
基于Bagging-SVM的Android恶意软件检测模型
2018-05-21 00:50谢丽霞
计算机应用 2018年3期
谢丽霞,李 爽
(中国民航大学 计算机科学与技术学院,天津 300300)
0 引言
恶意软件具有隐蔽性强、窃取用户隐私和恶意扣费等特点,给Android手机用户带来日益严重的安全威胁[1],Android手机的安全形势日益严峻。Android恶意软件的快速高效检测成为目前的一个研究热点。
随着机器学习算法的广泛应用,许多研究者尝试借助机器学习方法进行Android恶意软件检测研究。通过训练机器学习分类器可模拟Android软件的行为,从而准确地区分良性软件和恶意软件。训练机器学习分类器的特征包括Android软件的静态特征和动态特征,通过对Android软件安装包(Android PacKage, APK)逆向处理可获得如权限、API和意图等静态特征;通过监测APK文件运行过程的实时信息可获取如系统调用、网络流量等动态特征。相比之下,静态特征的获取不需要执行恶意软件,对系统的干扰小且易于统计分析,已成为较常用的特征提取方法。
文献[2]通过提取软件运行时的用户操作场景和行为习惯等信息作为特征,使用朴素贝叶斯(Naive Bayes, NB)分类器检测Android恶意软件。文献[3]通过提取Android软件的组件、函数调用和系统调用类作为特征,采用NB、部分决策树和J48等算法构造3层混合分类器检测恶意软件。上述两种方法可以实现对Android恶意软件的检测,但检测精度低。文献[4]提取Android软件中Java字节码信息作为特征,采用主成分分析法对特征降维,并运用随机森林(Random Forest, RF)、NB和支持向量机(Support Vector Machine, SVM)等算法构建分类器检测恶意软件。文献[5]提取网络流量属性作为特征,采用卡方检验和信息增益(Information Gain, IG)融合的方法筛选最优特征子集,运用朴素贝叶斯分类器检测Android恶意软件。文献[6]提取APK文件中的权限和意图信息作为特征,采用信息增益算法筛选特征实现一种基于改进随机森林算法的Android恶意软件检测模型。文献[4-6]通过对特征降维实现较好的检测效果,但检出率低。
使用机器学习算法检测Android恶意软件检出率低的重要原因是可收集到的恶意样本种类少且数量有限,这必然导致收集到的数据集不平衡。文献[7]针对Android恶意软件检测中的数据不平衡问题,提出一种基于最小风险的朴素贝叶斯分类器,但由于仅提取权限信息作为特征,导致检出率仍不高。文献[8]提出一种基于多级集成的恶意软件检测模型,提取Dalvik指令、权限和API等静态属性作为特征,构造基于J48决策树的三层集成分类器,该模型具有较好的检测效果,但技术实现较为复杂。
综上所述,现有Android恶意软件检测方法在解决特征降维、数据不平衡和技术实现等问题时存在诸多不足,导致Android恶意软件检出率低。
本文提出一种基于Bagging-SVM集成算法的Android恶意软件检测模型,其主要工作为:
1)提取Android软件的权限(Permission)、意图(Intent)和组件(Component)等静态属性作为特征,提高恶意软件和良性软件的区分度。
2)提出一种IG-ReliefF混合筛选算法,最大限度地剔除冗余和无关特征,从而提高后续分类检测效果。
3)为解决数据不平衡性导致的Android恶意软件的检出率和分类精度低的问题,提出一种基于Bagging-SVM的恶意软件检测算法。该算法使用bootstrap抽样构造平衡数据集,并训练基于Bagging的SVM集成分类器用于Android恶意软件检测,实现较高的检出率和分类精度。
1 模型设计
基于Bagging-SVM算法,设计一种Android恶意软件检测模型(如图1所示)。该模型由3个主要模块构成:特征提取模块、特征筛选模块和分类检测模块。
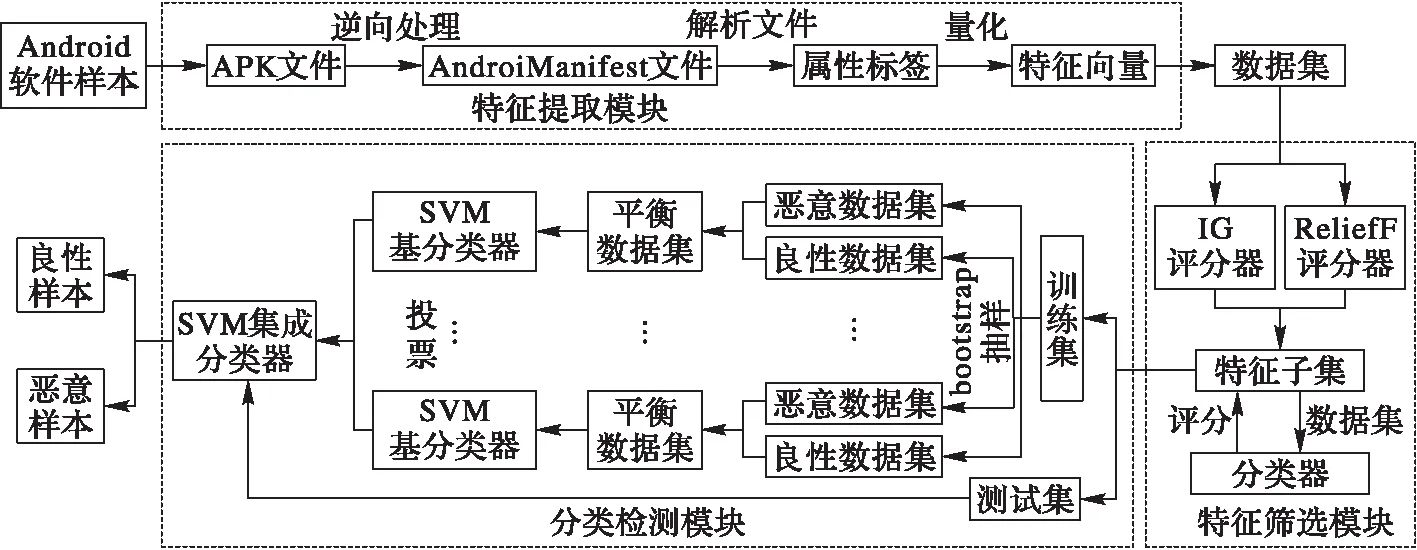
