
江苏省汉族人群的23个Y-STR的遗传多态性和群体遗传学分析
2018-07-05 06:33王会品张明明陆天宇孙世珺王慧君
重庆医学 2018年18期
王会品,张明明,陆天宇,王 珂,孙世珺,王慧君
(1.南方医科大学法医学院,广州 510515;2.中山市人民医院分子诊断中心,广东中山 528403; 3.淮安市公安局,江苏淮安 223001;4.启东市公安局,江苏南通 226000;5.南京市公安局 210000)
人类Y染色体属于性染色体,其遗传标记几乎不发生回复突变,其序列结构特征能稳定地由父亲传给儿子,呈父系遗传。因此,在法医学个体识别、亲子鉴定、混合斑中男性成分的检测、种族起源、群体进化和民族迁移等方面都具有独特的应用价值。在Y染色体各种标记中,短串联重复序列(short tandem repeats,STRs)由于具有高多态性和高突变能力而被广泛使用,且Y-STRs可进行多重扩增。目前为止,Y-STR单倍型参考数据库(YHRD)已经获得大规模的Y-STR数据,以便为法医提供可靠的Y-STR单倍型频率(https://yhrd.org)。在公安机关,Y-STR单倍型分析用于追踪潜在家系中的男性嫌疑犯,通过相同或高度相似的Y-STR单倍型提供犯罪证据[1-2]。江苏省位于人群流动较大的长三角区域,是中国23个省份中人群最密集的地区,其复杂的文化背景和极其密集的人群亟需最新的Y-DNA分型技术为法医学亲缘排查提供信息,分析江苏汉族和世界各地其他人群的基因血缘关系。为了研究江苏汉族人群Y-STR的生物地理分布,笔者通过PowerPlex®Y23系统对13个地级市916名男性进行分型,分析江苏人群内部的分化,并与18个东亚人群对比。
1 资料与方法
1.1一般资料 共916名健康汉族男性在知情同意的情况下提供血液标本,其中常州207例、徐州147例、宿迁111例、无锡98例、连云港71例、盐城62例、淮安55例、苏州47例、南京41例、南通39例、镇江17例、扬州14例、泰州7例。均来自江苏汉族人群且为无关个体,至少三代居住在当地。采用Chelex-100法提取基因组DNA。
1.2方法
