
结合注意力机制的Bi-LSTM维吾尔语事件 时序关系识别
2018-06-12 08:48田生伟吐尔根依布拉音赵建国
东南大学学报(自然科学版) 2018年3期
田生伟 胡 伟 禹 龙 吐尔根·依布拉音 赵建国 李 圃
(1新疆大学软件学院, 乌鲁木齐 830008)(2新疆大学信息科学与工程学院, 乌鲁木齐 830046)(3新疆大学中国语言学院, 乌鲁木齐 830046)
事件(event)作为知识表示的一种重要形式,在自然语言处理领域受到广泛关注.事件时序关系是指事件发生时其在时间上的先后顺序关系,是事件间的一种语义关系.孙辉[1]结合统计机器学习方法和计算语言学知识,构造出基于OTC语料库(Timebank语料库和Opinion语料库的合集)的英文事件时序关系识别模型.Tourille 等[2]通过对THYME[3]语料库分析,利用Bi-LSTM模型抽取医学事件时序关系,实验结果表明该模型能够有效学习过去和将来的语义信息.郑新等[4]通过构造全局优化模型,提出了一种基于全局优化的中文事件时序关系的推理方法,该模型将事件时序关系看成整数线性规划问题.
LSTM作为一种序列化模型,将维吾尔语文本视为有序词序列,可充分考虑文本有序性和词汇关联性,更加符合自然语言表现形式.Tang 等[5]通过构建基于LSTM模型来解决语义关系分类问题,实验结果表明,与LSTM相比,Bi-LSTM能挖掘更丰富的语义信息,并具有充分利用上下文信息的能力.Zhou 等[6]提出基于注意力机制的Bi-LSTM模型,将其应用于双语情感分析,从而验证了注意力机制在LSTM模型中应用的有效性.
目前,事件时序关系研究主要针对中文和英文等大语种,而关于维吾尔语等小语种的研究则相对较少.TimeML标注体系中提出了13种时序关系的分类方案,本文将事件时序关系划分为间断前后关系、不间断前后关系以及重叠关系3类.在维吾尔语事件时序关系识别任务中采用结合注意力机制的Bi-LSTM模型,将维吾尔语事件时序关系的识别问题转化为对事件时序关系的三分类问题.
1 事件相关定义
定义1事件是指在特定时间和环境下发生、由若干角色参与、表现出动作特征的一件事情[7].图1中描述了4个事件,分别为报道事件、火灾事件、死亡事件和受伤事件.

译文:
据土耳其媒体29日报道,土耳其东南部马尔丁省的一个叙利亚难民营当天发生火灾,造成3人死亡、6人受伤。
图1事件触发词举例
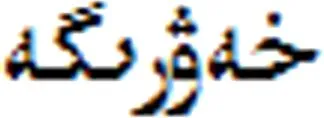


据新疆地震局预测……图2泛指事件举例
定义4候选事件对(candidate event pair)是指对维吾尔语文本中所有事件按照组对规则进行组对后的事件对.
假设给定维吾尔语文本中的事件集合为E={e1,e2,…,en}.按照一定的规则对事件集合中的事件进行组对,从而构成候选事件对〈ei,ej;y〉.其中,y∈{0,1,2}为候选事件对的标签,0表示事件ei和事件ej为间断前后关系,1表示事件ei和事件ej为不间断前后关系,2表示事件ei和事件ej为重叠关系.图3中共描述了火灾事件、死亡事件、受伤事件、事故事件(火灾)4个事件,分别用e1,e2,e3,e4表示,分析可知构成的候选事件对为〈e1,e2;1〉,〈e1,e3;1〉,〈e2,e3;2〉等.

译文:
今天上午,安徽合肥某小区居民楼发生一起大火,共造成1人死亡,6人受伤,目前事故原因正在进一步调查中。
图3候选事件对举例
2 维吾尔语事件时序关系识别模型
本文采用结合注意力机制的Bi-LSTM模型来完成维吾尔语事件时序关系的识别.识别过程如图4所示.
