
通用数据质量评估模型及本体实现
2018-06-08 01:43:03张晓冉
计算机研究与发展 2018年6期
张晓冉 袁 满
(东北石油大学计算机与信息技术学院 黑龙江大庆 163318) (xiaoran9217@163.com)
随着信息技术的发展,数据作为企业的重要资产,对生产经营、科学研究以及管理和决策等起着重要的作用.即使有良好设计和规划的信息系统也不能保证存放数据的质量都能满足用户的要求.用户录入错误、企业合并以及企业环境随着时间的推移而改变,这些都会影响所存放数据的质量[1].数据质量对于企业战略决策至关重要,因此数据质量的检测与数据质量的评估显得越来越重要,对数据质量评估模型的要求也更加迫切.
数据质量评估模型的研究由来已久,文献[2]早期提出了基于属性的数据质量评估模型,但缺少定量的系统方法.文献[3]在文献[2]的基础之上提出了数据质量评估模型,并阐述了构造方法和计算方法.随后,Parssian等人[4]于2004年提出了一套实用的数据质量评估方法,但其选择性假设导致了后续推导出的数据质量评估公式存在问题,随后Debabrata等人[5]建立了属性值的概率分布,对评估方法进行了修正,尽管完善了数据质量评估模型,但仍然存在不同属性正确率不同的问题.文献[6]在文献[4-5]的数据质量评估模型基础上,根据“不正确、不完整、非成员”3种错误类型来研究数据质量评估,提出了基于单一属性分布的数据质量评估模型.文献[7]根据电网统计数据的基本特征,从正确性、完整性、唯一性等7个方面进行质量评估,在此基础上构建了一个基于云模型的统计数据质量评估模型.文献[8]建立了EM4ADOM评估模型,该模型从数据的可用性、安全性以及可用性和安全性的权衡3个方面综合评估了匿名数据的质量.文献[9]提出了数据库数据质量评估模型,建立了一个数据质量可视化分析系统,但该模型是面向关系型数据的,对于非关系型数据没有涉及.
以上文献中的评估模型均存在不同程度的不足:文献[2]提出的评估模型缺少定量的系统方法;文献[3]虽然在此基础上补充了构造方法和计算方法,并且在数据仓库源数据的质量评估中得到成功应用,但是仍缺少一定的通用性和扩充性;文献[6]虽然对文献[4-5]进行了改进,但是仅仅局限于单一属性分布的数据质量的评估,对于多属性没有涉及;文献[7-8]都是针对某一领域的数据质量问题提出的评估模型,具有局限性;文献[9]提出的数据质量评估模型对于数据集中的数据类型有限制.
总的来看,笔者认为当前这些数据质量评估模型在发展上呈现这样一些特征:基本是从业务出发来构建这些质量模型,从不同的角度提出了多种多样的数据质量评估指标,这些指标有相同之处,也有不同之处;它们的共性都是领域针对性强,不具有通用性和扩展性,除此之外,对评估的数据集来源多有限制.其实,在进行数据质量研究与系统研发的过程中,完全可以撇开不同行业的业务,即忽略行业特点,从数据质量的实质出发,构建一个通用的模型作为机构进行数据质量研发的规范或标准.这种通用的模型,不是指该模型对于不同的数据约束规则,数据集都适用,而是指任何数据约束规则,数据集都可以以此模型框架为基础,遵循该模型进行扩充,即模型框架通用,内部的专业规则根据不同的专业需求进行添加定制,数据集是评估时选择的,通用模型以数据集为单位进行评估,具体选取哪种数据集、依据什么规则评估,需要由企业依据通用模型进行定制.
目前,数据质量面临的难题和挑战也是如何构建这一通用的模型标准.本体是对某一领域中公认的概念知识的建模,本体模型和具体应用是分开的,因此本体适合解决数据质量系统通用性评估的问题,同时本体在语义上的表达能力,可以解决复杂约束规则的定义问题.目前本体技术已被引入用来解决数据质量问题,文献[10]实现了基于本体的数据清洗系统框架,解决了现有数据清洗研究中缺乏语义约束和不能支持自动推理的问题.因此采用本体技术是可行的.
本文首先分析了数据质量评估中涉及的相关要素,抽取并定义了一个通用的数据质量评估数学模型,该模型是逻辑上的,具体的实现采用本体技术,定义了从该通用的数据质量评估数学模型到本体模型映射的转换规则.考虑到目前,绝大多数机构的数据存储在关系数据库中,所以以关系数据模型为例,依据所提出的数学模型和转换规则实现了对数据质量评估本体的抽取与构建.最后,结合中国石油油田开发数据进行了原型系统的实现,验证所提出模型的正确性、科学性、合理性以及可扩充性等.
1 数据质量相关技术研究
1.1 数据质量概念
数据质量问题及其研究由来已久,伴随着信息技术发展而逐渐成为被广泛关注的研究热点.目前对于数据质量没有一个明确的定义.文献[11]认为数据质量是数据适合使用的程度(fit for use),这一定义被业界广泛认可.文献[12]认为数据质量是数据满足特定用户期望的程度.国际标准化组织在ISO9000:2000《质量管理体系基础和术语》中将质量定义成一组固有特性满足要求的程度.
1.2 数据质量维度
数据质量维度为数据质量的业务需求提供框架,对数据质量维度进行量化度量为数据质量水平提供了实证.为了保持维度的有效性,维度的定义过程不能在管理的最后阶段进行,而是在数据质量规划设计的阶段就要开始[13].Wang等人[14]于1995年发表了一项关于数据质量的调查,调查中提出用维度集来描述数据质量.自此以后,其他学者也对质量维度深入研究.Wand等人[15]基于信息系统模型提出了5个数据质量维度:准确性、完整性、一致性、及时性和可靠性[15].Strong等人[16]通过对数据质量的179个特征进行了深入调查,针对数据用户需求,确定了15个常用质量维度.Redeman[17]将数据质量维度分为3类,分别是对应的概念视图数据、数据值和数据格式.文献[18]提出了具体的数据质量维度用来指导数据仓库的设计.Bovee等人[19]将数据质量定义成数据适合使用的程度,包括可访问性、可解释性、相关性和可信度这4个维度.Naumann[20]为集成Web信息系统定义了4类21个质量维度.通过上述研究,正确性、完整性、一致性是被公认的基本评价维度,定义如表1所示:

Table 1 Data Quality Dimensions表1 数据质量维度
1.3 数据质量约束规则
为了进一步的数据需求分析,采用约束规则的方式,对于每个维度进行具体的量化分析,集中定义数据质量维度包含的约束规则来验证数据来源系统质量,确定数据的适用程度以此满足业务需求.企业可以根据不同的质量评估需求选取评估维度并制定相应的约束规则.
