
基于免疫克隆算法的网店属地判定
2018-04-24 11:41:08程新党张新刚赵学武
新乡学院学报 2018年3期
程新党,张新刚,赵学武
淘宝网的交易量与日剧增,据浙江省商务厅发布的《浙江省网络零售业发展报告》统计,截至2014年底,淘宝网入住店铺数量达到147万家[1],而且店铺数量和交易量每天都在增加。各地工商管理部门有责任监管本地区的网店,而网店并不在本地工商系统内注册登记,导致属地工商局难于管理。虽然淘宝网提供了按地区搜索店铺的功能,但经工商管理部门的实际验证发现该功能不仅返回网店数量严重偏少,而且准确率较低。因此,目前部分地市工商管理部门采用人工筛选、逐个核实的方式查找属于本地区的网店。这种方式虽然准确,但人工处理所属区域标注不准、数量庞大的店铺不仅效率低下,而且很难做到全面查找。利用计算机技术实现的自动化属地判定不仅可以节省人力物力,而且在属地判定的同时也可对网店进行整理备案,有利于监管。为此,我们提出了一种使用自动化网页分析技术快速判断网店属地的方案。该方案使用免疫克隆算法和感知机模型,根据网店页面特定内容对网店进行属地判定,可以快速判断网店的属地,并且每周更新一次,对于随时都在增加和消亡的网络店铺的监控具有重要意义,能够满足工商管理部门对网店的监管需求,对消费者维权具有一定的意义。
1 相关工作
对于各地工商管理部门来说,仅需要监管所在地区内的网店经营情况,即仅需判定特定网店是否属于本地区即可。因此,属地判定技术属于二类分类的范畴。近年来,人们针对文本分类问题提出了很多模型,如朴素贝叶斯分类法[2]、决策树算法[3]、神经网络[4]和支持向量机[5]等。但纯文本分类的方法对结构化的网页分类误差较大。针对这个问题,兰均等[6]提出基于特征词的复合权重的关联网页分类技术,并取得了较好的效果。不过,对位置权重采用专家经验赋值的方法有一定的应用局限性。但他们的研究表明:对于网页这种半结构化文本的分类,不同位置的特征权重有很大的区别,在判定模型的选择时需要考虑到不同位置的特征差异性,而感知机模型、支持向量机模型、Logistic回归模型等的多项式系数都可以理解为权重信息。张长水在参考文献[7]中指出文本分类是最容易发生“维数灾难”的机器学习应用场景,虽然通过分词字典限制、部分提取等手段可有效地降低特征的维数,但实际特征总数仍达2 000多项,这使模型计算的复杂度较高,并且其中很多分词在地域的判定上毫无意义,需要通过特征选择技术选取与问题相关的特征并去除冗余。
特征选择在保留数据任务的同时,不仅能够提供与原数据近似的表现,而且对问题的本质具有更强的可解读性。特征选择也是有效的降维手段,可使计算更简单。
特征选择作为一种数据预处理手段,已经引起了国内外学者的广泛关注并被应用到多个行业,如图像分析、社会网络分析和入侵检测技术[8]等。应用较多的特征选择方法有文档频率、信息增益、互信息、开方拟和检验等。单松巍等[9]对中文网页分类中这几种特征选取方法进行了比较研究,指出这些方法的共同缺点是需要人工控制选择特征的数量,增大了算法的不可靠性和随机性。近年来,出现了一些有特色的优化问题求解方法[10-15],如模拟退火、遗传算法(GA)、免疫克隆选择(ICSA)和基于粗糙集理论(BRS)等方法。Dong等[10]与 Ghareb 等[11]的研究结果表明:遗传算法虽然具有较强的全局搜索性能,但在实际应用中容易产生早熟收敛问题,导致在进化后期特征信息对问题求解的指导作用被限制。Wang 等[13]与段洁等[14]提出了基于粗糙集依赖度量的特征子集选择方法,但该方法较为耗时。比较而言,参考文献[16-17]给出的免疫克隆算法具有收敛速度快、求解精度高和稳定性好等优点,能有效克服早熟问题。因此,我们选择免疫克隆算法进行特征选择,通过亲和度函数进行评估,得到最优的感知机模型,然后使用该模型对网店进行属地判定。
2 感知机与网店特征向量化
