
基于电信数据的室外定位技术研究*
2018-05-08 09:38:58廖山河赵钦佩李江峰饶卫雄
计算机工程与科学 2018年4期
廖山河,赵钦佩,李江峰,饶卫雄
(同济大学软件学院,上海 201804)
1 引言
近年来,手机已深入大众生活,随着越来越多的智能手机应用需要位置信息来提供基于位置的服务,室外定位已经成为生活中不可或缺的一部分。
目前使用最广泛的定位方式是GPS(Global Positioning System)定位,普通手机上的GPS传感器平均定位精度能够达到10 m左右。但是GPS定位技术还存在几个方面的缺陷:(1)能量消耗迅速[1];(2)在高楼林立的市区、地下及室内等地方信号不好;(3)一些手机没有GPS模块;(4)定位通过手机端的GPS传感器模块才能获得。考虑到GPS定位的这些缺点,不依赖GPS的定位方式被不断提出。
特别值得注意的是,电信运营商虽然为手机用户提供通话和数据服务,但却无法知晓用户手机端的精确GPS位置,比如用户在通过4G数据网络使用百度地图或高德地图等手机端应用程序进行导航时,即使用户开启了GPS传感器,运营商后台也无法获取手机端的GPS经纬度位置。因此,工业界和学术界提出了不少定位算法,利用电信数据来获取手机用户端的位置信息。
电信数据指的是手机接收到的基站的各种信息,主要包括基站ID信息和基站信号强度信息两类,在用户通话或者使用流量上网时,运营商的后台可以获取这些数据。相比于GPS定位,利用电信数据进行定位的优点在于:(1)能耗低,手机其实是随时都在接收基站信号的,收集这些信息的额外能耗接近于零;(2)网络覆盖范围好,在室内或地下也可能有基站信号;(3)普适性好,几乎所有的手机都能接收基站信号;(4)数据的便捷性,运营商后台和用户手机端都能直接获取电信数据。如果能够利用好电信数据的这些优势,并通过一些新的算法来提高基于电信数据的室外定位的精度,那么将会有非凡的意义。
基于上述,本文的主要工作是利用电信数据,通过不同方法实现手机端的室外定位并进行实验评估。具体来说,本文的贡献包括以下几个方面:
(1)实现了一种指纹定位算法与两种机器学习的方法,在真实数据的实验基础上综合各种方法的优点,得到了一种定位效果非常好的机器学习模型——基于区域栅格化的随机森林分类模型,使用该模型在我们收集到的数据上能够达到平均误差15~20 m,中位误差10 m的定位精度。
(2)通过对收集数据时不同的运动模式及建模时不同的特征进行对比,证明了基站信号相较于其他传感器数据——地磁传感器信号,更加适合作为定位的依据。
(3)基于对数据的异常检测和聚类,探索了修复原始采样数据的方法。
本文内容安排如下,第2节概述国内外相关工作取得的成果和不足;第3节给出五种定位算法的具体实现;第4节进行实验与评估;最后,第5节总结本文工作及对未来工作进行展望。
2 相关工作
由于室外定位在现实中扮演着无法替代的角色,所以国内外在这方面都有大量的研究工作。针对GPS耗电量高的缺点,可以采用间隔启用GPS或者按需启用GPS的形式,Paek等人[2]在2010年时提出了针对智能手机应用的速率自适应定位系统RAPS(Rate-Adaptive Positioning System),RAPS使用一系列技术巧妙地确定何时打开GPS,它还采用了celltower-RSS(Received Signal Strength)黑名单来检测GPS的不可用性(例如在室内),并避免在这些情况下打开GPS,最终RAPS可以在GPS始终处于开启状态的情况下将手机待机时间提高3.8倍以上。
对于在室外时不使用GPS,利用基站进行定位的研究,目前大概有三类解决问题的方法。
第一类是基于测量计算的方法[3]。其基本思想是通过估计点对点绝对值距离或估计基站信号的角度来计算位置。经典方法包括到达角方法AOA(Angle of Arrival)[4]、到达时间方法TOA(Time of Arrival)[5]和基于接收信号强度(RSS)的单源定位[6]。具体地,Yang等人[7]进行了基于基站的三角定位实验,但是实验结果并不令人满意。Quattrone等人[8]于2015年提出一种综合了测距方法(Range-based)与无测距方法(Range-free)的两层定位模型,基于测距的方法依赖于采用几何技术的可靠测量,实际应用中测量非常容易受到误差的影响,无测距的方法不考虑实际的距离,而是比较传感器的幅度,但可能导致错误的累积。因此,该论文综合两者,首先使用基于测距的方法来确定近似位置,然后采用无测距的方法来进一步优化定位。Perera等人[9]也于同年提出了一种利用手机的主连接基站推断用户运动轨迹的方法,该方法只需要用户连接的主基站位置、时间和速度这几种信息,便可以计算出用户行进的距离,以此来推断轨迹的直线段和转折点。本方法的好处是不需要任何历史轨迹信息或训练,降低了存储和计算成本,但其缺点在于要想确定一条轨迹需要至少三个连续基站服务范围的信息,而用户需要定位时显然不可能移动这么远的距离,因此该方法无法直接用于定位。总的来说,这些方法的计算往往不是很复杂,但是需要高精度的测量,因此实际应用中定位精度较弱。