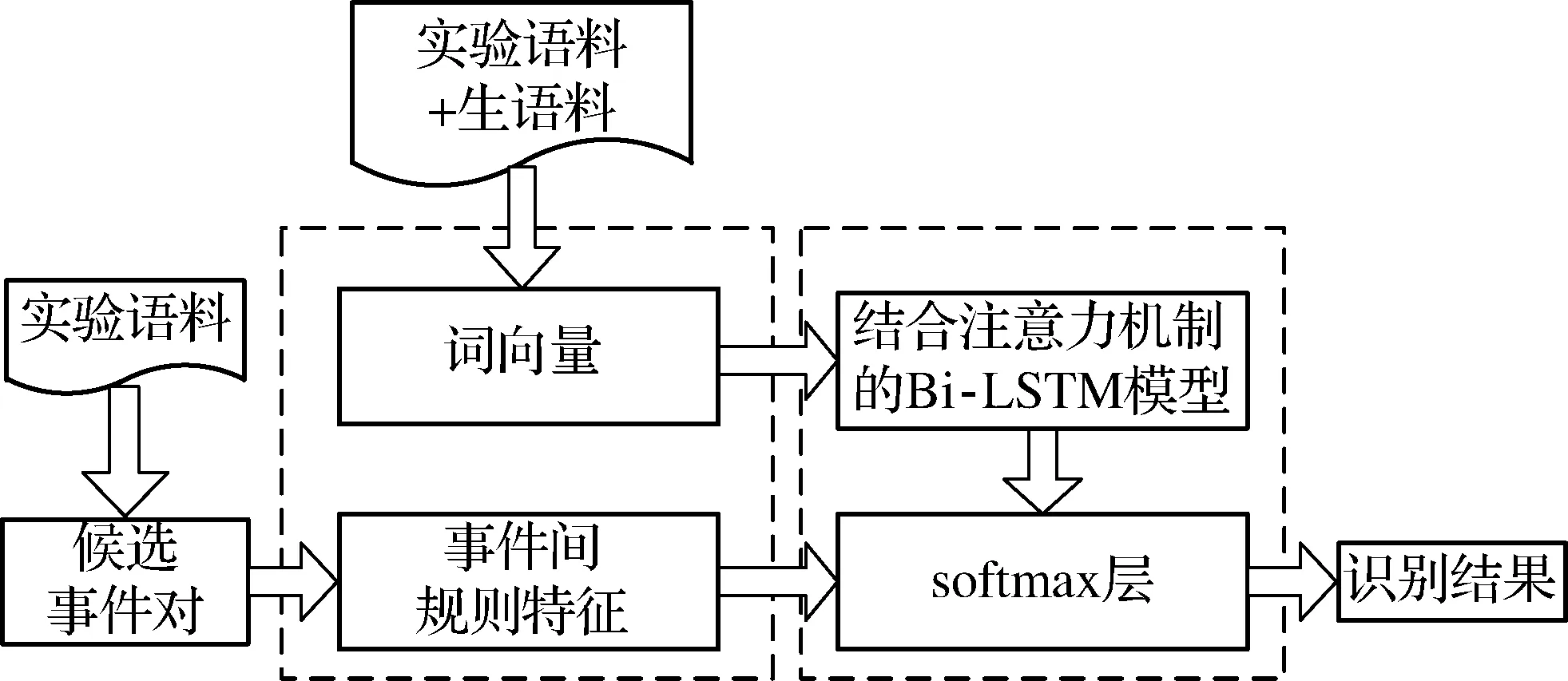
图4 维吾尔语事件时序关系识别过程框架图
2.1 候选事件对抽取
将已标注事件的实验语料进行事件提取,并按照一定的规则对其进行两两组对,判断组对的时序关系.然后,按照定义4,贴上对应的标签.具体的抽取步骤如下:
① 将实验语料中每篇语料所提取出来的事件放入对应的事件列表Li(i=1,2,…,N)中,其中N为实验语料的总数.
② 循环遍历事件列表Li并移除泛指事件.