2.1 感知机模型
感知机是一种二类线性分类模型,通过细微调节权重值可以减少感知机的期望输出和实际输出之间的差别。感知机的训练属于有监督学习算法,简单来说,可以采用基于误分类的损失函数对分类质量进行评估,再利用随机梯度下降法或其他算法对损失函数进行极小化,从而得到模型参数。基本模型可以用

表示,其中w为感知机模型权重参数,b为偏置量。
本文算法利用感知机模型的权重来区分网页中不同位置分词特征的重要性,不仅能够满足应用需求,而且感知机模型相对于支持向量机、Logistic回归等模型而言具有模型简单、算法易于实现、占用内存少等优点。
2.2 网店特征向量化
通过对大量网店人工分析发现,网店只有在店铺标题(位置编号1)、店铺名称(位置编号2)、店铺首页Meta元素(位置编号 3)、店铺介绍(位置编号 4)、所在地信息(位置编号5)、配送信息(位置编号6)、商品描述(位置编号7)等网页位置的分词中含有较多的地域特征,而其他位置几乎不含与地域相关的分词信息,并且这些不同位置的特征分词对于网店属地的判定所起作用的重要性差别也很大。模型整体示意图如图1所示。

图1 网店特征向量示意图
为了体现位置重要性的差别,我们采取了两步措施。第一步是先按位置对网页中的分词分别进行统计,再按照顺序组合,构成表达网店的文本特征向量。向量在各维度的取值表示对应特征的权重。特征的取值方式采用传统的TF-IDF(term frequency-inverse document frequency)法,如图 1 中的[x1,x2,…,xk]向量。这种TF-IDF计算方法不能表现分词在网页中位置的不同,而在我们所研究的问题中存在如店铺标题内的地域信息等在对属地的判定中所起的作用要比商品描述内的地域信息更重要的情况,因此属地判定模型还需要能够表示网页位置特征这一重要差异。故采取的第二步措施是使用感知机模型的权重系数来表示位置差异。在网页中位置相同的各个特征项共享同一个权重系数 (如构成店铺标题的各个分词),如图1中的{w1,w2,…,wk}序列。
由于分词项按上述7个不同位置分别统计可能导致部分特征被重复统计,当7个位置的特征分词组合后,特征数量将超过2 000项,因此需要引入免疫克隆算法进行特征选择去除冗余特征,降低模型的计算复杂度。
网店的特征表示是进行属地判定的基础。在向量空间(VSM)模型中,网页空间可被看作是由一组正交词条向量组成的向量空间。将样本中每个网店按7大位置要素的顺序分别采集分词并去掉停用词,再根据7大要素分别计算各分词的TF-IDF值,然后将每个样本的各TF-IDF值按照位置编号顺序组合成单一向量,如特征总数为n,则构成n维向量,即样本可以表示为

全体样本可以表示为
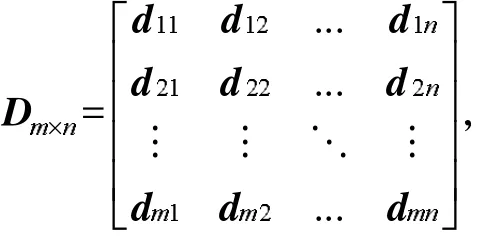
其中m为样本总数。各样本特征向量被分为7段,分段长度表示为

3 免疫克隆选择搜索算法
免疫克隆选择机制[18]最早是由Burnet等人提出的,该算法在设计上集中了全局搜索和局部搜索的优点,包含了细胞学习、记忆、克隆、变异和抗体多样性等多种生物特性。算法中B细胞和抗原对应着选择最优特征子集问题,而抗体对应着问题的可行解。克隆选择的本质是搜索出与抗原亲和度较高的抗体,然后对搜索出的抗体进行变异,这相当于在较优解的领域进行跳跃式搜索,可有效防止进化早熟,避免搜索陷入局部最优。同时,使用克隆选择也可加快收敛速度。我们使用免疫克隆选择算法将分段特征选择算法与感知机模型的训练结合起来,在获得最优特征组合的同时得到各个特征分段的位置权重信息,用于解决网店属地判定问题,这对将网页按主题分类也具有参考意义。
3.1 抗体编码
数据集 D 中含有 m 个样本 D={d1,d2,…,dm},每个样本都有特征集合X={x1,x2,…,xn},X包含n维特征。特征选择是在特征集合X中找到一个最优的特征子集S,使S含有k维特征,且有k<n。算法中每个抗体都表示一种特征组合,对应着X的一个子集。
