
基于Spark的空间范围查询索引研究
2018-04-18 11:07:42陈业斌
计算机应用与软件 2018年2期
陈业斌 刘 娜 徐 宏 刘 敏
(安徽工业大学计算机科学与技术学院 安徽 马鞍山 243032)
0 引 言
近年来,随着信息技术的不断发展,空间数据增长迅速,传统的数据处理方式不能满足大量数据的分析处理需求,为了满足日益增长的信息需求,选择合适的大数据分析处理平台尤其重要。传统的数据处理系统将数据存储于外存中,再进行数据处理解决问题,当传统数据处理平台处理大数据时,其计算能力的不足会导致系统性能随着数据量的增大而急剧下降,在实际应用中并不适用。
Spark是分布式内存计算框架,具有高效性、高可靠性与高性能的特征,适用于大数据的数据分析和分布式并行处理。依靠HBase的分布式处理能力将单个任务分解为多个任务,使用集群计算的方式将被分解的任务分配给每个节点在内存中进行数据的并行处理,保证高可靠、高并发、低延迟地处理空间数据。Spark在大数据处理领域提出了弹性分布式数据集(RDD[1])的概念,将部分RDD数据集缓存于内存中,在重用计算时具备一定程度的容错纠正机制[2]。因此,基于Spark的大数据处理平台在计算处理数据时具有高可靠性与高性能。Spark中的Spark SQL组件使用SQL和DataFrame API两类接口来处理结构化数据,通过使用Spark SQL组件操作SQL语句处理数据能够更方便地梳理数据间的关系[10]。
对于空间大数据的研究不断发展,技术逐渐成熟。2004年,Google公司发表了其内部设计的大数据处理平台MapReduce[7,12]分布式计算模型、GFS[8]分布式文件系统、BigTable[9]分布式数据库的论文,奠定了大数据处理框架的核心技术基础[3,13-14]。
斯坦福大学Chu等在2006年NIPS会议发表的论文,对常用机器学习算法的形式进行分析,基于简单通用具有自动容错机制的MapReduce抽象提出了适用于海量数据的机器学习算法通用计算框架[4]。然而分布式数据处理框架可能存在着单点故障和磁盘IO效率低的情况,从而影响数据处理的效率。
