
基于深度卷积神经网络的隧道衬砌裂缝识别算法
2018-06-28 02:03柴雪松朱兴永李健超辛学仕
铁道建筑 2018年6期
柴雪松,朱兴永,李健超,薛 峰,辛学仕
(1.中国铁道科学研究院集团有限公司 铁道建筑研究所,北京 100081;2.中国铁路兰州局集团有限公司 工务处,甘肃 兰州 730000;3.北京邮电大学,北京 100876)
隧道衬砌裂缝会影响隧道的稳定性,严重时危及列车运行安全,因此必须及时对衬砌裂缝进行有效识别。传统的检测方法是以人工目视检查为主,检测效率很低,检测质量也难以保证。为此,国内外相继研制了基于图像处理的隧道衬砌质量检测系统,实现了对隧道衬砌图像的快速采集,并开展了裂缝自动识别的研究。中国铁道科学研究院于2017年自主研制了隧道衬砌表面状态检测系统[1],能以50 km/h的速度采集含1 mm以上衬砌裂缝的图像,并实现了对图片中衬砌裂缝的快速准确识别。本文对该系统中的衬砌裂缝快速识别算法予以介绍。
隧道图像具有复杂的特性,既有水渍、污染及其他结构缝的存在,又有光照不均匀、噪声繁多、分布不规律的情况。这些都给传统的图像处理方法带来了发展瓶颈。近年来人工智能逐步发展,其中尤为重要的深度学习技术已经全面渗透计算机视觉领域,并且取得了傲人的成绩。本文提出的基于计算机视觉的衬砌裂缝自动识别算法正是将深度学习开创性地应用到传统的衬砌裂缝识别领域。这是一种有监督的学习方式,采用深度卷积神经网络能够更好地提取图像更深层次的特征,能做到在识别裂缝时不受或者少受环境因素干扰。试验表明,这一算法具有很高的识别率,同时时间性能优异,应用价值极高。
1 国内外研究情况
1.1 基于图像处理的裂缝检测法
目前,基于图像处理的裂缝检测已经取得了很多研究成果。国外,出现了基于网络分析的裂缝检测算法和基于最小路径的裂缝检测算法。此类方法不适合处理被严重噪声污染的图像。FUJITA等[2]提出了一种两步处理的算法。该算法能有效地去除图像中不均匀光照、阴影、污点等引起的噪声。后来,产生了一种利用形态学处理和逻辑回归的统计学分类的裂缝检测算法[3]。该算法对裂缝提取的精度超过80%,但是该算法会漏检一些细小的裂缝且计算量较大,效率低下。国内,李刚等[4]提出了一种基于Sobel算子和最大熵法的图像分割算法,褚燕利[5]提出了一种基于灰度图像及其纹理特性的裂缝特征提取算法。卢晓霞分析和比较了多种经典的算子,王晓明等提出了一种基于多图像和多分辨率的路面裂缝检测方法[6]。该方法使用了图像融合技术,而且多尺度的方法很好地保存了图像的集合特性,极大地提高了裂缝检测的可靠性和精度。随着机器学习方法的快速发展,结合机器学习方法和图像处理的裂缝识别算法不断涌现。
1.2 深度学习在图像分类中的发展
