
一种通用的基于图像分割的验证码识别方法
2018-05-11 06:14,,
山东科技大学学报(自然科学版) 2018年3期
,,
(山东科技大学 电子通信与物理学院,山东 青岛 266590)
验证码(completely automated public turing test to tell computers and humans apart,CAPTCHA)是一种用来区分用户是人类和计算机的自动响应程序。最早由卡内基梅隆大学的Ahn等[1]在2003年发表的论文中提出。验证码通常是由多个随机产生的字符组合生成一幅图像,通过加入干扰噪声,并使字母扭曲形变,以增加计算机识别的难度,达到防止恶意注册、刷票、论坛灌水等计算机自动化行为的目的。
作为人工智能领域的一项重要课题,越来越多的人开始致力于研究验证码图像识别技术。从目前国内外研究现状来看,针对验证码图像的识别方法主要有三种:基于特征模板匹配的方法,基于形状上下文的方法和基于神经网络的方法。潘大夫等[2]利用多种特征模板提出一种用于数字验证码识别的模板匹配算法。Bursztein Elie[3]提出一种通用的基于文本字符的CAPTCHA识别方法。Mori等[4]用传统的基于形状上下文的方法对EZ-Gimpy和Gimpy两种类型的验证码进行了识别研究。Huan等[5]针对Yahoo和MSN提出一种Projection-based字符分割算法,并通过机器学习将字符的分割与识别进行并行运算。其中,第一种方法能够对字体统一、排列工整,无扭曲变形的数字验证码有着较高的识别率,但适应性较差,对一般的存在扭曲粘连的字母验证码并不适用。第二种方法实现起来较为复杂,对存在较多干扰噪声的验证码识别效果并不明显。相比前两种识别方法,神经网络作为一种成熟的仿真算法,近年来在图像和语音识别方面取得了巨大进步。研究表明,只要能完整分割地验证码图像中的单个字符,就可以利用神经网络识别出字符本身[6]。但现有的验证码识别技术大都针对一种类型的验证码运用多种分类方法进行识别研究,对其它类型的验证码并不适用,且对存在粘连、扭曲的验证码的识别率并不理想。
本研究针对粘连、扭曲,且存在干扰噪声的验证码图像识别性能欠佳的问题,通过改进Otsu二值化分割算法和使用新的融合字符积分投影特性的连通域标记方法分割粘连字符,并基于卷积神经网络提出一种通用的能够适用于同时包含字母和数字,字符间存在粘连,且存在较多干扰噪声的验证码识别方法,并在Python 2.7环境下针对多个有代表性的网站验证码进行网络训练和识别,均达到了较高的识别率。
1 验证码识别流程
验证码识别的主要流程如图1所示。首先,利用Python脚本从四个具有代表性的网站自动下载一定数量的验证码样本图像。然后,由于样本图像都是含有干扰噪声的原始彩色图像,一般不能直接输入神经网络进行训练学习,因此需要进行预处理。预处理主要包括原始图像的灰度化,灰度图像的二值化,图像去噪等环节。字符分割是整个流程的重要环节,分割的结果将直接影响后续的训练识别。将分割得到的单个字符归一化后输入到基于卷积神经网络的LeNet-5模型[7]中进行字符的训练识别,并输出识别结果。

图1验证码识别流程