2013年加州大学伯克利大学AMPLab实验室发布了新一代基于内存计算模型的Spark分布式框架。该计算框架在开源社区的共同努力下,形成了和Hadoop相互促进的Spark生态圈,该生态圈包括Hadoop的HDFS分布式文件系统、实时计算框Streaming、机器学习包MLlib、图计算GraphX、Spark SQL等,同时和Hadoop一样支持HBase分布式数据库[5]。基于Spark框架能够高效处理实时数据[11]。
为了提高数据索引的效率,本文提出了基于Spark数据处理框架结合SIMBA的思路对数据索引进行优化。基于RDD机制实现数据的自动容错机制,使用现有的分布式内存查询分析引擎Spark SQL执行查询操作,基于Spark的优化机制处理大数据下的查询操作,高效准确地完成查询操作。
1 相关工作
本文基于Spark分布式计算处理框架与分布式空间数据分析系统SIMBA[6](Spatial In-Memory Big data Analytics)的思想优化数据索引。Spark通过启用内存分布数据集,构建了提供交互式查询和优化迭代工作负载的计算框架。Spark基于RDD的实现将分析处理产生的中间结果显式地留在内存中,改变了Hadoop大数据处理框架中出现的磁盘IO效率低的情况。
使用现有的Spark SQL查询引擎中DataFrame数据组织处理结构化大数据的模块,Spark DataFrame以RDD为基础,同时具有Schema信息,处理分布式大数据时通过将数据库对象分类的方式,提高了数据批处理的效率。
对数据通过采用分区策略优化数据分布,基于DataFrame将数据库对象分类,提供完备的操作符用于处理数据集的方式,能够提高查询效率与改善查询性能。
为了优化在大数据下的数据索引,依据SIMBA的思想基础,在RDD数据集中采取了过滤优化和局部索引的策略,对Spark的内核不作任何修改,以保证系统能够无缝嵌入新版本的Spark生态系统。在基于Spark的大数据处理框架下展开索引,能够高效地确定数据集范围内的候选点。对计算机应用与研究领域的大规模数据与复杂计算有极大的研究价值。
