
基于图模型及骨架信息的人体分割算法
2018-07-09 11:47:44岳焕景黄道祥宋晓林杨敬钰沈丽丽
天津大学学报(自然科学与工程技术版) 2018年8期
岳焕景,黄道祥,宋晓林,杨敬钰,沈丽丽
(天津大学电气自动化与信息工程学院,天津 300072)
人体分割是指从含有人的图像中将人的轮廓分割出来,它是 3D 人体重建[1]、3D 运动捕捉[2]和姿态估计[3]等应用的重要步骤,因此研究如何获取准确的人体分割结果具有现实意义.在实际场景中人体分割受到噪声[4]、遮挡、相似颜色和复杂背景等众多因素的影响,往往无法得到理想的结果,因此在复杂场景中如何获得准确的人体分割结果仍是一项十分具有挑战性的工作.Kinect v2相机利用时间飞行技术,获得的深度图像比第一代 Kinect准确性更高,其包含一个彩色相机和一个深度相机,为科研和工业获取RGB-D数据提供了极大地便利.除了提供RGB-D数据,Kinect v2也提供了采集场景中人的骨架信息.
近年来,国内外学者提出了大量的研究方案进行人体分割,根据使用图像信息的不同,可以分为 4类:基于彩色图的方法、基于深度图的方法、基于RGB-D的方法和基于骨架的方法.基于彩色图的方法利用图像物体间彩色信息的差异性,Gulshan等[5]用 Kinect深度相机采集图像数据集进行训练,先用自学习的线性分类器获得一个初始的分割结果,然后再利用自下而上的信息对初始分割结果进行精细化处理得到最后的结果.Rother等[6]用高斯混合模型分别对前景、背景建模,并采用迭代算法简化用户交互,少量的用户操作就可得到比较好的分割结果.Li等[7]利用在图割框架中结合从上而下和从下而上线索的数据驱动方法在静态图像中分割出人体轮廓,该方法通过探索人体运动学信息来帮助区分人体各部分,利用一个增强的分类器和 ICA-R本地学习方法来计算人体各部分的分布.Fernández-Caballero等[8]使用阈值和形状分析的方法解决人体分割问题.上述方法都只利用了图像的彩色信息,因此对于图像中颜色相近的物体不能准确分割.深度相机的流行为深度图的采集提供了便利,二维平面上相邻的物体往往具有不同的深度信息,因此利用深度可以有效地进行人体分割.Shotton等[9]利用深度图来提取人体动作,不需要依赖图像的帧间信息,只要使用单幅深度图像就可以快速预测人体动作,Hernández-Vela等[10]提出了在随机森林和图割理论基础上用深度图进行人体分割的方法.该类方法由于目前深度相机获取的深度图具有大量的噪声,深度缺失和低分辨率等不足,不能有效分割那些像素深度值错误或相近的区域.基于RGB-D的方法考虑深度、彩色图像对具有几何结构的相似性,Palmero等[11]获得彩色深度等不同特征的前景区域以减少搜索的区域,同时获得前景区域的特征描述,然后利用这些特征描述来学习概率模型,提升最后的分割效果.Vineet等[12]提出了一种建立在均值场基础上的姿态场模型,这种分割方法有效地减少了计算复杂度.此类利用彩色深度信息的人体分割算法,没有考虑到场景中人体本身这一重要信息,准确性有待提高.Junior等[13]提出了在骨架模型上寻找基于图的最大值路径的方法来产生人体分割轮廓.但是此种方法由于缺乏图像颜色信息,造成了不平滑的人体轮廓分割结果.
本文提出了一种联合RGB-D和骨架信息的人体分割算法,彩色深度对的几何结构相似性,克服单一颜色信息的不足,同时人体骨架可以提供人的轮廓信息,进一步提升了分割的准确性;此外,设计能量函数的数据项和平滑项,通过最小化能量函数来得到最后的分割结果.实验结果表明,与其他方法相比,本文方法具有较高的鲁棒性,在不同实际场景数据集中取得了比较理想的分割效果.
1 算法框架
本文提出的图模型使用 3种类型的信息:彩色图、深度图和相应的人体骨架.如图 1所示,所提出的方法包含2步:基于超像素聚集的过分割和基于图的超像素融合.在第 1步中,深度图和对应的彩色图作为输入,利用文献[14]给出的几何增强的超像素聚集算法得到超像素,这样得到的超像素更加紧凑且准确.超像素考虑了图像的 RGB-D信息,深度彩色弥补只利用单一信息的不足,从而更好地刻画物体边界.同时,与直接对像素进行处理的情况相比,这些超像素作为图的节点可以减少节点的数量,从而减少算法复杂度.第 2步为超像素融合,在图论优化框架下,结合 RGB-D和相应的人体骨架信息对这些超像素进行融合,从而得到最后的分割结果.
