
基于BIGRU的番茄病虫害问答系统问句分类研究
2018-05-31 03:35:40董翠翠董乔雪
农业机械学报 2018年5期
赵 明 董翠翠 董乔雪 陈 瑛
(中国农业大学信息与电气工程学院, 北京 100083)
0 引言
随着人工智能技术的迅猛发展,智能问答系统因能为人们提供准确的答案和智能化、个性化的信息服务而得到广泛研究。番茄是一种常见的日常蔬菜作物,有着广泛的市场需求。但是,番茄病虫害却是影响番茄品质和产量的重要原因。因此,在农业生产中需要能够快速准确地获取番茄病虫害信息的智能服务和搜索技术,以实现番茄病虫害的有效防治和及时治理。番茄病虫害智能问答系统的构建和应用是实现这一目标的基础,同时也是人工智能和智慧农业[1]发展的必然要求。
问答系统一般包括用户问句分类[2]、问句语义理解[3]和答案抽取[4]3个主要部分。问句分类作为问答系统的关键模块,对系统检索效率具有决定性作用。
目前,国内外对问答系统中问句分类的研究十分关注。大多问句分类方法是基于规则[5]和统计学习的方法,较少利用问句语义信息。
针对番茄病虫害问答系统的特点,问句分类分为病害和虫害两大类,本文利用KNN[6-7]、BIGRU[8]和CNN[9]神经网络方法分别进行番茄病虫害问句分类实验,以选取效果最优的分类模型作为问答系统最终采用的问句分类方法。
1 材料与方法原理
1.1 获取语料
通过Scrapy[10]爬虫框架,抓取番茄病虫害的各种百度百科、互动百科、中文维基百科和农业种植类网站等关于番茄病虫害信息的中文文本语料。参考《中国蔬菜栽培学》书中番茄部分的信息,对网络爬取的语料进行校正和完善。
1.1.1语料预处理
中文分词是中文问句信息处理的基础与关键。本研究采用条件随机场(Conditional random fields, CRF)[11]分词系统进行中文分词。CRF代表了新一代的机器学习分词技术,其基本思路是对汉字进行标注即由字构词,不仅考虑了文字词语出现的频率信息,同时考虑上下文语境,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果。条件随机场并不在每一个节点进行归一化,而是所有特征进行全局归一化,因此可以求得全局的最优值[12]。
番茄病虫害语料复杂多样,有许多农业专用术语和术语别名。综合考虑番茄病虫害语料的特点,结合问句分类的需求,本文构建了一个专门的番茄语料同义词库,可以进行番茄领域病虫害关键词的扩展。几种典型的番茄专业名词和对应的别名信息如表1所示。

表1 典型番茄别名信息Tab.1 Typical tomato alias information
1.1.2问句向量化
自然语言处理任务一般为文本的分布式表示,如矩阵或向量。对问句分类来说,先对用户问句进行分词、去除停用词。由word2vec[13]训练得到问句中每个词的词向量,将词向量对应相加并作平均处理,得到用户问句的空间向量表示。这些向量含有词本身的语法、语义信息。
本研究使用word2vec中的Skip- Gram[14]模型,词向量维度设置为100。以问句“番茄早疫病的原因?”为例,进行分词,然后去除停用词“的”,得到问句为“番茄 早疫病 原因”,经word2vec训练得到问句中各个词的词向量,例如“番茄”的词向量表示如图1所示。
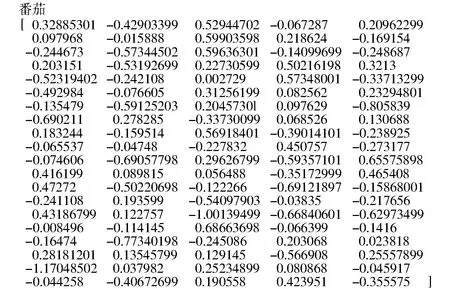
图1 问句词向量示例Fig.1 Examples of question word vectors
1.2 KNN问句分类
KNN算法又称为K最近邻分类(K-nearest neighbor classification)算法。该方法的思路是:如果一个样本在特征空间中的k个最相似即特征空间中最邻近的样本中的大多数属于某一个类别,则该样本也属于这个类别[15]。KNN 算法中,所选择的邻近样本都是已经正确分类的对象。该方法在分类决策上只依据最邻近的一个或者几个样本的类别来决定待分类样本所属的类别。
KNN算法的优点是应用简单,易于理解,易于实现,无需估计算法参数,无需训练,可以快速进行问句分类。算法复杂度低,容易实现。
