
基于在线聚类的协同作弊团体识别方法
2018-06-08 01:42谭文安周亮广
计算机研究与发展 2018年6期
孙 勇 谭文安 金 婷 周亮广
1(南京航空航天大学计算机科学与技术学院 南京 211106) 2 (安徽省地理信息集成应用协同创新中心(滁州学院) 安徽滁州 239000) (ysun.nuaa@yahoo.com)
随着云计算、服务计算以及社会计算等新技术不断应用于企业信息领域,越来越多的业务过程跨越了企业组织边界,构成了不同组织间松散耦合的云计算应用系统.云计算的广泛应用将传统的封闭、静态、可控的企业计算环境迁移到以开放、动态、不确定为特征的面向大规模服务计算的分布式系统.支持云计算应用系统的可信服务评估模型正面临着协同作弊和虚假评价等各种恶意攻击[1-2],严重影响了企业之间的协同工作效率[3].而且,传统的服务评估模型只适用于小规模企业信息系统,难以满足大数据环境下云计算应用系统的服务可信度评估和实时计算的要求.
在互联网应用中,协同服务系统日志的反馈数据可能存在着大量的虚假内容,严重干扰了云计算应用系统从海量的反馈数据中发现高可信的服务.在此背景下,尽管面向服务的云计算应用系统凭借集成第三方服务,降低了业务运作的成本,但也隐藏着巨大的风险.现有的跨组织云平台缺乏行之有效的可信评价机制应对恶意欺诈行为[4-8],而是假设反馈用户的评分值是真实可靠的,不存在虚假行为.但是,在现实世界中,攻击用户为了个体组织利益,对某些服务故意给出虚假错误的评价,影响了服务协同系统的预测评分质量.虚假用户可以通过欺诈行为获取利益,仅靠服务用户的自律难以确保云端服务的质量,应设计出更有效的可信服务评估机制,以消除欺骗行为所产生的负面影响,为跨组织业务推荐可信的服务,从而提高云计算应用系统的运行稳定性和可靠性[9-10].
服务用户虚假反馈评价和基于信誉的服务用户信任分析模型主要研究了个体服务用户恶意攻击.针对个体服务用户的虚假反馈评价,基于偏离率和声望值的用户信任评估方法通过迭代计算,分析反馈用户的评分真实性,从而估算出用户的信誉值[11].偏离率被用于评价服务用户的可信性,而声望值则用来计算服务用户的重要性.服务用户的偏离率越大,其可信度越低;用户的声望值越大,则表明用户的重要度越高[12].基于偏离率和声望值的信任评估方法遏制了个体欺诈提供者的一般恶意行为,但在应对协同作弊及策略攻击等恶意行为时,缺乏有效的评估机制.
基于聚类的可信度分析算法通过预处理基本用户信息进行离线聚类,能够有效地识别出协同作弊问题的服务用户群体[13-14].然而,大规模服务计算系统的大数据特性直接影响着协同作弊团体识别与检测的计算速度与质量.传统基于聚类的可信度分析算法存在居多限制:聚类过程采用了基于完全批量的训练学习方法,其算法的时间效率较低;当协同计算应用系统日志中服务用户反馈数据在线更新时,需要重新训练全部样本数据,难以适应大规模服务计算环境下服务反馈评分数据量大且变化快的特点.不同于基于完全批量学习的聚类方法,基于随机梯度下降法的在线聚类模型每次从全部服务反馈训练样本中随机抽取单个样本,并且仅对一个服务反馈样本数据进行学习,然后通过调整聚类模型权值参数以减少预测误差,该方法适用于实时在线服务检测分析[15-18].基于随机梯度下降法的在线聚类模型采用了随机抽样方法,减小了学习基数的规模量,极大程度地提高了协同作弊群体检测的时间效率,但是同时也降低了预测精度.
综上所述,支持跨组织云计算应用的协同作弊用户在线检测分析是一个复杂的综合问题,不仅需要考虑大规模服务计算的时效性问题,而且还需要考虑共谋欺骗检测与协同作弊用户团体识别等问题.针对时效性和协作恶意攻击问题,本文提出了一种基于在线聚类的协同作弊团体识别模型及其高效算法,主要贡献有3个方面:
1) 综合考虑大规模服务计算的大数据性特征,提出一种新颖的基于改进更新规则的在线聚类算法,采用小批量学习训练方法,通过基于自适应权重修正的聚类分组方差计算,并进行递减增量优化更新规则的动量性参数,以提高在线KMeans算法的聚类质量.
2) 建立了一套协同作弊检测机制,用以识别出协作虚假攻击行为.针对恶意团体协同作弊及策略攻击等恶意行为,充分考虑团体的同谋行为特征和协同攻击现象,利用聚类的性质以及团体的异常性,提出了基于同谋特征的决策图检测方法,快速自动识别出协同作弊行为.
3) 仿真验证分析了基于在线聚类的协同作弊用户识别算法,实验结果表明所提出的在线共谋团体识别算法具有良好时间性能,并有效地解决大规模服务计算中服务协作反馈欺骗的问题.
1 基于改进更新规则的在线聚类
大数据环境下,面向服务的集成应用平台中不断涌现出大批量的新用户及其评价数据,服务用户的反馈评价具有主观性高、规范低、更新快以及数量极大等特征,传统的基于聚类的服务可信度评估算法在进行聚类分析时会造成大量的时间开销,难以满足大规模服务可信度评估分析的实时性需求.因此,本文提出了基于改进更新规则的在线KMeans聚类分析技术,针对基于随机梯度法的在线聚类算法精度问题,采取一种改进的基于小批量学习的在线KMeans聚类算法;并且,通过自动修正权重的聚类分组方差优化方法,提高了在线KMeans算法的聚类质量,同时保证了聚类算法的时间效率.
1.1 在线聚类模型分析
KMeans聚类根据服务特征的相似性,将原始数据集划分为K个分组(cluster).KMeans聚类的输入包括类别数目K和训练样本数据,输出则为K个类别的分组集合[19].假设用户服务评分训练样本为R={rt|t=1,2,…,N},随机初始化K个聚类中心的参考向量为mi,i=1,2,…,K,根据参考向量mi,将所有的训练样本分配到K个用户聚类分组Gi,i=1,2,…,K中,聚类方法按可计算为
(1)
在每次迭代时,基于大批量学习的KMeans聚类方法求出同类所有用户的服务评价平均值作为临时中心点,更新分组中心的方法计算为
(2)
其中,ni为聚类分组Gi的用户数量.
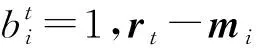
(3)
其中
(4)
式(3)采用随机梯度下降法,得到rt的更新变量计算为
(5)
由式(5)可得到rt的更新规则为
mi←mi+η·(rt-mi).
(6)
尽管基于随机梯度下降的在线聚类算法(SGDKMeans)适用于大规模服务可信度评估分析应用,但是SGDKMeans的聚类质量并不佳.因此,本文采用了基于小批量学习的在线聚类算法(MiniKMeans),通过小批量样本学习,逐步考虑小批量样本实例,每一步进行少许更新.基于小批量学习的在线聚类算法是批量梯度学习法和随机梯度下降法的一种折衷方案,介于两者之间.
综上分析,基于小批量学习的在线聚类算法每次选取适量的训练样本进行迭代优化,直到收敛,其算法描述如下:
算法1. 基于小批量学习的在线聚类算法(MiniKMeans).
输入:服务用户-服务评分信息D=(U,I,R)、聚类数目K;
输出:聚类结果.
① 随机选取K个用户作为聚类中心;
② 将训练样本Batches划分为多个小样本batch;
③ REPEAT
④ FORbatchINBatchesDO
⑤ FORrt∈batchDO*用户评分信息rt属于小批量样本中*
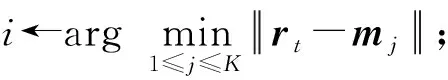
⑦ 采用小批量学习的更新规则:mi←mi+η·(rt-mi);
⑧ END FOR
⑨ END FOR
⑩ UNTILmi收敛.*聚类中心点不变*
根据算法1可知,在每次迭代时,只选择batch个训练样本,其中batch远小于所有训练样本数据,因此,基于小批量学习的在线聚类算法能满足大规模服务可信度评估分析的在线实时性需求.
