
复杂排班背景下企业考勤系统优化
2018-05-27 08:33王树贤罗锋覃云韬
中国管理信息化 2018年7期
王树贤 罗锋 覃云韬
[摘 要] 流行的企业考勤系统多与排班系统关联,在有复杂排班情况的企业里,排班系统因数据录入工作量太大而多被弃用,导致考勤系统统计功能丧失,人工统计效率非常低下。通过将考勤系统与排班系统分离,并经方案优化和算法优化,极大地提高了统计效率。
[关键词] 企业;考勤;排班;统计;优化
doi : 10 . 3969 / j . issn . 1673 - 0194 . 2018. 07. 036
[中图分类号] TP311 [文献标识码] A [文章编号] 1673 - 0194(2018)07- 0087- 04
1 引 言
目前,通过引入考勤机来监控员工的出勤纪律,已经十分普及。考勤机设备也发展出了刷卡式、指纹式、甚至人像识别式等多种先进型号,在事业型单位、一班制的企业等简单环境下的应用,已经相当的成熟。但是,针对有多班次倒班、允许员工私下调班等具有复杂排班模式的企业单位,考勤系统在考勤数据的整理、出勤时间的统计、异常数据的发现等方面,统计算法还远未成熟。
2 目前考勤系统存在的问题
为了应对多班次倒班等复杂的排班情况,目前流行的考勤系统主要通过和排班系统结合起来的方式来实现数据的关联。即把所有员工的班次信息也录入系统,这样,某员工上班和下班预设的时间段就确定了下来,考勤数据与这个预设的时间段相对比,得到正常出勤和非正常出勤的情况。
这种模式的缺点有如下几个方面:
(1)根据实际生产情况,员工的排班情况是多变的。可能这几天生产任务紧需要3班倒,过两天不太紧张了只需要上2班;某员工这一周上晚班,下周又可能上白班。这就需要不断地往系统里录入大量的排班信息,工作量很大,生产管理人员对于数据录入的积极性不高。
(2)对于员工众多的企业,某员工因有私事私下和工友调班是允许的,否则管理起来更加复杂。这样就使得系统里排班数据和考勤数据对不上,还是不能自动处理。
(3)多班次倒班时,员工上班时间和下班时间可能已不在同一天,即跨日期上下班。这给数据统计也带来了一些麻烦。
(4)员工难免有漏刷卡、重复刷卡的现象,当考勤数据不成对儿出现时,对上班刷卡还是下班刷卡的判断也会出现问题。
鉴于上述种种原因,许多企业已经放弃了考勤系统的统计功能,而仅仅是从系统中导出考勤记录,在Excel中手工逐条处理数据,工作量之大可想而知。
3 改进思路
3.1 措施一:上下班考勤机分离
针对以上问题,一个有效的改进途径是上下班考勤机分离,即上班和下班分别刷不同的考勤机。这样可以大幅降低系统处理的复杂度,目前已有考勤系统支持这种方式。
通过上下班考勤机分离,使得原来复杂的业务逻辑大幅简化。理论上,如果员工刷卡没有错误,就可以很容易计算出出勤时间。即使出现漏刷卡、多刷卡等异常情况,系统也很容易排查出异常,甚至可以判断错误原因,免除手工排查的大量工作。严格执行上下班分离的刷卡考勤制度,或者与门禁系统相结合,就可以随时计算出车间在岗人员数量,甚至可以列出在岗人员名单,使车间管理更加精细、更加直观。
上下班考勤机分离也有缺点。如果考勤机安装位置设计不够合理,员工不能轻易清晰的区分上班考勤机和下班考勤机,员工刷卡时会把上班和下班弄反,同样会导致考勤数据的错乱。所以,考勤机安装位置的设计非常关键,一定要考虑人们的思维习惯,一般设计在出入方向的右手边,并用醒目的文字标注,同时配合有效的培训和出错惩罚的管理制度。考勤机上下班分离方案,能够以较小的投入换来较大的改进效果。
3.2 措施二:考勤数据统计算法的优化
3.2.1 与排班系统分离
为了有效减少系统维护的数据量,针对有复杂排班需求的生产型企业,果断放弃考勤系统与排班系统的集成,单从考勤数据中提取员工的出勤情况。
3.2.2 考勤数据的整理
在生成报表前,先对考勤数据进行预处理。比如剔除无效数据、补充遗漏数据等。当然首先是提取出某时间段数据,再针对该部分数据进行处理。实践中,一般以一个月为一个统计周期。代码略。
3.2.2.1 无效刷卡数据的剔除
针对员工难免出现的重复刷卡的现象,系统尽可能的删除无效刷卡数据。可以采取的策略有:
(1)间隔5分钟内重复刷上班卡,以最后1次为准(代码以SQL Server为例,下同)。
DELETE a
FROM #t a JOIN #t b
ON a.工号=b.工号 AND a.日期=b.日期 AND a.考勤機=b.考勤机
WHERE DATEDIFF(ss, a.日期时间, b.日期时间) BETWEEN 1 AND 300
