
视频帧内运动目标移除篡改检测算法
2018-05-21 00:50林新棋陈黎飞
计算机应用 2018年3期
尹 立,林新棋,2,陈黎飞,2
(1.福建师范大学 数学与信息学院,福州 350007; 2.福建省网络安全与密码技术重点实验室(福建师范大学),福州 350007)
0 引言
数字视频篡改取证检测现已成为信号处理领域的一个研究热点[1]。现如今我们的日常生活中随处可见到可以记录视频的高品质数码产品,并且一些高级的视频编辑软件也进入大家的视野,大家可以比任何时候都方便地处理和修改自己拍摄的视频。科技改变了我们的生活的同时也会给一些不法分子以可乘之机。数字视频作为信息传播的媒介之一通常会被用于商业广告、媒体新闻、法律机构和政府组织等单位传播信息,如果这些用于传播信息的视频被恶意篡改,将会产生许多不良影响。数字视频内容的完整性和真实性的验证变得非常重要。
目前国内外关于数字视频篡改取证检测的主要研究方法分为两类:主动取证和被动取证。主动取证技术是指将待取证的数字视频中预先嵌入验证信息如数字指纹或数字水印,在取证的过程中通过验证所嵌入的验证信息是否完整来判断视频是否经过篡改,但是由于需要事先将验证信息嵌入到生成的视频中,主动取证技术有很大的局限性。被动取证技术又称为盲取证技术[1],这种取证方法不依赖于外部加入的验证信息,依据视频内容被篡改后会留下篡改痕迹而且会破坏视频内容的原有统计特性,利用视频内容自身的统计特性和信息验证视频的完整性和真实性。被动取证技术更为实用,已经成为视频篡改取证检测研究的一个热点。
针对视频帧内对象删除篡改操作,文献[2]指出对篡改区域进行修复会破坏时域连续性,导致视觉上的不连贯,所以会产生“鬼影”,于是针对视频修复时会产生“鬼影”提出一种新的篡改检测方法,该方法对有损压缩视频的检测具有较强的鲁棒性,但是其算法时间复杂度较高。文献[3]指出基于物体的篡改如移除物体后会通过后期的修复技术消除运动“鬼影”,这些被移除的物体的边界或者边界附近始终会有留下篡改的痕迹,并且篡改会破坏这些区域的统计特征,利用小波系数和梯度信息提取特征并通过SVM(Support Vector Machine)分类器进行分类,从而实现篡改视频的检测;但是该方法需要利用样本数据库进行训练,对样本数据库的依赖程度较高。文献[4]采用基于块的运动估计方法从相邻的视频帧中提取运动信息,通过比较原始视频和篡改视频的运动矢量的大小和方向的差异,检测视频是否经篡改;缺点是在遇到使用复杂的技术对目标人物进行删除篡改时,由于提取运动矢量的差异会比较困难,该方法可能会失效。文献[5]基于压缩感知理论使用KSVD(K-means Singular Value Decomposition )算法对差异帧进行特征提取,并构造高斯随机矩阵对特征进行测量获得低维压缩子空间,获得的低维压缩子空间通过kmeans进行分类,实现篡改视频帧的检测;但该方法不能定位具体的篡改位置。文献[6]针对动态物体被移除和帧复制的篡改,提出一种利用原始帧和篡改帧之间的噪声变化的特征去检测篡改视频的被动取证方法,该方法使用小波分解提取去噪后的视频帧的传感噪声特征,再将使用EM(Expectation Maximization)算法估计参数的GMD(Gaussian Mixture Density)作为贝叶斯分类器对篡改视频进行分类最后得出检测结果;虽然利用噪声变化的特征可以检测篡改视频,但是它对量化噪声敏感,对于高压缩的视频会造成误检。文献[7]提出了一种可以自动识别基于目标的篡改并定位篡改位置的视频被动取证检测方法,通过分析基于目标的篡改和图像隐写术之间的相似性,将视频片段中的基于目标的篡改的检测转换为相应视频帧的运动残差中的隐藏数据的检测;但该方法对于低比特率的视频鲁棒性较差。