文献[3]将数据质量问题分为模式层问题和实例层问题.模式层问题主要是设计缺陷导致的,例如完整性约束、唯一性约束;实例层问题主要是描述数据记录方面的数据质量问题,例如数据缺失、数据重复.文献[25]又将数据质量约束规则分为3类:数据项约束规则、跨列约束规则和交叉列约束规则.本文参照文献[26],通过对数据质量相关成果的研究和实际的需求将部分数据质量规则进行定义并分类如下,数据质量维度与数据质量约束规则及数据质量问题关系的映射如图1所示.
下面给出图1中的8个约束规则的定义.
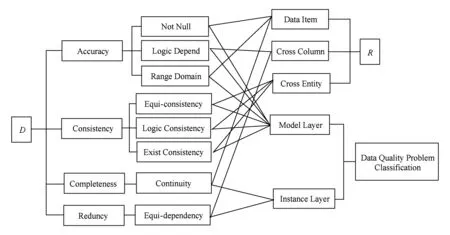
Fig.1 Mapping between data quality dimensions and constraint rules and problems’ relation图1 数据质量维度与数据质量约束规则及问题关系映射图
定义1. 非空约束规则.数据项取值不能为空的约束.
例如:在油田开发领域,数据表DAA01中的数据项井号jh,它的取值不能为空值,即DAA01.jh≠null.
定义2. 值域约束规则.数据项只能在规定的定义域内取值.
例如:在油田开发领域,数据表DAA02中的数据项含水率hs,其值只能在[0,1]内取,即hs∈[0,1].
定义3. 逻辑依赖约束规则.在同一数据集中,一个数据项的值与另一个数据项的值满足某种逻辑关系的约束.
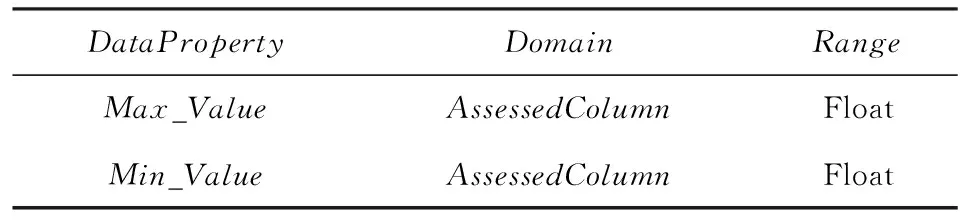
例如:在油田开发领域,数据表DAA091中的数据项井段顶深jdds2的值必须小于数据项井段底深jdds1的值,即DAA091.jdds2 定义4. 等值一致性约束规则.一个数据集中的数据项取值必须等于由另一个数据集中的一个或多个数据项的值按着指定算法计算得出值的约束. 例如:在油田开发领域,数据表DDA02中数据项四通高stg的值等于数据表DAA02中数据项套补距tbj的值减去DAA02中数据项油补距ybj值,即DAA02.stg=DAA02.tbj-DAA02.ybj. 定义5. 存在一致性约束规则.是对数据集之间数据项数据存在关系进行约束的规则,即一个数据集中的数据项必须在另一个数据集中的数据项上出现. 例如:在油田开发领域,数据表DAA05中的数据项井号jh的取值与数据表CD_WELL_SOURCE中数据项井描述well_desc的值必须保持取值的一致性,即DAA05.jh=CD_WELL_SOURCE.well_dec. 定义6. 逻辑一致性约束规则.是对数据集之间数据项数据满足逻辑关系进行的约束,即一个数据集中的数据项与另一个数据集中的数据项满足某种逻辑关系. 例如:在油田开发领域,数据表DAA01中的数据项注水zs的值小于数据表DBA04中的数据项投产tc的值,即DAA01.zs 定义7. 连续性约束规则.数据项的值必须保持取值连续性的约束. 例如:在油田开发领域,数据表DAA03中的数据项测点深度cdsd按主键分组,并且相邻字段之间保持相同的间隔取值. 定义8. 等值函数依赖约束规则.是对数据集内部数据项上数据取值进行约束的规则.在同一数据集中,数据项上的数据取值必须由其他数据项上的数据取值计算得出. 例如:在油田开发领域,数据表DAA02中的数据项压井液密度yjymd的取值等于该表中的数据项固井液密度gjymd的值加1,即DAA02.yjymd=DAA02.gjymd+1. 通过第1节研究表明,数据质量问题是多方面多角度的,通过多维度指标的共同作用反映数据质量情况.在评估维度体系中,正确性、完整性、一致性和冗余性是被公认的基本评价维度. 我们撇开领域业务自身的特点,数据质量模型是由被评估的数据集模式、维度集合、规则集合、评估实例集合、评估算法集合共同组成的复杂问题,据此给出形式化定义: 定义9. 数据质量评估Assess.任何Assess都可以形式化为一个五元组,表示为 Assess={S,D,R,I,A}, 其中,S为待评估的数据集模式;D为数据质量维度(dimension)的集合;R为度包含规则(rule)的集合;I为评估数据实例(instance)的集合;A为数据质量评估算法(algorithm)的集合. 定义10. 待评估的数据集模式S.待评估的数据集的模式,可以是关系数据库模式中的表或视图,也可以是XML模式等.每个模式可以用实体、联系进行描述如下: S={entity,relation}. 定义11. 实体(entity).客观存在并且相互区别的事物称为实体.可以是具体事物,也可以是抽象概念.每个实体可以用名称、属性、码、域进行描述如下: entity={ename,attribute,key,area}. 定义12. 属性(attribute).实体的某一特性为属性,由属性名、类型、长度组成,描述如下: attribute={attname,type,size}. 定义13. 码(key).唯一标识实体的属性集称为码. 定义14. 域(area).域是一组相同数据类型的值的集合,属性的取值范围来自于域.这里的域可以通过设定属性的类型来限定,也可以是可枚举的,例如area={a1,a2,…,an}. 定义15. 联系(relation).联系包含实体内部的联系和实体之间的联系.描述如下: relation={〈entity1,entity2〉,rname,rkind}, 其中,rname是联系的名称;rkind指联系的类型,即实体内部的联系和实体之间的联系. 定义16. 维度集合D.包含多个评估维度的集合,描述如下: D={dimi|define(dimi),1 其中,define(dimi)是对评估维度dimi的定义. 定义17. 规则集合R.