KNN通过测量不同问句之间的距离进行分类。算法具体步骤如下:
(1)文本预处理。番茄病害问句标签设置为0,番茄虫害问句标签设置为1。
(2)利用word2vec算法表示所有训练问句语料的空间向量和待分类问句的空间向量。
(3)遍历计算待分类问句与训练语料中各个问句的余弦距离。
向量A与向量B之间余弦距离计算公式为
(1)
余弦距离越大,说明问句属于同一类的可能性越大。
(4)对所有余弦距离排序,选出余弦距离最大的k个问句,此处k=6,k值是多次试验选出的最佳取值。
(5)分别统计此k个问句中0和1标签个数。哪个类别标签个数最多,待分类问句即为哪个类别。
1.3 BIGRU问句分类
GRU[16]模型是LSTM[17]模型的简化版,GRU使用“门”结构与LSTM的不同,将LSTM中的输入门和遗忘门合并成了更新门,它只包含2个门结构,重置门和更新门。并且线性自更新不用建立在额外的记忆状态上,而是直接线性累积建立在隐藏状态上,并依靠门结构来调控。重置门决定先前的信息如何结合当前的输入,更新门决定保留多少先前的信息。GRU的“门”结构如图2所示。

图2 GRU门结构Fig.2 GRU gate architecture
图2中x是输入数据,h为GRU单元的输出,r是重置门,z是更新门,r和z共同控制了如何从之前的隐藏状态(ht-1)计算获得新的隐藏状态(ht)。
更新门同时控制当前输入数据xt和先前记忆信息ht-1,输出一个在0到1之间的数值zt,计算公式为
zt=σ(Wz[ht-1,xt]+bz)
(2)
zt决定要以多大程度将ht-1向下一个状态传递,0代表完全舍弃,1代表完全保留,由式(2)可得。式中σ为sigmoid函数,Wz为更新门权重,bz为偏置。
此外,共情的因素也发生一定作用。转移性羞耻的特点是羞耻的行为主体与情绪的体验主体不一致,母亲是羞耻事件的当事人,但自我是实际的羞耻体验者。如果自我需要获得与母亲相似的羞耻体验,亲子间的共情将是必要的桥梁。共情研究发现,共情主体与对象之间的关系是共情发生的重要影响因素(颜志强,苏金龙,苏彦捷,2017)。母亲与子女之间具有天然的血缘关系,并且在重要的价值观上一致。因此,当羞耻体验发生后,对亲社会行为的影响呈现一致性。
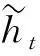
rt=σ(Wr[ht-1,xt]+br)
(3)
(4)
当前时刻的输出为ht,即
(5)
BIGRU模型的基本单元由一个前向传播的GRU单元和一个后向传播的GRU单元组合而成。本研究利用基于word2vec得到的问句词向量训练集来训练2层的BIGRU模型,采用2个BIGRU层和全连接softmax层,对测试问句进行分类。采用2层的模型,可以增加模型的参数,提高模型的学习能力。其中,每层的隐藏状态有2个信息流向,1传输给下一时刻,2要作为当前时刻下一层的输入。图3为2层的BIGRU模型。

图3 2层的BIGRU模型Fig.3 Two layers BIGRU model
BIGRU模型能够在输入和输出序列之间的映射过程中充分利用问句过去和未来的相关信息,其显著的优点是问句分类精度高,对词向量的依赖性小,复杂度低,响应时间比较快。
1.4 CNN模型问句分类
本研究采用卷积神经网络(Convolutional neural networks,CNN)模型从语义层面识别用户问题意图,对用户问句进行分类。自然语言处理任务在利用卷积神经网络时输入的不是像素点,一般为文本的分布式表示,如矩阵或者向量。对于番茄问句来说,先对句子进行分词,而表示句子的矩阵中的每一行代表句子中的一个词,即每行表示的是一个词的向量。可以利用word2vec学习到这些词的空间向量,这些向量含有词本身的语法、语义信息。利用100维的词向量表示一句含有8个词的句子时,则会得到一个8×100维的矩阵,将此矩阵作为卷积神经网络的输入,相当于一幅图像的像素矩阵输入。
