
图像识别处理技术在农业工程中的应用*
2018-06-05 01:44王慧,季雪
传感器与微系统 2018年6期
王 慧, 季 雪
0 引 言
现阶段,农业生产逐步走向现代化[1,2]。在果蔬农场中,使用了一定数量的采摘机器人,在实际工作过程中,机器人在单位时间内采摘的果实数量和质量,与人工相比有很大的差距。此外,在采摘过程中,机器人易损伤果实。因此,必须研发高精度的视觉系统,以快速准确地检测到符合采摘要求的果实,准确测量其位置,实现精确采摘[3,4]。该过程中涉及到机器视觉技术,融合了多门学科专业知识,主要包括光学原理、计算机学、影像成型、生物学以及过程控制学等[5~7]。
本文对图像识别技术在农业工程中的应用进行了研究,提出了一种苹果图像识别技术,为实现苹果智能采摘提供了新方法。
1 图像预处理
1.1 图像分割方法
苹果与背景之间的色彩差距较大,可以使用图像分割方法对果实和背景的颜色进行区分。在真实的果园背景中选取多张照片,重点突出果实和背景重合的区域,在该区域中选取并分析R,G,B 颜色因子的值。通过分析发现,R-G 和2R-G-B 可以明显区分苹果和背景的色彩。
由于固定阈值分割法无法较好地适应光线的变化,所以,使用的最大类间方差法(OTSU)法,该方法功能强大,可用于阈值分割,在进行求值时,使用的图像目标和背景使类内方差最小、类间方差最大。
图像分割后,图像中往往存在独立的点、小空洞、毛刺,为了降低这部分噪声对辨识产生影响,使用了文献[8]中所述的腐蚀—去除—膨胀的方法,即对分割后的图像实施腐蚀计算,以消除目标界线的临界点,促使边界向内收缩;采用小区域消除运算对图像法中依然存在的小区域实施消除;采用膨胀计算对目标临界点实施扩展,将目标接触的全部点整合到该目标中。最终图像分割为背景和果实2部分内容[9]。
1.2 图像特征提取
在图像辨识体系中最关键的是准确地判别目标。但由于苹果自然成长的无规则性,以及图像收集过程中拍摄角度的差异,极易产生果实之间叠加、枝叶挡住果实等情况,对准确辨识目标物产生很大干扰,获得的图像存在很差异,并且变化非常大。为了获得更加准确的神经网络辨识模型,以及更加便捷地辨识结果,在神经网络(neural network,NN)进行练习的过程中,将树枝、树叶、果实一起进行训练。训练样本特征时,在分割图像中选取对应的一段树枝、一片树叶,用于特征提取。在辨识样本图像的过程当中,仅需提取果实目标物的特性即可[10,11]。
根据文献[12]中的方法对果实特征进行提取。在RGB颜色空间中,可以直接实施颜色对比。肉眼看到的颜色与HSI颜色具有一定的相似性,并且能够适合全部的关联环境,在颜色特性中提取H,S,I 3个分量十分关键。提取HIS,RGB颜色空间中的6个颜色分量特性,用于介绍目标物的整体特性。树枝、树叶、果实均具有其独特的形态,并且其中存在很大的差异,提取对象的状态非常切合实际。根据苹果果实图像的特征,选择Hu不变矩和几何图像特点,其中Hu不变矩包括了7个特征向量,几何特征选择了周长平方面积、致密度、圆方差3种特征向量。提取10个不因对象物在图像中的角度、大小、位置而产生改变的形状特征,即特征满足旋转、缩放和平移(rotation scale translation, RST)不变性。
2 图像识别算法
使用神经网络算法对处理后的果实图像进行分析,从而识别出图像中的果实。将上述研究的苹果果实(目标)和树枝、树叶(干扰)的颜色形状特征共16种,作为NN识别模型的输入量,建立基于NN的苹果果实识别模型。
2.1 常规反向传播NN算法