Fig.1 Flow of the CAPTCHA recognition
2 本文验证码识别方法
2.1 预处理
图像预处理是进行字符分割前的必备环节,目的是去除不利于字符分割的干扰信息,突出显示与字符相关的特征信息,从而提高字符分割的正确率。图像的预处理过程主要包括如下三个环节:
1) 灰度化
由于原始图像是256 色的彩色图像,因此需要将彩色图像进行灰度化。这里采用传统的加权平均法进行原始图像的灰度转换:
L=0.299×R+0.587×G+0.114×B。
(1)
式中:L代表加权平均后灰度图像的像素值,R、G、B则分别代表red、green、blue三基色的分量值。
2) 二值化
假定0代表图像的背景色,1代表图像的前景色,用Gw表示(0,1)二值图像的像素值,则灰度图像的二值化可用下式表示:
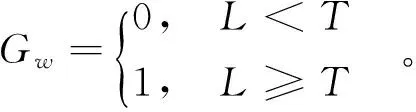
(2)
二值化过程的关键在于阈值T的选取,对于一般的灰度级分布曲线成单峰的,或前景与背景像素的灰度值差距较大的图像来说,通常选用最大类间方差法(Otsu法)计算整个灰度级范围内的最优阈值。其核心思想是在阈值为T时将灰度图像分为两类,一类代表前景,一类代表背景,若此时的T使得两类的类内方差最小,类间方差最大,则为全局最优阈值[8]。最大类间方差法的计算公式如下:
σ2(T)=ωΑ(μΑ-μ)2+ωΒ(μΒ-μ)2。
(3)
式中:A、B分别代表前景区域与背景区域,σ2(T)代表阈值为T时的类间方差,ωA、ωB、μA、μB分别代表阈值为T时的前景区域与背景区域的概率分布和灰度均值,μ为整个灰度图像的灰度均值。
令NA、NB分别为目标区域和背景区域的像素点数,N为灰度图像的像素点总和,则有:
N=NΑ+NΒ,
(4)
(5)
由于Otsu算法是一种全局最优阈值法,当前景区域和背景区域的灰度范围只占灰度直方图中的一小部分时,整体灰度平均会将大量灰度分布为0的像素纳入计算范围,从而影响二值化计算的效率。另外,当背景区域与前景区域的灰度值在灰度分布直方图中存在重合情况时,重复的计算前景区域和背景区域的灰度均值和概率分布不但会增加运算的时间和复杂度,还会影响二值图像分割的质量。因此,在原有Otsu算法的基础上做了如下改进:
1) 改全局最优阈值为局部最优阈值
在进行灰度均值和概率分布计算时,只考虑灰度分布直方图中灰度值分布不为0的像素,0和255的边缘像素也不纳入计算体系,从而在整个图像的灰度分布范围内求取局部最优阈值。
2) 将Otsu算法公式改为:
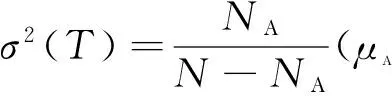
(6)
式中:NA为目标区域的像素点数,N为灰度图像的像素点总和,μ为整体灰度均值,μΑ为目标区域的灰度均值。
令g(i,j),gΑ(i,j),gΒ(i,j)分别代表原始灰度图像、前景区域、背景区域在某一坐标下的像素值,则有:
(7)
将式(4)、(5)、(7)带入式(3)中,消掉背景区域B的计算部分,从而得到改进后的局部最优阈值算法公式。
利用局部最优阈值,灰度图像二值化的具体步骤如下:
Step 1:求出灰度图像的全部像素点数N、整体灰度均值μ及灰度直方图中的最大灰度值Zmax、最小灰度值Zmin;
