
基于神经网络的井涌井漏实时预测方法研究
2018-05-18 05:51谢平蒋丽雯赵尧何海乐
现代计算机 2018年11期
谢平,蒋丽雯,赵尧,何海乐
(1.上海神开石油科技有限公司,上海 201112;2.上海计算机软件技术开发中心,上海 201112;3.南京航空航天大学计算机科学与技术学院,210016)
1 背景介绍
井涌井漏现象的发生会增加施工成本、延误工期甚至会造成人员伤亡,因此及时对井涌井漏现象进行预测可以为钻井工作提供良好的环境。若要准确实时地预测井涌井漏,必须及时地、准确地掌握井底裸露井段的压力体系大小及其动态变化,但评价地层压力又受井底钻头状态、地层岩性等变化因素的影响,因此快速准确地对井涌井漏现象进行预测是工业界和学术界面临的一项重要的挑战[1]。要准确预测井涌井漏发生情况首先应对井涌井漏的相关起因及征兆作必要的分析。
1.1 井涌发生原因及其征兆
所谓井涌是指泥浆连续不断井口或钻机转盘面的钻杆内涌出,之所会发生这样的现象是因为钻井过程中井筒的液柱压力低于底层压力,钻遇到了井下高压层。
钻井液如果出现以下的三种情况说明可能会发生井涌[2]。(1)钻井液返出量增加。发生井涌的主要标志之一是泵排量不变,钻井液从井口返出量增加;(2)钻井液量在钻井液池中呈上升趋势。钻井液量持续增加,并且在没有外界人为的增加钻井液的情况下,井涌现象正在发生。(3)停泵后钻井液依然从井内向外溢出。在已经停泵的情况下,钻井液继续从井内向外流出,说明井涌现象已在井内发生。
1.2 井漏发生原因及其征兆
井漏是指各种工作液在压差作用下直接进入了底层,可以发生在钻井、固井、测试或者修井的井下作业情况下,工作液包括钻井液、水泥浆、完井液以及其他流体等。井漏包括渗透性、裂缝性、溶洞性滤失[3]。
井漏发生的征兆主要是地层中有能容纳一定钻井液体积的空间和有足够大开口尺寸的漏失通道(如孔隙、裂缝或溶洞等),此时正压差存在与井筒与底层之间,这种正压差使得钻井液在漏失通道中发生流动。
2 井涌井漏实时预测算法及模型
人工智能成为当前研究热点,从上世纪80年代起,人工神经网络(Artificial Neural Network)便成为该领域的研究热点。它通过建立某种简单模型,按不同的连接方式组成不同的网络,这些网络是对人脑神经元网络的一种抽象,反映的是信息处理的过程。通过相互连接构成的大量的节点关系,形成一种运算模型,组成了人工神经网络。每个节点表示一种特定的输出函数,可成为激励函数。权重用每两个节点间的连接对该连接信息的加权值来表示。根据网络的连接方式、激励函数以及权重值的不同,网络的输出也不同。网络自身代表的是某种算法或者函数的逼近,或者是对一种逻辑策略在自然界的表达。
2.1 基于BP 神经网络的井涌井漏预测算法及模型
BP神经网络属于多层前馈型神经网络,包括正向传播阶段和反向传播阶段,信号向前面传递,误差则反向传播是该网络的主要特点。如图1所示,在正向传播阶段中,信号从输入层进入,经隐含层逐层进行处理,最后直至输出层。神经元的层与层之间的输出具有相关性。如果输出层得不到其所需的输出,则立马转入反向传播阶段(如图2所示),网络权值和阈值根据预测误差进行调节,从而使得BP神经网络预测输出一步步的逼近期望输出。该神经网络的拓扑结构如图3所示。

