
基于Apriori关联算法的配电网运行大数据关联分析模型
2018-05-04 07:53:36
上海电力大学学报 2018年2期
(国网上海浦东供电公司,上海 200122)
近年来,信息技术日益发达,配电网运行过程中积累了大量的运行维护数据。这些数据已广泛应用于电力系统规划、运行、资产管理、市场管理以及终端用户服务等各个领域[1]。通过有效分析来自各种智能表计的大数据,可以帮助决策部门更好地获得电力用户的相关信息[2]。目前,大数据分析在电力系统中的实际应用处于快速发展阶段,研究者从数据传输、存储、实时处理、多数据源异构和可视化等方面分析了电力大数据处理技术的发展现状和面临的挑战,提出了智能电网评估指标体系及评价方法[3-4],并给出了配用电大数据分析架构和应用路线图[5-8]。本文将大数据分析及数据关联挖掘技术应用于配电网的运行维护中,提出了基于Apriori关联算法的配电网运行大数据关联分析模型,以期为提高配电网运行维护指标提供决策建议。
1 配电网运行维护与大数据技术应用现状
1.1 配电网运行维护存在的问题
配电网运行维护是对配电网及其设施所采取的巡视检查、保养、简单修理等技术管理设施和手段的总称,主要包括基础数据管理、巡视检查与防护、配电网维护、状态评价、缺陷管理、用户公用设备移交、保供电管理、电压与无功管理,以及方案审查与设备验收投运等工作。在目前的配电网运行维护过程中,主要存在以下3个问题[9-13]。
(1) 配电网网架基础薄弱,自动化水平低,检测手段相对落后,且网点多、线长、面广,使得配电网的运行维护任务十分艰巨。与国外先进国家相比,我国在发电、输电、配电方面的投资比率差异较大。近年来,随着资金的不断投入,配电网的运行状况得到了很大改善,但与主网相比,基础设施仍显太差,网架结构仍然十分薄弱,尤其是台区低压设备老旧问题日益突出,用电高峰时段低压故障频发,供电抢修工作愈加繁重。
(2) 社会生产、生活用电激增,负荷增长屡创新高。区域性、季节性负荷需求对配电网的供电能力和运行维护提出了更高的要求。社会电气化程度越来越高,部分高新技术、高附加值产业用户对电能质量的要求也越来越高,使配电网安全稳定运行承受了巨大压力。
(3) 配电网运行维护管理模式相对滞后。在当前的配电网管理模式下,只有当线路发生跳闸时,才能发现设备出了问题,在缺陷消除后,并没有认真分析原因,导致此类问题仍会发生,形成恶性循环,造成了巨大的人力、物力的浪费及供电量的损失。
1.2 大数据技术应用现状
国内对电力大数据的研究主要集中在电力企业的生产、运营、管理等方面,在输变电设备故障识别与预测、配电设备负载估算及重过载预警、物资库存物料需求影响因素分析、配电网低电压实时监测应用、电网中长期负荷预测与用电量分析等方面已有实际应用。但在配电网的用电量预测、空间负荷预测、多指标关联分析等领域,由于国内难以支持智能配电系统和用户侧管理系统的有效集成,因此与国外的大数据应用方面存在巨大差距。