每个评估维度所包含规则的集合,描述如下: R={〈dimi,rulej〉|define(rulej), 其中,define(rulej)是对某一评估维度包含的约束规则的定义.每个维度包含多个约束规则. 定义18. 评估数据实例集合I.由评估实例记录构成的集合,描述如下: I={insi|define(insi),1≤i≤n}, 其中define(insi)是对评估实例的定义. 定义19. 评估算法集合A.由评估算法构成的集合,描述如下: A={algi|define(algi),1≤i≤n}, 其中,define(algi)是对评估算法的定义. 企业进行数据质量评估主要经过4个步骤:确定评估数据集模式S;遍历维度集选定评估维度D;遍历规则集R,在实例集I上对规则进行检查;将违反这些规则的记录存储在errordata中.最后通过数据质量评估算法集A,计算各维度指标的质量.数据质量评估流程算法的伪代码如算法1所示. 算法1. 数据质量评估流程算法. 输入:D,R,I,A; 输出:errordata. ① if (D=null‖R=null‖I=null) ② 返回空值; ③ end if ④ for 每一行D for 每一行R if (存在规则) ⑤ 在实例集I上对规则进行检查,将违反规则的记录存入errordata; ⑥ else ⑦ 返回空值; ⑧ end if ⑨ end for ⑩ end for 数据质量评估算法用于数据质量评估维度的计算,是数据质量评估的基本单位.本文以作者研发的《SYT7005-2014数据质量控制与评估原则》——石油天然气行业标准,作为依据给出数据质量评估算法,本文以准确性评估算法为例,具体的数据质量评估指标概念如下: 1) 问题分类数.在对一个数据集进行质量评估时,出现违反数据质量元素中约束规则种类的数量,记作Sq. 2) 问题记录数.在对一个数据集进行质量评估时,存在违反数据质量元素中约束规则的记录个数,同一条记录出现多个违反约束规则的不重复计算,记作Rq. 3) 问题数据数.在对一个数据集进行质量评估时,存在违反数据质量元素中约束规则的记录个数,同一条记录出现多个违反约束规则的重复计算,记作Dq. 4) 问题数据项个数.在对一个数据集进行质量评估时,出现违反数据质量元素中约束规则的数据项个数,一个属性违反多个约束规则不重复计算,记作Cq. 5) 缺少数据项个数.一个数据集元数据定义数据项个数与实际数据项个数的差,记作Cs. 准确性的评估包括:问题分类数Sq、问题记录数Rq、问题数据数Dq、问题数据项个数Cq、缺少数据项个数Cs. 设Cr为数据集的记录数,Cqd为元数据定义数据项个数,数据准确性为 其他评估维度算法详见文献[27]. 本体最早源于哲学范畴,随着信息技术的发展被赋予了新的意义.Gruber[27]给出了业界广泛接受的本体定义,即“本体是概念模型的明确的规范化说明”.本体描述了实体之间概念的联系,本体的目标是将某个具体领域的概念整合起来,确定该领域公认词汇,对词汇和词汇之间的关系给出形式化、规范化的定义.目前对于本体构建没有一个明确的规范和标准,1995年Gruber提出的5条准则被广泛接受:明确性和客观性、完全性、一致性、最大单调可扩展性、最小承诺和最小编码偏好.国外几种重要的本体构建方法有IDEF5、骨架法、企业建模法、METHONTOLOGY、循环获取法、5步循环法等.2002年,文献[28]中提到Stojanovic等人通过考察给出了一组从关系模型到本体的映射规则,基于这些规则能够直接得到一个候选本体,然后可以进一步对该候选本体进行评价和精炼,生成最终的本体.本文依照映射规则思想,在对本体技术进行充分研究的基础之上,从上述的质量评估数学模型出发,提出了从数学模型向本体模型转换的映射规则,抽取概念及其关系构建数据质量评估的知识本体. 本文将通用数据质量模型形式化为五元组Assess=〈S,D,R,I,A〉,其中S为模式集,D为维度集,R为规则集,I为实例集,A为算法集.文献[29]将本体形式化为五元组O=〈C,R,F,A,I〉,其中C为类,R为关系,F为函数,A为公理,I为实例.由此可见,从数据质量通用模型到本体模式的转换主要包含:模式集到本体的映射;维度集到本体类的映射;规则集到本体属性及公理函数的映射;实例集到本体类的实例及属性的实例的映射;算法集到本体类的映射.映射规则定义如下: 1) 模式集S的映射 模式集是指需要进行评估的数据集的模式的集合.例如关系数库模式,XMlSchema等.文献[30]对已有的模式映射技术进行了比较全面的综述.数据模式到本体的映射主要是模式和本体中对应元素的映射,通过人工参与及映射策略消除语法层次上的差异.模式集的映射包含实体映射和联系映射. ① 实体(entity)的映射 定义20. 实体(entity)的映射.实体可以是具体事物,也可以是抽象概念,通常映射成以实体名命名的本体类,映射过程为 ∀entityi∈S→Cename, 其中,Cename表示以实体名命名的本体类. ② 属性(attribute)的映射 定义21. 属性(attribute)的映射.实体属性映射成以属性名命名的本体类,映射过程为 ∀attributei∈S→Cattname. ③ 码(key)的映射 定义22. 码(key)的映射.码用来唯一标识属性.映射成本体中的函数,映射过程为 ∀keyi∈S→restriction((DataProperty, ④ 联系(relation)的映射 定义23. 联系(relation)的映射.联系包含实体内部的联系和实体之间的联系.通常映射成一对互逆的对象属性.映射过程为 ∀relationi∈S→ObjectProperty 其中,Centity1表示以entity1名字命名的本体类,Centity2表示以entity2名字命名的本体类. 