我们所研究的案例采用二进制基因串编码方案。基因串长度是特征总个数,抗体中每个基因位对应两种模式,即某位值为1时表示相应特征被选中,为0时表示相应特征未被选中。设特征向量di长度为n,对应抗体 ai编码为(β1i,β2i,…,βji,…,βni),j=1,2,…,n,则

3.2 亲和度函数设计
我们希望在特征选择的同时搜索到相应的感知机模型,因此在亲和度函数设计时需要考虑感知机模型的参数信息。根据感知机模型[式(1)],设抗体群为P={a1,a2,…,an},其中 ai(1≤i≤n)表示 X 的一个子集 Si,定义亲和度函数为

其中, λ 是一个大于0且小于1的权值参数,r表示以Si为特征时算法在交叉验证时的分类召回率。
召回率r(recall)是衡量算法正确识别的概率,根据感知机模型,定义为
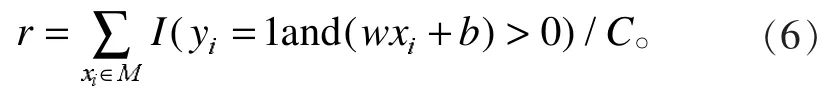
式(6)中:C为样本中正例的个数;I为指示函数,当yi=1 且(wx+b)>0 时 I为 1,否则为 0。
式(5)中的e表示与原始特征集X相比子集Si的简化率,定义为

这里的|X|、|Si|、|X|分别表示各集合中元素的数量。可以看出, λ 越大,r对亲和度的影响越大,反之e对亲和度的影响越大。
我们在亲和度函数中选择使用召回率r而不使用正确率的原因是:在属地判定应用中是以高召回率为标准来判定系统的优劣的,即要求具有较少的监管盲区。由于特征选择的原则是用尽量少的特征代替原本数量较多的特征,且使分类召回率较之前更好或者不发生较大改变,那么原问题就可以转化为式(5)所表示函数的最大化问题。
3.3 算法设计
算法总体上分为以下几个步骤:产生包含若干抗体的初始抗体群;使用随机梯度下降法结合特征分段与特征选择进行感知机模型的训练并计算对应抗体的亲和度;根据亲和度大小克隆出数量不等的抗体;按照一定的概率进行免疫操作后进行抑制操作,向抗体群补充新抗体来保证群体的多样性。
3.3.1 算法总体流程
算法流程如Algorithm1所示。
Algorithm1:免疫克隆搜索算法输入:
样本集 D={TR,TE};
转换后特征段长序列 L={l1,l2,…,l7};
输出:感知机模型与对应特征子集;
①初始种群大小p,最大进化代数TCmax,抑制操作比例Rs=0.25,克 隆 比 例 Rclone=0.25,p=50,λ =0.85,af=0.8,γ=0.9,TCmax=500;n=l7;
②P=population(random(),p,n) //初始抗体群for t to TCmax//未到最大进化代数时继续
③for each aiin P //对抗体群中的每个ai
执行Algorithm2计算模型
执行Algorithm3计算亲和度
④SortByFitness(P) //按亲和度降序排序P
⑤判断是否达到精度要求,是则退出
⑥z=p×Rclone//选择需要克隆的抗体数
for j=0 to z //计算各选中抗体克隆数量
kc=int((z×af/(i+3))×ln(z-i+1)-1)
Clone(P,i,kc)→PStemp
for each pjmin PStemp
//按概率 pmutate=1-exp[fj-fmax-0.1)/t]变异
PSmutate→P
⑦population(random(),p,n)→P //多样性
⑧af=af× γ//更新加速因子,返回③继续
⑨到最大进化代数输出结果并退出
3.3.2 设计原理
算法每个步骤设计原理和详细描述如下。
(1)产生初始抗体群。随机产生初始抗体群P,设初始抗体群规模大小为p=|P|,软件中生成方式为
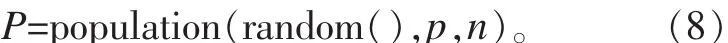