深度学习(deep learning)这一概念由Hinton等[7]于2006年提出。首先提出的是自动编码器的多层次结构模型,后来在限制玻尔兹曼机(Restricted Boltzmann Machine,RBM)的基础上拓展出了深度置信网络(Deep Belief Network,DBN)。它是一种无监督性逐层训练算法,在优化并解决深层结构问题方面有很大改善[8]。另外,SERMANET等[9]提出了卷积神经网络(Convolutional Neural Netwok,CNN)——一个较为直观的多层结构网络学习算法,利用图像空间信息减少训练参数数量从而在提高模型训练性能方面有了很大改善。深度学习通过分层式结构的多层信息处理来进行非监督的特征学习和图像分类,模拟人脑学习和分析的能力,形成一个神经网络[10-12]结构。它可以像人脑一样对外界输入事物进行分析和理解,该网络优势被广泛应用于图像、文本、声音等研究领域。
图像分类是要解决图片中是否包含某类物体的问题,对图像进行特征描述是物体分类的主要研究内容。一般说来,物体分类算法通过手工特征或者特征学习方法对整个图像进行全局描述,然后使用分类器判断是否存在某类物体。应用比较广泛的图像特征有SIFT,HOG,SURF等。这些对图像分类的研究中,大多数特征提取过程是人工设计的,通过浅层学习获得图像底层特征,与图像高级主题间还存在很大的“语义鸿沟”。而深度学习利用设定好的网络结构,完全从训练数据中学习图像的层级结构性特征,能够提取更加接近图像高级语义的抽象特征,因此在图像识别上的表现远远超过传统方法。
卷积神经网络在特征表示上具有极大的优越性,模型提取的特征随着网络深度的增加越来越抽象,越来越能表现图像主题语义,不确定性越少,识别能力越强。AlexNet的成功证明了CNN网络能够提升图像分类的效果,其使用了8层的网络结构,获得了2012年ImageNet数据集上图像分类的冠军[13],为训练深度卷积神经网络模型提供了参考。2014年GoogleNet另辟蹊径,从设计网络结构的角度来提升识别效果[14]。其主要贡献是设计了Inception模块结构来捕捉不同尺度的特征,通过1×1的卷积来进行降维。2014年另外一个工作是VGG,进一步证明了网络的深度在提升模型效果方面的重要性[15]。2015年最重要的一篇文章是关于深度残差网络(ResNet),文章提出了拟合残差网络的方法,能够做到更好地训练更深层的网络[16]。后续分类网络的发展如Google的inception系列,2017年的主流模型比如获得最佳论文奖的DenseNet等都借鉴了ResNet的设计思想。本文的模型也是基于ResNet的基础网络设计的。
1.3 基于深度学习的图像分割方法