2) 维度集D的映射 定义24. 维度集D的映射.维度集是指评估维度的集合,通常映射成本体中的类,映射过程为 ∀dimi∈D→Cdim, 其中,Cdim表示以维度名字命名的本体类. 3) 规则集R的映射 规则集中包含的是与评估维度相对应的规则.对于选定评估维度的数据集,制定评估维度对应的评估规则.在规则集中,规则分为数据项约束规则、同记录跨列约束规则和交叉列约束规则.有些限定规则可直接用OWL约束来实现,映射成本体公理或函数. ① 数据项约束规则的映射 定义25. 数据项约束规则的映射.规则限定的是实体属性本身,规则映射成数据属性,映射过程为 ∀rulei∈DataItem→DataProperty 其中,Ccol指的是规则限定的属性映射成的本体类,typeof(col(rulei))指的是规则限定的属性类型. ② 同记录跨列约束规则的映射 定义26. 同记录跨列约束规则的映射.规则限定的是同一实体的属性,属性间是关联关系的,规则映射成一对互逆的对象属性,映射过程为 ∀rulei∈CrossColumn→ObjectProperty 其中,Ccol指的是规则限定的属性映射成的本体类,Crelate指的是被规则限定的属性的关联属性映射成的本体类.由于限定属性和关联属性在同一实体中,因此Ccol和Crelate相等. ③ 交叉列约束规则的映射 定义27. 交叉列约束规则的映射.规则限定的是不同实体之间的属性,属性间是关联关系的,规则映射成一对互逆的对象属性,映射过程为 ∀rulei∈CrossEntity→ObjectProperty 其中,Ccol指的是规则限定的属性映射成的本体类,Crelate指的是被规则限定的属性的关联属性映射成的本体类. 4) 实例集I的映射 定义28. 实例集I的映射.实例集是指数据集记录实例的集合,映射成本体类的实例或本体属性实例,映射过程为 ∀insi∈I→(Class)∨(Property). 5) 评估算法集A 定义29. 算法集的映射.是数据质量评估算法的集合,映射成以算法名称命名的本体类,映射过程为 ∀algi∈A→Calg. 通过映射规则构建通用数据质量本体,1)遍历数据集模式,将实体映射成以实体名为概念的本体类,实体属性映射成以属性名为概念的本体类,将实体的关系映射成本体中的对象属性;2)遍历评估维度集中的所有维度,创建以维度名为概念的本体类,遍历维度集下对应的规则集合,判断规则是数据项约束规则还是同记录跨列约束规则或交叉列约束规则,按照Rule的映射规则创建本体的对象属性或数据属性;3)遍历实例集合,创建相应的本体实例;4)遍历算法集,创建以算法名为概念的本体类.数据模型映射成OWL本体有5个步骤: 步骤1. 遍历数据集模式S.①确定是否存在实体,若存在,按照定义20映射成本体类;②确定是否存在联系,若存在,按照定义23映射成对象属性. 步骤2. 遍历维度集D.确定是否存在维度,若存在,按照定义24映射成本体类. 步骤3. 遍历规则集R.①确定是否存在数据项约束规则,若存在,按照定义25映射成本体类;②确定是否存在同记录跨列约束规则,若存在,按照定义26映射成对象属性;③确定是否存在交叉列约束规则,若存在,按照定义27映射成对象属性. 步骤4. 遍历实例集I.确定是否存在实例,若存在,按照定义28映射成本体类. 步骤5. 遍历算法集A.确定是否存在算法,若存在,按照定义29映射成本体类. 本文基于数据质量模型及映射规则算法,考虑到多数数据存储在关系数据库中,因此以中国石油油田开发数据为背景进行数据质量评估本体的构建,以此验证模型和映射算法是可行的、通用的,按着3.2节给出的转换规则与算法,构建过程如下: 1) 模式集S的映射 ① 实体(entity)的映射.关系数据库模式中的实体是多张关系表,按照定义20将其映射成本体中的AssessedTable类. ② 属性(attribute)的映射.关系模式的属性是字段,按照定义21将其映射成本体中的Assessed-Column类. ③ 码(key)的映射.关系数据库模式中的码是关系表中的主键,按照定义22将其映射成本体函数. ④ 联系(relation)的映射.关系模式中,表和字段之间存在联系.按照定义23将其映射成本体中一对互逆的对象属性hascolumn和iscolumnof. 2) 维度集D的映射 企业数据质量关系数据库评估维度表中包含4类评估维度,分别是准确性、完整性、一致性和冗余性. ① 维度概念的映射.按照定义24,映射成4个维度的本体类. ② 维度关系的映射.每个维度包含多个约束规则,因此将维度与规则的关系映射成本体中的一对互逆的对象属性,hasrule和isruleof. 3) 规则集R的映射 企业数据质量关系数据库中包含8类数据质量约束规则,分别是非空约束、值域约束、逻辑依赖约束、等值一致性依赖约束、存在一致性依赖约束、逻辑一致性依赖约束、等值函数依赖约束、连续性约束规则.定义已在3.2节介绍,按照映射规则分别映射为 ① 非空约束.按照定义25的映规则,将非空约束规则通过必要属性(RequiredProperty)数据属性来表达.具体表达如表2所示: Table 2 Data Property for Not Null Rule表2 非空约束规则对应的数据属性 ② 值域约束.按照定义25将值域约束映射成本体中的数据属性Min_Value和Max_Value.具体表达如表3所示: Table 3 Data Property for Rang Domain Rule表3 值域约束规则 ③ 逻辑依赖约束.按照定义26将逻辑依赖约束映射成为对象属性GreaterThan和LessThan,具体表达如表4所示: Table 4 Object Property for Logic Depend Rule表4 逻辑依赖约束规则对应的对象属性 ④ 等值一致性约束.