
基于工作流及大数据的学习流引擎的构建与实现
2018-05-24 12:55黄河清
安阳师范学院学报 2018年2期
黄河清
(福建广播电视大学 漳州分校,福建 漳州 363000)
1 学习流引擎概述
1.1 学习流引擎(Learning Flow Engine)的概念
学习流引擎(Learning Flow Engine)属于软件,它是为学习流实例的执行提供运行服务的环境[1],称为“引擎” 。学习流引擎负责在线学习(E-learning)过程的定义和控制、学习活动的组织及其执行顺序的安排、学习项目的添加、学习应用工具的调用、在线学习内部数据的维护等等。作为学习流(Learning Flow)执行服务的实体,学习流执行服务模块驱动着整个学习流管理系统的运行。因此,学习流引擎是E-learning系统的重要部分,它能为E-learning提供学习活动和学习过程的有效控制,是学习流管理系统的核心[2]。
1.2 学习流引擎研究的内容
学习流引擎(Learning Flow Engine)作为学习流(Learning Flow)的核心软件组元,它决定了整个学习流管理系统(LFMS)的功能和效率。应用工作流技术的基本思想和方法,解决E-learning在大数据环境下的学习流程控制问题,进行面向大数据的学习流引擎的模型构建及技术实现研究,主要有以下几个方面:
学习流引擎的功能和性能:学习流引擎的功能和性能是整个学习流引擎研究中的重点。这方面首先要研究学习流程的特点,从需求分析的角度,综合远程教育及其项目要求[3]、教学支持系统架构[4]、教育系统及考试系统功能[5]、参考学习型组织的特点[6-8]、及各种教育模式(例如:学历教育、社区教育[7-8]、老年教育[9])的不同需求和共同特征,提取其特征和规律。研究学习情况的因素,总结在线学习的属性和功能,如自主化、个性化、智能化等,并应用建模技术和软件方法构建所需学习模型的功能[10]。性能方面要提高引擎的执行效率、以及同时处理多个任务的能力。
分布式学习流引擎:分布式学习流引擎使得学习流管理系统能够支持大范围、大数据、跨地域的网络学习。目前在大数据、互联网、移动通信的环境下,分布式技术的支持是E-learning发展的主流,无论是学校教育或社区教育,无论是什么年龄段的人群,都在海量信息中。全民的在线学习、智慧学习、远程教育等等,其核心方法都需要分布式技术的支持及应用。尤其是当学习流运行在大规模分布式的大数据集上时,学习流中的数据管理需求更加复杂。
学习流数据管理:在大数据环境,学习流引擎需要对存储在云中的学习资源大数据进行处理,结束并行运算时,需要对云端产生的数据进行存储,还可能要对来自各种环境和各种学习流管理系统的相关的数据进行管理。因此需要支持大数据学习流的数据管理方案,可行有效的是采用将数据存储和学习流的定义和执行分离的方法。
引擎的事务处理能力:指学习流引擎应对运行时异常和运行时错误的能力。在引擎的设计过程中[1],必须提供恢复机制使得引擎能够及时处理异常和错误并从中恢复,提高引擎的健壮性和稳定性。
柔性学习流引擎、动态学习流引擎、智能学习流引擎等:主要研究如何提高学习流引擎的自适应能力。学习过程及内容是复杂多变的,有时在学习之前并不能获得完整的过程定义,而只能获得部分定义;或者在学习流运行过程中需要根据实际需求动态修改学习流过程定义。因此,学习流引擎须适应流程的动态增加和修改,使得增加或修改后的流程能够正常运行。