Step 2:在Zmin≤T≤Zmax范围内根据式(6)迭代求出两类区域的类间方差σ2;
Step 4:将小于阈值T的像素值置为0,大于阈值T的像素值置为1,输出二值化图像。
按照上述二值化分割步骤,针对几种不同种类的验证码分别采用经典的Otsu法和改进后的局部最优阈值法进行实验,两种方法的二值化分割效果对比如表1所示,时间性能对比如表2所示。
表1两种方法二值化分割效果对比
Tab.1 Comparison of the two binarization segmentation method

表2 两种方法二值化分割时间性能对比Tab.2 Computation cost of the two binarization segmentation methods

二值化分割方法测试图像/幅处理时间/s单个图像平均处理时间/s经典的Otsu法30094.20.314本文改进后的方法30058.60.195
总结上述实验结果表明改进后的局部最优阈值算法不但减少了运算复杂度,提高了时间性能,而且改善了二值化图像分割的质量,有利于后续字符的分割和识别。同时,该算法对干扰噪声有较好的抑制作用,对于多数仅含有点噪声的验证码图像来说,可以直接在二值化环节将噪声去除,从而省略了滤波的步骤。
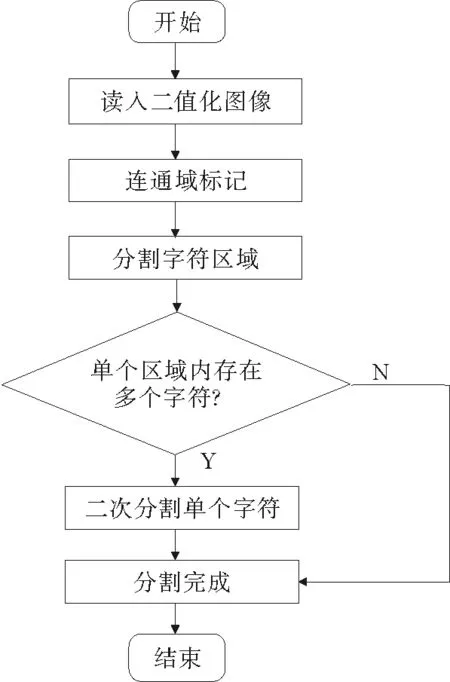
图2 改进的字符分割算法流程图Fig.2 Flow chart of the improved character segmentation algorithm
3) 图像去噪
二值化后的图像可能含有若干点噪声或细线噪声,这些干扰噪声的存在会影响后续字符分割的质量,因此有必要进行去噪处理。对于点噪声,可根据具体图像选择四邻域或八邻域遍历整个二值化图像每个像素点周围黑色像素点的个数,通过设置一定的阈值,将小于该阈值的黑色点当做孤立点,并将其像素值置为0,从而去除离散噪声。对于细线噪声,可通过Hough变换检测直线去除。
2.2 字符分割
字符分割是整个流程的关键,分割结果的好坏将直接影响后续字符的训练和识别。好的分割方法是将单个字符信息完整的予以保留,残缺或多余的字符信息都将对识别的正确率产生影响。传统的字符分割方法主要有两种,即投影法和连通域法。其中投影法最为常见,两种方法对于一般的字符间无粘连、重合的验证码图像都有着较高的分割成功率,但在处理复杂验证码的时候则显得差强人意。
本研究基于传统的字符分割方法设计出一种改进的、融合字符投影特性的、能够适用于字符间存在粘连的复杂验证码分割方法。该方法的流程图如图2所示。其基本思想是:首先读入二值化图像进行连通区域标记,标记时可采用一种高效的一遍扫描式算法[9]提高运算效率。标记完成后,依次确定每一个标记好的连通域的边界并进行初次分割,从而得到若干含有一个或几个字符信息的二值图像。若初步分割得到的图像数目等于原始图像的字符个数,则分割完成。否则,依次对初次分割得到的字符图像进行面积计算和黑色像素点统计,若大于一定阈值,则表明该图像包含多个粘连的字符,需要再次进行分割,否则将其当作离散块噪声去除。初次分割结果如图3(d)所示。二次分割时,对包含多个字符的初次分割图像从左到右依次统计竖直方向上的黑色像素点的个数,并在水平方向上进行积分投影,依据积分投影曲线的极小值确定粘连字符间的临界点,并根据该点进一步分割出单个字符,当存在多个极小值点时,可在整个字符区域的(1/4,3/4)宽度范围内,根据各极小值点所对应的最大黑色像素积分值确定粘连字符间的临界点。
