
基于聚类和改进共生演算法的云任务调度策略
2018-05-21 00:50李昆仑关立伟郭昌隆
计算机应用 2018年3期
李昆仑,关立伟,郭昌隆
(河北大学 电子信息工程学院,河北 保定 071000)
0 引言
云计算是近几年发展起来的一种按需共享信息服务模式,是未来网络服务的重要形式[1]。云计算系统将不同物理位置上的资源整合为一个逻辑整体,为用户提供一体化应用服务,因此,云环境中的任务调度与资源分配关系着整个云平台的使用效率,其模型的优劣直接关系到云计算系统是否能够提供有效的、可靠的服务,任务调度是云计算的关键技术之一[2-4]。
在云环境中,以遗传算法(Genetic Algorithm, GA)和粒子群优化(Particle Swarm Optimization, PSO)算法等为代表的群体优化算法被广泛地应用于解决调度问题并取得了可观的效果[5-8]。这些算法往往单一考虑调度代价,云计算的目标是按需提供服务,单纯的计算时间、通信消耗或负载均衡无法满足现实需求。因此,基于服务质量(Quality of Service, QoS)的调度算法被相继提出,主要分为基于成本的QoS和基于用户满意度的QoS。基于成本的QoS综合考虑执行时间、负载均衡、资源利用率等,如文献[9]提出一种基于成本的QoS驱动算法,算法不仅考虑了最大完工时间和负载均衡,还考虑了对任务进行分配时的时间和通信损耗,减小了调度代价。文献[10]提出一种多QoS约束的调度算法,以执行时间和资源利用率作为约束条件,并在动态环境中依据用户预算和截止期限来完成对任务的调度,保证了较高的资源利用率和较少的调度时间。基于用户满意度的QoS指在用户能在期望时间内完成任务的前提下,使用户的综合满意值最高。王娟等[11]为了满足不同用户的QoS偏好,提出了一种具有偏好感知的粒子群算法,该算法为防止占有率较高的任务偏好掩盖占有率低的任务,采用了按优先级分别调度任务,提升了用户的QoS。而文献[12]同样将用户按QoS进行分类并对类别按优先级来进行调度,与文献[11]不同的是该算法设定了类间与类内的双优先级,进一步提升了用户的满意度。
以上基于QoS的算法满足了不同场景的调度需求,但进行调度的任务面向全体服务资源,存在选择开销和计算量较大的问题。现有研究表明,对资源进行聚类预处理是解决该问题的有效方式,如杜晓丽等[13]提出的有向无环图(Direct Acyclic Graph, DAG)任务调度算法,陈志刚等[14]提出的资源多维性能聚类任务调度算法,以及李文娟等[15]和郭凤羽等[16]采用的基于模糊聚类的云任务调度算法等。这些算法证明引入聚类操作可降低任务调度开销,为本文提供了有益参考。因此,本文算法旨在解决以下问题:1)传统调度算法未综合考虑用户满意度与调度成本,没有完全体现云计算廉价按需服务的宗旨;2)智能算法对资源的选择开销大,收敛速度慢。基于聚类的算法执行代价小,但寻求最优分配能力往往低于智能算法。故当处理的任务量增加,传统算法不能平衡执行代价与寻优能力间关系。
针对上述问题,提出一种基于聚类和改进共生演(Symbiotic Organisms Search, SOS)算法的云任务调度策略。以提升云系统性能和云用户满意度为目标构造评价函数,进一步体现云计算廉价按需服务的宗旨。将任务与资源进行聚类处理,减小对资源的选择开销、提高收敛速度;依据改进的共生演算法进行细节处理,加强算法寻优能力。对比实验表明,综合聚类操作和共生演算法优点的调度策略拥有较快的收敛速度和较强的寻优能力,验证了本文算法在基于批量模式的云任务调度问题上的有效性。
1 云计算任务调度模型
目前,Google提出的MapReduce编程模式[17]是目前云环境中应用最广的编程模型,其基本执行过程如图1所示。
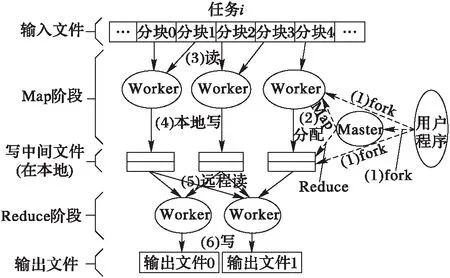
图1 Map/Reduce 云任务调度模型 Fig. 1 Map/Reduce cloud task scheduling model
Mapreduce共有6个过程,分为两个阶段:Map阶段和Reduce阶段。Map阶段将一个较大任务通过Map/Reduce函数分成N个较小任务并分配给多个Worker并行执行,然后输出中间文件保存在本地。Reduce阶段将Map阶段处理的结果进行分析和汇总并输出最终结果。