图1 Android恶意软件检测模型结构 Fig. 1 Android malware detection model structure
在特征提取模块和特征筛选模块完成数据的预处理,其主要目标为数据集提取和特征降维,处理过程为:
1)特征提取模块首先对Android软件样本的APK文件逆向处理得到清单文件AndroidManifest.xml,对清单文件解析获取属性标签,然后量化属性标签并构造特征向量,最后收集所有Android软件样本的特征向量组成数据集。
2)特征筛选模块采用IG[9]和ReliefF[10]2种算法对数据集中的所有特征评分,根据评分结果搜索特征子集,然后根据特征子集构造数据集,通过交叉验证法训练分类器获得分类结果,计算F1作为特征子集的评分。根据评分结果筛选分类效果最优的特征子集,从而完成特征降维。
在分类检测模块完成对分类器的训练和对恶意软件的检测,处理过程为:
1)采用随机抽样的方法将降维后的数据集拆分为训练集和测试集;
2)分别对训练集中的恶意数据集和良性数据集进行bootstrap抽样,构造样本数目相等的恶意数据集和良性数据集,合并二者组成平衡数据集;
3)重复2)构造多个平衡数据集,针对每个平衡数据集,训练1个SVM基分类器;多个SVM基分类器以投票的方式组成SVM集成分类器;
4)检测时,将测试集中的样本输入SVM集成分类器,输出SVM集成分类器中多个SVM基分类器的投票结果,以投票结果判定Android软件样本为良性样本或恶意样本。
2 数据预处理
2.1 特征提取
特征提取模块首先逆向分析提取APK文件中的Permission、Intent和Component静态属性作为特征,其次通过量化特征构造特征向量,最后将全部Android软件样本的特征向量合并为数据集。具体处理过程设计如下:
步骤1 运用反编译工具Apktool[11]将收集到的APK文件反编译,获取Android软件安装时的清单文件AndroidManifest.xml。
步骤2 采用Python中的xml.etree.Element Tree模块解析清单文件AndroidManifest.xml,统计清单文件中的Permission、Intent和Component信息。Android开发者自定义的Permission和Intent属性只属于特定样本,不具有代表性,因此不作统计。
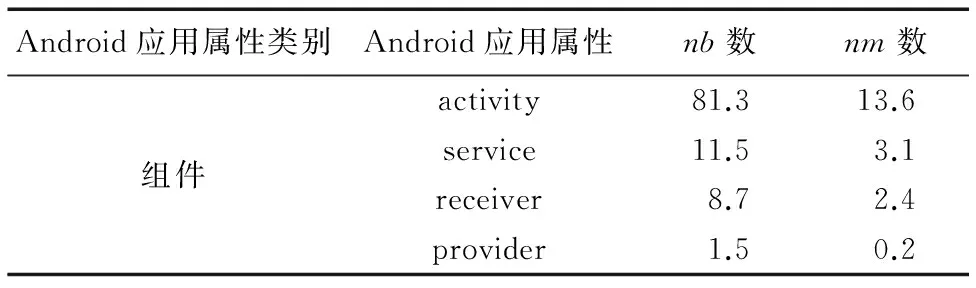
步骤3 将Permission和Intent的有无量化为1和0;把清单文件中窗口(activity)、服务(service)、广播接收者(receiver)和内容提供者(provider)的个数作为组件的量化结果。
步骤4 运用量化结果和类别标签(良性为‘0’,恶意为‘1’)构造特征向量,每个特征向量代表一个样本,将所有的特征向量合并为实验数据集。
2.2 特征筛选
为最大限度降低特征维度和提高后续的分类检测效果,特征筛选模块采用一种IG-ReliefF混合筛选算法。IG和ReliefF算法都是通过对特征评分筛选最优特征,但评分标准不同:针对某个特征,IG算法的评分值为该特征的熵值与其条件熵的差,主要量化单个特征对于分类结果的影响;而ReliefF算法的评分值为该特征与不同类别样本的距离和相同类别样本之间距离的差值,反映特征间的相关关系对分类结果的影响。IG-ReliefF算法结合二者的优点实现特征筛选,其过程为:首先,采用IG和ReliefF算法对特征评分,搜索2种算法下得分均高的特征子集;然后,使用搜索得到的特征子集构建数据集,并采用交叉验证法训练分类器,获取分类结果;最后,计算分类结果的评估指标作为特征子集的评分值,从而筛选出分类效果最优的特征子集。
2.2.1 特征子集评估指标
特征筛选中,为客观评估特征子集的优劣,本文计算准确率和检出率的调和平均值F1作为特征子集的评估指标。为此,首先定义4个基本指标量:TP表示恶意软件被正确识别的数量;FP表示良性软件被错误识别为恶意软件的数量;TN表示良性软件被正确识别的数量;FN表示恶意软件被错误识别的数量。利用基本指标,定义以下4个度量指标:
指标1 准确率表示被正确识别的恶意软件和被识别为恶意软件的数量比。
(1)
指标2 检出率表示被正确识别的恶意软件和实际恶意软件的数量比,也称作召回率。
(2)
指标3 分类精度表示被正确识别的软件和所有样本软件的数量比[12]。
(3)
指标4F1为准确率和检出率的调和平均值。
(4)
2.2.2 IG-ReliefF混合筛选算法设计
设实验数据集为S,其中包含p个特征F={f1,f2, …,fp},通过IG算法对p个特征的评分为G={g1,g2, …,gp},通过ReliefF算法对p个特征的评分为R={r1,r2, …,rp}。根据G和R中的评分结果筛选出评分最高的n个特征,分别为Gn和Rn,则特征子集FS的搜索公式为:
FS=Gn∩Rn
(5)
IG-ReliefF混合筛选算法步骤设计如下:
输入:实验数据集S;
输出:筛选后数据集D。
步骤1 采用IG和RelielfF算法对数据集S中的p个特征评分,评分结果保存为G和R,SF(初始值为空集)表示当前评分最高的特征子集,Fbest(初始值为0)表示当前最高评分值。
步骤2 依据n(初始值为1)的值由式(5)计算特征子集FS,基于FS组成筛选后的数据集D。
步骤3 将D中的数据随机均分5份,其中4份作为分类器的训练集,剩余1份作为分类器的测试集。执行训练和测试过程,保存对测试集的分类结果,并计算F1作为FS的评分值。
步骤4 将步骤3重复执行5次,计算F1的平均值Faverage。若Faverage>Fbest,则Fbest=Faverage,SF=FS;否则,跳过Fbest和SF的赋值阶段。
步骤5n自增1,重复步骤2~4。当n达到最大迭代次数p时,迭代停止,输出D。
3 分类检测模块
3.1 Bagging-SVM算法
3.1.1 问题分析
在Android恶意软件检测过程中,采用SVM算法分类检测存在两个问题:
1)由于Android恶意软件的样本收集困难,使得数据集中良性软件和恶意软件的数量比不平衡,使得训练后的SVM分类器分类结果偏向良性软件,导致Android恶意软件的检出率较低。
2)SVM算法对小样本分类效果较好,但是对样本敏感,尤其是处于分类边界上的样本,若分类边界上存在错分的样本,则会严重影响分类器的稳定性。
针对问题1,本文考虑分别对良性数据集和恶意数据集bootstrap抽样,构造平衡数据集,降低不平衡数据对分类结果的影响;针对问题2,由于Bagging算法可以显著提高分类不稳定算法的分类效果[13],因此考虑通过Bagging算法构造基于SVM的集成分类器,提高分类器的稳定性和检测精度。
3.1.2 算法设计
基于3.1.1节中的分析,本文提出一种基于Bagging-SVM的 Android恶意软件检测算法。首先,采用bootstrap抽样构造k个平衡数据集;然后,训练k个基于平衡数据集的SVM基分类器C;最后k个SVM基分类器以多数投票的方式组成SVM集成分类器C*;分类检测时,以SVM集成分类器C*的输出作为测试样本的分类结果。该算法流程设计如图2所示。
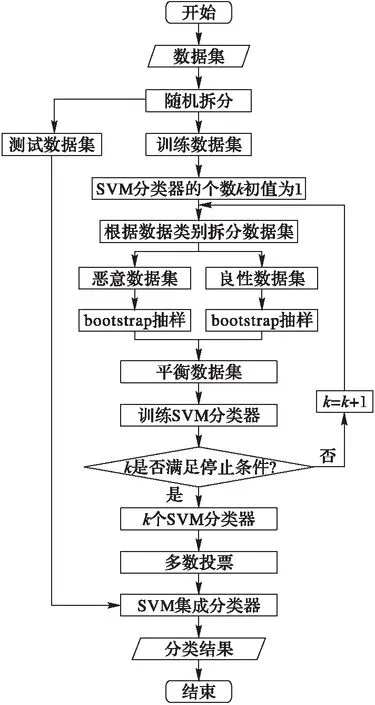
图2 Bagging-SVM算法流程 Fig. 2 Bagging-SVM flow chart
3.2 处理流程设计
为提高分类检测模块的执行效率,本文采用线性支持向量机(Linear Support Vector Machine, LSVM)设计基于Bagging-SVM分类检测模块,模块设计如下:
输入:筛选后的数据集D;
输出:测试集的分类结果O。
步骤1 随机从D中抽取80%的数据组成训练集D_train,剩余的20%组成测试集D_test,根据数据类别拆分D_train为良性数据集Db和恶意数据集Dm,即D_train={Db,Dm}。
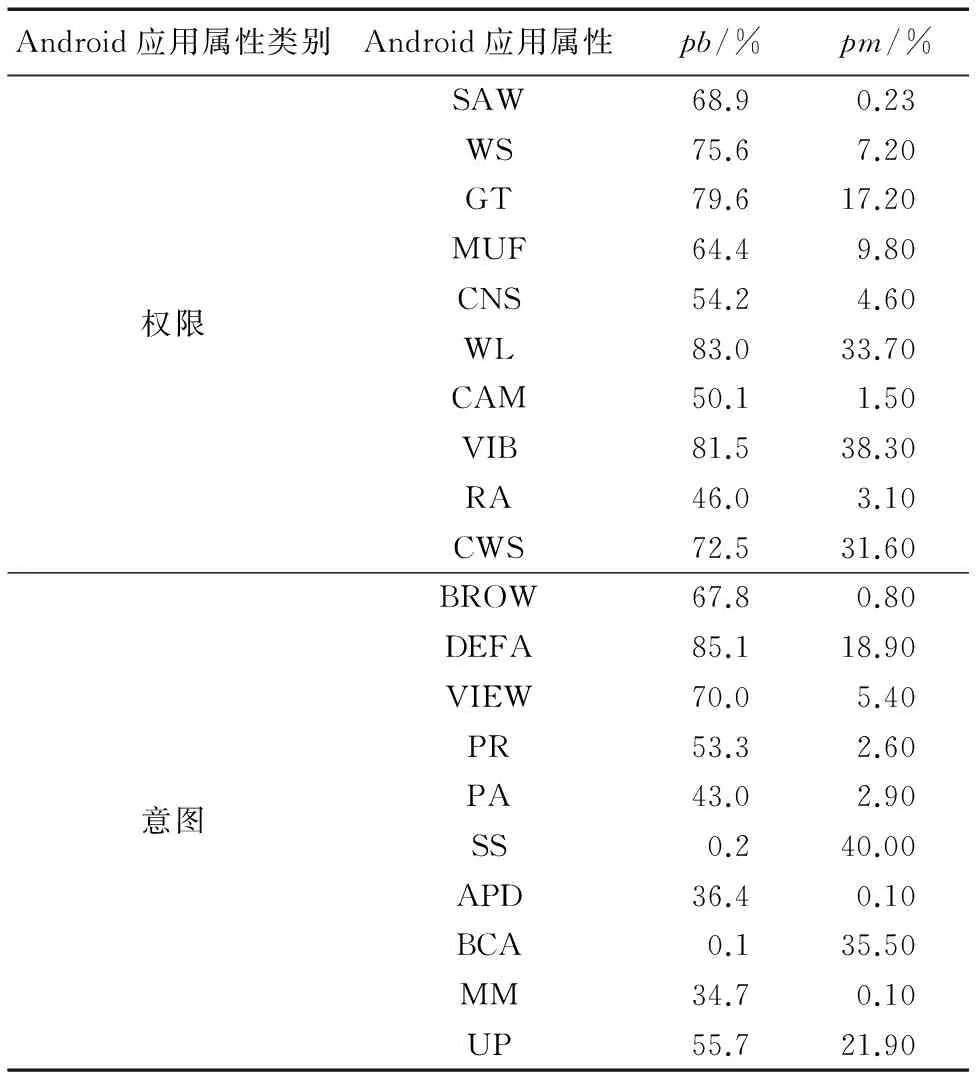
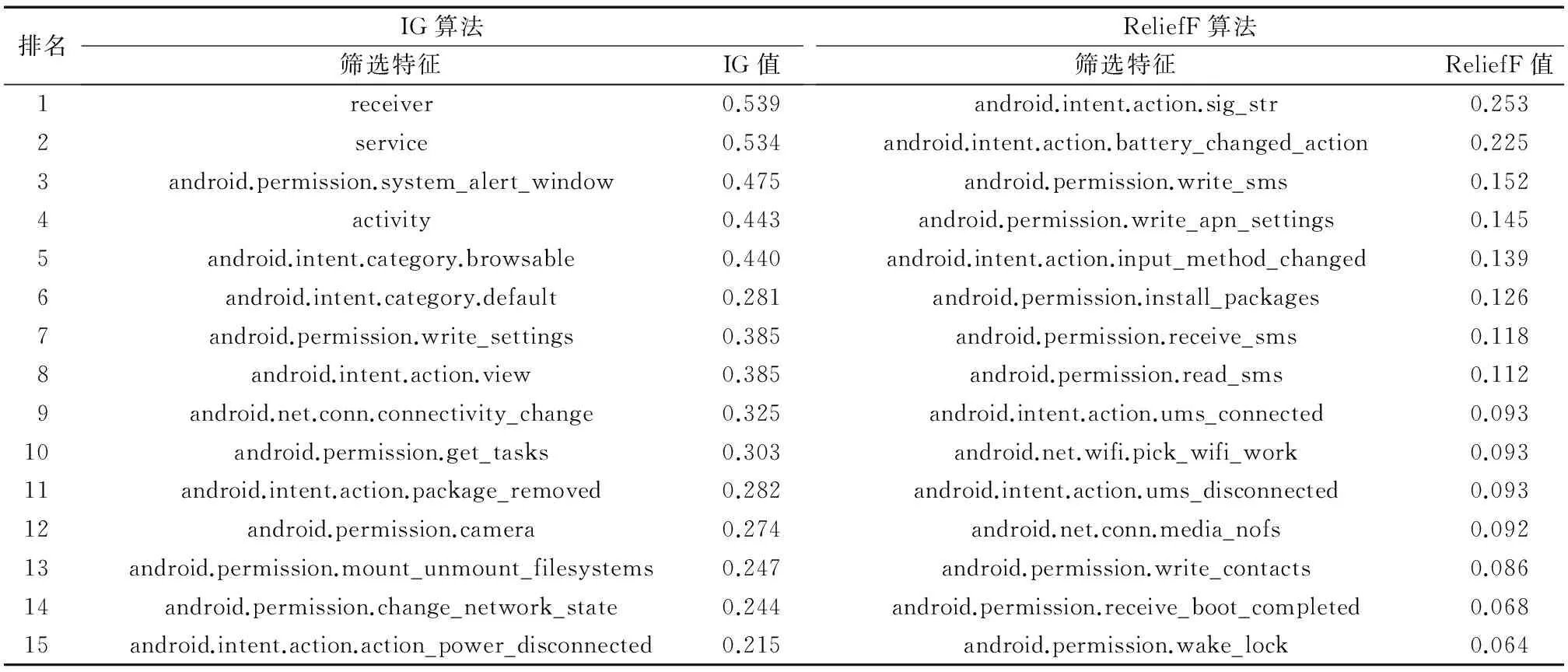