引擎的安全:这方面主要研究如何提高引擎的安全性能,保证在使用学习流的过程中,用户隐私和机密信息不会泄露,保证用户数据不受到侵犯,还要防范使用大数据出现的安全隐患。
1.3 面向大数据的学习流引擎研发路径
在面向大数据的需求下,学习流中的数据管理更加复杂,需要灵活有效的数据管理,用对象存储的方法构建数据管理方案,将数据存储与执行分离,以支持大数据学习流,从而使应用能在同一时间对多个分布式的资源进行调用,实现能将某个任务(TASK)从某个执行点迁移至另一个执行点,而不需要移动所有数据。
有不少流程应用的文件管理系统是基于POSIX ( Portable Operating System Interface),就是说流程中的每个任务可打开1个或多个输入文件、进行读和写等操作,之后关闭。在这样的情况下,学习流管理系统需要提供可以访问POSIX 文件系统数据的运行环境。云端在计算节点附近有对象存储器,可为多个文件系统提供服务,如提供存储、检索和删除数据对象( 或文件) 等有限的存储操作。
为了完成学习流引擎的设计与实现,下面从学习流引擎的功能分析与设计开始,进行系统构建和系统实现,并以基于 JVM的技术为实例,将 JVM资源分配和任务调度处理的理论和方法用于学习流引擎的研发。采用流程管理以过程为中心,协同平台以角色为中心的技术方法[11]。
2 学习流引擎的功能分析与设计
学习流引擎(Learning Flow Engine)的基本功能包括:控制学习过程定义及学习活动的导航、提供进入学习活动或退出学习活动的触发条件以完成状态控制、提供流程并行执行或者顺序执行的选项、提供学习流管理信息及数据的交换、还提供用户要执行的任务分配、设计用户操作接口、提供有关的应用程序、对整个系统进行管理等等。下面对这些基本功能进行分析和设计。
2.1 学习过程定义及信息转换功能设计
过程定义导入/导出接口,是过程建模和学习流执行服务之间的接口,该接口具有API调用功能,能进行格式转换,因而它是支持过程定义和信息转换的。学习流引擎必须在过程定义转换接口中提供对过程定义进行转换的功能,学习流引擎的过程定义转换功能有[1]:
第一,对过程及其运行环境之间的一个分离点进行定义,使得采用一种建模工具所产生的过程定义,还可以用于其他的学习流的输入,使得用户对建模的选择独立于对学习流管理软件种类的选择。
第二,针对能协同工作的学习流引擎及系统,做好提供输出过程定义的功能,提供分布的运行服务。
使用了过程定义作为接口,并在学习流引擎中提供对过程定义进行转换的功能。同时还必须提供一套接口或者API,以实现各种学习过程(例如自主学习、培训项目、学习型组织等等)的过程定义的解释和修改等功能[3-5]。
2.2 学习过程及活动状态控制功能设计
控制过程和活动状态是学习流引擎最重要的功能。学习流的工作过程可用状态变迁机器来表达,在响应外部事件,或学习流引擎的控制判断之后,过程或者活动实例的状态随即发生变化。
对于过程实例的基本状态变迁[11]如图1所示,过程定义时,当发生转移的前提条件成立,就发生状态转移(状态转移用箭头表示)。
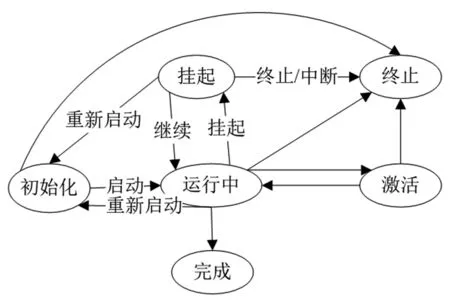
图1 学习过程基本状态变迁图
图1所示的学习过程里,其基本状态变迁共有五个状态,首先是"初始化"状态,此时, 创建过程实例,创建与过程状态相关的时间、日期、及各相关数据;处于"初始化"时,流程尚未被执行,因为执行的条件尚未满足。启动后,当条件满足时,才可以执行过程中的活动进入“运行中”状态。例如,过程当中的一个或多个活动已经被执行,如果过程里的活动已处于运行中,则处于“激活”状态。而在过程活动不能执行的情况下,则处于“挂起”状态。如果过程实例的结束条件成立,那么就可以转到“完成”状态。如果过程实例非正常结束,即中途被停止运行,则进入“终止”状态。
特别注意的是,在此是不允许中断活动的,学习流服务器开始了某个活动后,就不允许中途挂起或终止了,如果要中断,就要等待全部处于运行状态的活动都结束以后,过程返回到了正在运行中的状态,才允许中断、终止、挂起或重启等等。在具体处理时,可建立 “原子单元”, 一个单元内包括几个互为相关的活动,一个原子单元内的各个活动,必须全部执行完,万一执行出现了意外情况,那么就会返回到始点,各个活动都重新再执行。图2描述了活动实例的基本状态转移[12]。
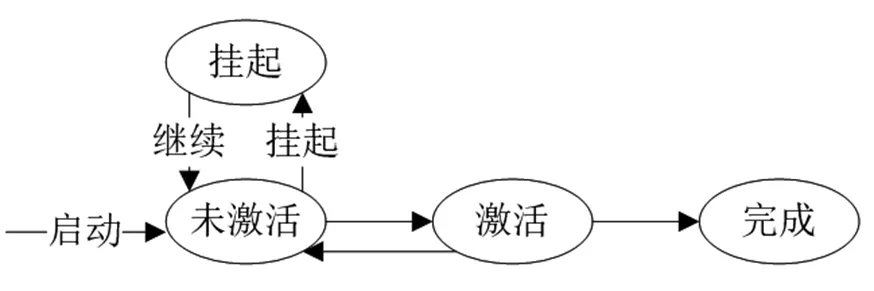
图2 活动实例的基本状态转移
图2所示的活动实例的基本状态有:未激活状态,此时活动早就被创建,但活动的进入条件尚未满足,同时也没有需要处理的任务。激活状态:创建好的任务,分配这个活动来进行任务的处理。挂起状态:此时活动实例被暂时调离,当条件允许时,才再被调回。完成状态:此时活动实例执行完成。
所述的基本状态及其转移是每个学习流引擎必备的。当然不同类型的学习流引擎其实现的状态和转移的类型可以不尽相同。
2.3 学习流的数据交换功能设计
学习流的内部控制数据支持其内部状态信息,这种控制数据是禁止被访问和转换的。不过为了响应某方面的特殊操作,也需要对外部提供一些相关内容及信息。同种的学习流执行服务器,可以通过使用内部对话在学习流机之间进行信息交换。这些数据主要有如学习流控制数据、学习流应用数据等等[1];对于这些数据的交换和维护,可以在不同的活动实例之间、学习流引擎与外部应用程序之间、学习流引擎与学习流引擎之间等等,进行交互。
学习流应用程序要实现相关数据交换,可通过学习流引擎的下面三个接口来处理:一个是客户端应用程序的接口、二是应用程序调用接口、三是学习流机的协作接口。
2.4 任务分配和系统接口的功能及其设计
学习流引擎能分派任务和信息给参与者,这个分派的能力是学习流引擎的重要区分特征。在不同的级别上执行分派功能(如:学习小组、班级、年级、学校等),这取决于学习流的范围;还可以使用各种消息传递、分布式对象技术等多种不同的消息机制。
学习流的制定服务(任务分配)是核心功能组件,通过引擎的任务分配接口将任务提供给用户、以及分布在学习流的范围内的应用程序。每一个这样的接口都是一个潜在的、可以与其他学习流服务、其他基础组件或应用程序组件进行集成的点[13]。
2.5 用户操作接口功能和设计
学习系统里,学习流的用户交互是通过已定义的、客户端应用程序和学习流引擎之间的接口进行的,最终完成各项自主学习及规定考试任务[3,6]。
学习流引擎客户端应用接口应提供的功能有[12]:学习流定义操作,即对学习流过程、对学习流属性的恢复或者查询等等给予定义。建立会话,连接或者断开客户与学习流管理系统之间的会话。过程控制,对过程实例进行创建/开始/结束、挂起/唤醒等。还有查询过程状态、任务表/任务项处理、过程管理、数据处理、应用程序调用等。