2 解决方案
在大数据索引中,为了改善系统性能,提出来索引优化策略,采用SIMBA项目的思路在Spark中提出优化策略,基于SQL创建索引并保存到内存中,从而提高查询性能和查询吞吐量。在大数据研究领域,基于Spark系统存取数据能够有效查找数据集中的数据。在空间范围中展开索引,为了提升索引效率和查询性能,使用Spark SQL解析器执行空间查询操作,并吸纳SIMBA开源项目的思路,将空间进行分区,提出全局过滤和局部空间索引两种优化策略,基于这些优化策略提升了索引性能。
2.1 分 区
在Spark集群计算系统中,采用数据分区的方式优化数据分布并采用操作符的方式处理数据,从而提高查询效率,改善查询性能。
对于分布式计算,采用Spark中Partitioner抽象类的RangePartitioner分区策略进行分区,如图1所示,使用分区的方式处理数据需要满足分区大小、数据局部性、负载均衡三个条件[11]。首先采用RangePartitioner方式接受RDD数据集和数据集的范围边界传值。接下来,基于调用预定义采样率的采样方法大致估算出数据分布。随后将原始的RDD数据集划分为多个分区,当分区所包含的数据项超过了平均数量时,RangePartitioner将对当前分区进行重采样。基于RangePartitioner分区能够尽量保证分区中数据量分布均衡,分区之间排列有序。基于这种采样分区的方式进行数据集分区,可以满足系统分区的负载均衡,同时将空间位置相近的数据尽量相邻,满足数据分区的局部性。
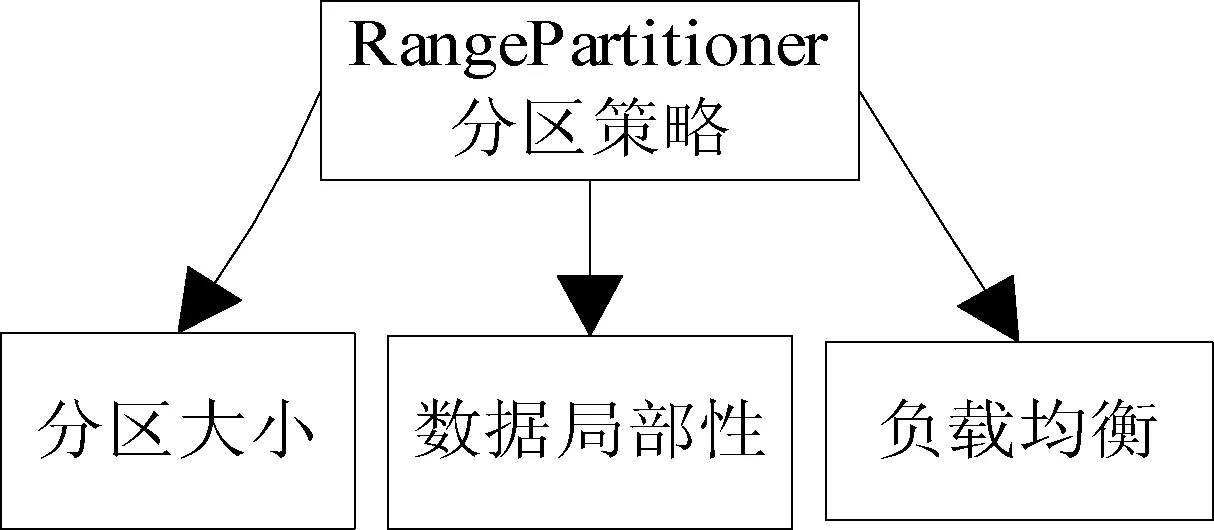
图1 数据分区策略
2.2 全局过滤