1.2.1STRs基因分型 试剂盒采用PowerPlex®Y23系统(美国Promega公司)。在美国Thermo Fisher Scientific公司9700型PCR扩增仪上进行多重PCR,在ABI3130XL DNA遗传分析仪上对扩增产物进行毛细电泳检测,并使用GeneMapperID-X软件进行基因型分析。
1.2.2质量控制 本实验室的Y-STR基因分型能力通过YHRD对于Y-STR单倍型质量检测。本文群体登记号为YA004256(https://yhrd.org)。经YHRD修正后,在遗传距离(RST)分析中去除了无效值、中间等位基因和基因拷贝数变异。根据国际法医遗传学会(ISFG)推荐、SCHNEIDER[3]提供的DNA多态性建议进行。
1.3统计学处理 使用Arlequin 3.0的直接计数法对Y-STR基因座等位基因频率和单倍型进行统计后,根据Neis的方法计算基因多样性(GD)[4]。计算法医学参数:单倍型多样性(HD)、识别能力(DC)和匹配概率(MP)。多拷贝基因座DYS385a/b常被用来分析组合单倍型。减去DYS389Ⅰ后,得到DYS389Ⅱ的等位基因。所计算的RST数值指小组内随机选择的等位基因相对于整个组的相似度,并使用YHRD推荐的多维标度图和Mega 6.0对邻接树进行可视化。基于RST值矩阵,采用MASS程序包(https://cran.r-project.org/web/packages/MASS/index.html)绘制MDS插图并获取初始值。
2 结 果
2.1单倍型和法医学参数 共发现912例不同的单倍型,包括908例(99.6%)单独的单倍型和4例(0.4%)重复出现2次的单倍型。此外,在DYS448和DYS456中观察到2个无效等位基因。另外,还发现3个微变异,即DYS458的16.1、DYS385的16.2、DYS448的19.2,都已在YHRD数据库中获得验证。
等位基因数目最少为DYS437的5个,最多为DYS458的13个,而且在DYS385a/b观察到76个不同的等位基因组合,除了DYS391、DYS438和DYS437,所有基因座的GD值都高于0.5。DYS385的GD值最高为0.960 7,因为该位点是由76个不同等位基因组成的多拷贝基因座(表1);最低的位于DYS438为0.394 2,因为该基因座上等位基因10的等位基因频率在所有基因座中最高,为0.753 3。