依据上述模型,任务与资源可描述如下:
T={t1,t2,…,tn}表示待处理的任务集合,n=|T|代表子任务数,第i个任务刻画为ti={tlength,tsource,tstorage},其中tlength表示任务长度,tsource表示传输数据量,tstorage表示所需存储空间。
R={r1,r2,…,rm}为云环境中的可用资源,m=|R|代表有效资源数。第j个资源rj(j∈[1,m])可以进一步刻画为rj={rcomput,rbandwidth,rstorage}。其中:rcomput为资源的计算能力,rbandwidth为资源的传输能力,rstorage表示资源的存储能力。
2 基于聚类和改进共生演的云任务调度策略
2014年,Cheng等[18]通过模仿自然界中不同生物间关系,提出一种新型优化算法——共生演(Symbiotic Organisms Search, SOS)算法。SOS算法最初用来解决复杂函数的优化问题,其易于实现且鲁棒性强,已被相继用来解决旅行商问题(Travelling Salesman Problem, TSP)、结构优化问题和控制问题等[19-22]。
2.1 标准共生演算法
SOS算法包含共生、共栖和寄生3个过程,描述如下。
共生过程:
Xinew=Xi+rand(0,1)*(Xbest-Mutual_Vector*BF1)
(1)
Xjnew=Xj+rand(0,1)*(Xbest-Mutual_Vector*BF2)
(2)
Mutual_Vector=(Xi+Xj)/2
(3)
其中:Xi为第i个个体,Xj是随机与Xi相作用的个体。rand(0,1)是[0,1]间的随机数,BF1和BF2取值为1或2。
共栖过程:
Xinew=Xi+rand(-1,1)*(Xbest-Xj)
(4)
其中:rand(-1,1)为[-1,1]随机数,(Xbest-Xj)反映一种受益关系,由Xj提供信息提升Xi的存活率。
寄生过程:
Xinew=Xp
(5)
Xp为系统中个体通过随机修改不同维数中的数值产生,能够增加种群多样性,防止陷入局部最优。
2.2 共生演算法的改进
文献[23]采用式(6)对SOS算法进行离散化,并证明在解决云任务调度问题时,离散共生演算法(Discrete Symbiotic Organisms Search, DSOS)相比PSO等智能算法能够得到更好的调度结果。本文以DSOS作为基本算法并对其进行以下改进,可进一步提高收敛速度和减小算法陷入局部最优的概率。
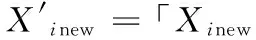
(6)
Xinew为更新个体,「⎤为ceil函数,mod为求余函数。
2.2.1 考虑潜在解的离散共生演算法
DSOS是一个更新与淘汰的过程,直接淘汰适应度低个体可能会损失潜在优秀解。如图2,黑色标记代表已找到最优分配位置,灰色代表未找到最优分配,其中A1代表当前最优,A2、A3为相比较的个体。很明显A2适应度大于A3,但若要实现全部最优分配,A2需要改变两部分片段,A3只需改变一部分片段,所以在寻优速度上,A3很可能会大于A2。

图2 三种个体基因比较 Fig. 2 Comparison of three individual genes
为克服上述缺陷,本文提出一种交叉方式,尽量减小优秀潜在解的损失,见式(7):
(7)
其中:J(x)为判断函数,接受更优个体,G(x1,x2)为在x1,x2间进行交叉变异的函数,随机选取交叉点,为防止交叉后个体与当前最优相同,变异位在最优片段范围选取,Xi为第i代适应度更高个体,Xzi为第i代暂时淘汰个体,Xbesti为第i代最优个体。
2.2.2 旋转学习寻优操作
2.2.1节在一定程度上加强了算法的性能,但算法依然可能陷入局部最优。因此,为增强算法的勘探能力,补充种群多样性,本文用旋转学习机制(Rotation-Based Learning, RBL)更新个体。
旋转角度决定RBL性能,角度固定,则学习范围固定。DSOS前期探索能力强,后期弱,固定旋转不适用SOS算法高效更新,因此,本文采用自适应角度旋转:β=d·2*π/Iter,d取值1或-1,决定旋转方向,Iter为迭代次数。该角度设定满足算法前期大范围搜索和后期小范围搜索的情况。