虽然深度学习在图像分类和目标检测上取得了巨大的进步,但仍有人质疑深度学习在工程中的应用效果。因为它无法很好地解决图像识别的另一大任务——图像分割。图像分割与图像分类的最大区别是图像分割要实现对每个像素的分类。而真正解决这一问题的是2015年CVPR的一篇图像语义分割的文章FullyConvolutionalNetworksforSemanticSegmentation,自此以后一系列的用于图像分割的改进神经网络模型被提出,从FCN,DecovNet,DilatedNet到DeepLab,PSPNet,分割精度进一步提升。
2 算法设计与实现
针对文献[1]中研制的隧道衬砌表面状态检测系统所获取的隧道衬砌图片,建立的衬砌裂缝识别算法的流程如图1 所示。
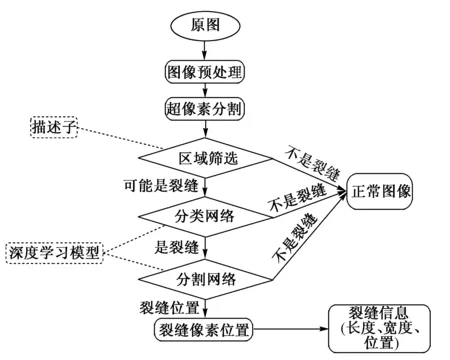
图1 衬砌裂缝识别算法流程
2.1 超像素分割(Simple Linear Iterative Clustering,SLIC)
通过相机获取的原始隧道图片(4 096×4 096)过于庞大,为便于处理,需要对其进行切分。由于裂缝分布的不均匀性,普通的切分方法极有可能使裂缝出现在切分图的边缘,对后续的分类模型训练造成负面影响。因此,本文采用SLIC超像素分割方法对原图进行分割,按照生成的一定数量的超像素对原图进行切分。裂缝的形状多为细长形,本文针对这一特点做了相应的算法改进,同时也做了大量试验对SLIC超像素分割进行优化和加速。该过程如图2所示。
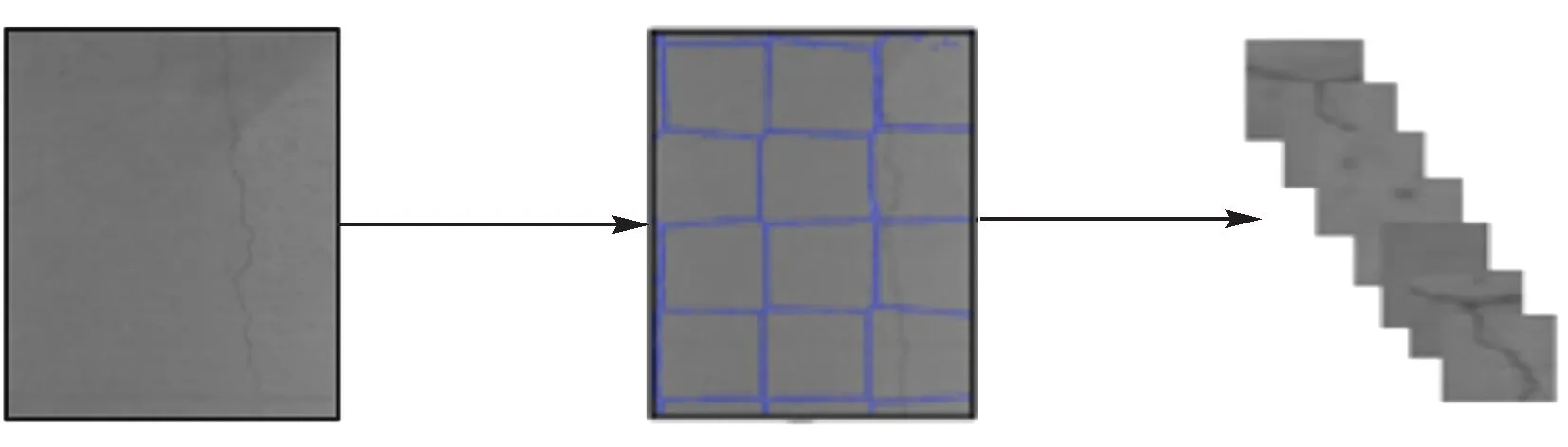
图2 超像素分割示意
输入为一张大图,经过超像素分割,聚类成一定数量的不规则图像块。经过调试和一些编程技巧的优化后,本文用cuda编程将分割程序运行在GPU(Pascal Titan X)上,速度为每张图片0.05 s,在同样效果的情况下速度大幅提升。
大图中每一个不规则像素块被切分出来按照一定格式保存,被用于裂缝识别数据集的建立。保存的图片如图3所示。可以看出,这些不规则的像素块有效地保持了裂缝的形状,避免了裂缝出现在分割的边缘处。

图3 超像素分割后像素块形成的图片
2.2 数据集
为了解决衬砌裂缝识别问题,本文构建了一个名为CNT的专有数据集,包含分类子集CLS-CRACK的专用数据集和分割子集SEG-CRACK。数据集选取3条完整隧道的图片数据作为数据源,涵盖不同路段、不同光照和不同的隧道类型。经过庞大的人工清洗和人工标注最终生成一个符合深度学习模型训练标准的数据集。其中,CLS-CRACK共包含 6 550 张图像和对应的分类标注,其中 4 550 张用作训练集,2 000 张用作验证集,正负样本比例基本为2∶1。CLS-CRACK数据集包括图像分类标签0和1,代表图片样本是否含有裂缝。SEG-CRACK数据集包含裂缝图片 2 000 张及其相应的分割标注,其中训练集 1 700 张,验证集300张。分割标注是包围裂缝的多边形,通过图像处理转化成分割掩码,用0和1的灰度值代表类别。