1.2 在线聚类算法的更新规则改进
在线KMeans聚类算法是将所有聚类分组中数据对象之间的距离之和作为最小化目标,忽视了每个聚类分组的距离之和不平衡现象,聚类获得的结果可能存在一种现象:一些分组内的距离之和较大,而另外一些分组的距离之和较小,采用所有分组距离累加的方法掩盖了某些聚类分组效果不佳的问题,导致在线KMeans聚类算法陷入局部最优[20].针对局部聚类分组的距离误差优化不平衡问题,基于小批量学习的在线聚类算法引入了自适应加权距离的计算方法,最小化所有聚类分组的最大距离误差,解决各聚类分组的距离误差不平衡问题,实现在线聚类的最优化,其定义为
(7)
其中,Emax(mi|rt)是所有聚类分组的最大距离误差,直接最小化Emax(mi|rt)是一个非常复杂的最优化求解问题.为了适用于在线聚类的优化模式,采用自适应加权距离方法,将Emax(mi|rt)最小化目标松弛为
(8)
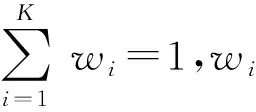
(9)
采用拉格朗日乘数法求解式(9),计算可得:
(10)
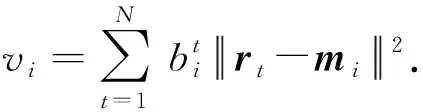
(11)
根据更新规则式(11),将训练样本在线地划分到加权距离最小的聚类分组中,相比于标准的样本分派距离,改进的更新规则融入了自适应权值修正方法.我们分析加权距离可知,若分组误差距离大,其权值也大,导致一部分距离该分组较远的样本被划分到其他分组;相反,具有权值较小且误差距离也小特征的分组吸收到部分样本.在聚类过程中,通过加权惩罚较高误差的分组,有效地平衡了局部聚类分组的距离误差.
(12)
(13)
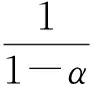
w(t)=β·w(t-1)+(1-β) ·w(t),
(14)
其中,β控制了上次权重对当前权值的影响,保证了聚类过程的稳定性.
同时,为了确保在线聚类正常收敛,针对聚类更新规则的动量项参数η难以确定的问题,本文采取一种新的η值计算优化模型,通过逐渐减少动量项参数η以更新聚类中心.
由聚类更新公式可知:
(15)
由式(15)推导可得:
(16)
可得:
(17)
比较式(17)和式(6),可选取η=1ni.
对于高速公路工程建设过程中的中心试验室工作人员来讲,要根据工程实际施工质量,不断学习先进的试验检测技术,并定期向工程管理人员汇报工作质量,不断提升高速公路工程的整体管理效率。例如,在某高速公路工程当中,中心试验室检测人员通过与工程管理人员进行有效沟通,不仅能够提升高速公路工程整体管理效率,而且有效降低工程施工材料的损耗率[3]。
综上分析,基于改进更新规则的在线聚类算法(MyKMeans)通过修改聚类更新规则的参数,进一步优化了基于小批量学习的在线聚类算法,MyKMeans可描述如下:
算法2. 基于改进更新规则的在线聚类算法(MyKMeans).
输入:服务用户-服务评分信息D=(U,I,R)和聚类数目k;
输出:聚类结果.
① 随机选取K个用户作为聚类中心;
② 将训练样本Batches划分为多个小样本batch;
③ REPEAT
④ FORbatchinBatchesDO
⑤ FORrt∈batchDO*用户评分信息rt属于小批量样本中*
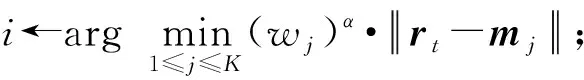
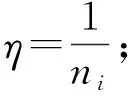
⑧ END FOR
⑨ END FOR
⑩ UNTILmi收敛.*聚类中心点不变*
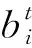
2 协同作弊用户识别
基于在线聚类的服务可信度分析方法将高相似性的服务用户划分到同一个聚类分组,其中可信的反馈评分用户占着绝大多数.虚假服务用户与可信服务用户评价行为存在明显的不同,2类用户的评分会出现较大的偏差,通常虚假用户表现出评价行为高度一致性.因此,当通过在线学习方法计算得出的聚类分组相似度较大时,极有可能是同谋团体.
2.1 协同作弊特征分析
协同作弊行为通常具有3个特征[21]:1)协同作弊团队表现出明显的整体性,在评价行为上保持高度的一致性;2)协同作弊团队与正常用户相比表现出异常性;3)协同作弊团队的攻击时间几乎相近,因为集中攻击能提高作弊的效果[22].通过深入分析协同作弊的攻击行为特征,本文将协同作弊的特征刻画方法进行了改进,提出一种新的基于协同作弊特征决策图的检测方法,用以识别出协同作弊团队.
协同作弊团体又称为同谋团体,同谋用户往往评分较大或较小,有强的关联性,采用聚类方法能识别协同作弊行为.同谋攻击者之间具有非常高的一致性特征,其相似度大于0.9,在评价行为上表现出高度的一致性[23-24].因此,相似度极高的聚类分组很有可能是协同作弊团体.
定义1. 协同作弊团体的整体性.针对协同作弊团队行为高度一致性问题,假设通过基于在线KMeans聚类的计算得到聚类分组为{Gi|i=1,2,…,K},聚类Gi中ni个用户反馈数据,采用团体评分一致性(group ratings consistency,GRC)评估聚类分组Gi的行为整体性,GRC(Gi)计算方法可定义为
(18)
GRC(Gi)表示聚类分组Gi整体性的程度,值越小则说明Gi整体性越高.实际上,协同作弊团体不仅具有高度整体性的特征,而且,相对正常用户,其数量较少.本文不采用平均值描述同谋团体的整体性特征,而是通过对所有值求和来刻画聚类分组的整体性特征,为了与协同作弊团体的异常性评价数值范围一致性,采用了协同作弊团体整体性计算值的倒数作为协同作弊的评价指标,其定义为
(19)
当聚类分组的GRC(Gi)值较高时,则表明该聚类分组协同作弊的可能性大.
定义2. 协同作弊团体的异常性.假设通过在线聚类计算得到了K个聚类分组{Gi|i=1,2,…,K},当协同作弊团队与正常聚类分组相比,通常表现出异常性.通过计算用户聚类分组之间的差异性,能够检测出同谋团体.因此,定义了一种团体评分偏差度(group ratings deviation,GRD)的指标函数,以识别出协同作弊团体的异常性,GRD定义为
(20)
其中,|R|表示所有的反馈用户数量;|Gj|代表聚类分组Gj的服务用户数量;D(·)表示偏差函数;聚类分组整体的偏离度GRD(Gi)大小反映了聚类分组Gi评价与真实值的偏差程度.因此,聚类分组的GRD(Gi)值越大,则表示该聚类分组越有可能是协同作弊团体.
定义3. 协同作弊团体的攻击时间相似性.协同作弊团体的攻击时间几乎相近,因此,将时间作为描述协同作弊团体的辅助评价指标[25-26].通过计算协同作弊团体中评价时间最大值和最小时间之间的时间窗,衡量协作团体的共谋攻击可能性.时间评价指标采用团体评分的时间相似度(group rating time similarity,GTS)表示,时间窗口函数定义为TW(rj),表示聚类分组Gi中用户j的评分时间窗口:
(21)
其中,T(rj)表示用户j的评分时间,j=1,2,…,K;τ是时间比较参数,表示可能作弊的评分时间窗.
本文采用聚类分组中反馈用户的最大评价时间窗TW(rj)作为协同作弊的评价指标,其定义如下:
GTS(Gi)=max{TW(rj)},
(22)
其中,j=1,2,…,K.
针对协同作弊团队的攻击行为特征,根据同谋欺骗恶意行为的特征定义,从聚类分组的整体性GRC(Gj)、行为异常性GRD(Gi)以及评分时间相似性GTS(Gi)三个方面进行协同作弊行为的检测分析.
