
SQL Server中获取多音字拼音首字母
2018-05-07 05:45陈令刚
电脑知识与技术 2018年8期
陈令刚

摘要:汉字拼音的首字母,可以简化商品的名称、客户单位的名称的查询,比如,在医院管理信息系统中,输入:“JN”就可以定位到“胶囊”。实现这一功能的关键在于提取出汉字的拼音首字母。但是当查询的汉字为多音字时,往往会提取错误的汉字首字母,如”银行”,容易提取的首字母为”YX”,实际应为"YH"。针对这一问题,提出了建立多音字词组与其首字母对照表的方法,首先判断语句中是否含有多音字词组,如果包含多音字词组则从多音字词组对照表中获取对应的汉字首字母。实验结果表明,提出的建立多音字词组与其首字母对照表的方法是可行的。
关键词:汉字拼音;SQL Server;排序规则
中图分类号:TP301 文献标识码:A 文章编号:1009-3044(2018)08-0005-02
1引言
在一些软件系统中,常常需要快速定位特定的信息,比如医院药房管理系统,工作人员查找药品规范名称,这时汉字录人的效率就比较低,如果只录入汉字拼音的首字母(汉字首拼),效率会有很大的提升,当要查找的汉字字数在4、5个以上时,汉字首拼的其重码率是很低的。实现这一功能的关键在于,在数据库的表结构中增加一列字段作为对应的汉字的拼音简码,这就需要提取出汉字的拼音首字母,获取汉字的首拼音。最容易想到的便是建立一个码表,也就是汉字与汉字首拼的对应表,但是这种方法要将所有汉字的汉字和首拼存到数据库,既费时又费力,且获取汉字首字符的效率也比较低。为此参考文献中提出了一种基于SQL Server排序规则的一种函数,但是该函数没有考虑到汉字多音字的情况。比如在获取“银行”的拼音首字母时,其函数实现的结果为“YX”,正确结果应该为“YH”,于是本文提出了一种改进的获取汉字首拼算法,使其能够提取出正确的多音字首拼,实验结果表明该方法是有效的。
2 SQL语言中的排序规则
排序规则是根据特定语言和区域设置标准指定对字符串数据进行排序和比较的规则。SQL查询语言中,order by语句实现查询结果的排序,其语法规则为:order by<排序列名>[ascIdesc]。跨库多表连接查询时,若两数据库默认字符集不同,系统就会返回这样的错误:“无法解决equal to操作的排序规则冲突”。英文报错为Cannot resolve collation conflict for equal to operation。这是由于默认字符集的不同导致SQL排序规则不同而引起的。SQL Server数据库提供一整套windows和SQL server专用的排序规则,SOL语句在具有不同排序规则设置的不同数据库上下文中运行时,其运行结果可能会不同。SQL Server排序规则由Windows区域设置(或者说字符集,如繁体和简体)和Windows排序规则后缀组成。SQL Server数据库支持的排序规则可以通过下面系统函数查看:
select*from::fn_helpcollations();
常用的汉字排序方式有:Chinese_Taiwan_Stroke_BIN、Chi-nese_Taiwan_Stroke_CI_AS、Chinese_PRC_BIN、Chinese_PRC_CI_AS。其中Chinese_PRC指中國大陆地区简体字,Chi-nese_Taiwan指中国台湾繁体字,Stroke是指按照笔画顺序进行排序,默认是按拼音排序,BIN指定使用向后兼容的二进制排序顺序,CI表示不区分大小写,AS表示区分重音。
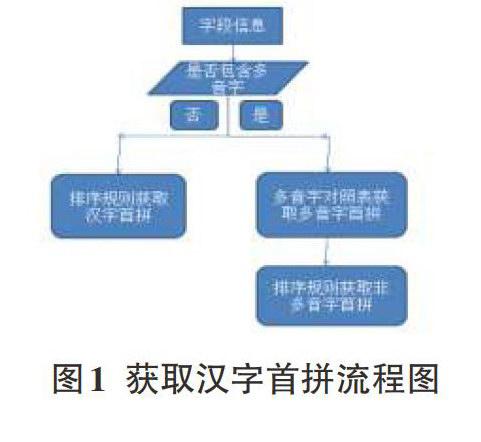
3 SQL Server获取多音字首拼原理
汉字的拼音首字符有23个,分别为:A、B、C、D、E、F、G、H、J、K、L、M、N、0、P、Q、R、S、T、W、X、Y、Z,代表23组汉语拼音音节。本文设计的函数依照Chinese_PRC_CI_AS_WS排序规则(大陆地区简体字,不区分大小写,区分重音,不区分全角半角),音节的排序顺序为依次升序排列。拼音字母在汉语拼音表中的序号作为它们相互比较大小的依据,如果两个汉字的拼音相同则认为这两个汉字大小相同。如“B”在汉语拼音表中排在“C”之前,则认为"B"小于"C"。如“曲(qu)”比“奇(qi)”大比“柔(mu)”小,则其首字符必然是“q”。但是这种方法没有区分汉字为多音字的情况,当检索语句中出现多音字时这用方法往往会提取出错误的首拼,比如“中国人民银行”,这种方法获取的首拼为"ZGRMYX"。通过分析发现多音字及其组成的词组数量比较少,于是本文提出了一种改进的实现方式,首先建立一个多音字词组与其正确的首字符的对照表,然后判断检查输入的语句中是否含有多音字词组,若检测出多多音字词组,则提取多音字词组与其首拼对照表中的首拼作为结果,算法流程图如下:
