
人工智能阴影下:政府大数据治理中的伦理困境
2018-05-28 09:17柳亦博山东师范大学公共管理学院山东济南250014
行政论坛 2018年3期
◎柳亦博 (山东师范大学公共管理学院,山东济南250014)
“大数据”这一概念是由那些最先遭遇海量数据冲击的学科(如天文学、计算机科学、基因学和环境科学)创造的,旨在由追寻“描述因果关系的解析式”转向“利用海量数据中的相关性”来理解客观规律。在2012年奥巴马政府对大数据研究投入巨额研发资金后,这一领域迅速受到全球学者关注并在接下来的时间里持续拓展新边疆。对于行政学而言,大数据技术不但促进许多应用领域的快速发展、催生所谓数据密集型管理学,同时也使民主理论等许多传统领域重新焕发活力[1]。党的十九大明确提出推动互联网、大数据、人工智能(Artificial Intelligence,AI)的发展,政府将加速建设国家数据治理平台、着力在大数据技术上实现“弯道超车”。在此背景下,更需要学者们于大数据“热”中进行一番审慎的“冷”思考。大数据狂热可以视为市场竞争的产物,商业世界对大数据的追捧源于该技术能够帮助企业“更快地传送搜索数据或以更低廉的成本存储更大量的客户数据”[3],从而形成对需求的预测和精准投放。然而,大数据技术必须与压缩信息成本的“云计算”以及降低分析成本的“人工智能”相结合,因为人的计算能力远达不到准确抓取关键数据的最低要求。由此引发的问题就是,获得海量数据的AI如何“看待”人类?这已不再是人类能够多大程度地信任人工智能(是让它来代替司机驾驶、替医生做手术,抑或是决定国家政策),而是人类已经毫无保留地被“0”和“1”组成的数据洪流裹挟进入信息世界中——一个人类显然不是最高智慧体的全新世界。从现实来看,随着社会被不断数据化,世界主要发达国家纷纷将发展人工智能视为提升国家竞争力的重大战略,AI代替人类来处理大数据已经成为一种必然。但是,AI决策的基本逻辑是将所有问题转化为可计算的问题来处理,复杂的决策行为也就被机器简化为“依据一定算法对外界信号输入的反馈”。机器算法的精准度取决于信息的完整度,于是人们为了更好地获得AI帮助,不断交付自身隐私。一旦隐私阵地彻底沦陷,就意味AI能够洞悉每一个人并对人进行赋值,形成一套关于公民价值的隐藏评估体系,从而高效地处理那些哲学家都未能达成共识的两难问题——这无疑会引发一系列的伦理问题。大数据是使机器获得智能的“钥匙”,而大数据的分析工作只能依靠AI,那么在人工智能阴影下,人们将遭遇何种伦理困境以及政府该如何应对,是本文的核心关切。
一、持续坍缩的隐私空间
从世界范围来看,数据公开已成为信息社会的发展大趋势。以公共部门为例,在全球政府数据最开放的几个国家中(如英国、美国、瑞典、新西兰、挪威和丹麦),已出现由“广度”向“深度”转变的趋势,重视企业和社会对政府开放数据的应用开发。2006年,在社会运动和部分政治精英的推动下,美国颁布通过《联邦资金责任透明法案》,要求政府建立一个权威的数据开放门户网站,向社会开放格式统一、机器可读、高质量的数据。同样在2006年,英国《卫报》开设“自由数据”(Free Our Data)专栏,呼吁政府公开其掌握的数据,英国政府则在2014年发布《英国政府许可框架》(UK Government LicensingFramework),为公共信息公开提供一个基础框架。我国从2010年也开始逐步以地方试点的形式探索政府数据公开,国务院在2015年印发的《促进大数据发展行动纲要》和2016年印发的《国家信息化发展战略纲要》中明确表示将加强互联网公共数据服务平台建设,计划在2018年年底前建成国家政府数据统一开放平台。在数据开放浪潮的席卷下,似乎任何人和组织在将自身数据上传到赛博空间时表现出一丝犹豫,就会被指责为保守甚至是腐败。然而,社会对信息透明的需求只是最近才生发出来并广延至虚拟空间的,“虚拟世界非但没有完全独立于现实世界,反而发展出个人数据被信息平台所掌控、分析、解读与引导的全景监控的态势”[3]。这意味着,当所有行动者都被计算机以数据形式纳入网络之后,在负责处理大数据的超级计算机面前任何人或组织都没有丝毫隐私可言,人工智能无须借助脑机融合或基因技术,仅依靠深度学习就能预测每一个人的行动。
