
基于签到序列模式的隐式位置访问推演技术
2018-06-15 04:34夏秀峰叶镇搏刘向宇周大海安云哲沈阳航空航天大学计算机学院沈阳110136
沈阳航空航天大学学报 2018年2期
夏秀峰,叶镇搏,刘向宇,周大海,安云哲(沈阳航空航天大学 计算机学院,沈阳 110136)
随着社交网络的蓬勃发展,多种社交应用为数亿用户提供着各种功能强大的社交服务。其中,位置签到服务是社交应用的一项主流服务。在签到服务中,用户使用带有定位功能的移动设备向服务器发送自己所处地理位置进行位置签到。基于位置签到数据服务商可以进行位置推演、用户移动模式分析等移动计算任务,从而实现提高服务质量、促进移动营销、旅行规划、灾难救援等实际应用[1-5]。
目前,Foursquare的签到数据已达5亿多条。国内的切客、街旁等签到服务也有近亿条的位置签到数据。但是,社交应用中的位置签到数据具有稀疏性和不完整性[4,7],主要原因是:(1)大规模的位置签到数据反映了用户某些行为模式和特性,从而为他人进行个人隐私推演提供了可能[5-9],导致移动用户在使用社交应用时极为谨慎,在某些敏感地点有意关闭位置签到服务;(2)用户的位置签到行为具有一定的随机性,更加增强了位置签到数据的稀疏性和不完整性。因此,导致了上述基于位置签到数据的各项移动计算任务的准确率、服务质量的降低。
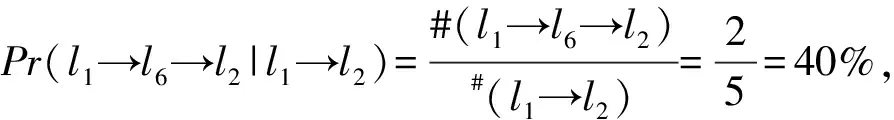
(1)对于不存在于历史轨迹数据的地点的访问概率推演结果为0;
(2)对于不同类别的地点的访问概率推演结果可能相同,无法进行更加精确的推演。

表1 历史轨迹数据
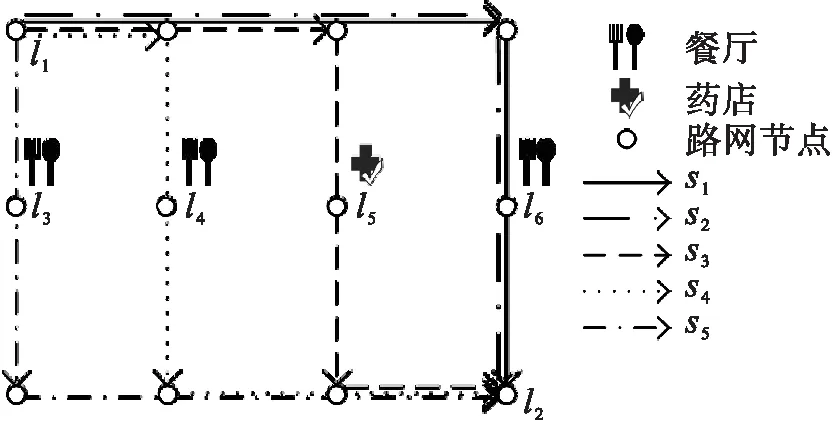
图1 用户u的历史轨迹数据
产生上述问题的原因在于,当前研究主要基于历史数据中的访问地点进行推演,而忽略了访问地点类别所导致的推演结果差异。针对此问题,本文提出了一种基于用户签到序列模式的隐式位置访问推演技术,其基本思想是利用用户的历史轨迹数据来生成签到序列模式,基于生成的签到序列模式对可能包含隐式地点访问的轨迹数据进行扩展,从而降低了轨迹数据的稀疏性问题,提高了隐式位置访问概率计算的精度。为了设计并实现本文的基于签到序列模式的隐式位置访问推演算法,需要解决如下挑战问题和难点:
(1)生成用户签到序列模式是一个挑战性问题。当采用频繁规则挖掘算法会丢失签到地点之间的时空关联特性,而采用时间关联规则挖掘算法则会忽略签到地点之间的空间连续性,设计一种适合的用户签到序列模式挖掘算法,在获得签到序列模式的同时保证签到地点之间的空间连续性和时空关联特性不发生改变是一个难点问题;
(2)当推演新地点访问时,需要采用降低数据稀疏性、增加候选隐式访问地点的方法解决,但有效地降低数据稀疏性、并在降低稀疏性的同时保持用户原有的签到序列模式不发生改变是另一个挑战性问题;
(3)现有的基于贝叶斯的地点访问推演模型没有考虑地点类别对于地点访问推演的影响,如何基于移动轨迹中地点类别设计地点访问推演模型是一个较复杂问题。
本文主要工作和贡献如下:
(1)提出一种用户签到序列模式的度量和挖掘方法,在保持签到地点时空关联特性的基础上,保证了邻近签到点间的空间连续性;
(2)提出了一种基于用户签到序列模式的隐式位置访问推演算法,基于用户的签到序列模式,通过对可能包含隐式地点访问的历史轨迹数据进行扩展,在降低轨迹数据的稀疏性同时提高了隐式位置访问概率计算的精度;
(3)基于真实大规模数据集进行实验测试,验证了所提出算法能有效抵制签到数据的稀疏性问题,高精度地对隐式位置访问进行推演和概率计算,同时验证了该算法的高执行效率。
1 相关工作