③ 将步骤②中剩余事件进行两两组对,构成事件对〈ej,ek〉(j=1,2,…,n-1;k=j+1,…,n),其中n为移除泛指事件后事件列表中的剩余事件总数.然后,判断事件ej和事件ek所具有的时序关系,贴上对应的标签,构成候选事件对〈ej,ek;y〉,并将其放入候选事件对集合E中.
④ 循环步骤②和步骤③,直至得到所有语料的候选事件对,并将其放入候选事件对集合E中.
2.2 事件间规则特征抽取
根据实验组维吾尔语语言学家总结的维吾尔语语言特点及事件时序关系特性,抽取了13项事件间规则特征.
1) 事件类别(EType):事件类别反映了事件所属类型.参照国际事件标注体系ACE(包含阿拉伯语、汉语、英语3种语言)以及实验组维吾尔语语言专家给出的事件结构特点,划分了8个大类、35个小类.若事件类别相同则特征值取1,否则取0.
2) 事件子类别(ESubType):事件子类别进一步定义了事件所属的类别.与事件类别相似,若事件子类别相同则特征值取1,否则取0.
3) 事件极性(EPolarity):事件极性有Positive和Negative两种.若根据上下文信息分析该事件已经发生或正在发生,则对应的事件极性为Positive;否则,事件极性为Negative.若事件极性相同则特征值取1,否则取0.
4) 事件时态(ETense):事件时态描述了事件为过去发生的事件还是现在发生的事件或者将来发生的事件.若事件时态相同则特征值取1,否则取0.
5) 事件间前后关系(EBeAfter):事件间前后关系指事件对应的触发词在文本中出现的先后顺序.假设有候选事件对〈ei,ej;1〉,若事件ei对应的触发词出现在前则特征值取1,否则特征值取0.
6) 事件间依存关系(EDependce): 事件间依存关系是根据句法分析得到的依存关系表.若2个事件出现在同一个句子中,则具有依存关系,特征值取1;否则不具有依存关系,特征值取0.
7) 事件触发词类型(EIndType):事件触发词类型包括泛指事件、本句事件和非本句事件.事件触发词类型不同时2个事件的时序关系为重叠关系的可能性较大,而事件触发词类型相同时2个事件的时序关系为前后关系的可能性较大,故事件触发词类型对判别2个事件的时序关系有重要意义.若事件触发词类型相同则特征值取1,否则取0.
8) 触发词词性(ECharacter):触发词词性能反映了事件的信息.若事件触发词词性相同,则特征值取1,否则特征值取0.根据语料统计知,事件触发词中接近90%的触发词词性为名词和动词.
9) 触发词语义角色(ESemRole):语义角色是指名词和动词组成语义结构后,名词在该语义结构中所担任的角色.触发词语义角色能较好地反映事件语义信息.若候选事件对触发词语义角色相同则特征值取1,否则特征值取0.
10) 触发词句法结构(ESynStruct):句法结构是维语语法重要的组成部分,反映了词在维语文本中所担任的成分.若候选事件对触发词句法结构相同,则特征值取1,否则特征值取0.
11) 事件间间隔事件数目(ENumber):经实验统计可知,实验语料中超过60%的候选事件对间隔的事件数为[0,2].因此,若候选事件对间隔的事件数目在此区间内则特征值取1,否则特征值取0.
12) 触发词格语法(ECaGrammar):格语法体现出名词性短语在篇章语句中的句法功能,在语法形式上具有独立性,是维吾尔语语言的重要特征之一.若候选事件对对应触发词的格语法相同,则特征值取1,否则特征值取0.
13) 事件间相对距离(ERelDistance):事件间相对距离是指候选事件对对应触发词在文本中间隔词或其他符号的个数.通过语料统计可知,实验语料中超过60%的候选事件对间的相对距离为[0,50].若候选事件对间相对距离在此区间内则特征值取1,否则特征值取0.