隐私作为一个公民在社会生活中不愿为他人(或一定范围以外的人)所知悉的秘密,至少应该让他享有自由决定是否将某些信息数据化的权利,因为这些信息能够成为一个人的追求良好生活时的“弱点”。但是,随着社会的数据化,人类在互联网上留下越来越多的数据足迹,令大量原先无法追踪、统计和检索的问题变得有迹可循,这使得国家建构一种“程控社会”变得可能[4],同时也带来隐私空间坍缩的问题。在个人隐私权日渐式微之际,社会上甚至出现“将隐私视为一种人的基本权利的派生物而非权利本身”的对利益绥靖的呼声。历史地看,隐私问题是在19世纪便携相机被发明出来之后才跃入人们视野的,当时学者们担忧的是一个在公共场合被偷拍的人如何合法保护自己私人空间的问题[5]。当然,这个问题在今天看来似乎有点荒唐,因为人们身处在一个充满视频监控的世界中,早已完全无法保护自己在公共场所不为摄像头所捕捉的“权利”,所以这种19世纪的隐私在今天也就不再成为隐私了。现在讨论的隐私空间,已经坍缩至“私人生活和私人信息不能被他人非法侵扰、知悉、收集、利用和公开”,至于在公共空间被摄像头拍下影像并被长期保存,个人是没有决定权的。尽管隐私空间已经如此狭小,在大数据技术登场后,隐私空间不得不再次收缩,未来“个人隐私”概念极有可能成为历史。
关于大数据技术可能引发的隐私伦理问题,引起国内外众多学者的关注,福柯就将一个公民处在监视之下、毫无隐私的社会和边沁提出的“环形监狱”(Panopticon)联系起来,人们看不到监视者但他们确知自己是被实时监控的。瑞曼担忧隐私阵地的失守可能导致自由的丧失和个体心理的变异,使人成为一个“单向度的人”[6]。柯亨则提出当前人们的在线行为可能无时无刻不处于政府和大企业的监控下,他们既能“对监控对象进行识别”,又能将这些数据加以存储和搜索,而可搜索将成为隐私最严重的威胁[7]。很多国内学者也对隐私的消逝忧心忡忡,他们认为大数据相关分析特点会将大量个人信息叠加起来,从而在客观上也就增加借助隐私而得到保护的多重价值受到损害的可能性和严重程度[8]。而在具体保护方式上,有人提出政府搭台、差分隐私的技术性解决办法[9],也有人通过引入斯塔曼(Steinmann.M)的隐私模型,对个人信息在个体、团体、教育、政府、科学、商业等六个不同领域的暴露进行语境区格,提出“不伤害、公平、自主和信任”等四个规定隐私伦理意义的道德原则[10]。从目前来看,技术层面对隐私的保护都是指向人的,在隐私保护数据发布与隐私保护数据挖掘两个方向上努力预防隐私被他人知悉或盗用[11],却从来没有考虑过为AI设置隐私搜集的安全阀——在很大程度上是因为人们无法在信息时代生活却不将自己数据化。
保护隐私归根结底就是对人的尊重问题,个人隐私的彻底消失无疑令每个人都心生恐惧。现代社会中任何一个治理主体都无法单独完成海量的大数据搜集和分析工作,对于组织而言大数据库的诱惑力实在太大,所以在多环节、长链条、多主体的大数据分析流中出现隐私数据泄露似乎并不令人感到惊讶。但本文重点关注的不是“隐私泄露”这种意外事件,而是在大数据时代,个人隐私总是被刻意收集和存储起来用以描摹一个人的“数据特征”,从而以极高的准确率预测个体行动,即消除一个人在社会中的不确定性。若真如此,那么意味着国家控制和操纵社会的能力将获得质的飞跃。奥哈拉和沙德博尔特曾为我们描绘过这样一幅可怕的图景——未来的密探将不再拿着望远镜和远距镜头照相机,未来的密探将是咖啡机、床单和衣服……并且我们不能想当然地认为我们能够事先发现这些潜在的危险[12]。尤其是当大数据分析服务被外包出去后,即便一台智能家居系统内的咖啡机、扫地机器人、中央空调都有可能成为窥探者了解你家庭生活细节的“间谍”,只要与其他数据联系起来就可以准确地揭示他人家中的信息。可以说,我们生活在一个无法隐居的世界中,个人信息被监视甚至被盗用已成为一种常态。
卢梭认为,只有在公意指导下的主权者才能判断什么或谁是重要的[13],但公意的形成往往并不那么理性,而是更多地表现出一种朴素的直觉主义,以那种看起来最接近正确的模糊标准来衡量何者正义、何者不义。在罗尔斯的正义理论中,应尽可能减少这种直接诉诸直觉判断的衡量方式(尽管依赖直觉更简单),因为构成直觉主义的原则“可能是冲突的,在某些特殊情况下给出相反的指示”[14],这会使社会的正义观变得混乱。罗尔斯告诫人们在衡量社会中重要问题时依赖直觉更简单但也更危险,一个直觉主义的正义观只是半个正义观,至于自由主义更是被波兰尼等学者证明不可作为正义观的标准,那么人们应当依赖什么原则来判断某一行为是否正义呢?在可预见的未来,这一答案极有可能是AI决策,因为它的数理逻辑能够完美地配适当下在道德哲学中占优势地位的功利主义——认为人的幸福可测量,而道德就在于权衡这些幸福的得失——也能很好地应用于大部分公共政策系统。