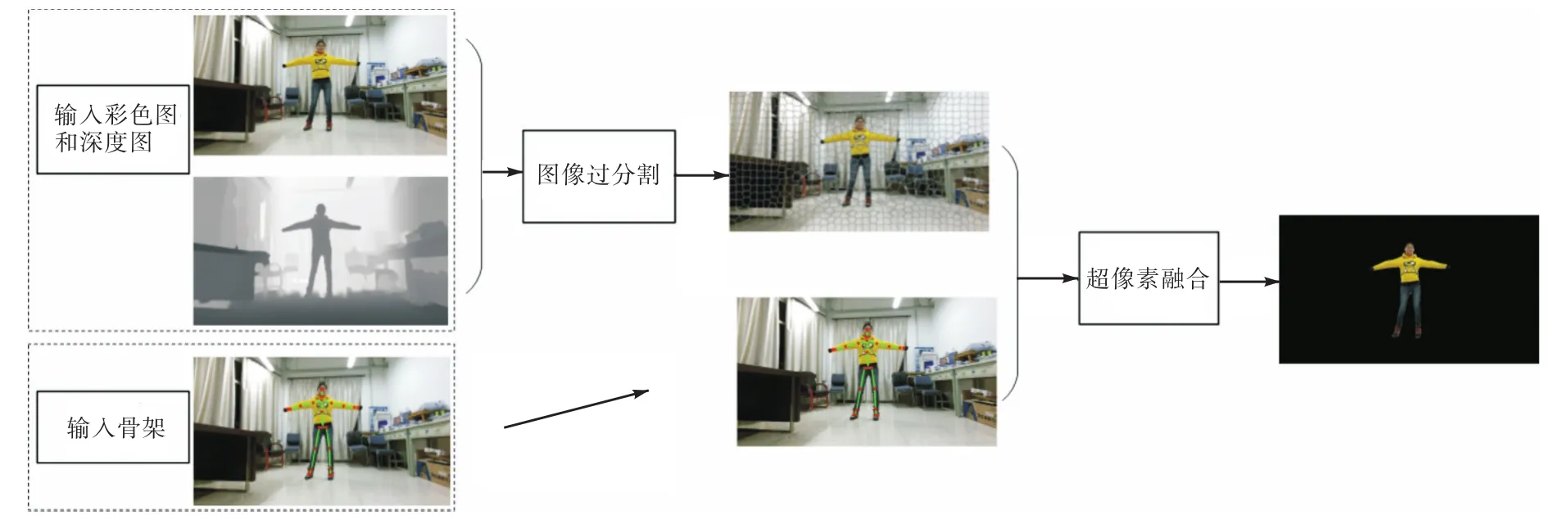
图1 基于RGB-D和骨架信息的人体分割框架Fig.1 Body segmentation framework based on RGB-D and skeleton information
人处于场景中时,图像的深度信息有助于区分颜色相近的物体.同时 Kinect深度相机可以采集得到一系列骨架节点的三维坐标信息,从而很好地提供了场景中人的位置和轮廓信息.通过联合 RGB-D和骨架信息,提出的方法能得到更加准确的人体分割结果.
2 深度图修复
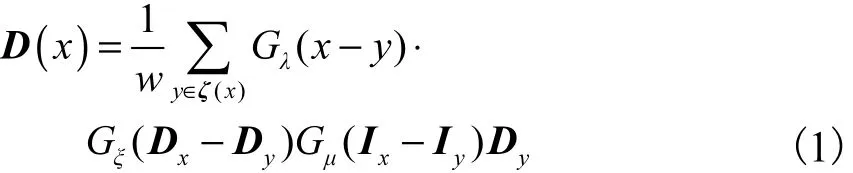
Kinect v2采集的彩色图像的分辨率为 1,920像素×1,080像素,而深度图的分辨率为512像素×424像素.本文利用 Kinect SDK将深度图扭转到彩色图坐标系下,得到相同分辨率的彩色图和深度图.扭转后的深度图存在较多的空洞区域,采用边缘引导的滤波方法[15]对其进行深度修复.引入彩色边缘图像控制深度扩散顺序,保证在空洞区域由外向内扩散填充,利用有深度值的像素向内逐步填充,缩小空洞区域直至修复完全部区域.针对边缘像素x的深度D(x ),滤波方程为式中:w为标准化系数;I为同一坐标系下的高质量彩色图像;ζ(x)为深度图D中像素x邻域内的可行集,由彩色图I中提取的彩色边缘图像E决定;y表示可行域ζ(x)内的像素位置;Dx为深度图D在像素x的粗略估计,由x周围邻域的平均值估计;Dy表示深度图中像素y位置处的深度值;Ix、Iy分别表示彩色图I中像素x、y位置处的彩色值;G(·)表示高斯核分别表示欧几里得空间距离、深度值差异和彩色空间差异,其下标λ、ξ、µ为对应项方差,实验中对应的值分别取200、100、6.边缘引导的滤波方法将稀疏的深度散点图中有效深度值扩散到整个图像,已恢复像素作为已知信息来修复空洞区域,逐步得到高质量的深度图像.修复结果如图2所示.