第二类是基于指纹识别的方法[10]。所谓指纹是指用于区分不同位置或区域的唯一依据。Quoc Vo和De两位IEEE成员[11]在2015年的文章中总结了当时所有的基于指纹识别的室外定位系统,它们使用通过传感器(如加速度计、麦克风、罗盘甚至日志)收集的数据来建立标识用户设备的唯一签名,并统计大量的数据建立指纹数据库,随后采用指纹识别的方法来定位用户设备。该论文中总共提出了三类指纹:一是视觉指纹,数据来源于照片或者视频,可以通过手机摄像头采集;二是运动指纹,数据来源包括通过加速度计得到的运动状态信息(运动或静止),和通过电子罗盘或陀螺仪得到运动方向信息(直行或转弯);三是信号指纹,数据来源包括WIFI接入点的信号、基站信号强度等。利用信号指纹进行定位不仅计算速度快,而且耗电量小,Cellsense是其中的代表方法[12],它将城市区域划分成一个个小的栅格,使用各个栅格里的基站信号强度RSSI(Received Signal Strength Indicator)的分布作为该栅格里的指纹。
第三类是基于机器学习的方法[13]。该类方法通过训练带位置信息标签的数据得到一个模型,之后就能利用该模型预测新数据的位置。在最近的工作中,Zhu等人[14]提出了一个基于Spark/Hadoop电信大数据平台的上下文感知回归模型,该模型是一个两层的随机森林模型,能够达到110 m的平均误差和80 m的中位误差。近期工作[15]提出定位后位置修复步骤,进一步优化定位精度。
目前不使用GPS进行定位的方法取得了很多成果,但是也存在不足,详细地比较各类方法能够帮助我们选择合适的方法进行移动定位[16]。普通手机GPS的定位精度能达到10 m,而上述提到的第一类方法,由于实际使用中的误差,精度远远达不到这个级别。第二类方法中综合使用多种类型的指纹可以使定位精度达到十几米,但仅仅使用基站信号强度作指纹的精度仍然在40 m左右。基站信号强度指纹与其他类型指纹的区别在于,其他类型的指纹数据只能在手机端收集,而基站信号强度指纹不仅可以在手机端收集,也可以在运营商的后台获取,两端可以独立地进行定位,这是它的一个巨大优势。对于第三类方法,我们利用机器学习模型(例如随机森林、神经网络等)进行室外定位的预测和对比,并且综合考虑第二类与第三类方法,既然指纹法可以将区域划分成栅格,并以栅格为目标进行定位预测,那么使用机器学习方法时也能利用该思路,将区域划分成栅格,从而不同于前期工作直接预测GPS经纬度位置的回归模型,而是根据分类的机器学习模型(预测用户位置在哪个栅格里)来解决定位的问题。
3 室外定位算法
本节首先简介本文工作的整体框架及相关术语,在3.2节中将会叙述如何实现一种基于指纹的定位方法Cellsense,这种方法将区域划分成大小相等的网格,预测时通过选择概率最大的网格来确定目标所在的位置。3.3节和3.4节分别介绍随机森林与多层感知器两种模型的应用,基于这两种模型我们使用了分类和回归两种方法。成功建立模型并预测之后,在3.5节探索了两种数据的后处理方法。
3.1 基本概念
本文所用的术语如表1所示,定位工作的数据全部由Android手机平台采集,整体流程框架如图1所示。
当手机与运营商的网络连接时,MR数据记录了手机的连接信息,这种连接信息包含基站(BS)的信息和信号强度数据。每条MR记录都包含至少一个基站的信息,通常情况下一条MR记录中有1到6个基站。其中,当前与手机连接的基站称
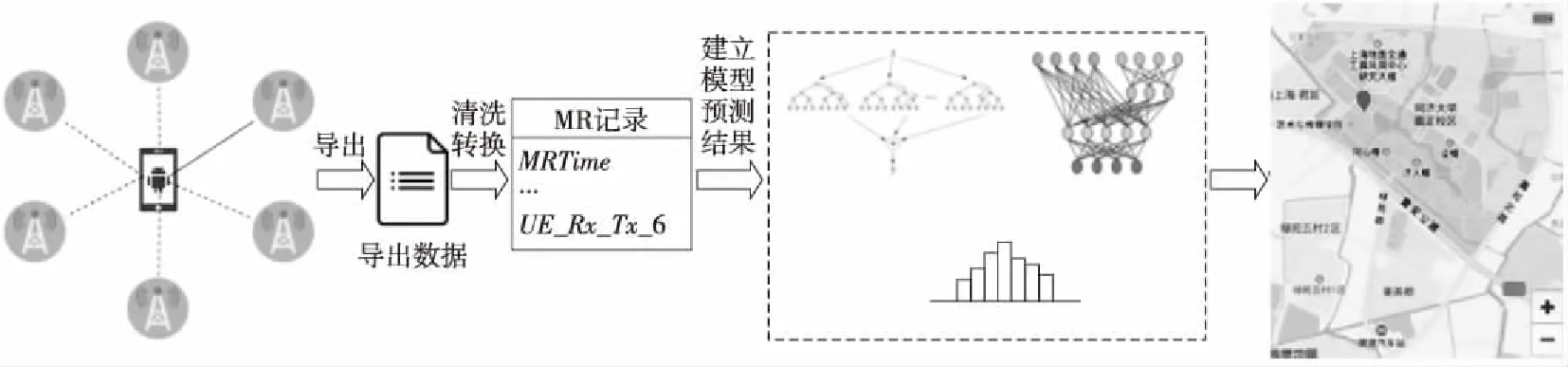
Figure 1 Framework of telecom data-based outdoor positioning图1 利用电信数据进行室外定位的框架

术语含义MR测量报告(MeasurementReport)数据,指的是手机所收集到的和基站有关的数据BSBaseStation,即基站IMSIInternationalMobileSubscriberIdentity,国际移动用户识别码RSSIRadioSignalStrengthIndex,基站信号强度值RFRandomForest,随机森林MLPMultilayerPerceptron,多层感知器CDFCumulativeDistributionFunction,累积分布函数
为主连接基站,而其他非主连接基站则称为邻接基站。手机的服务由主连接基站提供,当手机的持有者移动而使得手机超出当前主连接基站的服务范围时,主连接基站会从当前基站切换至邻接基站中的某一个。在本文所使用到的数据中,保证MR记录中基站列表里的第一个基站即是主连接基站。本文所使用到的MR数据格式如表2所示,Longitude和Latitude字段来自于手机GPS传感器,作为标签(Label)用于训练模型和测试时评估误差;MRTime记录采集的时间;IMSI用于区分不同的电话卡,在实际情况下,电话卡与手机之间往往是绑定关系,因此也同时区分了不同的手机;而以加数字结尾的字段均是基站信号的相关测量值,其中数字从1到6表示6个邻接基站(包括主连接基站)。