随着配电网业务覆盖面的进一步扩大,逐渐积累了超过TB级的数据,然而大多数电力企业的数据库仅仅实现了数据存储、查询、统计等最基本层次的功能,无法深入挖掘出隐藏在海量数据背后的潜在价值。因此,大数据技术在配电网运行维护管理中的应用已经势在必行。它是电网运行维护向更优、更强发展的必要手段。
2 上海配电网配用电信息系统及关联规则挖掘算法
2.1 上海配电网配用电信息系统及其数据特征
表1为上海电力公司目前投运的配用电信息系统及其输出数据类型。
对以上配电网生产系统信息进行梳理,可用于中压配电网指标评价大数据关联分析的数据如下:电网电气拓扑数据;用户台账数据及关联关系;线路、变压器设备台账数据;10 kV设备巡检、缺陷记录等;调度操作日志,设备操作日志;中压馈线电流数据;台区冻结电量及负荷数据;电压监测点数据;故障事件数据;停电事件数据;抢修工单信息;电能质量及事件数据;日/月线损率;电压合格率。
2.2 关联规则挖掘算法
1993年,AGRAWAL等人首先提出了关联规则的概念,同时给出了相应的挖掘算法,但是性能较差。1994年,他们建立了项目集格空间理论,并提出了著名的Apriori算法,至今Apriori仍然作为关联规则挖掘的经典算法被广泛讨论,其后诸多的研究人员对关联规则的挖掘问题进行了大量的研究。

表1 上海电力公司配用电信息系统及其输出数据
关联规则挖掘的对象一般是事务数据集。关联规则可定义为:设T={t1,t2,t3,…,tk,…,tm}为事务数据库,tk为T的第k件事务,I={i1,i2,i3,…,ik}是二元属性的集合,其中的元素称为项,对任意k,tk⊆I;X与Y是I的子集,X∩Y=Ø,在事务数据集中寻找X与Y的关联关系,关联关系记为X⟹Y。关联规则里有两个重要概念:支持度和置信度。支持度表示X和Y这一事件组合在总事务记录中出现的概率,置信度是指出现了项集X的事务中X和Y这一事件组合出现的概率。最小支持度Smin和最小置信度Cmin规定了支持度和置信度的阈值,只有达到这两个阈值才算强关联规则。
配电网运行维护中的各个指标,与配电网的设备情况、运行情况、人为因素、天气情况等均有着复杂的因果或关联关系。这些关系有些是明确或显而易见的,有些还未被明确发现,特别是一些关联不是特别强但对实际生产运行影响较大的关联关系。如果能够通过大数据分析方法寻找到这些关联关系,将为提升配电网运行维护指标提供更多的依据和手段。本文采用Apriori关联算法,将配电网运行维护数据与配电网事件或指标数据进行关联分析,得到配电网运行维护指标与运行状态、事件变化之间的关联关系及关联强弱。
3 配电网运行大数据关联分析模型
3.1 报表类数据关联分析
对于时间报表类数据,如故障抢修事件报表、设备缺陷记录等,在分析各项数据事件之间的关联关系之前,需要对报表数据做以下处理。
(1) 数据归一化 将含义相同但表述不同的项目统一成相同的描述语言,以提高算法的计算效率。例如,“电网故障”和“电网性故障”统一成“电网故障”,“过负荷”和“过载”统一成“过负荷”,“0.4 kV”和“380 V”统一成“0.4 kV”。