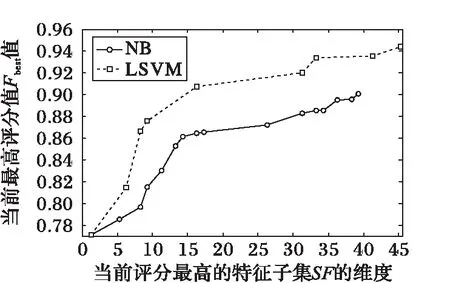
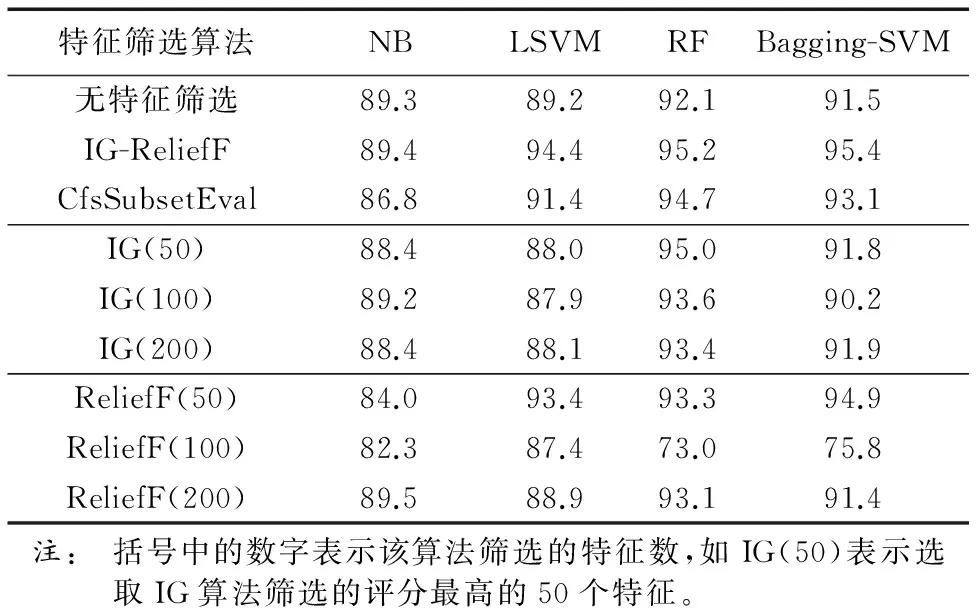
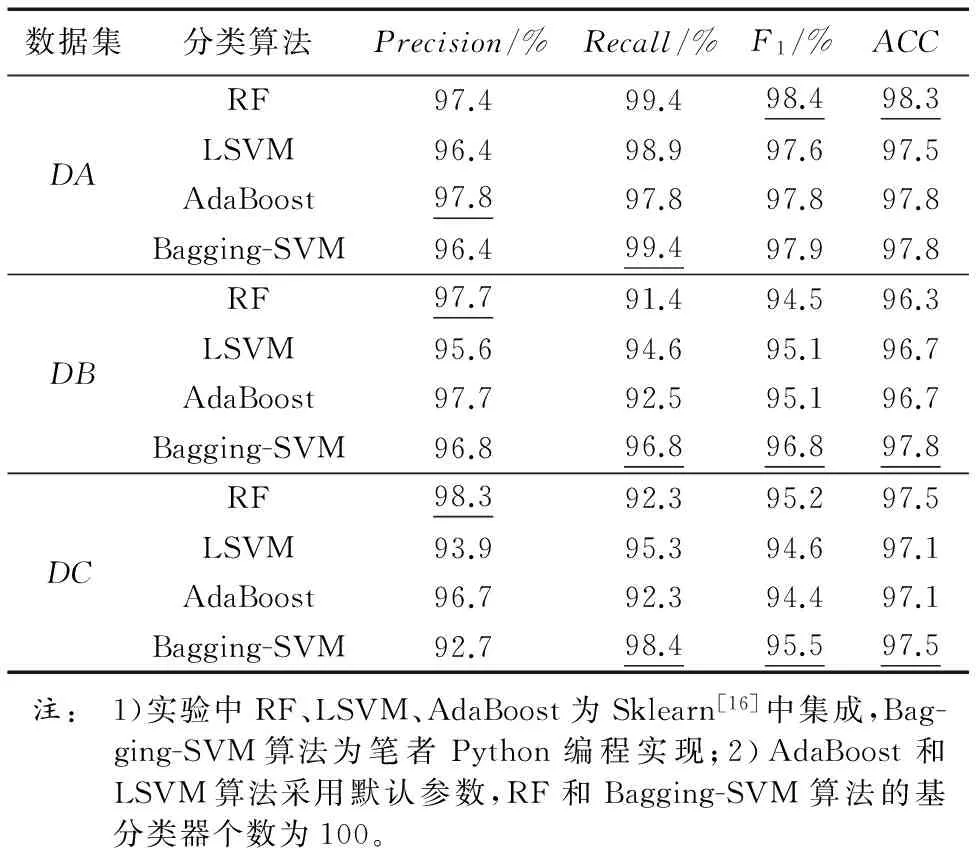
步骤2 设m和b分别表示Dm和Db中样本的个数。为实现bootstrap抽样,采用随机数发生器产生两组m个可重复的正整数IMi(i=1, 2, …,m)和IBi(i=1, 2, …,m),其中0 步骤3 以IMi作为待抽取的恶意样本的序号,以IBi作为待抽取的良性样本的序号,执行抽取过程得到m个良性数据和m个恶意数据,合并组成新的待训练数据集Di。 步骤4Di中的任意一个样本表示为(xi,yi)(i=1, 2, … ,m),其中xi=(xi1,xi2, …,xip)T对应第i个训练样本的属性集,yi∈{0, 1}表示该Android样本的类别,则SVM模型可表示为: (6) 其中:α为惩罚项,采用二次规划法求解该模型得到拉格朗日乘子λi,则LSVM基分类器C的参数w和c可由式(7)和(8)求解: (7) (8) 基分类器C表示为: (9) 步骤5 重复执行k次步骤2~4得到k个LSVM基分类器C,将k个基分类器C组合成SVM集成分类器C*。 步骤6 针对D_test中的每个测试样本x,将x输入SVM集成分类器C*中的k个基分类器中,计算k个基分类器的投票结果O,输出分类结果O。其中,投票公式为: C*(x)=vote(C1(x),C2(x),…,Ck(x))= (10) 本实验使用Jiang等[14]收集自Android恶意软件基因组项目的Android恶意软件,共计1 260个样本,从中随机抽取1 000个组成恶意数据集。良性Android软件来源于Google官方应用市场和360应用市场,使用Python编写爬虫脚本,分3次共下载4 500个不同的Android应用,使用kingsoft和F-scure对所有Android应用扫描,从中筛选出4 000个良性软件(被两种软件都判定为良性)组成良性样本集。将二者合并组成实验数据集。 实验中主机配置为Intel Core i5-3570 CPU @ 3.40 GHz,内存4 GB,特征提取及分类检测通过Python编程实现,特征筛选是在Weka[15]环境下完成。 按照2.1节的特征提取算法提取数据集,其中包含5 000个样本,每个样本有917个特征。为了便于对样本使用的特征统计分析,首先计算使用特定属性(权限或意图)的良性样本占良性样本总数的百分比pb,计算使用该属性的恶意软件所占恶意样本总数的百分比pm,统计所有属性中,pb和pm差值最大的前10个权限和意图如表1所示;然后计算平均每个恶意样本使用组件的个数nm和平均每个良性样本使用组件的个数nb,结果如表2所示。表1中所有的应用属性均采用缩写,权限{CWS, RA, VIB, CAM, WL, CNS, MUF, WS, GT, SAW}分别对应{CHANGE_WIFI_STATE, RECORD_AUDIO, VIBRATE, CAMERA, WAKE_LOCK, CHANGE_NETWORK_STATE, MOUNT_UNMOUNT_FILESYSTEMS, WRITE_SETTINGS, GET_TASKS, SYSTEM_ALERT_WINDOW},意图{PR, BCA, MM, APD, SS, PA, UP, VIEW, DEFA, BROW}分别对应{ PACKAGE_REMOVED, BATTERY_CHANGED_ACTION, MEDIA_MOUNTED,ACTION_POWER_DISCONNECTED, SIG_STR, PACKAGE_ADDED, USER_PRESENT, VIEW, CATEGORY.DEFAULT, BROWSABLE}。 表1 Android应用常用属性值统计Tab. 1 Attribute value statistics of Android software commonly used 表2 平均每个软件样本使用组件个数统计Tab. 