
农业水环境污染聚类预警分析
2018-05-07 05:45王惠申玮刘兴科王国臣彭佳红
电脑知识与技术 2018年8期
王惠 申玮 刘兴科 王国臣 彭佳红

摘要:控制农业水环境污染,保護农业生产环境具有重大意义。采用数据挖掘技术Kmeans聚类算法对2013年我国各地区农业水环境中化学需氧量、氨、氮、总磷、石油类、挥发酚、铅、汞、镉、六价铬、总铬、砷的排放量等指标进行聚类分析,并参照地表水环境质量标准GB3838-2002对污染种类与等级进行预警。结果表明,全国31个地区分为5类,第一类6个省份属于第Ⅴ类水环境等级;第二类11个省份属于Ⅳ类水环境等级;第三类8个省份属于Ⅳ类水环境等级;第四类1个省份属于Ⅳ类水环境等级;第五类5个省份属于Ⅲ类水环境等级。从结果中了解到了全国各地区农业水环境污染形成的原因,能够辅助农业水污染的预防和治理。
关键词:农业水环境;聚类算法;预警
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2018)08-0229-03
1概述
随着国内经济的快速发展与现代化工业设备的高度普及,我国农业生产迅速发展,严重影响地区水环境生态安全。从环境保护的角度来分析,水污染主要是指由人类活动产生的污染物而造成的。它主要有三大污染源:工业污染源、生活污染源和农业污染源。其中农业作为国民经济发展的基础,对于宏观经济发展具有不可替代的作用。因此针对我国突出的农业水环境问题,迫切需要建立水环境污染事故应急预警系统,水环境污染预警系统能够未雨绸缪,在水质恶化的早期阶段提醒管理者,从而及时制定水资源保护计划,进而开展相关预警工作,并能有力有效地支持水资源的可持续利用,为早日实现国家可持续发展战略目标奠定基础。在国内,预警系统的发展还处在起步阶段,建成的很少,主要集中于大城市。