3.2 基于指纹识别的定位方法
指纹是用于识别某个特定位置或区域的依据。基于指纹识别的移动定位方法就是利用收集的数据构建不同地点的指纹,预测时将MR记录与各个不同的指纹进行比较,选择指纹最相符的地点作为预测位置。
Cellsense[12]是目前最先进的一种基于指纹识别的移动定位方法。它将城市区域划分为小网格,每个网格由该网格内手机连接到的每个基站的RSSI分布组成的指纹表示。对于网格中的每个基
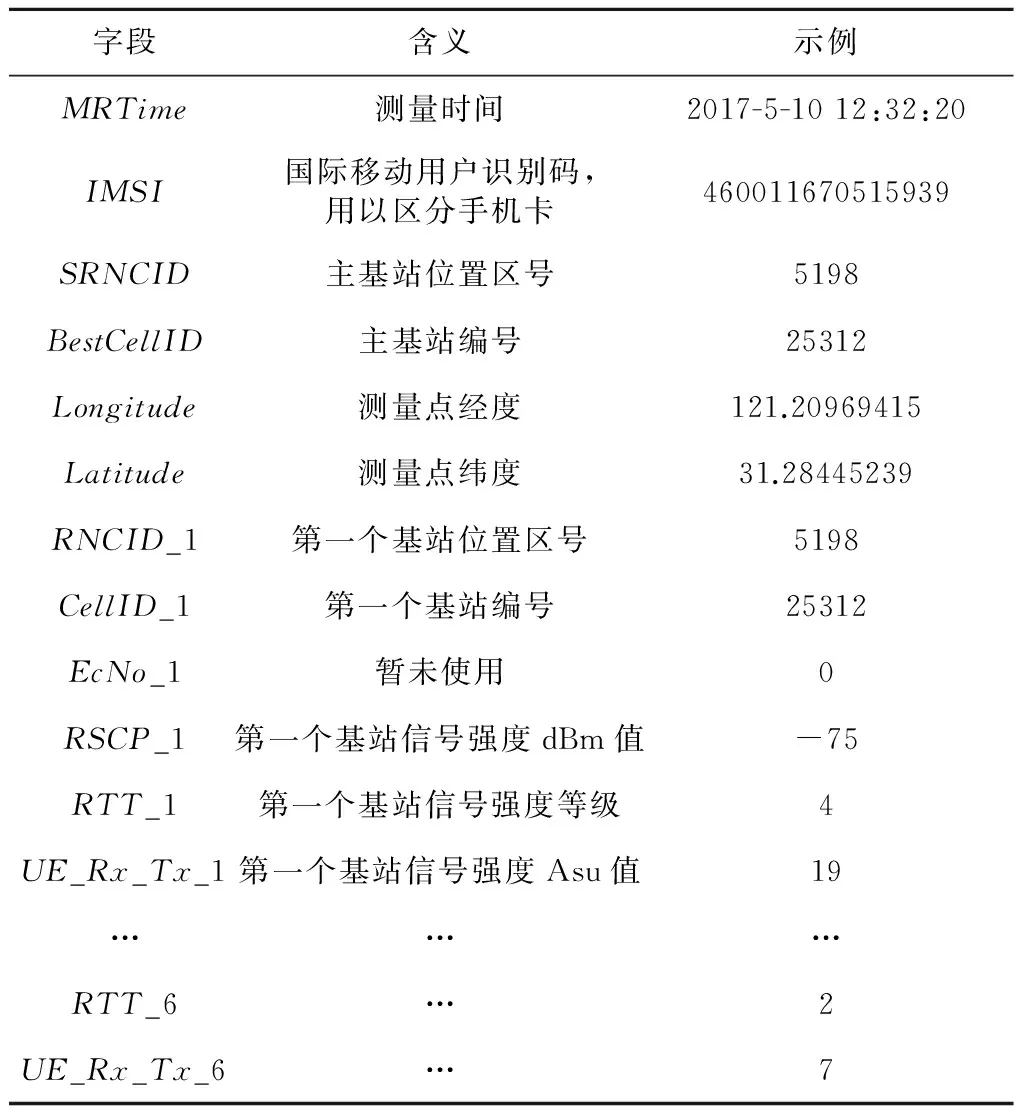
Table 2 Example of MR data表2 MR数据示例
站,将其RSSI分布设置为正态分布。当训练数据不足时,通过正态分布填充缺失值。Cellsense具体可以按照以下步骤实现:
(1)确定预测区域的范围,将预测区域划分为若干个正方形的栅格。
(2)训练模型:①将每条MR数据转换为三元组〈基站列表,RSSI列表,GPS坐标〉;②利用前面的结果,判断每条MR数据落在哪个栅格里,以此构建每个栅格各自的数据集合;③在每个栅格里,分别对每个基站对应的RSSI列表计算概率分布函数,如果一个栅格里有K个基站,那么就会有K个概率分布函数。
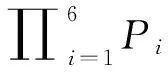
3.3 基于随机森林的定位模型
随机森林(RF)是一种由多个独立的决策树组成的模型,在本文工作中,我们利用MR数据中的信号测量作为特征,将位置点或位置网格用作训练机器学习模型的标签。位置点(即经度和纬度)可以通过回归模型预测,位置网格可以通过分类模型预测。
随机森林不需要用到MR数据的全部特征,但需要对特征做适当的处理,因此在训练模型之前要先进行特征提取的工作。特征提取的来源分为两部分,来源之一是手机所收集到的MR数据,来源之二是运营商提供的工参表数据,主要包含了每个基站的GPS坐标(经度和纬度)。将基站的经纬度加入,丰富特征,能够提高预测的效果。
回归模型根据MR数据和工参表提取的特征直接预测用户GPS坐标。
建立RF回归模型时,根据多次实验结果确定随机森林的参数,树的数量设置为100,树分裂时选取的特征数量设为总特征数的60%,评判分裂的效果时使用均方误差MSE(Mean Square Error),生成树使用bootstrap方法。
利用随机森林进行定位的另一种方法是建立分类模型。与利用指纹识别进行定位时的思想相似,将整个目标区域划分成多个栅格,此时预测目标从GPS经纬度变为预测用户在哪个栅格里,也从回归问题变成了分类问题。假设栅格的边长为D,并取栅格的中心作为每个栅格里所有数据的GPS坐标,那么在预测正确的情况下,预测值与真实值之间的误差最大大约为0.7*D,因此可以通过调整栅格的边长参数来实现定位精度与模型复杂度之间的取舍。
建立RF分类模型时,根据多次实验结果确定参数,栅格的边长设置为30 m,树的数量设置为100,树分裂时选取特征数量设为总特征数量的平方根,评价分裂效果时使用信息增益(Information Gain)作为指标,生成树使用bootstrap方法。
3.4 基于多层感知器的定位模型
多层感知器(MLP)是一种简单的前馈神经网络,本文使用了一个由一个输入层、一个隐藏层、一个输出层组成的三层MLP,用到的两种激活函数如图2所示。在隐藏层中,我们使用Relu(Rectified linear units)作为激活函数[17]。
与使用随机森林模型相似,我们分别建立回归模型与分类模型。基于MLP的回归模型直接根据输入特征预测用户的GPS坐标,因此输出层不需要使用激活函数。Keras包提供了现成的工具来构造神经网络,本文使用Theano[18]做后端,隐藏层的激活函数选择Relu,神经网络迭代次数设置为20次。
基于MLP的分类模型建立在区域栅格化的基础上,为了应用到MLP中,输出层使用Softmax作为激活函数[19],以保证输出的是落入各个栅格里的概率并且相加等于 1。最终选择概率最大的栅格作为用户所在的栅格,并将栅格的中心坐标作为用户的GPS坐标。构建分类MLP时,栅格的边长设置为30 m,隐藏层的激活函数选择Relu,神经网络迭代次数设置为20次。
3.5 数据的后处理
上面的工作实现了基于两种模型通过MR数据预测用户位置的方法,它们都能从训练集学习一个模型用于预测。但是,预测结果误差小的前提是手机收集到的MR数据是真实的,或者说因为设备原因造成的测量误差在允许范围内,如果用于训练的MR数据本身是不准确的,那么训练得到的模型自然就会出现偏差,用于实际应用时,因为设备不同造成测量值不同,进一步造成预测得到的结果不准确。另外,考虑到除了基站信号以外,手机内置的传感器还能收集地磁信号等数据,基站信号强度数据和地磁信号数据在物理环境中的分布是否有特定的规律,以及这种规律是否可以用于提高定位的精度,也是一个值得探索的问题。
