
基于深度学习的交警指挥手势识别
2018-05-16 09:44:33常津津罗兵杨锐郝叶林
五邑大学学报(自然科学版) 2018年1期
常津津,罗兵,杨锐,郝叶林
基于深度学习的交警指挥手势识别
常津津,罗兵,杨锐,郝叶林
(五邑大学 信息工程学院,广东 江门 529020)
为解决无人驾驶汽车快速准确地识别交警指挥手势的问题,本文提出一种基于深度学习的三通道输入交警指挥手势识别方法. 仿真实验表明,利用深度学习优化模型参数后,采集的8种交警指挥手势数据集的平均识别准确率可达97.87%,识别率较高,具有一定的应用价值.
Kinect设备;C3D;ConvLSTM;交警指挥手势
无人驾驶汽车能有效减少交通拥堵,提高道路安全性,是未来汽车发展的重要方向,也是目前的研究热点. 当遇到恶劣天气、交通事故等特殊情况时,单靠固定式交通信号进行调度已经难以满足要求,需要经验丰富的交警对现场状况进行灵活判断和疏导. 因此,需要无人驾驶汽车不仅能够识别交通信号,还要对灵活多变的交警手势做出相应反应.
基于视觉的交警指挥手势识别通常是基于视频序列或者骨架序列进行手势识别. 如GUO等人提出了一种方法来识别中国交警使用最大覆盖方案做出的手势[1-3],该方案身体部分最大限度地覆盖前景区域,提取出前景区域,然后构建交警身体五部分模型. 对于文献[1-3],只有RGB摄像机被用来捕获测试图像和视频,捕获到的图像和视频中的交警几乎覆盖整个前景区域,与实际场景不太符合. 随着3D测量设备Kinect[4]在手势识别中的广泛应用[5-6],越来越多的研究者开始利用Kinect设备来获取数据,然后进行手势识别. 文献[5-6]通过Kinect获取的骨架信息来进行交警手势识别,但由于骨架信息在获取的过程中容易丢失,导致准确率比较低. 上述方法都是通过单种模态进行交警手势识别的,由于单模态RGB数据易受光照、视角等因素的影响,导致识别率较低,因此就出现了多模态交警手势识别方法[7].
为解决识别准确率低的问题,受文献[8]启发,且交警手势识别是手势识别中的一种特例,本文利用文献[8]的多模态算法在样本集上进行实验,提出一种基于C3D[9]和ConvLSTM[10]的三通道交警指挥手势识别方法,并对深度网络结构的部分进行改进.
1 样本库的建立
1.1 建立数据库

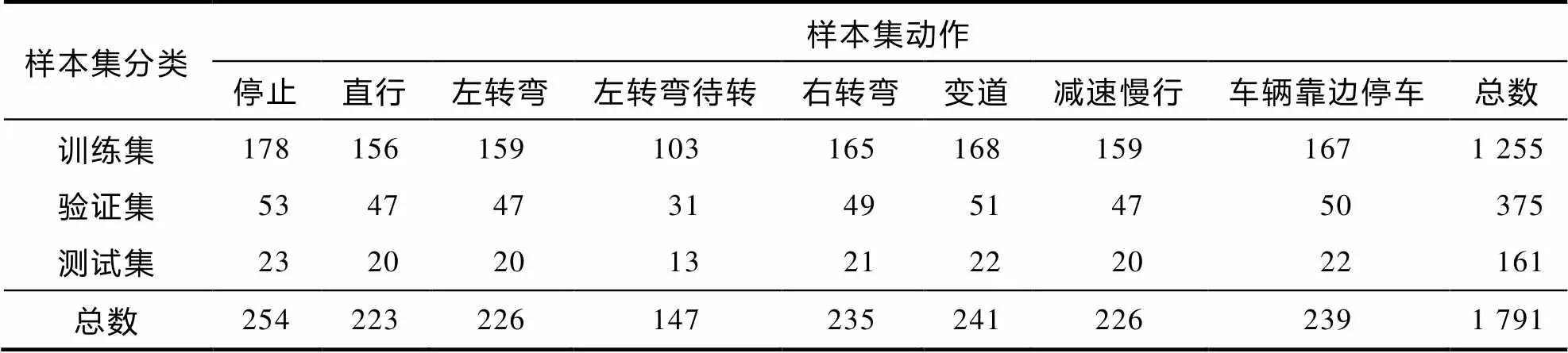
表1 各类样本数
部分样本如图1所示,其中图1-a为RGB数据,图1-b为骨架数据.