聚类分析是多元统计分析方法中的一种,是非监督模式识别的一个重要分支。所谓聚类,是将一个数据单位的集合(数据源)分割成几个称为类或类别的子集,每个类内的对象之间是相似的,但不同类的对象间区别相对较大。聚类分析是根据事物本身的特性研究对被聚类对象进行类别划分的方法。我们采用此方法对全国各地区2013年的废水数据及各项相关指标进行了相应的预处理,并深入分析水环境数据,参照地表水环境质量标准GB3838-2002对污染的种类与等级进行处理,并对数据进行分析、整理与预处理。
2材料与方法
2.1数据来源
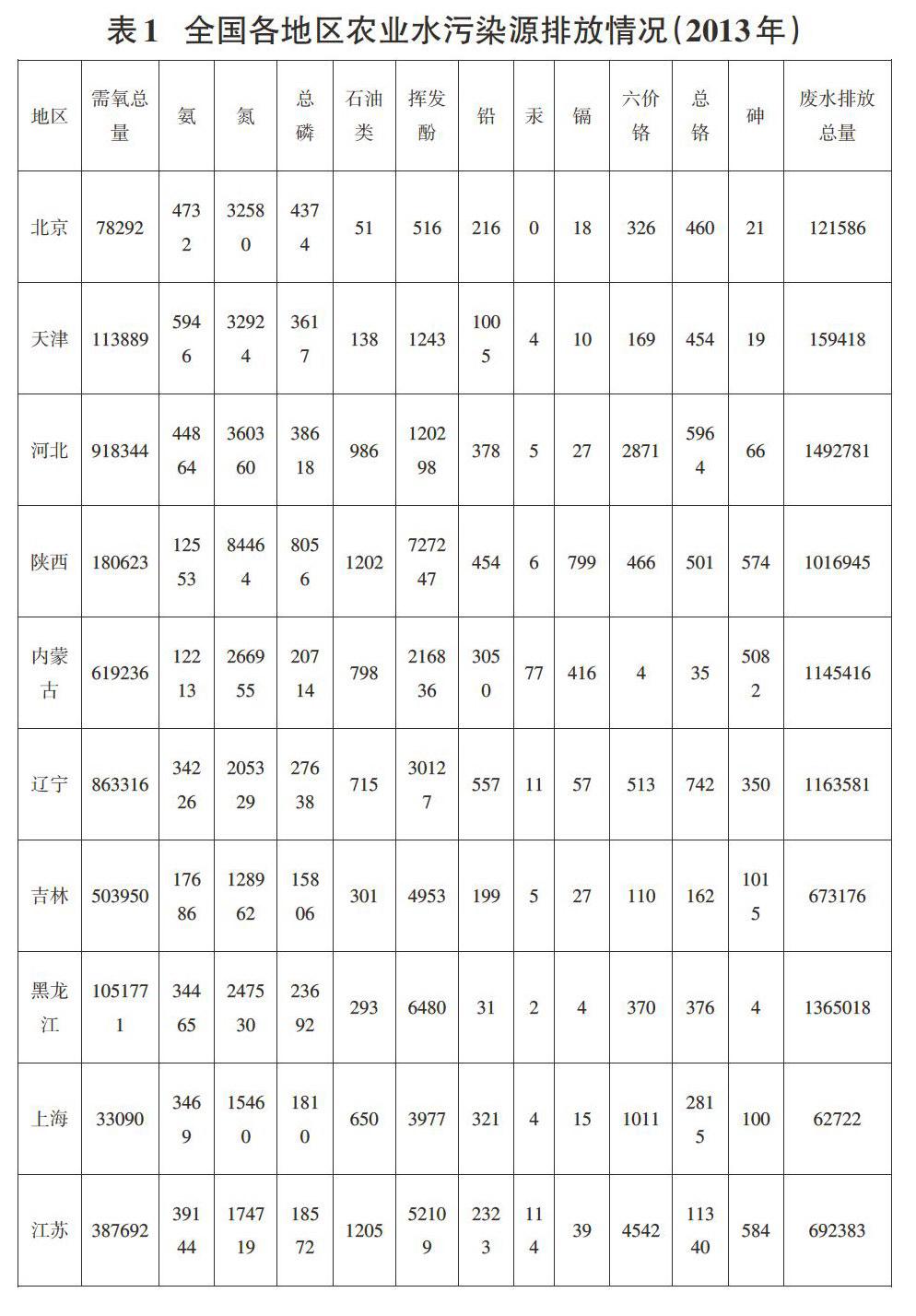
来源于2013中国环境统计年鉴,处理后的数据见表1。
2.2聚类技术Kmeans算法
聚类指一个类簇内的实体是相似的,不同类簇的实体不相似;一个类簇是测试空间中点的会聚同一类簇的任意两个点间的距离小于不同类簇的任意两个点间的距离。类簇可以描述为一个包含密度相对较高的点集的多维空间中的连通区域。聚类算法的选取主要取决于所研究数据的类型、聚类的目的和应用等。聚类算法大致上可分为层次聚类算法、划分式聚类算法、基于密度的聚类算法、基于网格的聚类算法、基于模型的聚类算法等。
Kmeans算法是一种基于划分的聚类算法,它通过不断的迭代过程来进行聚类,当算法收敛到一个结束条件时就终止迭代过程输出聚类结果。该算法的基本思想:先指定需要划分的簇的个数k值;然后随机地选择几个初始数据对象点作为初始的聚类中心;第三,计算其余的各个数据对象到这个初始聚类中心的距离,把数据对象划归到距离它最近的那个中心所处在的簇类中;最后,调整新类并且重新计算出新类的中心,如果两次计算出来的聚类中心未曾发生任何的变化,那么就可以说明数据对象的调整已结束,也就是说聚类采用的准则函数是收敛的,算法结束。
2.3数据处理
对近来全国历史数据以及特定的边界条件包括水资源总量,各流域水资源、节水灌溉面积、农业用水,重要河流、湖泊水质状况评价结果(河长统计和监测断面统计),各地区的废水排放及处理情况:如化学需氧量、氨、氮、总磷、石油类、挥发酚、铅、汞、镉、六价铬、总铬、砷的排放量情况信息的采集,数据的传递和接收。获取CSV文件,利用Weka组件导人数据,进行初始处理。预警模型计算进行预测环境污染的发生趋势,将研究污染物形态分级与定量结构、环境污染预测,建立分析预警模型。