位置推演是签到服务中一种基于用户历史数据的推测服务。它是指使用用户的背景知识(在移动社交网络中指用户的社会关系及历史签到数据)推导用户在某时刻的位置。截至目前,国内外研究人员不断对其进行深入研究,提出了多类推演算法。
第一种采用贝叶斯模型[1,3-4,7,9,17-18],该方法使用用户的历史数据建立一个贝叶斯模型,通过计算用户访问推演点的后验概率推演用户是否会访问该点,该模型存在着对于新地点的推演效果不佳问题。文献[5]、[11]、[19]中提出了一种在移动社交网络中推演用户位置的方法。该方法通过用户n个朋友在t时刻的位置以及时刻t的属性(具体包括t是工作日或周末,上下班时间段或其它时间段等)判断该用户在t时刻的位置。作者采用动态贝叶斯网络作为推演模型,并用真实的签到数据训练该模型但此方法需要进行训练学习,时间及空间代价较大。
第二种采用协同过滤推演模型[1,17-18],通过协同过滤找到与用户相似的用户,再推演这些相似用户访问该位置的概率来推演用户访问该地点的概率。2013年Z.Huo等[1]在文献中提出了一种协同过滤推演方法,虽然解决了无法推演新地点的问题,但是推演结果精度较低仅有42%。Cheng等[17]融合地域影响力和社交信息建立矩阵分解模型,从而进行个性化位置推荐。Jia等[18]提出SeqRWR方法动态选择在每个时间片对目标用户最有影响力的N个朋友,然后利用所提的TSB模型对朋友影响力的特征建模,推演用户在每个时间片的位置并进行推荐。
第三种采用隐马尔科夫模型。主要思想是应用马尔可夫过程推演用户位置。根据马尔可夫过程得知,用户下一个访问地点仅仅与用户前一个访问地点有关,精确度可达80%。2013年Andy Yuan Xue等[3]在文献提出了SubSyn算法。该算法主要减少了数据稀疏性对推演工作带来的困难,通过将用户活动空间划分为网格将推演位置转化为推演位置所处的网格,通过计算从一个网格到另一个网格的转移概率推演用户访问该点的概率。
综上所述,当前位置推演技术主要存在以下缺点:过于依赖历史数据,对于新访问地点推演的精度不理想,不同类别点的推演结果无法差异化;当位置签到数据具有较大稀疏性时,推演结果较差。产生上述问题的根本原因在于当前位置推演计算技术忽略了位置访问地点具有不同的类别,而访问地点类别对于位置推演和推演结果具有较大影响。针对此问题,本文提出了一种基于用户签到模式的位置隐私推演算法。
2 预备知识和问题定义
定义1 签到序列:位置签到数据以(li,ti)形式来表示,其中li表示签到地点,ti表示位置签到时间;将用户uk的签到数据按时间排序组成其签到序列sk=[(l1,t1),…,(li,ti),…,(ln,tn)],sk[(l1,t1),…,(li,ti),…,(ln,tn)],sk[i]代表用户uk第i个位置签到数据。
定义2 连续子序列:签到序列s=l1→…→li→…→ln,若存在序列t=li→li+1→…→li+k-1且由签到序列s中连续的k个点组成,k≤n,则将序列t定义为序列s的一个连续子序列,记为t⊆s。
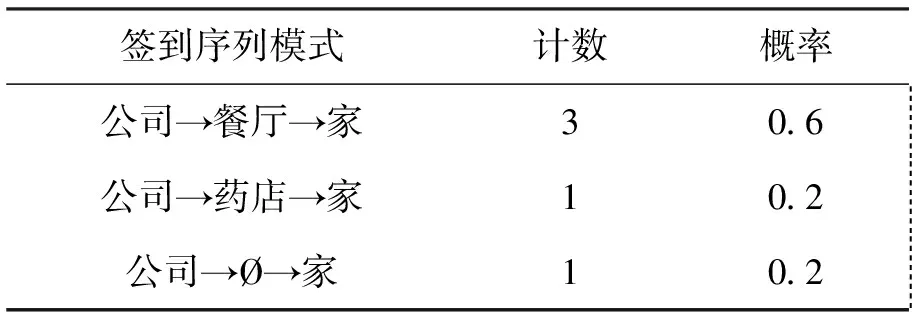
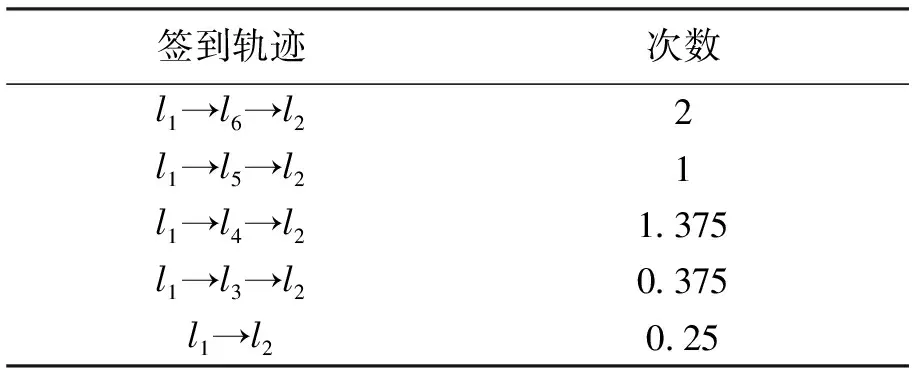
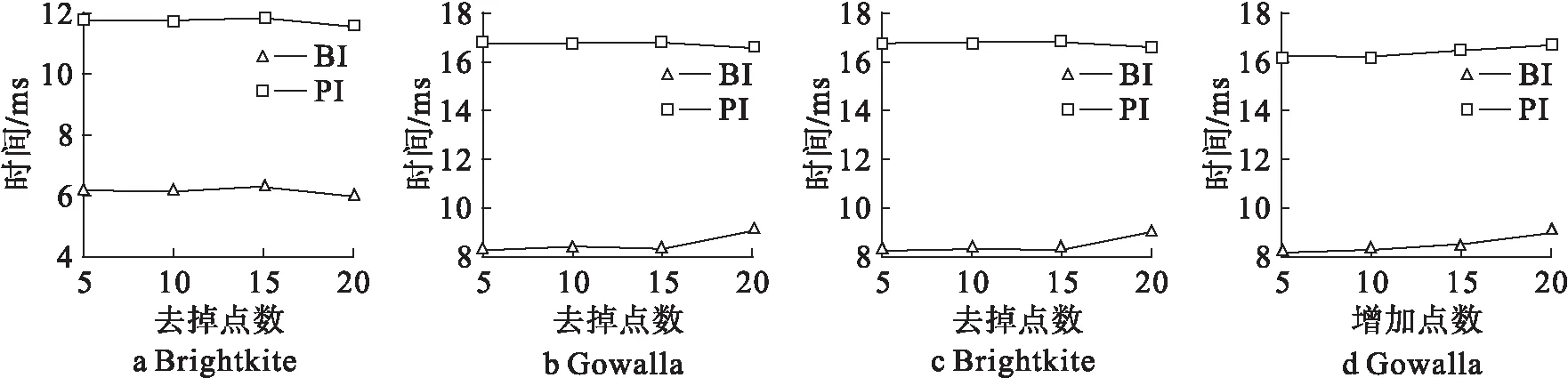
