
基于k-均值聚类的小麦质量评价
2018-04-21 06:04:57舒服华
现代面粉工业 2018年2期
舒服华
武汉理工大学职业技术学院 武汉 430070
小麦是我国北方农民种植的主要粮食作物,其价格直接关系到麦农种粮的积极性,进而影响我国的粮食安全。面制食品是我国居民喜爱的传统主食,面粉是影响面制食品质量的最主要因素,小麦的质量直接影响到面粉的质量。
为了保护农民种粮的积极性和促进粮食生产的发展,国家采取了保护价敞开收购农民小麦等粮食政策,消除了种粮农民卖粮难、卖粮苦的后顾之忧。然而,随着我国市场经济体制的逐步建立和完善,粮食购销市场已全面放开,粮食不仅是一种战略物质,也是一种重要的商品,必须遵循市场规律:自由竞争,优胜劣汰。
粮食作为一种特殊商品,有其自身的特点。从大局看,国家应该稳定粮食收购价格,保护农民的利益,统筹城乡一体发展,从市场角度看,种粮农户应提高产品质量,满足市场的需求。在当前市场经济条件下,小麦生产应当遵循一定的市场规律,那就是:优质优价,按质论价;品质差、不受市场欢迎的小麦品种将逐步退出保护价收购范围。
在小麦收购问题上,国家对其质量划分了严格的等级标准,不同等级的小麦,收购价格不同,这不仅体现了公平公正的原则,又能促进麦农提高种麦技术水平,生产高质量的产品更好满足市场需求,缓解购销矛盾。
国家制定的小麦质量等级评价指标虽然有6项,但在标准等级划分中,只对容重和不完善率作出了具体的定量要求,其它4个指标只作了同一的最低控制标准,其中色泽气味仅作了定性要求。这样的标准等级划分难以细致、准确、客观地反映小麦的质量状况,也给具体的操作带来了不便。而且,即使同一等级的小麦,质量也有优劣之分。因此,只有对小麦质量进一步细化,才能更好地发挥其商品的价值,使面粉企业选择到名副其实的优良产品,同时可以防止小麦市场出现以次充好、名不副实的欺诈行为。