2 Average number statistics of components per software sample 由表1可见,使用百分比差别最大的前10个权限是SYSTEM_ALERT_WINDOW(该权限允许Android软件显示系统窗口)、WRITE_SETTINGS(该权限允许读写系统设置项)和GET_TASKS(该权限允许Android软件获取当前或最近运行的软件)等安全威胁小且是常用软件必须的权限,这些权限良性软件使用百分比都超过50%,而恶意软件的使用量却较少。 由表1可见,使用百分比差别最大的前10个意图中有8个意图良性软件的使用百分比远高于恶意软件的使用百分比,这8个意图为BROWSABLE、VIEW和MDEIA_MOUNTED等实现常用功能必要的意图。剩余2个意图为SIG_STR和BATTERY_CHANGED_ACTION,这2个意图恶意软件的使用百分比远大于良性软件的使用百分比,这主要是由于恶意软件意图的触发事件大多是电池状态改变和手机信号状态改变等不易被察觉的事件。 由表2可见,大多数Android软件使用activity、service和receiver 3个组件,但平均每个软件使用的个数是有差别的,值得注意的是恶意软件使用的activity组件数远小于良性软件使用的activity组件数。 综上,本文模型所提取的权限(Permission)、意图(Intent)和组件(Component)属性特征可以明显地区分良性和恶意软件,适用于Android恶意软件检测。 4.3.1 特征筛选实验 本文采用的IG-ReliefF特征筛选算法对数据集处理,将数据集的特征由筛选前的917个降至筛选后的45个。 在特征筛选实验中,首先采用IG和ReliefF算法对917个特征进行评分,分值越高代表特征越优,2种算法评分最高的15个特征如表3所示。 表3 IG算法和ReliefF算法特征评分结果Tab. 3 Feature score results of IG algorithm and ReliefF algorithm 对比2种算法的评分结果,在IG算法中组件特征(receiver, service, activity)的排名较高,说明该特征对于分类结果的信息增益[10]较大,即单个该特征即可较好地区分良性软件和恶意软件。而在ReliefF算法中,由于ReliefF算法更多地考虑特征间的相关性,而组件特征与其他特征的相关性弱,所以ReliefF算法对组件的评分低。总体而言2种算法的评价标准不同,特征排名次序存在差异。 其次,为最大限度地搜索出最优特征子集,在筛选过程中设置最大迭代次数为917,然后分别采用LSVM和NB分类器进行特征筛选,实验中当前最优特征子集SF的评分变化趋势如图3所示。 图3 当前最优特征子集的评分变化趋势 Fig. 3 Scores variation trend of current optimal feature subset 由图3可见,LSVM在SF的维度为45时达到最大值,NB在SF维度为38时达到最大值,但是采用NB算法时的特征子集的评分较低,因此分类检测实验采用LSVM算法筛选的45个特征作为筛选结果。 4.3.2 特征筛选算法对比实验 为评估特征筛选模块的筛选效果,分别进行9组对比实验。9组实验中采用的特征筛选算法分别为:无特征筛选法、IG-ReliefF混合筛选算法、Weka中集成的CfsSubsetEval算法、IG算法和ReliefF算法;分类算法分别为:NB、LSVM、RF和Bagging-SVM算法;实验数据选用特征筛选后的数据全集,采用10折交叉验证法训练分类器并获取分类结果,采用不同特征筛选算法的4种分类算法的分类实验结果如表4所示。 由表4可见,使用LSVM、RF和Bagging-SVM算法时分类效果较好,而且相比其他筛选算法,使用本文提出的IG-ReliefF混合筛选算法分类效果最优;同时,使用NB算法结合IG-ReliefF时分类效果与最优筛选相差不大。