定义3 非连续子序列:签到序列s=l1→…→li→…→ln,若存在序列c=lp→lq→…→ld且由签到序列s中非连续的m个点组成,m 定义4 地点类别:每一个地点li均对应一个地点类别,记作c(li);将地点类别集合表示为C={c1,…,ci,…,cn},用户uk的所有签到地点的地点类别集合表示为Ck。 例如图1中,地点l3、l4、l6的地点类别为“餐厅”,l5的类别为“药店”,用户u的签到地点类别集合为Cu={“公司”,“餐厅”,“药店”,“家”}。 定义5 签到序列模式:签到序列模式可以用P=c1→c2→…→cn的形式来表示,对于用户u的某个签到序列s=lp→lm→…→ln→lq,s的签到序列模式可记作P(s)=c(lp)→c(lm)→…→c(ln)→c(lq)。在本文中,s的签到序列模式亦简称为s的模式。 定义6 签到序列模式支持度数:已知用户uk的签到序列集合为Sk,对于模式P=c1→c2→…→cn,将支持P的签到序列集合表示为SUPP(Sk,P)={s|s∈Sk:P(s)=P},该签到序列模式支持度数为sup(Sk,P)=|SUPP(Sk,P)|。 定义7 隐式地点:已知用户在ti和tj时刻分别访问地点li和lj并签到,如果在此过程中用户访问地点lm但未签到,则称地点lm为用户的隐式地点。 问题1 隐式地点访问概率推演:已知用户uk的历史签到序列集合Sk,对于位于路径li→lj上的隐式地点lm,推演和计算用户uk在从地点li移动至地点lj过程中访问lm的概率。 如图1所示,本文解决的主要问题是当用户在t1时刻经过地点l1并在t2时刻到达地点l2的过程中,基于用户的历史轨迹数据推演该用户访问l3、l4、l5、l6各地点的概率。 本节提出一种基于签到序列模式的隐式位置推演算法(Pattern based Hidden Location Inference,简称PI),具体过程如算法1所示。算法1基本思想是:首先基于用户的历史签到序列数据通过计算得到该用户的签到序列模式及其对应概率;然后根据得到的签到序列模式对用户的签到序列集合进行隐式位置推演和签到序列扩展;最后基于扩展后的签到序列集合采用贝叶斯后验概率来计算和推演用户访问隐式地点lm的概率。 算法1.隐式地点访问概率推演算法(Pattern based Hidden Location Inference) 输入: 签到序列集合Sk, 地点类别集合Ck, 地图map, 地点li、lm、li+1. 输出: 隐式地点lm访问概率. (1)PSPL=Pattern_Seq_Pro(Sk,Ck,li,li+1); /* 获得签到序列模式及对应概率 */ (2)Extend_Seq(li,li+1,Sk,Ck, map,PSPL);/* 隐式位置推演和签到序列扩展 */ (3)num1=0, num2=0; (4)For eachsiinSkDo (5) Ifli→lm→li+1⊆siThen (6) num1++; (7) Ifli→li+1⊂siThen (8) num2++; (10)Return Pro; 在算法1中,输入为签到序列集合Sk、地点类别集合Ck、地点li、lm和li+1,输出为用户uk从li移动至li+1过程中访问地点lm的概率。算法1首先调用子算法Pattern_Seq_Pro,Pattern_Seq_Pro算法输入为用户历史序列Sk、地点类别集合Ck、地点li和li+1,输出用户所有符合c(li)→c(lm)→c(li+1)形式的签到序列模式以及对应的访问概率,并存入列表PSPL。然后,算法1调用子算法Extend_Seq,Extend_Seq算法以签到序列集合Sk和PSPL作为输入,实现对用户签到序列集合Sk中某些轨迹的扩展。算法1基于扩展后的签到序列集合Sk、采用公式(1)来计算从li移动至li+1过程中访问地点lm的概率。在公式(1)中,∑Sli→lm→li+1表示签到序列集合中li→lm→li+1的数量,∑Sli→li+1表示签到序列集合中li→li+1的数量。公式(1)采用贝叶斯后验概率计算用户从li出发到达li+1途中访问lm的概率。 (1) 例如,针对表1中的历史签到序列数据,基于签到序列模式进行扩展后得到如表3所示的新签到序列Sk,此时采用公式(1)可得用户从l1出发到达l2途中访问各地点的概率分别为:Pr(l1→l3→l2|l1→l2)=0.075,Pr(l1→l4→l2|l1→l2)=0.275,Pr(l1→l5→l2|l1→l2)=0.2,Pr(l1→l6→l2|l1→l2)=0.4,Pr(l1→Ø→l2|l1→l2)=0.04;特殊地,Pr(l1→?→l2|l1→l2)表示用户从l1出发直达l2途中没有在任意点停留的概率。 算法2给出了签到序列模式概率计算(Pattern_Seq_Pro算法)的具体描述,以用户签到序列集合Sk、地点类别集合Ck、地点li和li+1作为输入,输出模式序列概率列表PSPL,该列表包含了用户所有符合c(li)→c(lm)→c(li+1)形式的签到序列模式以及对应的访问概率。 Pattern_Seq_Pro算法基本思想是:先基于用户地点类别集合Ck找到地点li和li+1对应的地点类别建立对应的签到序列模式;再基于得到的签到序列模式对用户的签到序列集合进行遍历并记录与之一致的数量;同时,根据输入地点类别得到对应的所有签到序列模式并统计数量;最后,基于以上两个统计数量采用贝叶斯后验概率来计算用户某一签到序列模式的概率。 算法2.模式序列概率(Pattern_Seq_Pro) 输入:签到序列集合Sk,地点类别集合Ck,地点li、li+1. 输出:模式序列概率列表PSPL. (1)num1=0; (2)For eachsiiinSkDo (3)If c(li)→c(li+1)⊂P(si) Then (4) num1++; (5)For each c(lm) inc(li)→c(li+1)⊂P(si) Do (6)num(c(li) →c(lm) →c(li+1))++; (7)Ifc(lm)∉LThen (8)L←L∪{c(lm)}; (9)For each c(lm) inLThen (11)Return PSPL。 算法2的时间复杂度为O(|Sk|+num1)。 例如,当输入地点l1和l2、表1中签到序列集合Sk、地点类别集合Ck时,算法2可得签到序列的模式:P(l1→l6→l2)=P(l1→l4→l2)=“公司”→“餐厅”→“家”,其中3个签到序列符合模式“公司”→“餐厅”→“家”,其对应概率为Pr(“公司”→“餐厅”→“家”)=0.6;相似地,可得P(l1→l5→l2)=“公司”→“药店”→“家”,该模式对应概率为Pr(“公司”→“药店”→“家”)=0.2;P(l1→Ø→l2)=“公司”→Ø→“家”=1,该模式对应的概率为Pr(“公司”→Ø→“家”)=0.2。表2给出了算法2得到的签到序列模式及其对应概率。 表2 签到序列模式概率 由于用户的签到序列具有地点稀疏性等特点,采用算法2中获得的签到序列模式及其概率通过算法3对某些序列进行扩展,从而降低签到序列数据稀疏度、实现隐式位置访问推演。 算法3给出了扩展签到序列(Extend_Seq算法)的具体描述,以用户签到序列集合Sk,地点类别集合Ck、地图数据map、签到序列模式列表PSPL、地点li和li+1作为输入,对Sk中符合特定规则的签到序列进行扩展。Extend_Seq算法的基本思想是在历史签到序列集合Sk中找到可扩展序列se=li→li+1,基于该序列中访问地点li、li+1及其时间差?t=ti+1-ti(地点li的访问时间记作ti)来获得此路径过程中可能经过的隐式地点,并基于PSPL中的签到序列模式来计算每个隐式地点的访问概率,具体过程如算法3所示。 