2.3 维吾尔语事件时序关系识别
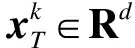

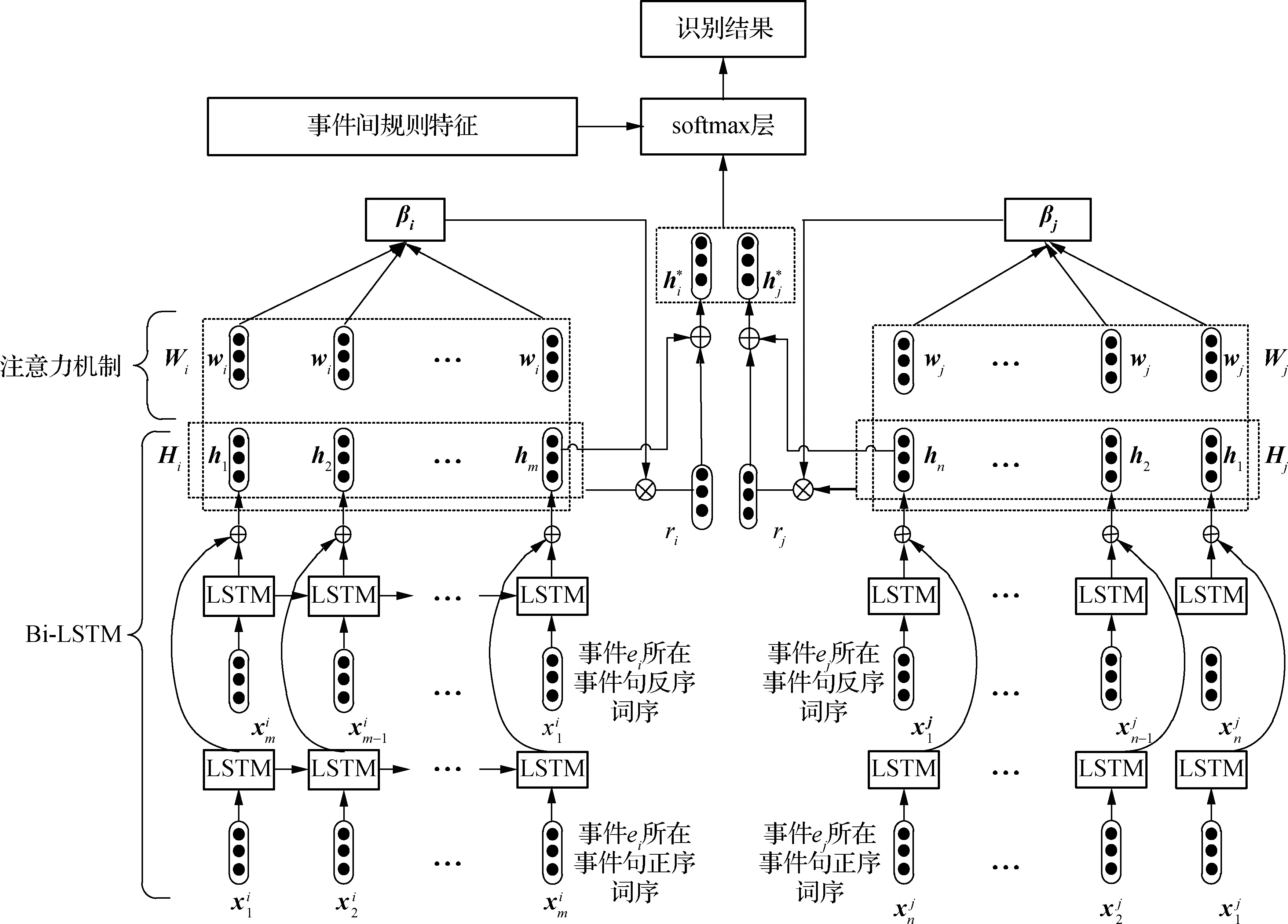
图5 结合注意力机制的Bi-LSTM维吾尔语事件时序关系识别模型
2.3.1 Bi-LSTM模型
LSTM模型[9]通过特殊设计的门控机制来避免长期依赖问题.本文利用Gers等[10]提出的LSTM变体形式,通过门控单元从记忆模块内收集激活值,更新记忆细胞的状态.
