
大数据相似性连接查询技术研究进展
2018-06-20 09:34:42马友忠张智辉林春杰
计算机应用 2018年4期
马友忠,张智辉,林春杰
(1.洛阳师范学院 信息技术学院,河南 洛阳 471934;2.河南省电子商务大数据处理与分析重点实验室(洛阳师范学院),河南 洛阳 471934;3.洛阳铁路信息工程学校 计算机教研室,河南 洛阳 471900)(*通信作者电子邮箱ma_youzhong@163.com)
0 引言
相似性连接查询是指给定两个数据对象集合R和S(集合、向量、空间数据、字符串等),一个度量函数sim和一个相似度阈值ε,找出所有分别来自R和S的相似度大于阈值ε的数据对象对。相似性连接查询是一种应用广泛且非常重要的操作,是很多数据分析及数据挖掘任务的基本操作,如分类、聚类、异常检测、重复文档检测等。
相似性连接查询存在两大挑战:一是相似度计算代价大,尤其是当数据类型比较复杂或者是数据维度比较高时,两个数据对象之间的相似度的计算将耗费很多时间。二是扩展性问题。随着大数据时代的到来,数据的规模日益增长,传统的集中式算法或串行算法已经不能在可接受的时间内完成大规模数据集的相似性连接查询任务。因此,如何借助最新的计算技术,设计具有良好扩展性的相似性连接查询算法,成为目前大数据相似性连接查询的重要研究内容。MapReduce是一个由Google最先提出的分布式计算软件框架,具有高可扩展性、高可用性、高容错性等特点,可以支持大规模数据的分布式处理,目前已经成为大数据处理的首选平台。为了解决大规模复杂数据类型的相似性连接查询问题,很多学者针对基于MapReduce框架的相似性连接查询算法进行了深入研究,提出了很多创新的解决方案。
根据分类标准的不同,相似性连接查询可以有不同的分类方法。可以按照数据对象类型、对象集合的动态性,以及查询结果和处理方式的不同等标准来进行划分。不同分类标准得到的类别之间可能会有重叠,并且不同的数据类型,对象之间的相似度度量函数往往不同,因此所采用的方法也不相同,本文将主要按照不同数据对象类型的连接查询方法进行分别描述。表1描述了不同数据类型对应的常用相似度度量函数,其中,集合、向量和字符串的相似度度量有所重叠,部分方法可以通用。为便于描述,本文中集合主要采用杰卡德相似度和余弦相似度,向量主要采用欧氏距离,字符串主要采用编辑距离。

表1 相似度度量函数
另外,关于集中式的相似性连接查询方法,文献[1-3]已经进行了综述,本文不再详细描述。庞俊等[4]对基于MapReduce框架的海量数据相似性连接工作进行了综述,但是主要包含的是2013年及以前的部分研究工作。还有部分学者[5-6]对典型的基于MapReduce的相似性连接查询算法进行了实验验证和比较。本文将针对截至2017年的云计算环境下的大数据相似性连接查询技术进行更全面、深入的分析。
1 集合相似性连接查询
集合相似性连接查询广泛应用于文本分类、聚类、重复网页检测等应用中,文本、网页都可以表示成单词的集合。集合的相似性度量主要包括杰卡德相似度、余弦相似度、重叠相似度和Dice相似度等。随着数据规模的不断扩大,单机环境下的相似性连接算法已经不能满足性能要求,有很多学者基于MapReduce框架,提出了若干种针对大规模集合数据的相似性连接查询处理方案,如表2所示。

表2 集合相似性连接查询方案
表2描述了已有的大规模集合相似性连接查询方案,并按照采用的技术不同,将其分为六类:穷举方案、前缀过滤、Word-Count-Like、混合方案、基于划分的方法和基于位置敏感哈希的方法。各类方案的主要优缺点和代表算法详细描述如下。
1)穷举方案。
文献[7]较早利用MapReduce框架对相似性连接查询问题进行了研究,并提出了Brute force算法和基于索引的算法。其中,Brute force算法通过精确匹配找出所有满足条件的文本对。该算法在Map阶段使用暴力法,计算出每一个文本和其他所有文本的相似度,然后输出所有相似度不为零的文本对;在Reduce阶段,针对每一个文本求出与其相似度最大的k个文本。该算法可以求出精确的结果,但是计算代价比较大。索引算法可以在一定程度上降低计算代价,提升性能,但是结果的精度会有所下降。总体来看,Brute force算法没有进行任何过滤,任意两个集合都需要比较一次;基于索引的算法虽然可以进行一定程度的过滤,但是过滤效果不理想,重复比较次数仍然会比较多。
2)前缀过滤。
文献[8]在MapReduce框架下,提出了一种基于前缀过滤(prefix filtering)技术的大规模集合数据相似性连接查询方案。文献[8]中处理的数据对象是一些记录(record)的集合,每一条记录由记录标识和其他若干个属性组成,其中连接属性是项(token)的集合。前缀过滤是一种很有效的过滤方法,其基本思想是:假设数据集中所有的项(token)按照其出现频度由低到高进行排序,得到一个序列O,数据集中的每一个集合都按照序列O进行排列,集合A的p-前缀就是集合A的前p个项。假定相似性度量采用杰卡德相似度,阈值为t,则如果J(A,B)≥t,那么A的(|A|-「t·|A|⎤+1)-前缀和B的(|B|-「t·|B|⎤+1)-前缀至少含有一个公共的项(token)。即如果两个集合的前缀没有公共的项,则这两个集合肯定不相似。根据上述基本思想,文献[8]在MapReduce框架下实现了前缀过滤方案。该方案主要分为三个阶段,分别为项排序(Token Ordering)、相似对生成(RID-Pair Generation)和最终结果生成(Record Join),每个阶段由一个或多个MapReduce Job来完成。项排序阶段的主要目的是通过计算数据集合的相关统计信息,得到具有较好过滤效果的集合前缀,具体方法是计算出集合中所有项(token)出现的频率,然后按照出现频率将所有项进行升序排列,作者分别提出了基本排序法(basic token ordering)和一阶段排序法(using one phase to order tokens)来完成排序任务。相似对生成阶段主要是根据连接的属性,找出相似度大于给定阈值的记录对,该阶段由一个MapReduce Job完成。在Map阶段,针对每一个输入记录,首先抽取出其ID和连接属性,然后根据前一阶段得到的项序列,计算出连接属性的前缀,接着根据连接属性的前缀构建倒排索引。针对每一个记录,会生成若干个〈key,value〉对的集合,其中:key是记录前缀中的每一个项;value包括该记录的ID和连接属性。在Reduce阶段,具有相同key值的value组合在一起,发送到同一个reducer中。同一个key就对应着包含该key的记录列表,这些记录有可能相似,针对这些记录,作者提出了嵌套循环链接和PPJoin+两种方法来计算相似度大于阈值t的记录对,包括记录ID和相似度。在最终结果生成阶段,将前一阶段得到的相似对集合与原始数据集合进行连接,获取记录的完整信息,得到最终结果。文献[9]的解决思路与文献[8]类似,改进之处在于文献[9]除了前缀过滤之外,又增加了长度过滤,这样就可以进一步提高性能。