Rodriguez和Laio[27]最近在《Science》提出了一种密度中心聚类算法,将密度值和斥群值表示在一个2维度的决策图上,受此算法的启发,本文提出了一种基于2维特征决策图的协同作弊团体识别方法,对于每个在线聚类分组,可为其计算出(GRC(Gi),GRD(Gi)),将二元组(GRC(Gi),GRD(Gi))分别以行为整体性为横轴、行为异常性为纵轴,从而形成了协同作弊特征决策图,该图能够帮助决策者快速发现离群作弊团体.在此基础上,将攻击时间作为辅助评价指标,进一步对聚类分组进行评分时间相似性GTS(Gi)计算,以更好地识别出同谋团队.
2.2 协同作弊团体发现框架与算法
支持跨组织业务应用的协同作弊团体发现算法框架,根据大规模服务系统日志中服务用户反馈评分信息,综合考虑大规模服务计算的大数据特性问题.首先采用了一种改进的基于小批量学习的在线聚类方法,并通过自动修正权重的聚类分组方差计算进行递减增量优化,将所有高相似性的服务用户聚到同一分组,通过计算目标服务用户与分组中心的相似性确定其所属的类别分组;然后,分析团体的同谋行为特征和协同攻击现象,利用聚类的性质和同谋团体异常性的特征,检测出协同作弊团体,其算法集成框架如图1所示:
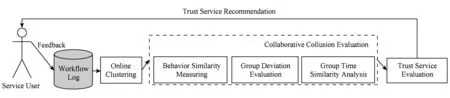
Fig.1 Integration framework of collaborative collusion evaluation图1 协同作弊团体发现算法集成框架
综上所述,基于在线聚类的协同作弊团体发现算法的具体步骤如算法3所示:
算法3. 基于在线聚类的协同作弊团体发现.
输入:服务用户-服务评分信息D=(U,I,R);
输出:协同作弊团体.
①RData←PreProcess(U,I,R);*数据预处理*
②Groups←MyKMeans(RData);*调用基于改进更新规则的在线KMeans算法对所有服务用户聚类分组*
③ FORGiINGroupsDO*计算分析每个聚类分组*
④ 利用在线聚类求解结果,计算所有服务用户分组的整体性:
⑥ 计算所有服务用户分组的攻击时间相似性:GTS(Gi)←max{TW(rj)},其中,j=1,2,…,K;
⑦ END FOR
⑧DecDiagram(GRC(Gi),GRD(Gi));
⑨ 利用攻击时间相似性验证共谋欺骗分组.
基于在线聚类的协同作弊用户识别方法的程序执行时间主要是在聚类过程产生的,假定采用基于完全批量的聚类方法,时间复杂度为O(n×K×d×i);当采用基于随机梯度下降法的在线聚类方法[28]时,时间复杂度为O(1×K×d×i);当采用基于小批量在线学习的聚类方法时,时间复杂度为O(m×K×d×i),其中,n和m是聚类训练样本数量,K为聚类的分组数,d为特征属性维度,i表示迭代次数.由于n≫m>1,总体而言,基于在线聚类的协同作弊检测算法极大地减少了聚类的计算时间,同时,基于协同作弊特征决策图的识别方法保证了对共谋检测的正确性.
3 仿真实验
本文实验环境基于Intel I5-7300 HQ笔记本,CPU主频为2.50 GHz,内存为8.00 GB,所有算法都运用Python编程语言,采用了PyCharm编译工具,运行在Windows 10操作系统上.为了验证所提出算法的可行性和有效性,本节将在不同规模的人工合成数据集、UCI真实数据集以及服务计算等真实数据集上进行了一系列的仿真实验.
3.1 人工数据集仿真实例
本节仿真实例将在不同规模人工合成数据集上,分别从在线服务用户聚类分析与基于改进在线聚类的协同作弊用户识别2个方面运用可视化方法对本文方法进行分析和说明.
3.1.1 基于在线学习的服务用户聚类分析
首先,仿真实验对在线聚类算法进行了收敛性分析,在线聚类分析实验过程中,采用了Scikit-learn的数据分析函数,以[1,1],[1,3],[3,3],[3,1]为中心生成了10 000个人工合成数据,对比分析了基于随机梯度下降的在线聚类算法(SGDKMeans)、基于小批量学习的在线聚类算法(MiniKMeans)以及基于改进更新规则的在线聚类算法(MyKMeans)的收敛速度.在聚类过程中,批量规模取值为500,3种算法在给定的人工合成数据集上运行20次,并计算出算法收敛时间的平均值,实验结果如图2和图3所示:
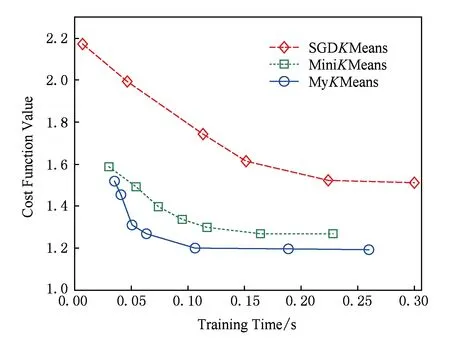
Fig.2 Convergence rate analysis of online clustering (Samples=5 000)图2 在线聚类收敛速度分析(Samples=5 000)
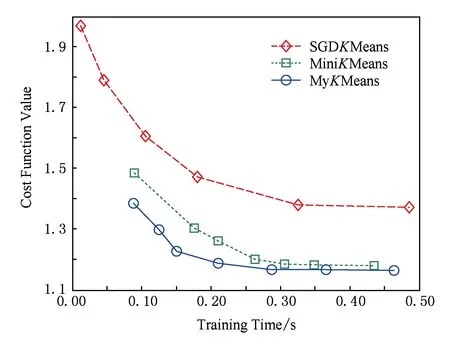
Fig.3 Convergence rate analysis of online clustering (Samples=10 000)图3 在线聚类收敛速度分析(Samples=10 000)
图2的训练样本数据的数量为5 000,而图3的样本数目为10 000.通过观察可知,SGDKMeans算法、MiniKMeans算法以及MyKMeans算法都能以较快的速度收敛,适用于大规模服务计算.但是,MyKMeans和MiniKMeans的聚类质量明显好于SGDKMeans算法;并且,本文所提出的在线聚类算法MyKMeans的收敛效果更优于MiniKMeans算法.
针对KMeans聚类的分组数目的确定问题,基于改进更新规则的在线聚类算法(MyKMeans)采用了基于拐点的聚类数目确定方法,首先随机选取训练样本数据中的K个点作为起始点,当K值确定后,随机进行聚类计算n次,取得最小开销函数值的K作为最终聚类结果,避免随机引起的局部最优解;并通过绘制出K-开销函数散点图,选取有明显拐点的开销函数值,设为K值,如图4所示.
在线聚类效果分析实验主要采用了Scikit-learn的数据分析函数,同样以[1,1],[1,3],[3,3],[3,1]为中心,生成了10 000个人工合成数据,分别应用KMeans+ +聚类算法、改进前的基于小批量学习的在线聚类算法(MiniKMeans)以及提出的基于改进更新规则的在线聚类算法(MyKMeans)进行了仿真模拟,实验效果如图5所示.其中ObjCost值表示误差平方和值,KMeans+ +的误差平方和最小,其ObjCost值为1.162 036;MiniKMeans的误差平方和值最大,其ObjCost值为1.180 610;而MyKMeans的ObjCost值为1.165 977,几乎和KMeans+ +接近,好于MiniKMeans算法,取得了良好的聚类效果.