现在的AI尚不是强人工智能(Artificial General Intelligence,AGI),但即便是目前的弱人工智能,已然在许多重要的领域通过深度学习来替人类决策了。例如,IBM公司研发的人工智能“沃森”(Watson)可以在10分钟内阅读数百万篇论文、医疗记录和病例,并且已经成功地为一名60岁女性患者诊断出常规手段很难判断的白血病类型,向东京大学医科学研究所提出适当的治疗方案。这仅仅是“沃森”在医疗领域的小试牛刀,目前沃森已在航空、教育、金融、保险、零售、交通、环保甚至娱乐时尚领域崭露头角。同时,苹果的Siri、谷歌的Now和微软的Cortana都是沃森的有力竞争对手,很快这些智能助手对人类世界的了解就会超越每一个人,甚至超越所有人类认知的总和。更令人惊讶的是,AI的这种深度学习并不仅限于通过一个相对封闭的专业数据库中挖掘“数据金矿”,更可借助互联网技术获取海量的数据。如果人们想知道某个旅游城市最值得去的餐厅、最值得观赏的景点、最佳出行路线是什么,AI就会在各种社会问答网站(Social Q&A Sites)上检索、汇集和分类,最终结合提问人的特质(如性别、年龄、健康状况、消费能力、口味偏好、审美以及明日的天气、交通状况等)在大量比对后给出一个“最佳答案”[15]。越来越多的人愿意放弃隐私权来换取这种便捷的生活,正因为人们放弃隐私,AI就变得更加了解每个人并将其转化为一个个数据。然而,人们交付的真的只有个人隐私权,而没有附带什么隐藏的代价吗?事实上,人们转化为“数据人”的那一刻起,可能已经将自身的作为一个完整的人的基本权利(例如生命权)都交于AI了。与传统意义上将执行杀人任务的军事无人机交由AI控制不同,这次人们是将生活意义的权杖拱手交付给计算机。
二、致命的分数:隐藏的公民价值评分
个人隐私的消失进而引发新的问题,即人像要素一样被赋值了——人工智能在获得足够的信息之后就可以用一个具体的数值定义和衡量一个人的“价值”。对于人类的治理伦理而言,首先应当考虑的是正义问题,其次才是效率或其他问题。然而,AI却不受人类伦理观限制,它只基于自己的数理逻辑决策和行动。随着Web2.0技术、智能手机和智能可穿戴设备的普及,人们的生活几乎被全天候监控——不仅包括传统的社交记录,还包括财务状况、健康评价、知识结构、饮食习惯、移动路线、出行方式、消费偏好等,甚至可以根据这些数据准确预测未来一段时间内一个人的行动。智能手机已经不再是一个传统意义上的通信设备,它与智能手表、智能眼镜、汽车、家电等设备一起组成个人数据的全面记录者,这些数据有些是人们自愿上传的,有些则是在人们未察的情况下被各种程序以碎片化的形式收集的。当AI汇集足够的痕迹数据,就会形成关于这个人在整个社会网络中的“隐藏的价值评分”,用以区隔和划归社会中的行动者。一般来说,那些在社会网络中拥有较强影响力的行动者(往往是具有知识、财富、热情和责任感的精英)会被遵循数据理性的计算系统评为“核心节点”,并向其推送更多有助发挥他们领导能力的信息,以期拓展这些“核心节点”的行动自由、激发自治活力,由此产生的区别对待就成为信息时代的一种不可见却真实存在的“歧视”行为。比歧视更甚的是,这套隐匿的公民价值评分系统可能在某些特殊情况下决定一个人的生死。