本文所用卷积神经网络结构如图4所示,利用该网络模型将用户所提出的问题分类,本研究分为两类,即番茄病害问题和番茄虫害问题。采用的卷积神经网络模型包括5层:输入层、卷积层、下采样层、隐含层、输出层。首先利用word2vec将句子表示为具有语法和语义信息的向量矩阵,作为卷积神经网络的初始输入[18],为了尽可能提取问句特征,本文设定两种卷积核,卷积层滤波器采用2种大小不同的滑动窗口4×100和5×100,每种窗口有128个卷积核,一共有256个。在图像处理领域,滤波器与图像的局部区域进行感知,而处理自然语言时滤波器覆盖句子中的几行,所以滤波器和输入的向量矩阵宽度相等,即滤波器的宽度也是100。
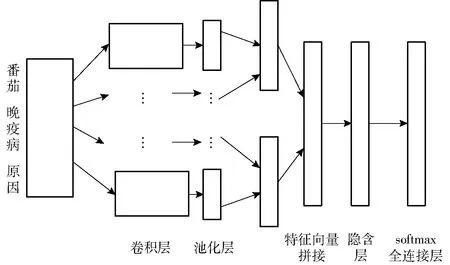
图4 卷积神经网络结构Fig.4 Structure of convolutional neural network
f(x)=max(0,x)
(6)
采用max-pooling找到特征图中最大的影响因素作为该局部的特征。下采样层有减少模型参数数量和减小模型训练参数的复杂度的作用。经过max-pooling操作提取的局部特征输入下一层隐藏层,最后经过softmax全连接层,进行分类。文本要进行的二分类问题,则输出层仅有一个神经元。利用softmax函数计算每个类别的概率公式为
(7)
CNN神经网络的优点是共享卷积核,对高维数据处理无压力,无需手动选取特征。训练好权重,即得特征,分类效果好,但是CNN网络需要调节参数,对处理大样本的数据分类效果较好。
2 问句分类实验
2.1 问句分类实验设计
本研究爬取收集番茄问句同时进行问句扩展,将番茄病害问句标注标签为0,番茄虫害问句标签标注为1,一共得到有2 000条样本。利用梯度下降算法[19]训练优化双向GRU模型和卷积神经网络模型,本文采用mini-batch梯度下降算法[20],每次选择n个小批量样本参与训练,n小于总的训练集样本数量,进行n次迭代,每次只使用一个样本,最终对n次迭代得到的梯度加权平均再求和,作为本次mini-bath的下降度。mini-batch梯度下降法一方面保证尽可能得到最优解,另一方面能够加快收敛速度。
本研究采用的batch大小为50。为了防止神经网络模型在训练过程中出现过拟合现象,本文定dropout参数[21]大小为0.5。为了增强模型的鲁棒性,使2种神经网络模型从语料中学习更多的信息,学习更准确的网络参数,并避免陷入局部最小值,本研究采用交叉验证[22]的方法,将数据集随机分成10份,其中9份作为训练集,另外1份作为测试集。
实验中利用word2vec表示句子中词的向量,而句子被表示为包含多个向量的矩阵,作为神经网络模型的初始输入,词向量在模型训练过程中不断学习更新。神经网络模型连接一个softmax全连接层,将该问句分为番茄病害类或者番茄虫害类。
采用准确率、召回率以及F1值[23]作为问句分类算法模型的测评指标。准确率和召回率经常用来度量信息搜索效率和统计学分类效果。此处问句分类准确率是指被正确分为某一类的样本数与全部被分为该类别的样本数量之比;召回率是指被正确分为某一类的样本数量与样本中全部属于该类别的数量之比。准确率与召回率在0和1之间,其值越接近1,表示准确率或者召回率越大。
准确率和召回率在某些情况下是矛盾的,当要求准确率非常高时,系统的召回率可能就会降低,当要求召回率非常高时,准确率有可能会降低,则需要一个综合评测指标,常用的方法是F1值。F1值是准确率和召回率的调和平均值,其公式为
(8)
式中P——准确率R——召回率
2.2 问句分类实验结果及分析
番茄病虫害问答系统问句分类采用word2vec表示句子向量,并利用KNN算法、BIGRU模型和卷积神经网络模型进行分类,其分类结果如表2所示。

表2 基于不同分类算法的问句分类结果Tab.2 Question classification results based on differentclassification algorithms %
由表2可知,BIGRU模型在番茄病害类和番茄虫害类的分类准确率、召回率都比基于CNN神经网络和基于KNN算法的结果高几个百分点。从综合评价指标来讲,在番茄病害类方面,采用BIGRU神经网络模型进行问句分类,其F1为91.82%,比利用CNN神经网络高2.25个百分点,比KNN算法高5.22个百分点;在番茄虫害类,采用BIGRU神经网络模型进行问句分类,其F1为92.48%,比利用CNN神经网络模型高2.57个百分点,比利用KNN高5.57个百分点。