如图3所示,b和a对应搜索空间的上下限,C为[a,b]中点,以C为圆心,(a+b)/2为半径作圆,设Z为N点坐标。
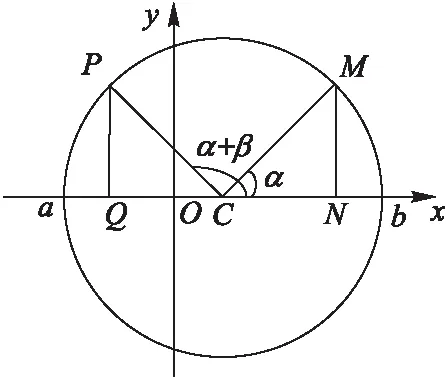
图3 二维空间中的旋转学习机制 Fig. 3 Rotational learning mechanism in two-dimensional space
将旋转学习机制嵌入到算法的操作为:
1)选取个体Xi对其每一维度都进行旋转学习,如下:
(8)
2)对M以旋转角度β进行旋转至P,点P在x轴上的投影Q为对应旋转学习的结果,则:
(9)
推广至高维情形,对应的旋转数可表示为:
z*=(ai+bi)/2-(μj×cosβ-νj×sinβ)
(10)
3)采用式(11)对学习点进行离散化,选取优秀个体进入下代种群:
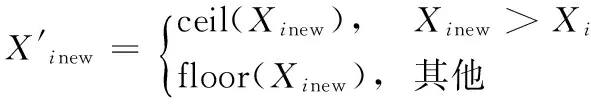
(11)
式(11)的离散方式更适合本文对β角的规定,实验表明该离散方式比直接采用ceil、floor或mod函数更有效。
2.3 资源与任务的模糊聚类
2.3.1 经典模糊C均值算法
模糊C均值(Fuzzy C-Means, FCM)是Bezdek于1981年提出[24],是基于目标函数聚类算法中较完善、应用较广的一种算法。任务或资源间没有确定的分界线,具有模糊特性,因此本文采用FCM对任务和资源进行模糊分类。FCM目标函数为:
(12)
其中:μij表示隶属度,ci是模糊组i的聚类中心,dij=‖ci-xj‖为第i个中心与第j个数据间的欧氏距离,m是一个加权指数。
2.3.2 资源的重排序放置与任务的模糊聚类
任务调度结果主要受资源计算能力、通信带宽和存储能力的影响,因此许多学者主要从处理能力、通信能力和存储能力三方面考虑资源的性能。本文参考文献[14-15],将资源模糊分为计算型资源、带宽型资源和存储型资源三类,并对其进行重排序放置,如图4所示。
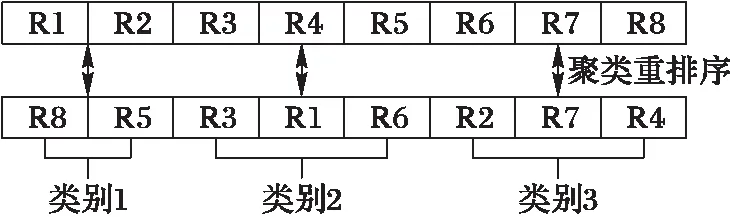
图4 资源的聚类重排序 Fig. 4 Clustering and reordering for resources
操作过程如下。
1)用式(13)对任务与资源进行模糊量化:
(13)
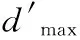
2)设置阈值t、迭代次数k和隶属度矩阵U,将资源分为R1、R2、R33类,将任务分为T1、T2、T3类。
3)依据类别相似度对资源集合按性能由高到低进行排序,并再次设定阈值t′,使满足‖tmi-tmc‖≤t′的任务i归入到第m(m=1,2,3)类,剩余任务纳入第4类,tmc为第m类聚类中心。
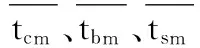
4)利用如下公式计算任务集需求度和资源综合能力:
(14)
(15)
5)按式(16)对任务进行指导分配;
da=‖tcd-rp‖
(16)
2.3.3 聚类的效用分析
受积木原理的启发,称聚类效用为积木效用,即在有限空间内放置积木块使积木高度最低。表1为初始化后相应资源拟分配到的任务,依据分配结果可将相对应任务量和资源的计算能力抽象为两组积木块组合,如图5将任务抽象为计算量积木,积木的长度代表对资源计算能力的需求。将资源抽象为性能积木,积木长度为处理单位任务量的时间消耗。
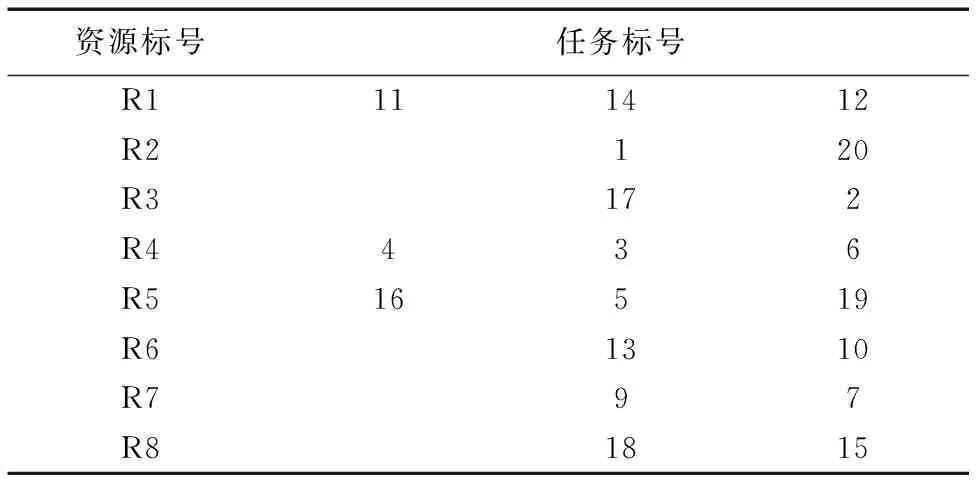
表1 资源所分配到的任务Tab. 1 Tasks assigned to resources
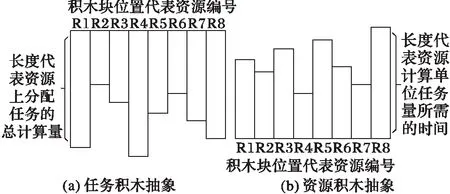
图5 任务与资源的积木抽象 Fig. 5 Task and resource abstract model
理想的调度结果是使完工时间最短且负载均衡,即任务积木与资源积木的最优垒积,如图6。
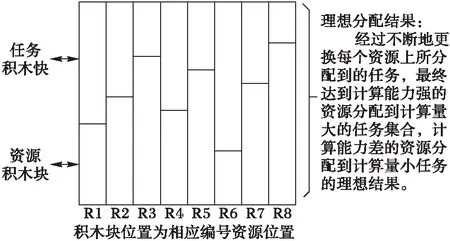
图6 理想分配效果 Fig. 6 Ideal assignment results