2.3 分类模型设计
2.3.1 模型细节
一个完整的分类网络包括输入、图片处理、计算推理和输出。在训练阶段输入包括图像和对应的标签,而在测试阶段输入只有图像。模型最终输出该图像是否含有裂缝。分类模型框架如图4所示。
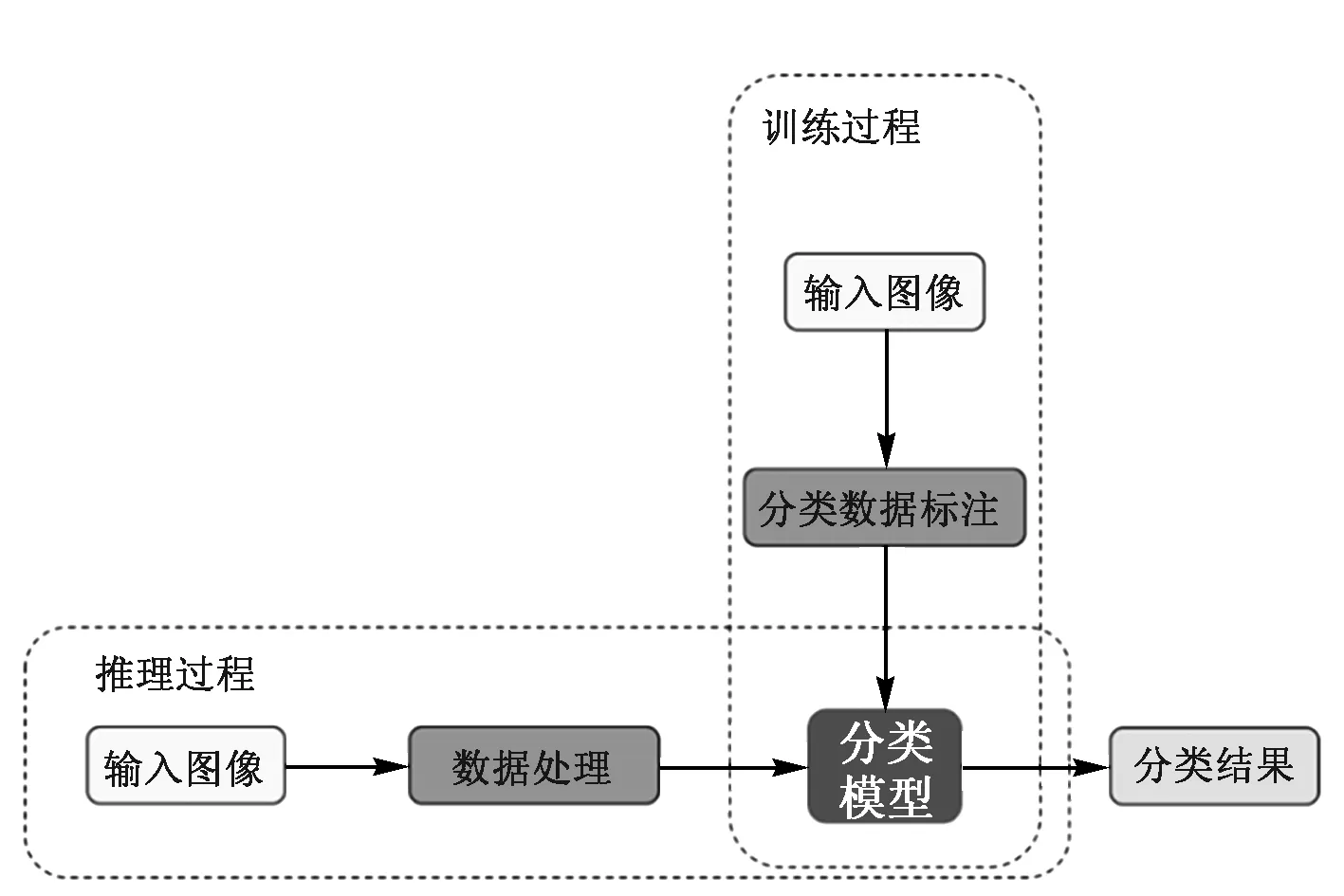
图4 分类模型框架
为了快速并准确地对隧道图片进行裂缝的识别,本文选择了速度性能均衡的ResNet18网络。
本文基于caffe深度学习框架来实现,在GPU(Pascal Titan X)上进行测试,一张尺寸300左右的图片前向与反向计算的时间分别是4.48 ms与5.07 ms,速度极快。ResNet18包括18个卷积层,第1层为7×7的卷积层,最后一层为全连接层,中间为8个模块结构,每个模块结构包括2个3×3卷积层。网络结构如图5所示。
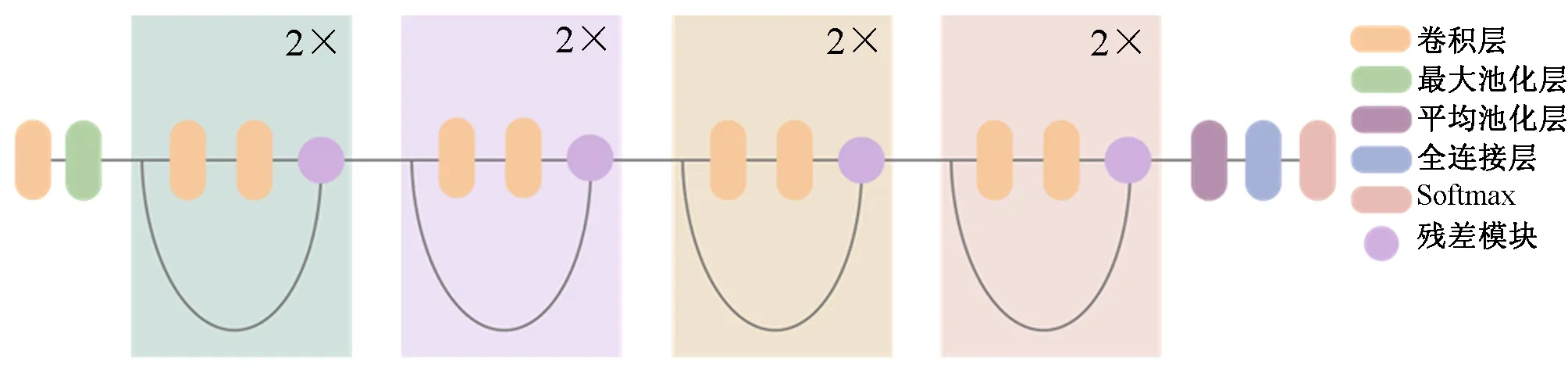
图5 ResNet18网络结构
2.3.2 模型训练与测试
本文使用caffe深度学习框架来进行模型训练与测试,模型训练采用在ImageNet上训练好的分类模型继续训练。训练参数的设置对于模型训练的效果至关重要。本文设置基础学习率为0.001并采用分段式下降策略,图片批数量为15,训练100次全数据,图片进入网络前统一缩放至600×600大小,并进行减均值除方差操作进行归一化处理。
模型测试应用了不同的裁切(crop)策略,即对一张图先缩放,再从图中crop出一定尺寸大小的图片。这些图片经过模型预测的结果综合起来能更好地提升准确率。
在分类任务中,最常用的性能度量指标是错误率和精度。但是,本项目关心的是挑出的图片中有多少是存在裂缝的或者所有存在裂缝的图片有多少被挑出来了。此时,查准率(precision)和查全率(recall)是更为适用于此类需求的性能度量指标。对于二分类问题,根据真实类别和模型预测的类别组合可划分为真正例(TP)、假正例(FP)、真反例(TN)和假反例(FN)4种情形。查准率P和查全率R分别定义为
查准率和查全率是一对矛盾的度量指标,很多情况下可根据模型的预测结果对样本进行排序,排在最前面的是最有可能为正例的样本,按照从前往后的顺序逐个把样本作为正例进行预测,每次可计算出当前的查全率和查准率,以查准率为纵轴、查全率为横轴作图就得到P-R曲线。本文的试验不仅分析了这些指标,也在P-R曲线上对模型效果进行了评估。