基于BIGRU模型的问句分类效果最优,CNN模型居中,KNN算法结果稍差。相对于KNN算法模型,BIGRU模型和CNN神经网络不需要手动提取特征,自动学习复杂特征的能力强大,并且效率较高。BIGRU模型的优势在于,从左到右推进模型做一次GRU,然后从右向左推进模型做一次GRU, 充分利用了句子分词后的前后位置信息。而且,BIRRU模型结构简单,模型训练参数较少,模型训练速度快,符合问答系统对响应时间的要求。
应用BIGRU模型进行番茄病虫害问句分类,正确预测的几种典型问句及对应的分类标签和结果如表3所示,其中标签0代表番茄病害,标签1代表番茄虫害。

表3 番茄问句分类举例Tab.3 Examples of tomato question classification
其次,是针对番茄智能问答系统问句分类效果最优的BIGRU神经网络模型,对影响问句分类的数据样本大小也进行了测试,将数据样本分别设置为500、1 000、1 500再进行测试,测试结果如表4所示。
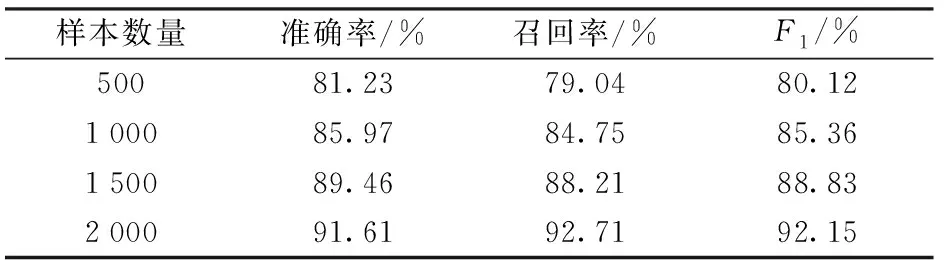
表4 不同数据集的BIGRU模型Tab.4 BIGRU model with different datasets
由表4可得,训练数据的大小对模型的效果有较大影响,番茄智能问答系统作为一个实用性系统,对准确率有较高的系统需求。而问句分类作为其关键环节,在对选定的模型进行训练时,要求训练数据尽可能的覆盖全面,从而可以提高整个系统的准确率。
最后,绘制了不同数据集下3种模型的F1实验结果,如图5所示。
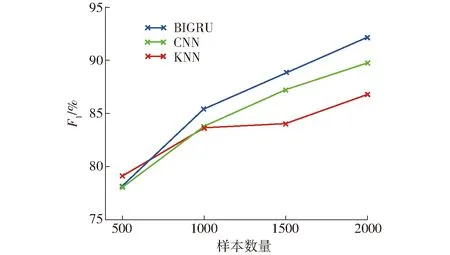
图5 不同数据集测试结果Fig.5 Test results for different datasets
由图5可得,当数据集较小时,KNN算法模型的效果比其他2种神经网络模型的F1高,随着数据集的增大,BIGRU模型和CNN模型的F1明显升高。神经网络模型参数的迭代学习需要较大数据集的支持,神经网络不需要手动提取特征,自动学习复杂特征的能力强大,并且效率较高。验证了BIGRU模型作为番茄病虫害智能问答系统问句分类模型的有效性。
3 结论
(1)针对番茄智能问答系统的特点,利用word2vec表示用户问句向量,有效地提取用户问句中语义信息,构建了基于BIGRU神经网络的番茄智能问答系统问句分类模型,有利于提高问答系统准确度,且此模型响应时间最快,符合问答系统对响应时间的要求。
(2)对比了CNN神经网络和KNN算法,结果表明BIGRU模型的准确率、召回率、F1优于其他两种问句分类算法。
(3)利用不同大小数据集对3种模型进行测试,结果表明随着数据集增大,BIGRU神经网络模型F1明显上升。番茄病虫害问答系统问句分类的效果不仅取决于问句分类算法的选择,模型训练数据集的大小也有较大影响。
1 李道亮,杨昊.农业物联网技术研究进展与发展趋势分析[J/OL].农业机械学报,2018,49(1):1-20.http:∥www.j-csam.org/jcsam/ch/reader/view_abstract.aspx?flag=1&file_no=20180101&journal_id=jcsam. DOI:10.6041/j.issn.1000-1298.2018.01.001.
LI Daoliang, YANG Hao. State-of-the-art review for internet of things in agriculture[J/OL]. Transactions of the Chinese Society for Agricultural Machinery, 2018, 49(1):1-20. (in Chinese)
2 郭海红, 李姣, 代涛. 中文健康问句分类与语料构建[J]. 情报工程, 2016, 2(6):39-49.