按照定义27将等值一致性依赖约束规则映射成为对象属性ReferenceEquals,具体表达如表5所示: ⑤ 存在一致性约束.按照定义27将该规则映射成本体的对象属性Exist,具体表达如表6所示: Table 6 Object Property for Exist Consistency表6 存在一致性约束规则对应的对象属性 ⑥ 逻辑一致性约束.按照定义27将该规则映射成本体中的对象属性ReferenceGreaterThan,ReferenceLessThan,具体表达如表7所示: Table 7 Object Property for Logic Consistency表7 逻辑一致性约束规则对应的对象属性 ⑦ 等值函数依赖约束.与等值一致性约束规则不同的是,等值函数依赖规则限定的同一数据集字段间的等值关联关系,因此按照定义27将规则映射成本体中的对象属性Equals.具体表如表8所示: Table 8 Object Property for Equi-dependency表8 等值函数依赖约束规则对应的对象属性 ⑧ 连续性约束.连续性约束规则限定的是字段本身在某一分组内的数据按一定步长连续,因此按照定义25将规则映射成本体中的数据属性Step和Groupby,具体表达如表9所示: Table 9 Data Property for Continuity表9 连续性约束规则对应的数据属性 4) 实例集I的映射 以评估单井小层数据表DAA05为例,DAA05包含字段SYDS,YLSYDS,YLSYHD.需将该表和字段以实例的方式添加到本体中. 5) 算法集A的映射 企业数据质量关系数据库中包含4类评估算法,分别是准确性评估算法、完整性评估算法、一致性评估算法和冗余性评估算法,按照定义29映射成4个本体类,OWL本体描述语言定义如下: 根据上述的数据质量评估通用数学模型以及数学模型到本体的映射规则,对企业关系数据库进行抽象和分析,构建了通用的数据质量评估本体模型.如图2所示: Fig.2 Data quality assessment ontology concept diagram图2 数据质量评估本体概念关系图 按照3.2节介绍的不同规则在本体中的映射方法,使用本体建模工具Protégé构建了数据质量本体,并生成了数据质量本体的OWL文件.数据质量本体的概念层次结构如图3所示.数据质量评估的实现需要利用Jena技术并借助eclipse对OWL文件进行解析.解析的主要内容是对数据质量本体类的解析、属性的解析以及实例的解析.通过解析出规则的属性,调用评估算法,实现对规则的评估. Fig.3 Data quality assessment ontology concept hierarchy diagram图3 数据质量评估本体概念层次结构关系图 通过Jena对本体进行解析后,可以通过选取规则对字段进行评估,本文主要以企业数据质量关系数据库中包含的8类数据质量约束规则为例,分别是非空约束、值域约束、逻辑依赖约束、等值一致性依赖约束、存在一致性约束、逻辑一致性约束、等值函数依赖约束、连续性约束规则.具体的评估实现如下: 1) 非空约束.通过解析非空字段,发现存在RequiredProperty数据属性,即在相应数据库中查询出对应的为空字段. 2) 值域约束.解析出本体中评估字段的数据属性Min_Value和Max_Value的值,查询数据不在Min_Value和Max_Value范围内的记录. 3) 逻辑依赖约束.解析出本体中评估字段是否存在LessThan和GreaterThan的关系,检验存在该关系的字段取值是否满足逻辑关系. 4) 等值一致性依赖约束.解析出本体中评估字段是否存在ReferenceEquals关系,检验存在该关系的字段取值是否满足等值关系. 5) 存在一致性约束.解析出本体中评估字段是否存在Exist关系,检验存在该关系的字段是否在另一个字段中出现. 6) 逻辑一致性约束.解析出本体中评估字段是否存在ReferenceGreaterThan或者ReferenceLessThan关系,检验存在该关系的字段取值是否满足逻辑关系. 7) 等值函数依赖约束.解析出本体中评估字段是否存在Equals关系,检验存在该关系的字段取值是否满足等值关系. 8) 连续性约束.解析出Step_length和Groupby属性的值,检验评估字段属性值是否满足连续性. 企业可以根据不同的专业需求按照本体映射规则对规则进行添加定制,同时相应地对评估规则的算法进行同步扩充,以保障对该规则的评估. 20世纪90年代初期,随着关系型数据库技术的发展,石油工业开始了油田勘探开发数据库的规划设计工作,经过几十年的建设已经初具规模.在各个油田数据中心数据库建设不断发展和完善的过程中,油田相关部门也逐渐建立起多种类型的数据库来处理日渐增多的数据,如何保障进入油田数据库数据的质量是石油工业需要解决的重要问题.A2(油田生产注入与产出数据)、A5(油田地面工程及采油数据)数据库利用完整性约束来限制数据的插入等操作,依然不能保证进入数据库的数据完全符合业务需求,因此目前油田开发数据库中仍然有很多数据质量问题存在,如数据不正确、数据残缺、数据重复等. 本文以石油领域的质量管控为应用背景,结合油田开发数据开发了基于数据质量本体的石油领域数据质量评估系统,对数据质量本体模型的有效性和技术可行性进行验证.油田开发数据种类繁多,因此,本文以开发数据库中存在质量问题较多的基础信息表DDA02、钻井地质信息表DAA02、井斜数据表DAA03和单井小层数据表DAA05为例,针对4个维度,选取其中具有代表性的约束规则进行评估,将评估结果与数据库实际情况进行比对,验证本文构建的数据质量评估正确性.