2.4 分割算法设计与实现
分割网络基于ResNet 18与DeepLabv 3分割框架设计。分割网络结构如图6所示。
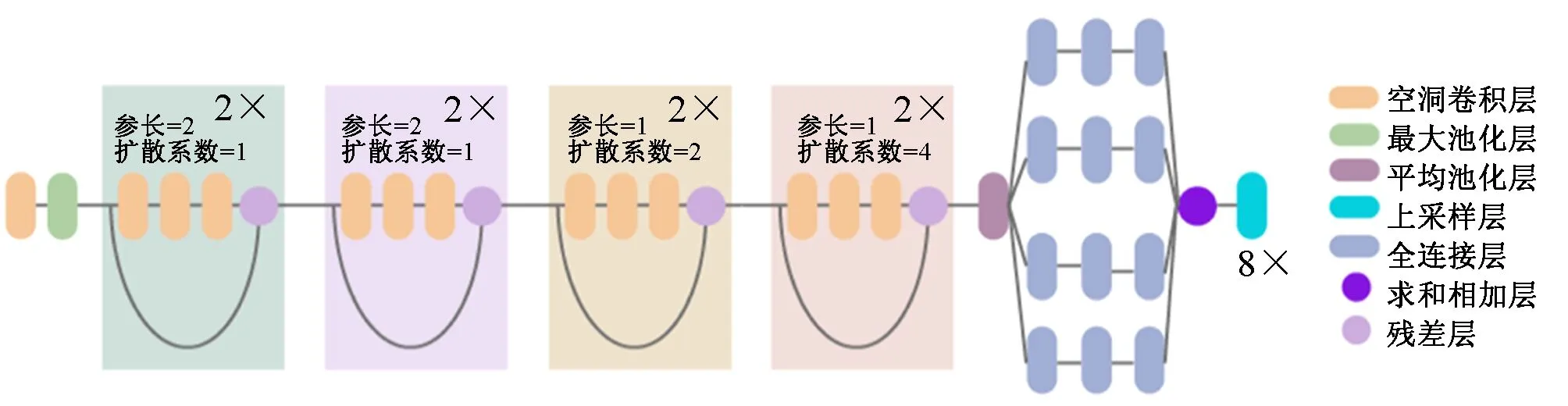
图6 ResNet 18-DeepLabv 3分割网络结构
2.4.1 带孔卷积
使用带孔卷积可以处理任意大小的输入图片,将最后一次全局池化的参长(stride)设为1,其前面网络的下采样过程用扩散系数(rate)为2的带孔卷积来替代,就能够直接在原始图像分辨率大小下获得特征响应。但是这种一直在全分辨率下进行计算的方式无论在时间上还是空间上都成本巨大。而根据FCN-8s最终是对8倍下采样的特征图进行8倍双线性插值得到原始输入图片大小的分割预测图。可以在得到8倍下采样特征图的后续网络中加入带孔卷积。这样既不会过多地增大时间和空间成本,又能对足够精确的特征图进一步优化。
根据空洞卷积原理,对原始ResNet 18网络进行了如下改进:即在第3次下采样后第4次下采样网络开始时,将后续所有网络的卷积层的stride设为1,同时添加空洞因子。其中对于之前的第4次下采样模型块rate=2,第5次下采样rate=4,最后得到8倍下采样的特征图,再通过8倍双线性插值后就可以得到原始图片大小的预测结果。
2.4.2 带权重的Softmax Loss函数
与常规的裂缝分割不同,裂缝分割有其数据分布的特殊性,裂缝在每张图片上其像素只占有很小比例,而深度学习框架常用的Softmax损失函数可以看作为一个平均投票器,这样就会导致像素更偏向于被预测为非裂缝的背景点。针对这个问题,修改了Softmax Loss函数,改为带权重的Softmax Loss函数,该函数使有裂缝的像素值位置加权参与运算。该方法有效解决了裂缝数据不均衡的问题。
2.4.3 分割模型测试指标
在深度学习语义分割任务中惯用的评价指标有像素分类准确率、均交并比(Mean Intersection over Union,MIOU)等。MIOU指的是模型预测结果与“真相”的交并比,是一个非常严苛的指标。在本文中只有一类裂缝需要被分割,因此只要计算裂缝的MIOU即可分析模型的分割效果。
2.4.4 分割模型阈值选取
在裂缝分割的过程中,经过分割网络的每个像素点都会得到一个得分。该得分代表着该像素点属于裂缝的置信度。在判断像素点是否为裂缝的过程中可以选取不同的阈值。选取不同阈值,获得的裂缝分割图像效果不同,如图7所示。

图7 不同阈值的分割图像
从图7可以看出:阈值选取得越高,越会导致一些裂缝点被认为是背景。为了不损失裂缝信息,在后面的试验分析中将阈值取为0.5。
3 分类试验结果与分析
3.1 对比试验分析