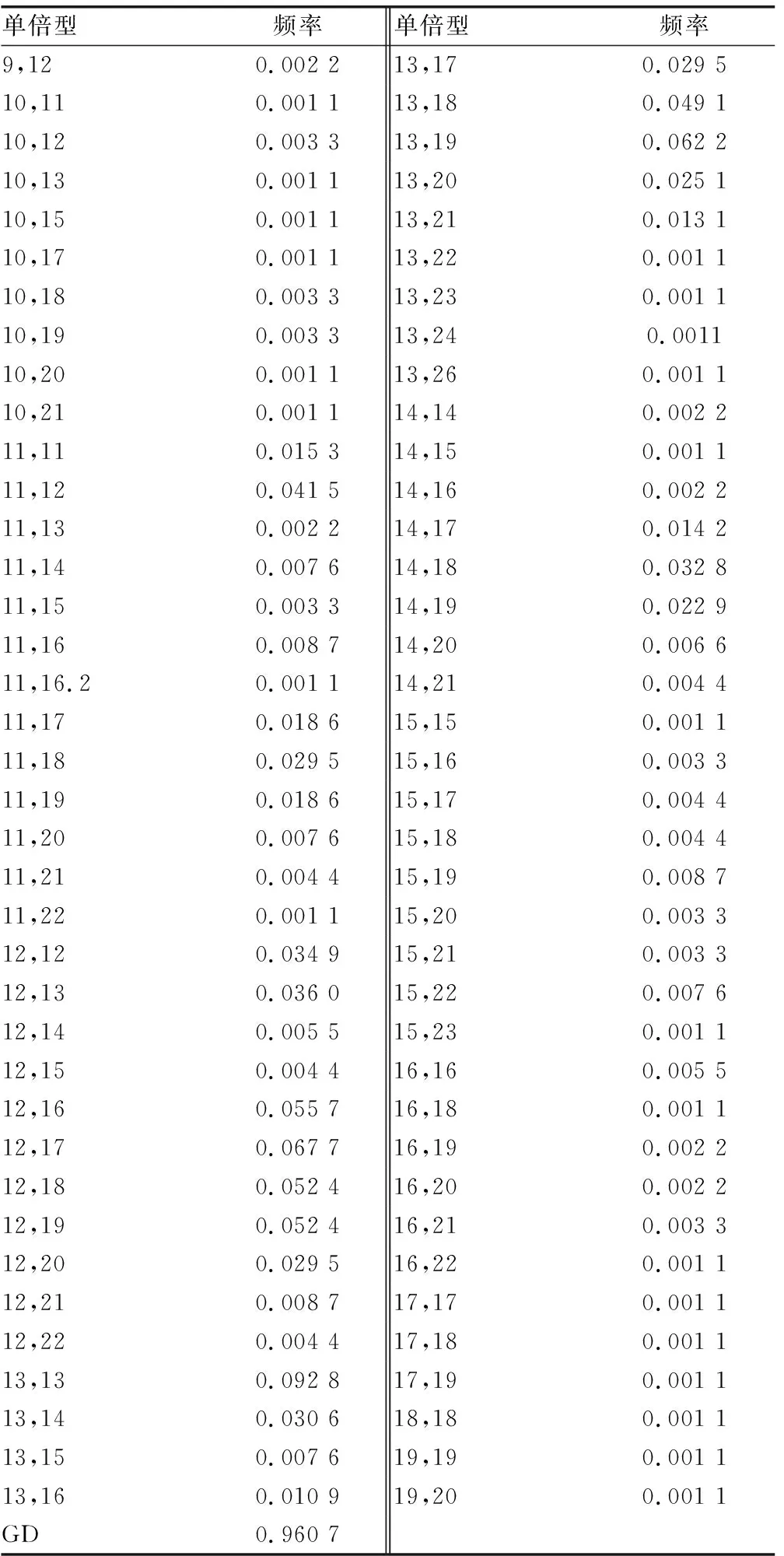
表1 江苏汉族人群多拷贝DYS385位点单倍型的频率分布及法医学参数(n=916)
GD:基因杂合度
2.2连锁不平衡分析 江苏汉族23个Y-STR的连锁不平衡分析见图1。在253个成对比较中,233个显示出连锁不平衡(黑边红色区域)状态,占92.1%。
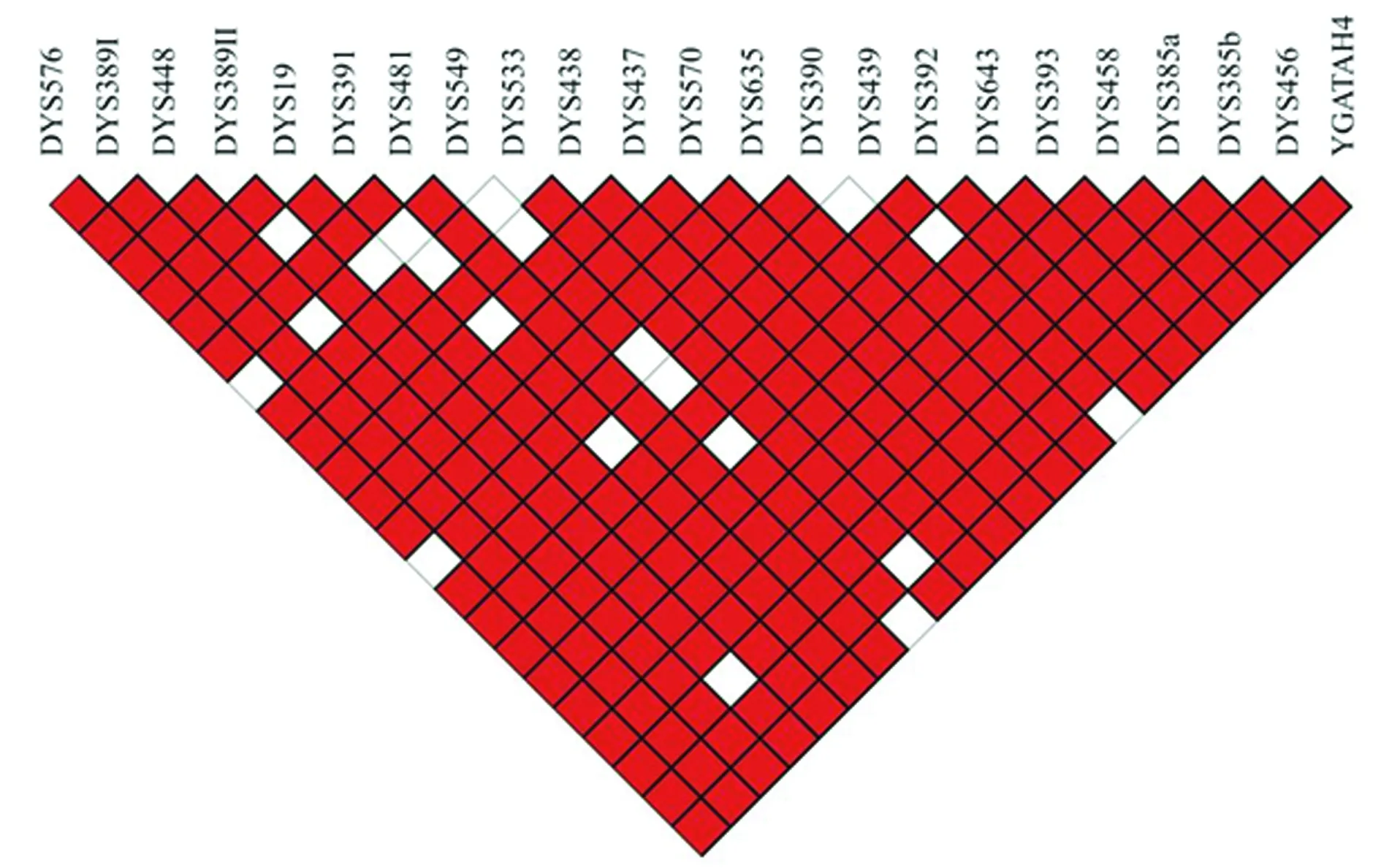
图1 江苏汉族23个Y-STR的连锁不平衡分析
2.3人群内差异 江苏省10个地级市的成对RST遗传距离和显著性差异见表2。镇江、扬州、泰州汉族人群因样本量小,无法反映其地区综合的遗传背景特征而被排除。这10个地区之间几乎没有差异。遗传距离最小的是徐州汉族与南通汉族(RST=0.000 0,P=0.144 1),连云港汉族与南通汉族的遗传距离最大(RST=0.029 2,P=0.045 1)。另外,徐州汉族和无锡汉族(RST=0.010 1,P=0.000 0),盐城汉族和无锡汉族(RST=0.015 3,P=0.036 0),连云港汉族和无锡汉族(RST=0.012 8,P=0.036 0),盐城和南通汉族(RST=0.026 9,P=0.018 0)比较,差异均有统计学意义(P<0.05)。经Bonferroni校正,只有无锡汉族和徐州汉族之间仍有明显差异(P=0.000 9)。江苏10个地级市的最佳邻接树,见图2。分枝长度之和(SBL)为0.015 663 28。邻接树中的10个江苏汉族人群并不符合地理分布。这一系统的重建显示了淮安和无锡汉族、南通和宿迁汉族之间的密切关系,南京与盐城汉族联系最紧密,其次是与连云港汉族、再次是与苏州汉族。为进一步验证,绘制多维标度图,其初始值达到0.008 24,表明结构重建水平为完美(图3),受到认可。盐城汉族和连云港汉族,南通汉族和无锡汉族之间的遗传关系与邻接树类似。此外,无锡、苏州、常州、南京汉族分散在多维标度图中。