未经任何处理的资源初始化后任务分配没有任何规律,可看出得到由图5到图6的结果需要多次搜索且不一定能得到最优分配。针对该问题,本文采用聚类操作可在一定程度上改善算法性能。首先对资源进行聚类后按类间相似度和相邻资源差异度重新排序放置,使得资源在虚拟空间中按标号有规律地放置,如图7所示。
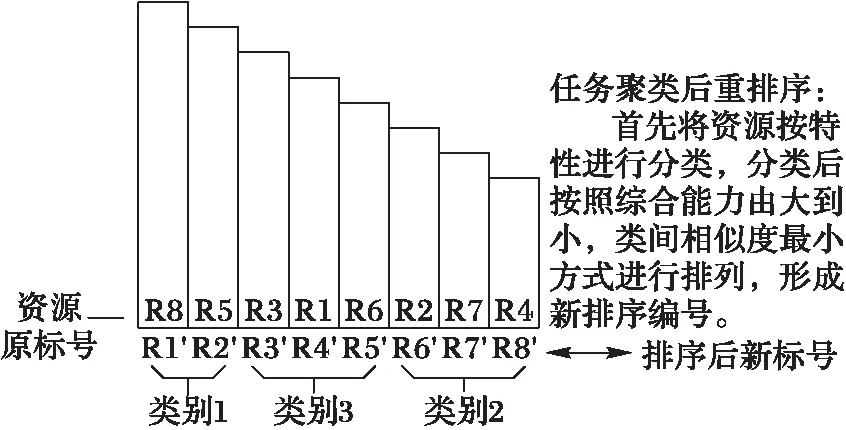
图7 资源聚类后重排序放置 Fig. 7 Reordered placement after resource clustering
对任务进行聚类后,同一类别任务对资源需求具有相似性,进行调度时必然偏向选取排序后资源的相似位置,使任务进行分配具有一定的目的性。经过指导迭代后便可得到如图8所示供需吻合的粗略结果。指导迭代是指通过计算任务集合对资源集合的需求来指导该类别任务在编码中的位置,以吻合相对应资源类别的迭代。
与传统算法不同,本文设定任务聚类集合为动态类集合,操作过程中同一类别任务依然可以选择非与该类最相似的资源集合,即某类任务较多时,可将部分任务调度到其他类资源进行处理,可保证系统的负载均衡。聚类后开始执行调度算法,每次调度针对同一类别任务进行(其他类别任务作为约束信息),因此称本步操作为细节搜索阶段。实验证明本文方法更易得到与资源吻合的理想结果,如图9所示。
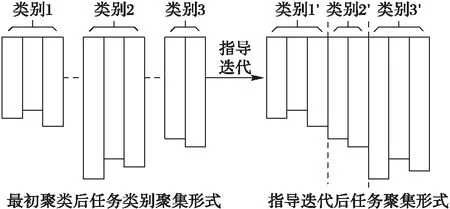
图8 聚类及指导迭代后任务聚集形式 Fig. 8 Task aggregation form after clustering and guided iteration
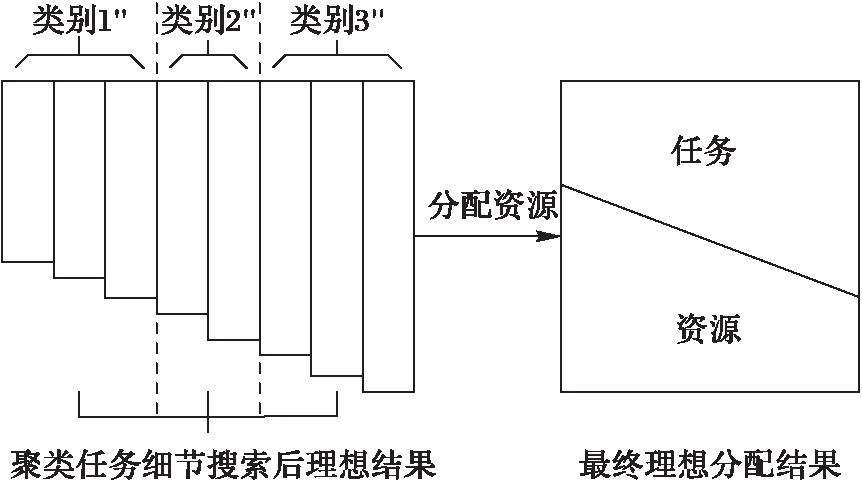
图9 最终理想分配结果 Fig. 9 Final ideal assignment results
聚类后不易进入局部最优的原因:本文改进的共生演算法主体用式(1)~(5)进行种群更新并利用式(6)进行离散化。由于算法的贪婪选择特性,算法后期种群中的个体具有极强的相似性,在空间随机选取的进行共生的两个个体可表示为Xi=Xs,Xj=Xs且Xbest=Xs,因此式(1)可描述如下:
Xinew=Xi+rand(0,1)*(Xbest-BF*(Xi+Xj)/2)=
Xs+rand(0,1)*(Xs-BF*(Xs+Xs)/2)=
Xs+rand(0,1)*(Xs-BF*Xs)
Xs-BF*Xs的取值为0或Xs,因此Xinew的取值范围为:
max(Xinew)=Xs+0*(Xs-BF*Xs)或
max(Xinew)=Xs+rand(0,1)*0=Xs
同理得到:
min(Xnew)=Xs+1*(Xs-2*Xs)=Xs-Xs=0
Xinew=Xi+rand(-1,1)*(Xbest-Xj)=
Xs+rand(-1,1)*(Xs-Xs)=Xs=Xi
上式表明共栖过程后期可能起不到更新种群的作用,前两步搜索不到的位置只能依靠寄生操作实现,但寄生操作不一定能够得到有效更新,算法在后期搜索效率低下。
对资源和任务进行聚类后上述问题得到改善,算法后期任务虽只能搜索到小于当前标号的资源,但是聚类后的资源聚集在相似位置,相似任务目的性地搜索资源,使算法后期依然以更大概率搜索到全局最优。本文又将资源按照处理能力由高到低的顺序排列如图7,使得处理能力强的资源能够被搜索到的概率更大,避免了处理能力强资源闲置的现象。因此,本文采取的聚类操可加强算法寻优能力。
2.4 编码策略
传统编码形式多为资源-任务间接编码形式,X={x1,x2,…,xN},其中N代表任务总数,xi代表第i个任务所分配的处理机标号。
本文采取聚类操作和指导迭代,每次进化操作均对同一类别个体进行,传统编码形式并不适应此操作,因此,本文提出一种可变资源-任务间接编码形式,X={xi1,xi2,…,xin}∪ {xj1,xj2,…,xjm}∪{xz1,xz2,…,xzp},其中i、j、z代表类别标号,n、m、p为每个类别的任务数,n+m+p=N,N为总任务数。
∪位置为可交换节点,片段染色体位置可更改,片段染色体针对相应类别个体进行编码产生。因此,依据指导迭代更新片段染色体位置,减小了对资源的选取范围,对片段内个体进行更新,可加强算法的细节搜索能力。
2.5 评价模型