(2) 提取描述性语言的关键词 现有的技术手段无法对描述性的语言进行分析,所以对于“故障描述”等主观性较强、规范性较低的项目,需要提取能够表征该项目描述的关键词,将关键词作为事务数据进行关联性分析。如“欠费停电,客户已付”提取关键词“欠费停电”,“设备故障,客户报修此处电表内总闸跳闸,请处理”提取关键词“设备故障”“跳闸”,“电能质量,客户报修一户电压低,电器无法正常使用,请处理”提取关键词“电能质量”“电压问题”“电器无法使用”。
(3) 去除无用项和重复项 将重复的项目或对于记录无实际区分作用的项目删除。如项目“故障类型”,实际一般填写为“非外损因素”或空,可以去除该项,以避免关联计算时数据维度过高,影响计算效率。
(4) 形成事务数据集 按照上述原则,将每条记录中的数据进行整理后,每个数据项的集合形成事务全集I={i1,i2,i3,…,ik,…},其中ik为某项事务。对每条记录即形成一个事务数据集Ik={i1,i2,i3,…,ik,…},每个Ik包含了若干个ik。将所有报表记录作为事务数据集的集合T={I1,I2,I3,…,Ik,…},对T进行关联分析,即可得到T中各事务ik之间或事务集X(X是某些ik的集合)与事务集Y(Y是另一些ik的集合)之间的关联关系,并得到这些关联关系的支持度和置信度。
3.2 时序事件数据关联分析
将馈线电流、电压这些时序运行数据进行离散化处理,并在离散化的过程中保持事务的时序运行特征和趋势。
(1) 数据频度设置 数据设置频度需考虑时序数据频度、事件指标频度及实际计算能力。每个时间断面会生成一个事务数据集,如果分析的数据频度过高,将会产生较多的事务数据集;如果分析的时序数据持续时间较长,将会产生高维数据矩阵,这对计算机的计算能力要求很高。建议设置15 min/断面或1 h/断面的频度,最大程度地保留时序运行数据特性。
(2) 连续时序数据事务离散化 将连续的时序数据离散化,如在t1时刻,馈线电流I满足0≤I<1 A时,设置为事务I0;1 A≤I<2 A时,设置为事务I1;2 A≤I<3 A时,设置为事务I2……以此类推,将连续的馈线时序电流离散化。离散化的区间长度可根据具体时序数据的数值范围来确定。在初步计算时,可将离散化区间设置为较长时段,减少对应事务的数量,降低事务数据集维度,从而降低计算量。当确定了关联较强的事务后,再将该区间继续分割离散化进行关联分析,从而确定更小的事务数据范围,以提高精度。
(3) 时序数据特征离散化 时序数据的特征除了时序数据本身值外,主要包括时序数据的变化趋势,如增加趋势或减小趋势。除了设置时序数据本身值作为事务外,还可以将时序数据的变化趋势设置为事务。如在t2时刻,馈线电流I在2 A≤I<3 A范围内时,设置时序值事务为I2,若馈线电流相对t1时刻是上升的,可设置时序特征事务为Iup;若馈线电流相对t1时刻是下降的,可设置时序特征事务为Idown;若馈线电流相对t1时刻是不变的,可设置时序特征事务为Iflat。即在每个时刻t,馈线电流将设置两个事务,其中Ik表征时序值本身,Iup或Idown或Iflat表示时序值的变化趋势。通过上述事务设置,可在事务数据集中表征时序数据值本身和一次变化特征。若需要分析时序值的二次变化特征或其他变化特征时,也可按照上述原则进行设置。