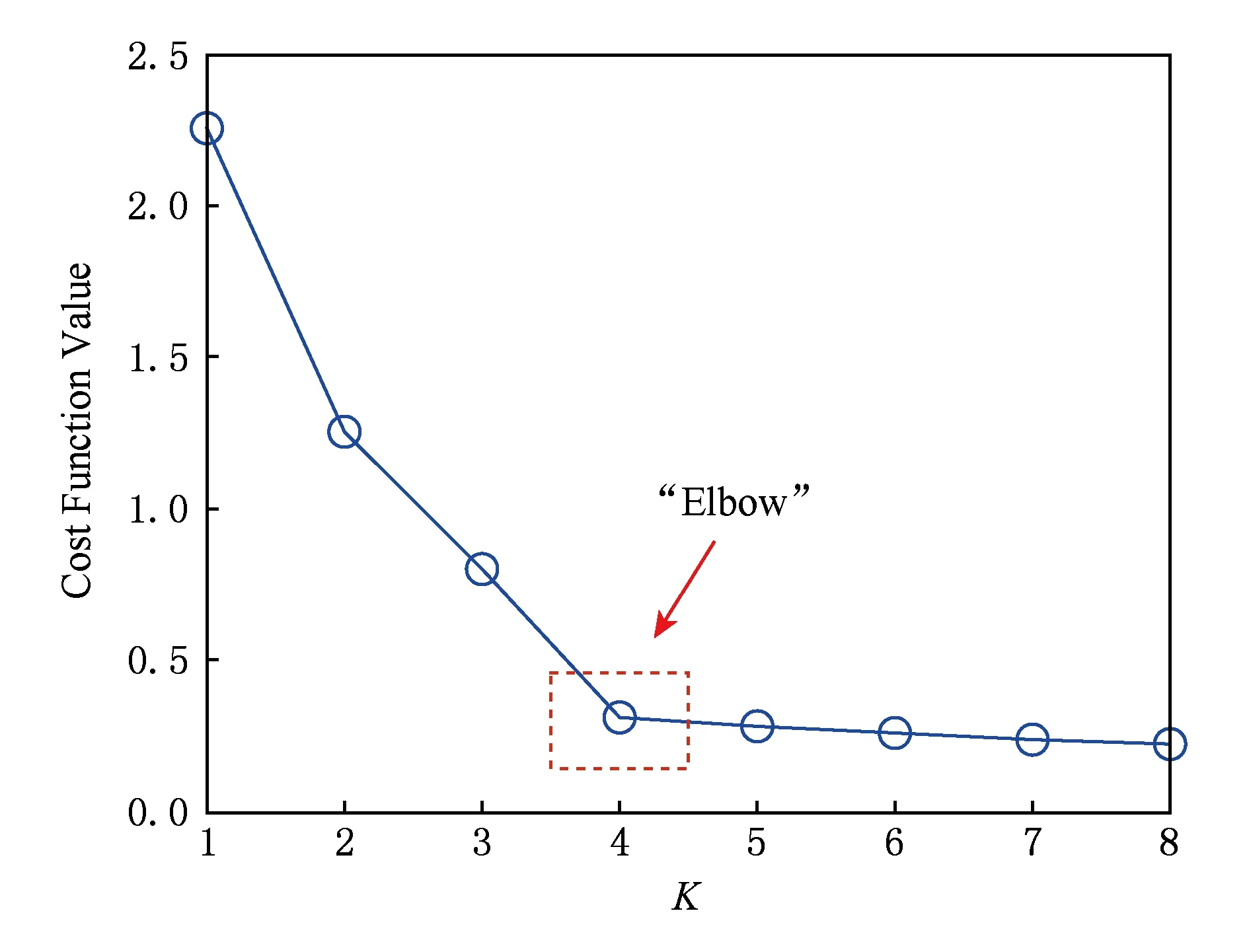
Fig. 4 K value confirmation of online clustering for MyKMeans图4 MyKMeans在线聚类K值选取分析
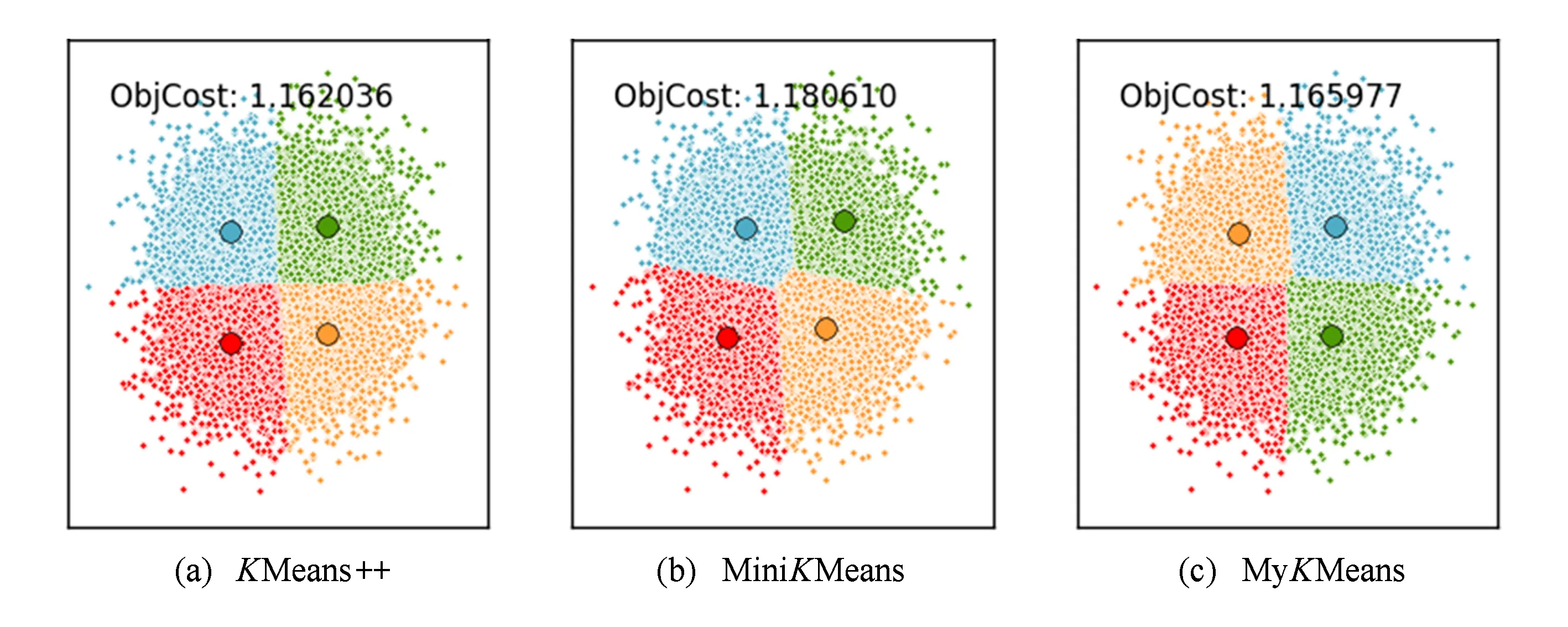
Fig. 5 Effective analysis of user clustering based on online learning图5 基于在线学习的用户聚类效果分析

Fig. 6 Silhouette coefficient analysis of online clustering图6 基于轮廓系数的在线聚类效果分析
在线聚类效果分析实验进一步采用轮廓系数,评估分析了KMeans+ +和MyKMeans算法的聚类效果,实验结果如图6所示.其中,KMeans+ +算法效果稍好于MyKMeans算法,MyKMeans算法与KMeans+ +算法的轮廓系数值几乎相同.
在验证所提出的基于改进更新规则的在线聚类算法(MyKMeans)的时效性时,为使得实验结果对比反差更大,效果更明显直观,算法时间效率实验生成3种规模间隔更大的人工数据[2 000,5 000,10 000],并将KMeans+ +,MiniKMeans,以及MyKMeans算法运行在该人工数据集上,3种算法的时间性能分析实验结果如图7所示.其中,MyKMeans算法的时间效率与改进前的MiniKMeans算法接近,都明显好于KMeans+ +算法,特别是随着样本数量的不断增多,MyKMeans算法比KMeans+ +算法效率表现得更好.
由实验分析可知,所提出的MyKMeans算法不仅表现出良好的算法时效性,而且具有较好的算法精度.