文献[8]针对基于纹理和结构的视频目标移除篡改,提出了一种利用Hessian矩阵的统计相关性来检测和定位篡改区域的方法;但该方法不能针对背景发生变化的视频进行检测。文献[9]利用光流不一致性来检测和定位篡改视频区域;但该方法检测精确度不高。文献[10]针对视频的logo被移除的篡改,提出了一种新的篡改检测算法。该算法通过分析logo区域的空间和时域上的统计特性估计可疑区域,然后使用SVM提取可疑区域的特征,并将可疑区域和参考区域的特征进行比较,从而判别可疑区域是否为篡改区域;但是对于logo被移除区域是非模糊的篡改该方法失效。
本文针对帧内对象删除篡改操作,提出一种基于主成分分析(Principal Component Analysis, PCA)的视频帧内前景目标移除篡改检测算法。实验结果表明,所提出算法可以有效检测静止背景下运动对象被移除的篡改,并且对压缩视频有很好的鲁棒性。
1 篡改检测方法
数字视频具有时域上连续的特性,而帧内的对象删除篡改操作会破坏这种一致性,虽然通过后期的修复技术可以掩盖篡改痕迹,但是画面的不连贯很难修复。对于这种画面不连贯的情况,为了使篡改痕迹显露,本文对差异帧进行处理,将处理的结果用二值图像来表示,然后对所有处理后的差异帧进行图像形态学操作,最后对每一帧的处理结果进行组合,输出检测结果。
该检测算法的实现步骤为:1)获取待测帧序列与基准帧的差异帧(灰度化);2)利用自适应稀疏算法对差异帧进行稀疏表示,得到去噪后的差异帧;3)将去噪后的差异帧分为h×h的非重叠图像块;4)对差异帧进行PCA变换,获得图像块降维后的特征向量空间,接着利用得到的特征向量空间,提取差异帧每个像素的特征向量;5)对每个像素的特征向量使用kmeans进行聚类,根据聚类结果构造差异帧的二值矩阵;6)对所有处理后的差异帧进行图像形态学操作,最后输出检测结果。
1.1 获取差异帧
将待测的视频转化成帧序列图像,对帧序列图像进行灰度化处理,从而减少运算量。假设视频帧大小为H×W,彩色图像转化为灰度图像公式[11]为:
Y=0.299R+0.587G+0.114B
(1)
在得到可疑视频序列后,将待测的可疑帧序列作为待测帧,记第k帧为Ik,Ik={ik(i,j)|1≤i≤H,1≤j≤W}。将不包含运动前景目标的背景静止的未篡改帧序列作为参考帧,记作Io,Io={io(i,j)|1≤i≤H,1≤j≤W}。差异帧Id可以表示为Id=|Ik-Io|。
1.2 基于稀疏表示的差异帧去噪
鉴于差异帧存在许多噪声信息,这些噪声信息会降低篡改检测的准确度,因此需要在检测之前尽可能地移除这些无用的多余的噪声信息。近年来主流的去噪方法是通过稀疏分解去噪。传统的去噪方式通过区分有用信息和噪声信息的频率不同来去噪。在含有噪声的图像中,传统理论认为有用信息集中在低频区域,而无用的噪声信息集中在高频区域。然而这种理论并不总是正确的,存在有用信息集中在高频区域,这些高频区域的有用信息决定图像的边缘和细节等;另一方面无用的噪声信息既含有高频成分也含有低频成分。也就是说,图像信号中的有用信息的频率和无用的噪声信息的频率存在重叠,通过区分频率不同来去噪的传统方法不能达到很好的去噪效果,导致去噪效果一般。而基于稀疏表示的图像去噪是从图像中提取稀疏成分,这些稀疏成分代表了图像中的有用信息,并且这些稀疏成分可以很好地表示图像的结构信息,即保留了图像的绝大部分信息,从而将图像中有用信息和噪声信息分开,实现噪声去除。