为了进一步提高过滤效果,减少候选对的数量,文献[10]中提出了一种基于多前缀的集合相似性连接方案。文献[8]中所使用的前缀过滤技术虽然在一定程度上减少了候选对的数量,但是在候选对中仍然有很多是不相似的,因为即使两个对象的前缀有公共的项,这两个对象也不一定相似。文献[10]通过分析、观察发现,集合的前缀是按照某个项的排序生成的,不同的排序,所产生的前缀就不一样。基于该思想,文献[10]为每个对象按照不同的排序生成多个不同的前缀,其中用第一个前缀来建立倒排索引,用其他的前缀来进行进一步的过滤,最终通过过滤的候选对才需要进行最后的验证,从而大大减少了计算的代价。同时,文献[10]还提出了一个代价模型,来确定序列(即前缀)的数量,并提出了多种排序方案,主要包括随机选择(random selection)、基于反序列的随机选择(random selection with reverse ordering)和基于词频的全局排序(TF as the first global ordering)。作者还在单机环境及MapReduce框架下分别对该算法进行了实现及验证,实验结果表明,基于多前缀的集合相似性连接方法具有较好的性能。
但是基于前缀过滤技术的方案也存在一些不足之处:a)网络传输代价较大。每个集合都要复制多次,复制的次数等于前缀的长度,因此对于较长的集合来讲,数据复制率太高,会导致网络传输代价比较大。b)重复比较次数比较多。对于任意两个集合,如果它们的前缀中有k个公共项,则会重复比较k次。
3)Word-Count-Like方案。
为了克服前缀方案中存在的缺点,文献[11]中提出了一种“Word-Count-Like”的解决方案Pairwise Join,之所以取名为“Word-Count-Like”,是因为该方案充分利用了MapReduce框架的特性,基本思路类似于Word-Count程序。文献[11]主要解决的是文档的相似性连接问题,每一个文档可以被表示成一个词的权重的向量,相似性度量采用的是权重向量的内积来表示。该方案主要分两个阶段来完成,第一阶段主要生成倒排索引,第二阶段用来计算任意两个文档的相似度,每个阶段均由一个MapReduce Job来实现。在Job 1中:Map阶段针对每一个输入的文档向量〈i,di〉,输出〈key,value〉的集合〈t,〈i,di[t]〉,其中:i是文档标识;di是权重向量;t是单词;di[t]是t在文档i中的权重。在Reduce端,同一个单词t对应的value被组合在一起,按照〈t,[〈i,di[t]〉,〈j,dj[t]〉,…]〉的形式输出。在Job 2中,Map阶段针对每一个〈t,[〈i,di[t]〉,〈j,dj[t]〉,…]〉进行处理,输出〈〈i,j〉,w=di[t]·dj[t]〉的集合,其中:〈i,j〉是两个文档的ID对;w是t在两个文档中的权重的乘积。在Reduce端,与同一个〈i,j〉对对应的w被组合在一起,对这些权重求和,得到的最终结果就是文档对〈i,j〉的相似度。
文献[12]的基本思路与文献[7]类似,提出了V-SMART-Join方案。不同之处在于文献[12]中对处理方案进行了一般化,处理的数据对象类型进行了扩充,可以处理集合、多重集合以及向量,相似性度量可以采用内积、余弦相似度以及杰卡德相似度等。此外,文献[12]中还提出了一些解决方案,用来高效处理倾斜数据,并在大规模真实数据集上进行了充分的实验,实验结果表明,文献[12]方案的性能比文献[8]方案的性能要高30倍以上。
Word-Count-Like方案的优点是避免了重复比较,任何一对文档只需要比较一次。另外,文档本身没有被重复复制,传输的仅仅是各个单词对应的权重,所以大大降低了网络传输的代价。但是该类方案也存在一些局限性,任何两个文档只要包含一个公共元素,都需要比较一次,没有利用到相似度阈值和前缀的过滤功能,因此会产生很多不必要的候选对。
4)混合方案。前缀过滤方案和Word-Count-Like方案各有优缺点,文献[13]中结合上述两种方案的优点,提出了一种混合方案Self-Join,从而进一步提高了集合相似性连接的效率。文献[13]对文献[11]进行了扩充,在建立倒排索引时候,利用前缀过滤技术来缩短索引列表的长度,从而可以大幅减少中间结果的数量。由于采用了前缀进行过滤,对于任意一个候选对中的文档来说,可能只包含一部分权重信息,因此还需要两次远程操作来获取其相应的权重信息,从而计算出最终的相似度。由于远程操作的代价一般比较大,为了解决这一问题,文献[13]又提出了一种优化方案——SSJ-2R (Double-Pass MapReduce Prefix-Filtering with Remainder File)。
该方案的优点是将前缀过滤技术与Word-Count-Like方案进行了结合,从而减少了候选对的数量;没有重复计算,每一对只计算一次。不足之处在于,因候选对中没有集合的全部信息,所以需要在候选对的基础上,进行进一步的处理,进行数据的传输等;候选对的数量与ALL Pairs方法中候选对的数量是一样的,即只要两个集合的前缀中至少含有一个公共项,就成为一个候选对。
5)基于划分的方法。文献[14]中提出了一种基于垂直划分的相似性连接查询算法FS-Join,可以有效避免重复计算,并可以实现Map端和Reduce端的负载均衡。但是,枢轴(Pivot)的选择以及枢轴个数的确定对该算法的性能影响较大,需要花费较大的代价确定枢轴及其个数。为了减少重复计算的代价,Greedy+[15]设计了一种新的划分机制,将集合划分成若干子集,并确保:如果两个集合相似,那么它们一定有相同的子集。
6)基于位置敏感哈希的方法。个性化位置敏感哈希(Personalized Locality Sensitive Hashing, PLSH)方法[16]在传统位置敏感哈希技术的基础上,提出了一种新的采用灵活阈值的分块技术(banding technique),从而可以大幅减少伪正例的个数,提高计算效率,并能够实现伪正例和伪反例之间的平衡。
2 向量相似性连接查询
向量数据相似性连接查询针对的数据类型是向量,包括低维向量和高维向量,如图形、图像、Web文档、基因表达数据等多种数据经过处理后,都可以用向量来表示。向量的相似性度量也有很多种,包括余弦相似度、杰卡德相似度、欧氏距离和闵可夫斯基距离等,本文将主要研究基于欧氏距离的解决方案。根据返回结果的不同,向量相似性连接查询可以分为基于阈值的连接查询、Top-k连接查询和KNN连接查询,具体信息如表3所示。