这里 n 为特征长度,random()为在(0,1)上均匀分布的随机函数。函数population()的功能是:先用random()函数值生成p×n阶矩阵,再对矩阵元素四舍五入使之转变为0或1,这样便返回p个由n位二进制位串表示的抗体,每个抗体的长度为n,与特征向量长度相同。但因特征向量由7个分段构成,而二进制位串编码方式未含各段长度信息,故需要与段长相结合。段长表示为序列L={l1,l2,…,l7},L的值在网店特征向量化之后已经确定。为了便于计算,将L的各元素做如下处理l1=l1;li=li-1+li;i=2,3,…,7。算法中使用的 L 均指转换之后的L。
(2)搜索感知机模型。对抗体群P中各个抗体a,先计算各抗体对应特征子集选择时的感知机模型参数,再使用该模型计算出对应的亲和度函数值。这部分可以分为计算模型参数和计算亲和度两个部分。
1)计算模型参数
根据图1的描述,特征向量x的总长度为n,但实质上是由7段不同性质的特征分量按照固定顺序构成,每段特征分量共享同一个权重值wj,即该模型最多有 7 个权重 w1、w2、…、w7,段长序列为 L。 因此该模型的训练与常规算法不同,采用随机梯度下降法。算法如Algorithm2所示。
Algorithm2:特征分段感知机模型训练算法输入:
训练样本集TR;
转换后特征段长 L={l1,l2,…,l7};
待评估抗体 am=[β1m,β2m,…,βjm,βnm];
最大迭代次数Tmax和学习率η;
输出:模型参数w和b;
①初始化参数:w=0,b=0,k=0,Err=0;
②for t=0 to Tmax//循环迭代Tmax次
③{TR}→di=(xi,yi)//从训练集中随机选择出 di
④k=0 //计算wx
for j=0 to n-1
if j>lkthen k←k+1
ifβim==1 then dtemp←dtemp+wk×xij
⑤if(dtemp+b)×yi<0 then
⑥Err←Err+1
⑦for j=0 to n-1 //更新w
if j>lkthen
k←k+1
wk←w+tx×yi×η
else ifβim==1 then tx←tx+xi
⑧b←b+yi×η
⑨if t>|TR|and Err==0 then
return w,b //误分类为0时退出
⑩返回②继续
11return w,b //到达最大迭代次数退出
Algorithm 2中的步骤④是根据待评估抗体am和段长序列L将选中的特征值xij与该特征对应的权重wk相乘后累加。步骤⑤用来判断:如在当前值和b值下分类错误,则由步骤⑦循环更新各个权重,由步骤⑧更新b值。算法最终返回模型参数w和b。最坏情况下的时间复杂度为 O(2n×Tmax)。
2)计算亲和度
使用测试样本集T及w和b的值,根据式(5)、(6)和(7)计算亲和度,算法如 Algorithm3所示。Algorithm 3 的时间复杂度为 O(n×|TE|),|TE|表示集合中元素的数量。
Algorithm3:亲和度计算输入:
测试样本集TE;
转换后特征段长序列 L={l1,l2,…,l7};
待评估抗体 am=[β1m,β2m,…,βjm,βnm];
感知机模型参数w和b;
输出:亲和度函数值f;
①初始化:TP=0,FN=0,TN=0,FP=0,Te=0;
②for j=0 to n-1 //计算简化率
if βim==1 then Te←Te+1
e=(n-Te)/n
③for each diin{TE}
④di(xi,yi) //从测试集中顺序取 di
⑤k=0 //计算 w·x
for j=0 to n-1
if j>lkthen k←k+1
ifβim==1 then dtemp←dtemp+wk×xij
⑥if(dtemp+b)×yi>0 then //分类正确
⑦if yi==1 then TP←TP+1 //样本为正例
else TN←TN+1 //样本为负例
