
基于规则拟合的TCP数据包流量混淆系统
2018-04-18 11:07:45张琪鑫魏松杰
计算机应用与软件 2018年2期
张琪鑫 吴 超 罗 娜 魏松杰
(南京理工大学计算机科学与工程学院 江苏 南京 210094)
0 引 言
以互联网信息传播为基础的信息技术时代,网络数据交换越发频繁,应用程序的网络流量在承载并传输用户信息的同时,也成为行为模式分析、数据挖掘、用户追踪、隐私泄露的一个薄弱环节。虽然通过数据加密技术和网络安全协议,可以保证网络数据在传播过程中内容的保密性和完整性,但通过对于指定网络接入设备和应用程序的连接会话、数据流量的分布情况的分析记录,可以轻易地区分并识别不同的网络流量发送实体,进而对于特定的网络接入设备和应用程序进行特征描述和行为追踪[1]。这类方法在网络流量分析和异常检测中为研究者提供了基于流量工程的独特检测方法,但在网络攻击者和隐私窃取者手里,也成为了嗅探、识别用户网络行为隐私的双刃剑[2-3]。
流量混淆作为网络流量数据在分发共享过程中的一个隐私保护手段,可以实现在不改变流量数据包的分布特征、时序状态和数据一致性的前提下,对于指定包头信息的混杂和模糊,典型的如Anonym、Anontool等[4-5]。但这些混淆工具不适用于对于网络流量的实时在线处理,无法支持具有隐私保护的匿名通信过程。流量混淆方法可以用于在线匿名通信,例如常用的匿名通信系统Tor[6]。为了抵御流量分析和流量监管,Tor引入了多种传输插件对其流量进行混淆。Meek作为Tor的一种最常用的传输插件,它把Tor的流量伪装成访问云服务平台的流量。Meek通过第三方服务器进行流量转发,使得传输内容看起来像是在访问另一个站点[7]。但是基于Tor的匿名通信系统,也存在着以下不足[8]:
1) 依赖基于浏览器代理的加密技术,通过浏览器建立HTTPS隧道进行流量传输,从而隐藏Tor的TLS指纹特征。
2) 由于Tor匿名流量必须经过第三方服务器,所以它的连接特征、数据流统计特征和数据流动态特征趋于固定,可以被基于SVM等的机器学习算法分类建模,实现对Tor匿名流量的识别。
3) Tor系统的混淆无法根据用户需求定制方案。
本文针对以上Tor匿名通信系统的不足,面向移动智能设备平台上的应用程序流量,立足于对于网络TCP数据包流量的实时处理与在线混淆,设计并实现了一个基于规则拟合的数据包混淆系统,其主要功能与创新点如下:
1) 设计并实现了一个基于混淆规则的流量拟合系统,可以实时地在网络连接端口实现TCP数据包的嗅探、缓存、处理、转发。
2) 提出的混淆方法完全从数据流统计特征、数据流静态特征和数据流动态特征进行处理,混淆后的TCP数据包流量难以被现有的面向网络时序数据的机器学习算法分析建模或分类识别。
3) 用户可以对数据包的分布、间隔、顺序、长度等四种时序特征处理方法进行组合定制,实现自己所需的TCP流量的混淆效果。
4) 系统实现作为独立程序运行在网络层,不需要第三方软件环境,混淆窗口和细粒度可以被用户自由定制。
1 系统设计
本系统基于OSI网络层次结构模型,在网络层实现面向TCP数据包的流量混淆功能,在网络端口实现数据包的截取和缓存,在应用程序实现对于混淆规则的配置和管理,具体系统架构如图1所示。运行在设备网络连接端口上的数据包嗅探程序,将所有符合混淆规则的IP网络流量,例如指定协议和端口的数据包,进行截取并存入相应的缓存队列。混淆引擎接收应用层程序和用户对于混淆目标的设置,并将设置的规则与模板提供给网络流量混淆引擎。网络流量混淆引擎根据规则设定,调用相应的混淆功能模块,对缓存队列中的数据包进行在线处理,将处理结果即混淆后的新的数据包通过链路层注入到网络环境中。