图1 正向传播阶段

图2 反向传播阶段
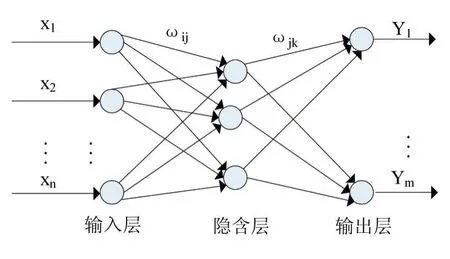
图3 BP神经网络拓扑结构图
在进行井涌井漏预测之前需要先建立原始数据集,利用原始数据集对BP神经网络模型进行训练。利用训练过后的模型对新采集的数据进行实时的预测分析。
图3中,X1,X2,…Xn是BP神经网络的输入值,Y1,Y2,…Ym是BP神经网络的预测值,ωij和ωjk为BP神经网络权值。作为一个非线性函数的BP神经网络,将n个输入节点映射到m个输出节点。网络的联想记忆和预测能力通过训练来达到,结果的预测通过用训练数据对BP神经网络进行训练后达到。BP神经网络的训练过程步骤如下。
步骤1:网络初始化。输入层节点数、隐含层节点数和输出层节点数分别用n、l、m代表,根据输入输出序列可确定。神经元之间的连接权值ωij,ωjk分别表示输入层、隐含层和输出层并进行初始化,初始化隐含层阈值a,输出层阈值b,学习速率η和神经元激励函数f。
步骤2:隐含层输出计算。隐含层输出H通过输入向量X={x1,x2,…,xn}、输入层和输出层之间的连接权值及一个隐含层阈值a计算得到,如公式(1)所示。

激励函数有多种表达形式,一般选取公式(2)的形式:

步骤3:输出层输出计算。预测输出O可根据三个值来计算得到,分别为隐含层输出H,连接权值ωjk以及阈值b,如公式3所示。

步骤4:误差计算。网络预测误差e的计算可通过网络预测输出O和期望输出Y得到,如公式(4)所示。
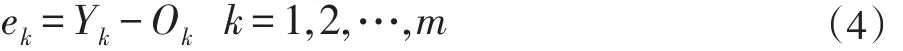
步骤 5:权值更新。根据公式(5)、(6)和网络预测误差e对网络连接权值ωij、ωjk进行更新。
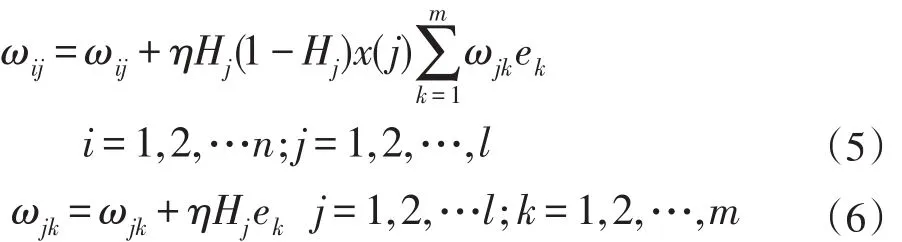
步骤6:阈值更新。由网络预测误差e更新网络节点阈值 a,b,如公式(7)和(8)所示。

步骤7:判断迭代是否终止。若没有结束,返回步骤2。
2.2 基于支持向量机(SVM)算法的井涌井漏实时预测算法及模型
支持向量机(Support Vector Machine)方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上,通过在有限的范本信息中找寻一种模型,并在模型的复杂性和学习能力之间寻求最佳折衷,使得泛化能力达到最优,可以用于解决分类、回归和预测问题[5]。
在钻井过程中通过仪器设备将实时采集的数据传输到数据库中,根据已有数据作为原始数据集,训练建立支持向量机模型,实现对后续采集的数据进行实时的预测分析。模型的建立首先需要从原始数据里提取训练集和测试集并对其进行一定的预处理(必要的时候还需要进行特征提取),然后用训练集对SVM进行训练,再用得到的模型来预测测试集的分类标签,其算法流程如图4所示。

图4 SVM流程图
在井涌井漏数据集中,选取与井涌井漏发生具有相关性的数据项,然后把井涌井漏发生结果做标记。因此井涌井漏预测转化为三分类问题,数据集可按要求分为三类,即训练和测试集中的数据均包含井涌、井漏、正常数据。算法具体步骤如下:
步骤1:数据集的准备。首先把样本数据集分为两个部分,一个做训练集,另外的做测试集,并且对应相应的训练集标签和测试集标签。
步骤2:数据预处理,对数据进行简单的缩放操作。为提高分类准确度,采用公式(9)对训练集和测试集进行数据归一化预处理。