输入:地点li、li+1,签到序列集合Sk,地点类别集合Ck,地图数据map,模式序列概率列表PSPL. (1)D=Ø,L=Ø, times=0; /* D存储扩展后的签到序列 */ (2)For eachsiinSkDo (3)Ifli→li+1⊆siThen (4)Δt←ti+1-ti; (5)L←Hidden locations with respect toli,li+1, map and Δt; (6) For each categorycm∈C(L) Do (8)For each locationlmin L of categorycmDo (9) Add (li→lm→li+1, times) toD; (10)NormalizeD; /* 对列表D中的访问概率进行归一化 */ (11)Sk=Sk∪D; Extend_Seq算法首先遍历用户签到序列集合Sk,判断序列si中是否存在li至li+1的连续子序列,若存在则计算在ti时刻从li出发、ti+1时刻到达li+1的时间差Δt=ti+1-ti。基于li、li+1和时间差Δt在地图map中筛选出所有从li至li+1途中能在Δt时间内经过的地点并存入集合L。对于集合L中的任意地点lm与li、li+1组成的签到序列采用公式(2) 计算其访问次数。在公式(2)中,|cm(L)|表示集合L中地点类别为cm的地点数量,PSPL(c(li)→cm→c(li+1))表示签到序列模式c(li)→cm→c(li+1)的访问概率,得到的times表示扩展序列li→li+1后签到序列li→lm→li+1的访问次数。 (2) 对于L中的每一个地点lm与li和li+1组成签到序列sj=li→lm→li+1,连同其对应的访问次数times以二元组形式存入列表D。需要对D中所有签到序列的访问次数按照公式(3)进行归一化。在公式(3)中,times(sj)表示D中未归一化时签到序列sj的访问次数,time(sj)表示归一化后签到序列sj访问次数。 (3) 通过将集合D与集合Sk合并,得到扩展后的签到序列集合Sk。算法3的时间复杂度为O(|Sk|+|L|)。 表3 扩展后轨迹数据 本文对提出的隐式位置推演算法的有效性进行评估。在实验过程中,选取两个真实数据集Brightkite和Gowalla进行实验和分析。 Brightkite和Gowalla是基于位置的社交网络服务提供商,其中用户可以通过签到服务来分享他们的位置。本文对Brightkite和Gowalla数据集进行预处理,筛选出美国加州地区的签到数据,预处理后Brightkite数据集包含9192名用户,签到时间从2008年4月到2010年10月,签到记录为52万条;在Gowalla数据集中共有14852名用户,时间从2009年2月至2010年10月,签到记录为65万条。对用户签到序列以天为单位分割为若干子签到序列;提取出两个数据集中签到地点并对其进行编号,通过开源API获得签到地点的地点名称和地点类别;表4显示实验数据集的统计信息。 实验软硬件环境如下:(1)硬件环境:Intel Core i5 3.20GHz,4GB DRAM内存;(2)操作系统平台:Microsoft Windows 7;(3)编程环境:Python2.7.11,Pycharm。 为了进行对比,本文将文献[1]中的推演算法进行了实现,记作BI。实验中随机抽取1 000名用户历史签到记录。随机向每个用户的历史签到记录中去掉5、10、15、20个点,将去掉点后的历史签到记录作为集合1。在用户的历史签到记录集合中随机添加5、10、15、20个用户未曾签到过的地点作为干扰点,将添加点后的历史签到数据作为集合2。其中,去掉点与增加点被视为用户的隐式位置。 表4 实验数据集统计信息 本文采用以下四个标准衡量推演结果。 (2)预测率1:推演算法计算用户访问集合1中去掉点的访问概率。 (4)预测率2:推演算法计算用户访问集合2中增加点的访问概率。 正确率结果如图2所示,在两个数据集上,PI算法的正确率都要高于BI算法。