k-均值聚类是解决聚类问题的一种经典算法,它简单、快速,适合于处理大数据集,该算法具有较好的可伸缩性和高效性,当簇接近高斯分布时,其聚类效果更佳,运用k-均值聚类法对小麦的质量进行综合评判是一种尝试。
1 评价指标体系
按照国家相关标准,小麦质量等级评价指标共有6个:容重、不完善率、杂质含量、杂质中矿物质含量、水分、色泽气味,小麦品质共分为5个等级。文中选取容重(B1)、不完善率(B2)、杂质含量(B3)、杂质中矿物质含量(B4)、水分(B5)、色泽气味(B6)6 个指标作为小麦质量等级综合评定指标,小麦质量等级评价指标体系如图1所示。
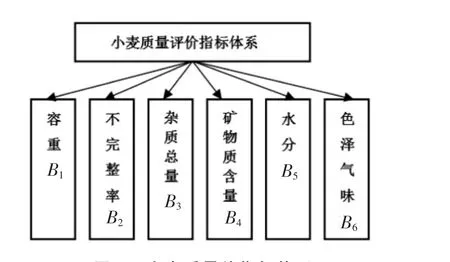
图1 小麦质量价指标体系
2 k-均值聚类方法与步骤
2.1 k-均值聚类原理
k-均值聚类算法是科学和工程领域诸多聚类算法中极其有影响和价值的一种聚类技术。它是各类聚类方法中最基本、最适应的划分方法,通常采用误差平方和准则函数作为聚类准则函数。
k-均值聚类的基本思想是:以样本空问中k个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。算法具体步骤如下:
①从n个数据对象中任意选择k个对象作为初始聚类中心;
②根据每个聚类对象的中心,计算每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行划分,将每个对象重新赋给最相近的类;
③重新计算每个聚类的中心;
④重复步骤②、③,直到每个聚类不再发生变化为止。
k-均值聚类算法尝试找出使平方误差函数值最小的k个聚类,即:

式中:E是数据库中所有对象的平方误差总和;
x表示给定的数据对象;
zi是簇si的中心。
这个准则使生成的结果簇尽可能地紧凑和独立。
2.2 数据规范化
由于每个指标的量纲和数量级不同,为了便于决策,需要对原始数据进行规范化处理。属性指标一般分为效益型(越大越好)和成本型两类(越小越好),不同类型的指标,规范化方法不同。
对于效益型指标,规范化采用如下方式:
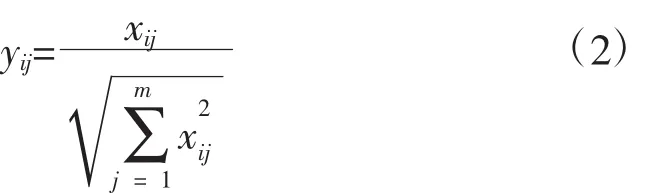
对于成本型指标,规范化采用如下方式:
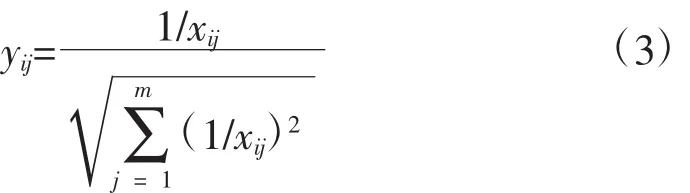
式中:xij为原始数据序列;
yij为规范化数据序列。
2.3 确定指标的权重
由于k-均值聚类法指标的权重对分类结果影响较小,故文中采用较为简单的环比评分法确定评价指标的权重。具体方法为,首先根据评价指标对评价结果的影响大小,对每个评价对象的重要性程度进行评分,评分可为百分制也可十分制,可为小数也可为分数,根据决策者的喜好自行决定。设评价指标Bi的重要性评分为Pi,则Bi的权重为:

式中:wi为指标Bi的权重。
2.3 确定加权规范化数据
加权规范化数据为评价对象各指标规范数据与其对应的权重之积,即:

式中:wi为指标Bi的权重;
yij为第j个评价对象第i个评价指标的规范化数据。
3 应用实例
以某小麦样品为例,品种为襄麦25。选取15个样本,以图1所示的容重、不完善率、杂质含量、杂质中矿物质含量、水分、色泽气味6个指标为小麦综合等级评定指标。故评价对象集为 S={s1,s2,…,s15},评价指标集为B={B1,B2,…,B6}。所有指标性能测试参照国家相关标准,经检测,这15样品的6个指标值如表1所示(其中色泽气味采用专家评分法),数据为测试3次的平均值。
