基核函数
则SVR可调的模型参数有惩罚系数C、核函数参数σ和不敏感损失系数ε。
不敏感损失系数ε控制着SVR回归函数对样本数据的不敏感区域的宽度,影响支持向量的数目,其值和样本噪声有密切关系。ε过大,支持向量数就少,可能导致模型过于简单,学习精度不够;ε过小,回归精度较高,但可能导致模型过于复杂,得不到好的推广能力。随着ε的下降,误差趋于稳定,但求解时间增大。
为找到最优核参数σ和惩罚系数C,用GA优化SVR参数。优化的整体流程如图1所示。
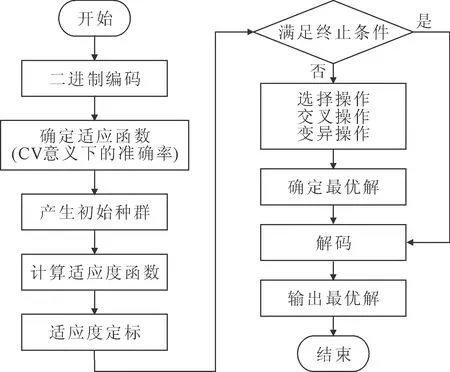
图1 利用GA优化SVM参数的算法流程
为了精确地评价预测性能的优劣,采用平均绝对误差(mean absolute error,MAE)eMA、平均绝对百分误差(mean absolute percent error,MAPE)eMAP和均方根误差(root mean square error,RMSE)eRMS来评价预测精度,它们分别表示为
2 仿真分析
验证所给算法的有效性。实验环境为Intel(R) Core(TM) i7-4 790 CPU @ 3.60GHz,内存16 GB,Windows 10 64位专业版操作系统,Python 2.7,Matlab R2013a软件。
2.1 数据预处理
原始电信位置数据如表1所示,其中共包含数据4 686 428条。

表1 电信原始数据集描述
选定区域代码为371 312的基站覆盖区域,选择时间范围为9月1日0时至30日24时,采样间隔为15 min,从原始电信位置数据中提取出时间序列,如图2(a)所示。其中,采样时间点500到2 000之间存在部分缺失值,需要借用灰度预测方法[15]进行填补。补全后的时间序如图2(b)所示。
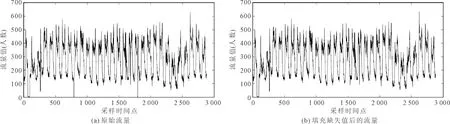
图2九月某区域时间序列
2.2 训练集和模型参数的选取
对于所提取出的时间序列,选取其中20天的数据,经进一步处理后,得出横向特征输入训练集和综合特征输入训练集。
利用训练数据,使用GA对其参数进行寻优, 得出基于SVR的预测模型参数,如表2所示。