由于Gowalla数据集密集度高于Brightkite数据集,所以PI算法在Gowalla数据集上正确率达到81.75%高于在Brightkite数据集的61.5%。去掉的地点皆为用户曾经访问过的地点,虽然去掉了地点,但仍有可能从其余的历史记录中推测出对应的签到模式。所以PI算法在正确率上要高于BI算法。 错误率如图3所示,PI算法在Brightkite数据集上的错误率不到10%。随着增加点数不断增多两个算法在错误率上呈上升趋势。增加的点有三种类型,第一类为用户曾经访问过的地点;第二类为用户未曾访问过的地点,但与起点和终点组成的签到序列对应的模式符合用户的签到模式;第三类为用户未曾访问过的地点,且与起点和终点形成的签到序列对应的模式不符该用户的签到模式;由于PI算法基于历史记录以及用户签到模式,所以当增加地点为第三类型地点时,PI算法的错误率会下降。而当为第二类地点时,错误率就会上升,如图3(a)中,当增加点数为15时PI算法的错误率为13%,而当增加点数为20时,错误率为12%。 图2 正确率 图3 错误率 预测率1、预测率2的结果如图4、5所示。预测率1证明了算法的有效性和可用性,预测率2则代表算法的无效性。结合图4和图5,可以得到预测率1在两个数据集上的平均值为50.8%,预测率2在两个数据集上的平均值为22.3%,预测率1高于预测率2,说明了BI和PI算法对用户访问地点推演皆有效。PI算法在两个数据集上的预测率1的平均值为65.6%,BI算法在两个数据集上的预测率1的平均值为40.6%,PI算法结果高于BI算法。原因是PI算法对数据集进行了扩充增加了可选序列数目。PI算法的预测率2在两个数据集分别为15%和20%,低于BI算法在两个数据集上的预测率2。由于添加点的随机性,当添加点为第二类地点时PI算法的预测率2要明显低于BI算法。 图4 预测率1 图5 预测率2 算法运行时间结果如图6所示,由于Gowalla数据集中地点密度高于Brightkite数据集,所以无论是增加点还是去掉点,两种算法在Brightkite数据集上的运行时间都要小于在Gowalla数据集上的运行时间。PI算法在两个数据集上的平均运行时间为13.77 ms,BI算法在两个数据集上的平均运行时间为7.25 ms,PI算法运行时间要大于BI算法,这是由于PI算法需要比BI算法进行更多的计算导致的,例如PI算法中包含了模式序列概率计算与签到序列扩展计算。由于去掉、增加点数目有限,候选集中地点数目总体上变化不大,导致两种算法的时间变化不明显趋于稳定。 本文针对基于时空特性的隐式位置推演问题展开研究,提出了一种基于用户签到序列模式的隐式位置访问推演算法PI算法实现对用户隐式位置访问的概率计算。PI算法通过历史轨迹数据生成签到序列模式,基于签到序列模式对可能包含隐式地点访问的轨迹数据进行扩展,从而降低了轨迹数据的稀疏性,提高了隐式位置访问概率的计算精度。通过真实的签到数据集进行实验表明PI算法能有效抵制签到数据的稀疏性问题,并能高精度地对隐式位置访问进行推演和概率计算,同时还验证了PI算法的高执行效率。 图6 算法运行时间对比 参考文献(References): [1] HUO Z,MENG X,ZHANG R.Feel free to check-in:privacy alert against hidden location inference attacks in GeoSNs[C]//International Conference on Database Systems for Advanced Applications.Springer,Berlin,Heidelberg,2013:377-391. [2] WANG H,WANG H,YI F,et al.Context-aware personalized