图1 部分样本数据
1.2 数据预处理
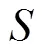
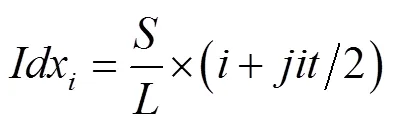
基于时间抖动策略的数据增强操作在不打乱每个手势的原有采样帧的基础上来增加数据,采样结果如式(2)所描述:
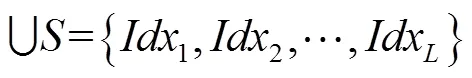
2 基于深度学习的三通道输入识别方法
由于单一的视频输入或骨架输入识别准确率低,骨架一般分辨率低,视频中背景变化大,根据经验可知,骨架数据可很好地表征位置信息,而光流数据可很好地表征运动信息,因此本文采用了利用RGB数据、骨架和光流数据输入的深层网络结构识别方法. 识别系统的结构如图2所示,结构框架主要由4部分组成:输入数据、C3D、ConvLSTM和多模态融合.
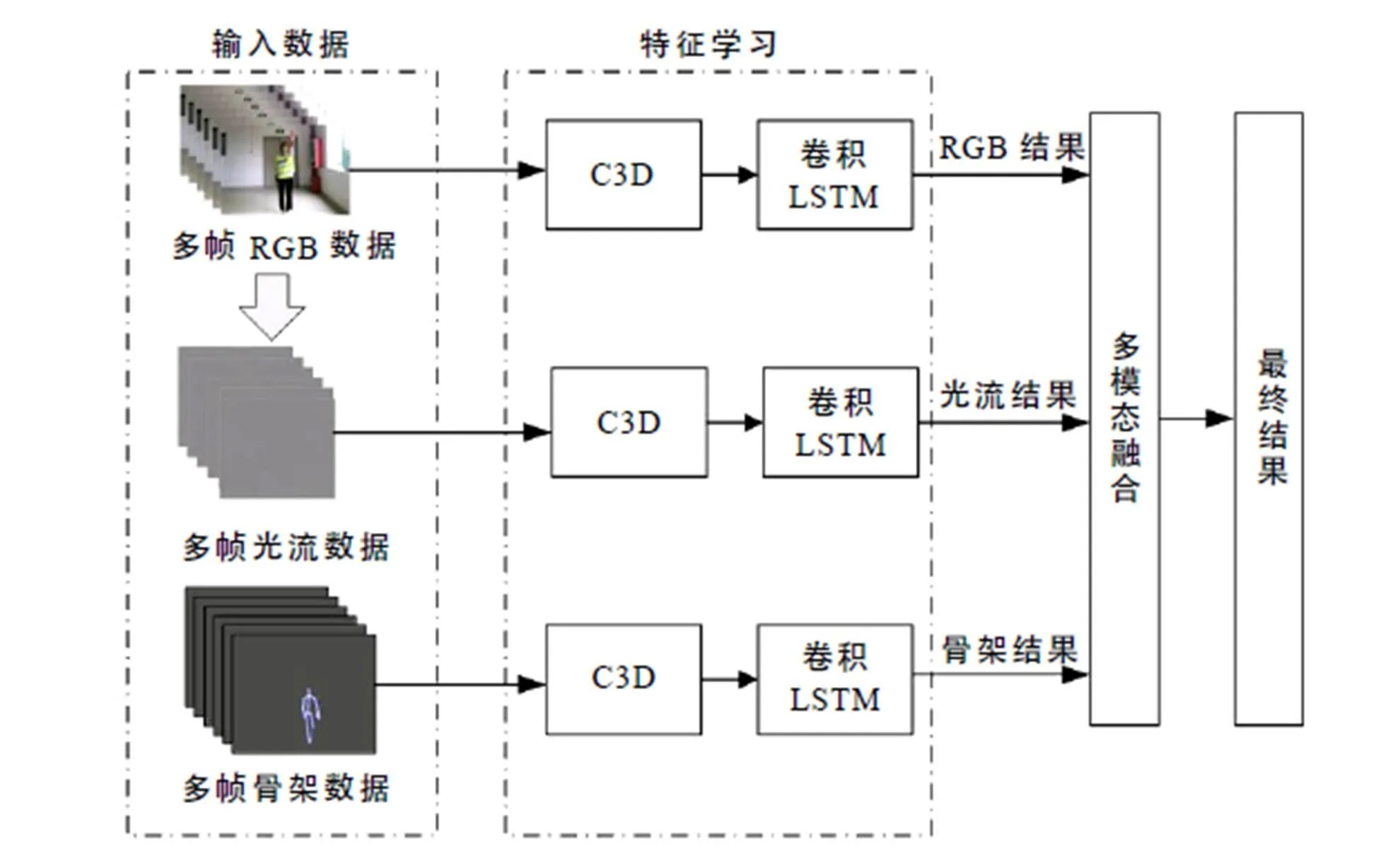
图2 交警指挥手势识别系统的基本框架
2.1 输入数据
基于深度学习三通道输入的交警手势识别系统的基本框架如图2所示,输入数据由3种模态的数据组成,其中多帧RGB数据和多帧骨架数据来自本文采集的样本库(见1.1),多帧光流数据采用Brox光流算法[11]从RGB视频数据提取得到. 利用骨架数据的优点,通过增加额外的光流数据提高识别率. Brox光流算法是根据光流约束方程,假定亮度恒定和图像梯度恒定,且假设光流场平滑来计算每个像素点的状态矢量,从而捕捉其运动信息. 光流基本约束方程为

式(3)是基于短时间目标图像亮度不变的条件,在位移比较大的情况下容易失效,因此采用原始的非线性灰度值恒定假设