表的字段约束规则如表10所示: Table 10 Constraint Rules表10 约束规则 首先将评估表以本体实例添加到数据质量评估本体中,再将字段约束规则以数据属性或对象属性方式添加到本体.通过解析数据质量本体的类以及规则字段属性,分别进行值域约束、逻辑依赖约束、连续性约束和存在一致性约束的评估,Oracle数据库系统的检索与本体模型评估结果对比如表11和图4所示. 上述的评估结果均与数据库中存在的数据质量问题的实际情况相一致,由此可见,本文构建的评估本体能够准确描述约束规则,且评估结果与实际数据库相符合,该数据质量评估本体结构合理,有利于数据质量领域的知识共享,是可行有效的. Table 11 Query Contrast表11 评估结果对比表 Fig.4 Query contrast diagram图4 查询对比图 本文提出了一个数据质量评估数学模型,设计了一个从数据质量评估数学模型到本体模型映射的转换规则,以企业数据质量关系数据库为例进行了实验,参照模型和规则实现了数据质量评估本体抽取,构建了通用的数据质量评估本体模型.企业可以根据不同的专业需求按照通用模型对内部业务规则进行添加定制,扩充评估指标以及评估算法,选取不同来源、不同格式的数据集进行评估,这一模型已在油田开发领域数据的质量评估中得到了应用,评估结果与实际一致,验证了该模型的有效性.下一步的工作重点是对规则和映射方法进行改进和优化,完善本体结构,实现本体的自动构建,并结合专业数据应用中出现的各种质量规则,利用本体的推理技术进一步实现对潜在数据质量相关问题的推理研究. [1]Guo Zhimao, Zhou Aoying. A survey of research on data quality and data cleaning[J]. Journal of Software, 2002, 13(11): 2076-2082 (in Chinese)(郭志懋, 周傲英. 数据质量和数据清洗研究综述[J]. 软件学报, 2002, 13(11): 2076-2082) [2]Wang R Y, Reddy M P, Kon H B. Toward quality data: An attribute-base approach[J]. Decision Support System, 1995, 13(34): 349-372 [3]Yang Qingyun, Zhao Peiying, Yang Dongqing, et al. Research on data quality assessment methodology[J]. Computer Engineering and Applications, 2004, 40(9): 3-4 (in Chinese)(杨青云, 赵培英, 杨冬青, 等. 数据质量评估方法研究[J]. 计算机工程与应用, 2004, 40(9): 3-4) [4]Parssian A, Sarkar S, Jacob V. Assessing data quality for information products: Impact of selection, projection, and cartesian product[J]. Management Science, 2004, 50(7): 967-982 [5]Debabrata D, Subodha K. Reassessing data quality for information products[J]. Management Science, 2010, 56(12): 2316-2322 [6]Xu Min, Xu Yong. A data quality assessment model based on single attribute[J]. Statistics and Decision, 2013, 33(11): 4-8 (in Chinese)(徐敏, 徐勇. 基于单一属性分布的数据质量评估模型[J]. 统计与决策, 2013, 33(11): 4-8) [7]Yan Hongwen, Chen Peng. Research on quality asssessment of power grid statistical data based on cloud model[J]. Computer Applications and Software, 2014, 34(12): 100-103 (in Chinese)(颜宏文, 陈鹏. 基于云模型的电网统计数据质量评估方法研究[J]. 计算机应用与软件, 2014, 34(12): 100-103) [8]Chen Jianming, Han Jianmin. Evaluation model for quality ofk-anonymity data oriented to microaggregation[J]. Application Research of Computers, 2010, 27(6): 2344-2347 (in Chinese)(陈建明, 韩建民. 面向微聚集技术的k-匿名数据质量评估模型[J]. 计算机应用研究, 2010, 27(6): 2344-2347) [9]Teng Dongxing, Zeng Zhirong, Yang Haiyan, et al. Visual quality analysis method for relational data[J]. Journal of Software, 2013, 24(4): 810-824 (in Chinese)(滕东兴, 曾志荣, 杨海燕, 等. 一种面向关系型数据的可视质量分析方法[J]. 