path inference from large-scale GPS snippets[J].Expert Systems with Applications,2018,91:78-88. [3] XUE A Y,ZHANG R,ZHENG Y,et al.Destination prediction by sub-trajectory synthesis and privacy protection against such prediction[C]//Data Engineering(ICDE),2013 IEEE 29th International Conference,Brisbane,2013:254-265. [4] 李媛.基于位置的社交网络推荐算法的研究与应用[D].沈阳:中国科学院沈阳计算技术研究所,2015. [5] 霍峥,孟小峰,黄毅.PrivateCheckIn:一种移动社交网络中的轨迹隐私保护方法[J].计算机学报,2013,36(4):716-726. [6] WICKER SB.The loss of location privacy in the cellular age[J].Communications of the ACM,2012,55(8):60-68. [7] BAO JIE,HE TIANFU,RUAN SIJIE,et al.Planning bike lanes based on sharing-bike’s trajectories[C]//Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Halifax,2017:1377-1386. [8] SADILEK A,KAUTZ H,BIGHAM J P.Finding your friends and following them to where you are[C]//Proceedings of the Fifth ACM International Conference on Web Search and Data Mining.Washington D.C,2012:723-732. [9] 孙瑞.基于轨迹和POI数据的热点区域实时预测[D].长春:吉林大学,2017. [10]陈勐,刘洋,王月,等.基于时序特征的移动模式挖掘[J].中国科学:信息科学,2016,46(9):1288-1297. [12]WERNKE M,SKVORTSOV P,DÜRR F,et al.A classification of location privacy attacks and approaches[J].Personal and Ubiquitous Computing,2014,18(1):163-175. [13]ZHANG L,FANG C,LI Y,et al.Optimal strategies for defending location inference attack in database-driven CRNs[C]//Communications(ICC),2015 IEEE International Conference.London,2015:7640-7645. [14]SONG Y,HU Z,LIU H,et al.A novel group recommendation algorithm with collaborative filtering[C]//Social Computing(SocialCom),2013 International Conference.Washington,DC,2013:901-904. [15]YAP