⑧else //分类错误
if yi==1 then FN←FN+1 else FP←FP+1
⑨返回④取下一个样本di+1继续
⑩r=TP/(TP+FN) //计算召回率
(3)亲和度排序比较。将所有抗体按亲和度值进行降序排列,如果种群达到最大进化代数Tmax或者精度达到预定要求,则将抗体群中亲和度最高的抗体进行映射输出,即为算法所选择的特征子集。同时,输出感知机参数w和b,即搜索到了最优感知机模型。否则,转(2)。
(4)克隆选择。对按亲和度值降序排列后的抗体群,选择前z=p×Rclone个抗体进行克隆,并且要求每个抗体克隆新抗体个数与亲和度值成正向关系,同时删除其他亲和度较低的抗体。所有从选中的抗体克隆出的抗体总数由
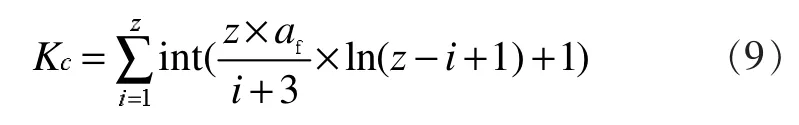
决定。其中i为z个最优抗体的排序号,int()为取整函数。通过式(9)中自然对数和乘法规则将抗体数按优劣进行了层次划分。
式(9)中的 af为加速因子[19],它随着进化代数动态更新。引入加速因子是为了加快算法收敛速度。在每一代结束时按照

进行更新。af的初始值小于1,γ 的取值范围为[0.5,1.1],根据参考文献[20],当af=0.89且γ =0.9时收敛速度与最优解达到最佳。
(5)基因免疫。所有克隆产生的抗体在进入下一代之前,都需要进行基因免疫。本算法仅利用变异操作进行免疫,即对代表抗体的基因位按照
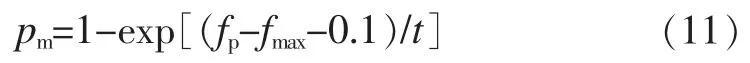
表示的概率pm进行0/1反转操作;同时删除重复抗体来保持多样性,保证新抗体尚未在候选抗体群中出现过。
式(11)中fmax表示本代抗体群中亲和度的最大值,fp表示基因免疫前该抗体的亲和度值,t为当前进化代数。在进化初期t取值较小而pm值较大时,抗体中有较多的基因位被反转,扩大了搜索范围,在一定程度上避免陷入局部最优。随着进化代数t增大,pm值减小,抗体中较少的基因位被反转,相当于执行局部精确搜索。在同一代抗体中,亲和度较小的抗体所对应的可行解距离全局最优解较远,由式(11)计算得到的pm值较大,因而抗体中被反转的基因位就较多,即免疫后的新抗体距离原抗体较远,这样的pm值设计确保了基因免疫操作的有效性。
(6)抑制操作。为了保证对抗体群的多样化的抑制操作,即随机产生一定数量的抗体加入候选抗体群中,必须保证新产生的抗体尚未在候选抗体群中。
(7)重复(2)~(6)中算法各步骤直到取得最优解。
3.4 算法分析
算法的时间复杂度主要由几部分构成:感知机模型训练 O(2n×Tmax)、亲和度计算 O(n×|TE|)、亲和度排序 O(p×p/2)、基因免疫与抑制操作 O(n×p),其中 n 为样本的特征长度。当进化代数为TCmax时,算法整体时间复杂度为 O(TCmax×2n×Tmax+TCmax×n×|TE|+TCmax×n×p+TCmax×p×p/2)≈O(TCmax×3n×Tmax),与进化代数、感知机模型训练迭代次数和特征长度相关。
本算法与其他智能算法(如进化算法、遗传算法等)相比有如下不同:仅选择优秀抗体进行克隆,配合加速因子加快了算法的收敛速度;引入变异概率pm,在进化初期执行较多全局搜索,在进化后期执行较多局部搜索,实现了全局与局部搜索较好的平衡;抑制操作体现出了免疫反应的自我调节功能;感知机模型训练算法结合了特征分段与特征选择技术;其中特征分段技术可使段内特征分量共享同一权值,较好地区分了网页中不同位置的特征分词在分类时的重要性差异。
4 实验及分析
4.1 评估标准
为了评价本算法得到的最优特征子集和相对应的感知机模型的分类质量,需要将样本数据进行二次划分:先将样本按照交叉留存验证法划分为训练集TR和测试集TE,再用留一法将训练集TR作为完整样本划分为训练集TR1和测试集TE1,并在TR1上使用本算法搜索得到的最优特征子集和相对应的感知机模型,最后使用测试集TE1进行验证评估。