(4) 事件事务设置 对于断电、线路故障等这些突发性非时序事件,同样需要设置事务项。如当tk时刻发生线路故障时,可设置线路故障为事务Break,并可在tk-1时刻设置事务Break(former),在tk+1时刻设置事务Break(after)。通过上述事务设置,可在事务数据集中表征线路故障等突发性非时序事件的发生趋势,通过与时序数据的变化趋势关联,可分析线路故障等突发性非时序事件发生时时序数据的变化趋势。
(5) 形成事务数据集 对于时序事件数据,将系统运行数据与系统突发性非时序事件按照上述原则,在每个时刻tk,形成一个事务数据集tk={i1,i2,i3,…,ik,…},对事务数据集集合T进行关联分析,即可得到T中各事务ik之间或事务集X与事务集Y之间的关联关系,进而得到时序运行数据与系统故障的突发性非时序事件之间的关联。
3.3 关联规则及关联分析实现
3.3.1 关联规则和频繁项集
关联规则的一般形式为:项集X和Y同时发生的概率称为关联规则的支持度,即S(X⟹Y)=P(X∪Y)。当项集X发生时,项集Y发生的概率即为关联规则的置信度,C(X⟹Y)=P(X|Y)。
最小支持度是用户或专家定义的衡量支持度的一个阈值,表示项目集在统计意义上的最低重要性;最小置信度是用户或专家定义的衡量置信度的一个阈值,表示关联规则的最低可靠性。同时满足最小支持度阈值和最小置信度阈值的规则称作强规则。
项集是项的集合,包含k个项的项集称为k项集,如集合{牛奶,麦片,糖}是一个3项集。项集的出现频率是所有包含项集的事务计数,又称绝对支持度或支持度计数。如果项集I的相对支持度满足预定义的最小支持度阈值,则I是频繁项集,记作Ik。
项集X的支持度计数是事务数据集中包含X的事务个数,简称为项集的频率或计数。已知项集的支持度计数,则关联规则X⟹Y的支持度和置信度很容易从所有事务计数、项集X和项集X∪Y的支持度计数中推出:
Confidence(X⟹Y)=P(X|Y)=
也就是说,一旦得到所有事务的个数,项集X,项集Y和项集X∪Y的支持度计数,就可以导出对应的关联规则X⟹Y和Y⟹X,并可以检查该规则是否是强规则。
3.3.2 Apriori算法实现
Apriori算法的主要思想是找出存在于事务数据集中最大的频繁项集,利用得到的最大频繁项集与预先设定的最小置信度阈值生成强关联规则。
根据频繁项集的所有非空子集也必须是频繁项集这一性质可以得出:向不是频繁项集的项集I中添加事务X,新的项集I∪X一定也不是频繁项集。
Apriori算法实现的两个步骤如下。
步骤1 找出所有的频繁项集(支持度必须大于等于给定的最小支持度阈值)。在这个过程中,连接步和剪枝步互相融合,最终得到最大的频繁项集Lk。