G E,LI X L,YU P.Effective next-items recommendation via personalized sequential pattern mining[C]//Database Systems for Advanced Applications.Springer Berlin/Heidelberg,2012:48-64. [16]HUO Z,MENG X,HU H,et al.You can walk alone:trajectory privacy-preserving through significant stays protection[C]//International Conference on Database Systems for Advanced Applications.Springer,Berlin,Heidelberg,2012:351-366. [17]YUAN Q,CONG G,MA Z,et al.Time-aware point-of-interest recommendation[C]//Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval,New York 2013:363-372. [18]CHENG CHEN,YANG HAIQIN,KING I,et al.Fused matrix factorization with geographical and social influence in location-based social networks[C]//Proceedings of the 26th AAAI Conference on Artificial Intelligence,Toronto,2012:17-23. [19]JIA YANTAO,WANG YUANZHUO,JIN XIAOLONG,et al.Location prediction:a temporal-spatial bayesian model[J].ACM Transactions on Intelligent Systems and Technology,2016,7(3):31. [20]DASH M,KOO K K,GOMES J B,et al.Next place prediction by understanding mobility patterns[C]//Pervasive Computing and Communication Workshops(PerCom Workshops),2015 IEEE International Conference.St.Louis,2015:469-474.3 隐式地点访问概率推演

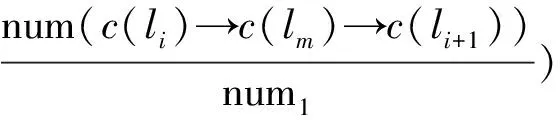
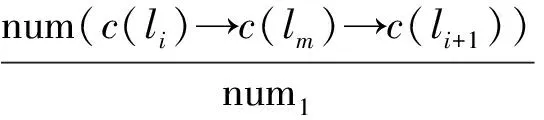



4 实验
4.1 实验设置
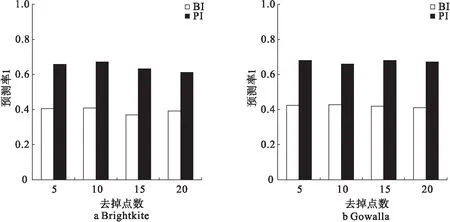
4.2 实验结果分析





5 总结
猜你喜欢
大学数学(2022年6期)2023-01-14
四川大学学报(自然科学版)(2021年6期)2021-12-27
少儿画王(3-6岁)(2020年4期)2020-09-13
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
文苑(2015年9期)2015-09-10
浙江大学学报(工学版)(2015年1期)2015-03-01
新课程学习·中(2013年3期)2013-06-14