根据稀疏表示理论可知,一幅含噪声图像包含两部分:一部分是图像的稀疏成分,这部分包含图像的结构信息;另一部分是图像去除稀疏成分后剩下的部分,即图像的噪声,该部分不包含图像的结构信息。基于稀疏表示的图像去噪,根据图像中的稀疏成分来区分有用信息和噪声信息,从而达到去噪效果。经过图像的稀疏分解可以得到图像的一种线性表示[12]为:
(2)
其中〈Rkf,gγk〉表示图像f或者图像残差Rkf在对应原子gγk上的分量,对于一幅含噪声的图像f可以表示如下:
f=fs+fn
(3)
其中:
(4)
(5)
其中:fs是图像的有用信息即稀疏成分,fn为图像中的无用信息即噪声成分。
与传统的图像去噪不同,基于稀疏分解的图像去噪是提取图像中的稀疏成分,再利用提取到的稀疏成分重构图像,从而达到图像去噪的目的。本文采用KSVD算法[13]实现图像信号的自适应稀疏表示。KSVD算法是一种训练字典稀疏表示的去噪算法,该算法将超完备字典的训练和优化结合起来,训练得到的字典能更好表示图像的特征,将训练得到的超完备字典的原子通过正交匹配追踪法(Orthogonal Matching Pursuit, OMP)实现图像信号的稀疏表示。
1.3 差异帧特征提取
将去噪后的差异帧进行非重叠分块,即分成h×h的非重叠图像块。使用PCA提取分块后差异帧中每个像素点(i,j)的特征得到向量U(i,j)。令集合Id(x,y)={id(p,q)|x-「h/2⎤+1≤p≤h-「h/2⎤,y-「h/2⎤+1≤q≤y+h-「h/2⎤},其中(x,y)为图像块h×h(h≥2)内像素的坐标,「⎤表示向上取整。构造协方差矩阵:
(6)
其中:
(7)
T表示矩阵转置。Γ为集合中的元素id(x,y)的均值向量,1≤k≤M,M=⎣(H×W)/(h×h)」,⎣」表示向下取整。协方差矩阵大小为h2×h2,并且有r(r=h2)个特征向量。
利用协方差矩阵Σ可以求得差异帧中像素点(i,j)的投影向量U(i,j)。令λi(i=1,2,…,r)(r=h2)为协方差矩阵的第i个特征值,然后依据特征值大小进行排序,即λ1≥λ2≥…≥λr,其对应的特征向量为ωi(i=1,2,…,r)(r=h2),从中取S(S≤r)个特征向量得到:
W(i,j)=[w1,w2,…,wS]
(8)
将id(x,y)投影到W张成的特征向量空间中,由特征向量降维得到的特征向量空间W。因为差异帧中的任意像素点(i,j)都可以向其投影,所以可以得到该像素点在该空间的投影向量U(i,j),即生成空间像素点(i,j)的维度为S维的向量:
U(i,j)=[u1,u2,…,uS]T
(9)
us=wsT(id(x,y)-Γ)
(10)
其中:1≤s≤S,1≤S≤h2。
PCA保留的特征向量空间W与均值向量Γ可以将空间中的像素点投影到低维空间。由于对应r-S个特征值的特征向量被舍去了,导致原始的高维空间降维到低维空间,造成原始高维空间与低维空间不同。当视频帧受到噪声影响时,最小特征值对应的特征向量往往与噪声有关,将这部分信息舍去可以在一定程度上起到去除噪声的效果。前面已经对差异帧进行稀疏去噪,经过PCA变换可以再次去除残留的噪声,通过两次去噪,可以得到更优的去噪结果。再次,数据降维的主要动机是使空间中像素点的采样密度增大[14],舍去该部分信息可以增加对空间中像素点的采样密度,从而降低数据维度,减少了运算数据量。
1.4 差异帧特征聚类
将投影得到的空间像素点的向量U(i,j)进行特征聚类,取k=2,使用k-means算法进行聚类,即将特征子空间分为两个类,类1和类2。将个数较多的类记为类1,个数较少的类记为类2,η1表示类1对应的向量,η2表示类2对应的向量。通过计算向量U(i,j)与两个类对应的向量之间的欧氏距离,对投影得到的特征向量进行分类。定义二值矩阵:
A={a(i,j)|1≤i≤H,1≤j≤W}
(11)
相关区域像素值为“1”,表示为白色,相关区域像素值为“0”,表示为黑色。可以得到:
(12)
其中‖‖2表示欧氏距离。
1.5 图像形态学操作和结果处理
对得到的二值矩阵A进行“开”运算。“开”运算可以删除不包含模板形状的对象区域,可以平滑对象轮廓,断开图像中狭窄的连接,并去掉细小的突出部分和孤立的点。“开”运算定义为:
f∘b=(f⊖b)⊕b
(13)
其中:f为原图像,b为算子。设待测视频帧序列长度为L帧,每次间隔m帧进行一次处理,令I(i)表示第i帧处理后的结果,将二值矩阵A(i)处理结果记为I(i)。判断第i帧序列是否大于L,如果小于L则更新第i帧序列继续处理,直到帧序列大于L。然后将每次帧序列处理的结果I(i)依次进行“或”运算[15],即将处理得到的帧序列进行并运算并保留所有的处理结果,最后将最终处理结果存入一个新的二值矩阵Iz中。
1.6 篡改判别
视频帧内运动目标被删除篡改之后,为了保持视觉上的连续性,需要对篡改边界区域进行修复处理。尽管如此,仍然会在视频帧内遗留一些篡改痕迹,例如画面不一致导致的阴影以及没有完全移除运动目标周围的影子(称之为“鬼影”)等。通过本文算法,将不可见的“鬼影”显现化最终二值图像中的白色区域显示出来。而未经篡改的原始视频,没有经过帧内目标移除操作,当进行获取差异帧操作时不会产生因画面不一致所带来的痕迹,故而检测结果不会出现白色区域。因此:如果图像Iz中出现白色块状或带状区域,则表示该可疑视频经过篡改;如果图像Iz中不出现任何痕迹,则表示该视频未经篡改。
2 实验结果与分析
本文所使用的原始视频来自公共视频数据库 Surrey University Library for Forensic Analysis( SULFA)。实验视频共有20个,这些视频分别由Canon SX220 (codec H.264)、Nikon S3000 (codec MJPEG)和Fujifilm S2800HD (codec MJPEG)拍摄所得,视频分辨率320×240,帧率为30 frame/s。所选取的实验视频均为背景静止且有唯一的运动前景目标,使用视频编辑软件Mokey 4.0.0对视频帧进行前景目标删除。实验所用计算机的配置为处理器Intel(R) Core(TM) i5-3470 CPU @ 3.20 GHz,内存容量4.0 GB,显卡Intel HD Graphics,操作系统Windows 7 64位,使用Matlab(R2015b)运行代码。
图1和图2的实验结果给出了原始有目标的视频帧和篡改后的视频帧以及使用本文所提算法对这些视频帧检测后的结果,其中图1(a)为有运动目标的原始视频帧;图1(b)为删除运动目标的篡改视频帧;图1(c)为使用本文算法对图1(a)检测的结果;图1(d)为用本文提出的算法处理图1(b)的结果。图1的(d)和图2的(d)表明背景静止的视频且帧内目标被移除即该视频经过篡改,检测的结果确实出现白色块状或带状区域;而图1的(c)和图2的(c)表明原始的未篡改视频,检测结果确实无白色区域。这表明本文提出的算法确实能够检出运动目标被删除的篡改视频。

图1 视频检测结果对比1 Fig. 1 Comparison of video detection results Ⅰ

图2 视频检测结果对比2 Fig. 2 Comparison of video detection results Ⅱ