AND a.刷卡用途='上班';
(2)间隔5分钟内重复刷下班卡,以第1次为准。
DELETE a
FROM #t a JOIN #t b
ON a.工号=b.工号 AND a.日期=b.日期 AND a.考勤机=b.考勤机
WHERE DATEDIFF(ss, b.日期时间, a.日期时间) BETWEEN 1 AND 300
AND a.刷卡用途='下班';
注意DATEDIFF()函数中,日期时间的参数顺序与第(1)条的顺序相反。
(3)间隔2分钟内刷上班和下班卡,以最后1次为准。
DELETE a
FROM #t a JOIN #t b
ON a.工号=b.工号 AND a.日期=b.日期
WHERE DATEDIFF(ss, a.日期时间, b.日期时间) BETWEEN 1 AND 120;
3.2.2.2 跨日期上下班考勤数据的预处理
最直观的报表形式为每日出勤情况,所以针对跨日期上下班考勤数据,需要进行一些预处理。
(1)一天第1次刷卡为下班卡的,若为9点之前下班,则认为是跨零点上班,即前一天上班当天下班。当天从零点计算出勤时间。系统补零点上班卡。
INSERT INTO #t(工号, 姓名, 部门, 二级部门, 三级部门
, 日期, 序号, 视同时间, 刷卡用途
)
SELECT 工号, 姓名, 部门, 二级部门, 三级部门, 日期, 0 序号
, CASE WHEN 刷卡时间<'09:00:00' THEN '0:00:00' END 视同时间
, '上班' 刷卡用途
FROM #t
WHERE 序号=1 AND 刷卡用途='下班';
(2)一天最后1次刷卡为上班卡的,若为15点之后上班,则认为是跨零点上班,即当天上班第二天下班。当天计算出勤时间到24点,系统补24点下班卡。
with t AS
(
SELECT 工号, 日期
, MAX(序号) 序号
FROM #t
GROUP BY 工号, 日期
), t2 AS
(
SELECT #t.工号, #t.姓名, #t.部门, #t.二级部门, #t.三级部门
, #t.日期, #t.序号, #t.刷卡时间
FROM #t JOIN t ON #t.工号=t.工号 AND #t.日期=t.日期
AND #t.序号=t.序号 AND 刷卡用途='上班'
)
INSERT INTO #t(工号, 姓名, 部门, 二级部门, 三级部门
, 日期, 序号, 视同时间, 刷卡用途
)
SELECT 工号, 姓名, 部门, 二级部门, 三级部门
, 日期
, 序号+1 序号
, CASE WHEN 刷卡时间>'15:00:00' THEN '23:59:59' END 视同时间
, '下班' 刷卡用途
FROM t2;
3.2.2.3 漏刷卡数据处理
经过上述数据处理之后,相邻两次刷卡刷卡用途还相同,即均为上班卡或均为下班卡的,则认为中间缺一次刷卡操作,系统补1次时间为空的刷卡记录。
(1)重新整理序号,方便后面相邻两次相同用途刷卡数据处理。
;with t AS
(
SELECT 工号, 日期, 序号
, rn=ROW_NUMBER() OVER(PARTITION BY 工号, 日期 ORDER BY 序号)
FROM #t
)
UPDATE #t
SET #t.序号=t.rn
FROM #t JOIN t ON #t.工号=t.工号
AND #t.日期=t.日期 AND #t.序号=t.序号;
(2)补1次时间为空的刷卡记录,用以报表中提示缺1次刷卡操作。
INSERT INTO #t(工号, 姓名, 部门, 二级部门, 三级部门
, 日期, 序号, 刷卡用途
)
SELECT a.工号, a.姓名, a.部门, a.二级部门, a.三级部门
, a.日期
, a.序号-0.5 序号
, CASE a.刷卡用途 WHEN '下班' THEN '上班' ELSE '下班' END 刷卡用途
FROM #t a JOIN #t b ON a.工号=b.工号 AND a.日期=b.日期
AND a.序号=b.序号+1
WHERE a.刷卡用途=b.刷卡用途;
3.2.2.4 数据预处理注意事项
以上数据预处理步骤,充分运用了顺序号这一字段。所以,维护好顺序号,是数据处理的关键。不同目的数据处理操作的先后顺序,也要仔细考量。
3.2.3 生成出勤报表
经过上述一系列的数据处理,系统终于可以生成出勤数据報表了。
with t1 AS
(
SELECT 工号, 姓名, 部门, 二级部门, 三级部门, 日期, 视同时间, 刷卡用途