LSTM模型在处理事件句词序列时往往忽略下文信息.Bi-LSTM模型包含一个前向LSTM模型和一个后向LSTM模型,前向LSTM模型捕获某一时刻的前文特征信息,后向LSTM模型捕获某一时刻的后文特征信息[11].将这2个上下文信息相加,则t(t=1,2,3,…,N)时刻的输出为
ht=hb,t+hf,t
(1)
式中,ht,hb,t,hf,t分别为Bi-LSTM模型、前向LSTM模型和后向LSTM模型在t时刻的输出.
2.3.2 注意力机制
本文根据对应事件触发词设计注意力机制,以此来增强模型获得对应事件句的事件语义信息的能力,则事件ek所在事件句的事件语义特征表达为
(2)
βk=softmax(WMMk)
(3)
rk=βkHk
(4)
(5)
式中,Mk∈R2d×m为事件句词序序列经过模型后的语义表示;Wh,w∈R2d×2d为Hk和Wk结合后的权重矩阵;WM∈R2d为Mk对应的权重矩阵;Wp和Wx分别表示模型训练时rk和hm的权重矩阵.Rocktäschel等[12]证明将Wxhm放入最终的事件句表达时,能够挖掘事件句隐含的事件语义信息.
2.3.3softmax层
softmax层分类公式为
(6)

3 实验结果与分析
3.1 语料准备
实验中选取天山网、人民网等维语网页作为语料来源.利用网络爬虫下载网页,经过去重、去噪等操作筛选出包含事件描述的新闻报道文本,作为实验语料.本实验共标注了300篇语料,统计发现其中包含1 361条为间断前后关系,993条为不间断前后关系,829条为重叠关系.按照2.1节中的样本构建方法,生成3 183条样本数据.
3.2 实验评价标准
本文对模型性能的评价标准为准确率、召回率及衡量模型整体性能的F值.假设间断前后关系、不间断前后关系以及重叠关系的准确率分别为Pi,Pn和Po,召回率分别为Ri,Rn和Ro,在测试样本中的分布比例分别为A,B,C.则事件时序关系模型性能的准确率Pm、召回率Rm、F值分别为
Pm=PiA+PnB+PoC
(7)
Rm=RiA+RnB+RoC
(8)
(9)
3.3 实验设计
为保证实验结果的稳定性,所有实验均将样本数据随机打乱,然后采用十折交叉验证,取10次结果的平均值作为最终结果,参数设置如下:学习率为0.01;每一次迭代训练时批处理样本数为15;模型训练达到最优的迭代次数为55;词向量维度为150;Bi-LSTM隐藏层节点数为150.
3.3.1 语义特征对实验性能的影响
2.2节抽取的特征主要是事件类型、事件极性以及事件句法结构等基于事件间内部结构的特征,缺少对整个事件句的语义考虑.本节探讨了基于词向量和结合注意力机制的Bi-LSTM模型生成的事件语义特征对事件时序关系识别的影响.分别将表1中的2类特征作为softmax层的输入,验证语义特征对事件时序关系识别的影响,实验结果见表1.
由表1可知,在去掉事件语义特征、仅包含事件间规则特征条件下的准确率、召回率、F值较包含全部特征的准确率、召回率、F值分别为下降了23.39%,21.80%,22.57%.由此证明了引入事件语义特征的有效性.这是因为时序关系是事件间的一种语义关系,事件间规则特征仅考虑了事件间内部结构特点,缺乏对整个事件句的语义信息考虑;而结合注意力机制的Bi-LSTM模型能够充分考虑事件句的全局语义信息,挖掘事件句隐含的事件语义特征.

表1 事件语义特征对事件时序关系识别的影响 %
3.3.2 词向量维度对实验性能的影响
不同维度的词向量蕴含的语义信息不同.理论上,维度越大的词向量所蕴含的语义信息越丰富.故本文选择的词向量维度u=10,50,100,150,200.实验结果见表2.