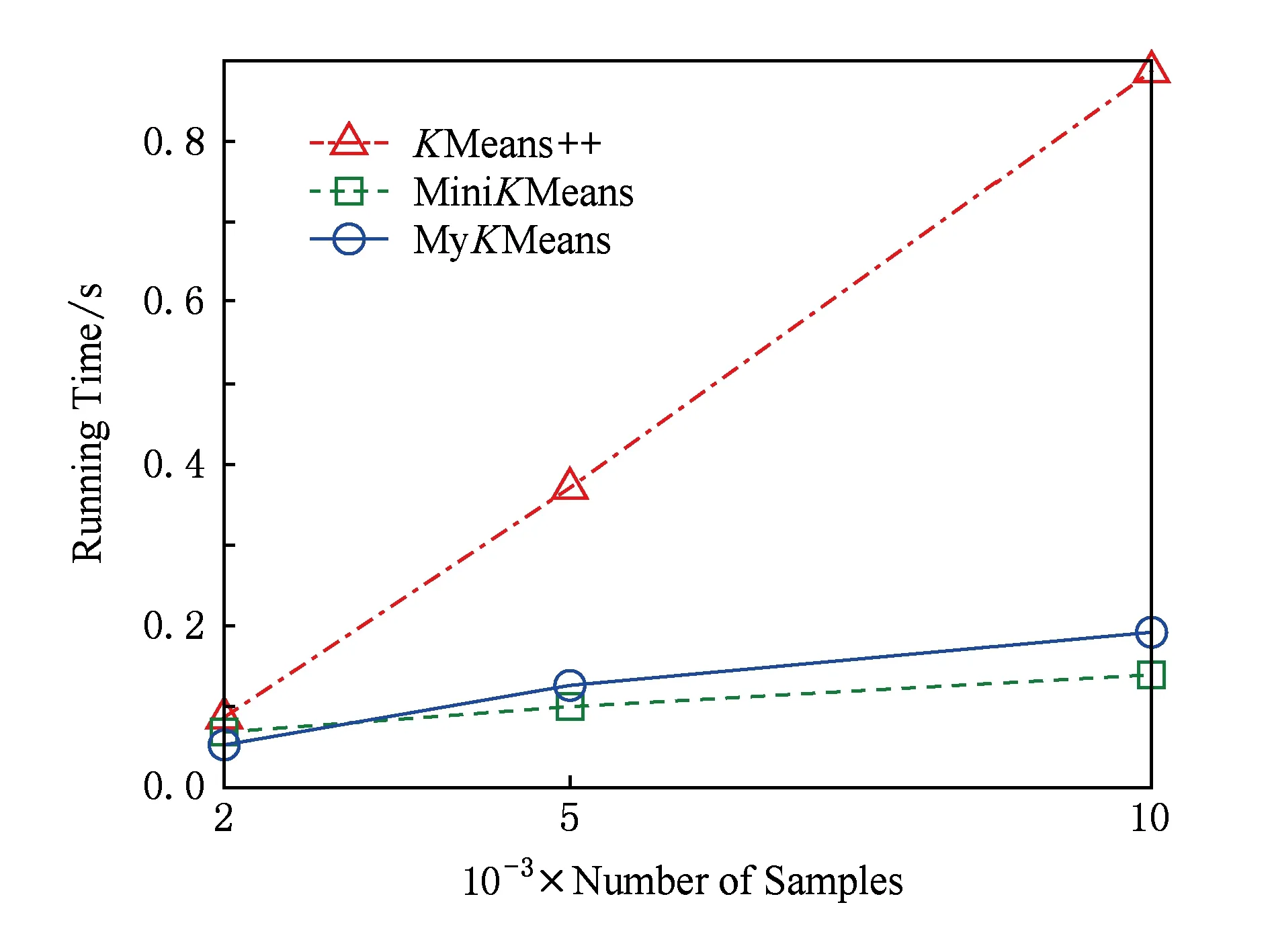
Fig. 7 Time efficiency analysis of clustering algorithm图7 聚类算法的时间效率分析
3.1.2 协同作弊特征决策图可视化分析
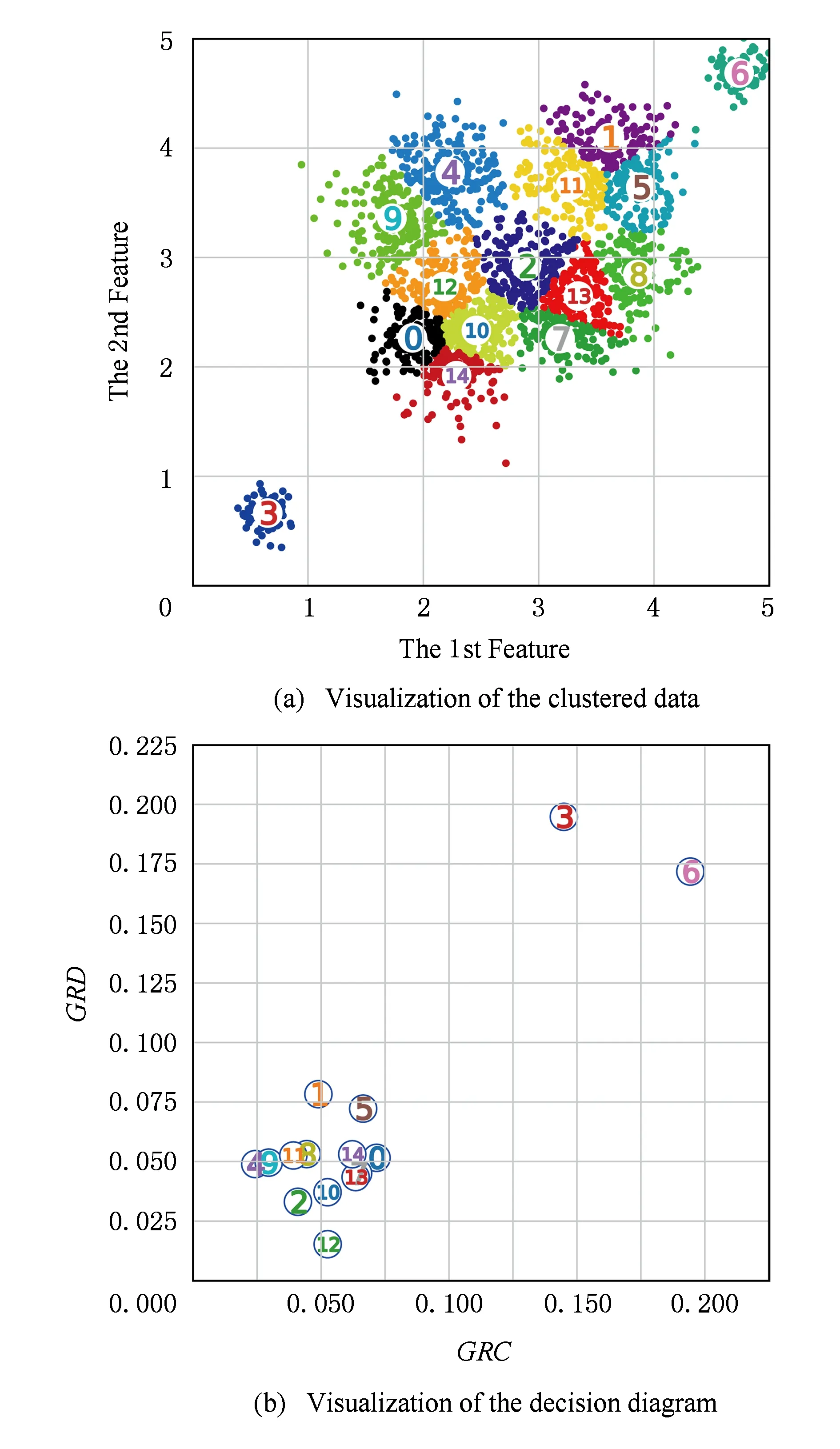
Fig. 8 Binary decision diagrams of collaborative collusion features图8 协同作弊特征2维决策图分析
协同作弊用户分组检测实验采用人工合成数据方法,针对协同作弊团队的攻击问题,根据协同作弊恶意行为的特征定义,从聚类分组的整体性、行为异常性以及评分时间相似性3个方面进行协同作弊检测分析.对于每一聚类分组,计算出聚类分组行为的GRC(Gi)和异常性值GRD(Gi)二元组,分别以行为整体性的取值为横轴、行为异常性值为纵轴,从而形成了协同作弊特征决策图,为用户可信度评估分析提供了决策支持,如图8所示.