GUO Haihong, LI Jiao, DAI Tao. Classification of Chinese health question and construction of corpus[J]. Technology Intelligence Engineering, 2016, 2(6):39-49.(in Chinese)
3 范士喜, 韩喜双, 相洋,等. 基于HM- SVMs的问句语义分析模型[J]. 计算机应用与软件, 2016, 33(5):84-86.
FAN Shixi, HAN Xishuang, XIANG Yang, et al. A question semantic analysis model based on HM- SVMs[J]. Computer Applications and Software, 2016, 33(5):84-86.(in Chinese)
4 AHMED W, ANTO B. Answer extraction techniquefor question answering systems[J]. International Journal of Innovative Research in Computer and Communication Engineering,2016, 4(11):20352-20357.
5 TIAN W D, GAO Y Y, ZU Yongliang. Question classification based on self-learning rules and modified bayes[J]. Application Research of Computers, 2010, 27(8):2869-2871.
6 ZHANG S, LI X, ZONG M, et al. Learning k for kNN classification[J]. ACM Transactions on Intelligent Systems & Technology, 2017, 8(3):43-1-43-19.
7 魏芳芳, 段青玲, 肖晓琰,等. 基于支持向量机的中文农业文本分类技术研究[J/OL]. 农业机械学报, 2015,46(增刊):174-179. http:∥www.j-csam.org/jcsam/ch/reader/view_abstract.aspx?flag=1&file_no=2015S029&journal_id=jcsam. DOI:10.6041/j.issn.1000-1298.2015.S0.029.
WEI Fangfang, DUAN Qingling, XIAO Xiaoyan, et al. Classification technique of Chinese agricultural text information based on SVM[J/OL]. Transations of the Chinese Society for Agricultural Machinery, 2015, 46(Supp.):174-179.(in Chinese)
8 JABREEL M, MORENO A. Target-dependent sentiment analysis of tweets using a bi-directional gated recurrent unit[C]∥International Conference on Web Information Systems and Technologies, 2017.
9 高震宇, 王安, 刘勇,等. 基于卷积神经网络的鲜茶叶智能分选系统研究[J/OL]. 农业机械学报, 2017, 48(7):53-58.http:∥www.j-csam.org/jcsam/ch/reader/view_abstract.aspx?flag=1&file_no=20170707&journal_id=jcsam.DOI:10.6041/j.issn.1000-1298.2017.07.007.