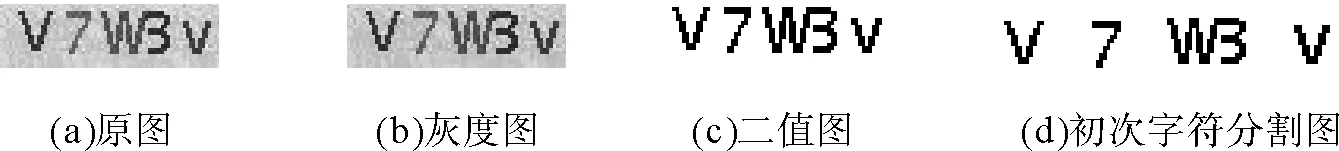
图3 分割结果示意图Fig.3 Segmentation results demonstration of a sample character image
图3所示的验证码图像均包含五个由数字和字母随机组成的字符序列,而初次连通域标记分割得到四个字符区域,表明其中一个字符区域同时包含两个字符信息。通过计算每个字符区域的面积和其中黑色像素点之和可知第三个字符区域包含两个粘连的字符。对该字符区域在水平方向上积分投影,如图4所示,该字符区域存在4个极小值点,分别标为x1、x2、x3、x4,由于x4处的对应的竖直方向上黑色像素点之和最小,且满足:
dmin≤di≤dmax。
(8)
其中:di代表二次分割粘连字符时单个字符的宽度,dmin、dmax分别代表字符的最小宽度和最大宽度,这里设定dmin=10,dmax=18。因此x4为粘连字符的分割边界点,在该点处进一步分割出单个字符。
将分割得到的单个字符归一化为29×29像素大小的二值化图像,以便后续进行字符的训练和识别。
2.3 基于卷积神经网络的字符识别
卷积神经网络(convolutional neural networks,CNN)是一种特殊的基于误差反传算法实现的多层前馈神经网络。同其他神经网络相比,其最大的不同之处在于通过局部连接和权值共享使得特征提取和训练识别能够同步进行,并通过自适应、自学习,找到分类性能最优的特征信息[10]。不但避免了人工手动提取特征信息的主观性,降低了神经网络的复杂度,同时也保证了对字符旋转、缩放、扭曲的鲁棒性。针对字符识别,Lecun等[11]提出一种基于卷积神经网络的字符识别系统LeNet-5,并将其成功的应用于银行手写数字的识别上。Simard等[12]又在此基础上做了改进,简化了LeNet-5的结构。如图5所示,简化后的LeNet-5系统包括输入层在内共有5层网络结构,相比原始的LeNet-5系统的7层网络结构而言,将卷积层和池化层结合在一起,并将卷积后的输出直接作为池化层的输入,避免了池化层过多参数学习过程,简化了运算流程,同时保留了对图像位移、扭曲的鲁棒性。另外,原始的LeNet-5系统最初是用来识别0-9的手写数字,输出层的节点数为10 个,而简化后的LeNet-5系统可根据验证码样本字符集的个数确定输出层相应的节点数量。不同网站验证码的样本字符个数如表5所示,如编号为2的网站验证码的样本字符集是由28 个字母和数字组成的,其对应的输出层节点数为28 个。每个节点与相应的字符一一对应,输出节点值最大的对应的字符即为卷积神经网络的训练输出值[12]。
本研究采用简化后的基于CNN的LeNet-5模型针对不同种类的验证码图像分别进行训练和识别。将归一化得到的二值化字符图像直接输入到卷积神经网络中,待训练完成,将测试集样本经过相同的预处理和字符分割操作后输入训练好的神经网络中识别,并输出识别结果。