因此,数据的后处理部分主要包括两方面:(1)针对MR数据和地磁信号数据的测量值,用一种异常检测的办法找出与绝大多数数据相差比较大的采样点,并对这些采样点的数据进行修复;(2)对MR基站信号数据进行聚类,探索是否存在一种固定的聚类模式,能够反映RSSI在物理环境中的分布情况,即每次聚类的中心点是否是大致确定的。对于以上两方面,异常检测得到的异常点和聚类得到的类中心点,如果它们存在一定的固定规律,能够用于定位大致位置,则将其称之为锚点(Anchor Point)。这部分工作参考了Dejavu系统[20],该系统是国外已有的成功案例。
3.5.1 异常点检测
锚点定义为多个点中的特异点,与绝大多数点的数据差异较大,本文中利用异常检测寻找锚点的思路为:

找出异常的特征值后,可以对这些点的数据以线性插值的方式进行修复。
3.5.2 基于聚类的锚点
每条MR记录构成一个向量v=([CID1,RSSI1],…,[CIDN,RSSIN]),通过计算两个基站信号强度向量的距离可以将所有的数据聚成不同的类,此为第一层聚类。之后,在不同的类簇中,依据MR记录的位置进行空间聚类,把在同一块区域中的MR数据聚到一起,此为第二层聚类。
第一层聚类时,使用层次聚类的方法,不同MR向量之间的距离计算公式如式(1)所示:
(1)
其中,A表示在两条MR记录中出现的基站的并集,fi(a)表示基站a在MR记录i中对应的RSSI值,如果在MR记录i中未接受到基站a,则fi(a)=0。式(1)的取值在0~1。计算类与类之间的距离时使用平均连接法(Average Linkage Method),当距离小于某个设定的阈值时停止聚类,本文中取值为0.3。
经过第一层聚类后,即使是相同的类,点之间的实际距离也可能相差很远,因此需要在每个类中再进行空间聚类,以便把同一区域中的相似点聚到一起。为了减少异常值的影响,在两层聚类中都只有在类中点的数量足够多时才接受。在第二层聚类时,也使用了层次聚类的方法,设定一个区分不同类的最大距离阈值,超过这个距离之后不再聚到同一个类中,在本文的工作中,该距离设置为20 m。聚类完成后,取每个类中所有点的中心作为该类的代表位置。
4 实验与评估
4.1 实验设置
4.1.1 实验环境
实验的软硬件参数如表3所示。
Table 3 Experiment settings表3 实验环境设置
4.1.2 数据集描述
实验所用到的数据收集于同济大学嘉定校区,如图2所示,收集数据时使用了7部手机以及走路(Walk)、跑步(Run)、骑自行车(Bicycle)、开车(Car)四种运动模式,并针对不同的信号制式(2/3/4G网络)进行了收集。数据的总量一共有149.1 MB,包含了55个子数据集,每个子数据集对应一次数据收集工作,覆盖的路径长度为4.5 km。因为工参表只有2/4G基站的参数,因此在实验中使用的是2/4G的数据,在实验前,先对2/4G数据进行基本的统计,表4展示了2/4G数据MR记录的统计结果,表5展示了2/4G基站的统计结果。
Figure 2 Locations of sampling points图2 数据采集点分布示意图

信号制式数据量/条手机到主基站距离中位值/m主基站RSSI平均值/dBmGSM(2G)32813977.88-75.12LTE(4G)16491453.79-85.96

Table 5 Statistics of 2/4G base stations表5 对2/4G基站的统计
4.1.3 评估标准
在实验中我们使用预测位置和真实位置之间的地球表面距离来判断定位效果的好坏,将其称为定位误差。由GPS经纬度坐标计算两点间距离的方法如式(2)所示。
S=2×arcsin
(2)
其中,lat1、lat2分别表示两个点的纬度,a=lat1-lat2为两点纬度之差,b=lon1-lon2为两点经度之差,r为地球近似半径,取6 378.137 km。
4.1.4 实验流程
本节首先对各种方法进行实验,给出各个方法效果的一个直观印象,包括定位精度和运行时间;之后会选择效果好的方法,进一步对收集数据时的运动模式、采用的特征的影响进行实验;最后,比较经过后处理的数据与原数据的定位精度。进行实验时,每种方法都采用十次交叉验证的方式得到最后的结果,并且结果以表格或者CDF曲线的形式展现。
4.2 不同方法定位精度的比较
首先,我们对不同方法的预测精度进行比较,作为一个基准实验(Benchmark)。如图3和图4所示,图中横轴表示定位误差,即预测点与真实点之间的直线距离,单位为m;纵轴表示各阶段误差数据比例的累计分布函数值。举例来说,纵轴(CDF)取0.5表示中位误差,此时横轴对应的误差值为E,则意味着50%的数据定位误差在E以下。该图对应的数值结果可以参照表6,p67为171.22 m表示67%的数据定位误差在171.22 m以下,p80与p90同理。表中加粗的数据为每阶段最好的结果。

Figure 3 Localization accuracy of different methods on 2G data图3 不同方法在2G数据上的定位误差