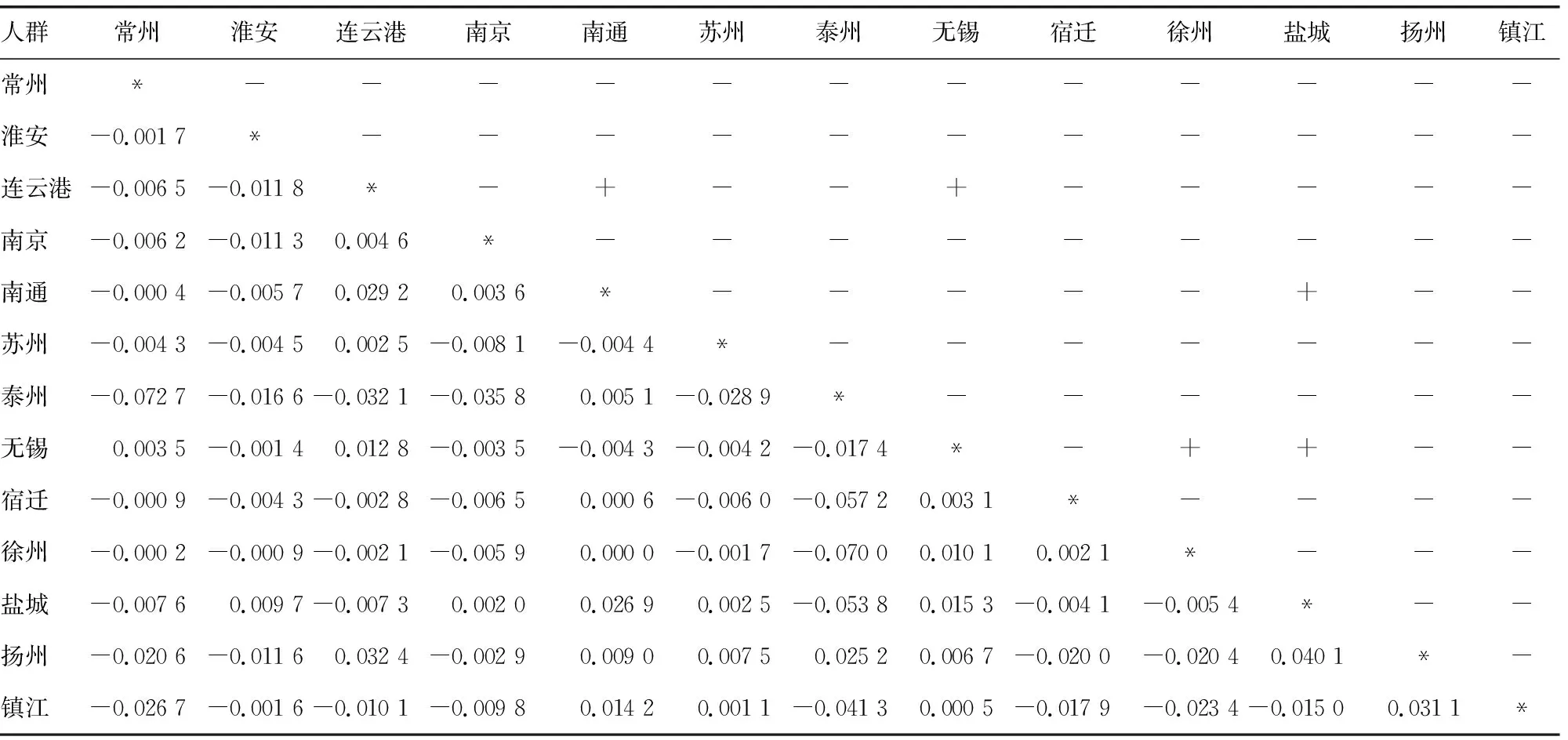
表2 江苏省13个地级市多个汉族人群RST值遗传距离矩阵
+:P<0.05;-:P>0.05;对称轴上:对应的P值;对称轴下:RST值;*:无数据
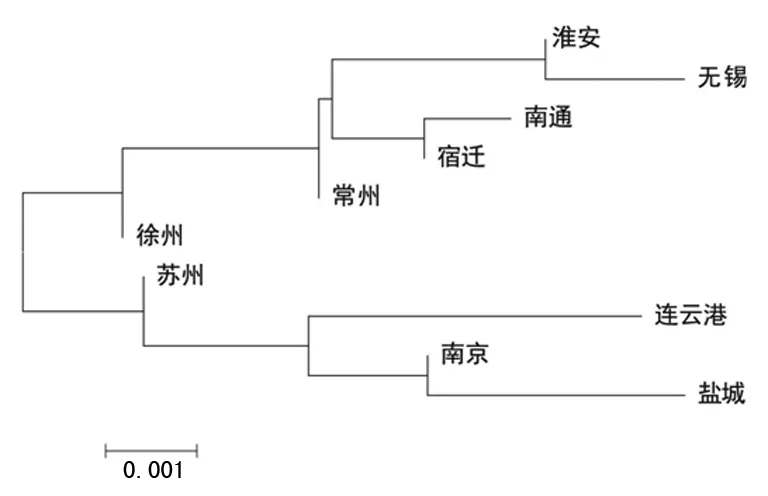
图2 江苏10个地级市的最佳邻接树
2.4人群外差异 分析江苏汉族人群和其他18个东亚人群(北京汉族、成都汉族、群马日本人、京族、茨城日本人、吕宋菲律宾人、菲律宾人、汕头汉族、静冈日本人、新加坡汉族、新加坡印度人、新加坡马来西亚人、韩国人、南方汉族、东京日本人、傣族、宣威汉族、白族)的差异。江苏汉族人群内部的数值均小于0.000 3(Bonferroni校正值的0.05/171)。江苏汉族人群与其他18个人群的成对RST值大于江苏汉族人群内部数值。江苏汉族人群与茨城日本人(RST=0.034 1,P=0.000 0)、吕宋岛菲律宾人(RST=0.009 5,P=0.000 0)、汕头汉族(RST=0.090 6,P=0.000 0)、新加坡汉族(RST=0.041 0,P=0.000 0)、新加坡印度人(RST=0.113 6,P=0.000 0)、新加坡马来西亚人(RST=0.079 9,P=0.000 0)和韩国人(RST=0.018 2,P=0.000 0)有明显差异。剩下11个人群,包括4个中国汉族,与江苏汉族人群的遗传距离都很接近。与地理位置一致,新加坡印度与江苏汉族的遗传距离最大。
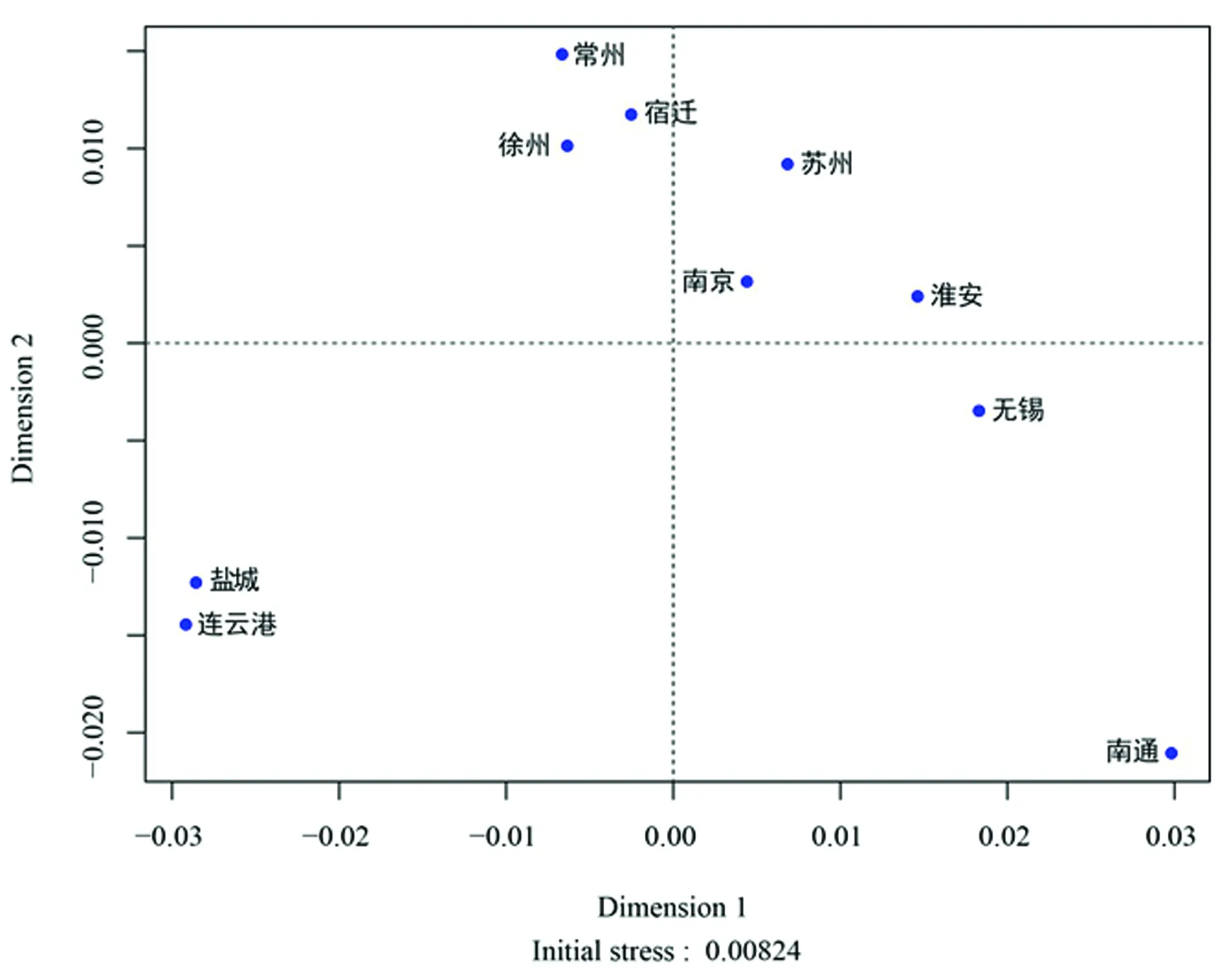
图3 江苏省10个地级市的多维标度图
此外,绘制上述人群的邻接树(图4)和多维标度图(图5),并标注语言的亲缘关系。19个东亚人群的分支长度测试结果(SBL=0.071 320 81)大于江苏省13个市的结果。系统发育树清楚表明,江苏汉族和傣族来自同一个节点,其次是宣威汉族和北京汉族,都属于汉藏语系。源自阿尔泰语系的5个人群(群马日本人、静冈日本人、韩国人、东京日本人和茨城县日本人)相距较近,与含有江苏汉族的那束相比,位于邻接树的另一侧。
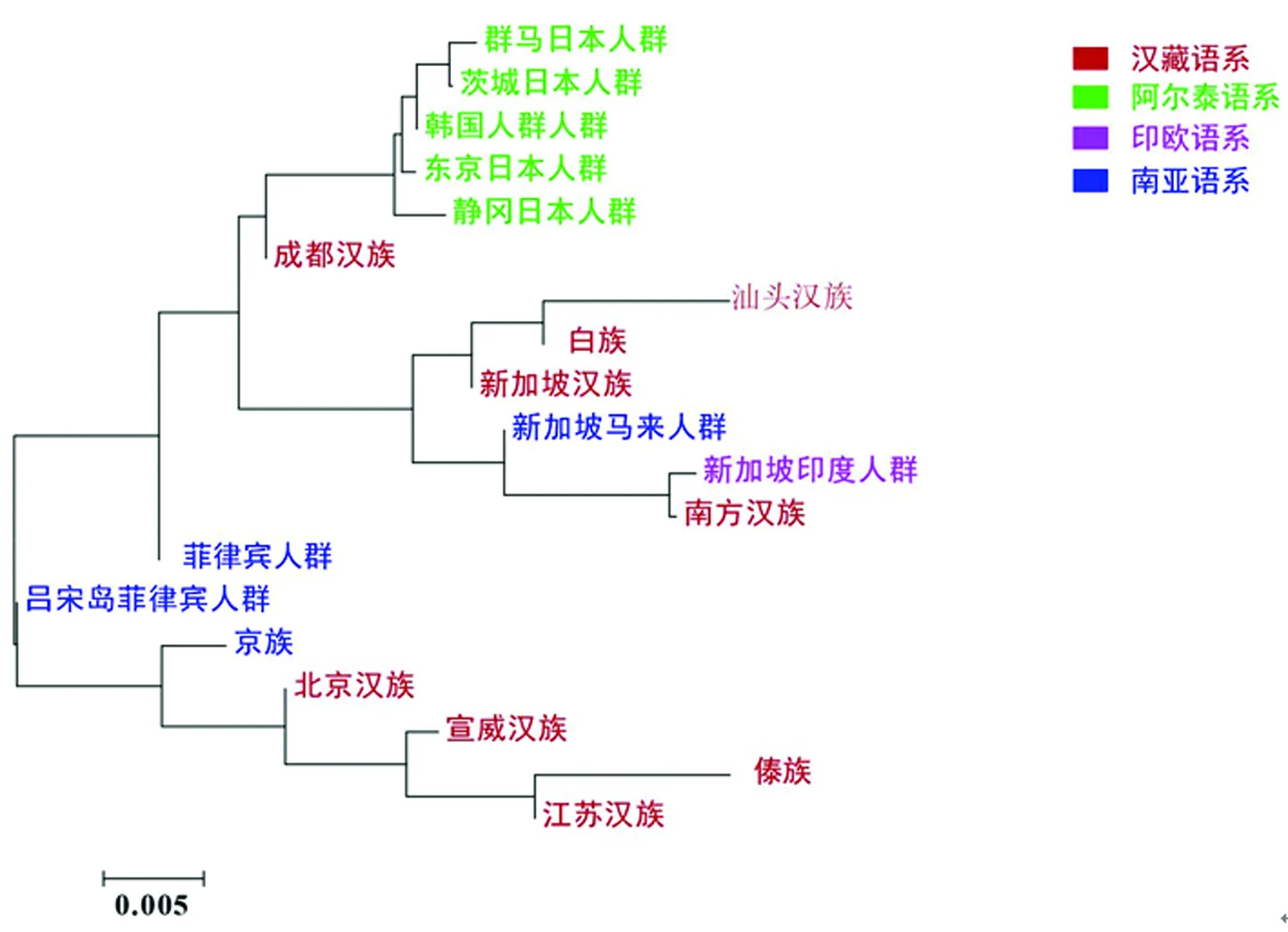