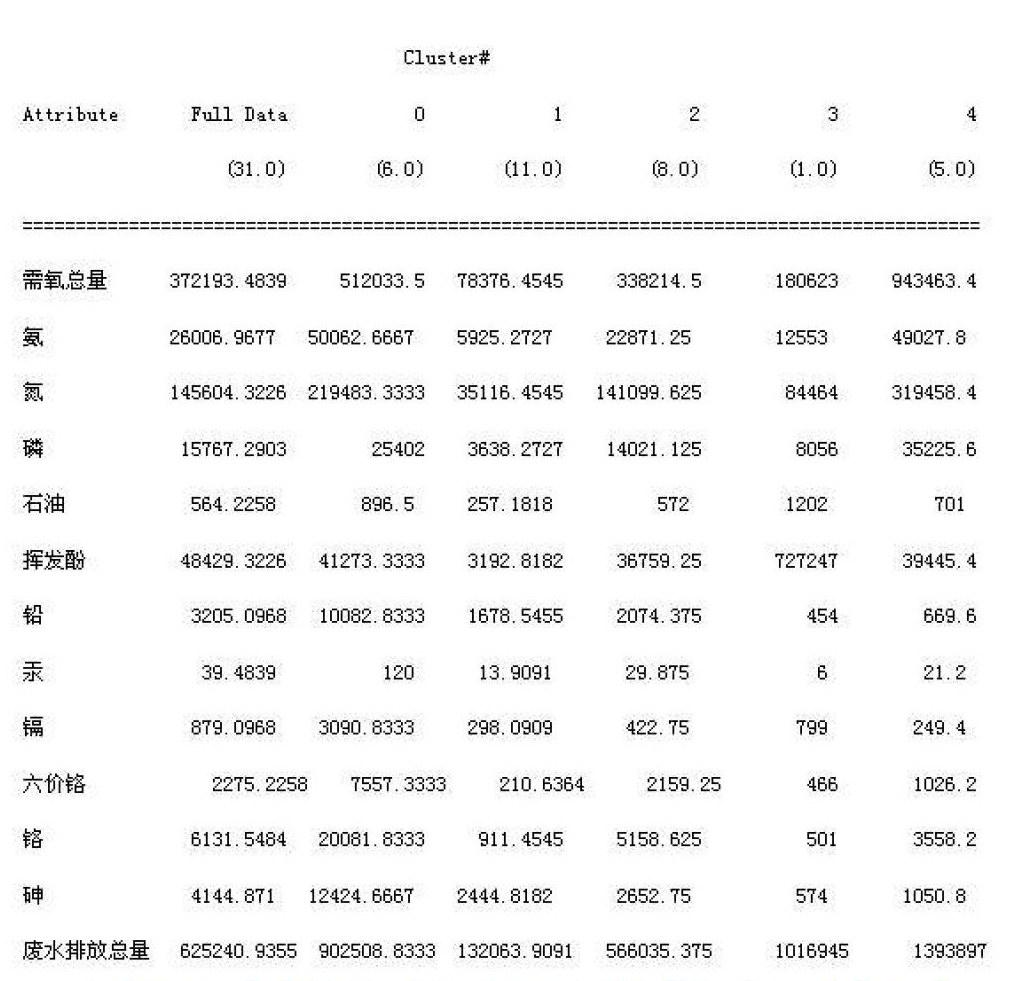
利用Weka软件,采用Kmeans聚类算法,对表1的数据进行聚类处理,得到的挖掘结果如下所示:
根据以上聚类结果,我们可以看到把数据中31个地区分成了5类,各类的特点如下:
①第1类包含6个省份,这些省份磷元素指标(均值25402)、挥发酚指标(均值41273.3333)和铅元素指标(均值10082.8333)在平均水平范围之内,其他排放量指标均超出各省平均水平。
②第2类包含11个省份,这些省份各个元素排放量指标均在各省平均水平范围内,六价铬(均值210.6364)、铬元素指标(均值911.4545)远远低于各省平均水平。
③第3类包含8个省份,这些省份石油类指标(均值572)超出各省平均水平,其他元素排放量指标均接近各省平均水平。
④第4类包含1个省份,这个省份石油类指标(均值1202)和挥发酚指标(均值727247)超出各省平均水平,其他指标均在各省平均水平范围。
⑤第5类包含5个省份,这些省份需氧总量(均值943463.4)、氨(均值49027.8)、氮(均值319458.4)、磷(均值35225.6)、石油类(均值701)排放量指标均超出各省平均水平,其他在各省平均水平范围内。
3结果分析以及结论
3.1结果分析
分析聚类Kmeans算法聚类结果,可以得出以下结论:
第一类的6个省份,分别是海南、新疆、云南、山东、广西、四川,这些地区是我国农业发展大省,是我国周围边陲地区,农业种植面积和产业比重占较多,所以各个元素指标均超全国各地区平均水平,整体农业水污染也较严重。
第二类的11个省份,分别是内蒙古、安徽、福建、江西、湖北、湖南、重庆、贵州、西藏、甘肃、宁夏,具有单位面积农资投入量较大的特点但欠发达,有些省份畜牧业发达带动草业农业发达展,所以农业水环境污染相对全国其他地区较轻。