为体现云计算廉价按需提供服务的宗旨,本文提出一种综合调度成本和用户满意度的驱动模型。
将同一物理平台或应用服务于尽可能多的用户,必须减小资源的空闲率,提高资源的整体使用率,从而使得成本降低,提升经济效益,故本文将任务的处理时间和资源利用率作为成本约束条件。其中时间指标函数为:
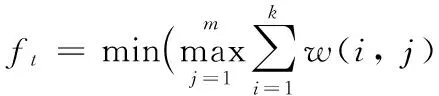
(17)
其中:m为资源数,k为第j个处理器上要处理任务的数量,w(i,j)表示第i个任务在第j个处理器上的时间损耗。资源利用率指标函数为:
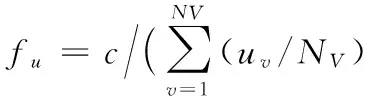
(18)
其中:NV为资源总数;uv表示第v个资源的综合利用率;实验发现资源利用率与时间消耗不处于同一数量级,因此采用加入权重c(本文取值15)的方式,使得二者数量级相同,因此调度代价适应度函数定义为:
Fd=min(α*ft+β*fu)
(19)
其中:α、β∈rand(0,1),α+β=1且α·β≠0。
为提升用户满意度,本文提出一种基于偏好的满意度模型。将任务按属性分为四类:计算型任务、带宽型任务、存储型任务和普通任务。计算型任务的评价准则为:
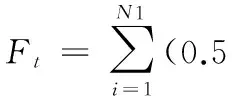
(20)
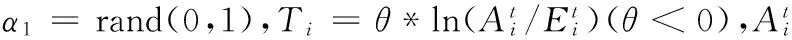
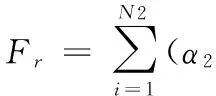
(21)
存储型任务的评价准则:
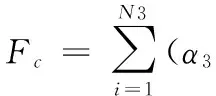
(22)
普通任务评价准则:
(23)
综合评价准则定义为:
Ftotal=max(Δ-(Ft+Fr+Fc+Fp)/N)
(24)
N1、N2、N3、N4为各类任务的数量,且N1+N2+N3+N4=N,Δ为满意度最优值,一般Δ=10。故本文的驱动模型为:
Fz=γ1*Ftotal-γ2*ε*Fd
(25)
其中:γ1、γ2为权重系数,ε为数量级调整系数。
2.6 算法流程
考虑任务数量大小对聚类效果的影响,算法设定任务数小于设定值NT(NT值取60~150时效果最佳)时直接采用改进的SOS算法,当任务数大于设定值NT时采用基于聚类的改进共生演算法——基于模糊C均值和改进共生演算法的云任务调度算法(Fuzzy c-means based and Improved Discrete Symbiotic Organisms Search algorithm, FIDSOS),具体过程描述如下。
1)参数初始化:设置种群大小Scale、迭代次数K、终止条件及各项参数。
2)算法选择与种群初始化:判断任务数目是否大于设定阈值NT,大于则进入步骤3),否则依据资源-任务整体编码方式生成初始种群并进入步骤4)。
3)对任务和资源进行模糊聚类并对资源进行重排序,依据任务的聚类结构按照可变资源-任务间接编码方生成初始种群,进行指导迭代后进入步骤4)。
4)依据改进DSOS算法对种群进行更新得到进化种群:
①按SOS算法过程对种群进行进化更新;
②对暂淘汰个体按式(7)进行更新操作;
③对当前优秀个体进行旋转寻优操作。
5)判断种群是否达到终止条件,达到则进入步骤6);否则返回步骤4)。
6)得到调度结果,计算满意度和调度代价。
3 实验与分析
3.1 实验环境及实验参数
参考文献[11-12]及[25-26]模拟搭建的云任务调度仿真系统及作者在文献[27]所做的前期工作,利用Matlab实现一个云任务调度仿真系统。仿真系统主要由任务产生器、资源产生器、故障干扰产生器、调度器和评价器5部分组成。任务产生器产生任务向量,任务属性包括任务大小等QoS因素,本文研究的是批任务。资源产生器可依据要求产生资源,资源属性包括:CPU频率(计算能力)、能提供的存储空间、带宽等。故障干扰产生器主要模拟网络中可能出现的故障,作用于资源,可影响资源属性。调度器接收到调度请求后对任务和可用资源进行标号并依据调度算法得到的结果将任务分配到资源上,然后更新节点值。评价器判断调度结果是否满足系统和用户需求。