通过观察图8可知,聚类分组3和分组6由于同时具有较大的GRC(Gi)和GRD(Gi)值,于是从其他聚类分组中脱颖而出,从而帮助管理者直观地快速检测出协同作弊团体.因此可见,协同作弊特征决策图方法能够有效地呈现出共谋团体.在此基础上,可将攻击时间作为辅助评价指标,进一步对聚类分组3和6进行评分时间相似性GTS(Gi)计算,以更好地识别出协同作弊团队.
3.2 真实数据集仿真实例
本节实验采用了真实数据集,分别从聚类精度和时间效率2个方面测试了本文提出算法MyKMeans的有效性和可行性.其中,仿真实验从UCI机器学习数据库[29]中选择了Iris,Digits,20newsgroup以及在WS-DREAM数据集[30]中选取了wsdata1和wsdata2等真实数据集,相关数据集的信息如表1所示:
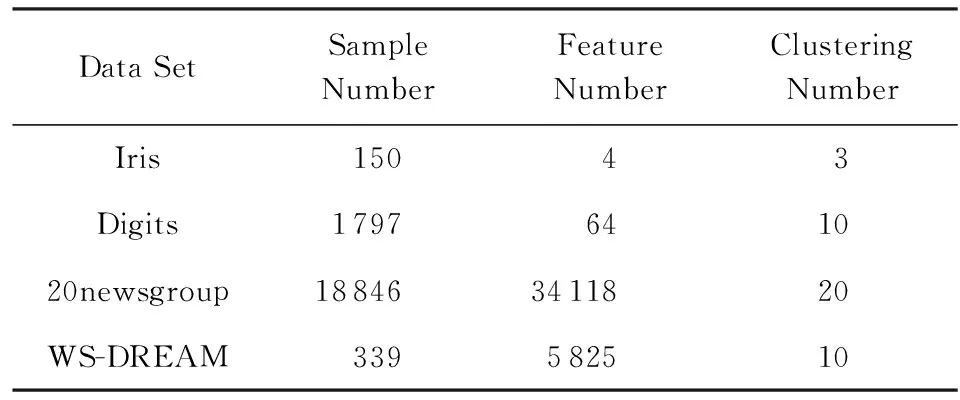
Table 1 Real Data Analysis表1 真实实验数据分析
3.2.1 在线聚类算法的精度分析
在聚类精度实验过程中,将采用聚类性能度量函数分析聚类结果的精确度,度量函数指标包括6个聚类有效性评测指标:1)类内聚合度Inertia;2)调整兰德指标(adjusted rand index,ARI);3)调整互信息(adjusted mutual information,AMI);4)同质性指标(homogeneity,Homo);5)完整性指标(completeness,Compl);6)调和平均指标(V-measure,V-meas).其中,类内聚合度Inertia是类内聚合度的一种度量方式,当Inertia值越小时,聚类效果越好;调整兰德指数ARI是一个外部评测指标,根据数据真实分类标签,测试数据的聚类结果与实际分类之间的相似度;当聚类精度越高时,即聚类结果越近似于实际分类,ARI值也越高;调整互信息AMI是利用基于互信息的方法来衡量聚类效果,当聚类结果越近似于实际分类,AMI值也越高;同质性指标Homo是分析每个聚类是否只包含单个类别的成员;完整性指标Compl则是分析给定类的所有成员是否都分配给了同一聚类分组;而调和平均指标V-meas表示Homo和Compl两者的调和平均,V-meas,Homo,Compl的值在0~1之间,值越大则表明聚类效果越佳.
首先,我们采用了UCI分类数据集Iris进行精度仿真实验,Iris数据集包含了150个数据样本,分为了3类,每类有50个数据,每个样本数据包含4个属性特征.数据集Iris的聚类精度实验结果如表2所示:

Table 2 Clustering Accuracy Analysis of Iris Data表2 Iris实验数据的聚类精度分析
其次,我们采用了UCI手写数字图像训练集Digits进行精度仿真实验,Digits共有1767个手写数字的图像矩阵,每个手写数字图像都储存成为8×8的矩阵,每个像素表示一个特征.因此,Digits原始数据是64个特征.数据集Digits的聚类精度仿真实验结果如表3所示:
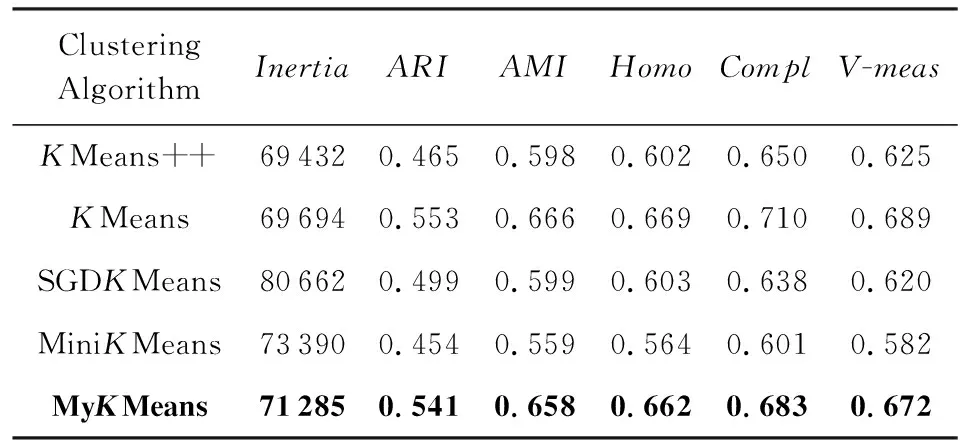
Table 3 Clustering Accuracy Analysis of Digits Data表3 Digits实验数据的聚类精度分析
最后,我们采用了UCI机器学习库的20新闻语料数据集(20newsgroup)进行精度仿真实验,本次实验抽取了20newsgroup数据集中4个不同话题的新闻组信息,包含了2 034个新闻语料样本数据,每个样本的特征维度是4 331.在聚类处理过程中,首先采集数据并提取特征,将有噪文本转化为向量表征;然后进行聚类模型训练实验.数据集20newsgroup的聚类精度实验结果如表4所示:
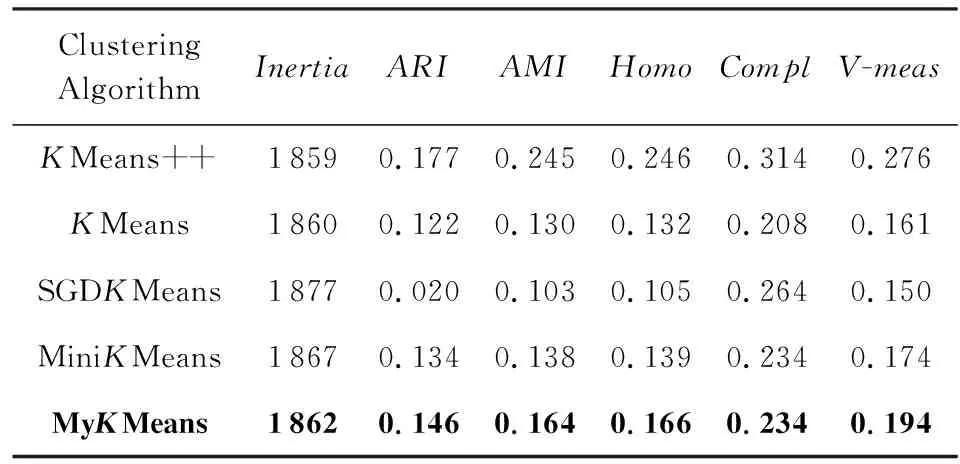
Table 4 Clustering Accuracy Analysis of 20newsgroup Data表4 20newsgroup实验数据的聚类精度分析
通过观察表2~4,可以得出以下结论:本文提出的改进聚类算法MyKMeans,在3个真实数据集上的聚类效果均优于SGDKMeans和MiniKMeans算法,表现出了良好的算法性能.