图4 江苏汉族和19个东亚人群的邻接树
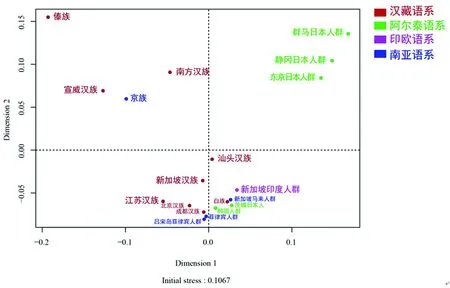
图5 江苏汉族和19个东亚人群的多维标记图
如图5所示,多维标度图的初始值为0.106 7,具有良好的可信度。江苏汉族、北京汉族、成都汉族和新加坡汉族人群聚集在左下象限中。此外,江苏汉族距群马日本群体、静冈日本群体和东京日本群体较远,大致符合邻接树的结果。结构重建表明,江苏汉族与北京汉族(北方汉族)的关系最密切。
3 讨 论
在人类群体遗传学中,遗传距离是群体间遗传差异和遗传分化的重要指标。系统发生树常用来描述某一群有机体发生或进化关系的拓扑结构,可直观地描述人种或群体之间的进化关系。本研究对916名来自江苏汉族无关个体的健康男性DNA样品进行23个Y-STR基因分型。总共发现912例不同的单倍型,其中包括908例单独的单倍型(99.6%)和4例重复出现2次的单倍型(0.4%),表明PowerPlex®Y23系统中包含的23个Y-STR在江苏汉族人群中具有高度多态性(HD=0.999 995 2),法医学应用也有极大的价值(DC=0.995 6,MP=0.001 1)。GD值最高为DYS385的0.960 7,最低值为DYS438的0.394 2。连锁不平衡分析详细地阐述了将这些标记物作为单倍型分析的必要性。与江苏汉族人群相似,DYS438等位基因10的频率在辽宁汉族、广东汉族、湘南韩族和韩国的相同位点中也最高。然而,其根本原因尚不清楚,这种遗传现象可能与群体遗传学中的人群瓶颈有关,从而导致遗传漂移[6]。同样,这也可能是由始祖效应引起,从新成立的群体角度来看,后代的遗传多样性严重依赖于早期的大量移民[7]。因此,随机化可能导致人群中最多数的等位基因不同。除去DYS385、DYS458的GD值最高,因其在单拷贝基因座中具有最多的等位基因。各种法医学参数的分布表明,江苏汉族人群遗传多样性较高。