其中,连接步的目的是找到k项集。基于给定的最小支持度阈值,剔除1项候选集i1中小于该阈值的项集,得到1项频繁项集L1;由L1自身连接产生2项候选集i2,保留i2中满足约束条件的项集,得到2项频繁项集,记为L2;由L2与L1连接产生3项候选集i3,保留i3中满足约束条件的项集,得到3项频繁项集,记为L3……这样循环下去,得到最大频繁项集Lk。
剪枝步紧接着连接步,在产生候选项ik的过程中起到减小搜索空间的作用。由于ik是Lk-1与L1连接产生的,根据Apriori的性质,频繁项集的所有非空子集也必须是频繁项集,因此不满足该性质的项集将不会存在于ik中,该过程就是剪枝。
步骤2 由频繁项集产生强关联规则。由步骤1可知,未超过预定的最小支持度阈值的项集已被剔除,如果剩下这些规则满足了预定的最小置信度阈值,那么就挖掘出了强关联规则。根据这一强关联规则,即可分析出配电网各时间、时序数据、运行指标之间的关联关系,为优化配电网运行指标提出指导。
3.4 关联分析模型的流程
基于Apriori关联算法,对配电网运行中所产生的报表数据、时序数据、指标数据进行关联分析,实现流程如图1所示。
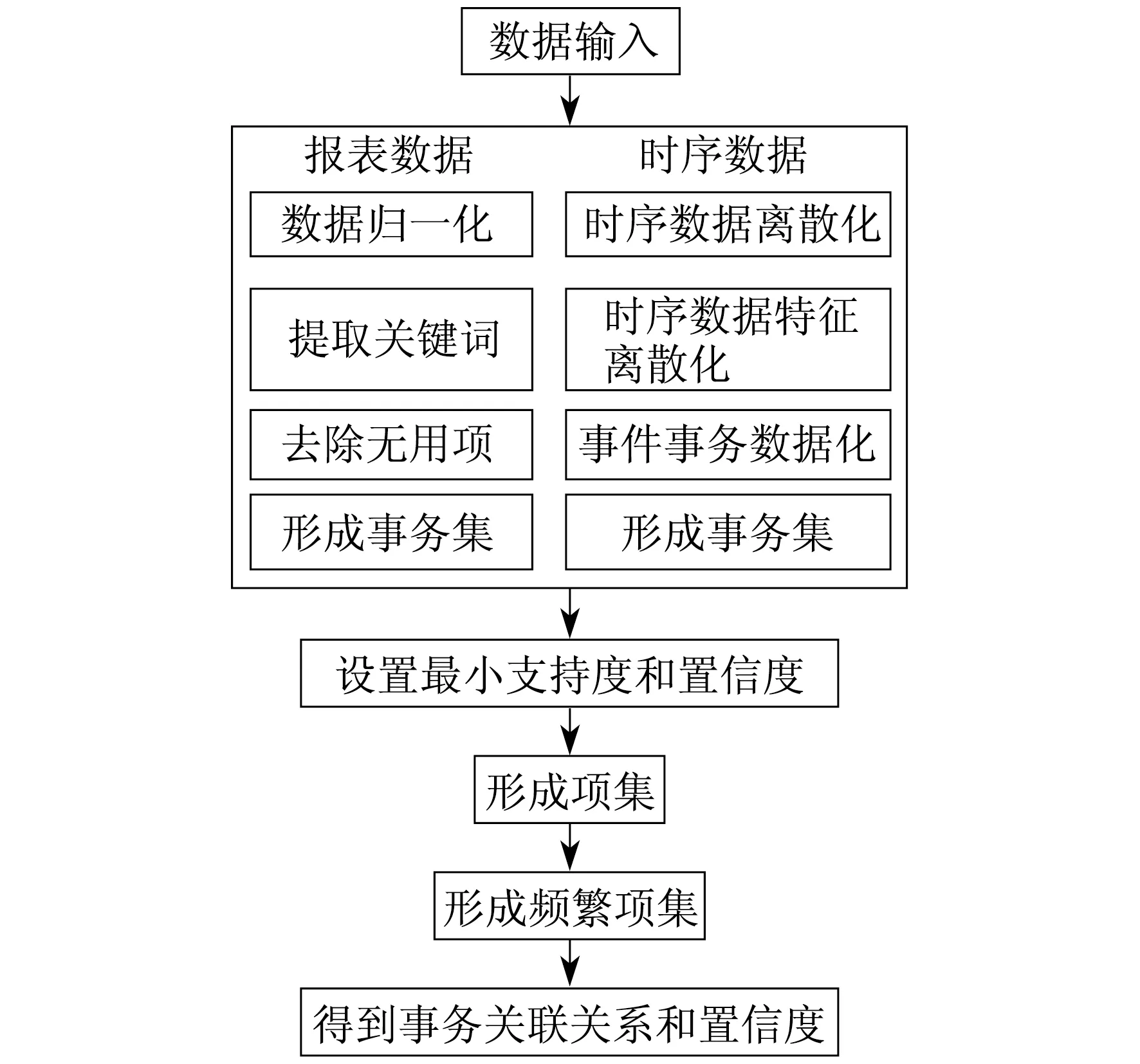
图1 基于Apriori关联算法的配电网运行大数据关联分析模型流程
通过基于Apriori关联算法的配电网运行大数据关联分析模型,可以得到配电网运行中各因素或指标之间的相互关联关系。关联关系的强弱以支持度和置信度表示,支持度和置信度越高,表示关联关系越强,即表示两个或多个配电网运行因素或指标同时发生的概率越高。对一些支持度和置信度较低的事件集,也可具体分析其关联关系,挖掘不明显的配电网运行关联关系。
4 算例分析
利用所提出的基于Apriori关联算法的配电网运行大数据关联分析模型,对上海电网故障抢修管理系统中上海某供电公司2014年故障抢修数据进行分析,并寻找其中的数据关联。
上海某供电公司2014年产生故障抢修数据共45 986条,关联分析数据项包括电压等级、故障描述、故障原因、设备分类、故障分类、抢修班组、设备名称、停电时间等。在关联分析之前,对故障抢修记录数据进行预处理:对抢修数据进行归一化处理,如“0.4 kV”“380 V”“220 V”统一成“低压电网”,“电压高”“电压低”“电压忽高忽低”等统一成“电压问题”;对故障描述语句提取关键词,将描述性语言转换成描述特征并能够分析,提取的关键词包括“重合成功”“母线接地”“缺相”“着火”“一户无电”等;将用户停电时间进行离散化处理,将停电30 min以内设置为事件t00,停电30~60 min设置为事件t01,停电60~90 min设置为事件t10,停电90~120 min设置为事件t11,停电120~180 min设置为事件t20,以此类推;将每条故障抢修记录形成一个事务数据集,共形成了包含45 986条事务数据集的事务集。