2.6 应用程序调用接口功能及设计
在学习流执行的过程中,不可避免地需要调用外部的应用程序,需要对不同平台及各种环境下执行调用的逻辑进行处理,在大数据共享大环境里,常常要使用公共格式,进行各种数据或参数的传递。
学习流引擎可在本地使用过程定义中的信息来确定活动的性质以及要调用的程序类型及参数。供调用的子程序或者存于学习流引擎相同的平台里,也可能存放在诸如各种云中或其他平台;为了方便调用,过程定义应有具体的寻址信息和应用程序类型的数据。
其中,学习流引擎的应用程序调用接口的主要功能有[12]:首先是能连接/断开应用程序会话,即能够创建会话;再者是能开始或挂起以及恢复或放弃活动,能查询活动的属性,这是活动管理;还有重要的功能就是数据处理,能提供学习流的数据或者应用程序数据或者相关数据地址。
2.7 系统管理功能与设计
作为一个完整的学习流管理系统,学习流执行服务必须对外界提供一个用来进行系统管理的接口。如果这一接口符合标准,则可以开发统一的管理工具,对不同的学习流管理系统进行管理[4-5]。
学习流引擎的系统接口的基本功能有[2]:用户及角色的管理、资源与过程的控制、审查管理、查询过程状态。打开及关闭过程(或者活动)实例查询,提取过程(或者活动)实例的相关信息。
学习流引擎在实现上述功能的时候,并不是将所有的功能都实现,一般是根据需求实现某几个需要的功能,不同的系统往往在功能上相差甚远。虽然是面向不同的学习用户及满足不同的学习需求,但是最重要的原因是统一的标准尚缺乏。因此,这些功能只作为参考,对于某个具体的学习流,通常不用全部实现这些功能。但是,对于模型的解释和对过程和活动的控制是所有的引擎都必须要实现的功能,这是学习流引擎的核心,不具备这种功能就不能称为学习流引擎。
3 学习流引擎系统及构建
3.1 学习流引擎系统方案的构建
对于学习流参考模型和学习流引擎的具体功能,在实现时还要考虑很多具体的设计问题,需要考虑实际应用中的效率,实现成本等各种问题。不同的实现方案各有优缺点,一般来说,提出一套学习流的实现方案要考虑3个方面:
首先要确定学习流模型,构建学习流过程描述及其实现方案。虽然学习流模型和实现方案之间有一定的关系,但是他们不能相互确定。就是说,一种方案可以执行不同的模型,同一种学习流模型可以有不同的实现方案。学习流模型所构建的是系统对过程的描述,而学习流的实现方案是学习流管理系统自身的运行机制。模型与实现之间无特定的对应关系。
其次是选择实现方案采用的技术,主要指底层通信基础。例如:CORBA, DCOM, MQSERIES,WEB服务器等等。
再次是确定系统的模块划分,确定各个模块之间的协作关系,以完成学习流的运转。对于不同的设计模式,其模块和协作的设计都可能不相同。
针对学习流管理系统的不同要求,其实现的软件体系结构也是不同的。设计学习流引擎时,根据数据存储和运行环境的不同要求,构建的体系结构相应也不同,它们除了具备学习流的基本功能外,还可以进行应用集成,进行嵌入式应用[13]。基本方法是基于工作流引擎的实现技术,设计所需的学习流引擎[3]。
3.2 常见学习流引擎及体系结构
从实现技术的角度,常见的学习流引擎有以下几种类型:基于Domino的、基于消息中间件的、基于微软平台的、基于J2EE的学习流引擎。