, Row_Number()Over(partition by 工号, 日期, 刷卡用途 order by 序号) 序号
FROM #t
), t2 AS
(
SELECT 工号, 姓名, 部门, 二级部门, 三级部门, 日期, 序号
, CASE WHEN 序号=1 AND 刷卡用途='上班' THEN 视同时间 END 上班1
, CASE WHEN 序号=1 AND 刷卡用途='下班' THEN 视同时间 END 下班1
, CASE WHEN 序号=2 AND 刷卡用途='上班' THEN 视同时间 END 上班2
, CASE WHEN 序号=2 AND 刷卡用途='下班' THEN 视同时间 END 下班2
, CASE WHEN 序号=3 AND 刷卡用途='上班' THEN 视同时间 END 上班3
, CASE WHEN 序号=3 AND 刷卡用途='下班' THEN 视同时间 END 下班3
, CASE WHEN 序号=4 AND 刷卡用途='上班' THEN 视同时间 END 上班4
, CASE WHEN 序号=4 AND 刷卡用途='下班' THEN 视同时间 END 下班4
, CASE WHEN 序号=5 AND 刷卡用途='上班' THEN 视同时间 END 上班5
, CASE WHEN 序号=5 AND 刷卡用途='下班' THEN 视同时间 END 下班5
, CASE WHEN 序号=6 AND 刷卡用途='上班' THEN 视同时间 END 上班6
, CASE WHEN 序号=6 AND 刷卡用途='下班' THEN 视同时间 END 下班6
FROM t1
), t3 AS
(
SELECT 工号, 姓名, 部门, 二级部门, 三级部门, 日期
, MAX(上班1) 上班1
, MAX(下班1) 下班1
, MAX(上班2) 上班2
, MAX(下班2) 下班2
, MAX(上班3) 上班3
, MAX(下班3) 下班3
, MAX(上班4) 上班4
, MAX(下班4) 下班4
, MAX(上班5) 上班5
, MAX(下班5) 下班5
, MAX(上班6) 上班6
, MAX(下班6) 下班6
FROM t2
GROUP BY 工號, 姓名, 部门, 二级部门, 三级部门, 日期
)
SELECT 工号, 姓名, 部门, 二级部门, 三级部门, 日期
, 上班1, 下班1
, 上班2, 下班2
, 上班3, 下班3
, 上班4, 下班4
, 上班5, 下班5
, 上班6, 下班6
, ROUND((ISNULL(DateDiff(n, 上班1, 下班1), 0)
+ISNULL(DateDiff(n, 上班2, 下班2), 0)
+ISNULL(DateDiff(n, 上班3, 下班3), 0)
+ISNULL(DateDiff(n, 上班4, 下班4), 0)
+ISNULL(DateDiff(n, 上班5, 下班5), 0)
+ISNULL(DateDiff(n, 上班6, 下班6), 0)
) * 1.0 / 60, 1) 出勤时间
FROM t3
ORDER BY 工号, 日期;
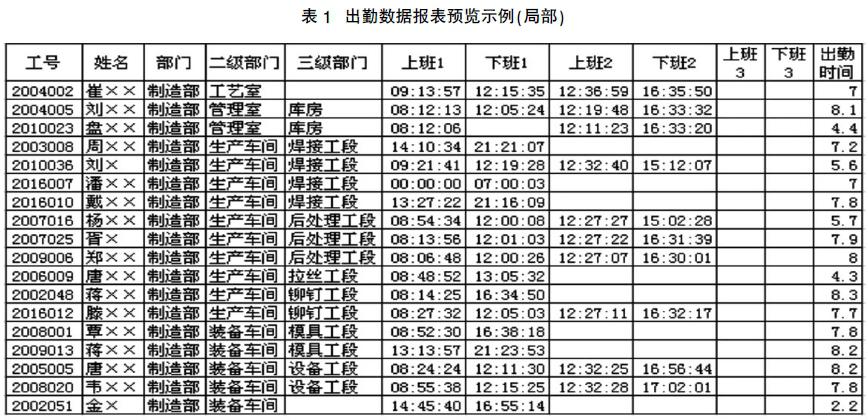
某一天的出勤数据报表预览示例如表1所示。
通过报表预览可以很明显的发现,工号为2010023的员工盘××漏刷了一次下班卡。后来通过视频监控录像证实了该员工正常按时下班,因漏刷卡对该员工给予警告处理。在手工补齐下班考勤数据后,即可正式生成报表。
经过数据整理,针对部分重复刷卡的无效数据已经剔除,漏刷卡情况也给与明确提示。通过报表预览,可以快速的发现数据错误,进行手工的数据处理后再生成最终报表,统计效率得以极大改善。
4 结 论
经某企业的应用实践证明,通过方案改进和算法改进,对于复杂排班环境下的生产型企业,考勤系统的实用性大大提高,考勤统计人员的工作量大幅减少,极大地提高了工作效率,得到用户的好评。
猜你喜欢
房地产导刊(2022年5期)2022-06-01
中学生数理化(高中版.高二数学)(2021年12期)2021-04-26
电子制作(2019年12期)2019-07-16
电子制作(2019年9期)2019-05-30
计算机测量与控制(2017年6期)2017-07-01
人间(2016年27期)2016-11-11
数字技术与应用(2016年9期)2016-11-09
商(2016年27期)2016-10-17
教育与职业(2014年1期)2014-04-17