图1 流量混淆的系统结构图
图2具体描述了运行在网络层的数据包混淆流程。本系统目前共支持四种数据包混淆操作,即针对数据包的分布拟合、时间间隔、相邻顺序和包长度的调整和混杂操作。分布拟合功能就是将截取的多组数据包分析后按照指定时序特征发送出去,是对于已知样本数据包的分布特征的模拟,这需要应用层提供作为被模拟对象的数据包流样本。时间间隔混淆就是在不改变数据包个数和相邻顺序的前提下,将数据包之间的发送时间间隔进行调整和控制,以便符合应用程序设置的间隔时间分布规律。顺序混淆是指将一段时间窗口中的相邻数据包的局部发送顺序进行调整乱序。长度混淆是指对于相邻数据包进行符合混淆规则的合并和拆分,其效果为数据包个数的改变。未来根据用户的隐私保护和流量乱序的需求,并可以开发并配置更多的混淆操作功能模块。所有混淆模块对数据包流的混淆操作后,必须保证相应的TCP连接不能中断,并且收到服务器返回的应答信息也不能出错,即不能影响应用层的正常通信功能。

图2 数据包流量混淆的流程
2 混淆方法
本节主要介绍四种流量混淆操作的基本思路。其中流量分布拟合即将A流量的分布拟合成符合另一流量B特性的新流量。其他三种混淆方式则在时间、顺序、长度上进行数据包流的混杂效果。同时这三种方式也可以互相叠加重复。例如,mixorder(order1,order2,mixinterval(normal,traffic))的方式就是先对traffic数据包的时间间隔按照正态分布混淆后,再将混淆后的数据包的order1和order2的次序对调。
2.1 流量分布拟合simulate(trafficA,trafficB)
先读取trafficA的流量信息,着重分析其包间间隔的时序特征,随后我们再读取trafficB的流量信息,着重分析其包计数。再将trafficA的时序特征拟合到trafficB上,就能实现流量分布特征的拟合目的。
2.2 时间间隔mixinterval(distribution,traffic)
通过总结Tor匿名通信系统固定数据流统计特征的不足,本系统采用随机化的办法,将数据包之间的时间间隔混淆成无法体现用户流量特性的多种随机分布再发送出去,支持正态分布mixinterval(normal,traffic)、指数分布mixinterval(exp,traffic)等。
2.3 包序混淆mixorder(order1,order2,traffic)
典型的TCP协议实现具有差错控制机制,即对于提前到达的乱序数据包暂不确认,直到前面的顺序数据包到达后再一起进行累计确认。依托于这一机制,将一个session内指定时间窗口的数据包顺序进行混淆。若超时发送方仍未收到确认,发送方将重发该数据段,造成接收方收到重复数据段,接收方只需要简单地丢弃重复段即可,不影响连接双方的正常通信。
2.4 长度混淆mixamount(seq,amount,traffic)
利用TCP连接的Seq和Ack连接机制,将一个会话内指定的数据包拆分为多个数据包,或者将多个连续数据包进行报文合并,以期改变会话过程中数据包的个数,以及单个数据包的长度[9]。图3显示了该混淆操作的一个具体的混淆示例。