公式(9)中,x,y∈Rn,xmin=min(x),xmax=max(x),y∈[0,1]。
步骤3:选择核函数类型。本文选择RBF(径向基)核函数,如公式(10)所示。
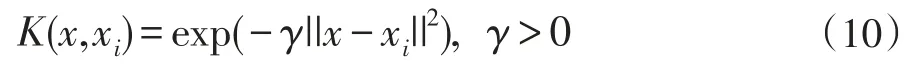
步骤4:选择分类器的最佳参数c和g。本文在K-CV情况下获得c和g的最佳参数,K取5,通过进行交叉验证的方式,不断的尝试各种可能的(c,g)组合值,交叉验证精度最高的(c,g)组合被找出。
步骤5:带入训练样本集获取SVM模型。利用数据集训练出SVM模型。
步骤6:利用获取的模型进行挖掘分析得到结果。在得到最优算法模型后,应用该模型对进行同样预处理的数据集进行分类预测分析,记录相应结果并展示。
在以上SVM算法步骤中,分类器的最佳参数c和g的选择和确定是较为关键的一步,也是分类器能够达到较好分类效果的重要一步。目前没有固定的寻找得到最佳参数c和g的方法,本文采用交叉验证的方法选择最佳参数c和g。交叉验证方法即是让c和g在一定的范围内取值,对于取定的c和g,把训练集作为原始数据集,然后通过利用K-CV方法进行分类后,得到分类准确率,该准确率即体现了在对应c和g下的训练效果。比较多组对应c、g的准确率,找出最佳的c和g并记录下来。
给定训练集train及其标签train_label,通过K-CV方法选取最佳的参数c和g的算法如下。
算法一:利用K-CV方法选取最佳参数c和g
1:Start
2:bestAccuracy=0;bestc=0;bestg=0; %相应的数据初始化
3:for c=2^(cmin):2^(cmax)%将c和g划分网格进行搜索
4:for g=2^(gmin):2^(gmax) % 采 用 K-CV方法
5:将train大致平均分为K组,记train(1),train(2),…,train(K)
6:相应点标签分离出来,记为train_label(1),train_label(2),…,train_label(K)
7:for run=1:K
8:让train(run)作为验证集,其他的作为训练集。
9:记录此时的验证准确率为acc(run)
10:end
11:cv=(acc(1)+acc(2)+…+acc(K))/K;
12:if(cv>bestAccuracy)
13:bestAaccuracy=cv;bestc=c;bestg=g;
14:end
15:end
16:end
17:Over
其中 cmin,cmax,gmin,gmax,K 是给定的数。c 和g的值则要进行离散化的查找,针对本文的情况,本文c和g在2的指数范围网格内进行查找。
3 实验结果及分析
3.1 数据集介绍
本文采用神开井涌井漏数据集,从汇聚得到的众多钻井数据中选取11个较密切的指标,分别是全烃、C1、钻压、悬重、立管压力、出口流量、总池体积、入口密度、出口密度、入口电导率、出口电导率。数据集中包含井涌数据样本142个,井漏数据56个,正常样本数据2000个。分别建立BP神经网络模型和支持向量机模型,利用建立的神经网络模型对井涌井漏情况进行分析和预测。每类数据集均值展示如图5所示:
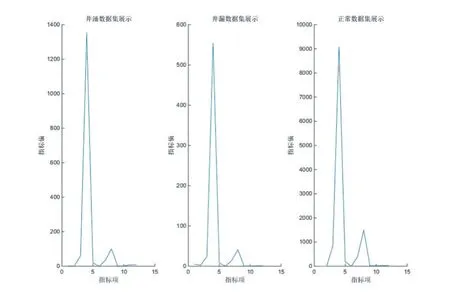
图5 数据集属性分析图
3.2 基于BP 神经网络的井涌井漏预测分析
如图6所示,建立BP神经网络模型。每个指标的重要性不同,分为两级,第一级关联度为1,第二级关联度为2(1最高,2最低)。钻压、悬重、立管压力这三个指标为第一级指标,其余为第二级指标。在输出层中,1代表正常,2代表发生井漏,3代表发生井涌。数据集中75%用于训练,25%用于测试。
先将原始数据进行归一化处理,采用最大-最小标准化方法,利用MATLAB神经网络工具箱实现神经网络的构建,BP神经网络计算结束后再进行反归一化处理。训练样本在经过量化后被代入模型,井涌井漏的预测值将会被得到。实验结果如表1所示。