第三类的8个省份,分别是河北、陕西、辽宁、吉林、河南、广东、山西、青海,这些省份是我国石油产量前十内的省份,大多又都是内陆省份,所以石油类指标超出全国平均水平,农业投入面积较大但是欠发达,所以农业水污染并未超标。
第四类的1个省,这个省份是黑龙江,黑龙江是我国石油产量最大的省份,此外黑龙江也是我国农业大省,所以它的石油和挥发酚指标超出全国各个省份平均水平,但农业水污染还在全国各省水平范围内。
第五类的5个省份,分别是北京、天津、上海、江苏、浙江,这些省份具有电子科技轻工业服务业等发达,农业技术超前但投入面积小的特点,所以这些省份的氨、氮、磷、需氧总量超全国各省平均水平,但农业水污染在全国各省范围内,相对污染较轻。
根据划分情况,参照地表水环境质量标准GB3838-2002对污染的种类与等级进行处理:第一类的省份属于第Ⅴ类水环境等级;第二类属于Ⅳ类水环境等级;第三类属于Ⅳ类水环境等级;第四类属于Ⅳ类水环境等级;第五类属于Ⅲ类水环境等级。
3.2结论
农业水污染具有污染源多样性、非特定性、不确定性等特点,已经对我国现代化产生严重的影响,因此进一步提高对废水污染认识,了解其形成原因,辅助快速而有效的控制农业水污染具有重大意义。采用数据挖掘聚类技术对各省份的农业水污染数据进行聚类处理,将全国各地区的农业废水排放情况为标准,从分析结果中我们了解到了各地区农业水污染形成的原因,从而对其各地区农业水污染进行预警,便于农业水污染的预防和治理,从根源上控制农业水污染。
猜你喜欢
中华建设(2020年5期)2020-07-24
今日农业(2019年12期)2019-08-13
现代园艺(2017年22期)2018-01-19
现代电子技术(2016年23期)2017-01-12
中国卫生(2016年12期)2016-11-23
航天返回与遥感(2014年4期)2014-07-31