徐州和无锡地理位置相距较远,分别位于江苏省最北部和最南部,这导致重大遗传分化。来自苏南的汉族人群与来自苏北的汉族人群关系密切,这证明了江苏汉族人群的同质性很高。多维标度图的结果与邻接树重建结果一致。常州、连云港、南通汉族人群在第1、2维度上是3个异常值,可能原因是这3个地级市均位于江苏省的边缘地区,与邻近省份的人群有频繁的基因交换。将苏南和苏北汉族人群基因联系起来,发现苏南吸收了许多来自苏北的流动人口。江苏省10个地级市汉族人群的遗传特征主要有两个方面:(1)苏南和苏北汉族人口的显著差异;(2)现代生活方式不断影响苏南各族人群的人群结构,另外从基因流动的角度,江苏汉族人群频繁的交互将其联系到一起。
在人类起源的研究中,东亚地区一直是研究人类起源与迁徙过程中的一个重要节点。东亚人群中一系列的mtDNA研究显示,东亚现代人群来源于一个共同的祖先群体。从亚洲有限数量群体的mtDNA多态的研究表明,东亚人群起源于同一祖先[8-11]。在东亚人群水平上,只有淮安汉族和南通汉族的人群数据和相应的遗传背景此前被收集和分析过[12],发现江苏汉族人群与全国范围内汉族群体的遗传关系很近。综合考虑考古学分析、Y染色体单核苷酸多态性、常染色体短串联重复序列和常染色体单核苷酸多态性的分析,中国北方和南方汉族之间存有显著差异[13]。考虑到江苏省处于南北方的边缘地带,并且有复杂的历史人群变动,江苏汉族人群来自南方还是北方仍无定论。结合邻接树和多维标度图,本研究对江苏汉族内部和江苏汉族与所引用18个东亚人群的成对RST遗传距离和P值进行了分析,客观地说明了江苏汉族人群的遗传背景。笔者第一次描绘了江苏汉族人群的内在差异和遗传特征。另外,就东亚层面而言,江苏汉族人群主要来自北方汉族。
综上所述,本研究通过分型916例个体23个Y-STR遗传标记,丰富了江苏汉族的法医学分子数据库,有利于推动对人群遗传学和分子人类学的认识。本研究初步阐述了江苏汉族人群的内部和人群间遗传结构。为了更好地推断江苏汉族的起源和分布,笔者建议对不同遗传标记进行更多的基因分型。本研究的局限性在于江苏人群内部的样本量不一致,可能对结构重建有一定影响。接下来,笔者将从江苏汉族人群中选出更具代表性的样本,以更全面、更科学地从法医学角度解释江苏汉族遗传背景与人群交互。