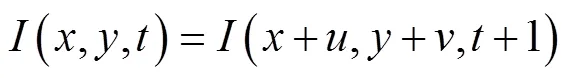
灰度值恒定假设易受亮度影响,因此为保证灰度值发生一些小的变化,引入图像灰度值梯度恒定假设
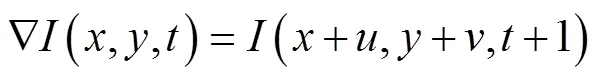
将上述约束条件用能量表示为
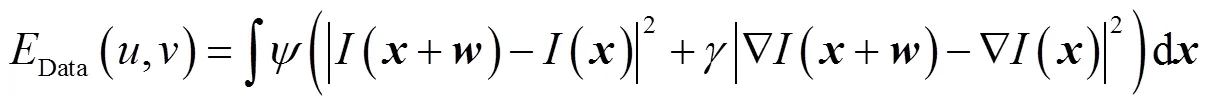
光流场平滑的能量为
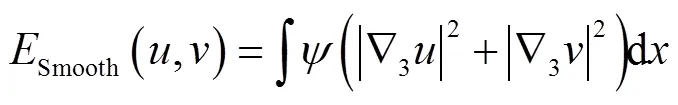
数据项与平滑项之间的加权和为总能量,表示为式(8).
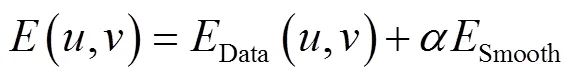
2.2 三维卷积神经网络
C3D是用于人体动作识别的代表性三维卷积神经网络,批量正则化[12]用来加快训练深度网络. 它对初始化不敏感,能够使用较大一点的学习率(文中使用的初始化学习率为0.01). 与文献[8]不同的是,本文增加了网络深度,采用了8个卷积层,4个池化层,每一个卷积层的卷积核尺寸都是3×3×3,步长和补充的像素是1×1×1,滤波器的个数依次是64,128,256,256,512,512,除了conv3a,conv4a,conv5a层之外,每一个卷积层后面都跟着一个批量正则化层、一个ReLU层和一个池化层,除了第一个池化层的核尺寸是1×2×2,步长是1×2×2之外,其余各池化层的核尺寸和步长都是2×2×2,也就是说空间池化只在第1个卷积层中起作用,空时池化在第2个、第4个和第6个卷积层起作用,这些池化层使每个卷积层的输出尺寸在空间上和时域上分别以1/4和1/2的比例缩小. 因此C3D只能够学习短期的空时特征.