图3 数据包的长度混淆示例
3 实验结果与分析
为了验证所提出的面向TCP数据包的流量混淆系统的有效性和运行效率,对主流移动应用Android平台进行了混淆的系统实现和实验验证。其中混淆模块采用Android系统中的VpnService形式进行实现。对于数据包的各种混合操作采用Python脚本程序实现。在实验过程中运行的网络连接端口的网口监控和数据包抓取采用scapy开源软件[10],它是一款功能丰富的交互式数据包处理、网络扫描和发现工具。提供多种类别的交互式数据包构造和分析方法,能方便地对数据包进行编辑、发送、嗅探、应答和反馈匹配等。
3.1 实验方法
实验设计:将不同类型的Android应用App单独运行在模拟器上,采用ADT中的Monkey工具进行人机交互并捕获产生的网络流量数据。在此基础上,进行以下两种方式的流量清洗与选择:(1) 过滤掉TCP/IP等其他协议的通信数据;(2) 过滤掉一些不完整或中断的TCP连接的数据流量。在网络流量清洗后,进行流量分布拟合与流量混淆两类实验,其中流量混淆由包间隔混淆、包顺序混淆、包长度混淆三种方式叠加而成,并采用了不同的混淆参数进行三次混淆实验。
特征提取:分析pcap流量文件,提取了总包数、总连接数、平均TCP连接时长、源地址端口信息熵、目的地址IP信息熵、目的地址端口信息熵。信息熵表示信息的分散与混乱程度,能够一定程度上量化信息的价值。信息熵的计算公式如下:
(1)
式中:pi表示每一种信源Ui出现的概率,若某一信息的取值确定且唯一,例如源地址端口的IP信息,那么该信息的信息熵为0,即该信息只存在有一种取值,没有继续探索的价值。因此,实验分析中并没有使用源端口IP信息熵。
相似度分析:实验采用欧几里德距离与余弦相似度进行流量拟合与混淆的相似度评估。欧几里德距离衡量的是空间中两点的实际距离,即与流量各个维度的特征值大小直接相关,距离越小,两点位置越近。余弦相似度则是度量空间两个向量的夹角,强调的是方向上的差异,相似度越接近1,则两向量越相似。若对于两个网络流量中的TCP数据包序列X和Y可以分别提取出一系列特征:X(x1,x2,…,xn),Y(y1,y2,…,yn),则两点之间的欧几里德距离与余弦相似度的计算公式如式(2)、式(3)所示,式(4)可进一步将欧几里德距离转换为相似度Sim1进行度量。实验采用Sim1、Sim2这两种评估方式综合度量流量拟合与混淆的效果,更具有说服力与可信度。
(2)
(3)
(4)
3.2 实验结果
针对Android应用程序的网络流量分析和行为建模方面的研究,已经发现具有相似功能的应用程序在网络流量上具有行为一致性,而不同类型应用程序的网络流量则在时序特征上差别较大[3]。以下实验将选用具有不同网络流量特征的三类应用程序进行流量混淆和比较。
3.2.1流量拟合
实验中采用Android平台上的新闻类应用“百度新闻”、社交类应用“陌陌”与视频类应用“爱奇艺视频”进行流量拟合分析。具体方法是通过分析百度新闻、陌陌与爱奇艺视频的流量,使得爱奇艺视频应用、陌陌应用的流量特征与分布与百度新闻相似,从而实现指定目标流量对象的拟合。