图6 BP神经网络模型
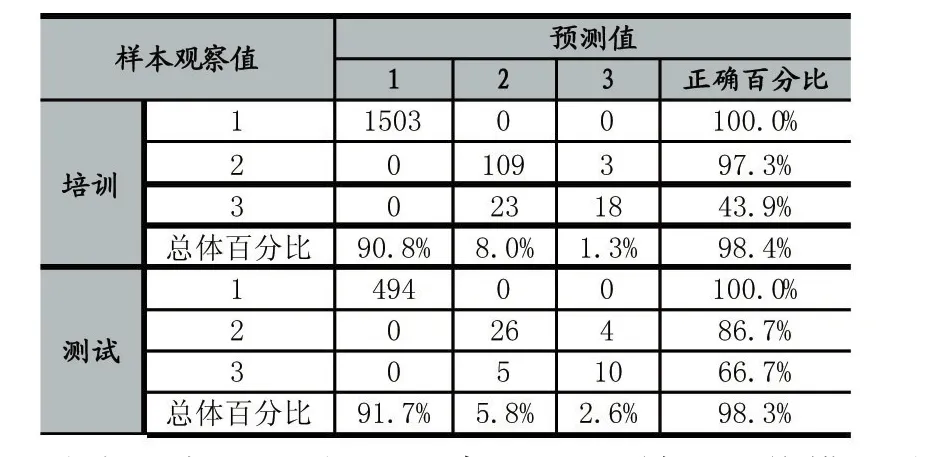
表1 实验结果分析表
从表1中可以看出,所建立的BP神经网络模型总体正确率为98.3%,预测结果与实际观测值基本吻合,由此表明本文所建立的利用BP神经网络实现井涌井漏的预测模型可以获得很好的预测效果,无疑对指导矿井安全提供了必要的理论依据。
3.3 基于SVM 的井涌井漏预测分析
本实验是在Windows7系统、在MATLAB 2014b平台、版本号为3.22的支持向量工具libsvm下进行。数据集在归一化之后将会被随机的分为不等的两份,其中一份用作训练集,另一份则作为测试集。在本实验中,总数据集的4/5用作训练集,剩下的1/5作为测试集。最终的分类结果如图7所示。
从图7中可以看出,该方法误差小,模型拟合度好,因此利用SVM对井涌井漏进行预测可以得到比较精确的结果,为钻井工作提供了极大的技术支持。
4 结语
本文分析了井涌井漏发生的原因及征兆,阐述了神经网络的思想和算法,深入研究了神经网络算法在井涌井漏预测分析中的可行性和现实的可操作性。介绍了BP神经网络算法和支持向量机算法的应用步骤,阐明了利用这两种算法进行井涌井漏现象预测的可行性。最后以神开井涌井漏数据集为实验对象,以BP神经网络算法、SVM算法分别进行了实验分析,预测结果理想且较准确,充分说明了以神经网络算法进行井涌井漏预测分析可操作性和高效性。

图7 支持向量机分类结果图
参考文献:
[1]朱文鉴,郭学增.石油钻井井涌井漏实时预测专家系统研究[J].现代地质,1997(1):86-90.
[2]薛玖火,刘强,王翔,等.MX10井古生界井漏原因浅析及建议[J].钻采工艺,2016,39(1):38-41.
[3]罗远游.川西地区固井及完井过程中井漏原因分析及对策[J].天然气工业,1988(1):66-69.
[4]吴微,陈维强,刘波.用BP神经网络预测股票市场涨跌[J].大连理工大学学报,2001,41(1):9-15.
[5]丁世飞,齐丙娟,谭红艳.支持向量机理论与算法研究综述[J].电子科技大学学报,2011,40(1):2-10.
猜你喜欢
西部探矿工程(2022年8期)2022-12-12
黄河之声(2022年10期)2022-09-27
河南科技(2022年8期)2022-05-31
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
现代电力(2022年2期)2022-05-23
中学生数理化·高二版(2022年4期)2022-05-09
世界有色金属(2020年4期)2020-12-08
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