其中,J2EE采用B/S多层结构的,J2EE技术架构保证了系统能够进行长期稳定的功能扩展[14],基于J2EE的学习流引擎具有实现简单、性能优良、系统柔性、扩展便捷、配置简化的优点。可以使学习流管理系统具有分布式与跨平台的特性[15]。因此,基于J2EE的学习流引擎是讨论的重点,下面详细讨论基于J2EE的学习流。
学习流引擎用J2EE架构实现,结合JSP、XML与EJB技术进行系统设计,其核心用EJB和 JSP编写,使学习流管理系统的柔性提高。如图3所示是一个基于J2EE的学习流引擎的体系架构[16]。该引擎主要包括6个部件:处在顶端的“解析器”、与“解析器”相连的“流程管理”、接着是处于中心的“执行器”、以及“任务分派”部件、“事件服务器”部件、“时间服务器”部件以及“客户端接口”[2]。

图3 基于J2EE的学习流引擎体系结构
学习流引擎的流程管理模块主要负责流程的执行控制,包括启动、挂起、恢复和终止。作为引擎的核心,执行器负责流程中节点实例的具体执行。为了支持有关事务,执行器用EJB定义其相应J2EE事务属性节点的方法。引擎通过事件服务器JMS实现向外部系统发送及接收事件。
J2EE通过提供计算环境所需的服务,支持多层体系结构的应用开发,从而使部署在J2EE上的多层应用具有可扩展、安全、可靠、易用的特性[16]。用这种方式可以实现基于Web的管理,能够把EJB Server集群,还能够把EJB分发到不同的Server上,Server还提供连接池和事务处理,如:外部USER可通过形如get Connection的方法获取连接,使用完成后再通过形如release Connection的方法将连接返回,返回后连接没有关闭,紧接着由连接池管理器进行回收,准备下一次使用。从而使相应的学习流引擎具有一定的事务处理功能,提高了系统的处理性能及效率[15]。
4 基于JVM WF的学习流引擎的设计与实现
设计学习流引擎时,将工作流技术和现代教育技术相结合,采用JVM WF的实现机制,进行解决方案的构思及引擎的设计和实现。采用将JVM实现原理中对资源的分配和任务的调度处理等理论和方法,构建以过程为中心的流程管理和以角色为中心的协同工作相结合的学习流引擎,充分考虑了学习流中的学习情况因素,从而保证学习流引擎调度的高效率、高性能以及稳定性[12]。
4.1 引擎总体架构
学习流引擎的组成包括三大核心模块:一是过程解释器、二是引擎控制器,第三是协同中心。学习流引擎的总体架构如图4所示。
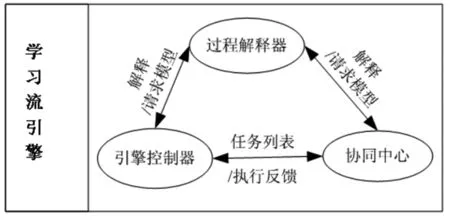
图4 学习流引擎的总体架构图
过程解释器:它是学习流引擎的一个对外接口,引擎通过过程解释器获取模型。对学习流模型和其他流程模型进行解释,并向引擎控制器和协同中心传递学习流模型。
引擎控制器:它是学习流引擎的核心部分,位于学习流实例的运行中心,各个重要模块,包括创建功能、激活功能、挂起功能、终止功能,以及过程实例的运行状态间的切换也是由引擎控制器完成的。
协同中心:处理用户的协同、任务的执行,完成引擎控制器所生成的任务以及资源的协调工作。
4.2 过程解释器设计
作为接口工具的过程解释器,它位于学习流建模工具与学习流引擎之间,过程解释器解释学习流模型并传递给学习流引擎。使用直观、友好的学习流建模工具进行学习流程建模时,建模工具会自动地将学习模型翻译为学习流引擎能够识别的语言(如APDL)。