软件学报, 2013, 24(4): 810-814) [10]Zhang Lianchao. Research on ontology-based data cleaning system framework[D]. Nanjing: Nanjing University of Aeronautics and Astronautics, 2008 (in Chinese)(张联超. 基于本体的数据清洗系统框架研究[D]. 南京: 南京航空航天大学, 2008) [11]Huang K T, Lee Y W, Wang R Y. Quality Information and Knowledge[M]. Upper Saddle River, NJ: Prentice Hall, 1998: 99-136 [12]Kahn B K, Strong D M. Product and service performance model for information quality: An update[C]Proc of the 3rd Int Conf on Information Quality. Cambridge, MA: MIT Press, 1998: 102-115 [13]DAMD. DAMA Data Management Knowledge System Guide[M]. Translated by Ma Huan. 1st ed. Beijing: Tsinghua University Press, 2012 (in Chinese)(DAMD. DAMA数据管理知识体系指南[M]. 马欢, 译. 1版. 北京: 清华大学出版社, 2012) [14]Wang R Y, Storey V C, Firth C P. A framework for analysis of data quality research[J]. IEEE Trans Knowledge and Data Engineering, 1995, 7(4): 623-640 [15]Wand Y, Wang R Y. Anchoring data quality dimensions in ontological foundations[J]. Communications of the ACM, 1996, 39(11): 86-95 [16]Wang R Y, Strong D M. Beyond accuracy: What data quality means to data consumers[J]. Journal of Management Information Systems, 1996, 12(4): 5-33 [17]Redeman T C. Data Quality for the Information Age[M]. London: Artech House, 1997: 130-137 [18]Jarke M, Jeusfeld M A, Quix C, et al. Architecture and quality in data warehouses: An extended repository Approach[J]. Informayion Systems, 1999, 24(3): 229-253 [19]Bovee M, Srivastava R P, Mak B. A conceptual framework and belief-function approach to assessing overall information quality[J]. International Journal of Intelligent System, 2010, 18(1): 51-74 [20]Naumann F. Quality-driven query answering for integrated information systems[G]LNCS 2262: Proc of the 7th Int Conf on Cooperative Information Systems. Berlin: Springer, 2002: 103-124 [21]Batini C, Cappiello C, Francalanci C, et al. Methodologies for data quality assessment and improvement[J]. ACM Computing Surveys, 2009, 41(3): 1-52 [22]McGilvray D. Executing Data Quality Projects: Ten Steps to Quality Data and Trusted Information[M]. San Francisco, CA: Morgan Kaufmann, 2008: 62-73 [23]Jarke M, Lenzerini M, Vassiliou Y, et al. Fundamentals of data warehouses[J]. IEEE Software, 2001, 18(5): 92-95 [24]Liu Liping, Chi L N. Evolutional data quality: A theory specific view[C]Proc of the 7th Int Conf on Information Quality. Cambridge, MA: MIT Press, 2002: 292-304 [25]Loshin D. The Practitioner’s Guide to Data Quality Improvement[M]. San Francisco, CA: Morgan Kaufmann, 2010 [26]Yuan Man, Zhang Xue. A data quality assessment model based on rules[J]. Computer Technology and Development, 2013, 23(3): 81-84 (in Chinese)(袁满, 张雪. 