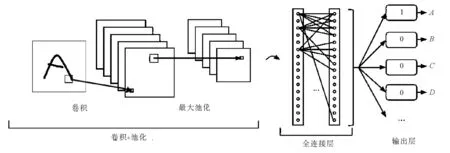
图5 简化后的LeNet-5网络结构Fig.5 Network architecture of simplified LeNet-5
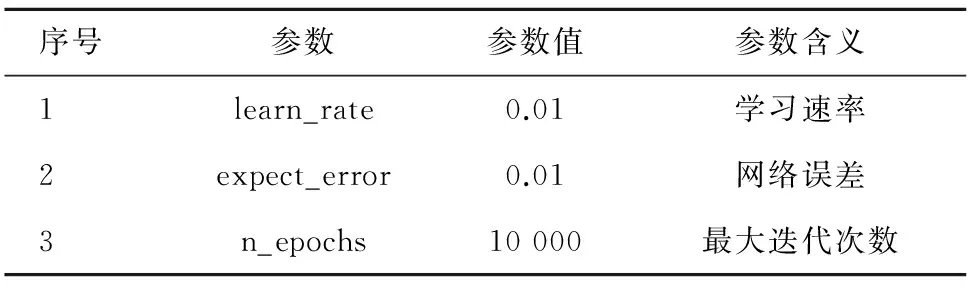
序号参数参数值参数含义1learn_rate0.01学习速率2expect_error0.01网络误差3n_epochs10000最大迭代次数
3 实验与分析
选取9 个不同网站不同类别的验证码图像作为样本进行训练和识别,其中1 个是由四位无粘连的阿拉伯数字随机排列组成的验证码图像,另外8 个则是由字母和数字组成的部分存在扭曲、粘连的字符验证码图像。分别将每种验证码样本图像平均分为两份,一份作为训练集进行网络的学习与训练,另一份作为测试集测试训练好的网络,不同验证码的样本集数量如表5所示。
在Python 2.7环境下实现了算法的整个流程,具体包括图像的预处理、图像分割及字符归一化,字符的训练和识别等。为便于对比,针对不同类型验证码识别的卷积神经网络设置为相同的训练参数,具体如表3所示。不同验证码图像的处理结果如表4所示,为便于查看效果,连通区域标记后的图像内同一连通域的颜色随机显示,识别错误的单个字符用下划线标注,不同验证码的识别率统计结果如表5所示。
表4本文算法对不同验证码图像的识别流程结果
Tab.4 Results of main steps of the proposed method for different CAPTCHAs’ images

从识别结果来看,形状相似的字符如s与5,n与h,0与6,y与v等识别的错误率较高;另外,字符分割不完整或存在多余信息时也会造成识别错误。由此可知,在验证码字符识别的过程中,分割是比识别更为困难的问题,单个字符分割的好坏程度将直接影响后续的分割结果。如网站1的验证码图片由纯数字组成,这种验证码字符种类较少,且字体工整,无扭曲变形,易于分割和识别;网站2~8的样本字符数较多,且部分存在扭曲粘连的情况,但经过改进的算法分割后,识别率也均达到了70%以上;网站9字体模糊,单个样本图像含有的字符数量太多,且存在严重粘连、扭曲和断裂的情况,这种类型的验证码分割较为困难,分割出的单个字符信息可能出现残缺或冗余情况,整体图像的识别率在10%左右。
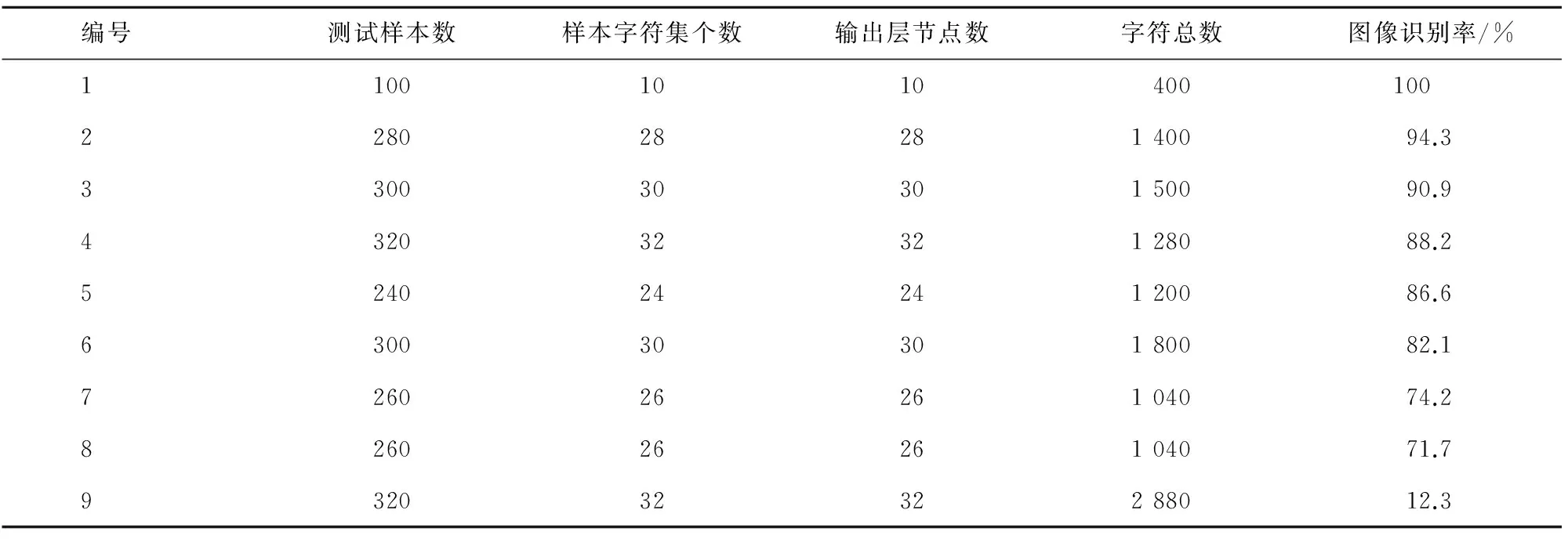
表5 不同验证码图像的识别统计结果Tab.5 Statistical data of different CAPTCHAs’ recognition experiments
从表5可以看出,结合卷积神经网络构建的基于图像分割的验证码识别方法能够适用于不同种类的验证码字符识别,且误识率较低,能够满足一般验证码识别的精度要求,具有一定的实用价值。
4 结论