如何对一维模型语言进行解释、获取模型的信息是过程解释器设计的关键。可使用XML语言进行模型描述,因此需要使用对XML格式文档进行解释的技术。在系统建模中使用XML语言描述学习过程模型,对XML的解析有两种比较常用的方法:SAX(Simple API for XML)和DOM(Document Object Model)[12]。
事件驱动方法SAX是用于处理 XML 的接口和软件包,它提供对XML文档的低级访问,内存消耗小。DOM是以面向对象(OO)方式描述的文档模型,其逻辑结构是节点树。经解析XML文件,其元素经过转化成为DOM文档节点,节点的类型例子有如Document、Element、Type、Comment等,其中每一个DOM有一个Document根节点。它可以有子节点,或者叶子节点如Text节点、Comment节点等。DOM 和 SAX 的主要差异是它们的 API 结构。SAX 不提供修改 XML 文档的功能。而 DOM 提供修改XML文档的功能[12]。
4.3 引擎控制器设计
在学习流中,引擎控制器完成过程实例的创建与激活、挂起及终止,并完成过程实例的运行状态间的切换,是学习流实例运行的中心。在学习流引擎中,流程由节点组成,节点有两类节点:原子节点和流程节点。所谓原子节点是不可再细分的学习任务或学习活动;流程节点可以再细分成由多个节点或流程节点组成的子流程。
学习流引擎控制器包括学习流调度控制、及节点状态控制和节点执行控制三个控制,学习流引擎的核心引擎控制器工作由这三方共同完成。在学习流引擎运行时,学习流调度对学习流节点实例进行调度,包括运行调度和资源调度,需要维护两个队列:等待队列、流程节点队列。
4.4 引擎实现的关键技术
1. Java容器技术实现对象管理。基于WF的学习流管理系统的逻辑相当复杂和多变,采用基于关系数据库的技术实现学习流的核心逻辑。研究中充分利用Java容器管理系统的实例对象,而容器间嵌套使用的方式更容易实现学习流元素之间的关系,图5表现了这种关系。
Java提供了丰富的容器API,使用这些容器非常方便简单,例如过程模型类LfcProcessModel[12]中的数据成员关系可以参看图6的代码节选。
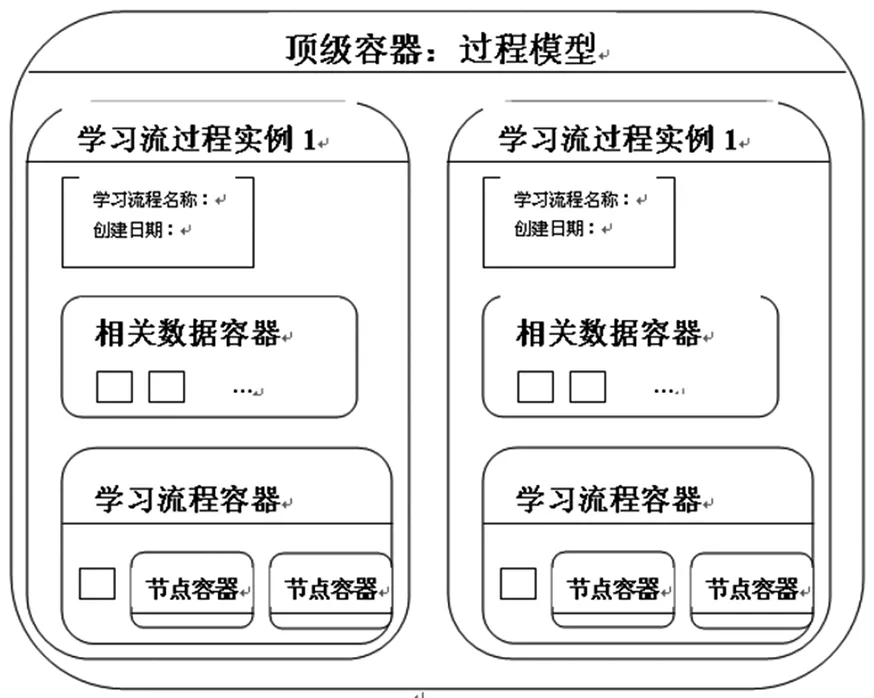
图5 系统使用的Java容器
Java的对象管理有两种:克隆及按引用访问方式,使用克隆,也就是深度复制,可以产生一个同原对象完全一样的副本,方便快捷。而按引用访问方式,使系统在执行对象实例的操作时,保证对象的访问不会产生另外的临时副本,确保为对象本体的唯一修改版本,实现了数据一致性的保证;使用Java容器技术时,默认情况是按引用管理,以确保数据的一致性[12,13]。

图6 使用容器的代码示例
2.多线程技术实现学习流实例管理。学习流管理系统应该是支持多任务的管理系统,因此作为学习流的核心管理层,过程控制模块必须提供对多任务管理的支持。JVM提供了多线程管理机制,能满足多任务的需求[17]。例如已经封装的调度策略、资源分派策略等等,因为已经对外提供了接口,应用时按照标准API对接口操作就可以了,如图7所示。

图7 JVM中的多线程管理