为了比较算法的性能,在算法搜索阶段,我们在相同的数据集上还进行了基于粗糙集理论的特征选择和基于遗传算法的特征选择实验,并且使用准确率(precision)、召回率(recall)以及 F1 测量(F1-Measure)三个指标对分类结果进行比较。准确率是对算法决策正确性的衡量,召回率是衡量算法正确识别的概率,F1测量测试综合考量两种因素。计算方法是:precision=这里的TP为正确找到的属于某地的店铺,AC为找到的所有属于某地的店铺,CC为样本中属于某地的店铺。
4.2 数据来源
实验数据样本通过如下方法得到。
工商局工作人员通过人工查找和电话确认的方法,找到属于南阳市的网店720个,确定不属于南阳市的网店2 200个,在不属于南阳市的网店集合中随机加上800个属地未确定的网店,得到了3 000个样本数据,记为样本1。
感知机模型系数仅用来区分网页分词的位置权重,因此,在理论上使用某个地市样本获得的模型权重参数w应具有通用性,而偏置量b则不具有通用性。为了验证模型的通用性假设,选取属于郑州市的网店300个,不属于郑州市的网店1 200个,记为样本2。
在实验中,样本数据采用<URL,分类标贴>对的形式表示,即一个网店可以表示为di={URLi,Yi},如d1={https://zhat.taobao.com,1}表示该网店属于某地,d2={https://sulbin.taobao.com,-1}表示不属于某地。将所有{URL,值}存入数据表中,根据URL通过采集程序访问指定页面,取指定位置的词,分词后存入本地文件中,按照2.2中的方法将各网店样本数据向量化并形成新的样本格式。
4.3 结果分析
与其他的免疫克隆选择算法相比,我们所用算法的基本流程与卢晓勇等在参考文献[20]中所采用的流程类似,均对进化与亲和度计算的顺序有所调整。免疫克隆算法需要设置的参数较多,主要有初始化抗体群的抗体数、克隆选择抗体的比例、进行基因免疫的抗体比例、抑制操作的比例以及进化代数等[21]。我们进行了大量实验,结果表明:初始化抗体群的抗体数的选择仅仅影响算法的运行时间,对特征选择和感知机模型几乎没有影响。
为了简化算法,我们将克隆选择抗体的比例和抑制操作的比例定为25%,进行基因免疫的抗体比例定为100%。为了确定进化代数,设初始值TCmax=5 000,在实验的算法搜索阶段,记录的进化代数与误分类数关系如图2所示。
图2中共有三条曲线,分别是无特征选择下感知机模型(Only-Percep.)、使用遗传算法进行特征选择下的感知机模型(GA)和使用免疫克隆算法进行特征选择下的感知机模型(ICSA)。当进化代数在470时,ICSA的误分类数最小,故最大进化代数选择500即可。从无特征选择下感知机模型的实验结果可以看出:由于网店属地判定的特殊性,分词(原有特征)中无效项或干扰项太多,导致样本数据线性不可分;进化代数从600到900,误分类数基本不变(针对线性不可分的情况,我们将误分类数降到10个以下作为终止条件)。从图2中还可以看出ICSA的收敛速度比GA快,误分类率也低。
在GA中,根据适应度函数选出的双亲基因相似度较高,它们产生的后代与双亲的基因也会更接近,在一定程度上使基因模式单一化,这不仅会减慢进化速度,甚至会导致进化停滞不前;而ICSA结合了变异概率设计,可以在较优解附近进行跳跃式或精细化搜索,在收敛速度与最优搜索上表现得更加优秀。
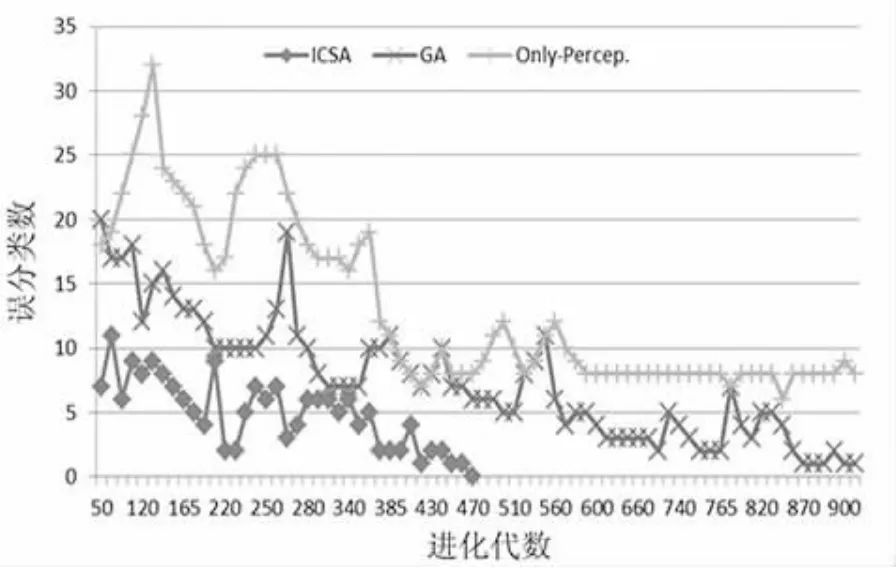
图2 三种算法进化代数与误分类数关系