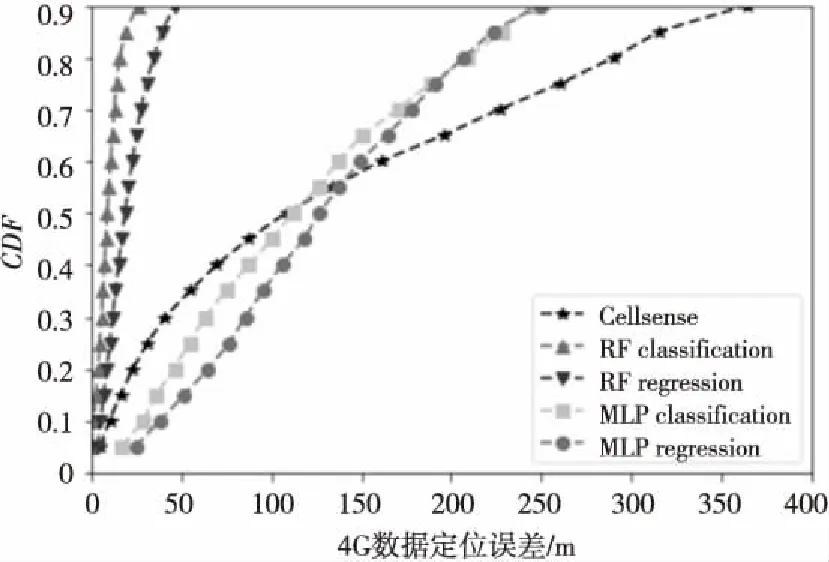
Figure 4 Localization accuracy of different methods on 4G data图4 不同方法在4G数据上的定位误差

信号制式方法平均误差/m中位误差/mp67/mp80/mp90/m2GCellsense180.1970.80171.22328.41526.422GRFclassification19.1510.0813.1516.9825.412GRFregression31.6320.6229.5640.9260.432GMLPclassification92.0154.6089.40143.80223.202GMLPregression157.22130.40180.80234.60305.104GCellsense159.45106.58206.32290.41359.984GRFclassification14.508.9712.2916.0426.364GRFregression31.7220.6829.7240.9560.734GMLPclassification127.84110.95157.30205.20244.004GMLPregression156.46129.10182.30238.50300.40
分析实验结果可以得出以下结论:
(1)首先从图中可以看出,2G数据与4G数据有相同的规律:很明显RF的定位精度要远远高于MLP与Cellsense的定位精度,而MLP与Cellsense相比较,只有少部分数据的Cellsense预测精度要比MLP的预测精度好,而当比较整体的预测精度时(超过53%的数据),MLP还是要比Cellsense更胜一筹。这是因为Cellsense是一种基于统计的方法,需要能够明确地区分各个栅格,收集数据时的路径实际上是一个环状的,环内部的基站信号强度数据并没有收集到,在构建各个栅格的指纹时,有一些栅格因为数据稀少或者缺失,无法构建能有效区分自己与其他栅格的指纹,因此定位时只有一些特征很明显的MR数据才被预测到了正确的栅格里,而其他的MR数据由于不同栅格太相似,在预测时出现了错误,导致误差很大。相比之下,MLP学习得到的模型虽然在一些位置的预测精度比不上Cellsense的预测精度,但从整体来看,它能更深层次地挖掘特征与位置的关系,因此总体效果更好。
(2)其次,比较分类与回归方法可以看出,不管是RF模型还是MLP模型,分类的效果都要优于回归的效果,例如,RF classification与RF regression相比,在2G和4G数据上分别有39.46%和54.28%的精度提升。这是因为在栅格化之后,每一类(每个栅格)数据的共性能够更好地被发现,因此预测数据属于哪个栅格比预测其具体GPS坐标要准确得多。
(3)最后,对比2G与4G两种信号制式可以发现,同一种方法对4G数据的定位精度要高于2G数据的定位精度,参照表4和表5可以发现,这是因为4G的基站到手机的距离以及基站之间的距离都比2G的小,即基站密度更大,在这种情况下,即使4G的信号弱于2G,定位精度也比2G高。
4.3 不同方法运行时间的比较
如图5所示是五种方法在2/4G数据上进行实验各自的运行时间,横轴表示不同的信号制式和不同的方法,纵轴表示算法运行的时间,以s为单位。由于实验中均采用十次交叉验证的方式,因此由每种方法运行时间除以10作为单次运行时间。很明显,MLP classification方法所用的时间最长,其次是Cellsense,而随机森林模型不管是进行分类还是回归,运行时间都很短。

Figure 5 Efficiency of different approaches图5 不同方法运行时间
另外,不管是RF还是MLP,分类方法的运行时间都大于回归方法的,这也可以理解,因为分类方法在训练之前需要先划分栅格,以及将训练集数据的GPS坐标转换为栅格的编号,预测之后又要将预测值从栅格编号转换回GPS坐标。
根据4.2节和本节的实验可以清楚地发现,不论是2G数据集还是4G数据集,随机森林分类模型在各方面都表现得非常优秀,因此为了表述简洁,后面进一步的实验都只用随机森林分类模型进行展示。
4.4 不同数据收集模式定位精度的比较
收集数据时采用了走路(Walk)、跑步(Run)、骑自行车(Bicycle)、开车(Car)四种运动模式,本节的实验主要研究运动模式对预测精度的影响。图6展示了RF分类方法对于2G数据不同运动模式的数据的预测结果,图7是4G数据相应的结果。
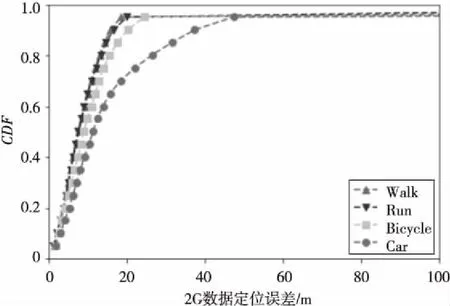
Figure 6 Effect of motion modes(2G data,RF classification)图6 运动模式的影响(2G数据,随机森林分类)
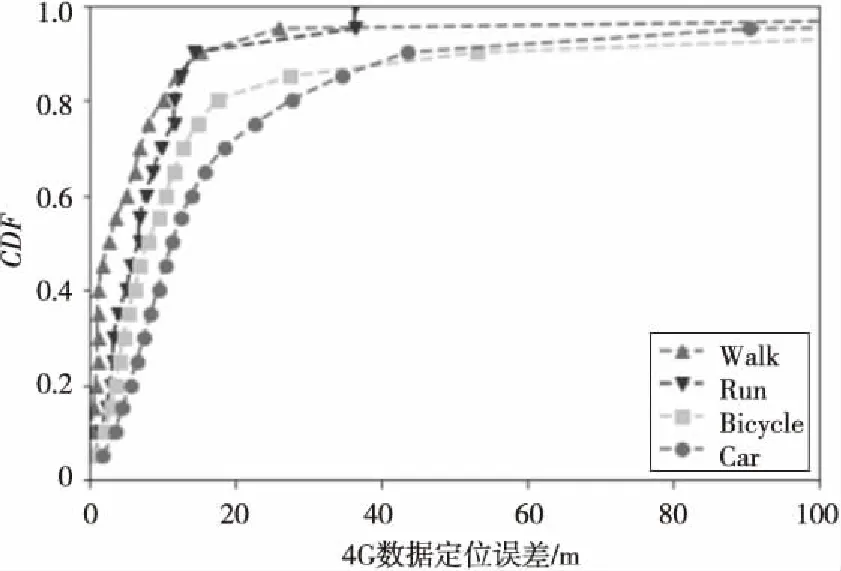