对事务集进行大数据关联分析,设置最小支持度为10%,最小置信度为50%,对关联结果进行整理,去除明显的无用项,得到关联结果如表2所示。
由表2可以看出,关联分析可以得到一些运行维护人员已知并且显而易见的结论,如“一户无电”的抢修基本都是发生在低压电网(置信度为97.80%)等。
同时,通过关联规则可以得到一些有助于进行配电网运行维护分析和提升供电质量的事件之间的关联关系。如在低压电网事件中,55.91%的停电时间在30 min之内,而低压电网发生熔断故障时,85.97%的停电时间可控制在30 min之内;客户误报中,欠费停电原因达到52.40%,而客户误报的停电恢复时间有49.81%可以控制在30 min内;抢修班组“13东捷三林”有96.32%的抢修均在低压电网,而其他抢修班组却没有这样的规律;低压配电柜故障有72.23%的事件是熔断器故障;而一户无电且熔断故障下,88.57%的可在30 min内恢复供电等。
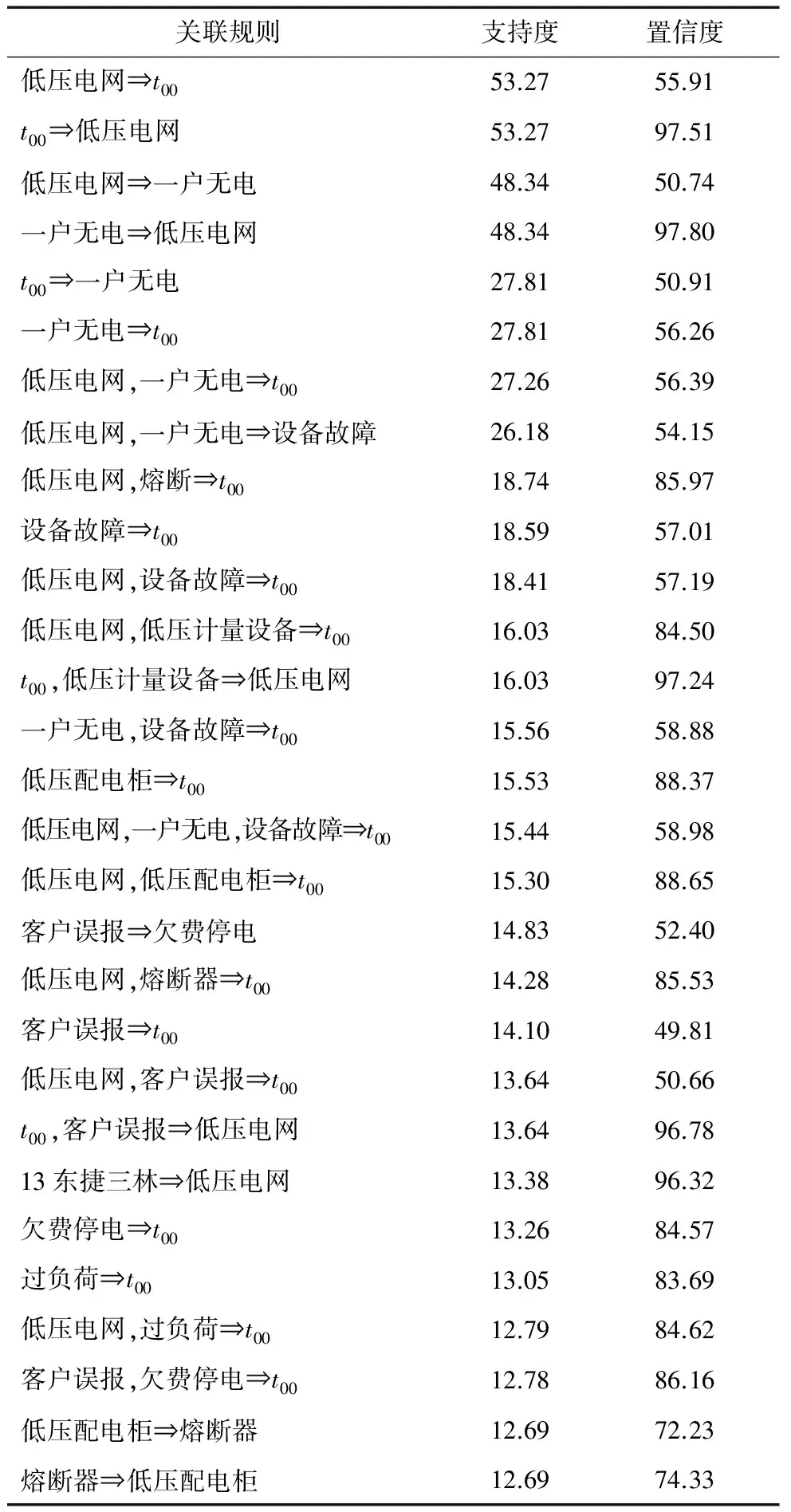
表2 上海某供电公司2014年故障抢修数据关联分析规则结果 %
5 结 语
本文建立了基于Apriori关联算法的配电网运行大数据关联分析模型,可以得到配电网运行中各因素及指标之间的相互关联关系,除了可以验证已知的配电网关联关系外,更大的意义在于可以挖掘之前未发现的配电网各运行因素与指标之间的隐性关联,使得配电网运行、管理部门能够更深刻地了解和掌握配电网的运行情况与指标情况,为提高配电网的运行维护指标提供决策建议。
参考文献:
[1] TAFT J,DE MARTINI P,PRELLWITZ L V.Utility data management & intelligence[R].San Jose:CISCO,2012.
[2] IBM Corporation.Managing big data for smart grids and smart meters[EB/OL].[2014-08-01].http://www.smartgridnews.com/artman/uploads/1/IBM_anaytics_paper.pdf.
[3] IBM Corporation.Smart grid method and model[R].Beijing:IBM Corporation,2010.
[4] U.S.Department of Energy.Smart grid system report[R].New York:U.S.Department of Energy,2009.
[5] 刁赢龙,盛万兴,刘科研,等.大规模配电网负荷数据在线清洗与修复方法研究[J].电网技术,2015(11):3134-3140.
[6] 宋亚奇,周国亮,朱永利.智能电网大数据处理技术现状与挑战[J].电网技术,2013(4):927-935.