从表1可以看出特征选择算法整体上较无特征选择算法表现更佳。这说明:对特征冗余度较大的数据集,特征选择不仅能降低计算的复杂度,而且可以提高判定精度。与GA相比,ICSA算法在F1-Measure和准确率上表现较好,说明ICSA算法搜索到了更优解,而GA可能陷入了局部最优,即ICSA比GA更适合本文中的应用领域。从图3中四种算法的ROC(receiver operating characteristic curve)曲线可以看出ICSA和 RSB(rough set-based)特征选择算法表现优异,但由于RSB召回率较低,不适合本文中的情况。
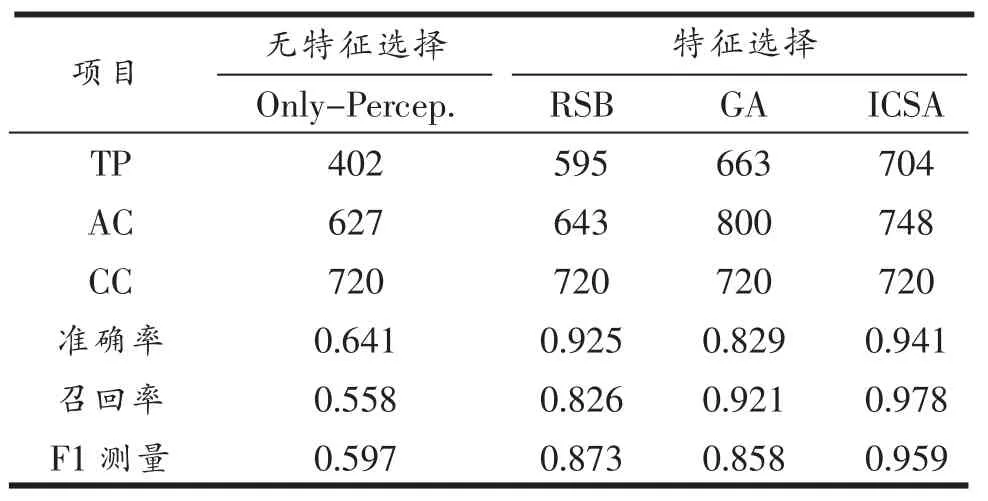
表1 四种算法分类结果比较
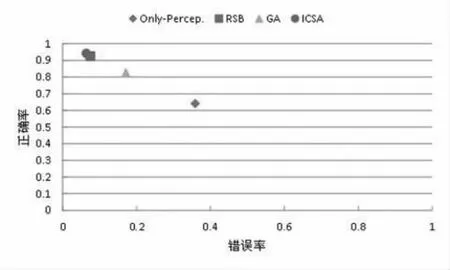
图3 四种算法的ROC曲线
式(5)中的参数 λ 直 接影响召回率和特征简化率对亲和度的贡献。λ 的大小与召回率的影响成正比关系,与特征简化率成反比关系。取 λ 初值为0.05,然后按照0.05的步长逐步增加到0.95,共进行19次试验,误分类数与 λ 的关系如图4所示。从图4可以看出:误分类数随着 λ 的增大而振荡减小,在 λ =0.85时达到最小值。这说明冗余特征对属地判定具有较大的负面影响,同时也说明了进行特征选择的必要性。

图4 ICSA算法中λ取值与误分类数关系
对于克隆选择比例设置,我们设计的实验是Rclone从0.1以步长0.05增加到0.9。实验中发现:在Rclone>0.3后,克隆出子代总数与选择克隆抗体数之和大于种群大小,即 p<z+∑int([z×af/(i+3)]×ln(z-i+1)+1),为了保证种群大小固定就必须加大抑制操作的比例,而抑制操作就需要删除一定数量的优秀抗体或其子代,这会导致部分克隆和免疫操作无效,不仅占用了CPU的运算时间,减慢了收敛速度,而且有可能错过全局最优解。加速因子af的加入在一定程度上抵消了克隆选择比例较大带来的影响,但加速因子为一变值,只会随着进化代数的增加而逐渐减小来增加影响,这样就导致了过大的抑制比例,在进化后期会带来不利影响。如果抑制比例也采用变值,则又增大了算法的复杂度,使参数确定更加困难。克隆选择比例与迭代次数的关系如图5所示。
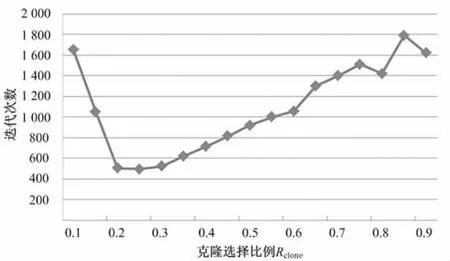
图5 克隆选择比率与迭代次数的关系
使用样本2作为本文算法的输入,其他参数不变,求得感知机模型记为M2,由样本1求得的模型记为M1,M1和M2各参数值如表2所示。由表2可知,整个感知机模型sign(wx+b)不具备通用性。对应权重参数之差绝对值之和为0.69,而对应权重参数差直接求和仅为0.01。这些均表明了运用感知机权重参数表征网页位置重要性差异是正确可行的。这种分段式特征项统计方法可为研究网页分类提供参考。需要指出的是,在使用本文算法解决网店属地判定的问题时,必须先采集本地样本进行训练,求得对应的感知机模型。

表2 M1和M2参数对照表
5 结束语
根据免疫克隆选择算法搜索到的感知机模型和选中的特征项,先应用爬虫程序自动抓取每个网店页面中的分词,分段计算被选中的特征项的TF-IDF值,并按照规定顺序组合形成网店特征向量,然后使用搜索到的感知机模型判定该网店是否属于某个特定地区,将属于该地区网店的首页URL存入监管系统数据库中。系统运行两周之后,将淘宝网网店扫描完毕,共发现属于南阳本地的店铺1 1000多个,经工商管理部门实际验证,准确率达到95%。该判定方法同样适用于其他地区,只需对该地区样本数据进行训练即可求得对应模型。
实验结果与系统的实际使用效果表明我们提出的算法在淘宝个体网店的属地判定上是可行的,而且所提出的网页分词特征位置权重的自动化训练方法、特征分段统计以及改进的免疫克隆特征选择算法在对网页这种半结构化文本的分类中也有一定的参考价值。
参考文献:
[1] 浙江省商务厅.浙江省网络零售业发展报告[R/OL].(2015-06-17)[2017-05-10].http://www.zcom.gov.cn/art/2015/6/17/art_1127_176182.html.