表2 词向量维度对实验结果的影响 %
由表2可知,词向量维度越大,反映模型性能的准确率、召回率、F值越高.u=150时模型性能达到最优,准确率为89.42%,召回率为86.70%,F值为88.03%.与u=150时相比,u=200时准确率、召回率及F值分别下降了10.19%, 6.90%和8.52%.究其原因在于,维度过高的词向量虽然包含更加丰富的语义信息,但是也包含了干扰信息和噪音,易产生过拟合现象,导致模型对数据的泛化能力降低[13],影响模型的学习能力.
3.3.3 特征有效性验证
结合维吾尔语语言特点及事件时序关系特性,抽取出13项事件间规则特征,并对其进行有效性验证,结果见表3.
由表3可知,在去掉某一项规则特征之后,剩余12项规则特征和语义特征融合之后模型的准确率、召回率、F值与包含全部特征时的准确率、召回率、F值相比均下降.由此证明了13项事件间规则特征在维吾尔语事件时序关系识别性能上的有效性.
3.3.4 与其他循环神经网络模型的性能对比
在维吾尔语事件时序关系识别上,为验证本文模型的有效性,将本文提出的模型与传统LSTM模型[9]、LSTM模型[10]以及Bi-LSTM模型进行对比实验,结果见表4.
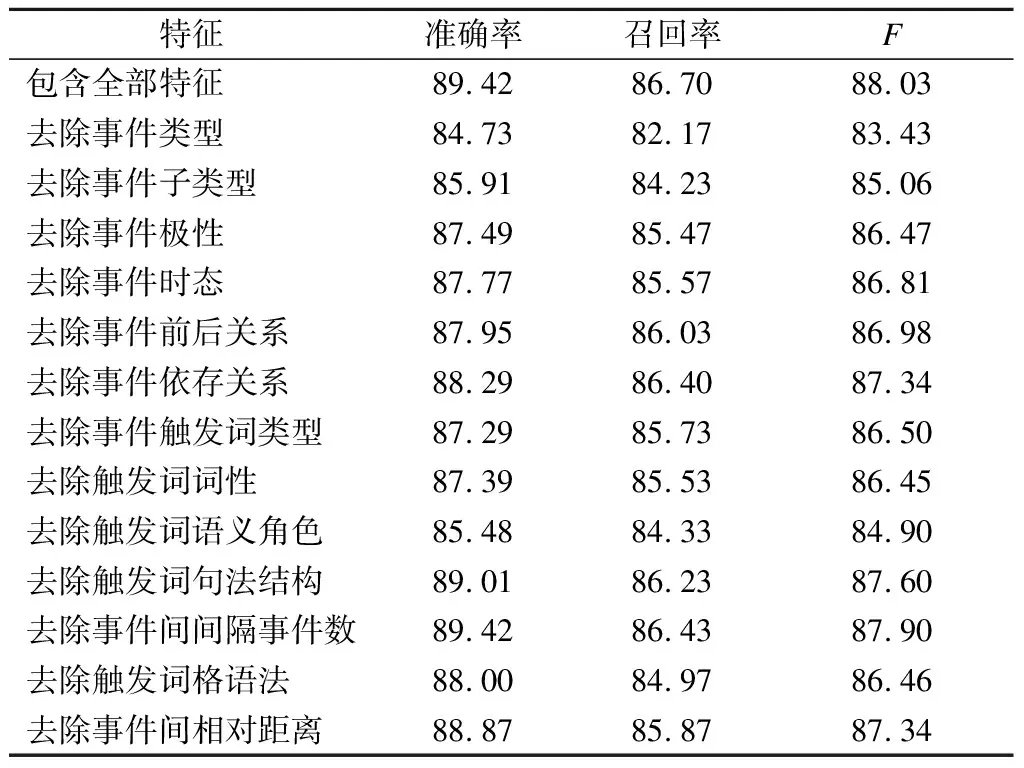
表3 特征有效性验证 %

表4 4种循环神经网络性能对比 %
由表4可知,LSTM模型在维吾尔语事件时序关系识别性能上优于传统LSTM模型,这是因为LSTM模型充分利用前一时刻细胞状态的信息,能够更加有效地挖掘事件句所隐含的深层语义信息.Bi-LSTM模型关于维吾尔语事件时序关系识别的实验性能优于LSTM模型,这是因为LSTM模型的序列信息从前向后依次传播,并不包含从后向前的传播过程,这种单向机制仅包含事件句词汇序列当前时刻的前文信息,而对后文信息并未涉及;而Bi-LSTM模型在LSTM模型基础上增加了一个反向LSTM模型,正向LSTM模型用于捕获上文的特征信息,反向LSTM模型用于捕获下文的特征信息,从而可捕获文本全局上下文信息.本文提出的结合注意力机制的Bi-LSTM维吾尔语事件时序关系识别的实验性能优于上述循环神经网络模型,这是因为前者利用Bi-LSTM模型提取出给定事件句所隐含的深层语义信息,同时根据事件触发词设计注意力机制,得到该事件句所隐含的事件语义特征表达.