图2 深度图修复结果Fig.2 Recovery result of depth map
3 基于RGB-D和骨架信息的图模型
3.1 能量函数
s表示图像I中一个超像素,1,2,…,M}表示经过聚类算法得到的所有超像素的集合,这当中M表示集合中超像素的个数,表示所有的标签.则融合问题可以理解成每一个超像素s∈S分配一个标签,例如,定义能量函数为
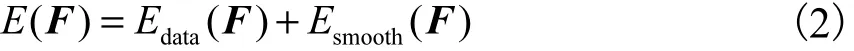
式中:Edata(F)表示数据项,反映超像素s被标记body和background的可能性;Esmooth(F )表示平滑项,反映相邻超像素对属于同一标签的相似度,利用α-expansion 算法[16]来最小化能量函数.
3.2 数据项
数据项衡量超像素和标签之间的相近程度.数据项越小,则表明超像素与标签之间的关联性越强.数据项定义为

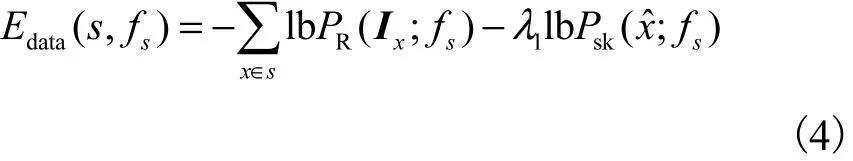
式中:λ1为参数表示一个超像素s连接到标签fs的可能性,其由两部分组成用来表示Ix被标记为fs的概率密度函数,用Ix来表示观测到的像素x的 RGB-D数据,包含了彩色和深度数据,超像素里的所有像素的来衡量整个超像素的彩色深度数据用来反映超像素种子点被标记fs的概率密度函数,ˆx是在超像素聚集阶段生成的超像素的种子点.用高斯混合函数来为数据分布建模,概率密度函数表达式为
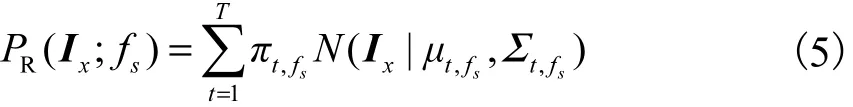
入高斯混合函数进行细致迭代.本文用sigmoid函数将超像素到背景和超像素到人体的距离映射到概率,其表达式分别为
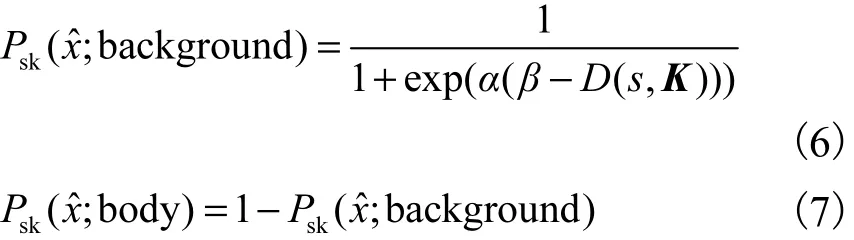
式中α、β是控制sigmoid函数坡度和相位的参数.α、β根据超像素种子点到骨架的距离设置成合适的值,实验中α=50,β=0.185 4.定义超像素属于人体部分的可能性与超像素到骨架的距离成反比,如果超像素越接近骨架,其属于人体部分的可能性就越大.D( s, K)表示超像素到骨架距离,即
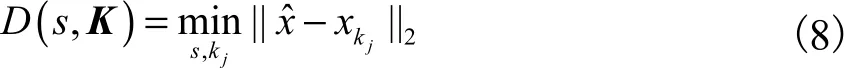
式中:K表示人体骨架,它由一系列骨架节点组成,,kj表示第 j个骨架连结点,J表示节点数量.超像素种子点到骨架最小距离如图3所示,黄线表示一个超像素种子点到部分骨架节点的距离,黑线表示超像素种子点到骨架的最短距离