阈值相似性连接查询:文献[17]中提出了一种称为DAA(Dimension Aggregation Approximation)技术的降维方法,并在此基础上提出了基于MapReduce框架的并行相似性连接查询算法。DAA是受分段累积近似法(Piecewise Aggregate Approximation, PAA)技术的启发,PAA是时间序列中一种比较有效的数据降维方法,其核心思想是:将一个长度为n的时间序列,划分成m段,形成一个长度为m的新序列,用每一段内的所有元素的均值作为新序列的元素值,基于新序列,可以构建一个新的距离函数,该距离是原始序列距离的下界,因此可以基于降维后的序列来对原始向量进行过滤。
在DAA技术的基础上,结合MapReduce框架,作者以嵌套循环连接算法为基础,提出了两种新的并行化算法:一阶段过滤验证算法OSFR(One-Stage Filtering-and-Refinement)和两阶段过滤验证算法TSFR(Two-Stage Filtering-and-Refinement)。在进行数据传输的过程中,OSFR除了传输降维后的向量之外,原始向量也要一起传输,在得到候选对以后,在验证阶段就可以直接利用原始向量的信息计算原始距离。但是当向量维度特别高时,这种方案的网络传输代价比较大。TSFR算法分为两个阶段来完成,在第一个阶段仅仅使用降维后的低维向量进行计算,得到候选对以后,再利用第二个阶段去获取原始向量信息,进行最后的验证。该方案可以减少网络传输的代价,但是在第二个阶段需要远程获取原始向量的信息,也需要一定的额外开销。最后,作者提出了一个代价模型,用来进行算法选择,通过分析和实验验证表明,OSFR算法比较适合于较低维向量,TSFR算法比较适合于超高维向量。文献[17]方案可以以较低的代价进行过滤,从而减少不必要的比较。但是,该方案的时间复杂度仍然是O(n2),即任意两个向量在低维空间上都需要比较一次。

表3 向量相似性连接查询技术
文献[18]中提出了一种基于网格划分方法的大规模向量相似性自连接处理方案,该方案的核心思想是利用网格对数据对象进行划分,并按照相应的过滤技术,减少计算比较的次数,降低网络传输的代价。以二维向量为例来进行介绍:假设距离阈值为ε,首先将空间进行网格划分,格子的宽度为ε,对于每一个单元格内的对象,只可能与自身以及周围的八个单元格内的对象相似,这样就不需要与其他单元格内的对象进行比较,可以减少大量的计算量。为了保证计算的完整性,每一个单元格内的数据都需要复制3d次(d是向量的维数),在不同的Reduce上进行计算。实际上有些计算和复制是重复的,可以采取一定的措施来减少数据复制的比率,即每一个单元格内的对象只与其自身和左下方的单元格内的对象比较即可,这样也可以保证计算的完整性,基于这种方法,数据复制的比率可以降为2d。另外,作者还提出了一些优化方法,在Reduce端进一步减少计算的次数。该方法具有很好的并行特性,很容易在MapReduce框架下实现。其不足之处是该方法只适合于维度较低的情况,一旦维度比较高时,其性能急剧下降。
为了解决这一问题,文献[19]对文献[18]方案进行了扩充,提出了一种新的基于MapReduce的连接方案——PHiDJ(Parallel High-Dimensional Join),PHiDJ方案主要通过对维度分组和变长的网格划分来提高连接速度。具体思路为:首先把d个维度(高维)划分成若干个互不相交的组(低维),每一个组包含若干个维;然后针对每一个组,再采用文献[18]方法处理,最后进行验证、过滤。另外,文献[18]采用的是均匀网格划分法(等宽),文献[19]则采用了变长的网格划分方案,具有更好的适应性和过滤效果。作者通过大量的实验结果表明,文献[19]算法比文献[18]算法具有更好的性能,并且能够处理更高维的向量。
文献[20-21]中提出了一种基于MapReduce框架的相似性连接查询算法MRSimJoin(MapReduce Similarity Join),该算法的核心思想是从数据集中随机选取k个向量作为中枢,然后将每一个向量分配到距离最近的中枢所在的分区,这样可以形成k个基本分区。由于基本分区之间的向量仍有可能相似,因此,两个不同基本分区边界中的向量组成窗体对分区。如果某个分区的大小小于单个节点所能处理的最大向量数,那么该分区就不需要再进一步划分,可以直接这对该分区执行相似性连接查询操作;反之,则需要对该分区作进一步划分。每一轮划分都由一个MapRedcue Job来负责实现。
文献[22]对MRSimJoin算法[20]进行了改进,提出了一种MapReduce框架下增量式数据相似性(MapReduce-based Similarity Join for Incremental Data Set,MRSJ_IDS)连接算法,该算法能够支持增量式数据集的相似性连接查询。MRSJ_IDS算法的基本思想是:首先通过抽样的方式获得一个样本集合,然后对样本集合进行聚类,将各个类的中心作为中枢,按照MRSimJoin算法中的方法对全部数据进行划分,从而得到基本分区和窗体对分区。针对每一个分区创建一个KD-树索引,并计算出相似对。对于新增数据,首先根据事先确定的划分原则找到相应的分区,再根据该分区的KD-树索引进行查询、插入操作,从而获得新增数据对应的相似对,并对原有的KD-树索引进行更新。
FACET(FAst and sCalable maprEduce similariTy join)[23]以余弦相似度来衡量向量之间的相似度。由于文献[8-10]中提出的前缀过滤方法只适用于集合数据,作者针对向量数据和余弦相似度提出了新的前缀过滤机制和长度过滤机制,并结合MapReduce框架设计了并行实现算法FACET[23],可以快速、精确计算出所有的相似对。
SAX-Based HDSJ(Symbolic Aggregate approXimation based High-Dimensional Similarity Join)[24]采用PAA对高维向量进行降维,并在此基础上,利用符号累积近似法(Symbolic Aggregate Approximation, SAX)转换成SAX字符串,基于SAX可以对原始高维向量进行分组,由于SAX字符串之间的距离是向量之间原始距离的下界,因此,可以利用SAX进行有效过滤。SAX的过滤效果直接影响到相似性连接查询的效率。为了进一步提高过滤效果和减小过滤代价,文献[25]在SAX-Based HDSJ[24]的基础上提出了基于多PAA的相似性连接查询方案MP-V-SJQ。