[1]GOPINATH S,ZHONG C,NGUYEN V,et al.Developmental validation of the Yfiler Plus PCR Amplification Kit:an enhanced Y-STR multiplex for casework and database applications[J].Forensic Sci Int Genet,2016,24:164-175.
[2]PURPS J,SIEGERT S,WILLUWEIT S,et al.A global analysis of Y-chromosomal haplotype diversity for 23 STR loci[J].Forensic Sci Int Genet,2014,12:12-23.
[3]SCHNEIDER P M.Scientific standards for studies in forensic genetics[J].Forensic Sci Int,2007,165(2/3):238-243.
[4]贺永锋,陈利萍,赵杰,等.陕西渭南地区汉族人群17个YSTR基因座多态性及遗传关系分析[J].人类学学报,2014,33(2):230-233.
[5]WEN B,XIE X,GAO S,et al.Aaalyses of genetic structure of Tibeto-Buman populations reveals sex-biased admixture in southern Tibeto-Burmans[J].Am J Hum Genet,2004,74(5):856-865.
[6]王永在,王勇,黄太宇,等.内蒙古汉族人群17个Y-STR 基因座遗传多态性[J].国法医学杂志,2009,24(2):117-118.
[7]宋兴勃,范红,应斌武,等.成都地区汉族人群17个Y短串联重复序列基因座遗传多态性分析[J].南方医科大学学报,2009,29(10):1973-1976.
[8]窦雪丽,王瑛,刘宏,等.广东汉族人群24个Y-STR 基因座多态性及法医学应用[J].新医学,2014,45(12):796-800.
[9]张蒙,饶健安,赵艳超,等.基于STR基因频率探究我国32个行政区域汉族亚群的遗传特征[J].中山大学学报(自然科学版),2014,53(1):106-112.