对数据集采用数据分区的方式将数据集分为多个大小相近的分区,虽然能够改善查询效率,然而在空间查询时依然需要采用全局扫描的方式对数据进行筛选。为了能够更大程度地改善查询性能,提高查询效率,使用全局过滤的方式过滤数据,减少需要扫描的分区数量。使用RangePartitioner分区函数计算每个分区的边界,并将每个分区的上界保存在一个边界数组中,在空间查询时,通过判断查询点所落在的分区边界进行分区剪枝,通过这种全局过滤的方式大幅度地降低扫描分区的数量,从而减少索引时间提升查询效率。
2.3 局部索引
在空间查询时,Spark数据处理框架通过在各分区数据集中建立线段树的方式进行空间索引,基于线段树压缩空间,快速查找到空间数据[14]。
使用线段树索引,线段树作为一种二叉搜索树,其索引方式如图2所示,首先依据分区中的边界值根据上下界端点的特征计算出中间值,将其作为根节点,再根据中间值可以将空间范围分为三部分:第一部分为左集合,包含右边界小于中间值的空间范围间隔;第二类为右集合,包含左边界大小中间值的空间范围间隔;第三类为中间集合,包含中间值落在其边界内的空间范围间隔。使用线段树进行范围查询,通过对节点值进行比较,小于节点值则进入左子树中进行查找,大于节点值则进入右子树中查找,依次迭代比较,直到匹配到对应的节点值。在定位到对应叶节点后,线性遍历叶节点中的RDD数据集,相较于全局线性遍历提高了查询效率,降低了时间复杂度。
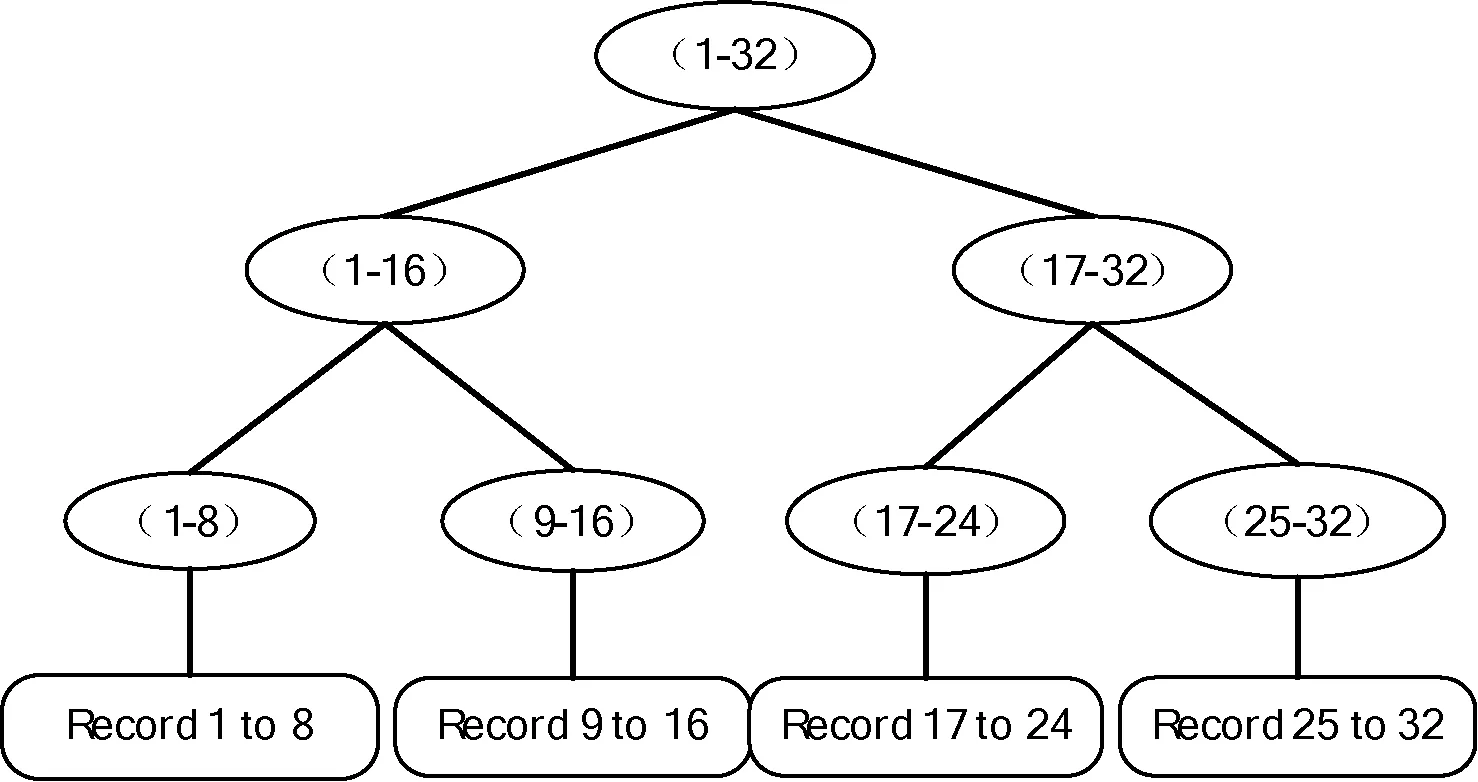
图2 线段树索引示意图
2.4 优化策略
基于Spark处理框架的空间范围查询,如图3流程所示。首先输入查询语句,使用DataFrames查询引擎将查询语句转化为抽象语法树。再使用Catalyst组件自带规则解析查询语句中对应的表属性及其查询条件,从而追踪到查询数据源,并生成分析后的逻辑计划。通过缓存管理机制Cache Manager和索引管理机制Index Manager检查内存中是否存在数据和索引,如果存在已经建立好的索引则读入,最后获得满足条件的查询结果集。
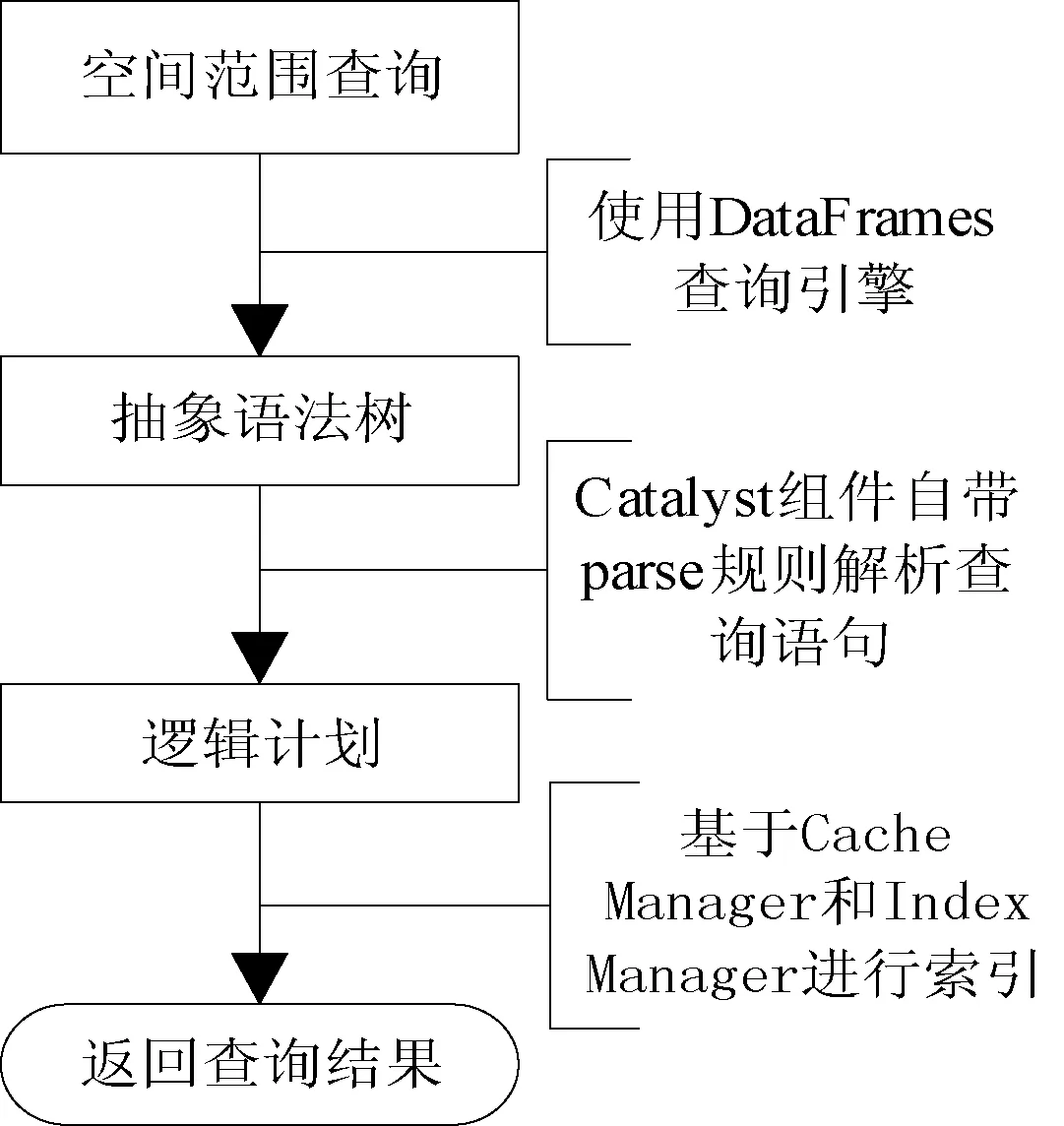
图3 查询步骤