2.3 卷积长短期记忆网络
传统的全连接LSTM可以很好地处理时序数据,但对于空间数据,将会带来冗余性,主要是由于FC-LSTM内部门之间是依赖与类似前馈式神经网络计算的,无法刻画空间数据的局部特征. 而卷积LSTM将输入到状态和状态到状态的转移过程中将前馈式计算替换成了卷积运算,因而可以很好地建模时空关系[10]. 新的ConvLSTM的工作原理由式(9~13)表示:
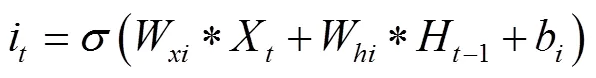
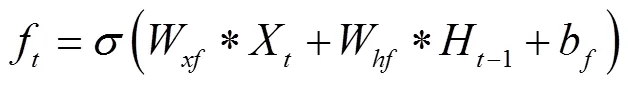

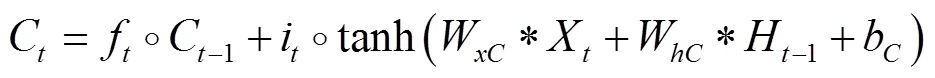
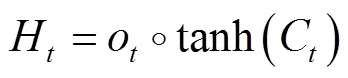
本文使用2层的ConvLSTM,其最高层的输出被当作每个手势的长时间空时特征,因此ConvLSTM的最终目的是实现空时特征的时间长度为1. 此处卷积核的尺寸是3×3,步长是1×1,滤波器的个数分别是512、640,同时在进行卷积操作时使用Same-Padding,因此在经过两层ConvLSTM后,其输出和C3D具有相同的空间尺寸,只是改变了时间长度.
综上所述,骨架数据可以很好地去除背景,但有时候会丢失部分信息,而光流能够捕捉手势的运动特征,故上述三通道输入数据分别是RGB数据、骨架数据和光流数据,通过增加光流通道,利用其各自的优点来提高识别率. 考虑到文献[8]的结构不能很好地表征手势特征,因此本文将原始的4层卷积层改成8层,每层的卷积核大小为3×3×3,步长为1×1×1,且在卷积层之后加上批量正则化层来加快神经网络训练,通过增加网络深度,使网络学习到更好的特征,从而提高识别准确率.
3 实验结果与分析
本文主要硬件平台:Microsoft Kinect2.0传感器一台,英伟达显卡GeForce GTX 1080;电脑配置为Linux操作系统,Intel®Core™i5-4460处理器,3.2GHz主频,8G内存;系统采用的软件开发环境:PyCharm 2017,KinectSDK-v2.0_1409;实验条件:python2.7,6,TensorFlow0.12.0,opencv3.1.0.
为验证本方法的有效性,主要从3个方面来验证:1)光流能否提高识别准确率;2)基于三通道数据的交警手势识别是否更具有优越性;3)本文提出的算法与文献[8]算法相比,哪种算法识别率更高.
首先验证1)和2),分别在6种条件下比较识别准确率:①RGB数据②骨架数据③RGB+骨架④RGB+光流⑤骨架+光流⑥RGB+骨架+光流,交叉验证集的实验结果如图3所示.

图3 交警手势识别在五种条件下分别在交叉验证集上各类手势中的平均识别率
由图3可知:在加入额外光流通道之后,RGB+光流和骨架+光流两种组合明显比单通道RGB或单通道骨架的平均识别率高,RGB+光流与RGB+骨架在8类交警指挥手势中的效果一样,高于骨架+光流组合的平均识别率,这说明额外的光流通道可提高识别准确率,但效果一样的双通道RGB+骨架和双通道RGB+光流都存在左转弯与右转弯误判的情况,如表2,表3. 为解决这个问题,加入额外光流通道之后,三通道在8类交警指挥手势中的统计结果如表4.