为了减少不必要的比较,并实现各个计算节点的负载均衡,文献[26]中提出了基于动态网格划分的相似性连接查询方案Grid-Based SJ(Grid-Based Similarity Join):首先通过采样的方法进行动态网格划分,并根据划分结果构造网格索引;然后依据网格索引对所有数据进行分配和计算,尽量确保各计算节点负载均衡。
SJT(Similarity Join Tree)[27]通过计算所有点与某个选定点之间的距离,将原始数据映射到一维空间内,并在一维空间内使用距离阈值进行等宽划分。如果某块内的数据个数超过一定阈值,可以对该块进行进一步划分。为了能够较好地描述上述数据划分思路,作者在SJT[27]中设计了相似性连接树。既可以减少不必要的比较计算,也可以实现各个计算节点的负载均衡。
K最近邻(K-Nearest Neighbor, KNN)相似性连接查询:文献[28]最早对基于MapReduce框架的KNN连接查询问题进行了研究,为了减少比较次数,降低网络传输代价,文献[28]中提出了一种基于空间填充曲线技术的近似KNN连接查询方案zKNNJ(z-order basedK-Nearest Neighbor Join)。
zKNNJ的基本思路是:首先采用z-order方法将d维空间的点转换成一维数据,并按照z-order值进行排序;在此基础上,d维空间的KNN连接查询可以转换成一维上的范围查询;为了提高查询结果的准确度,可以将原始向量转换成多个一维序列。基于上述思想,作者提出了基于MapReduce的并行计算方案H-zKNNJ。H-zKNNJ基本思路是:首先将集合R和S按照上述的转换方法,转换成两个一维的序列;接着将两个一维序列分别划分成n个组,划分的时候要求R和S具有相同的划分边界,并且要确保划分的均衡性,作者提出了一种基于采样技术的划分方案;将向量进行划分以后,对于R中的每一组Ri,从S中找出可能满足KNN查询要求的集合Si′(可能包含S中多个组的数据),最后将Ri和Si′中的向量进行比较即可得到KNN的查询结果。但是H-zKNNJ也存在一些不足之处,如只能返回近似的结果、不能有效地处理较高维度的向量等。
与文献[28]返回近似的KNN连接查询结果不同,文献[29]中提出了一种精确的KNN连接查询方案,该方案主要基于维诺图(Voronoi Diagram)对数据进行划分。基本思路是:对于给定的两个向量集合R和S,首先采用维诺图把集合R划分成k个互不相交的子集R1,R2,…,Rk;然后针对R中的每一个子集Ri,按照一定的方法,从集合S中找到一个对应的子集Si,Si需要满足如下要求:∀r∈Ri,KNN(r,S)⊆Si,S的各个子集之间可能会有重叠。按照上述划分方案,集合R中的每一个子集Ri只需要与对应的子集Si进行比较,这样就可以大大降低网络传输的代价,同时也减少很多不必要的计算。上述方案的难点有两个:一是如何对集合R进行划分;二是如何为R的每一个子集Ri寻找相应的Si。在利用维诺图对集合R进行划分时,核心是中枢(pivot)的选择,作者分别提出了随机选择(random selection)、最远选择(farthest selection)和k-means选择(k-means selection)三种不同的选择方案,并分别进行了实验验证。实验结果表明,该方案在处理中低维度向量时效果较好,但是无法有效处理超高维度向量。
文献[30]在嵌套循环连接框架的基础上,分别提出了精确KNN(Distributed Sketched Grid based KNN Join using MapReduce,DSGMP-J)连接算法和近似KNN(Voronoi Diagram based KNN Join using MapReduce,VDMP-J)连接算法。在DSGMP-J算法中,首先采用DSG(Distributed Sketched Grid)对空间进行划分,然后针对每一个单元格内的数据建立一个本地索引,这样就可以利用本地的DSG索引来求出局部KNN结果。DSGMP-J方案虽然实现起来比较简单,但是在进行数据划分时,没有考虑数据的真实分布情况,只是采用了简单的均匀划分方案。为了解决这一问题,作者采用维诺图对数据进行划分,在此基础上,提出了一种近似的KNN查询方案VDMP-J。
Top-k相似性连接查询:文献[31]中提出了基于MapReduce框架的Top-k相似性连接查询方案。作者首先提出了两种串行化算法,分别是divide-and-conquer算法和branch-and-bound算法;然后又提出了两种基于MapReduce框架的并行化算法,分别是完全对划分算法(All pair Partitioning Algorithm, TopK-P-MR)和关键对划分算法(Essential Pair Partitioning Algorithm, TopK-F-MR)。TopK-P-MR算法实际上是一个嵌套循环连接算法,需要分两个阶段来实现,首先找出局部的Top-k结果,然后再找出全局的Top-k结果。在计算局部Top-k时,可以利用到前面提出的串行化算法。但是该方案的时间复杂度是O(n2),即任意两个向量之间都需要计算一次,计算代价过大。为了解决这一问题,作者又提出了TopK-F-MR算法,该算法首先通过采样的方法,找出第k个最小的距离,并以该距离作为Top-k结果的距离上界,然后根据该上界对数据进行过滤和划分,这样就可以减少很多不必要的比较和计算,大大提高计算的效率。
针对大规模高维向量,文献[32]中提出了一种基于MapReduce框架的并行Top-k连接查询算法SAX-Top-k。SAX-Top-k算法首先提出了一个基于采样技术的Top-k阈值估计方法,并结合符号累积近似法(SAX)设计了高效的过滤方案,最后结合MapReduce框架提出了基于SAX的并行Top-k连接查询算法。
文献[33]中针对高维数据提出了基于局部敏感哈希(Locality-Sensitive Hashing, LSH)的距离,并将基于LSH的距离转换成高维数据签名的海明距离,在此基础上,设计了基于Spark的Top-k相似性连接查询方案。与基于Hadoop的方案相比,文献[33]方案的计算速度更快,具有更好的扩展性。
3 空间数据相似性连接查询
空间数据相似性连接是指给定两个空间数据集合R和S,找出所有满足空间关系要求的空间数据对。其中,空间数据可以是点(兴趣点,如一栋房子、一个商铺、一个邮筒、一个公交站等)、线(街道)、多边形(住宅小区、医学图片中的细胞等)等,空间关系可以是欧氏距离、相交(重叠)等。根据返回结果的不同,又可以分为相交连接、Top-k连接、KNN连接和空间聚集连接等。