图3 超像素种子点到骨架最小距离Fig.3 The minimal distance between the seed of superpixel and the skeleton joints
3.3 平滑项
平滑项衡量相邻超像素对之间的光滑程度.全图所有相邻超像素对的平滑程度加权为
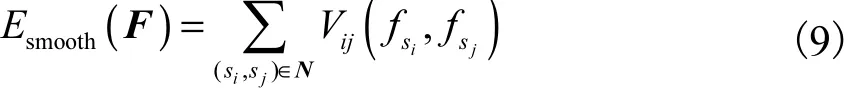
式中:表示相邻超像素对的代价值,只有当si和sj的标签不一样时,对应代价才会存在,否则,该项为零,N表示超像素对的集合定义为

其中对应代价为

式中:Ci,j和Hi,j分别表示连续性分量和直方图分量;λ2、λ3为控制参数.
连续性分量:利用其颜色信息的差异性衡量超像素间的差异.超像素是像素的组合,不能直接考虑相邻超像素之间的差异程度.为了衡量超像素间的差异程度,可以在边界上找到一个梯度变化最小的方向,作为超像素之间连接的方向,通过度量这个方向上的彩色差异程度,来计算连续性分量.用Ωij表示超像素si与sj相邻边界上的像素,那么连续性分量为
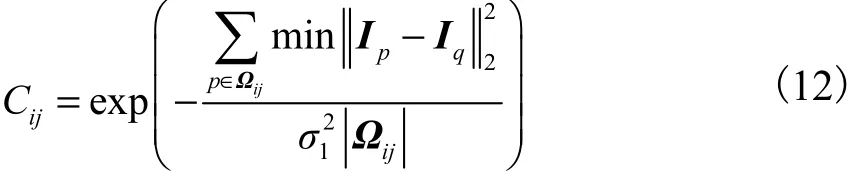
式中:Iq是像素p的8联通临域;表示在边界Ωij上的所有像素点个数;σ1是控制指数衰减的参数.
直方图分量:RGB-D数据直方图分量可以反映相邻超像素的趋近程度.超像素si和sj的 RGB-D 数据直方图矢量分别为hi和hj.每一个直方图都被归一化到和为一的范围.直方图分量可以表示为

式中:σ2是用来控制指数衰减的参数;mi和mj分别表示向量 hi和hj的均值,则相关系数ρ(hi, hj)的计算方法为

其中σi和σj是用类似的方法计算,计算公式为
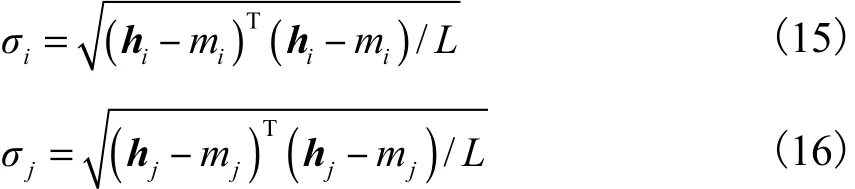
式中L是直方图中总的柱状条数.
4 实验结果和分析
利用 Kinect v2采集实际场景的图像为测试图像.实验中,参数设置为.本文使用手工标定的图像作为真值图,为比较不同算法下的分割结果,计算 the overlap score作为评价标准,其计算公式为
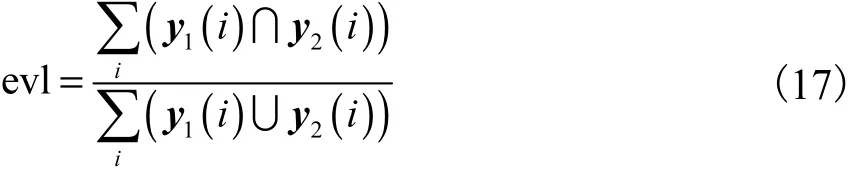
式中:y1和y2分别表示分割出的结果二值图和真值二值图;i表示像素.根据评价标准,其计算的结果越大,人体分割的效果越好.