如图4(a)所示,展示了三种不同类型APP的典型网络行为。因为新闻类应用的特点是一次点击返回大量回复,所以图中显示的百度新闻在0~0.5秒内已经返回了80%的数据包。视频类应用的特点是连续绵长的连接,所以爱奇艺视频在图中显示为较为均匀的分布特征。社交类应用在无广告时都是发送消息时才会发送流量,所以陌陌在图中表现为时断时续的阶梯型特征。图4(b)是将视频类和社交类应用拟合成新闻类应用后的分布图,除了在拐点处有细小差别外,其余时间间隔的分布与新闻类的行为特征无异。如果不考虑数据包的内容信息,单从时序特征分析,爱奇艺这种视频类和陌陌这种社交类的流量特性已经非常类似于新闻类的流量特征。混淆后的网络流量在TCP/IP层完全可以抵御基于类别的数据流量分析和建模。

图4 网络流量的数据包分布拟合
3.2.2流量混淆
本实验中对搜狐新闻与百度新闻的流量进行包间隔混淆、包顺序混淆、包长度混淆三种方式的叠加混淆,同时还修改了源地址与目的地址的端口信息,混淆结果如表1和表2所示。
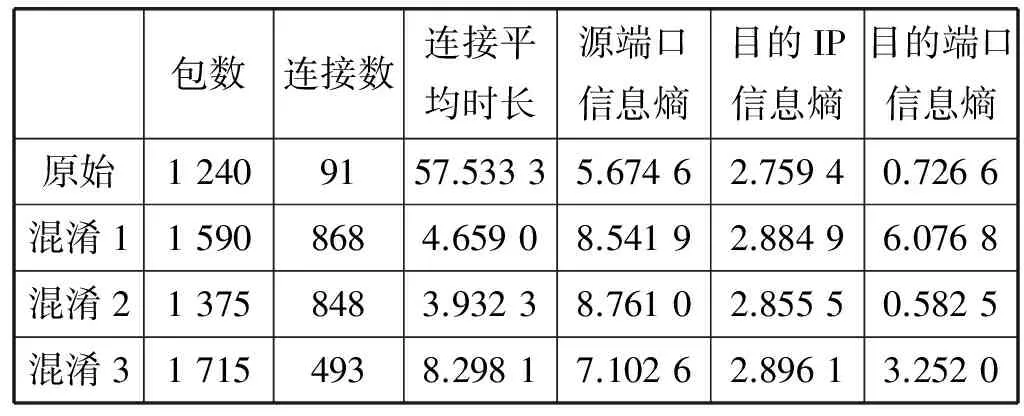
表1 搜狐新闻App的流量混淆结果

表2 百度新闻App的流量混淆结果
由数据可知,每一列的特征值并不是处于相同规模,因此采用式(5)进行归一化预处理:
(5)

归一化后,实验分别采用欧几里德相似度式(4)与余弦相似度式(3)计算原始流量与混淆后流量的相似度Sim1、Sim2。表3、表4分别为搜狐新闻特征值归一化的结果与相似度计算结果。表5、表6为百度新闻特征归一化后的结果与相似度计算结果。欧几里德相似度的取值范围为[0,1],越接近1则越相似;余弦相似度的取值范围为[-1,1],越接近1表示方向越相似,等于0表示方向不相似,越接近-1则表示方向完全相反。由表4、表6可发现,两个应用的混淆效果都较好,欧几里德相似度都低于0.3,余弦相似度都小于0,证明本文提出的混淆方法的有效性。
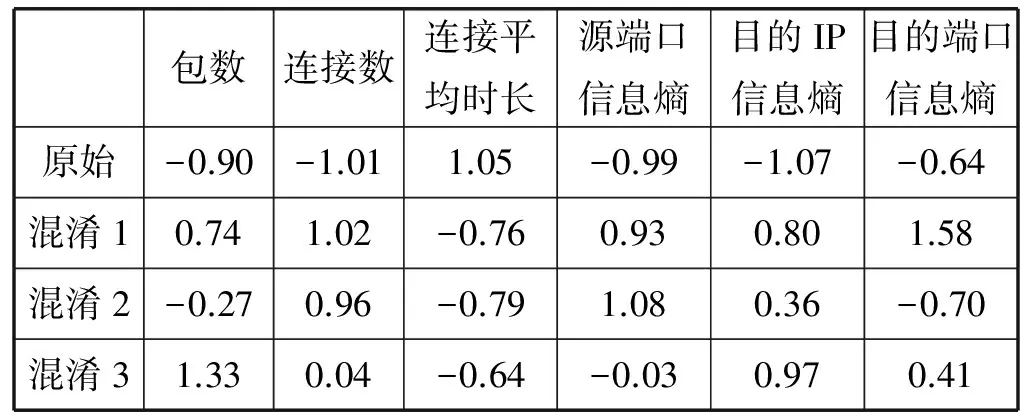
表3 搜狐新闻应用的流量归一化处理结果

表4 搜狐新闻应用的流量混淆结果
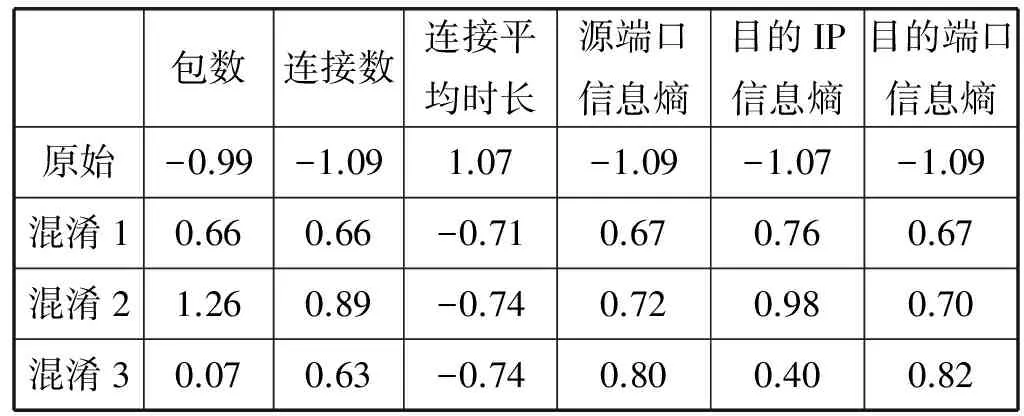
表5 百度新闻应用的流量归一化处理结果
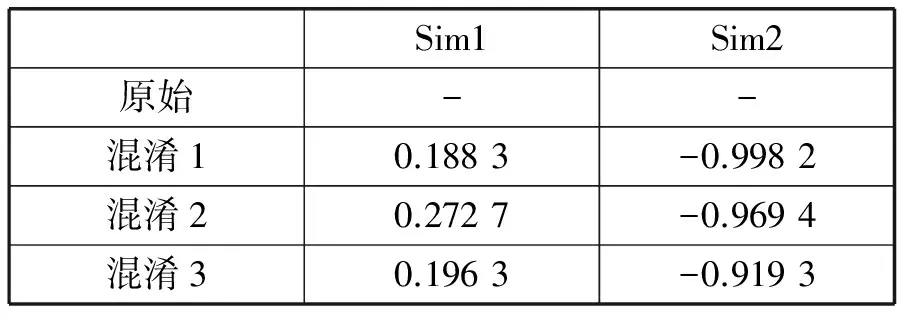
表6 百度新闻应用的流量混淆结果
4 结 语
本文针对TCP网络流量数据包,设计并实现了一个在线流量混淆系统,可以实现流量拟合和流量混杂两大功能,并支持不同混淆的规则定义与操作组合。通过实验结果分析可以看出,拟合流量的相似度很高,对流量的混淆也具有选择性与针对性。本系统目前采用VpnService方式部署在Android平台上时,每秒能同时并发处理上千个应用数据包请求,且能在1秒内完成对流量的拟合和模拟,用户端几乎没有延迟感。
本系统专注于数据流统计特征、数据流静态特征、数据流动态特征的混淆,并不依赖于第三方服务器,但是可以扩展并部署在第三方代理服务器上;也不需要指定的浏览器插件,基于最常用的TCP连接,即可实现对既有数据包的拟合和混淆,拟合和混淆均不会断开原先连接,且能收到既定的回复;用户还可以自定义自己的混淆方式,大大增强了混淆的灵活性。
[1] RezaeiTabar A H,Diyanat A,Khonsari A.On the Perfect Privacy:A Statistical Analysis of Network Traffic Approach[J].IEEE Communications Letters,2016,20(7):1357-1360.