针对9种不同类型的验证码字符图像,采用一种通用的字符分割方法,并结合卷积神经网络对分割得到的单个字符进行训练识别,取得了良好的识别效果。实验结果表明,基于图像分割的验证码识别方法对粘连、扭曲,且存在干扰噪声的验证码字符图像有着较高的识别率和适应性,对字符识别及相关领域的研究和应用具有一定的借鉴意义。但该方法对于存在严重粘连的、难以分割的复杂验证码图像的识别效果仍有待改善。因此,如何显著提高模糊粘连字符的分割成功率需要进一步研究。
参考文献:
[1]AHN L,BLUM M,HOPPER N,et al.CAPTCHA:Using hard AI problems for security[M].Berlin:Spring,2003:294-311.
[2]潘大夫,汪渤.一种基于外部轮廓的数字验证码识别方法[J].微计算机信息,2007,23(25):256-258.
PAN Dafu,WANG Bo.A digit validation image recognition algorithm based on exterior contour[J].Microcomputer Information,2007,23(25):256-258.
[3]BURSZTEIN E,MOSCICKI A,FABRY C,et al.Easy does it:More usable CAPTCHAs[C]//ACM Conference on Human Factors in Computing Systems,2014,2:2637-2646.
[4]MORI G,MAILK J.Recognition objects in adversarial clutter:Breaking a visual CAPTCHA[C]//IEEE Conference on Computer Vision & Patten Recognition,2003,1:124-141.
[5]HUANG S,LEE Y,BELL G,et al.A projection-based segmentation algorithm for breaking MSN and YAHOO CAPTCHAs[J].Lecture Notes in Engineering & Computer Science,2008,2170(1):1-4.
[6]CHELLAPILLA K,SIMARD P.Using machine learning to break visual human interaction proofs [C]// Advances in Neural Information Processing Systems,2004:265-272.
[7]YOSHUA B,DEEP LEARNING,Convolutional Networks[N/OL].(2013-01-12)[2013-11-06].http://www.deeplearningbook.org/contents/convnets.html.
[8]OTSU N.A threshold selection method from gray-level histograms[J].IEEE Transactions on Systems,Man & Cybernetics,1979,9(1):62-66.