3.2.2 在线聚类算法的时间性能分析
本次实验将从不同规模的样本数量和不同数量的属性特征2方面,在真实新闻语料数据集20newsgroup上验证分析了本文相关的聚类算法的时间效率.图9是基于不同数据规模的聚类时间性能实验结果,验证了本文相关聚类算法的时间相对于不同规模样本数量的变化情况,随着规模增加,聚类处理时间不断增加.图10是基于不同维度属性特征的聚类时间性能实验结果,主要分析了在不同属性特征数量的变化情况下本文相关聚类算法的时间性能.由图10可知,随着维度增加,聚类处理时间不断增加.
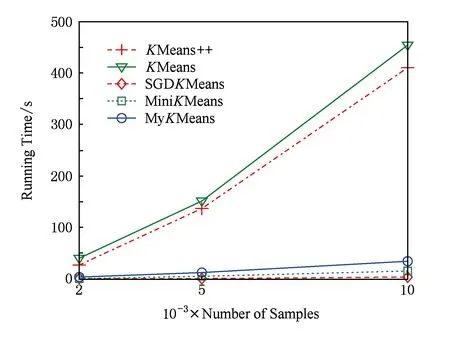
Fig. 9 Time efficiency analysis of clustering algorithms图9 不同数据规模的聚类算法时间效率分析
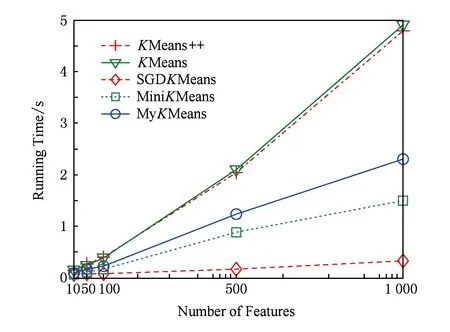
Fig. 10 Time efficiency analysis of clustering algorithms图10 不同属性特征规模的聚类算法时间效率分析
通过观察聚类实验结果图9和图10,可得出以下结论:在数据集20newsgroup的不同数据规模和属性特征数的变化情况下,MyKMeans的聚类时间性能远优于KMeans和KMeans+ +聚类算法,与MiniKMeans算法的时间性能接近.由此分析,本文所提出的在线聚类算法在真实数据集表现出良好的算法时效性,而且具有较好的算法精度,进一步验证说明了本文提出算法的可行性和有效性.
3.2.3 协同作弊用户分组识别算法的分析实验
协同作弊团体识别实验采用了真实的WS-DREAM数据集wsdata1和wsdata2,其中wsdata1和wsdata2是用于服务用户评价和服务推荐的数据集,根据共谋作弊恶意行为的特征,我们分别对WS-DREAM的2个数据集进行了攻击.然后,运用在线聚类算法MyKMeans对WS-DREAM数据集进行聚类分组,并在此基础上,采用本文的在线协同作弊团体识别方法,计算出每个聚类分组的行为二元组:整体性值GRC(Gi)和异常性值GRD(Gi).其中,表5是wsdata1数据集的所有聚类分组的特征行为二元组值.
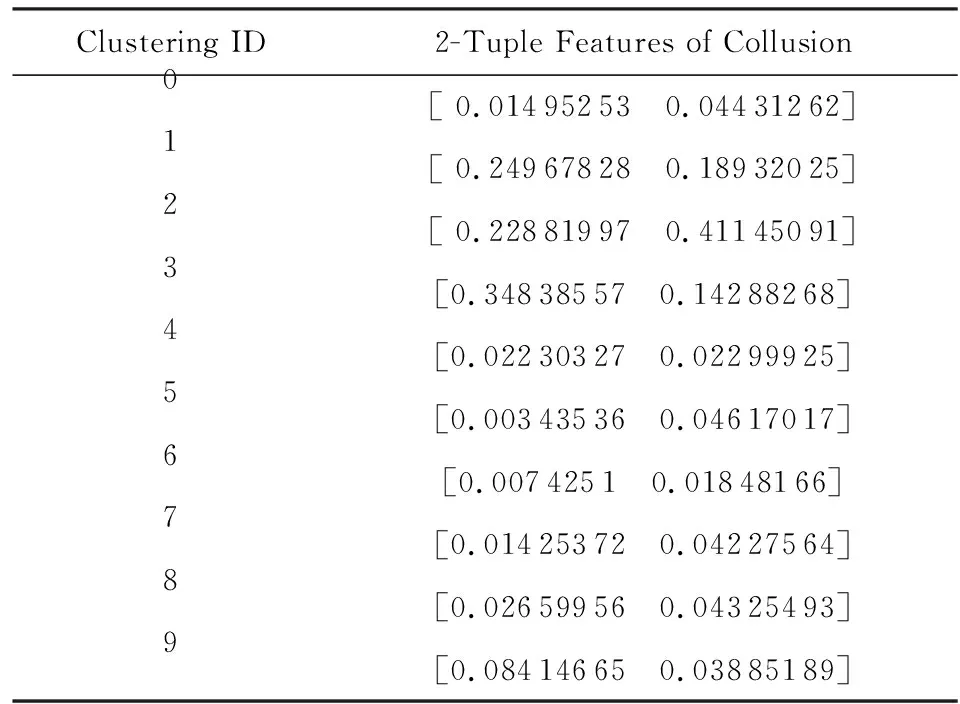
Table 5 Analysis of wsdata1 Collusion Features表5 wsdata1协同作弊检测分析
在此基础上,我们采用共谋特征决策图方法,分析了每个聚类分组的行为,如图11和图12所示:

Fig. 11 Analysis of wsdata1 collusion features图11 wsdata1协同作弊检测分析
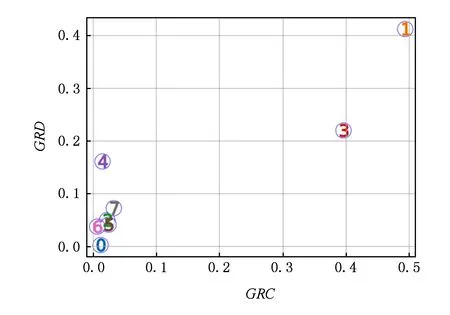
Fig. 12 Analysis of wsdata2 collusion features图12 wsdata2协同作弊检测分析
在图11中,具有共谋特征的聚类分组1、分组2以及分组3都有较大的GRC(Gi)和GRD(Gi)值,并且远离正常聚类分组,于是被识别出来;同样,在图12中,聚类分组1和分组3也是同时具有较大的GRC(Gi)和GRD(Gi)值,在基于作弊特征二元决策图的可视化方法帮助下,我们有效地区分出了正常聚类分组和共谋团体.而且,通过综合分析实验结果表5和图11~12可知,相对于表格分析方法,基于特征决策图的检测方法更容易识别出具有协同作弊特征的聚类分组.在真实数据集wsdata1和wsdata2上,基于特征决策图的协同作弊团队发现方法表现出了良好的识别效果,验证分析了本文所提出的协同作弊团队识别方法.
4 总结与展望
针对大规模服务计算的大数据特性,提出了基于改进更新规则的在线聚类算法,采取改进的基于小批量学习的在线KMeans聚类算法,并通过自动修正权重的聚类分组方差优化方法,提高了在线KMeans聚类算法的解质量,同时保证了聚类算法的时间效率;进一步,基于在线聚类分组的基础上,充分考虑协同作弊及策略攻击等恶意行为的特征,定义了同谋攻击的一致性、异常性以及时间相似等检测指标函数,设计了一个基于协同作弊特征决策图的共谋团体识别方法,采用可视化的方式分析了聚类分组的情况.通过在线聚类和协同作弊检测方法,实现了共谋团体的快速识别,本文主要工作包括:1)提出了基于改进更新规则的在线聚类算法;2)提出了在线协同作弊团体发现算法,为面向服务的云计算应用系统集成可信服务提供了技术支持;3)仿真实验分析了基于在线聚类的协同作弊团体识别方法的可行性.实验结果表明,提出的算法通过融合在线聚类与共谋欺骗检测技术,有效地解决了大规模服务计算中协同反馈欺骗问题.
基于在线学习的协同作弊团体识别方法能够快速检测出共谋欺骗用户,为可信分析提供决策支持,因此,在可信计算与服务推荐系统领域有着重要的应用前景.当前,基于在线学习的协同作弊团体识别方法面临各种挑战,特别是如何有效地使用分布式数据和并行计算技术,基于并行在线学习的协同作弊团体识别问题有待人们进一步深入探索和解决.