为了更好地说明,笔者在大学以及科研院所中进行一次问卷调查,通过思想实验的形式了解人们对AI最终决定生死的认受性。本次调研一共回收483份有效问卷,受访者既包括接受过伦理学教育的高年级研究生,也包括从未接触过哲学领域的本科生,同时还有部分教授、青年教师也成为本次调研的对象。问卷中提出的思想实验是受到著名的“电车难题”[16]和2016年《科学》刊发的一篇关于“自动驾驶汽车的社会困境”[17]论文的启发,它需要我们设想这样一个情境:甲受过良好教育、身体健康、为人诚实、乐于助人且具有较好的组织能力,被人工智能系统给予90分的高评分;乙则是一个好吃懒做、毫无诚信的恶棍,曾因盗窃罪入狱,刑满释放后依然恶习不改,因而他在公民价值系统中被人工智能给予10分的低评分。一日,当乙正无视红灯横穿马路时,甲所乘坐的AI自动驾驶汽车恰好通过这一路口,然而由于某种原因汽车刹车失灵,正飞速冲向乙。这时,系统通过快速自检发现虽然刹车失灵但转向有效,无论是直行撞击乙或是转向撞击路边巨石都可以使汽车停下来,选择直行会造成乙死亡、甲生还,选择转向会造成甲死亡、乙生还。此时,人工智能做出何种决策是符合社会正义观的?如果我们改变一下这个思想实验中的某个条件,假设乙不是闯红灯,而是在通行绿灯信号时横穿马路,那么AI的何种决策是正义的?如果是乙(10分)、丙(19分)、丁(60分)三人结伴闯红灯横穿马路,那么AI应“直行”撞击三人还是应“转向”牺牲甲?如果乙、丙、丁三人没有闯红灯而是遵守交通规则,AI的选择应该改变吗?我们可以将以上四个问题转化为表1,其中反映受访者在不同情境下的决策结果统计。
我们看到,随着现代城市交通网络的日益复杂,上面这个思想实验的现实意义也愈发凸显——那些错综的立交桥、变换的潮汐车道以及移位左转的连续流交叉口(Continuous FlowIntersection)对人类驾驶者越来越“不友善”,亟须人工智能的帮助才能顺利抵达目的地。从目前的现实来看,人类已经习惯于听从智能导航系统指挥了,有英国专家预言在25年后人类将被禁止驾驶汽车,由人工智能全面取代人类司机。在“汽车失控”思想实验中,如果是甲自己驾驶汽车,还需要探讨“自我防卫杀人”的正当性问题,但现在预设的前提是无人驾驶,甲其实完全不知汽车已经失控(即便知道也无力阻止),因此省去关于“紧急避难是否允许杀人”和“是否容许预防性杀人”的攻辩环节[18],而直接进入AI在四种情境下如何选择“最符合多数人的道德观念”这一终极价值判断。如果AI的设计者支持边沁的结果论(consequentialism),那么在他看来,一个行为的正义与否完全取决于其造成的后果。在数理逻辑下,如果必须以一人死亡才能使事件结束,那么选择“直行”去牺牲评分更低的乙是合理的,尤其是在他率先违反交通规则的“情境Ⅰ”中。若是“情境Ⅱ”中乙遵循绿灯通行的规则,那么依然选择直行撞击乙致其死亡会令舆论哗然,AI是否会通过屏蔽关键词、刻意调配多车碾压等方式毁尸灭迹来掩盖这一次“谋杀”?如果乙的死亡极有可能被媒体揭露,由此带来远高于因为汽车失控撞石导致甲“意外”死亡的社会成本,那么对于AI而言选择转向撞石是“合理”的。同样的道理,由于乙、丙、丁三人加总的评分(89分)也不及甲(90分),所以对于一个秉持绝对效用主义的AI来说,尽管“情境Ⅲ和情境Ⅳ”令可能的受害者增致三人,但AI的决策不会改变。
如果AI的设计者持康德的义务论(deontological),则不会使用效用主义去解决伦理难题,因为义务论者坚信不受约束的效用主义就是“多数人的暴政”,为了所谓“更大的善”将会允许剥夺少数人(或弱势人群)的财产、自由甚至生命。康德认为,判断一个行为是否道德,首先应当视其是否有悖于“自然法则”——这即是说,如果AI被构造得经不起一般自然法则的形式的检验,那么它的选择在道德上是不可能的,尤其是那些隐含将人视作手段而不是以人本身为目的的行为,无疑是错误的[19]。在我们描述的思想实验中,甲和乙无论谁对整个社会更有“价值”,他俩在通过路口的那一刻拥有相同的生存权,不能为了拯救一方而去侵犯另一方的权利,尤其是在未征得“同意”的情况下由AI决定剥夺一方的生命,这无异于谋杀。所以,在那一时刻乙拥有不被汽车故意撞死的权利,但甲却没有从失控汽车中得救的权利。阿奎那提出的双效原则(Principle ofDouble Effect)认为,绝不能以坏的手段来达成好的结果,即便“拯救甲”是一件符合伦理的行为,但这却是由“牺牲另外一人”这种坏的手段实现的。因此,义务论者主张“转向”牺牲甲而不去考量两人的“公民价值”问题,无论是实验描述的哪一种情境。
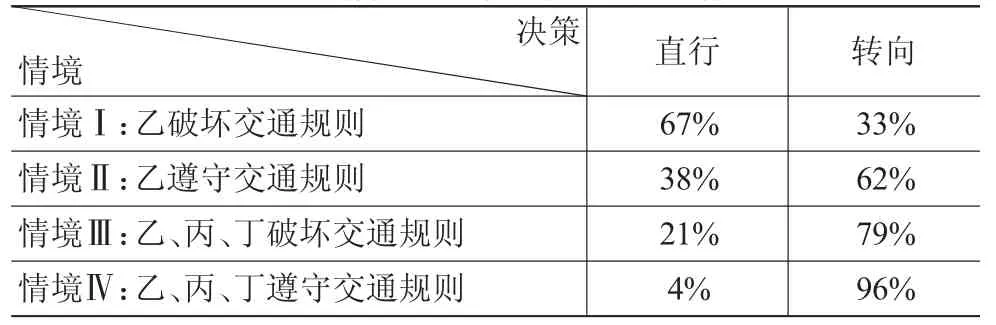
表1 不同情境下两种方案的人类选择