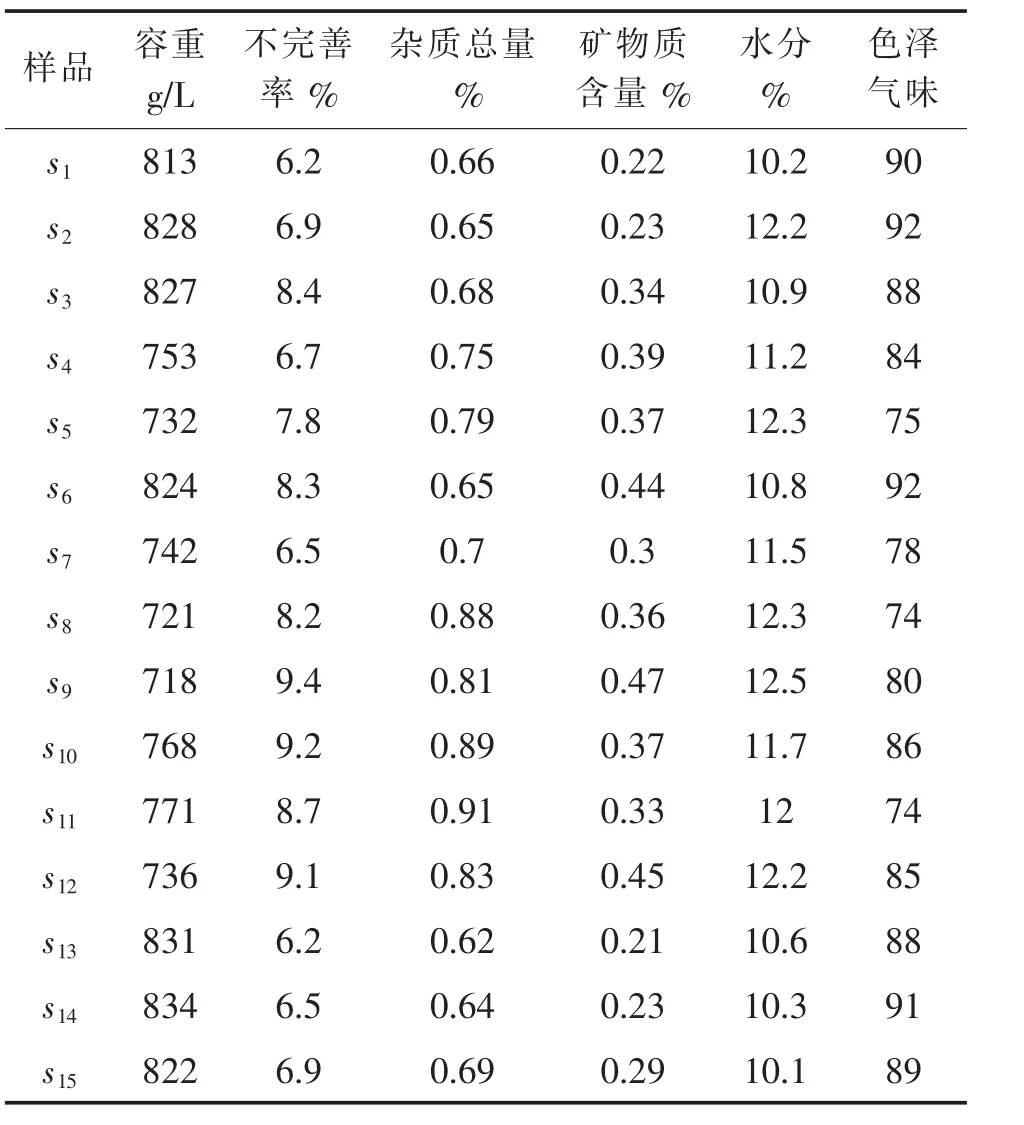
表1 小麦质量指标测试值
3.1 数据规范化
小麦质量6项性能指标中,第1项和第6项为效益型指标,其余项为成本性指标,分别按式(2)和式(3)进行规范化处理,结果如表2所示。
3.2 确定权重
根据有关标准结合生产实际经验,给出小麦质量6项性能指标的重要性评分。它们分别为:P1=10,P2=9.5,P3=9.0,P4=8.5,P5=8.0,P6=7.5,按式(4)计算出6 项性能指标的权重为:w1=0.1905,w2=0.1809,w3=0.1714,w4=0.1619,w5=0.1524,w6=0.1429。
3.3 确定加权规范化数据
按式(5)计算加权规范化数据,结果如表3所示。
3.4 聚类
按上述k-均值聚类方法进行聚类。首先确定聚类数目,聚类数目太多理不清头绪,太少无从体现差别,对于15个大小的样本,分为3类比较合适,于是取聚类数目k=3,据此得到各类别的中心,结果如表4所示。
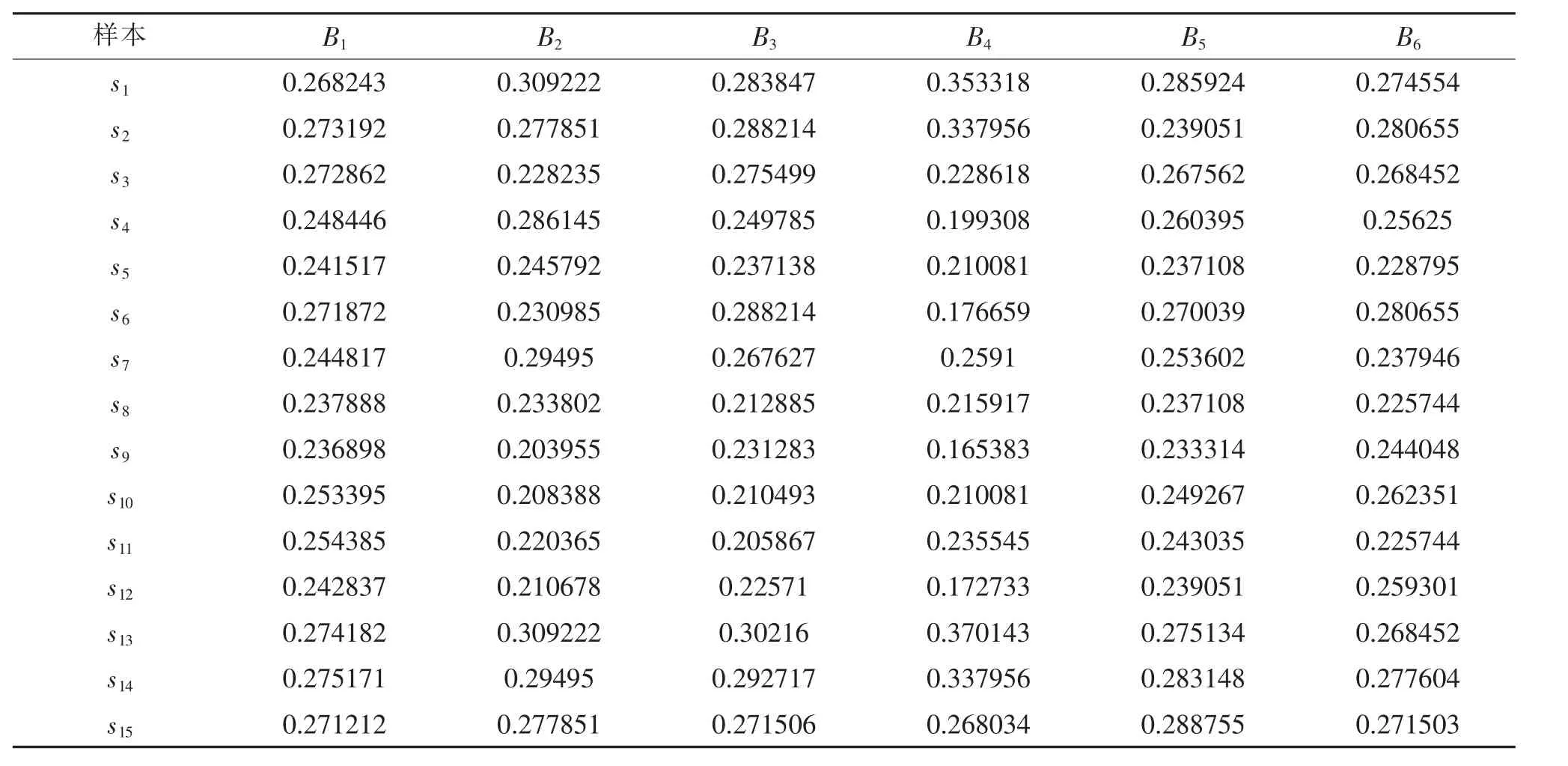
表2 原始数据规范化结果

表3 加权规范化数据
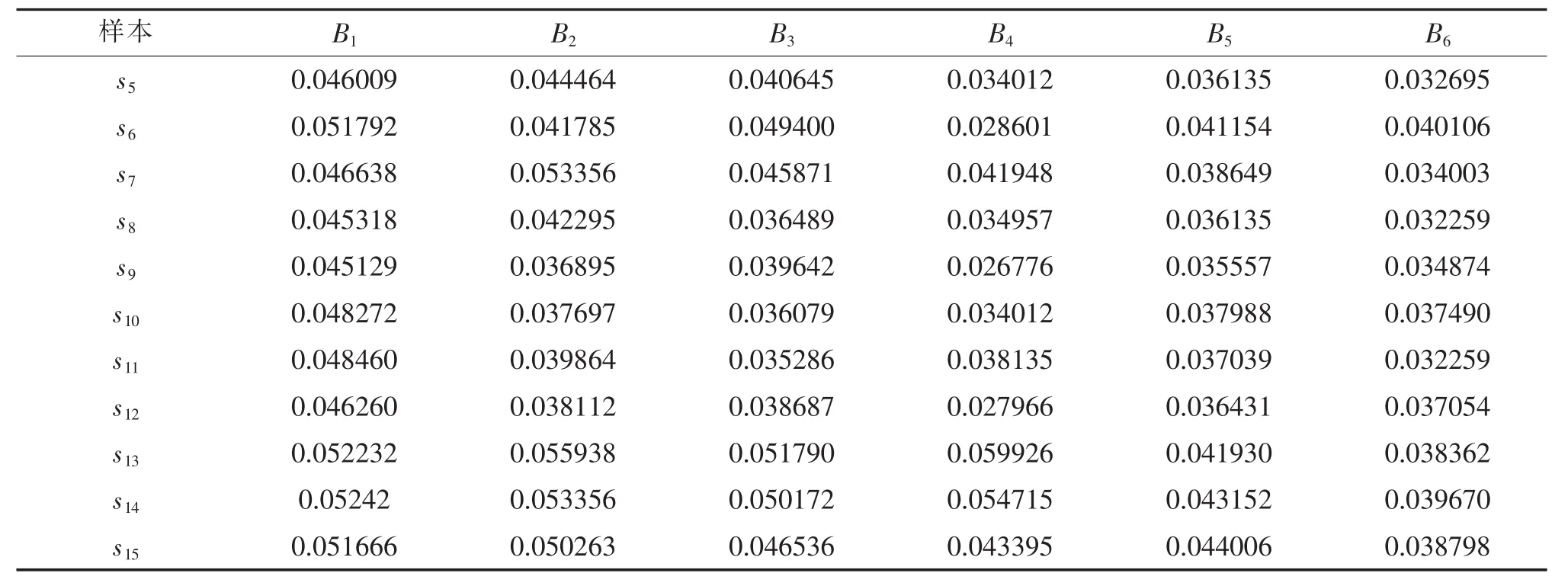
续 表

表4 各类别的中心值
以误差平方和准则函数为聚类准则函数 由此,可得到样本的分类结果及各类别样本至其中心的距离之和,结果如表5所示。

表5 分类结果及类间距离
从分类情况看,第一类的样品的质量要劣于第二类,第二类样品的质量要劣于第三类。样本的分类结果直观图见图2所示。

图2 聚类结果直观图
4 结语