仿真系统模拟10~1 000个任务在处理器上的执行情况。通过控制任务产生器将任务长度控制在[500,1 500]范围内,带宽需求控制在[100,500]内,存储需求控制在[200,1 000]内;同理,通过控制资源产生器,将资源的计算能力控制在[2 000,10 000]内,传输能力控制在[500,5 000]内,存储能力控制在[500,5 000]内。各项指标均按一定规则在上述范围内用模拟器随机生成。
将本文算法与改进遗传算法(Global Genetic Algorithm, GGA)、混合粒子群遗传算法(Hybrid Particle Swarm Optimization and Genetic Algorithm, PSO-GA)和基本DSOS算法进行对比分析。优化目标为最小代价和用户满意度。实验统一设置终止条件为最大迭代次数为400次或连续50次迭代差值小于0.001。算法具体参数参照表2。

表2 算法参数Tab. 2 Algorithm parameters
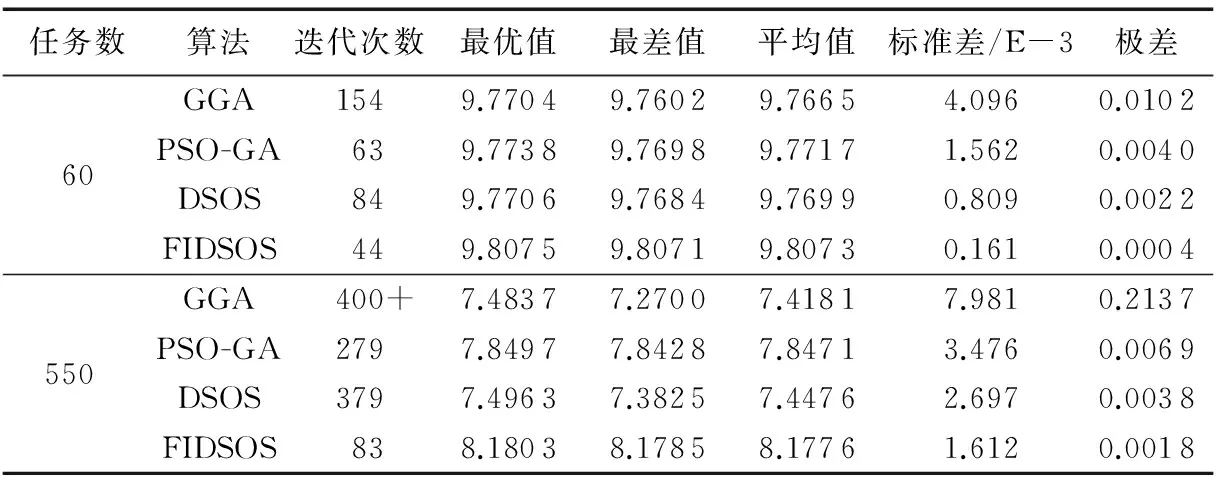
表3 不同任务数算法性能对比Tab. 3 Performance comparison with different number of tasks
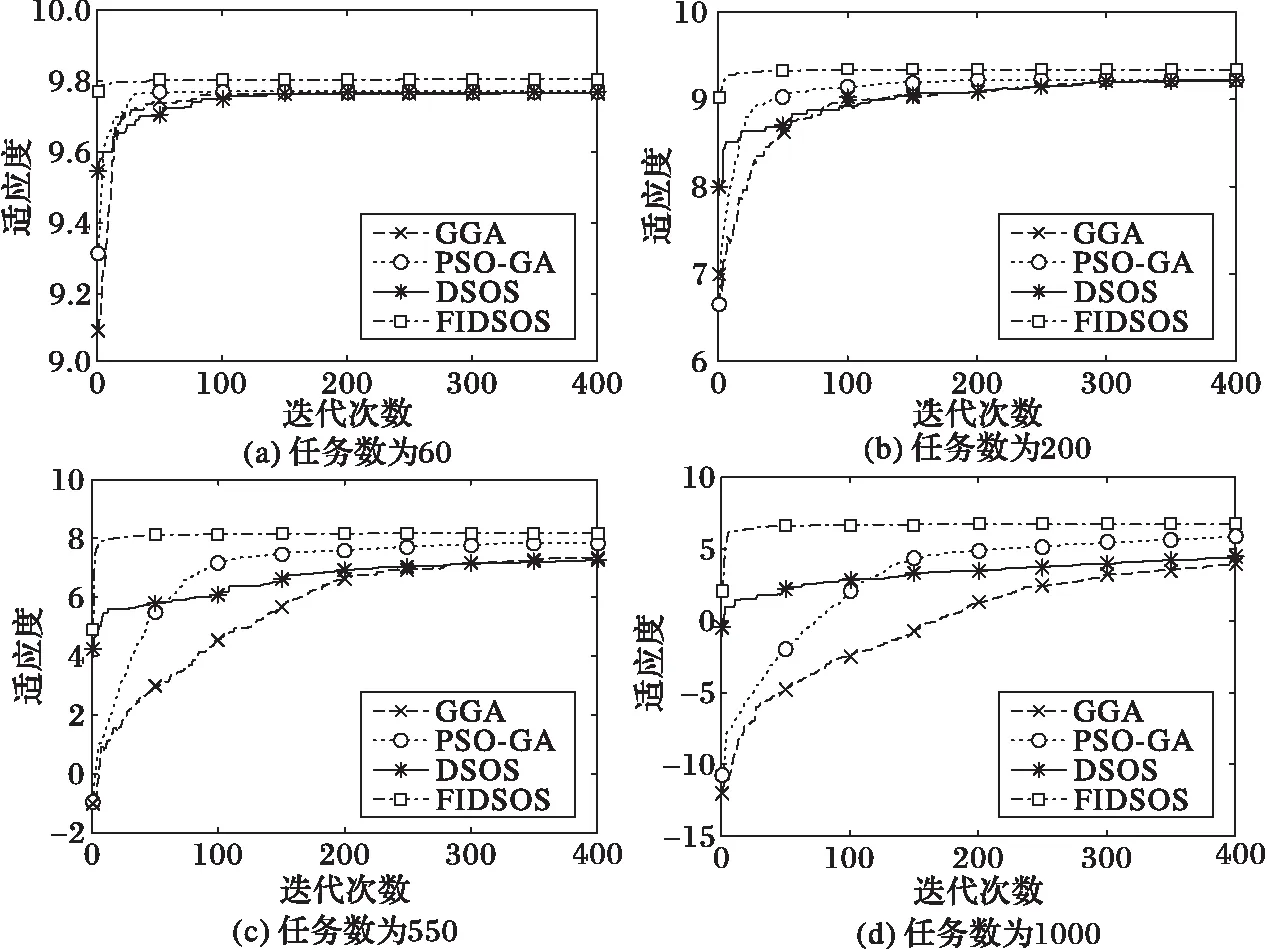
图10 任务数不同时适应度和迭代次数对比 Fig. 10 Fitness and iteration comparison with different number of tasks
其中改进GA中:
(26)
(27)
其中:fmax为最大的适应度值,favg为平均适应度值,f′为要交叉的两个个体中较大的适应度值,f为要变异个体的适应度值;PSO-GA算法中rand(0,1)代表在0~1随机取值;本文算法中fb=2*π/k,k为当前迭代次数。
3.2 实验结果分析
为防止特殊情况对实验结果的影响,所有实验各运行10次,记录调度成本值和用户满意度并取10次的平均值作为最终结果。
系统生成8个虚拟机资源和10、20、60、100、150、200、550、1 000个数目的子任务集合进行实验。
表3展示了任务数量为60和550时的算法性能,可知四种算法中GGA算法稳定性较差,其次为PSO-GA算法。DSOS算法和本文算法拥有较好的稳定性,且在任务数增加时本文稳定性所受影响较小。算法迭代次数和寻优能力对比如图10所示,为方便说明任务数大小对算法的影响,选取对比任务数为60、200、550和1 000 四个数目。可看出当任务数较少时四种算法的寻优能力相差不大,随着任务数的增加本文算法寻优能力优势越发明显。当任务数超过200后其他算法性能极度下降,性能下降最快的是遗传算法,而本文算法依然保持着较好鲁棒性和较强的寻优能力。遗传算法更新个体上依靠交叉和变异,交叉点和变异点数目的选取影响着算法速度,随着任务数目的增加若交叉点和变异点一成不变必然会导致算法寻优能力变差。而PSO算法和SOS算法依据各自的进化公式在相应的解空间上不断搜索最优解,寻优所受影响势必小于遗传算法,但由于搜索的无目的性和评价函数的影响,在任务数增加时依然会使得寻优能力变差。本文算法对资源和任务进行模糊聚类后,能在解空间上具有目的性的搜索,使得算法寻优速度快且不会因为由于任务数的增加而使得算法性能加速下降。
寻优速度不能完全说明算法优劣,本文旨在最小化调度代价的同时最大化用户满意度。由图11和图12知,任务较少时本文算法与其他三种算法在调度代价和用户满意度上相差甚微,只有当任务数增加到60时差别才开始显现,效果最差的为GGA算法,PSO-GA与DSOS算法效果相当,本文算法在调度代价和用户满意度上都有着较好结果。
随着任务规模逐渐增加,算法差异开始变得明显。由图13可看出在调度代价上DSOS算法与PSO-GA算法寻优能力相当,GGA算法表现最差,本文算法保持最优;但在用户满意度上(如图14所示),DSOS算法与GGA算法相当,均劣于PSO-GA算法,本文算法保持最优且优势愈发明显。
传统改进算法单一考虑系统性能或用户满意度,在以调度成本约束用户满意度的情况下可能产生不一样的优化结果,算法性能无法保证。本文采用基于聚类和改进共生演的算法能够在保持最小化调度代价的同时在解空间进行有目的性的搜索,可收敛到更优解,进而提高了用户的满意度。由此可见,FIDSOS算法具有更好的性能。