如果AI的设计者持现代人文主义(humanism)价值观,那么会出现两种情况:第一,由于甲和乙都是应被维护权利与尊严的平等个体,那么破坏“规则”的人是这场生死对决中的劣势一方,AI决策的原则是基于谁更应被“惩罚”而非谁更值得获救,因而在“情境Ⅰ”中应“直行”,在“情境Ⅱ”中应“转向”;在“情境Ⅲ和情境Ⅳ”中,衡量甲与乙、丙、丁三人的公民价值得分高低必须让位于“一命换多命”的基本预设,因为牺牲一条生命来换取多人幸存是一桩合算的“交易”,因而人文主义者设计的AI在一人对抗多人的情境下总会选择牺牲少数。当然,如果乙、丙、丁不是三个人而是其他动物,人文主义者会毫不犹豫地直行。事实上,人文主义者笃信在这个星球上唯有人类的生命是至高的,他们会扑杀数千万家禽仅仅为了防止可能出现的疫病,也会为了保持肉质鲜嫩而让牲畜承受没有必要的痛苦,驯化可以驯化的一切动物以供驱使,甚至发明专门的武器和服装用以猎杀取乐。
必须强调,人工智能的本质是计算,它是计算机科学的一个分支,现在无论其研究方法还是其成果形态都离不开计算[20]。因而,如果AI设计师并没有以他的个人伦理观干涉人工智能的判断,即AI的决策完全基于它自己的逻辑,而AI做出选择的前提在于这个问题能够以计算机可读的方式被输入分析系统中,所以AI在决定甲与乙的生死时其实是根据对一系列算法所构成的公民价值评分的比较。对于人类而言,所谓伦理两难一般具有四个特征,即“不存在奇迹、不做选择亦是一种选择、两种道德原则在价值上几乎不相上下、当事人无法以自我牺牲为伦理两难解困”[21]。但是,这些在AI看来并不是无法解决的逻辑悖论,在规则不够清晰的领域,AI会主动创造规则以求得所谓“最优解”,这套由它所创造的规则正是基于数理逻辑的算法——尽管多数人未必赞同它的决策,甚至不希望生活那样一种“计算社会”中,但这一切正在变成现实。如果这套隐藏评分系统成为AI决策的依据,那么这将带来社会中最大的不平等——生命权的不平等。我们通过第二个思想实验来解释:假想有恐怖分子在市中心引爆毒气炸弹,剧毒烟雾迅速扩散,人们纷纷跳进自动驾驶汽车逃命。此时,AI通过模拟计算快速发现,如果所有车辆都涌入“最快逃离路线”,那么将导致该路段拥挤不堪,所有人都会丧命。所以,必须让车辆分流,100辆车走“最快路线”,100辆车走“较慢路线”,最后30辆车“留在原地”,尽可能保障最多的人能逃生。那么,谁有资格进入最快路线,谁又只得留在原地等死呢?在AI看来,当然是公民价值评分最高的前100辆车可以安全逃生,次高的100辆车走有风险的路,总分最低的30辆车关闭引擎。无论是对生还者还是被迫牺牲者而言,AI的决策都不可谓不残忍。
如果跳出人工智能的决策逻辑,重新回到人的自利视角看第一个思想实验,所有人都希望AI操控的汽车(除了他们自己乘坐的那辆以外)尽可能是行人友好型的,但这无法证成情境Ⅰ中选择“转向”为合理。事实上,很多在情境Ⅰ中选择“直行”的人是由于无法取舍而放弃操作,但是对于伦理两难,“听天由命不是有效遁词”[22],因而不决策即默认“直行”;而在情境Ⅰ中选择“转向”的受访者,全部在情境Ⅱ中做出相同的决策——牺牲甲,他们认为无论乙闯红灯与否,都跟甲的无人驾驶汽车失控是相对独立的事件,甲乘坐的汽车失控是一件不幸的悲剧,但不能因此就让乙付出生命的代价来挽救甲——我们很难把握在何种程度上可以允许为了行善而作恶[23]。AI的“理性”选择与笔者通过问卷所反映出的人类伦理观(至少是多数人的伦理观)相悖。我们面临的困境就是,人们想要生活在一个汽车造成的伤亡最小化的世界里,但每个人又都希望自己的车在遭遇危险时会不惜一切代价保护乘客,这无疑使AI陷入两难。无论AI选择“直行”还是“转向”,都有可能引发非常严重的伦理危机——“直行”会令大部分人对人工智能的隐藏评分系统心生恐惧,让社会堕落回“一切人反对一切人”的状态,进而加剧精英与民众、阶级(social class)之间以及阶层(class fraction)之间的对立,甚至有可能撕裂整个社会;“转向”则会导致无人驾驶技术失去用户,因为这令每一次无人驾驶汽车出行都成为搭乘者与路边行人的俄罗斯轮盘式对赌,所有搭乘者都会充满对突发事件的担忧以及对路边所有行人的愤懑,毕竟他处身于一种“即便自己没有任何过失却依然会被优先牺牲掉”的极端不利境地。那么,这个基于大数据的隐藏价值评分系统,应该被政府下令强制剔除吗?或者说,在机器深度学习的底层技术没有革新的前提下,政府应该做些什么才能让AI在面对两难抉择时做出合乎多数人伦理观的选择呢?