多线程能同步完成多项任务,学习流在进行多线程处理时,需要解决共享公共数据区产生的执行同步问题。在Java中,有相应的接口和处理策略,采用Java提供的简单易用的synchronized,对线程之间的协作关系进行控制。从而达到提高资源使用效率的目的。
3.序列化机制为学习流执行环境的持久化提供保证。运行环境的保存和恢复是系统实现时要提供的功能之一。研究采用Java的容器技术来实现对系统内的对象实例的管理和控制,整个系统的运行环境是由这些存在于容器中的实例构成的,如何实现对这些对象的持久性管理,是实现系统持久性的关键,本研究在程序设计中,使用序列化机制来实现所需的管理[17]。
序列化机制包含两个过程:第一是把内存中的对象永久保存,也就是保存在持久性介质中的序列化过程,第二是将持久性介质环境恢复到内存中的反序列化的过程。序列化机制支持自动嵌套调用。这适用于本系统内部容器之间的嵌套关系,而且程序上利用Java的接口,容易实现。序列化与平台无关、不需要额外成本。序列化存储可存于本地环境、远程环境、异地网络、也可以是云存储,或者其他存储方式,与平台无关。在系统实施中,零成本,而且序列化保密性能好,速度和效率较高,维护容易,用户欢迎[9,18]。
4.标准接口JDBC技术。JDBC是Java数据库连接(Java Data Base Connectivity)的简称,JDBC为各种常用数据库提供无缝联接,从而提高了软件系统的通用性,用户要访问什么类型的数据库在网络及开放系统是很难预料的。为了使用方便,有正确的驱动器组,JDBC就可以访问其相关的数据库资源。从而更加体现了平台无关的特性,具有可操作性、灵活性和易扩展性[15]。
5 结语
以工作流为基础,进行的学习流引擎的设计与实现中,解决好引擎的控制调度问题是关键一环,引擎控制和调度解决的好坏直接影响到引擎的性能和稳定性。学习流引擎可以借鉴处理线程的机制来解决实例调度、状态控制、多实例同步和实例间通信等问题。但它和学习流引擎在运行机制和处理问题对象上是不同的,处理的具体问题也不同,此时需要认真考虑以下问题[12]:
第一,管理的对象。学习流引擎所管理的资源是作为教学者的人和作为教学资源的更为复杂的资源[4,9],这些资源是很难进行精确预计的,并且这些资源(如人)的性能是不稳定的(如不同的人个性不同,人在学习过程中会受外界、情绪等诸多因素影响)。在学习流引擎运行过程中无法提供精确的资源情况,因此在需要运行时间等参数时必须依靠原有的经验模型以及通过多次运行后得出的历史数据进行不断修正,才有可能使学习流引擎具有更高的性能。
第二,解决问题的复杂度。例如,JVM所执行的线程是由代码段所组成的计算机程序,程序是结构化的事物,在执行程序代码时是严格按照编程者已经编写的代码去执行的,这些代码段在不修改代码和运行环境时,可以保证程序每次执行的一致性[17]。对于学习流引擎,处理的是学习过程流程,其中有结构化的流程同时也要处理非结构化流程。在引擎执行的过程中参与者的执行以及参与者执行的结果对引擎的运行结果产生很大的差异,因此引擎对同一个流程的运行由于外界的因素是具有差异性的。为了能控制和管理这种差异性,应加强学习流引擎对于非结构化流程的处理能力,应进一步研究学习流的仿真和智能化。
[参考文献]
[1]范玉顺.工作流管理技术基础[C].北京:清华大学出版社,施普林格出版社.2001.1.