[10]WEN B,LI H,GAO S,et al.Genetic structure of Hmong-Mien speaking populations in East Asia as revealed by mtDNA lineages [J].Mol Biol Evol,2005,22(3):725-734.
[11]SAHA A,SHARMA S,BHAT A,et al.Genetic affinity among five different population groups in India reflecting a Y-chromosome geneflow[J].J Hum Genet,2005,50(1):49-51.
[12]YIN C Y,JI Q,LI K,et al.Analysis of 19 STR loci reveals genetic characteristic of eastern Chinese Han population[J].Forensic Sci Int Genet,2015,14:108-109.
[13]CHEN J,ZHENG H,BEI J X,et al.Genetic structure of the Han Chinese population revealed by genome-wide SNP variation[J].Am J Hum Genet,2009,85(6):775-785.
猜你喜欢
医学与法学(2020年3期)2020-09-18
医学与法学(2020年3期)2020-09-18
医学与法学(2020年2期)2020-07-24
新生代·下半月(2019年7期)2019-09-10
刑事技术(2018年2期)2018-05-05
中国现当代社会文化访谈录(2016年0期)2016-09-26
中国继续医学教育(2015年4期)2016-01-07
新疆大学学报(哲学社会科学版)(2015年4期)2015-10-12
中国司法鉴定(2015年4期)2015-02-28
中国司法鉴定(2015年4期)2015-02-28