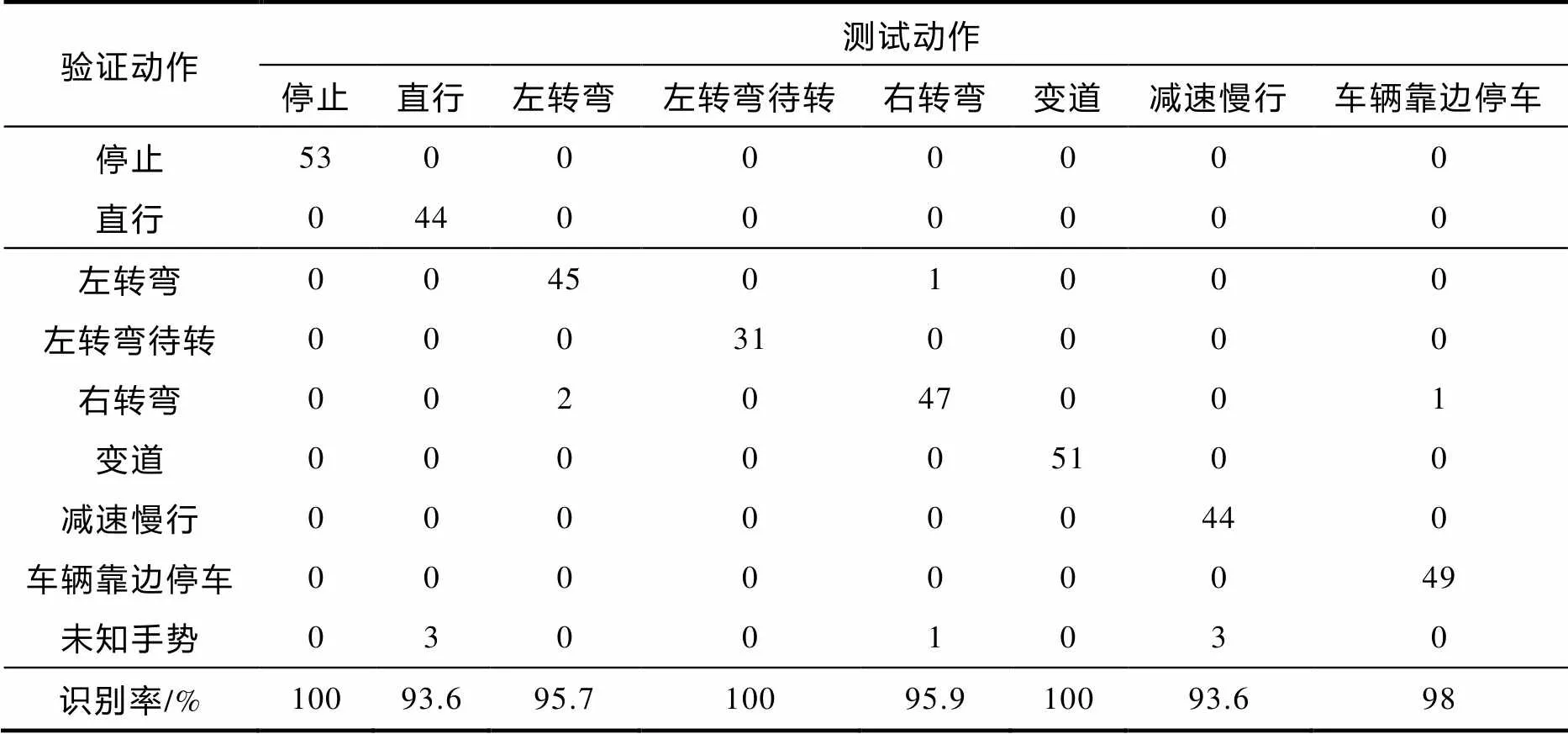
表2 RGB+光流在8类交警指挥手势的统计结果
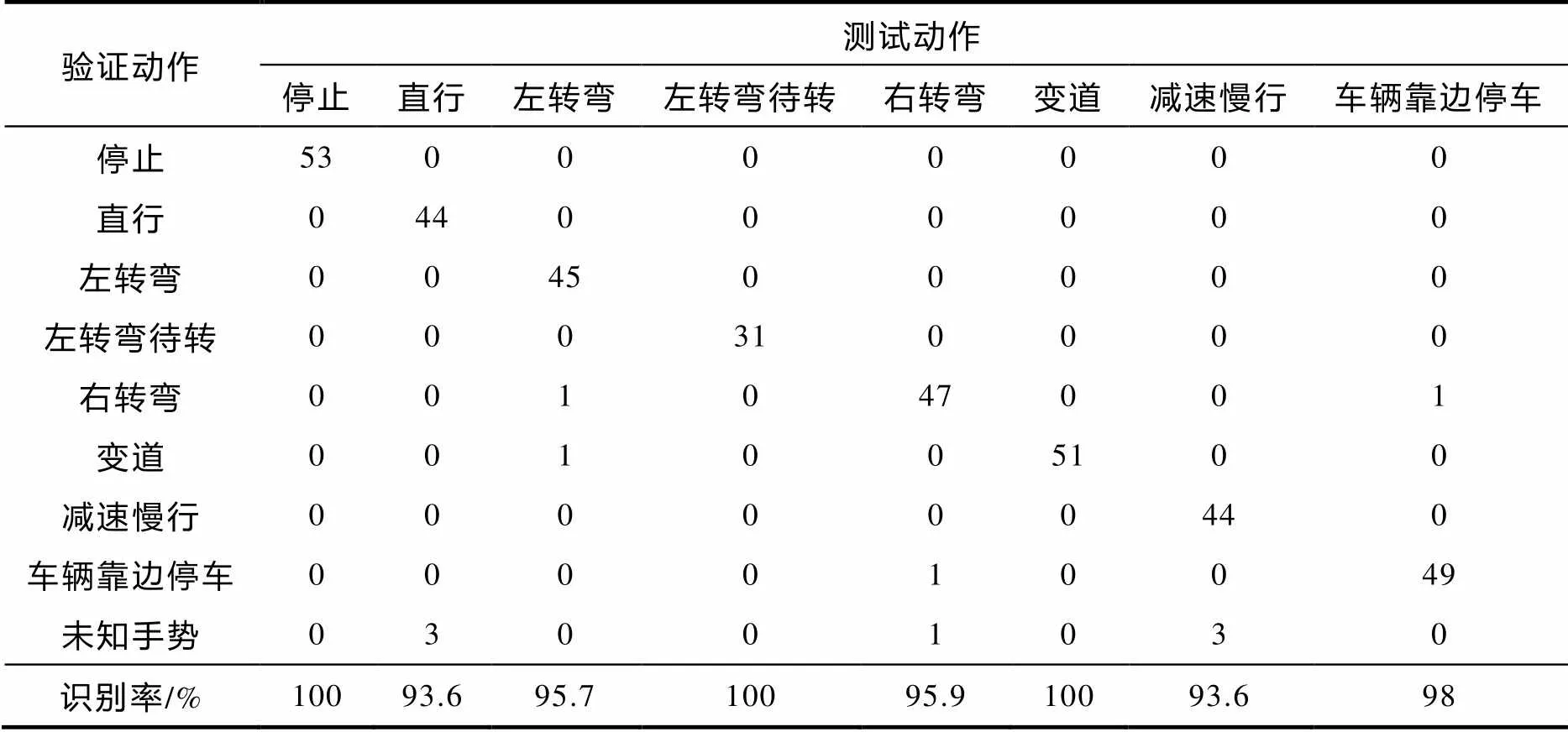
表3 RGB+骨架在8类交警指挥手势的统计结果