说明本文提出的IG-ReliefF混合筛选算法可剔除大量无关特征,有利于提高分类检测的效果。 表4不同分类算法F1值比较% Tab. 4 Comparison of F1 value by different classification algorithms % 为验证本文模型对Android恶意软件检测的有效性,进行3组检测实验,实验步骤设计如下: 步骤1 对筛选特征后的数据集D抽样构造3个数据集DA、DB和DC,3个数据集中恶意数据为恶意数据全集,包含1 000条数据;良性数据为分别从包含4 000条数据的良性数据全集中无放回随机抽取的1 000、2 000和4 000条数据。 步骤2 对DA、DB和DC无放回抽样构造样本数相等的10份数据,9份为训练集,剩余1份为测试集。 步骤3 将Bagging-SVM算法分别与Android恶意软件检测中常用的集成式机器学习算法RF和AdaBoost对比,并与基分类器采用的LSVM算法对比,训练相应的4种分类器。 步骤4 采用4种分类器对测试集分类,获得分类结果,计算分类检测的评估指标Precision、Recall、F1和ACC。 步骤5 重复执行10次步骤2~4并计算10次分类检测结果中Precision、Recall、F1和ACC的平均值,结果如表5所示。 表5 分类效果比较Tab. 5 Classification effects comparison 由表5可见,采用平衡数据集DA分类检测时,4种分类器的分类效果较好,且Bagging-SVM分类器的分类结果在检出率、F1和分类精度3个指标上优于LSVM分类器;采用不平衡数据集DB和DC分类检测时,随着不平衡度的增加,4种分类器的检测效果都有降低,但Bagging-SVM分类器在检出率、F1和分类精度3个评估指标上均优于其他分类器。由于恶意软件被误报为良性软件造成的威胁远高于良性软件被误报为恶意软件,而较高的恶意软件检出率表明较少的恶意软件被误报为良性软件,所以Bagging-SVM算法通过降低一定的准确率换取高的检出率在Android恶意软件检测中是有意义的。 根据上述实验结果可见,本文提出的Android恶意软件检测模型在数据不平衡时仍具有较高的检出率和分类精度,能够检测出绝大多数恶意软件。 本文针对Android平台恶意软件泛滥以及现有分类算法检出率低等问题,提出基于Bagging-SVM的Android恶意软件检测模型。模型选取权限、意图和组件等属性作为特征提高了对Android软件的区分度,采用IG-ReliefF混合筛选算法最大限度地剔除了冗余和无关特征,运用Bagging-SVM集成分类器解决数据不平衡问题导致的分类检出率低的问题。实验证明本文模型在样本数据不平衡时仍具有较高的检出率和分类精度。 未来将在更大的Android软件样本数据空间并采用不同的不平衡方法开展实验研究。 参考文献(References) [1] 卿斯汉. Android 安全研究进展 [J]. 软件学报, 2016, 27(1): 45-71.(QING S H. Research progress on Android security [J]. Journal of Software, 2016, 27(1): 45-71.) [2] 张怡婷, 张扬, 张涛, 等. 基于朴素贝叶斯的Android软件恶意行为智能识别 [J]. 东南大学学报(自然科学版), 2015, 45(2): 224-230.(ZHANG Y T, ZHANG Y, ZHANG T, et al. Intelligent identification of malicious behavior in Android applications based on naive Bayes [J]. Journal of Southeast University (Natural Science Edition), 2015, 45(2): 224-230.) [3] 杨欢, 张玉清, 胡予濮, 等. 