[2] 曹守富.社交媒体大数据的朴素贝叶斯分类方法研究[D].长沙:湖南大学,2016.
[3] 王靖,王兴伟,赵悦.基于变精度粗糙集决策树垃圾邮件过滤[J].系统仿真学报,2016,28(3):705-710.
[4] 沈夏炯,王龙,韩道军.人工蜂群优化的BP神经网络在入侵检测中的应用[J].计算机工程,2016,42(2):190-194.
[5] 杜红乐,滕少华,张燕.协同标注的直推式支持向量机算法[J].小型微型计算机系统,2016,37(11):2443-2447.
[6] 兰均,施化吉,李星毅,等.基于特征词复合权重的关联网页分类[J].计算机科学,2011,38(3):188-190.
[7] 张长水.机器学习面临的挑战[J].中国科学:信息科学,2013,43(12):1612-1623.
[8] EESA A S,ORMAN Z,BRIFCANI A M A.A novel feature-selection approach based on the cuttlefish optimization algorithm for intrusion detection systems[J].Expert systems with applications,2015,42(5):2670-2679.
[9] 单松巍,冯是聪,李晓明.几种典型特征选取方法在中文网页分类上的效果比较[J].计算机工程与应用,2003,22:145-148.
[10] DONG H,TENG X,ZHOU Y,et al.Feature subset selection using dynamic mixed strategy[C]//IEEE Congress on Evolutionary Computation,IEEE,May 25-28,2015,Sendai:IEEE,2015:672-679.
[11] GHAREB A S,BAKAR A A,HAMDAN A R.Hybrid feature selection based on enhanced genetic algorithm for text categorization[J].Expert systems with applications,2016,49:31-47.
[12] LIN SW,LEE Z J,CHEN SC,et al.Parameter determination of support vector machine and feature selection using simulated annealing approach[J].Applied soft computing,2008,8(4):1505-1512.
[13] WANG C,QI Y,SHAO M,et al.A fitting model for feature selection with fuzzy rough sets[J].IEEE transactions on fuzzy systems,2017,25(4):741-753.
[14]段洁,胡清华,张灵均,等.基于邻域粗糙集的多标记分类特征选择算法[J].计算机研究与发展,2015, 52(1):56-65.
[15] MAINAKI M,MARINAKIS Y.A hybridization of clonal selection algorithm with iterated local search and variable neighborhood search for the feature selection problem[J].Memetic computing,2015,7(3):181-201.
[16] DU H F,JIAO L C,WANG SA.Clonal operator and antibody clone algorithms[C]//International Conference on Machine Learning and Cybernetics 2002 Proceedings,November 4-5,2002,Beijing.[S.l.]:IEEE,2002:506-510.
[17] DE CASTRO L N,VON ZUBEN F J.Learning and optimization using the clonal selection principle[J].IEEE transactions on evolutionary computation,2002,6(3):231-259.
[18] BURNET F M.Clonal selection theory of immunity[J].Nature,1964,204:924-925.
[19]卢晓勇,陈木生,吴政隆,等.基于免疫克隆特征选择和欠采样集成的垃圾网页检测[J].计算机应用,2016,36(7):1899-1903.
[20] MARYAM S H,SEYED A S.Artificial immune system based on adaptive clonal selection for feature selection and parameters optimisation of support vector machines[J].Connection science,2016,28(1):47-62.
猜你喜欢
电子制作(2017年23期)2017-02-02 07:17:06
公民与法治(2016年16期)2016-05-17 04:16:30
兽医导刊(2016年12期)2016-05-17 03:51:50
海峡姐妹(2016年9期)2016-02-27 15:22:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
爆笑show(2015年4期)2015-06-24 07:39:17
肝博士(2015年2期)2015-02-27 10:49:44
发明与创新(2015年29期)2015-02-27 10:39:42
现代检验医学杂志(2015年4期)2015-02-06 02:02:06
振动工程学报(2014年4期)2014-03-01 01:15:41