Figure 7 Effect of motion modes(4 Gdata,RF classification)图7 运动模式的影响(4G数据,随机森林分类)
很明显,走路(Walk)与跑步(Run)的结果要优于骑自行车(Bicycle)和开车(Car)的结果,这是因为收集数据的时间间隔是固定的,速度越快所收集数据的密度也就越低,在一块很小的区域内,可能就只有一两条数据甚至没有数据,自然定位误差也就更大了。具体到不同的运动方式,速度关系为v(走路) 第二次收集的数据包含了地磁信号,考虑到地球磁场是有规律的,那么手机收集到的地磁信号数据是否存在一定的规律,能够用来提升定位的精度呢?为了探究地磁信号对定位精度的影响,本节对地磁信号数据和基站信号数据的不同组合进行实验,以对比不同特征对定位精度的影响。 针对基站特征和地磁数据特征,一共进行了四种特征组合的实验:(1)以基站ID(CellID)和RSSI值作为特征;(2)以基站ID、RSSI值和地磁信号(geomag)作为特征;(3)以基站ID和地磁信号数据作为特征;(4)仅以地磁信号作为特征。从图8和图9可以看出,总的来说,加入地磁数据对提升定位精度并没有显著效果。在原本的特征上加上地磁数据作为新增的特征,最后得到的新CDF曲线与原曲线几乎重合,表明地磁特征的引入无明显作用;另一方面,对比CellID + Geomag曲线和Geomag曲线可以发现,相比于地磁数据,CellID对定位的作用更大,这是因为基站的位置与基站ID恒定不变,而地磁信号变化则大得多。 Figure 8 Effect of features(2G data,RF classification)图8 特征对定位精度的影响(2G数据,随机森林分类) Figure 9 Effect of features(4G data,RF classification)图9 特征对定位精度的影响(4G数据,随机森林分类) 在3.5节,我们参考Dejavu系统提出了检测数据异常点和聚类的后处理方法。实验发现,针对不同子数据集RSSI聚类得到的聚类点分布相差较大,因此由RSSI聚类寻找锚点的方法不可行。而针对不同的子数据集进行异常检测后得到的异常点分布相对来说,要稍微有规律一些,对异常点处的数据进行线性插值,将这种新的数据称为修复数据。对MR数据中主连接基站信号强度(RSCP_1)实施异常点检测,对比修复数据和原数据的定位效果如图10和图11所示。 Figure 10 Effect of RSCP_1 Repair(2G data,RF classification)图10 异常修复RSCP_1数据(2G数据,随机森林分类) Figure 11 Effect of RSCP_1 Repair(4G data,RF classification)图11 异常修复RSCP_1数据(4G数据,随机森林分类) 从图10和图11中的结果可以看出,修复后的数据对定位精度的提升很小,只在2G数据上总体定位精度的最差情况下有少许提升。究其原因,是因为修复的数据量在总数据量中占比太少,实际上,对原来的每个子数据集,异常检测得到的点少的只有几个,多的也只有几十个,相对于总的数据量来说,这些点的值即使修复了,对整体的影响也很小。 本节对收集到的数据进行了各种实验。首先对比了五种方法:Cellsense、RF分类、RF回归、MLP分类和MLP回归,得到了各个方法效果的直观印象,RF无疑是最优的模型,而MLP和Cellsense相较而言效果要差一些,其中MLP的总体误差比Cellsense更小,而分类的效果要好于回归,当然分类方法预测精度更高的代价是运行时间更长。之后我们又针对收集数据时的运动模式和建模时使用的特征进行了大量实验并选取随机森林分类模型展示实验结果:对比不同运动模式,我们发现速度越慢、数据越密集的运动模式定位精度越高;对比不同的特征,发现地磁信号对定位精度的提升没有明显作用,这是因为手机上的地磁传感器精度较差,且不同手机测得的数值差别也很大。最后,我们比较了经过后处理的数据与原数据的定位精度,发现由于后处理修复的点的数量太少,因此前后定位精度相差很小。 为了实现基于电信数据的移动定位工作,本文基于收集的真实数据,选取Cellsense、RF分类、RF回归、MLP分类和MLP回归五种方法进行实验。经过大量的实验,最终得到了随机森林分类模型是在电信定位中效果最好的模型,不管是定位误差还是运行速度都远远优于Cellsense和多层感知器模型。在实际的应用中,定位精度能够达到25 m,在好的情况下甚至可以达到10 m。这种方法不仅定位精度高,而且只需要基站信号强度数据就可以实现,因此普适性非常好;同时相比于GPS定位,收集基站数据的耗电量也很少;此外,由于基站信号数据本身的便捷性,既可以在用户的手机上利用该方法进行定位,也可以在运营商的后台实现。我们通过实验还证明了数据越密集,定位精度越高,因此可以通过调整数据采样频率进行精度与能耗的平衡。手机地磁数据对定位精度的提升不大,因为相较于基站信号的稳定性,地磁信号的分布规律更难确定,且不同手机由于硬件的差异使得地磁测量值相差很多。 