模型采用的是Softmax分类器,最终输出的是该图像是否存在裂缝的概率值。试验中,概率值大于0.5则认为测试图像存在裂缝。本文首先做了单尺度crop(600/600)试验,模型精度为0.927,查准率和查全率分别为0.545和0.800。以此作为基准试验,做了三组对比试验。试验参数及结果见表1。
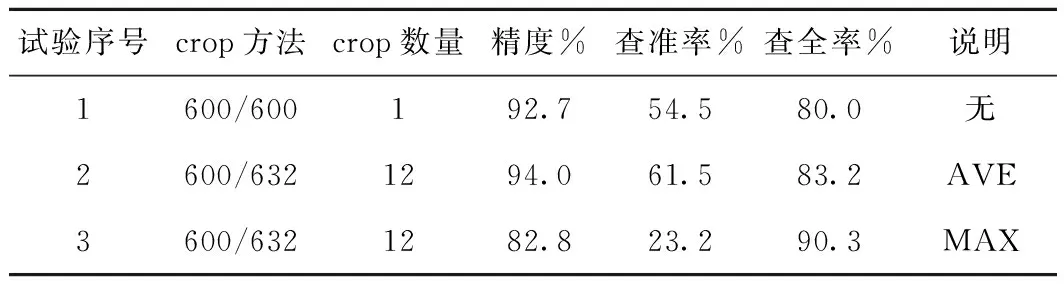
表1 分类模型性能测试对比试验参数及结果
从表1中可以看出:试验2比试验1在精度,查准率和查全率方面都有所提升,原因是一张图片crop出多个子图片,模型对这些子图片都进行判别,再综合考虑所有的结果最后对一张测试图像给出结果。试验3与试验2对比,不同之处在于模型的最终结果不根据多张子图片的结果综合打分,而是找出其中概率最大的结果。依据是,在更关注查全率的前提下隧道图片正样本较少,且裂缝为细长形不容易被发现,一旦在某个状态下被确定为裂缝则就认为它存在裂缝,这样能提高查全率。经过分析,试验2的multi-crop策略能有效提升模型精度,因此在搭建级联网络时采取试验2的参数。
3.2 P-R曲线分析
P-R图直观地显示出分类器模型在测试样本总体上的查全率和查准率,能通过曲线的分布情况与曲线下的面积来比较分类器的性能。3次试验的P-R曲线见图8。
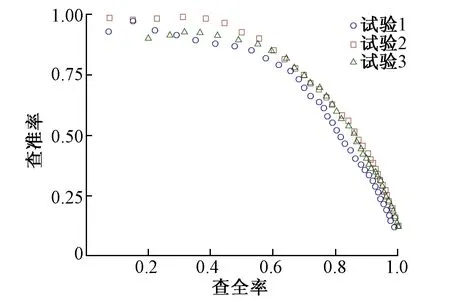
图8 分类模型性能测试对比试验P-R曲线分析
从图8中可以看出:试验2和试验3的P-R曲线基本能完全包住试验1的曲线,即试验2、试验3的查准率和查全率都要高于试验1。多尺度crop的技巧对于提高模型性能具有良好的效果。试验2和试验3的曲线存在交叠,模型性能较难评估。虽然表1表明在相同得分阈值下,试验3的查全率要高于试验2,但试验2的曲线下方面积比试验3大,试验2曲线取得查准率和查全率双高点的可能性要大于试验3曲线。因此,通过分析P-R曲线不仅能够评估模型性能,还能根据不同的任务需求寻找最合适的得分阈值。在裂缝分类任务及后面的试验中,默认阈值为0.5。
4 分割试验结果与分析
4.1 对比试验分析
用SEG-CRACK的验证集共300张图片进行模型的测试,进行了多组试验与baseline对比来分析MIOU,结果见表2。

表2 分割模型性能测试结果对比
4.2 可视化结果分析
裂缝分割优化结果见图9。可看出分割优化后图像与标注图像非常吻合。

图9 裂缝分割优化结果展示
5 结论与展望