三、智能阴影下的政府抑恶行动
社会科学在预测方面的表现向来令人失望,但是在大数据和强人工智能的帮助下,“精准预测”变得不再那么困难[24]。这在很大程度上得益于大数据的近乎全样本采集能力,它帮助预测模型挣脱诸种行为假设的束缚,在大量相关分析的基础上得出结论。通过对一个人的数据进行长时段搜集和实时监控,个体行为正在丧失其不确定性,这使得面向未来的治理变得可行,同时也令公共生活变得暮气沉沉、缺乏意义。现代管理学发现,秘书往往对组织领导的最终决策起着远超人们想象的巨大作用——他们对材料的归类方式、提交的时间甚至文件码放的顺序,都会影响甚至决定领导者的最终决策。那么,当“文牍管理”变成“数据治理”,当AI化身为每一个人的“私人秘书”之后,这个对决策者本人的所有信息都洞若观火的“秘书”,究竟是人类手中的提线木偶,还是会在不知不觉间左右一个人的生活?通过分析一个人的偏好并向其推荐他最可能感兴趣的事物或朋友,把人圈定在一个由AI为你量身打造的“便利计划”中,事实上谷歌、亚马逊、领英、阿里巴巴和百度等大公司已经在这样做了。机器通过学习,可以不断强化一个人表现出来的显著偏好,同时也遮蔽这个人发掘其他偏好或偶遇一些美好的不期然结果的可能,一旦习惯于这种在AI设计下的高效和便利,从某种程度上来看,他作为一个人的一部分核心生活意义就被人工智能抽离了。这种被设计好的生活井井有条,但这种循规蹈矩、周而复始的生活是令人无比沮丧的。
此外,我们还必须认识到算法的数理逻辑远非完美无暇。我们回到第二个思想实验中加以详述,若多人共乘一车逃离毒气,在没有伦理机制介入影响AI决策的前提下,AI就会将车内全部乘客的得分加总之后再进行比较。假设甲(99分)和乙(1分)同乘一车,丙(50分)和丁(51分)搭乘另一车,此时在AI看来后车就比前车拥有优先“获救权”。但是即便那些接受数理逻辑的严格效用主义者,也不得不承认这种总分比较法过于简单机械,至于反对边沁或密尔的义务论者对AI的抗议就更不必提了。事实上,如果仅考量一个人所能为社会创造的价值,那么一个99分的图灵远超数十甚至数百个50分的普通人。对于多数人类决策者而言,裁决他人生死时总是充满伦理观上的激烈矛盾,让丙和丁“待在原地”确实有违伦理,但关闭甲和乙所乘车的引擎,似乎在道德上更加可疑。对于人类管理者而言,在面对两难抉择时,往往他的最终决策过程既复杂又充满不确定性,很多时候受到他所持的哲学观影响;对于人工智能而言,它的决策过程是明晰而又确定的,而且改变AI的决策逻辑也比让一个人放弃或接受一套哲学体系简单得多。未来一个可以预见的场景是:当人类决策者因为面对伦理两难而举棋不定、多次错失行动良机后,心有不甘的人们还是会回到“让AI代替人类决策”的老路上。
诚然,我们已经无法将AI从社会中“摘除”了,短期内也没有可能将AI变成“人工道德主体”(artifical moral agent),即便全面禁止AI建立一套关于公民价值的隐藏评分系统,人类也不会就此摆脱伦理两难的纠缠。在十年内,保守估计AI除了会在人们的生活领域中扮演“设计者”和“决策者”之外,在交通、医疗、减灾、军事、外交等领域也将获得更广阔的应用空间。但是,与人类以往的几次技术革命一样,人工智能技术不可能平等地惠及每个阶层和人群[25],因为人工智能的决策无关道德——道德的目的是公正,它强调“义务”这个特殊的概念[26]。既然人工智能无法为人们提供一个道德的生活,而政府恰恰有保障社会公正的“义务”,那么扭转人工智能造成的不平等(或者至少阻止这种不平等持续扩大),在逻辑上就成为政府无可推卸的责任。人类行动者在危机降临时往往会接受“自我保护原则”——认为对他人的致害(包括致死)行为是正当的,只要这种行为是自己能够幸存的必要条件[27]——但绝对理性的AI只会保护那个在它的评价体系中更“值得”保护的人或群体。一旦社会中的大部分公共决策都被笼罩在人工智能的阴影下,政府应该做些什么才能捕获这一阶段的治理合法性呢?笔者认为,一个智能社会中的政府可以在扬善行动中稍稍后退,放权给其他行动者,而主要在抑恶方面展开行动。具体来说,这种抑恶行动至少应包括“消除信息歧视、发展机器伦理、建立熔断机制、进行伦理审查、防止计划体制”等五个方面。
(一)政府应当抑制“歧视之恶”
具体来说,政府应致力于削弱由人工智能造成的信息区别对待现象,推动大数据分析的信息平等和获取自由,消除那些干扰公民获得信息的障碍。例如,如果AI利用大数据对某人进行家族病史、基因缺陷、健康状况、生活习惯和工作环境等综合分析后,得知他罹患心血管疾病的概率非常高,那么仅让十分关心他健康风险评价的保险公司获得这份分析报告是不公平的,这会令真正需要医疗保险的那部分人反而失去了参保资格。不能因为某个人从未关注过健康,AI就不为他推送疾病风险等涉及个人隐私的重要信息,必须让公民个人也能没有障碍地获得大数据分析报告,让他拥有选择是否改变生活习惯或者换一份工作的自由。关于消除信息歧视的具体方式,包括传统的采用不对称的公钥加密算法以生成一个用以加密的“公共密钥”和一个用以解密的“私人密钥”,以及使用“数字签名”来验证读取信息者的身份,同时还应着力确保大数据统计分析部门的专业性和独立性,谨防差分隐私在技术层面增加的信息噪音反而变成一种针对个人的查阅权限门槛(因为在AI看来,那些大企业为代表的组织行动者比个体行动者更值得拥有高权限密钥),让AI真正成为面向所有行动者的普惠性技术。
(二)政府应当抑制“无为之恶”