为了检验算法对有损压缩视频的检测效果,本文对8个不同压缩比的视频进行检测,检测结果如表1所示。结果表明算法对有损压缩视频可以进行有效的检测,对有损压缩视频具有很好的鲁棒性;而且对于未篡改的视频片段也具有较高的检测准确性。文献[6-7]方法对高压缩的视频和低比特率的视频检测鲁棒性较差,会产生误检;而本文给出的算法针对差异帧,通过对差异帧的像素点使用PCA进行处理,获取像素点的特征并使用k-means进行分类,使得检测算法对有损压缩视频误检率低,并且不受视频格式影响。
二分类问题常用的评价指标为准确率(precision)和召回率(recall)以及F1值。本文用正类和负类对样本视频进行标记。令实验中的原始未篡改的视频为正类,经过帧内对象删除篡改的视频记为负类。设TP为正类预测为正类数目;FN为正类预测为负类数目;FP为负类预测为正类数目;TN为负类预测为负类的数目。
本文准确率(precision)定义为:
(14)
召回率(recall)定义为:
(15)
此外还有F1值,是基于查准率与召回率的调和平均(harmonic mean)定义的:
(16)
本文对视频素材进行篡改检测,通过统计并计算上述3个度量指标,结果如表2所示。从表2可以看出,本文提出算法的检测指标均超过90%,这表明本文提出的算法具有一定的有效性,可用视频篡改鉴定。文献[5]提出了基于压缩感知的视频帧内目标移除篡改检测算法,本文算法与文献[5]的算法进行比较,比较结果如表2所示。本文算法准确度、召回率以及F1值均优于文献[5]的算法的。实验结果表明,本文所提出的算法可以有效地进行视频帧内对象删除篡改检测,并且不受压缩比的影响,对有损压缩视频具有很好的鲁棒性。
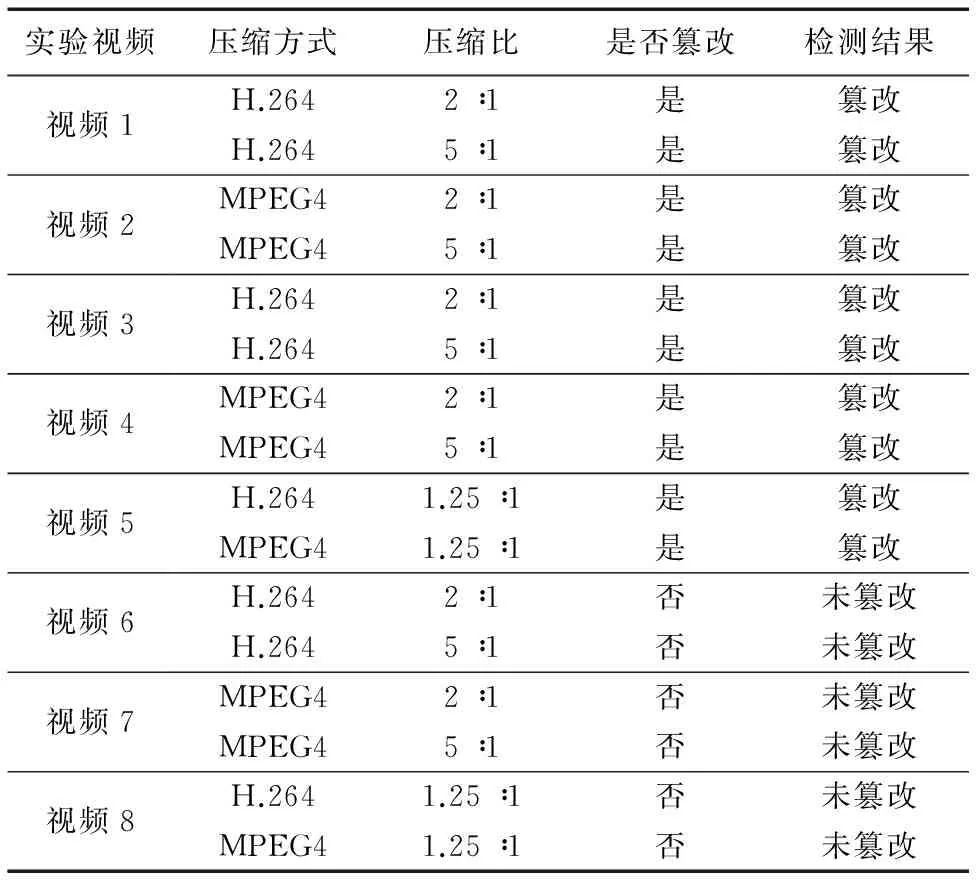
表1 不同压缩比的篡改视频检测结果Tab. 1 Tampering video detection results for different compression ratio

表2 不同算法比较结果 %Tab. 2 Performance comparison of different algorithms %
3 结语
本文提出了基于PCA的视频帧内前景目标移除篡改检测算法,利用稀疏表示的方法将视频差帧内的噪声去除,将去噪后的差异帧使用PCA提取特征并分类,最终获得检测结果。如果直接对视频差异帧进行特征提取,由于视频帧有干扰噪声存在,实验结果将出现大量的白点,这些白点会干扰检测结果,导致篡改痕迹不能被显示,并且容易对未篡改的视频造成误检;而使用稀疏表示对差帧去噪,可以最大限度地滤除噪声并保留视频差帧的原始信息,所以本文首先利用稀疏表示对差异帧去噪,然后进行特征提取。由于篡改时产生画面不一致的阴影以及篡改时没有完全移除目标周围的影子,这些痕迹导致检测结果出现白色区域。而未经篡改的原始视频,没有经过帧内目标移除操作,当获取差异帧操作时不会产生因画面不一致所带来的痕迹,故而检测结果无白色区域。经过实验验证,本文算法对背景静止的视频帧内对象移除的篡改可以进行有效的检测,但是本文算法对有强光照射且光线出现抖动的场景检测效果不理想,算法只能针对特定的篡改方式进行检测,适用性不强,今后工作需要进一步解决这个问题。
参考文献(References)
[1] BESTAGINI P, FONTANI K M, MILANI S, et al. An overview on video forensics [C]// EUSIPCO 2012: Proceedings of the 2012 Proceedings of the 20th European Signal Processing Conference. Piscataway, NJ: IEEE, 2012: 1229-1233.