文献[34]中提出了一种基于MapReduce框架的空间数据连接算法SJMR(Spatial Join with MapReduce)。该算法通过一个MapReduce Job来完成,在Map阶段,作者提出了一个空间划分函数,将空间对象划分到不同的子区域中,每一子区域中的数据由一个Reduce任务负责处理。为了确保划分的均匀性,作者提出了基于空间填充曲线的划分方法。在Reduce阶段,采用过滤-验证框架进行处理,在过滤阶段,为了提高过滤效果,作者提出了Plane Sweeping技术,从而可以减少候选对的数量。由于一个空间对象可能会被划分到不同的子区域中,所以在Reduce端可能会出现很多重复的比较,作者提出了一种基于参考点的方法,从而确保一对空间数据最多只被比较一次。
文献[35]中针对海量空间数据,提出了一种基于MapReduce框架的Top-k空间连接查询算法(Top-kSpatial Join Algorithm using MapReduce,TKSJMR),该算法要求找出k个与其他空间数据具有最大交叠数的对象。主要通过三个阶段来完成,每一个阶段由一个MapReduce Job来实现。第一个阶段为空间连接阶段,主要负责找出所有相交的空间数据对;第二个阶段为连接结果统计阶段,负责统计出每个对象与其他对象相交的总数目;第三个阶段为Top-k结果获取阶段,主要是从上一阶段的统计结果中找出相交数最大的k个对象。为了进一步提高效率,作者进行了一些优化,如为了减少必要的比较,在空间连接阶段,作者采用了基于网格的划分方法;为了避免重复比较,又提出了基于参考点的方法。同时为了减少MapReduce Job的数量,作者把后面两个阶段进行了合并。
文献[36]中提出了一种基于MapReduce框架的快速空间聚集连接查询算法MRFM(Map-Reduce-Filter-Merge)。文献[37]首先提出了基于MapReduce框架的并行R-tree索引构建方法,并在R-tree索引的基础上提出了基于MapReduce的KNN连接查询算法。文献[38]中针对空间连接问题,提出了一种新的“可控-复制”框架,基于该框架可以减少集群节点之间的网络传输代价,能够有效处理基于“重叠”和“包含”两种谓词的空间连接查询问题。
文献[39]中针对MapReduce框架下的空间关键字连接查询问题进行了研究,提出了基于前缀过滤和网格化分技术相结合的空间文本对象过滤算法,并在此基础上又提出了两种优化方法,从而进一步提升了空间关键字连接查询的性能。
4 概率数据相似性连接查询
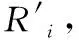
MELODY-JOIN[41]在MapReduce框架下,针对直方图概率数据提出了一种基于EMD距离的阈值相似性连接方案。其核心思想是:首先将原始的直方图概率数据转换到EMD距离的标准下界空间,然后采用特定的网格划分方法对标准下界空间进行划分;接下来计算每一个记录与每一个单元格的EMD距离的下界,如果该下界值大于给定的阈值,则该记录就不需要与该单元格内的所有记录进行比较;否则需要进一步比较。同时,为了解决负载均衡的问题,作者提出了基于Quantile Grid的划分方法,从而使得每一个单元格包含的记录数量近似相等。但是,MELODY-JOIN[41]需要三个MapReduce Job来实现,需要消耗三次Job启动时间;另外,MELODY-JOIN[41]的负载均衡策略仅仅依赖于连接负载(join workload),无法有效处理转换空间内的数据倾斜问题。Heads-Join[42]通过引入EMD下界和上界对MELODY-JOIN[41]进行了进一步扩展,既可以处理范围连接(range join),又可以处理Top-k连接,并将Heads-Join框架在MapReudce、BSP和Spark模式下分别进行了实现。
为了解决MELODY-JOIN[41]存在的问题,文献[43]中提出了基于映射的数据划分框架EMD-MPJ(Mapping-based Partition Join),它只需要两个MapReduce Job即可完成,其数据划分方案主要是基于线性规划的对偶理论进行设计。为了实现负载均衡,EMD-MPJ设计了针对Reduce端的连接代价模型,并据此进行连接负载的分配。
文献[44]中针对大规模概率集合数据提出了两种基于MapReduce的并行化方法:基于Map端过滤的连接和基于Reduce端过滤的连接。基于Map端过滤的连接算法主要根据集合的存在概率,在Map端将那些没有可能与其他任何概率集合相似的集合直接过滤掉;基于Reduce端过滤的连接算法主要采用基于概率总和以及概率上界的过滤方法来减少候选相似对的数量,从而降低计算代价。
5 字符串相似性连接查询
林学民、李国良、王炜等学者对集中式环境下的字符串相似性连接查询问题进行了细致深入的研究,并提出了大量创新性的成果[45-50]。文献[51-53]主要探讨了基于MapReduce框架的海量字符串数据可扩展相似性连接查询问题。文献[51]以编辑距离作为字符串间的相似性度量,以trie树结构为基础,提出了一种新的索引结构PeARL。PeARL索引由一系列trie树构成,每一棵trie树用来索引以某个前缀(prefix)开头的字符串。在进行连接查询时,master节点首先从根节点开始逐步扫描trie树,针对trie树的每一对内部节点,计算其对应前缀的编辑距离,如果大于给定的阈值,则该对节点就可以过滤掉;否则继续往下扫描,直到遇到叶子点对(字符串节点对)时,为其生成一个map task。以此类推,为每一个可能相似的字符串节点对生成一个map task,最后以并行的方式来计算字符串之间的实际编辑距离。
文献[52]主要对基于划分的签名机制进行了扩展,从而可以支持基于集合相似度(杰卡德相似度)的字符串连接。为了解决文献[8]中存在的过滤效果不理想、数据倾斜等问题,文献[52]中提出了一种基于划分的签名机制,将每个字符串按照某种规则划分成若干个分段,如果两个字符串相似,它们至少包含有一个相同的分段。基于该特性,就可以为每一个分段生成一个〈key,value〉对,这样就可以取得较好的过滤效果。为了进一步减少〈key,value〉对的数量,作者又提出了一种基于合并的算法,从而可以减少网络传输的代价。文献[53]对PassJoin(Partition-based Method for Similarity Joins)算法[54]进行了扩展,提出了一种更快的算法PassJoinK,并结合MapReduce框架,对PassJoinK算法进行并行化,提出了可扩展的字符串相似性连接查询算法PassJoinKMRS。
6 图数据相似性连接查询