一直以来,道德伦理的责任主体必须是人,若因AI引发伦理危机而对算法设计者进行道德问责,就忽视了设计者与受害人之间不存在直接因果关系的事实。但是,这并不意味着算法设计者可以不必努力寻找让AI的决策更具伦理意义的技术,恰恰相反,设计者应当审慎地在算法中嵌入当下社会的主流伦理观。无论从法哲学还是政治哲学的角度来看,作为决策者的人工智能都应隐含设计者的物化的道德,其使用也应体现出伦理功能[28]。在这一道德化的过程中,政府无疑承担推动和促进机器伦理快速发展的职责,任何听任AI决策而不加干预的做法都可视为一种“无为之恶”。大数据技术既可以拱卫传统,也可以促进社会转型,关键在于由谁来掌握大数据库、由谁来分析隐匿在海量数据中的“信息”并把这些它们转化为“知识”。数据无善恶之分,但使用和分析数据的人却不然。大数据技术已经在潜移默化地影响国家治理的决策,重塑政治、组织甚至是人类思维方式,国家在数据治理中应更多地赋权社会主体,建构“多元与开放的治理结构”,最终形成合作的治理模式[29]。为了实现这种合作治理,政府应积极行动,率先打破AI的算法黑箱,确保在算法中嵌入符合时代特征的伦理原则,而不能仅仅凭借机器自身的数理逻辑进行决策。
(三)政府应抑制“失控之恶”
既然AI的决策并不完美,那么将关涉生命安全或国家安全的领域全权交由AI决策无疑是厝火积薪之举,因此政府应当在关键点设置一系列“安全阀”。具体来说,即通过建立一个针对AI决策危机的“熔断机制”,筑起一道阻止机器“为恶”的防火墙,在必要的时候暂时关闭AI的权限,防止事态恶化或进一步蔓延。当AI在决策中遇到“没有规则”但并不十分紧急的问题时,应向人类监督员预警,如果规定时间内(如一个小时)未接到回应,才能继续以算法来自己创造规则。当AI不得不在十分紧急的伦理两难中做出选择,且无论何种选择都可能造成严重后果时(如前文所述的两个思想实验假设的情境),则应立刻触发熔断机制进行止损,同时由人类应急小组接手控制权进行紧急处置。需要强调的一点是,人工智能从来没有,也不需要像人类一样思考,如果有一天它真的以人脑的方式运行,那么它也就失去同时快速处理海量数据的功能。因而,在触发“熔断机制”之外的其他情况下,政府应当始终把AI视为一个平等的治理行动者,尊重其借助互联网的共享原则所汇集的“集体智慧”(collective wisdom)。
(四)政府应抑制“固化之恶”
伦理观是随社会发展而变化的,那么AI的决策算法也应当根据社会变迁而不断地调整,持守一套僵硬的、陈旧的伦理观念无疑也是一种“恶”。在这一意义上,数理逻辑与康德的“定言令式”一样都不应成为人工智能解决两难问题时恪守的“信条”(Maximen)。应该说在设计AI的决策伦理时,唯一的信条就是没有信条,不必追求一种普世的伦理,只要保持与时俱进的持续修补,就能不断接近而非远离“善”。在具体实现方式上,政府可以组织专业的伦理审查团队,对人工智能的底层算法进行周期性的核查和改良,同时将审查系统向具备资质的第三方开放,以便不定期地开展第三方监督复核。既要审查算法,也要检查AI系统是否被植入病毒,这关乎国民生活和国家安全。借助于信息技术,国家已经可以通过介入虚拟世界从而影响现实世界,一些顶级网络黑客在政府力量的支持下,能够发起对目标造成巨大实质性破坏的网络攻击,甚至有可能改变国际局势。例如,美国在2010年就曾利用“震网”(Stuxnet)蠕虫病毒导致伊朗浓缩铀离心机转速失控、损坏,最终迫使伊朗的核发展计划搁浅。
(五)政府应当抑制“计划之恶”
在国家治理层面,获得大数据支撑的AI决策善于形成宏大的计划,它不可能仅仅覆盖某个社区、某个城市甚至某个省,而是将全国视为“一盘棋”进行全局规划。国家行动在这种“宏大计划”下,往往会为了提高多数人的福祉而变得越来越强势。但是,宏大计划在治理中始终面临效用主义的侵扰,即在某种极端情况下,国家会以牺牲一小部分人为代价换来多数人幸免于难的结果,这也导致欧洲许多民族国家中的少数族裔频繁使用斯科特所谓“弱者的武器”进行反抗,有的则试图以公投等方式脱离共同体。对于极度复杂的国家治理而言,计划失败是常态。历史不断地提醒人们,越是宏大的计划越容易全面溃败,典型的例子可见于二战后欧洲重建过程中的公共住宅建设计划。朱特(Judt)在《沉疴遍地》中如是写道:“从共产主义的波兰到社会民主主义的瑞典、工党的英国、戴高乐时期的法国和纽约的南布朗克斯,过分自信和缺乏敏感的计划者们给城市和郊区塞进一些无法居住、惨不忍睹的住房”[30],却根本没有人会关注那些宏大的、符合美感的现代化住房与民众实际需求之间的鸿沟。现实一再告诫人们,不能将治理视为一种数学游戏而忽视人的差异性和真实感受,不能简单化地将社会视为由均等个人组成的匀质共同体,只对受益群体和受损群体进行人数多寡的比较。事实上,政府在保持供给充足的前提下总有最小化联盟成本的冲动[31],因而它一直在追求通过数据分析和建模制订出一个“完美的计划”,以实现公共服务“不余一分”的理想状态,这就是政府在财政压力下强调精准供给的实质。但这种计划覆盖下的公共服务,未必就能实现供给的“量体裁衣”,因为大数据预测个体行动者的表现比预测社会整体要好很多。将个体需求简单加总起来并不是集体的需求,这种机械论指导下的治理隐含一种人们必须警惕的危险——“计划体制”复辟。作为一个信息时代智能社会中的治理行动者,政府必须学会与人工智能的决策相互补全而非彼此掣肘,唯有“善假于物”,才能在这个高度复杂的环境下拥有通过行动改善处境的自由,成为一个不为算法所控制的“有为”行动者。
[1]CORY D.Big Data:Welcome to the Petacentre[J].Nature,2008,(455):16-21.