[7] 王继业,季知祥,史梦洁,等.智能配用电大数据需求分析与应用研究[J].中国电机工程学报,2015(8):1829-1836.
[8] 刘道伟,张东霞,孙华东,等.时空大数据环境下的大电网稳定态势量化评估与自适应防控体系构建[J].中国电机工程学报,2015(2):268-276.
[9] STEPHEN B,ISLEIFSSON F R,GALLOWAY S,et al.Online AMR domestic load profile characteristic change monitor to support ancillary demand services[J].IEEE Transactions on Smart Grid,2014,5(2):888-895.
[10] 陆如,范宏,周献远.基于大数据技术的配电网抢修驻点优化方法[J].供用电,2015(8):31-36.
[11] 张铭泽,仇成,秦旷宇,等.上海超大型城市配电网安全可靠性提升策略研究[J].供用电,2016(5):16-21.
[12] RAHMAN M N,ESMAILPOUR A.An efficient electricity generation forecasting system using artificial neural network approach with big data[C]//IEEE First International Conference on Big Data Computing Service and Applications(Big Data Service).Redwood,CA:IEEE,2015:213-217.
[13] GUO K Y,JIN P,QI L,et al.A multi-fault rush repair strategy for distribution systems based on game theory of multi-agent[C]//Chinese Association of Automation.Wuhan:Chinese Automation Congress (CAC),2016:1293-1298.
猜你喜欢
作文大王·低年级(2022年12期)2022-12-23 02:16:15
中国交通信息化(2022年10期)2022-11-17 08:19:42
核科学与工程(2021年4期)2022-01-12 06:30:22
河南水利年鉴(2020年0期)2020-06-09 05:43:44
计算机应用(2018年5期)2018-07-25 07:41:26
轴承(2015年2期)2015-07-25 03:51:04
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
长春大学学报(2013年8期)2013-06-21 09:04:04
电讯技术(2011年11期)2011-04-02 14:00:37