本文提出了一个基于深度学习的衬砌裂缝识别算法,针对隧道图片特征分析并优化了SLIC超像素分割算法,构建了一个用于衬砌裂缝分析的数据集CLS-CRACK。在此基础上,设计分类网络ResNet 18,用caffe深度学习框架进行模型训练与优化。最后,将训练好的模型在验证集上进行性能分析。试验结果表明,该模型在CLS-CRACK数据集上表现良好,模型识别正确率94%,能够快速准确地实现裂缝的识别。完成裂缝识别后,用ResNet 18网络参考DeepLabv 3框架搭建裂缝分割网络,针对裂缝分割问题作了诸多调整改进使得模型收敛,且做了大量的试验来优化分割模型,最终在分割验证集上MIOU达到65%。
通过进一步收集现场图片并不断完善模型,本文的研究成果在铁路衬砌裂缝检测中可以发挥积极作用。
[1]柴雪松,李健超.基于图像识别技术的隧道衬砌裂缝检测系统研究[J].铁道建筑,2018,58(1):20-24.
[2]FUJITA Y,MITANI Y,HAMAMOTO Y.A Method for Crack Detection On A Concrete Structure[C]//Pattern Recognition,the 18th Internation Conference.IEEE,2006.
[3]LANDSTROM A,THURLEY M J.Morphology-based Crack Detection For Steel Slabs[J].Selected Topics in Signal Processing,IEEE Journal,2012,6(7):866-875.
[4]李刚,贺昱曜.不均匀光照的路面裂缝检测和分类新方法[J].光子学报,2010,39(8):1405-1408.
[5]褚燕利.基于灰度图像及其纹理特性的裂缝特征提取[J].公路,2010,7(7):131-136.
[6]卢晓霞.基于图像处理的混凝土裂缝宽度检测技术的研究[D].电子科技大学,2010.
[7]HINTON G E,SALAKHUTDINOV R R.Reducing the Dimensionality of Data with Neural Networks[J].Science,2006,313(7):504-507.
[8]BENGIO Y,COURVILLE A,VINCENT P.Representation Learning:A Review and New Perspectives[J].Pattern Analysis and Machine Intelligence,IEEE Transactions,2013,35(8):1798-1828.
[9]SERMANET P,CHINTALA S,LECUN Y.Convolutional Neural Networks Applied to House Numbers Digit Classification[C]Pattern Recognition,the 21st International Conference.IEEE,2012.