[1]Jiang Meng, Cui Peng, Faloutsos C. Suspicious behavior detection: Current trends and future directions[J]. IEEE Intelligent Systems, 2016, 31(1): 31-39
[2]Wang Haiyan, Yang Wenbin, Wang Suichang, et al. A service recommendation method based on trustworthy community[J]. Chinese Journal of Computers, 2014, 37(2): 301-311 (in Chinese)(王海艳, 杨文彬, 王随昌, 等. 基于可信联盟的服务推荐方法[J]. 计算机学报, 2014, 37(2): 301-311)
[3]Sun Yong, Tan Wenan. Cross-organizational workflow task allocation algorithms for socially aware collaborative computing[J]. Journal of Computer Research and Development, 2017, 54(9): 1865-1879 (in Chinese)(孙勇, 谭文安. 支持社会协同计算的跨组织工作流任务分派算法[J]. 计算机研究与发展, 2017, 54(9): 1865-1879)
[4]Bouguettaya A, Singh M, Huhns M, et al. A service computing manifesto: The next 10 years[J]. Communications of the ACM, 2016, 60(4): 64-72
[5]Meng Xiaofeng, Li Yong, Zhu Jianhua. Social computing in the era of big data: Opportunities and challenges[J]. Journal of Computer Research and Development, 2013, 50(12): 2483-2491 (in Chinese)(孟小峰, 李勇, 祝建华. 社会计算: 大数据时代的机遇与挑战[J]. 计算机研究与发展, 2013, 50(12): 2483-2491)
[6]Wu Zhiang, Zhuang Yi, Wang Youquan, et al. Shilling attack detection based on feature selection for recommender systems[J]. Acta Electronica Sinica, 2012, 40(8): 1687-1693 (in Chinese)(伍之昂, 庄毅, 王有权, 等. 基于特征选择的推荐系统托攻击检测算法[J]. 电子学报, 2012, 40(8): 1687-1693)
[7]Burke R, Mobasher B, Williams C, et al. Classification features for attack detection in collaborative recommendation systems[C]Proc of the 12th Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2006: 542-547
[8]Wu Zhiang, Wang Youquan, Cao Jie. A survey on shilling attack models and detection techniques for recommender systems[J]. China Science Bull, 2014, 59(7): 551-560 (in Chinese)(伍之昂, 王有权, 曹杰. 推荐系统托攻击模型与检测技术[J]. 科学通报, 2014, 59(7): 551-560)
[9]Tan Wenan, Sun Yong, Li Lingxia, et al. A trust service-oriented scheduling model for workflow applications in cloud computing[J]. IEEE Systems Journal, 2014, 8(3): 868-878
[10]Sun Yong, Tan Wenan, Li Lingxia, et al. A new method to identify collaborative partners in social service provider networks[J]. Information Systems Frontiers, 2016, 18(3): 565-578
[11]Li Baichuan, Li Ronghua, King I, et al. A topic-biased user reputation model in rating systems[J]. Knowledge and Information Systems, 2015, 44(3): 581-607
[12]Li Ronghua, Yu Xu, Huang Xin, et al. Robust reputation-based ranking on bipartite rating the networks[C]Proc of the 12th SIAM Int Conf on Data Mining. Philadelphia, PA: SIAM, 2012: 612-623
[13]Chandola V, Banerjee A, Kumar V. Anomaly detection: A survey[J]. ACM Computer Survey, 2009, 41(3): 1-15
[14]Vasilomanolakis E, Karuppayah S, Mühlhäuser M, et al. Taxonomy and survey of collaborative intrusion detection[J]. ACM Computing Surveys, 2015, 47(4): 55:1-55:33
[15]Yang Haiqin, Lu Rongcong, Jin Guoqing. Big data oriented online learning algorithms[J]. Communications of CCF, 2014, 10(11): 36-40 (in Chinese)(杨海钦, 吕荣聪, 金国庆. 面向大数据的在线学习算法[J]. 中国计算机学会通讯, 2014, 10(11): 36-40)
[16]Yang Haiqin, Lyu M R, King I. Efficient online learning for multitask feature selection[J]. ACM Trans on Knowledge Discovery from Data, 2013, 7(2): 1-27
[17]Orabona F, Crammer K, Cesa-Bianchi N. A generalized online mirror descent with applications to classification and regression[J]. Machine Learning, 2015, 99(3): 411-435
[18]Shalev-Shwartz S. Online learning and online convex optimization[J]. Foundations & Trends in Machine Learning, 2012, 4(2): 107-194
[19]Poole D L, Mackworth A K. Artificial Intelligence: Foundations of Computational Agents[M]. Cambridge, UK: Cambridge University Press, 2010
[20]Tzortzis G, Likas A, Tzortzis G. The MinMaxk-Means clustering algorithm[J]. Pattern Recognition, 2014, 47(7): 2505-2516
[21]Miao Guangsheng, Feng Dengguo, Su Purui. A collusion detector based on fuzzy logic in P2P trust model[J]. Journal of Computer Research and Development, 2011, 48(12): 2187-2200 (in Chinese)(苗光胜, 冯登国, 苏璞睿. P2P信任模型中基于模糊逻辑的共谋团体识别方法[J]. 计算机研究与发展, 2011, 48(12): 2187-2200)
[22]Miao Guangsheng, Feng Dengguo, Su Purui. Colluding clique detector based on activity similarity in P2P trust model[J]. Journal on Communications, 2009, 30(8): 9-20 (in Chinese)(苗光胜, 冯登国, 苏璞睿. P2P信任模型中基于行为相似度的共谋团体识别模型[J]. 通信学报, 2009, 30(8): 9-20)
[23]Mehta B, Nejdl W. Unsupervised strategies for shilling detection and robust collaborative filtering[J]. User Modeling and User-Adapted Interaction, 2009, 19(12): 65-97
[24]Gunes I, Kaleli C, Bilge A, et al. Shilling attacks against recommender systems: A comprehensive survey[J]. Artificial Intelligence Review, 2014, 42(4): 767-799
[25]Mukherjee A, Liu Bing, Wang Junhui, et al. Detecting group review spam[C]Proc of the 20th Int Conf on World Wide Web. New York: ACM, 2011: 93-94
[26]Mukherjee A, Liu Bing, Glance N. Spotting fake reviewer groups in consumer reviews[C]Proc of the 20th Int Conf on World Wide Web. New York: ACM, 2012: 191-200
[27]Rodriguez A, Laio A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191): 1492-1496
[28]Kanungo T, Mount D M, Netanyahu N S, et al. An efficientk-means clustering algorithm: Analysis and implementation[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2002, 24(7): 881-892
[29]University of California, School of Information and Computer Science. UCI Machine Learning Repository[EBOL]. (2007-06-25) [2013-04-04]. http:archive.ics.uci.eduml
[30]The Chinese University of Hong Kong. WS-DREAM: Towards Open Datasets and Source Code for Web Service Research[EBOL]. (2015-08-29) [2017-08-18]. https:wsdream.github.io

SunYong, born in 1977. PhD. Member of CCF. His main research interests include cooperative computing, service computing, social workflow scheduling, intelligent infor-mation systems, and software engineering.

TanWenan, born in 1965. PhD, professor, PhD supervisor. Senior member of CCF. His main research interests include software engineering, process engineering and development environment, enterprise dynamic modeling, trusted service comput-ation, and enterprise intelligent information systems.

JinTing, born in 1994. MSc candidate. Her main research interests include coo-perative computing and service computing.

ZhouLiangguang, born in 1981. MSc. His main research interests include data mining and geographic information science.
猜你喜欢
中等数学(2022年8期)2022-10-24
北京航空航天大学学报(2022年8期)2022-08-31
汉字汉语研究(2021年4期)2021-11-26
中等数学(2018年8期)2018-11-10
小学阅读指南·低年级版(2018年5期)2018-11-02
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
故事作文·低年级(2017年12期)2017-12-13
互联网天地(2016年1期)2016-05-04
环球时报(2012-03-28)2012-03-28