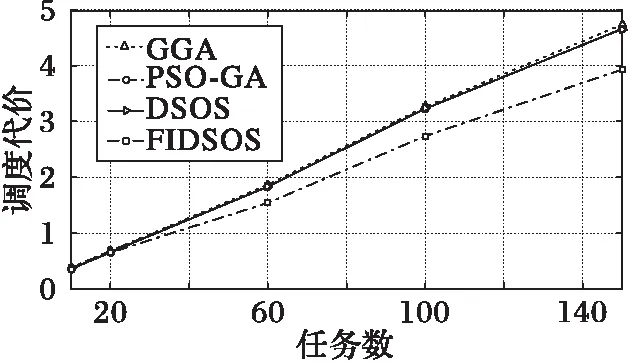
图11 任务较少时算法调度代价对比 Fig. 11 Cost comparison with less tasks
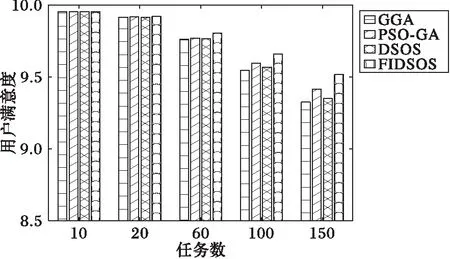
图12 任务较少时用户满意度对比 Fig. 12 Satisfaction comparison with less tasks
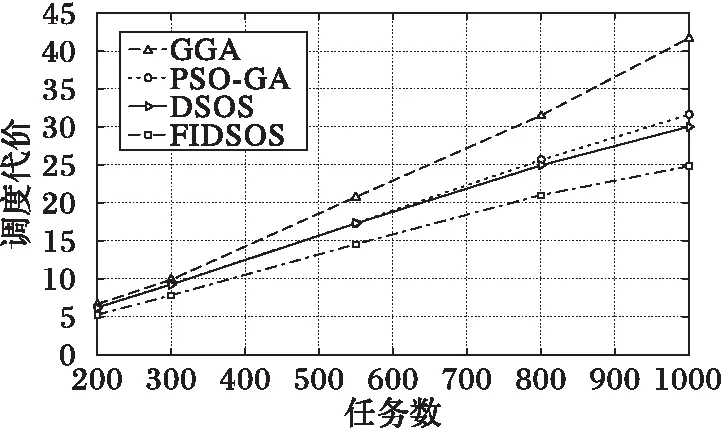
图13 任务较多时算法调度代价对比 Fig. 13 Cost comparison with more tasks
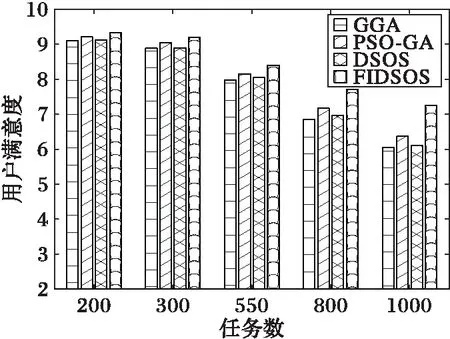
图14 任务较多时用户满意度对比 Fig. 14 Satisfaction comparison with more tasks
4 结语
针对现有一些调度算法未将调度代价和用户满意度综合考虑且容易陷入局部最优解、收敛慢的问题,提出一种在云环境下使用的任务调度算法。为提升算法精度,设置阈值NT,任务数量小于NT时直接采用改进共生演算法,任务数大于NT时采用基于聚类和改进的共生演算法。通过对任务和资源进行聚类,算法能对解空间进行目的性的搜索,进而提高算法的寻优速度。改进共生演算法考虑潜在优秀解可防止优秀解的丢失,最后对整个种群进行的旋转寻优操作,减小了算法陷入局部最优的概率,加强了算法的寻优能力。实验结果表明,相比改进的遗传算法GGA、PSO-GA算法和DSOS算法,本文算法在保持高收敛性能的前提上能够搜索到更为优秀的解,能够实现较小调度成本且能够提高用户的满意度。
参考文献(References)
[1] FOSTER I, ZHAO Y,RAICU I, et al. Cloud computing and grid computing 360-degree compared [C]// GCE’08: Proceedings of the 2008 Grid Computing Environments. Washington,DC: IEEE Computer Society, 2008: 1-10.
[2] BOCHENINA K. A comparative study of scheduling algorithms for the multiple deadline-constrained workflows in heterogeneous computing systems with time windows [EB/OL]. [2017- 04- 12]. http://pdfs.semanticscholar.org/c88f/93f927d69432276665f53a5203c6987e8594.pdf.
[3] DURAO F,FONSEKA A,GARCIA V C, et al. A systematic review on cloud computing [J]. Journal of Supercomputing, 2014, 68(3): 1321-1346.
[4] AVRAM M G. Advantages and challenges of adopting cloud computing from an enterprise perspective [EB/OL]. [2017- 04- 12].https://core.ac.uk/download/pdf/82662807.pdf.
[5] AHMAD S G, LIEW C S, MUNIR E U, et al. A hybrid genetic algorithm for optimization of scheduling workflow applications in heterogeneous computing systems [J]. Journal of Parallel and Distributed Computing, 2016, 87(C): 80-90.