在本文的工作基础上,未来还有以下几个可以继续研究的方面:(1)本文数据的覆盖范围还不够大,只在特定区域进行实验,下一步计划在广泛区域进行验证;(2)目前根据GPS轨迹判断运动模式的方法已经很成熟了[21],基于现有的工作,进一步地可以尝试根据基站MR数据来判断运动模式;(3)在定位的基础上,可以进一步研究运动轨迹推测与轨迹地图匹配。 参考文献: [1] Carroll A, Heiser G.An analysis of power consumption in a smartphone[C]∥Proc of USENIX Annual Technical Conference,2010:21. [2] Paek J, Kim J,Govindan R.Energy-efficient rate-adaptive GPS-based positioning for smartphones[C]∥Proc of the 8th ACM International Conference on Mobile Systems,Applications,and Services,2010:299-314. [3] Patwari N, Ash J N,Kyperountas S,et al.Locating the nodes:Cooperative localization in wireless sensor networks[J].IEEE Signal Processing Magazine,2005,22(4):54-69. [4] Swales S C,Maloney J E,Stevenson J O.Locating mobile phones and the US wireless E-911 mandate[C]∥Proc of IEE Colloquium on Novel Methods of Location and Tracking of Cellular Mobiles and Their System Applications,1999:2/1-2/6. [5] Lopes L,Viller E,Ludden B.Gsm standards activity on location[C]∥Proc of IEE Colloquium on Novel Methods of Location and Tracking of Cellular Mobiles and Their System Applications,1999:7/1-7/7. [6] Vaghefi R M,Gholami M R,Ström E G.RSS-based sensor localization with unknown transmit power[C]∥Proc of 2011 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),2011:2480-2483. [7] Yang J,Varshavsky A,Liu H,et al.Accuracy characterization of cell tower localization[C]∥Proc of the 12th ACM International Conference on Ubiquitous Computing,2010:223-226. [8] Quattrone A,Kulik L,Tanin E.Combining range-based and range-free methods:A unified approach for localization[C]∥Proc of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems,2015:49. [9] Perera K,Bhattacharya T,Kulik L,et al.Trajectory inference for mobile devices using connected cell towers[C]∥Proc of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems,2015:23. [10] Koshima H,Hoshen J.Personal locator services emerge[J].IEEE Spectrum,2000,37(2):41-48. [11] Vo Q D,De P.A survey of fingerprint-based outdoor localization[J].IEEE Communications Surveys & Tutorials,2016,18(1):491-506. [12] Ibrahim M,Youssef M.CellSense:An accurate energy-efficient GSM positioning system[J].IEEE Transactions on Vehicular Technology,2012,61(1):286-296. [13] Witten I H,Frank E,Hall M A,et al.Data mining:Practical machine learning tools and techniques[M].2nd Edition. San Francisco:Morgan Kaufmann Publisher Inc,2016. [14] Zhu F,Luo C,Yuan M,et al.City-Scale localization with Telco Big Data[C]∥Proc of the 25th ACM International Conference on Information and Knowledge Management,2016:439-448. [15] Zhang Yi-ge,Rao Wei-xiong,Yuan Ming-xuan,et al.Confidence model-based data repair for telco localization[C]∥Proc of 2017 18th IEEE International Conference on Mobile Data Management(MDM),2017:186-195. [16] Huang Yu-kun,Rao Wei-xiong,Zhu Fang-zhou,et al.Experimental study of telco localization methods[C]∥Proc of 2017 18th IEEE International Conference on Mobile Data Management(MDM),2017:299-306. [17] Hahnloser R H R,Sarpeshkar R,Mahowald M A,et al.Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit[J].Nature,2000,405(6789):947-951. [18] Bergstra J,Breuleux O,Bastien F,et al.Theano:A CPU and GPU math compiler in Python[C]∥Proc of the 9th Python in Science Conference,2010:1-7. [19] Anzai Y. Pattern recognition and machine learning[M].San Francisco:Morgan Kaufmann,2012. [20] Aly H,Youssef M.Dejavu:An accurate energy-efficient outdoor localization system[C]∥Proc of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems,2013:154-163. [21] Zheng Y, Liu L,Wang L,et al.Learning transportation mode from raw gps data for geographic applications on the web[C]∥Proc of the 17th International Conference on World Wide Web,2008:247-256.4.5 不同特征定位精度的比较
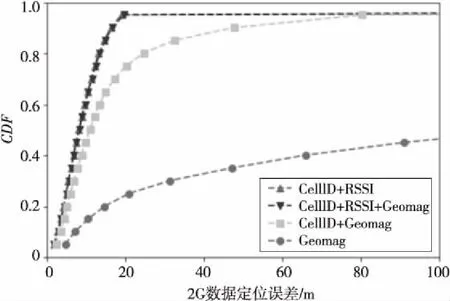

4.6 后处理对定位精度的影响
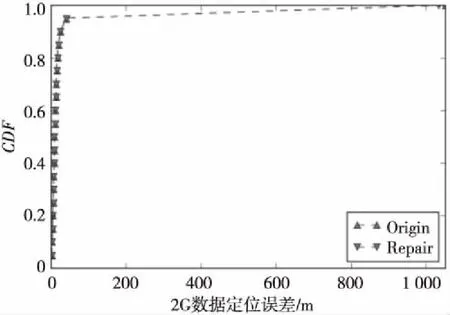
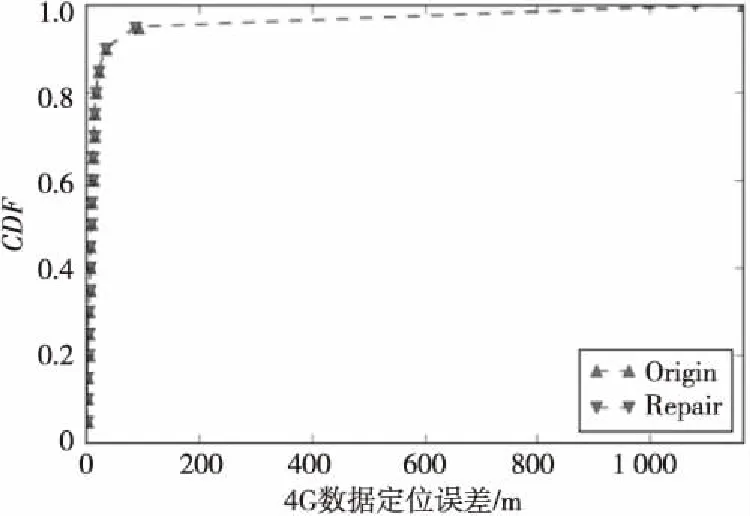
4.7 实验总结
5 结束语
猜你喜欢
军事文摘(2023年4期)2023-04-05 13:57:35
科技创新与应用(2021年31期)2021-11-09 13:11:18
小哥白尼(趣味科学)(2021年11期)2021-02-28 08:35:00
小天使·一年级语数英综合(2020年10期)2020-12-16 02:57:11
智富时代(2019年4期)2019-06-01 07:35:00
测控技术(2018年4期)2018-11-25 09:47:22
自动化学报(2016年8期)2016-04-16 03:39:00
青少年科技博览(中学版)(2015年7期)2015-08-12 18:50:24
弹箭与制导学报(2015年1期)2015-03-11 15:32:23
雷达学报(2014年4期)2014-04-23 07:43:13