[2]余阳, 王颍, 刘醒梅,等. 基于社会关系的工作流任务分派策略研究[J]. 软件学报, 2015, 26(3):562-573.
[3]陈展虹, 李呈林. 教师教育技术能力培训项目分析[J]. 福建教育学院学报, 2011(2): 69-72.
[4]詹立彩,旷玲丽,赵芸辉,徐鹤.远程开放教育教学支持服务系统构建——以福建开放大学学习平台建设为例[J].福建广播电视大学学报,2016(01):1-5.
.[5]陈精珠, 刘朝宗, 林碧群. 开放大学网络考试系统功能论证[J]. 福建广播电视大学学报, 2012(6): 15-18.
[6]王凌宇. 广播电视大学创建学习型组织问题初探[J]. 福建广播电视大学学报, 2011(5): 50-53.
[7]黄河清.基于云计算的福建本土化社区教育新模式——以电大系统智能移动社区学习平台为例[J].福建广播电视大学学报,2016(03):26-30.
[8]纪开祝,许冲,陈宝兴.复杂网络重叠社区结构发现的演化算法研究[J].计算机工程与科学,2016,38(10) :2077-2082.
[9]吴东晖, 蔡新霞. 台湾老年教育发展理念, 模式及其对大陆的启示[J]. 河南广播电视大学学报, 2012, 25(3): 80-82.
[10]杜燕军.基于百会文件构建高校学术期刊协同审稿系统[J].中国科技期刊研究,2013,24(02):345-348.
[11]王元.基于JVM机制和角色协同的工作流引擎研究和实现[D]. 广州:中山大学,2004.
[12]郭威.学习流引擎的设计与实现[J].现代计算机(专业版),2010(06): 130-132 +135.
[13]Tristan Glatard,Marc-étienne Rousseau,Sorina Camarasu-Pop,Reza Adalat,Natacha Beck,Samir Das,Rafael Ferreira da Silva,Najmeh Khalili-Mahani,Vladimir Korkhov,Pierre-Olivier Quirion,Pierre Rioux,Sílvia D. Olabarriaga,Pierre Bellec,Alan C. Evans. Software architectures to integrate workflow engines in science gateways[J]. Future Generation Computer Systems,2017(10):239-255.
[14]倪曌,白利芳,董奥冬.一种面向业务规则和流程的推理引擎架构[J].计算机应用与软件,2017,34(03):98-102+153.
[15]黄河清.基于云计算的“智慧漳州”关键问题及模型构建[J]. 龙岩学院学报, 2015,33(3): 96-100.
[16]徐建军, 谭庆平, 杨艳萍. 一种基于J2EE的工作流引擎体系结构[J]. 计算机应用, 2005,25(2):469-471.
[17]林荣辉. 基于JVM的工作流管理开发平台研究与实现[D]. 广州:中山大学, 2005.
[18]Huang H. Efficient all-to-all broadcast algorithm in torus networks[C] . IEEE International Conference on Intelligent Computing and Intelligent Systems?(Vol.3, pp.911-916).IEEE, 2010.
猜你喜欢
房地产导刊(2020年12期)2021-01-14
人民交通(2020年4期)2020-04-16
商周刊(2017年22期)2017-11-09
山东青年(2016年1期)2016-02-28
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
当代修辞学(2014年3期)2014-01-21
公务员文萃(2013年5期)2013-03-11
中学生英语·外语教学与研究(2008年4期)2008-03-18
海外英语(2006年11期)2006-11-30