作为一种多层前馈型网络,反向传播神经网络(back propagation NN,BPNN)能够前向输入信号,逆向反馈误差信号。在进行前向运输时,输入信号的处理途径为输入层—隐含层—输出层,采用逐层处理的方法。通过对比期望输出以及输出层输出进行反馈,网络结构中的权值可以通过两者的差值进行调整。利用BPNN经过多次训练后即可更加接近期望输出,进而得到合适的阈值和权值。
NN函数实际上具有非线性的特点,其非线性函数的因变量为输出层输出的变量,自变量为输入层输入的变量,形成一个函数映射。本文根据NN所具有的特点,在充分分析影响识别质量影响因素的基础上,采用NN训练得到识别质量和影响因素间的关系,其具体的关系可以通过权值和阈值体现出来。
但在应用BPNN的过程中存在一定的问题:阈值和权值随机生成,容易导致局部最优,降低了训练效果;无法有效地确定学习率,当学习率过大时结果准确性无法保证,如果学习率太小会减缓训练过程,无法保证快速的收敛。解决方法:在寻找权值和阈值时借助遗传算法实现,能够有效避免局部最优问题;改进原有的固定学习率,在对自适应学习率进行改进的过程中有效地提升学习效率。
2.2 遗传优化算法
使用文献[13]改进算法对遗传优化算法进行更进一步优化。通过改动常规的变异和交叉操作来提升进化速度:1)对免疫算法中所具有的免疫记忆机制进行应用,保护优秀个体,不进行交叉和变异操作,提升最优解的寻找速度;2)改变变异过程中的变异概率,先对适应度进行排序,并标记后30 %的个体,在变异操作的过程中采用更高的概率以保证最优个体的出现,加快进化速度;3)由于染色体具有较长的长度,为了保证优秀个体的产生采用多点交叉的方法。
3 苹果图像识别模型构建
本文主要考察苹果、树枝和树叶的16种颜色形状特征,通过识别模型分别识别出图像中的果实、树枝以及树叶, 因此,可以确定NN模型的输入节点数为16,输出节点数为3。常规NN使用经验试凑法确定隐含层节点数为35。
针对BPNN对于网络初始阈值和权值比较依赖,采用随机选取的方法容易出现局部最优现象,应用遗传算法实现全局优化,得到全局最优解。在优化和寻优神经网络初始阈值和权值时应用遗传算法能够达到自适应学习的目的,有效提升了训练和学习效率。
4 苹果图像识别分析
4.1 苹果图像特征提取
选取1 000幅苹果果实图像,按照图像分割与特征提取方法提取用于识别的特征。获得完整果实和有树叶遮挡果实的图像处理过程如图1所示。

图1 苹果果实图像处理过程
4.2 苹果图像识别结果分析
使用200幅仅有一个苹果果实的图像对识别模型进行训练,使用剩余600幅图像对训练后的识别模型进行测试,测试样本随机分为3组:图像中大部分图像为完整苹果果实;部分图像被树叶遮挡;另一部分图像存在苹果果实重叠,各情况在样本中的比例如表1所示。

表1 苹果果实识别测试样本
针对3组样本,分别使用常规BPNN和本文研究的识别模型得到的识别准确率如图2所示。
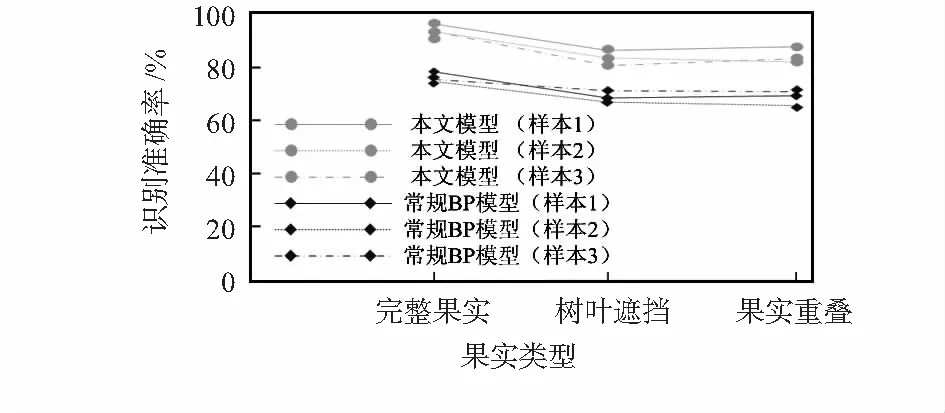
图2 3组测试样本的苹果果实识别准确率
可以看出:针对完整的果实,本文模型和常规BP模型的识别准确率分别为95.8 %和86.6 %;针对有树叶遮挡的果实,本文模型和常规BP模型的识别准确率分别为84.3 %和80.9 %;针对有重叠的果实,本文模型和常规BP模型的识别准确率分别为82.6 %和75.2 %。
树叶遮挡和果实重叠会降低识别模型的识别准确率,经过实验,不同遮挡率情况下,识别模型的识别准确率如图3所示。