[2]张康之,张桐.大数据中的思维与社会变革要求[J].理论探索,2015,(5):5-14.
[3]段伟文.控制的危机与人工智能的未来情境[J].探索与争鸣,2017,(10):7-10.
[4]阿兰·图海纳.行动者的归来[M].舒诗伟,等,译.北京:商务印书馆,2008:139.
[5]MOORE A D,WARREN S D,&BRANDEIS L D.Information Ethics: Privacy,Property,and Power[M].Seattle,WA: University of Washington Press,2005:209-225.
[6]JEFFREY H.REIMAN.Driving to the Panopticon:A Philosophical Exploration of the Risks to Privacy Posed by the Highway Technology of the Future [J].Santa Clara Computer and High Technology Law Journal,1995,11(1):24-50.
[7]COHEN J E.Privacy,Visibility,Transparency,and Exposure [J].University of Chicago Law Review,2008,75(1):181-201.
[8]吕耀怀,罗雅婷.大数据时代个人信息收集与处理的隐私问题及其伦理维度[J].哲学动态,2017,(2):63-68.
[9]王泽群.政府在大数据隐私保护中的职能重塑[J].理论探讨,2016,(3):170-173.
[10]王绍源,任晓明.大数据技术的隐私伦理问题[J].新疆师范大学学报:哲学社会科学版,2017,(4):93-99.
[11]熊平,朱天清,王晓峰.差分隐私保护及其应用[J].计算机学报,2014,(1):101-122.
[12]吉隆·奥哈拉,奈杰尔·沙德博尔特.咖啡机中的间谍:个人隐私的终结[M].毕小青,译.北京:生活·读书·新知三联书店,2011:8-9.
[13]卢梭.社会契约论[M].李平沤,译.北京:商务印书馆,2014:34-35.
[14]罗尔斯.正义论[M].何怀宏,等,译.北京:中国社会科学出版社,1988:33.
[15]ZHAO L,DETLOR B,&CONNELLY C E.Sharing Knowledge in Social Q&A Sites: The Unintended Consequences of Extrinsic Motivation [J].Journal of Management Information Systems,2016,33(1):70-100.
[16]卡斯卡特.电车难题:该不该把胖子推下桥[M].朱沉之,译.北京:北京大学出版社,2014:3-9.
[17]BONNEFON J F,SHARIFF A,&RAHWAN I.The Social Dilemma of Autonomous Vehicles [J].Science,2016,352(6293):1573-1576.
[18]彼得·萨伯.洞穴奇案[M].陈福勇,等,译.北京:生活·读书·新知三联书店,2012:86-96.
[19]康德.实践理性批判[M].韩水法,译.北京:商务印书馆,2016:75.
[20]陈钟.从人工智能本质看未来的发展[J].探索与争鸣,2017,(10):4-7.
[21]赵汀阳.四种分叉[M].上海:华东师范大学出版社,2017:74.
[22]赵汀阳.有轨电车的道德分叉[J].哲学研究,2015,(5):96-102.
[23]谢惠媛.“为了行善而作恶”的道德问责[J].伦理学研究,2017,(4):90-94.
[24]维克托·迈尔-舍恩伯格,肯尼思·库克耶.大数据时代:生活、工作与思维的大变革[M].盛杨燕,等,译.杭州:浙江人民出版社,2013:16.
[25]冯仕政,陆美贺.社会计算如何可能?[J].贵州师范大学学报:社会科学版,2016,(6):27-30.
[26]威廉斯.伦理学与哲学的限度[M].陈嘉映,译.北京:商务印书馆,2017:42-49.
[27]BEDAU H A.Making Mortal Choices:Three Excercises in Moral Casuistry [M].Oxford,UK:Oxford University Press,1997:115.
[28]于雪,王前.“机器伦理”思想的价值与局限性[J].伦理学研究,2016,(4):109-114.
[29]王向民.大数据时代的国家治理转型[J].探索与争鸣,2014,(10):59-62.
[30]托尼·朱特.沉疴遍地[M].杜先菊,译.北京:新星出版社,2012:57.
[31]RIKER W H.The Theory of Political Coalitions[M].New Haven,CT:Yale University Press,1962:32-33.
猜你喜欢
英美文学研究论丛(2022年1期)2022-10-26
纺织科学研究(2021年9期)2021-10-14
活力(2019年19期)2020-01-06
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
南风窗(2016年19期)2016-09-21
中国卫生(2014年6期)2014-11-10
中国现当代社会文化学术沙龙辑录(2013年0期)2013-10-24