表2 GA-SVR预测模型参数
2.3 区域流量预测仿真
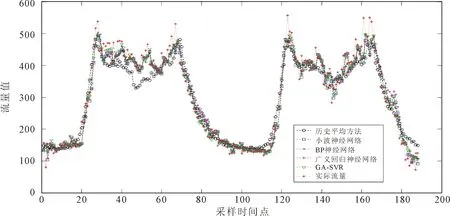
根据所选参数建立模型,对区域人群流量进行预测,结果如图3所示。由其可见,历史平均预测方法、小波神经网络方法、BP神经网络方法、广义回归神经网络方法与GA-SVR方法,均较好地反映出区域流量的变化规律。在图3的预测曲线中,当采样时间点处于20到28之间、70到80之间和115到125之间这些过渡阶段时,5种预测方法的预测结果与真实值相差很小,预测的流量能够较好地跟踪区域人群流量的实时变化趋势。但是,当流量值处于峰值或者低谷区域时,如采样时间点处于29至68之间时,历史平均预测方法不能很好地预测流量的变化趋势和数值,而其他4种方法则表现出更好的预测性能。预测性能指标如表3所示。
(a) 输入横向特征
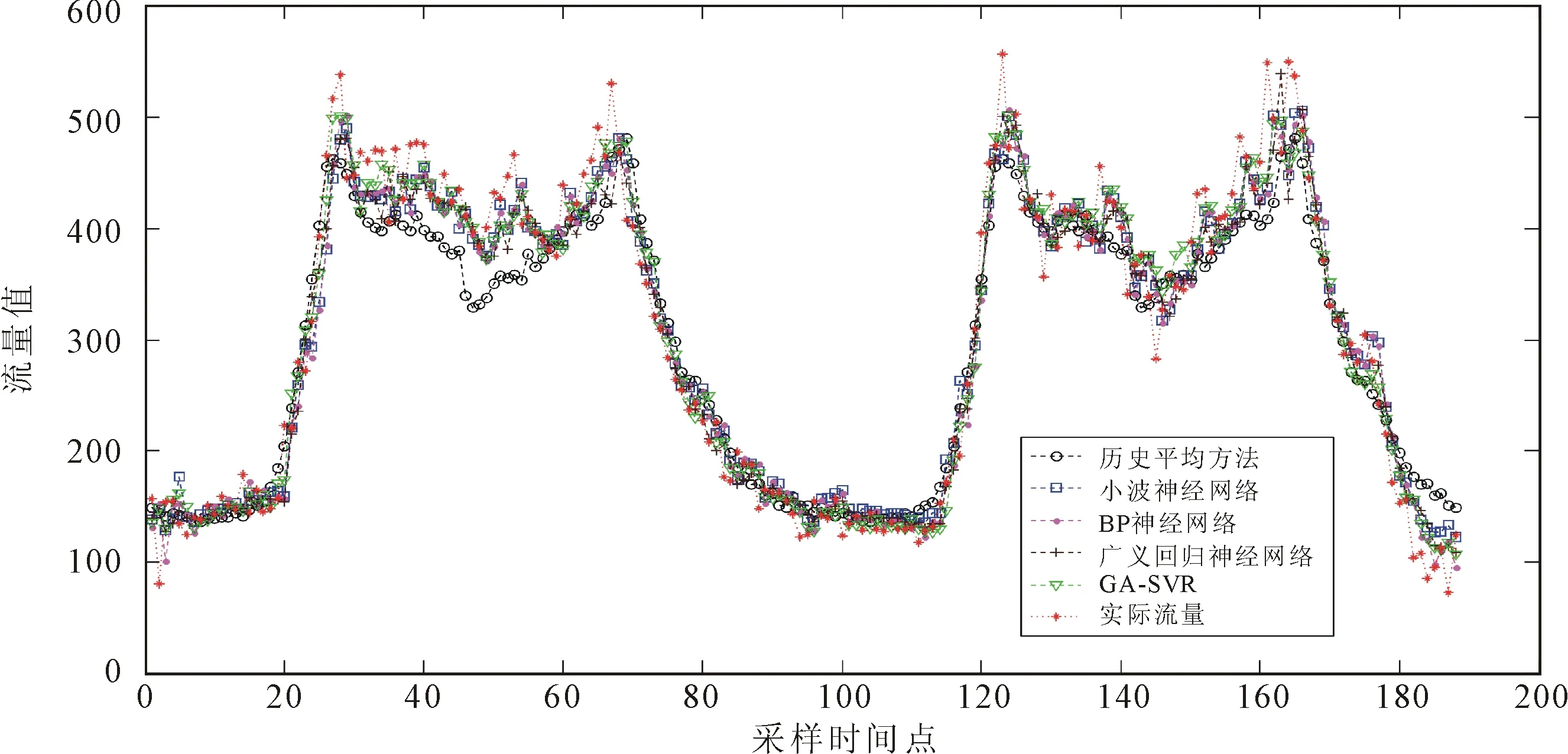
(b) 输入混合特征

表3 预测性能指标
当输入相同时,由表3可见,GA-SVR方法的3项性能指标数值均比其他方法低,算法的3项预测性能指标数值越低说明算法的预测精确度越高,预测性能越好。考虑区域人群流量的纵向变化趋势后,应用小波神经网络方法、BP神经网络方法、广义回归神经网络方法和GA-SVR方法,分别在电信数据集上进行实验,其性能指标数值均有所下降,这说明6种方法的预测精确度均得到提升。
3 结语
针对神经网络、传统SVM进行人群流量预测精度低的问题,综合考虑人群流量变化的横向和纵向趋势,并优化算法参数,给出一种基于GA-SVR的人群流量预测算法,与历史平均预测方法、小波神经网络预测方法、BP神经网络预测方法、广义回归神经网络预测方法和传统SVR方法对比,所给算法不仅可用于区域人群流量预测,且其预测精度更高。算法预测精度受特征选择和参数优化的影响较大,今后将重点研究如何更精确更有效地选择训练样本的特征,并根据不同数据集进行参数优化,以求进一步提升算法的精确度。
猜你喜欢
玩具世界(2022年2期)2022-06-15
房地产导刊(2021年8期)2021-10-13
出版人(2020年4期)2020-11-14
恋爱婚姻家庭(2020年27期)2020-10-09
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
百花洲(2018年1期)2018-02-07
瞭望东方周刊(2017年45期)2017-12-08
重型机械(2016年1期)2016-03-01
海军航空大学学报(2015年4期)2015-02-27