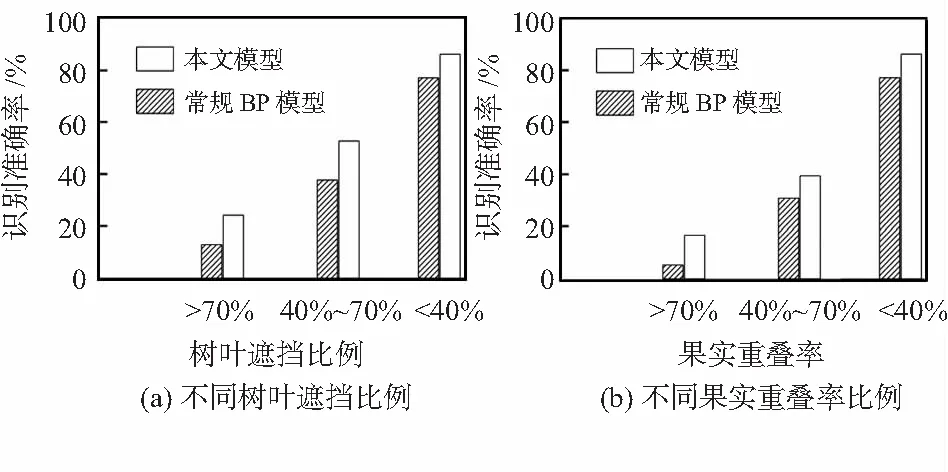
图3 不同遮挡率情况下识别模型的识别准确率
不同遮挡率情况下,识别模型的识别准确率测试结果可以看出:当树叶遮挡比例或果实重叠率大于70 %时,虽然本文模型较常规BP模型具有更好的识别准确率,但总体识别准确率极低,无法满足识别与采摘的精度要求,当树叶遮挡比例或果实重叠率在40 %~70 %之间时,总体识别准确率有所上升,只有当树叶遮挡比例或果实重叠率在40 %以下时,总体识别准确率才能够稳定,满足识别与采摘的精度要求。
5 结 论
针对图像识别技术在农业工程中的应用进行了研究,提出了一种苹果图像识别技术,为实现苹果智能采摘提供了一种新方法。测试结果表明:1)相比常规BPNN模型,本文方法具有更高的识别准确率。2)当树叶遮挡比例或果实重叠率大于70 %时,识别准确率极低,无法满足识别与采摘的精度要求;当树叶遮挡比例或果实重叠率在40 %以下时,总体识别准确率满足识别与采摘的精度要求。
参考文献:
[1] 王 琼.基于优化理论的神经网络研究及在抽油机故障诊断中的应用[D].大庆:东北石油大学,2011:11-14.
[2] 冯 娟,曾立华,刘 刚,等.融合多源图像信息的果实识别方法[J].农业机械学报,2014,45(2):73-80.
[3] 马晓丹.苹果树冠层光照分布计算方法研究[D].北京:中国农业大学,2015:14-16.
[4] 冯 娟,刘 刚,王圣伟,等.采摘机器人果实识别的多源图像配准[J].农业机械学报,2013,44(3):197-203.
[5] 王 晋.自然环境下苹果采摘机器人视觉系统的关键技术研究[D].秦皇岛:燕山大学,2014:66-69.
[6] 吕小莲,吕小荣,卢秉福.西红柿采摘机器人视觉系统的设计与研究[J].传感器与微系统,2010,29(6):21-24.
[7] 李 剑,李臻峰,宋飞虎,等.基于近红外光谱的水蜜桃采摘期的鉴别方法[J].传感器与微系统,2017,36(10):48-50.
[8] 吕继东,赵德安,姬 伟.苹果采摘机器人目标果实快速跟踪识别方法[J].农业机械学报,2014,45(1):65-72.
[9] 吕继东.苹果采摘机器人视觉测量与避障控制研究[D].镇江:江苏大学,2012:13-16.
[10] 谢忠红.采摘机器人图像处理系统中的关键算法研究[D].南京:南京农业大学,2013:15-25.
[11] 王津京.基于支持向量机苹果采摘机器人视觉系统的研究[D].镇江:江苏大学,2009:35-60.
[12] 贾伟宽,赵德安,刘晓洋,等.机器人采摘苹果果实的K-means和GA-RBF-LMS神经网络识别[J].农业工程学报,2015,31(18):175-183.
[13] 毕艳亮,宁 芊,雷印杰,等.基于改进的遗传算法优化BP神经网络并用于红酒质量等级分类[J].计算机测量与控制,2016,24(1):226-228.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
学苑创造·A版(2020年3期)2020-04-24
电子制作(2019年16期)2019-09-27
中国交通信息化(2019年4期)2019-07-13
电子制作(2018年19期)2018-11-14
电子制作(2018年14期)2018-08-21
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
红领巾·萌芽(2016年2期)2016-09-10