[2] Lakhina A,Crovella M,Diot C.Mining anomalies using traffic feature distributions[C]//ACM SIGCOMM Computer Communication Review.ACM,2005,35(4):217-228.
[3] Wei S,Wu G,Zhou Z,et al.Mining network traffic for application category recognition on Android platform[C]//Progress in Informatics and Computing (PIC),2015 IEEE International Conference on.IEEE,2015:409-413.
[4] Foukarakis M,Antoniades D,Antonatos S,et al.Flexible and high-performance anonymization of NetFlow records using anontool[C]//Security and Privacy in Communications Networks and the Workshops,2007.SecureComm 2007.Third International Conference on.IEEE,2007:33-38.
[5] Farah T,Trajkovic L.Anonym:A tool for anonymization of the Internet traffic[C]//Cybernetics (CYBCONF),2013 IEEE International Conference on.IEEE,2013:261-266.
[6] Tor Anonymity Network[OL].https://www.torproject.org/.
[7] 李响.基于Meek的Tor匿名通信识别方法的研究和实现[D].北京交通大学,2016.
[8] 周勇.基于Tor的匿名通信研究[D].西安电子科技大学,2013.
[9] 杨伟伟,刘胜利,蔡瑞杰,等.一种Tor匿名通信系统的改进方案[J].信息工程大学学报,2012,13(4):503-507.
[10] 李树军.Scapy在网络协议分析实验教学中的应用[J].实验科学与技术,2014,12(6):110-113.
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22 09:52:26
微型电脑应用(2021年3期)2021-03-31 08:56:46
汽车维修与保养(2020年11期)2020-06-09 05:42:22
网络安全和信息化(2018年4期)2018-11-09 12:01:54
电脑与电信(2018年12期)2018-03-23 02:37:36
北京航空航天大学学报(2017年7期)2017-11-24 05:27:28
西北工业大学学报(2015年3期)2015-12-14 13:08:48
中国卫生(2014年7期)2014-11-10 02:32:54
中国新通信(2014年11期)2014-09-11 19:27:52
河南科技(2014年23期)2014-02-27 14:18:43