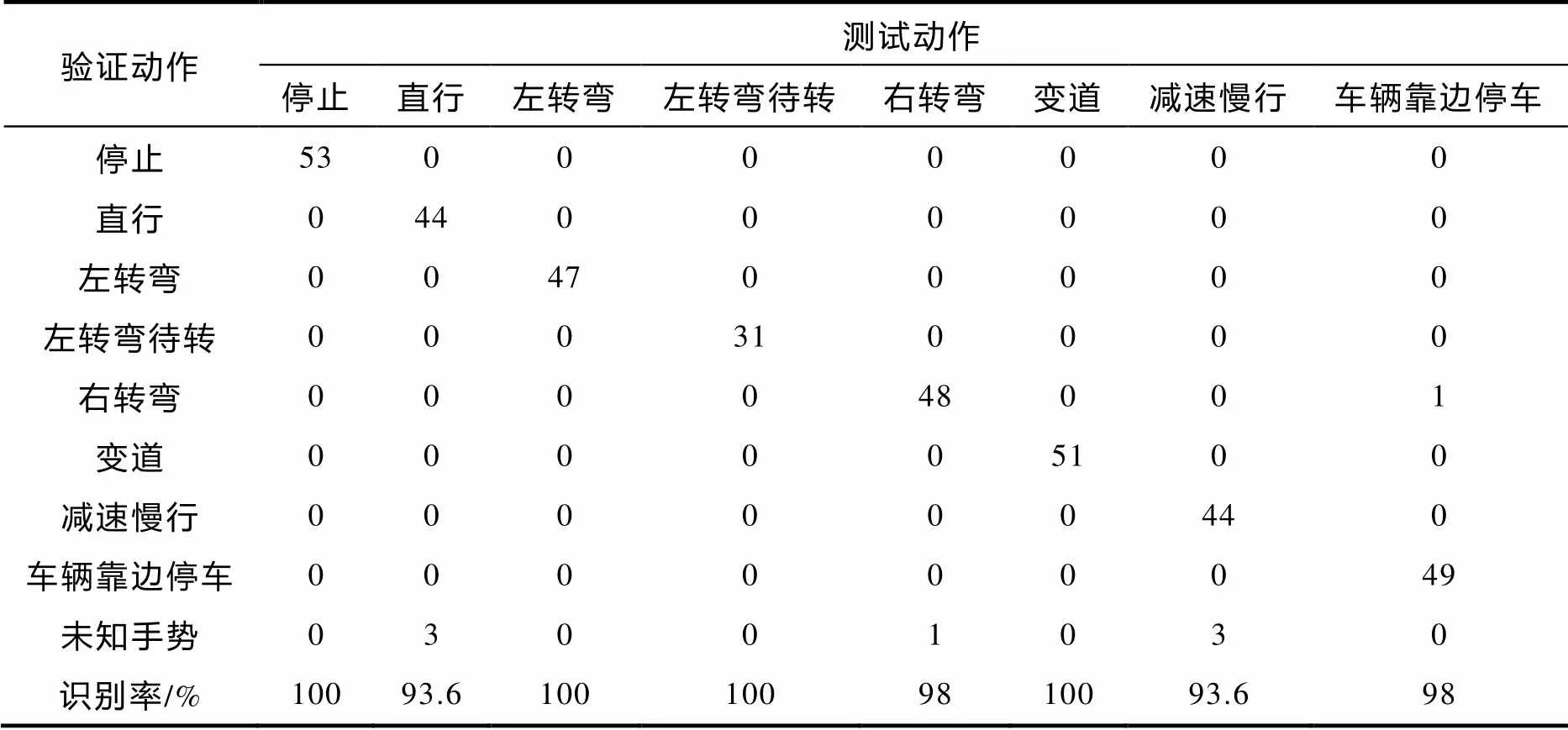
表4 三通道方法在8类交警指挥手势的统计结果
表2、表3和表4中的未知手势是指未识别出来的手势. 由表4可知,三通道方法在停止、左转弯、左转弯待转和变道上的识别准确率为100%,识别率最低的手势是直行和减速慢行(93.6%),解决了左转弯、右转弯出现误判的情况,只有车辆靠边停车出现了误判情况,造成这种情况的原因是车辆靠边停车与右转弯的这两种手势相似度很高. 实验证明,本文提出的算法在一定程度上提高了交警指挥手势识别率.