GAO Zhenyu,WANG An,LIU Yong, et al.Intelligent fresh-tea-leaves sorting system research based on convolution neural network[J/OL].Transactions of the Chinese Society for Agricultural Machinery,2017,48(7):53-58.(in Chinese)
10 WANG J, GUO Y. Scrapy-based crawling and user-behavior characteristics analysis on taobao[C]∥International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery. IEEE Computer Society, 2012:44-52.
11 方艳, 周国栋. 基于层叠CRF模型的词结构分析[J]. 中文信息学报, 2015, 29(4):1-7.
FANG Yan, ZHOU Guodong. Analysis of word structure based on cascaded CRF model[J]. Journal of Chinese Information Processing, 2015, 29(4):1-7.(in Chinese)
12 陈飞, 刘奕群, 魏超,等. 基于条件随机场方法的开放领域新词发现[J]. 软件学报, 2013, 24(5):1051-1060.
CHEN Fei, LIU Yiqun, WEI Chao, et al. New word discovery in open domain based on conditional random field method[J]. Journal of Software, 2013, 24 (5):1051-1060.(in Chinese)
13 GOLDBERG Y, LEVY O. word2vec explained: deriving Mikolov et al. ’s negative-sampling word-embedding method[J/OL]. Eprint ArXiv, 2014.ArXiv: 1402.3722.
14 KILLIAN J, MORCHID M, DUFOUR R, et al. A log-linear weighting approach in the word2vec space for spoken language understanding[C]∥Spoken Language Technology Workshop. IEEE, 2017:356-361.
15 刘雨康, 张正阳, 陈琳琳,等. 基于KNN算法的改进的一对多SVM多分类器[J]. 计算机工程与应用, 2015, 51(24):126-131.
LIU Yukang, ZHANG Zhengyang, CHEN Linlin, et al. Improved one to many SVM multi classifiers based on KNN algorithm[J]. Computer Engineering and Application,2015, 51(24):126-131.(in Chinese)
16 TANG Y, HUANG Y, WU Z, et al. Question detection from acoustic features using recurrent neural network with gated recurrent unit[C]∥IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2016:6125-6129.
17 WEN T H, GASIC M, MRKSIC N, et al. Semantically conditioned LSTM-based natural language generation for spoken dialogue systems[J]. Computer Science, 2015:1-13.
18 GORDEEV D. Detecting state of aggression in sentences using CNN[M]. Speech and Computer, Springer International Publishing, 2016.
19 毛勇华, 桂小林, 李前,等. 深度学习应用技术研究[J]. 计算机应用研究, 2016, 33(11):3201-3205.
MAO Yonghua, GUI Xiaolin, LI Qian, et al. Deep learning application technology[J].Application Research of Computers, 2016, 33(11):3201-3205.(in Chinese)
20 ARAB A, ALFI A. An adaptive gradient descent-based local search in memetic algorithm applied to optimal controller design[J]. Information Sciences, 2015, 299:117-142.
21 SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting[J]. Journal of Machine Learning Research, 2014, 15(1):1929-1958.
22 边耐政, 李硕, 陈楚才. 加权交叉验证神经网络在水质预测中的应用[J]. 计算机工程与应用, 2015, 51(21):255-258.
BIAN Naizheng, LI Shuo, CHEN Chucai. Application of weighted cross validation neural network in water quality prediction[J]. Computer Engineering and Applications, 2015, 51(21):255-258.(in Chinese)
23 POWERS D M W. Evaluation: from precision, recall and f-factor to ROC, informedness, markedness & correlation[J]. Journal of Machine Learning Technologies, 2011, 2:2229-3981.
猜你喜欢
小猕猴学习画刊(2022年12期)2022-02-06 03:00:52
今日农业(2021年21期)2022-01-12 06:31:52
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
今日农业(2020年23期)2020-12-15 03:48:26
中国交通信息化(2018年5期)2018-08-21 03:37:40
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