基于多类特征的Android应用恶意行为检测系统 [J]. 计算机学报, 2014, 37(1):15-27. (YANG H, ZHANG Y Q, HU Y P, et al. A malware behavior detection system of Android applications based on multi-class features [J]. Chinese Journal of Computers, 2014, 37(1): 15-27.) [4] WOLFE B, ELISH K, YAO D. High precision screening for Android malware with dimensionality reduction [C]// ICMLA 2014: Proceedings of the 2014 13th International Conference on Machine Learning and Applications. Piscataway, NJ: IEEE, 2015: 21-28. [5] ARORA A, PEDDOJU S K. Minimizing network traffic features for Android mobile malware detection [C]// ICDCN ’17: Proceedings of the 18th International Conference on Distributed Computing and Networking. New York: ACM, 2017: Article No. 32. [6] 杨宏宇,徐晋.基于改进随机森林算法的Android恶意软件检测 [J].通信学报,2017,38(4):8-16.(YANG H Y, XU J. Android malware detection based on improved random forest [J]. Journal on Communications, 2017, 38(4): 8-16.) [7] 乔静静.Android未知恶意软件检测方法的研究[D].北京:北京工业大学,2013:39-48.(QIAO J J. Research of unknown malware detection on Android [D]. Beijing: Beijing University of Technology, 2013: 39-48.) [8] 张巍,任环,张凯,等.基于移动软件行为大数据挖掘的恶意软件检测技术[J].集成技术,2016,5(2):29-40.(ZHANG W, REN H, ZHANG K, et al. Malware detection techniques by mining massive behavioral data of mobile Apps [J]. Journal of Integration Technology, 2016, 5(2): 29-40.) [9] FEIZOLLAH A, ANUAR N B, SALLEH R, et al. A review on feature selection in mobile malware detection [J]. Digital Investigation, 2015, 13: 22-37. [10] LUO Y X. Malicious detection based on ReliefF and boosting multidimensional features [J]. Journal of Communications, 2015, 10(11): 910-917. [11] 丰生强.Android软件安全与逆向分析[M]. 北京:人民邮电出版社,2013:20-28.