一种基于规则的数据质量评价模型[J]. 计算机技术与发展, 2013, 23(3): 81-84 [27]Gruber T R. A translation approach to portable ontology specifications[J]. Knowledge Acquisition, 1993, 5(2): 199-220 [28]Du Xiaoyong, Li Man, Wang Shan. A survey on ontology learning research[J]. Journal of Software, 2006, 17(9): 1837-1847 (in Chinese)(杜小勇, 李曼, 王珊. 本体学习研究综述[J]. 软件学报, 2006, 17(9): 1837-1847) [29]Zhai Baorong. Study on extraction and storage of OWL ontology based on relational database[D]. Changsha: National University of Defense Technology, 2011(翟保荣. 基于关系数据库的OWL本体的提取与存储研究[D]. 长沙: 国防科学技术大学, 2011) [30]Rahm E, Bernstein P A. A survey of approaches to automatic schema matching[J]. VLDB Journal, 2001, 10(4): 334-350 ZhangXiaoran, born in 1992. Master candidate. Her main research interests include data quality and information integration. YuanMan, born in 1965. PhD. Professor. His main research interests include information and data science, data quality, knowledge organization and application, and integration technology.2 数据质量评估数学模型及评估算法
2.1 数据质量评估数学模型定义
1≤i≤p,1≤j≤q},2.2 数据质量评估流程算法
2.3 数据质量评估算法
3 通用数据质量评估本体构建
3.1 本体基本概念
3.2 数据模型向本体模型转换的映射规则
minCardinary=1),FunctionalProperty).
(Domain:Centity1,Rang:Centity2).
(Domain:Ccol,Rang:xsd:typeof(col(rulei))),
(Domain:Ccol,Rang:Crelate),
(Domain:Ccol,Rang:Crelate),3.3 数据模型向本体模型转换的映射算法
3.4 数据质量评估本体构建实现






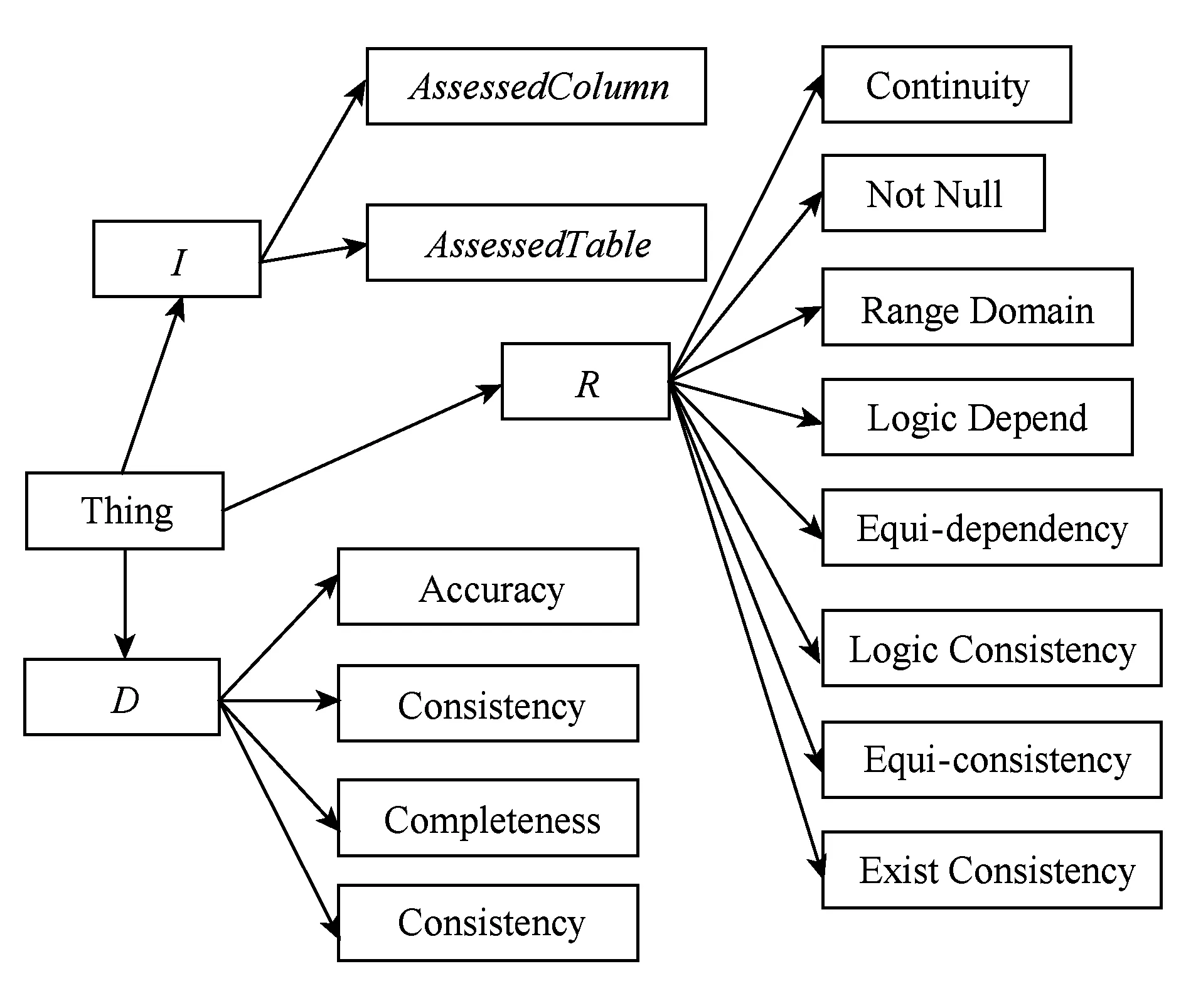
3.5 数据质量本体评估实现

4 数据质量评估本体应用效果分析
4.1 数据质量评估本体应用背景

4.2 评估实验结果比对

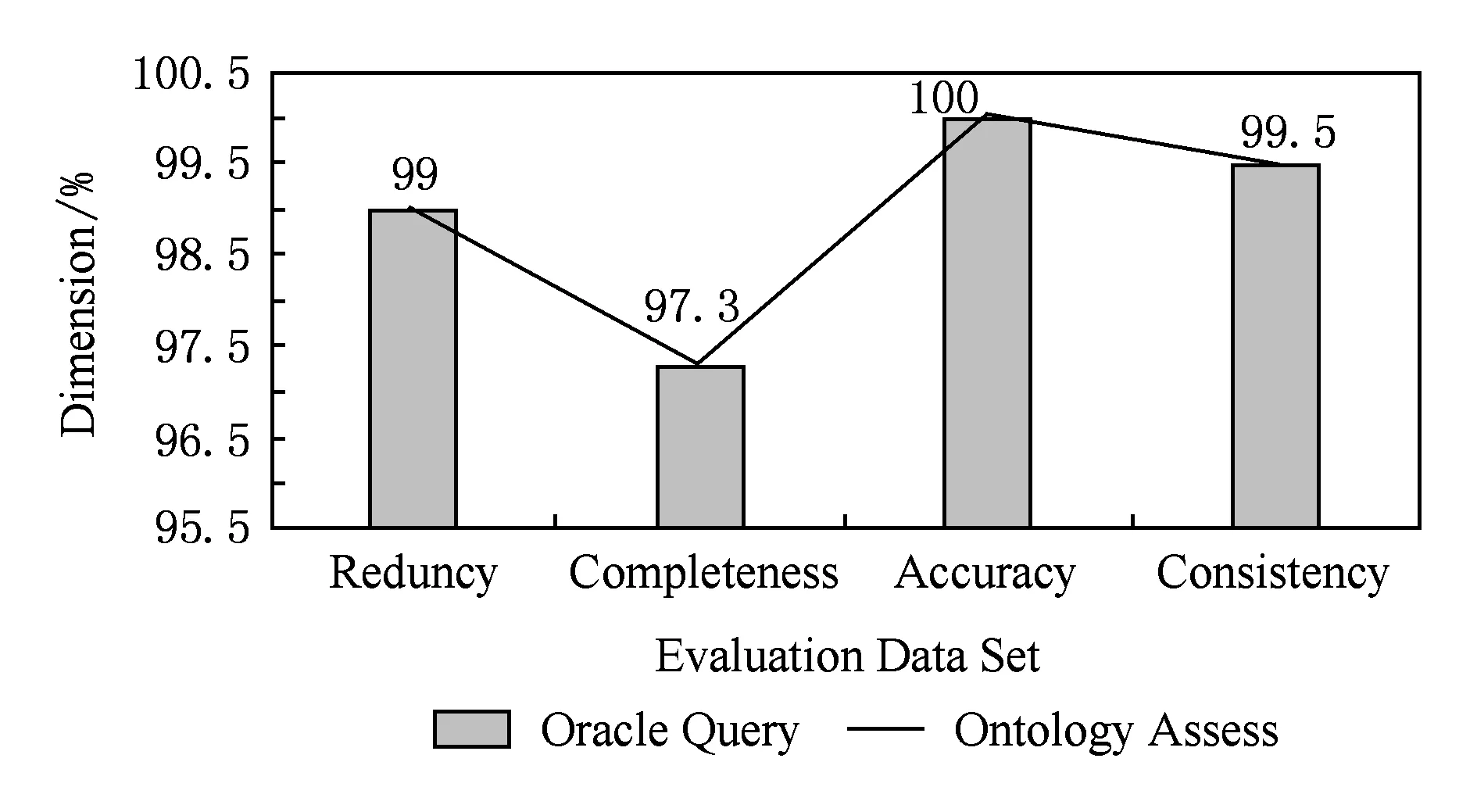
5 总 结

 猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27加油站服务指南(2021年4期)2021-07-21 02:29:22中国音乐学(2020年4期)2020-12-25 02:58:06数学年刊A辑(中文版)(2020年1期)2020-05-19 00:30:30甘肃科技(2020年19期)2020-03-11 09:42:42计算机与生活(2019年11期)2019-11-12 05:41:02科技与创新(2019年14期)2019-08-12 12:55:20文学教育(2016年27期)2016-02-28 02:35:15人生十六七(2015年6期)2015-02-28 13:08:38卷宗(2013年6期)2013-10-21 21:07:52
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27加油站服务指南(2021年4期)2021-07-21 02:29:22中国音乐学(2020年4期)2020-12-25 02:58:06数学年刊A辑(中文版)(2020年1期)2020-05-19 00:30:30甘肃科技(2020年19期)2020-03-11 09:42:42计算机与生活(2019年11期)2019-11-12 05:41:02科技与创新(2019年14期)2019-08-12 12:55:20文学教育(2016年27期)2016-02-28 02:35:15人生十六七(2015年6期)2015-02-28 13:08:38卷宗(2013年6期)2013-10-21 21:07:52