文献[55]中针对海量图数据的相似性连接查询问题,提出了可扩展的前缀过滤方案,从而减少比较次数;设计了一种有效的候选项约减方法来降低数据传输代价;并基于MapReduce框架设计了可扩展的图数据相似性连接查询算法。文献[56]主要研究了基于编辑距离的图相似性连接查询问题,作者主要提出了一种基于“过滤-验证”机制的算法MGSJoin(Graph Similarity Joins in MapReduce),采用布隆过滤器技术来减少冗余计算和网络传输代价,并集成多路连接策略来增强验证阶段的效率。文献[57]主要解决了海量RDF数据的连接查询问题。针对RDF数据的SPARQL查询往往包含很多连接操作,查询代价比较高,当数据规模比较大时,传统的单机算法无法满足性能要求,于是文献[57]中提出了基于MapReduce框架的高效RDF数据连接方案。首先将原始的RDF数据按照谓词(predicate)进行分解重组,每一个谓词对应一个谓词文件;然后在这些谓词文件的基础上,把SPARQL查询转换成一系列的MapReduce Job,其中可能包含很多连接操作;作者提出了一种新颖的树形结构索引(all possible join tree)来索引所有可能的执行计划;最后依据代价模型来选择最优的查询计划,从而获得最快的响应时间。
7 研究工作展望
目前,在云计算环境下针对多种不同数据类型(集合数据、空间数据、概率数据等)的大数据相似性连接查询算法的研究已经取得了一些成果,但是仍然存在诸多挑战性问题值得进一步深入研究:
1)大规模超高维数据相似性连接查询技术。
该研究中,对照组用遵医护理,全面化针对性护理干预组用全面化针对性护理干预。结果显示,全面化针对性护理干预组满意程度、血糖空腹指标、餐后2 h指标的监测结果、微量泵注入胰岛素治疗的依从性、复常血糖的时间、住院治疗时间、低血糖、酮症酸中毒等不良事件的发生率方面相比对照组更有优势(P<0.05)。
“高维”是大数据的一个重要特征,基因序列、轨迹数据、视频、音频、图片等非结构化数据都具有高维特性,高维大数据的有效分析和管理是大数据面临的一个重大挑战。高维向量相似性连接查询主要面临两大挑战:一是如何设计高效的过滤方案。当向量维度较高时,现有的以树形索引为基础的过滤方案会面临“维度灾难”问题。当向量维度逐渐增大时,索引的过滤效果逐渐降低,当维度超过一定阈值时,索引的性能甚至不如顺序扫描。二是如何设计高效的可扩展算法。随着向量维度的不断增高,两个向量之间相似度的计算代价会比较大;随着参与连接的向量集合规模的不断扩大,相似性连接的时间复杂度呈指数级增长。传统的集中式处理算法已经无法有效处理大规模超高维向量的相似性连接查询问题。
2)复杂数据类型的大数据相似性连接查询技术。
已有的相似性连接查询研究工作主要集中在常见的集合数据、字符串数据和向量数据。然而,除了这三种数据类型之外,还有很多结构更为复杂的数据类型,如轨迹数据、时间序列、基因数据、流数据、图和XML文档等。这些数据的结构往往更为复杂,相似度的计算代价更高,并且,由于类型不同,已有的相似性连接查询技术并不能有效处理这些更为复杂的数据类型。因此,需要针对这些复杂数据类型的结构和特点,研究新的相似度计算方法、过滤技术和并行化方案。
3)增量式大数据相似性连接查询技术。
目前的大数据相似性连接查询技术大都是基于MapRedcue框架,然而,MapRecduce是一种批处理模型,无法有效处理实时查询和增量式查询。基于Spark等新的计算框架的增量式大数据相似性连接查询技术,有待进一步深入研究。
4)基于哈希学习的近似KNN连接查询技术。
局部敏感哈希技术是解决海量高维向量KNN连接查询的一种有效方案。常用的局部敏感哈希函数虽然具有位置敏感性,但并不能有效保证哈希映射前后数据之间的相对位置关系,影响KNN连接查询结果的质量。将哈希学习思想与局部敏感哈希技术相结合,通过学习的方法来对局部敏感哈希函数进行学习,使得学习到的LSH函数能够最大限度地保持哈希映射前后数据之间的相对位置关系。在此基础上,结合MapReduce框架,研究高维向量并行近似KNN连接查询算法,有效应对扩展性问题。
隐私保护是大数据时代的一个重要研究课题。轨迹数据、基因数据、社交网络数据等都包含了大量的个人敏感信息,如何在确保相似度计算准确性和效率的同时,又能最大限度地保护隐私数据,成为一个亟待解决的研究课题。目前,面向隐私保护的大数据相似性连接查询技术研究工作还处于起步阶段,需要进一步深入研究,例如,可以尝试将差分隐私等最新的隐私保护技术应用到大数据相似性连接查中。
8 结语
相似性连接查询是一种十分重要的操作,在很多数据挖据和数据分析任务中都有应用。随着数据规模的不断增长,针对大数据的相似性连接查询问题出现了新的挑战。本文针对集合、向量、空间数据、概率数据等不同类型大数据的相似性连接查询技术相关工作进行了深入研究,对其优缺点进行了归纳总结,最后指出了大数据相似性连接查询面临的若干挑战性问题。
参考文献(References)
[1] 庞俊,谷峪, 许嘉, 等. 相似性连接查询技术研究进展[J]. 计算机科学与探索, 2013, 7(1): 1-13.(PANG J, GU Y, XU J, et al. Research advance on similarity join queries[J]. Journal of Frontiers of Computer Science & Technology, 2013, 7(1): 1-13.)
[2] 林学民, 王炜. 集合和字符串的相似度查询[J]. 计算机学报, 2011, 34(10): 1853-1862.(LIN X M, WANG W. Set and string similarity queries: a survey[J]. Chinese Journal of Computers, 2011, 34(10): 1853-1862.)
[3] YU M H, LI G L, DENG D, et al. String similarity search and join: a survey[J]. Frontiers of Computer Science, 2016, 10(3): 399-417.
[4] 庞俊, 于戈, 许嘉, 等.基于MapReduce框架的海量数据相似性连接研究进展[J]. 计算机科学, 2015, 42(1): 1-5.(PANG J, YU G, XU J, et al. Similarity joins on massive data based on MapReduce framework[J]. Computer Science, 2015, 42(1): 1-5.)