3.3.5 与其他模型的性能对比
在自然语言处理领域,SVM和CNN是2种常见模型.为充分验证本文方法的有效性,将本文方法与SVM和CNN进行性能对比,结果见表5.
由表5可知,3种模型中,SVM模型的准确率、召回率、F值最低.这是因为SVM为浅层机器学习算法,其挖掘数据特征的能力与本文模型和CNN相比相对较弱,后面2种模型能够捕捉数据中更加复杂的数据分布,有效学习文本中更高层的特征表示.本文模型的准确率、召回率及F值最高.这是因为浅层CNN模型利用局部卷积思想,只能捕获文本序列的局部特征,缺乏对全局上下文信息的考虑[14];而本文模型不仅能捕获事件句全局上下文语义信息,还能捕获事件句隐含的事件语义信息.
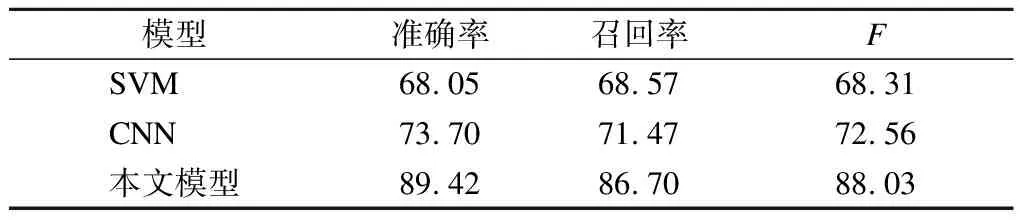
表5 几种模型性能对比 %
4 结论
1) 基于维吾尔语语言特点及事件时序关系特性,利用结合注意力机制的Bi-LST模型挖掘维吾尔语事件句隐含的事件语义特征.
2) 根据事件间内部结构特点,抽取13项事件间规则特征,通过特征融合,完成维吾尔语事件时序关系识别任务.
3) 通过与传统LSTM模型、LSTM模型、Bi-LSTM模型进行对比实验,验证了本文模型在挖掘事件语义信息方面的有效性.
4) 通过与SVM模型和CNN模型的相比,验证了本文模型在挖掘深层语义信息和复杂数据内部结构的优势.
参考文献(References)
[1] 孙辉. 事件时序关系识别的研究与实现[D]. 哈尔滨:哈尔滨工业大学计算机科学与技术学院,2010.
[2] Tourille J, Ferret O, Neveol A, et al. Neural architecture for temporal relation extraction: A Bi-LSTM approach for detecting narrative containers [C] //Procofthe55thAnnualMeetingoftheAssociationforComputationalLinguistics(ShortPapers). Vancouver, Canada, 2017: 224-230. DOI:10.18653/v1/p17-2035.