本系统基于Spark数据处理框架,将创建的索引容器均封装为RDD抽象,所以具备RDD的容错机制,因此该系统在进行空间查询时具备一定的容错性。
3 查询方法设计
3.1 集群计算
本系统基于Spark分布式计算框架,基于时空数据库进行参数化查询,系统利用通用编程语言,通过集群内存计算实现高效的数据处理及分析应用。
本系统基于Spark的实现数据索引,能将处理分析产生的中间结果显式地驻留在内存中,通过分区策略来优化数据分布,采用全局过滤与局部索引的方式完成数据索引。在空间范围查询时,对查询进行分析,嵌入空间索引优化策略,利用系统的分布式计算方法处理时空数据库,提高查询的性能与效率。
3.2 系统架构
本系统基于Spark 系统,依据Spark SQL执行范围查询,具有高吞吐量和低延迟特性。
在本系统中通过使用Spark应用程序的方式执行空间范围查询,具体系统架构如图4所示,在Spark框架下使用Spark SQL解析器将查询语句解析为抽象语法树,使用Spark Catalyst优化器执行逻辑计划生成。
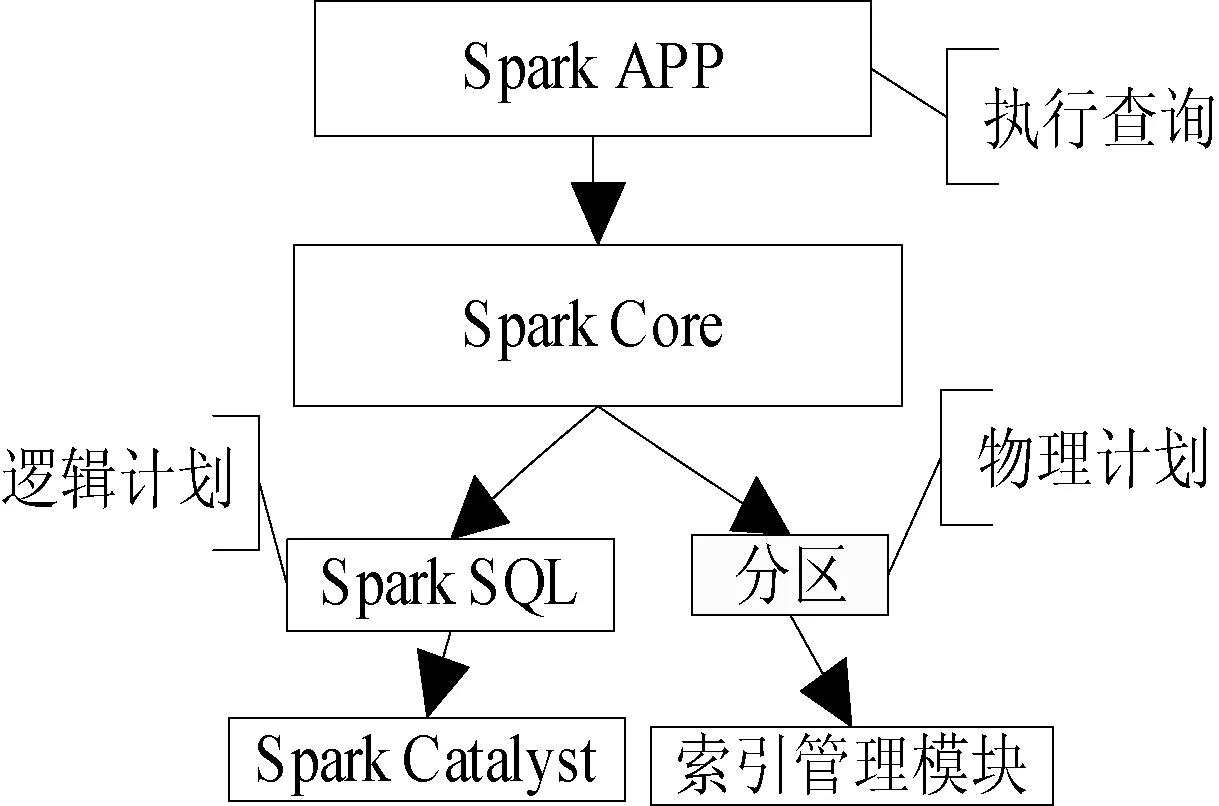
图4 Spark系统架构
在物理计划执行阶段,新建索引管理模块Cache Manager和Index Manager用于执行内存和磁盘索引,对完成分区优化的数据执行查询操作。本系统基于Spark中的Spark Catalyst和Spark SQL组件完成逻辑计划,基于数据分区与索引管理模块完成物理计划,能够更加高效、高性能地完成空间查询。
3.2.1查询方式
本系统基于Spark Catalyst展开空间查询,并通过索引管理机制对Spark SQL内核的解析器执行空间查询,使得本系统在空间索引时能够支持必要的关键字查询。
索引时通过使用关键字确定数据集中的查询对象,将查询拓展为空间点查询与空间范围查询,通过建立线段树的方式提高查询性能与查询效率。
3.2.2关键字接口
在空间范围查询时,使用空间范围关键字选择结构化表中查询语言,使用空间点关键字表达空间对象,在查询通过空间范围的表达形式,在WHERE语句中优先匹配进行查询。对于空间范围查询的表达形式如下所示:
POINT(point1,round1)
在系统中开展的空间范围查询操作,空间范围查询为查询数据集中空间属性落在指定空间范围内的所有记录,具体索引表达形式如下:
SELECT * from locations
WHERE POINT(locations.point)
IN POINT({34,23},40)
3.2.3复合索引查询
本系统空间范围查询基于Spark SQL的语法,通过索引管理机制在时空数据集上建立空间范围索引,不但能够执行空间查询还能够执行包含关键字的复合查询。在执行空间查询中为了能够提高查询性能与查询吞吐量,提出来建立线段树的方式完成索引,具体查询表达形式如下:
CREATE INDEX pointIndex ON locations(point)
USER INTERVALTREE
在复合查询时,本系统基于空间关键字进行查询,能够查询时空数据集中落在空间范围内的所有记录,并对结果集基于属性id做GROUP操作,复合查询表达形式如下:
SELECT locations.point from locations
WHERE POINT(locations.point)
IN POINT(point1,round)
GROUP BY locations.point
3.3 索引机制
本系统通过提供索引管理机制提升索引效率。基于索引管理模块在时空数据集上建立空间索引,创建索引并保存在内存中,建立包含空间查询与空间查询建立所依赖的RDD数据集。基于索引管理机制进行空间索引,能够快速定位数据集位置,从而实现较高的查询吞吐量与较低的查询延迟。
采用线段树的思想设计索引。通过二分法构造相应区间,并构造区间内的子区间,将其存储为新的节点。通过上下界的两个端点能够将每个节点区间定位到数据集中,通过SQL接口在各个分区数据集中建立对应的空间索引。基于线段树进行空间索引,能够高效查询到所有覆盖在给定空间范围的数据。
4 实验环境