[5] SILVA Y, REED J, BROWN K, et al. An experimental survey of MapReduce-based similarity joins[C]// Proceedings of the 9th International Conference on Similarity Search and Applications. Berlin: Springer, 2016: 181-195.
[6] KIMMETT B, SRINIVASAN V, THOMO A. Fuzzy joins in MapReduce: an experimental study[J]. Proceedings of the VLDB Endowment, 2015, 8(12): 1514-1517.
[7] LIN J. Brute force and indexed approaches to pairwise document similarity comparisons with MapReduce[C]// Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2009: 155-162.
[8] VERNICA R, CAREY M J, LI C. Efficient parallel set-similarity joins using MapReduce[C]// Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2010: 495-506.
[9] 李瑞, 王朝坤, 郑伟, 等.基于MapReduce框架的近似复制文本检测[J]. 计算机研究与发展, 2010, 47(增刊1): 400-406.(LI R, WANG C K, ZHENG W, et al. Near duplicate text detection based on MapReduce[J]. Journal of Computer Research and Development, 2010, 47(S1): 400-406.)
[10] RONG C T, LU W, WANG X, et al. Efficient and scalable processing of string similarity join[J]. IEEE Transactions on Knowledge and Data Engineering, 2013, 25(10): 2217-2230.
[11] ELSAYED T, LIN J, OARD D. Pairwise document similarity in large collections with MapReduce[C]// HLT-Short 2008: Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics on Human Language Technologies. Stroudsburg, PA, USA: ACL, 2008: 265-268.
[12] METWALLY A, FALOUTSOS C. V-SMART-Join: a scalable MapReduce framework for all-pair similarity joins of multisets and vectors[J]. Proceedings of the VLDB Endowment, 2012, 5(8): 704-715.
[13] BARAGLIA R, MORALES G, LUCCHESE C. Document similarity self-join with MapReduce[C]// Proceedings of the 10th IEEE International Conference on Data Mining. Piscataway, NJ: IEEE, 2010: 731-736.
[14] RONG C T, LIN C B, SILVA Y, et al. Fast and scalable distributed set similarity joins for big data analytics[C]// Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering. Piscataway, NJ: IEEE, 2017: 1-12.
[15] DENG D, LI G L, WEN H, et al. An efficient partition based method for exact set similarity joins[J]. Proceedings of the VLDB Endowment, 2015, 9(4): 360-371.
[16] WANG J J, LIN C. MapReduce based personalized locality sensitive hashing for similarity joins on large scale data[J]. Computational Intelligence and Neuroscience, 2015, 2015: Article No. 37.
[17] LUO W, TAN H, MAO H, et al. Efficient similarity joins on massive high-dimensional datasets using MapReduce[C]// Proceedings of the 13th IEEE International Conference on Mobile Data Management. Piscataway, NJ: IEEE, 2012: 1-10.
[18] SEIDL T, FRIES S, BODEN B. MR-DSJ: distance-based self-join for large-scale vector data analysis with MapReduce[C]// Proceedings of the 15th BTW Conference on Database Systems for Business, Technology, and Web. Berlin: Springer, 2013: 37-56.
[19] FRIES S, BODEN B, STEPIEN G, et al. PHiDJ: parallel similarity self-join for high-dimensional vector data with MapReduce[C]// Proceedings of the 30th IEEE International Conference on Data Engineering. Piscataway, NJ: IEEE, 2014: 796-807.
[20] SILVA Y N, REED J M, TSOSIE L M. MapReduce-based similarity join for metric spaces[C]// Proceedings of the 1st International Workshop on Cloud Intelligence. New York: ACM, 2012: Article No. 3.
[21] SILVA Y N, REED J M. Exploiting MapReduce-based similarity joins[C]// Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2012: 693-696.
[22] 徐媛媛, 陈华辉. 基于MapReduce增量式数据集的相似性连接[J]. 计算机应用研究, 2014, 31(11): 3369-3384.(XU Y Y, CHEN H H. MapReduce-based similarity join for incremental data set[J]. Application Research of Computers, 2014, 31(11): 3369-3384.)
[23] YANG B, KIM H, SHIM J, et al. Fast and scalable vector similarity joins with MapReduce[J]. Journal of Intelligent Information Systems, 2016, 46(3): 473-497.
[24] MA Y Z, MENG X F, WANG S Y. Parallel similarity joins on massive high-dimensional data using MapReduce[J]. Concurrency and Computation: Practice and Experience, 2016, 28(1): 166-183.
[25] MA Y Z, JIA S J, ZHANG Y X. A novel approach for high-dimensional vector similarity join query[J]. Concurrency and Computation: Practice and Experience, 2017, 29(5): 1-12.
[26] JANG M Y, SONG Y, CHANG J. A density-aware similarity join query processing algorithm on MapReduce[M]// PARK J J, JIN H, KHAN M K, et al. Advanced Multimedia and Ubiquitous Engineering. Berlin: Springer, 2016: 469-475.
[27] LIU W, SHEN Y M, WANG P. An efficient MapReduce algorithm for similarity join in metric spaces[J]. The Journal of Supercomputing, 2016, 72(3): 1179-1200.
[28] ZHANG C, LI F, JESTES J. Efficient parallel kNN joins for large data in MapReduce[C]// Proceedings of the 15th International Conference on Extending Database Technology. New York: ACM, 2012: 38-49.
[29] LU W, SHEN Y, CHEN S, et al. Efficient processing of k nearest neighbor joins using MapReduce [J]. Proceedings of the VLDB Endowment, 2012, 5(10): 1016-1027.
[30] 戴健, 丁治明. 基于MapReduce快速kNN Join方法[J]. 计算机学报, 2015, 38(1): 99-108.(DAI J, DING Z M. MapReduce based fast kNN join[J]. Chinese Journal of Computers, 2015, 38(1): 99-108.)
[31] KIM Y, SHIM K. Parallel Top-Ksimilarity join algorithms using MapReduce[C]// Proceedings of the 2012 IEEE 28th International Conference on Data Engineering. Washington, DC: IEEE Computer Society, 2012, 510-521.
[32] 马友忠, 慈祥. 海量高维向量的并行Top-k连接查询[J]. 计算机学报, 2015, 38(1): 86-98.(MA Y Z, CI X. Parallel Top-kjoin on massive high-dimensional vectors[J]. Chinese Journal of Computers, 2015, 38(1): 86-98.)