比较 GrabCut算法[6]、GSC 算法[17]和本文的算法,分割结果如图 4所示,场景图像中人与背景处于不同距离.场景图从上到下依次记为 1~6,实验的前4组数据是利用一台Kinect v2相机在不同场景中采集的数据,后两组数据为同一场景下,由摆放在水平支架上的两台 Kinect v2相机拍摄所得,从而得到同一场景下不同视角的图像.从实验结果来看,本文所提出的算法获得的分割结果更加准确,如衣服和手脚处能够达到更好的分割效果.GrabCut算法在背景杂乱的时候,不能很好地处理人体边界.GSC算法对颜色分布和物体形状比较敏感,在第2组图像衣服处和第3组图像裤子处出现较大区域分割不清.从第5组和第6组图像实验结果来看,对于不同视角下的同一场景,所提出的方法在脚和上衣标签处仍能进行很好的分割,具有较高的鲁棒性.

图4 各算法的分割结果Fig.4 Segmentation results of several algorithms
Kinect v2相机采集深度图时的工作距离有一定的要求,最好在 0.8~3.0,m,同时精度受室外光线等因素干扰较大,所以本文的数据采集主要集中在室内.对分割结果进行评价指标计算,得到图4中6组实验的人体分割结果的the overlap score评价指标如表 1所示.相比于其他两种算法,本文算法显著地提高了the overlap score指标,平均能达到95.11%,,而GrabCut算法和GSC算法分别平均能达到79.74%,和91.23%,.本文方法比 GrabCut算法平均提高15.37%,,比GSC算法平均提高3.88%,.
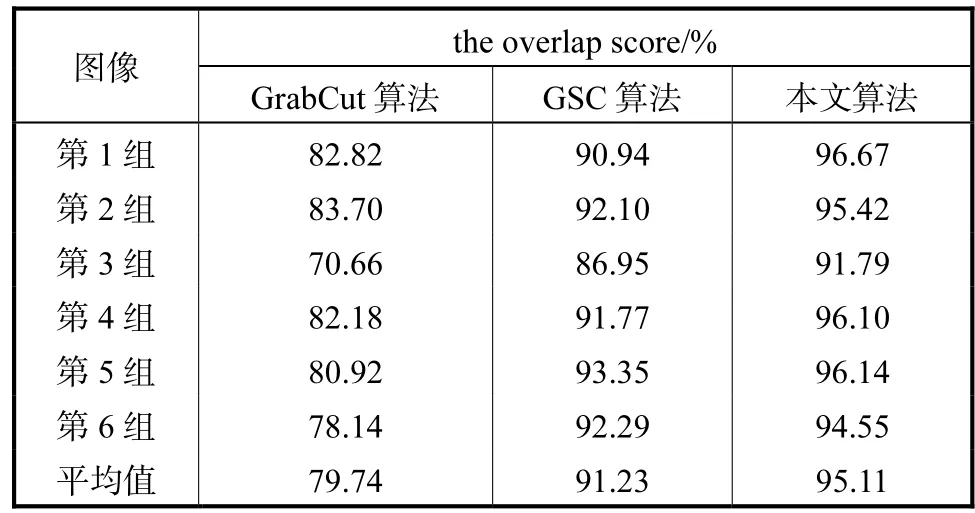
表1 3种算法the overlap score评价标准比较Tab.1 Comparison of the overlap score of three algorithms
Kinect相机内部自带的SDK也提供了一种人体分割方法,其利用彩色图和深度的映射关系,将彩色图上的像素点转换到深度图坐标系中,判断该像素点是否属于人体,若是则在彩色图取出,从而实现人体分割.如图 5所示,相比较本文提供的方法,SDK提供的方法在人接触其他物体的地方分割明显不理想.虽然这种方法可以实现实时分割,但是深度图像精确度不高,导致SDK方法的分割结果较差,在腿与背景物体相接触时,毛毯的大片区域被误认为是人体一部分而被分割了出来.脚也存在较大区域被误认为成背景区域而没有分割出来.而本文的方法在这些地方得到了较好的分割结果,显著提升了分割的质量.

图5 Kinect SDK方法和本文方法比较Fig.5 Comparison between Kinect SDK method and the proposed method
5 结 语
本文提出了一种基于图模型及骨架信息的人体分割算法,可以有效地在复杂场景中准确地分割出人体轮廓.在过分割阶段,利用修复的深度图和对应的彩色图像产生超像素;然后在图优化框架中,考虑人体骨架这一重要信息,并结合图像的 RGB-D信息,进行超像素融合得到最后的分割结果.实验结果表明,与其他方法相比,本文所提出的在图论优化框架中联合图像多种信息的方法,能够得到更加准确的人体分割结果.下一步的工作将考虑其他图像信息,并考虑实时场景中的人体分割.