图4 骨架效果图
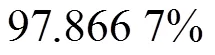

表5 各种算法的平均识别率比较
4 结束语
[1] CAI Zixing, Guo Fan. Max-covering scheme for gesture recognition of Chinese traffic police [J]. Springer- Verlag, 2015, 18(2): 403-418.
[2] GUO Fan, CAI Zixing, TANG Jin. Chinese traffic police gesture recognition in complex scene [C]// IEEE, International Conference on Trust, Security and Privacy in Computing and Communications. [s.l.]: IEEE, 2012: 1505-1511.
[3] GUO FAN, TANG Jin, CAI Zixing. Automatic recognition of Chinese traffic police gesture based on max-covering scheme [J]. Advances in Information Sciences & Service Sciences, 2013, 5(1): 428.
[4] 洪京一. 世界信息技术产业发展报告(2014-2015)[M]. 北京:社会科学文献出版社,2015: 296-300.
[5] LE Q K, PHAM C H, LE T H. Road traffic control gesture recognition using depth images [J]. Ieie Transactions on Smart Processing & Computing, 2012(1): 1-7.
[6] SONG Wenjie, FU Mengyin, YANG Yi. Recognition method of traffic police and their command action based on kinect [C]// The 33th Chinese Control Conference, Nanjing: IEEE, 2014: 3361-3366.
[7] GUO Fan, TANG Jin, WANG Xile. Gesture recognition of traffic police based on static and dynamic descriptor fusion [J]. Multimedia Tools & Applications, 2016, 76(6): 1-22.
[8] ZHU Guangming, ZHANG Liang, SHEN Peiyi, et al. Multimodal gesture recognition using 3D convolution and convolutional LSTM [C]//IEEE Access, 2017(99): 1.
[9] TRAN D, BOURDEV L, FERGUS L, et al. Learning spatiotemporal features with 3D convolutional networks [C]// IEEE International Conference on Computer Vision, Washington, DC: IEEE. 2016: 4489-4497.
[10] SHI Xingjian, CHEN Zhourong, WANG Hao, et al. Convolutional LSTM network: A machine learning approach for precipitation nowcasting [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal: IEEE, 2015: 802-810.
[11] BROX T, BRUHN A, PAPENBERG N, et al. High accuracy optical flow estimation based on a theory for warping [C]// Proceedings of European Conference on Computer Vision, [s.l.]: [s.n.], 2004: 25-36.
[12] LOFFE S, SZEGEDY C. Batch Normalization: Accelerating deep network training by reducing internal covariate shift [C]// International Conference on International Conference on Machine Learning. [s.l.]: JMLR. org, 2015: 448-456.
[责任编辑:韦 韬]
A Study of Traffic Police Command Gesture Recognition Based on Deep Learning
CHANGJin-jin, LUOBing, YANGRui, HAOYe-lin
(Information Engineering School of Wuyi University, Jiangmen, 529020, China)
In order to achieve quick and accurate identification of the hand gesture of the traffic police, a three-channel-input traffic police command gesture recognition method based on depth learning is proposed in this paper. Simulation experiments show that the average recognition accuracy of the 8 traffic police command gestures in the data sets can reach 97.87%, and is therefore of application value.
Kinect equipment; C3D; ConvLSTM; traffic police command gestures
1006-7302(2018)02-0038-07
TP391
A
2018-03-10
常津津(1992—),女,河南南阳人,在读硕士生,研究方向为数字图像处理及应用;罗兵,教授,博士,硕士生导师,通信作者,研究方向为机器视觉、智能信息处理、数字图像处理及应用.
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
计算机工程(2020年3期)2020-03-19 12:24:50
红领巾·萌芽(2019年9期)2019-10-09 03:42:56
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
小学科学(学生版)(2018年12期)2018-12-19 05:13:50
电光与控制(2018年10期)2018-10-13 08:19:00
中国交通信息化(2018年3期)2018-06-13 03:27:58
小学阅读指南·低年级版(2017年6期)2017-06-12 01:39:24
中国交通信息化(2016年2期)2016-06-06 07:28:02
中国铁道科学(2014年6期)2014-06-21 06:35:32