(FENG S Q. Android Software Security and Reverse Analysis [M]. Beijing: Post & Telecom Press, 2013:20-28.) [12] HE H, GARCIA E A. Learning from imbalanced data [J]. IEEE Transactions on Knowledge & Data Engineering, 2009, 21(9): 1263-1284. [13] BREIMAN L. Bagging predictors [J]. Machine Learning, 1996, 24(2): 123-140. [14] JIANG X, ZHOU Y. Dissecting Android malware: characterization and evolution [C]// SP ’12: Proceedings of the 2012 IEEE Symposium on Security and Privacy. Washington, DC: IEEE Computer Society, 2012: 95-109. [15] 袁梅宇.数据挖掘与机器学习:WEKA应用技术与实践[M].北京:清华大学出版社,2016:329-344.(YUAN M Y. Data Mining and Machine Learning: WEKA Application Technology and Practice [M]. Beijing: Tsinghua University Press, 2016: 329-344.) [16] PEDREGOSA F, GRAMFORT A, MICHEL V, et al. Scikit-learn: machine learning in Python [J]. Journal of Machine Learning Research, 2011, 12(10): 2825-2830. This work is partially supported by the Science and Technology Foundation of Civil Aviation Administration of China (MHRD201205). XIELixia, born in 1974, M. S., associate professor. Her research interests include network and information security. LIShuang, born in 1990, M. S. candidate. His research interests include network and information security.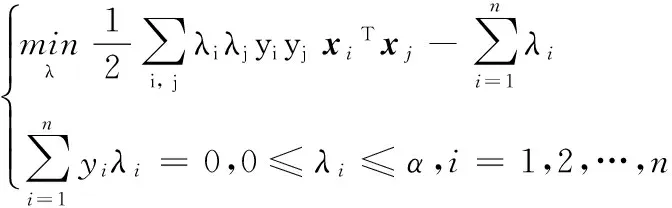
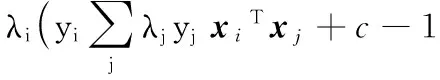
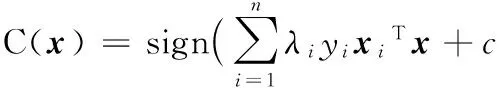
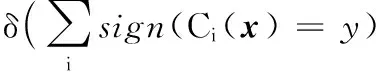
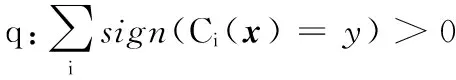
4 实验与结果
4.1 样本和环境配置
4.2 数据集提取及分析
4.3 特征筛选及模块评估
4.4 检测实验
5 结语
猜你喜欢
中老年保健(2022年6期)2022-08-19
昆明医科大学学报(2022年4期)2022-05-23
电子产品世界(2022年4期)2022-04-21
昆明医科大学学报(2021年12期)2021-12-30
内蒙古林业(2021年6期)2021-06-26
现代临床医学(2021年2期)2021-03-29
计算机系统应用(2021年2期)2021-02-23
昆明医科大学学报(2021年1期)2021-02-07
天津医科大学学报(2021年1期)2021-01-26
电子技术与软件工程(2017年14期)2017-09-08