[10]BENGIO Y.Deep Learning[M].Massachusetts:MIT Press,2015.
[11]AGATONOVIC-KUSTRIN S,BERESFORD R.Basic Concepts of Artificial Neural Network (ANN) Modeling and Its Application in Pharmaceutical Research[].Journal of Pharmaceutical and Biomedical Analysis,2000,22(5):717-727.
[12]BENGIO Y.Learning Deep Architectures for AI[J].Foundations and Trends in Machine Learning,2009,2(1):1-127.
[13]KRIZHEVSKY A,SUTSKEVER I,HINTON G E.ImageNet Classification with Deep Convolutional Neural Networks[J].Neural Information Processing Systems,2012,1-9.
[14]SZEGEDY C,LIU W,JIA Y,et al.Going Deeper with Convolutions[J].Computer Vision and Pattern Recognition,2015,1-9.
[15]SIMONYAN K,ZISSERMAN A.Very Deep Convolutional Networks for Large-scale Image Recognition[C]//the International Conference on Learning Representations,2015.
[16]HE K,ZHANG X Y,REN S Q,et al.Deep Residual Learning for Image Recognition[J].Computer Vision and Pattern Recognition,2015(12):1-9.
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
现代电子技术(2018年20期)2018-10-24
北京航空航天大学学报(2018年1期)2018-04-20
现代情报(2018年11期)2018-01-07
中国与非洲(法文版)(2017年10期)2017-11-23
CHIP新电脑(2016年3期)2016-03-10