[3] Styler W, Bethard S, Finan S, et al. Temporal annotation in the clinical domain [C] //The52ndAnnualMeetingoftheAssociationforComputationalLinguistics. Baltimore, Maryland, USA, 2014: 143-154.
[4] 郑新, 李培峰, 朱巧明. 基于全局优化的中文事件时序关系推理方法[J]. 中文信息学报, 2016,30(5): 129-135.
Zheng Xin,Li Peifeng,Zhu Qiaoming.Global inference for temporal relations between Chinese events[J].JournalofChineseInformationProcessing,2016,30(5):129-135.(in Chinese)
[5] Tang D, Qin B,Feng X, et al. Effective LSTMs for target-dependent sentiment classification [C] //ProcofCOLING2016. Osaka, Japan, 2016: 3298-3307.
[6] Zhou X, Wan X, Xiao J. Attention-based LSTM network for cross-lingual sentiment classification [C] //Proceedingsofthe2016ConferenceonEmpiricalMethodsinNaturalLanguageProcessing. Austin, Texas, USA, 2016: 247-256. DOI:10.18653/v1/d16-1024.
[7] 付剑锋. 面向事件的知识处理研究[D].上海:上海大学计算机学院,2010.
[8] 钟军, 禹龙, 田生伟,等. 基于双层模型的维吾尔语突发事件因果关系抽取[J]. 自动化学报, 2014,40(4):771-779. DOI: 10.3724/SP.J.1004.2013.00771.
Zhong Jun,Yu Long,Tian Shengwei,et al.Causal relation extraction of Uyghur emergency events based on cascaded model[J].ActaAutomaticaSinica,2014,40(4):771-779. DOI: 10.3724/SP.J.1004.2013.00771. (in Chinese)
[9] Hochreiter S, Schmidhuber J. Long short-term memory[J].NeuralComputation, 1997,9(8): 1735-1780.
[10] Gers F A, Schmidhuber J. Recurrent nets that time and count [C] //ProcofIEEE-INNS-ENNSIntJointConfonNeuralNetworks. Como, Italy, 2000: 189-194.
[11] Melamud O, Goldberger J, Dagan I. Context2vec: Learning generic context embedding with bidirectional LSTM[C]//Proceedingsofthe20thSIGNLLConferenceonComputationalNaturalLanguageLearning. Berlin, Germany, 2016:51-61. DOI:10.18653/v1/k16-1006.
[12] Rocktäschel T, Grefenstette E, Hermann K M, et al. Reasoning about entailment with neural attention [C] //ProcofIntConfonLearningRepresentations. San Juan, Puerto Rico, 2016:1-9.
[13] 李敏, 禹龙, 田生伟,等. 基于深度学习的维吾尔语名词短语指代消解[J]. 自动化学报, 2017(11):1984-1992. DOI: 10.16383/j.aas.2017.c160330.
Li Min,Yu Long,Tian Shengwei,et al. Coreference resolution of Uyghur noun phrases based on deep learning[J].ActaAutomaticaSinica,2017(11):1984-1992. DOI: 10.16383/j.aas.2017.c160330.(in Chinese)
[14] 田生伟, 周兴发, 禹龙,等. 基于双向LSTM的维吾尔语事件因果关系抽取[J]. 电子与信息学报, 2018,40(1):200-208. DOI: 10.11999/JEIT170402.
Tian Shengwei,Zhou Xingfa,Yu Long,et al.Causal relation extraction of Uyghur events based on bidirectional long short-term memory model[J].JournalofElectronicsandInformationTechnology,2018,40(1):200-208. DOI: 10.11999/JEIT170402. (in Chinese)
猜你喜欢
中国农业信息(2021年3期)2021-11-22
电子制作(2017年13期)2017-12-15
自动化学报(2017年4期)2017-06-15
海外华文教育(2016年1期)2017-01-20
电子制作(2016年15期)2017-01-15
当代教育理论与实践(2015年9期)2015-12-16
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12
语言与翻译(2015年4期)2015-07-18
民族古籍研究(2014年0期)2014-10-27
语言与翻译(2014年3期)2014-07-12