[9]冯海文,牛连强,刘晓明.高效的一遍扫描式连通区域标记算法[J].计算机工程与应用,2014,50(23):31-35.
FENG Haiwen,NIU Lianqiang,LIU Xiaoming.Efficient one-scan algorithm for labeling connected component[J].Computer Engineering and Applications,2014,50(23):31-35.
[10]MARTIN T,HOWARD B,MARK H,et al.神经网络设计[M].北京:机械工业出版社,2002:201-210.
[11]LECUN Y,BOTTON L,BENGIOAND Y,et al.Gradient-based learning applied to document recognition[C]// Proceedings of IEEE,1998,86(11):2278-2324.
[12]SIMARD P,SETINKRAUS D,PLATT J.Best practice for convolutional neural networks applied to visual document analysis[C]//International Conference on Document Analysis and Recognition,2003:958-962.
[13]任柯昱,唐丹,尹显东.基于字符结构知识的车辆牌照识别的研究[J].计算机工程与设计,2006,279(21):4033-4035.
REN Keyu,TANG Dan,YIN Xiandong.Fast recognition method of license plate character based on image structure feature analysis[J].Computer Measurement and Control,2006,279(21):4033-4035.
[14]郭尚,苏鸿根.基于像素的计算大量连通区域面积的快速算法[J].计算机工程与设计,2008,29(7):1760-1763.
GUO Shang,SU Honggen.New fast area calculation of numerous adjacent connection regions based on pixel[J].Computer Measurement and Control,2008,29(7):1760-1763.
[15]王璐,张荣,尹东,等.粘连字符的图片验证码识别[J].计算机工程与应用,2011,47(28):150-154.
WANG Lu,ZHANG Rong,YI Dong,et al.Breaking visual CAPTCHA of merged characters[J].Computer Engineering and Applications,2011,47(28):150-154.
[16]AMARI S.Natural gradient works efficiently in learning[J].Neural Computation,1998,10(2):251-276.
[17]LAUER F,SUEN C,BLOCH G.A trainable feature extractor for handwritten digit recognition[J].Pattern Recognition,2007,40(6):1816-1824.
[18]TIVIVE,F,BOUZERDOUM A,et al.An eye feature detector based on convolutional neural network[C]//Proceedings of the 8th International Symposium on Signal Processing and Its Applications,2005:90-93.
[19]MATE S,AKIRA Y,MUNETAKA Y,et al.Pedestrian detection with convolutional neural networks[C]//IEEE Intelligent Vehicles symposium Proceedings,2005:224-229.
[20]YAN J,AHMAND A.A low-cost attack on a microsoft CAPTCHA[C]//Proceedings of the 15th ACM Conference on Computer and Communication Security,2008:543-554.
[21]连晓岩,邓方.基于图像识别和神经网络的验证码识别[J].中南大学学报(自然科学版),2011,42(增1):48-52.
LIAN Xiaoyan,DENG Fang.CAPTCHA recognition based on image recognition and neural networks[J].Journal of Central South University (Science and Technology),2011,42(S1):48-52.
[22]赵志宏,杨绍普,马增强.基于卷积神经网络LeNet-5的车牌字符识别研究[J].系统仿真学报,2010,22(3):638-641.
ZHAO Zhihong,YANG Shaopu,MA Zengqiang.License plate character recognition based on convolutional neural network LeNet-5[J].Journal of System Simulation,2010,22(3):638-641.
[23]SOLEM J.Programming computer vision with Python[M].北京:人民邮电出版社,2012:195-206.
[24]GONZALEZ R,WOODS K.数字图像处理[M].2版.北京:人民邮电出版社,2007:335-391.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
小哥白尼(军事科学)(2022年2期)2022-05-25
天津医科大学学报(2021年1期)2021-01-26
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
红领巾·萌芽(2019年8期)2019-08-27
数字通信世界(2019年3期)2019-04-19
中国与非洲(法文版)(2017年10期)2017-11-23
自动化学报(2017年5期)2017-05-14