客观准确评价小麦的质量,对维护小麦市场的正常秩序,保护麦农的利益,维护粮食企业的合法权利,促进我国小麦生产持续健康发展等具有重要的意义。k-均值聚类根据较少的已知聚类样本的类别,对决策对象进行优化调整确定部分样本的分类,降低总的聚类时间复杂度,此外该算法具有优化迭代功能,在已经求得的聚类基础上,再次进行迭代修正调整部分样本的聚类,优化了初始监督学习样本分类不合理的部分,提高了聚类的准确性。
本文运用k-均值聚类对小麦质量进行分析,有利于发挥小麦的商品特性,对面粉企业选择物有所值的产品,经销商诚实守信经营,提高面粉的质量,更高好满足人们生活需要等具有重要现实意义。
[1]王小平,万兰.小麦质量指标的检测与分析[J].现代面粉工业,2009(6):38-40
[2]马心宇,马琳.试论创新机制统筹发展构筑粮食安全保障新体系[J].粮食问题研究,2017(6):16-23
[3]成升魁,汪寿阳.新时期粮食安全观与粮食供给侧改革[J].中国科学院院刊,2017,32(10)
猜你喜欢
电子测试(2017年15期)2017-12-18 07:19:27
商周刊(2017年23期)2017-11-24 03:24:09
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
智能系统学报(2015年4期)2015-12-27 09:38:39
中国卫生产业(2015年10期)2015-03-11 18:58:41
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
中国当代医药(2015年9期)2015-03-01 02:02:15
电子设计工程(2015年6期)2015-02-27 12:04:53
中国卫生(2014年3期)2014-11-12 13:18:18