参考文献:
[1]Graf H,Yoon S M,Malerczyk C. Real-time 3D reconstruction and pose estimation for human motion analysis[C]//IEEE International Conference on Image Processing. Hong Kong,China,2010:3981-3984.
[2]Liu Y,Gall J,Stoll C,et al. Markerless motion capture of multiple characters using multiview image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(11):2720-2735.
[3]Shakhnarovich G,Viola P,Darrell T. Fast pose estimation with parameter-sensitive hashing[C]//IEEE International Conference on Computer Vision. Nice,France,2003:750-757.
[4]刘正光,林雪燕,车秀阁. 基于二维灰度直方图的模糊熵分割方法[J]. 天津大学学报,2004,37(12):1101-1104.Liu Zhengguang,Lin Xueyan,Che Xiuge. Fuzzy entrogy segmentation method based on 2D gray histogram[J]. Journal of Tianjin University,2004,37(12):1101-1104(in Chinese).
[5]Gulshan V,Lempitsky V,Zisserman A. Humanising GrabCut:Learning to segment humans using the Kinect[C]//IEEE International Conference on Computer Vision Workshops. Barcelona,Spain,2011:1127-1133.
[6]Rother C,Kolmogorov V,Blake A. Grabcut:Interactive foreground extraction using iterated graph cuts[C]//ACM Transactions on Graphics. New York,USA,2004:309-314.
[7]Li S,Lu H,Shao X. Human body segmentation via data-driven graph cut[J]. IEEE Transactions on Cybernetics,2014,44(11):2099-2108.
[8]Fernández-Caballero A,Castillo J C,Serrano-Cuerda J,et al. Real-time human segmentation in infrared videos[J]. Expert Systems with Applications,2011,38(3):2577-2584.
[9]Shotton J,Sharp T,Kipman A,et al. Real-time human pose recognition in parts from single depth images[J].Communications of the ACM,2013,56(1):116-124.
[10]Hernández-Vela A,Zlateva N,Marinov A,et al.Graphcuts optimization for multi-limb human segmentation in depth maps[C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence,USA,2012:726-732.
[11]Palmero C,Clapés A,Bahnsen C,et al. Multi-modal RGB-depth-thermal human body segmentation[J]. Inter-national Journal of Computer Vision,2016,118(2):217-239.
[12]Vineet V,Sheasby G,Warrell J,et al. Posefield:An efficient mean-field based method for joint estimation of human pose,segmentation,and depth[C]// International Workshop on Energy Minimization Methods in Computer Vision and Pattern Recognition. Berlin,Heidelberg,Germany,2013:180-194.
[13]Junior J C S J,Jung C R,Musse S R. Skeleton-based human segmentation in still images[C]//IEEE International Conference on Image Processing. Orlando,USA,2012:141-144.
[14]Yang J,Gan Z,Li K,et al. Graph-based segmentation for RGB-D data using 3-D geometry enhanced superpixels[J]. IEEE Transactions on Cybernetics,2015,45(5):927-940.
[15]Ye X,Yang J,Huang H,et al. Computational multiview imaging with Kinect[J]. IEEE Transactions on Broadcasting,2014,60(3):540-554.
[16]Boykov Y,Veksler O,Zabih R. Fast approximate energy minimization via graph cuts[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2001,23(11):1222-1239.
[17]Gulshan V,Rother C,Criminisi A,et al. Geodesic star convexity for interactive image segmentation[C]//2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco,USA,2010:3129-3136.
猜你喜欢
小主人报(2022年24期)2023-01-24 16:49:29
儿童时代·快乐苗苗(2022年6期)2022-08-06 07:24:16
电子乐园·上旬刊(2022年5期)2022-04-09 22:18:32
中国新技术新产品(2020年5期)2020-05-06 03:36:28
学生天地(2019年33期)2019-08-25 08:56:18
计算机应用(2019年3期)2019-07-31 12:14:01
小天使·二年级语数英综合(2018年7期)2018-09-11 10:32:54
软件导刊(2016年9期)2016-11-07 22:22:57
科技视界(2016年2期)2016-03-30 11:17:03
中国煤层气(2014年3期)2014-08-07 03:07:45