[2] ZHANG J, SU Y, ZHANG M. Exposing digital video forgery by ghost shadow artifact [C]// MiFor ’09: Proceedings of the 1st ACM Workshop on Multimedia in Forensics. New York: ACM, 2009: 49-54.
[3] CHEN R, YANG G, ZHU N. Detection of object-based manipulation by the statistical features of object contour [J]. Forensic Science International, 2014, 236(3): 164-169.
[4] LI L, WANG X, ZHANG W, et al. Detecting removed object from video with stationary background [C]// IWDW ’12: Proceedings of the 11th International Conference on Digital Forensics and Watermarking. Berlin: Springer, 2012: 242-252.
[5] SU L, HUANG T, YANG J. A video forgery detection algorithm based on compressive sensing [J]. Multimedia Tools and Applications, 2015, 74(17): 6641-6656.
[6] PANDEY R C, SINGH S K, SHUKLA K K. A passive forensic method for video: exposing dynamic object removal and frame duplication in the digital video using sensor noise features [J]. Journal of Intelligent and Fuzzy Systems, 2017, 32(5): 3339-3353.
[7] CHEN S, TAN S, LI B, et al. Automatic detection of object-based forgery in advanced video [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2016, 26(11): 2138-2151.
[8] BAGIWA M A, WAHAB A W A, IDRIS M Y I, et al. Digital video inpainting detection using correlation of hessian matrix [J]. Malaysian Journal of Computer Science, 2016, 29(3): 179-195.
[9] SAXENA S, SUBRAMANYAM A V, RAVI H. Video inpainting detection and localization using inconsistencies in optical flow [C]//
TENCON 2016: Proceedings of the 2016 IEEE Region 10 Conference. Piscataway, NJ: IEEE, 2016: 1361-1365.
[10] SU Y, ZHANG J, HAN Y, et al. Exposing digital video logo-removal forgery by inconsistency of blur [J]. International Journal of Pattern Recognition and Artificial Intelligence, 2010, 24(7): 1027-1046.
[11] GRUNDLAND M, DODGSON N A. Decolorize: fast, contrast enhancing, color to grayscale conversion [J]. Pattern Recognition, 2007, 40(11): 2891-2896.
[12] BERGEAUD F, MALLAT S. Matching pursuit of images [C]// Proceedings of the 1995 International Conference on Image Processing. Washington, DC: IEEE Computer Society, 1995, 1: 53-56.
[13] AHARON M, ELAD M, BRUCKSTEIN A.K-SVD: an algorithm for designing overcomplete dictionaries for sparse representation [J]. IEEE Transactions on Signal Processing, 2006, 54(11): 4311-4322.
[14] 周志华.机器学习[M].北京:清华大学出版社,2016:230-232.(ZHOU Z H. Machine Learning [M]. Beijing: Tsinghua University Press, 2016: 230-232.)
[15] GONZALEZ R C,WOODS R E.数字图像处理[M].阮秋琦,阮宇智,译.第3版.北京:电子工业出版社,2011:48-49.(GONZALEZ R C,WOODS R E. Digital Image Processing [M]. RUAN Q Q, RUAN Y Z, translated. 3rd ed. Beijing: Publishing House of Electronics Industry, 2011: 48-49.)
This work is partially supported by the National Natural Science Foundation of China (61672157), the Fujian Provincial Higher Education Innovation Team Project (IRTSTFJ, J1917), the Fujian Normal University “Network and Information Security Key Theory and Technology” School Innovation Team Project (IRTL1207).
YINLi, born in 1992, M. S. candidate. His research interests include machine learning, multimedia information processing.
LINXinqi, born in 1972, Ph. D., associate professor. His research interests include multimedia information processing, pattern recognition.
CHENLifei, born in 1972, Ph. D., professor. His research interests include statistical machine learning, data mining, pattern recognition.
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
劳动保护(2019年3期)2019-05-16
数学学习与研究(2018年15期)2018-11-12
客车技术与研究(2014年6期)2014-02-28
意林(2011年10期)2011-05-14