[7] BRATTON D, KENNEDY J. Defining a standard for particle swarm optimization [C]// Proceedings of the 2007 IEEE Swarm Intelligence Symposium. Washington, DC: IEEE Computer Society, 2007: 120-127.
[8] XUE S-J, WU W. Scheduling workflow in cloud computing based on hybrid partial swarm algorithm [J]. TELKOMNIKA : Indonesian Journal of Electrical Engineering, 2012,10(7): 1560-1566.
[9] BANSAL N, MAURYA A, KUMAR T, et al. Cost performance of QoS driven task scheduling in cloud computing [EB/OL]. [2017- 04- 15]. http://core.ac.uk/download/pdf/82232227.pdf.
[10] ARABNEJAD H, BARBOSA J G. Multi-QoS constrained and profit-aware scheduling approach for concurrent workflows on heterogeneous systems [J]. Future Generation Computer Systems, 2017,68: 211-221.
[11] 王娟,李飞,张路桥.PSO应用于QoS偏好感知的云存储任务调度[J].通信学报,2014,35(3):231-238.(WANG J, LI F, ZHANG L Q. Apply PSO into cloud task scheduling with QoS preference awareness [J]. Journal on Communications, 2014, 35(3): 231-238.)
[12] GAMAL EL DIN HASSAN ALI H, SAROIT I A, KOTB A M. Grouped tasks scheduling algorithm based on QoS in cloud computing network [J]. Egyptian Informatics Journal, 2017, 18(1): 11-19.
[13] 杜晓丽,蒋昌俊,徐国荣,等.一种基于模糊聚类的DAG任务图调度算法[J].软件学报,2006,17(11):2277-2288.(DU X L, JIANG C J, XU G R, et al. A grid DAG scheduling algorithm based on fuzzy clustering [J]. Journal of Software, 2006, 17(11): 2277-2288.)
[14] 陈志刚,杨博.网络服务资源多维性能聚类任务调度[J].软件学报,2009,20(10):2766-2774.(CHEN Z G,YANG B. Task scheduling based on multidimensional performance clustering of grid service resources [J]. Journal of Software,2009, 20(10): 2766-2774.)
[15] 李文娟,张启飞,平玲娣,等.基于模糊聚类的云任务调度算法[J].通信学报,2012,33(3):146-153.(LI W J, ZHANG Q F, PING L D, et al. Cloud scheduling algorithm based on fuzzy clustering [J]. Journal on Communications, 2012, 33(3): 146-153.)
[16] 郭凤羽,禹龙,田生伟,等.云计算环境下对资源聚类的工作流任务调度算法[J].计算机应用,2013,33(8):2154-2157.(GUO F Y, YU L, TIAN S W, et al. Workflow task scheduling algorithm based on resource clustering in cloud computing environment [J]. Journal of Computer Applications, 2013, 33(8): 2154-2157.)
[17] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters [C]// OSDI ’04: Proceedings of the 6th Conference on Symposium on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2004: 10.
[18] CHENG M Y, PRAYOGO D. Symbiotic organisms search: a new metaheuristic optimization algorithm [J]. Computer and Structures, 2014,139: 98-112.
[19] EZUGWU E S, ADEWUMI A O, FRINCU M E. Simulated annealing based symbiotic organisms search optimization algorithm for traveling salesman problem [J]. Expert Systems with Applications, 2017,77: 189-210.
[20] YU V F, REDI A A N P, YANG C L, et al. Symbiotic organisms search and two solution representations for solving the capacitated vehicle routing problem [J]. Applied Soft Computing, 2017, 52(C): 657-672.
[21] TEJANI G G, SAVSANI V J, PATEL V K. Adaptive Symbiotic Organisms Search (SOS) algorithm for structural design optimization [J]. Journal of Computational Design and Engineering, 2016, 3(3): 226-249.
[22] GUHA D, ROY P, BANERJEE S. Quasi-oppositional symbiotic organism search algorithm applied to load frequency control [J]. Swarm and Evolutionary Computation, 2016,33: 46-67.
[23] ABDULLAHI M, NGADI M A, ABDULHAMID S M. Symbiotic organism search optimization based task scheduling in cloud computing environment [J]. Future Generation Computer Systems, 2016,56: 640-650.
[24] BEZDEK J C. Pattern Recognition with Fuzzy Objective Function Algorithms [M]. Norwell, MA: Kluwer Academic Publishers, 1981:10-18.
[25] 王娟,李飞,刘兵,等.融合层次分析法的PSO云存储任务调度算法[J].计算机应用研究,2014,31(7):2013-2016.(WANG J, LI F, LIU B, et al. AHP integrated PSO task scheduling algorithm in cloud storage system[J]. Application Research of Computers, 2014, 31(7): 2013-2016.)
[26] LI K. Scheduling parallel tasks with energy and time constraints on multiple manycore processors in a cloud computing environment [EB/OL]. [2017- 03- 01]. http://www.cs.newpaltz.edu/~lik/publications/Keqin-Li-FGCS-2017.pdf.
[27] 李昆仑,王珺,宋健,等.基于改进GEP和资源改变量的局部云任务调度算法[J].软件学报,2015,26(S2):78-89.(LI K L, WANG J, SONG J, et al. Local cloud task scheduling algorithm based on improved GEP and change of resources [J]. Journal of Software, 2015, 26(S2): 78-89.)
This work is partially supported by the National Natural Science Foundation of China (61672205).
LIKunlun, born in 1962, Ph. D., professor. His research interests include pattern recognition, image processing, computer network, intelligent information processing.
GUANLiwei, born in 1990, M.S. candidate. His research interests include cloud computing task scheduling, virtualization.
GUOChanglong, born in 1991, M. S. candidate. His research interests include data mining, recommendation algorithm.
猜你喜欢
吉林大学学报(信息科学版)(2022年2期)2022-08-15
计算机测量与控制(2022年2期)2022-03-30
小学生作文(低年级适用)(2020年10期)2020-11-10
福建基础教育研究(2019年2期)2019-09-10
福建基础教育研究(2019年2期)2019-05-28
软件导刊(2018年11期)2018-11-19
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
理科考试研究·初中(2017年4期)2017-11-04
互联网天地(2016年1期)2016-05-04