[33] CHEN D H, SHEN C G, FENG J Y, et al. An efficient parallel Top-ksimilarity join for massive multidimensional data using spark[J]. International Journal of Database Theory and Application, 2015, 8(3): 57-68.
[34] ZHANG S B, HAN J Z, LIU Z Y, et al. SJMR: parallelizing spatial join with MapReduce on clusters[C]// Proceedings of 2009 IEEE International Conference on Cluster Computing and Workshops. Piscataway, NJ: IEEE, 2009: 1-8.
[35] 刘义, 陈荦, 景宁, 等. 海量空间数据的并行Top-k连接查询[J]. 计算机研究与发展, 2011, 48(增刊3): 163-172.(LIU Y, CHEN L, JING N, et al. Parallel Top-kspatial join query processing on massive spatial data[J]. Journal of Computer Research and Development, 2011, 48(S3): 163-172.)
[36] LIU Y, CHEN L, JING N, et al. MRFM: an efficient approach to spatial join aggregate[C]// Proceedings of the WAIM 2012 International Workshops: GDMM, IWSN, MDSP, USDM, and XMLDM. Berlin: Springer, 2012, 140-150.
[37] 刘义, 景宁, 陈荦, 等. MapReduce框架下基于R-树的k-近邻连接算法[J]. 软件学报, 2013, 24(8): 1836-1851.(LIU Y, JING N, CHEN L, et al. Algorithm for processingk-nearest join based on R-tree in MapReduce[J]. Journal of Software, 2013, 24(8): 1836-1851.)
[38] GUPTA H, CHAWDA B, NEGI S, et al. Processing multi-way spatial joins on Map-Reduce[C]// Proceedings of the 16th International Conference on Extending Database Technology. New York: ACM, 2013, 113-124.
[39] ZHANG Y, MA Y, MENG X. Efficient spatio-textual similarity join using MapReduce [C]// Proceedings of the 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technologies. Piscataway, NJ: IEEE, 2014: 52-59.
[40] 雷斌, 许嘉, 谷峪, 等. 概率数据上基于EMD距离的并行Top-k相似性连接算法[J]. 软件学报, 2013, 24(增刊2): 188-199.(LEI B, XU J, GU Y, et al. Parallel Top-ksimilarity join algorithm on large probabilistic data based on earth mover’s distance[J]. Journal of Software, 2013, 24(S2): 188-199.)
[41] HUANG J, ZHANG R, BUYYA R, et al. MELODY-JOIN: efficient earth mover’s distance similarity joins using MapReduce[C]// Proceedings of the 30th IEEE International Conference on Data Engineering. Piscataway, NJ: IEEE, 2014: 808-819.
[42] HUANG J, ZHANG R, BUYYA R, et al. Heads-Join: efficient earth mover’s distance similarity joins on Hadoop[J]. IEEE Transactions on Parallel and Distributed Systems, 2016, 27(6): 1660-1673.
[43] XU J, LEI B, GU Y, et al. Efficient similarity join based on earth mover’s distance using MapReduce[J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(8): 2148-2162.
[44] MA Y Z, MENG X F. Set similarity join on massive probabilistic data using MapReduce[J]. Distributed and Parallel Databases, 2014, 32(3): 447-464.
[45] WANG J N, LI G L, FENG J H. Extending string similarity join to tolerant fuzzy token matching[J]. ACM Transactions on Database Systems, 2014, 39(1) : Article No. 7.
[46] LI G L, DENG D, FENG J H. Pass-Join+: a partition-based method for string similarity joins with edit-distance constraints[J]. ACM Transactions on Database Systems, 2013, 38(2) : Article No. 9.
[47] JIANG Y, LI G, FENG J H, et al. String similarity joins: an experimental evaluation[J]. Proceedings of the VLDB Endowment, 2014, 7(8): 625-636.
[48] WANG W, QIN J B, XIAO C, et al. VChunkJoin: an efficient algorithm for edit similarity joins[J]. IEEE Transactions on Knowledge & Data Engineering, 2013, 25(8): 1916-1929.
[49] LU J H, LIN C B, WANG W, et al. String similarity measures and joins with synonyms[C]// SIGMOD 2013: Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2013: 373-384.
[50] XIAO C, WANG W, LIN X M, et al. Efficient similarity joins for near duplicate detection[J]. ACM Transaction of Database Systems, 2011, 36(3): Article No. 15.
[52] DENG D, LI G L, HAO S, et al. MassJoin: a MapReduce-based algorithm for string similarity joins[C]// Proceedings of IEEE 30th International Conference on Data Engineering. Piscataway, NJ: IEEE, 2014: 340-351.
[53] LIN C, YU H Y, WENG W, et al. Large scale similarity join with edit-distance constraints[C]// Proceedings of 19th International Conference on Database Systems for Advanced Applications. Berlin: Springer, 2014: 328-342.
[54] LI G L, DENG D, WANG J N, et al. Pass-join: a partition-based method for similarity joins[J]. Proceedings of the VLDB Endowment. Berlin: Springer, 2011, 5(3): 253-264.
[55] PANG J, GU Y, XU J, et al. Efficient graph similarity join with scalable prefix-filtering using MapReduce[C]// Proceedings of 15th International Conference on Web-Age Information Management. Berlin: Springer, 2014: 415-418.
[56] CHEN Y F, ZHAO X, GE B, et al. Practising scalable graph similarity joins in MapReduce[C]// Proceedings of the 2014 IEEE International Congress on Big Data. Washington, DC: IEEE Computer Society, 2014: 112-119.
[57] ZHANG X F, CHEN L, WANG M. Towards efficient join processing over large RDF graph using MapReduce[C]// Proceedings of the 24th International Conference on Scientific and Statistical Database Management. Berlin: Springer, 2012: 250-259.
This work is partially supported by the National Natural Science Foundation of China (61602231), the National Key R&D Plan Project (2016YFE0104600), the Science and Technology Open Cooperation Project of Henan Province (172106000077, 152106000048), the Key Scientific Research Project of Higher Education of Henan Province (16A520022).
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
小资CHIC!ELEGANCE(2022年1期)2022-01-11 00:49:59
河北画报(2020年8期)2020-10-27 02:54:20
数学物理学报(2020年3期)2020-07-27 01:19:46
海峡姐妹(2017年12期)2018-01-31 02:12:22
作文与考试·初中版(2017年12期)2017-04-19 20:24:45
法大研究生(2017年1期)2017-04-10 08:55:06
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:21
中学生(2015年12期)2015-03-01 03:43:53