本文的测试平台为十个节点构建的集群运行环境,在集群上运行对比实验,其中的8Xeon E5-2620,2.00 GHz处理器,96 GB内存。在这十个节点中均使用Ubuntu系统,在Ubuntu 14.04.2 LOS系统下搭建Apache Hadoop 2.4.1大数据处理框架,建立Apache Spark 1.5.2集群计算平台,选择具有2.00 GHz处理器和96 GB内存的2台机器中的一台作为主节点,剩余机器作为从节点。构建的Spark集群将以Standalone模式运行,并配置所有的从节点最高可以使用15 GB内存。
实验使用的真实数据集采用纽约出租车接单数据集为测试数据,包括2013年全年纽约市所有出租车的接单数据,对数据进行去重处理和数据格式检测,获得包含1.7亿条出租车接单记录元组的有效实验数据集,每一条元组包含,出租车接单ID、接单开始时间和接单结束时间。在实验中测试系统的空间点查询和空间范围查询两种查询操作的效率,在本文中使用OS(Optimized Spark)表示优化之后的Spark,将OS与对应原生Spark(未被优化的Spark)的基准查询效率进行比较,通过比较查询时的吞吐量和查询延迟来评价优化后的系统对数据索引性能的改善。每个测试基于500次实验进行查询,查询效率按照吞吐量和查询延迟进行衡量:吞吐量=查询数量/总执行时间(min);查询延迟=总执行时间(s)/查询数量。
通过比较在数据集大小不同的情况下,原生Spark系统与OS系统进行空间查询时的查询延迟与吞吐量的变化,对两个系统进行性能与效率的评价。如图5所示,原生Spark系统与OS系统在数据集大小不断增加的时候,查询延迟的时间也不断增加,相比于OS系统,原生Spark系统的延迟时间增长率要远远高于OS系统。如图6所示,是在不同数据集大小的情况下吞吐量的变化,随着数据量的增长,两个系统的吞吐量都发生了一定程度的下降,然而OS系统依旧优异于原生Spark系统。在空间点查询时,OS系统的查询操作包含全局过滤和分区查询两部分优化,因此OS系统在查询性能与效率上优于原生Spark系统。
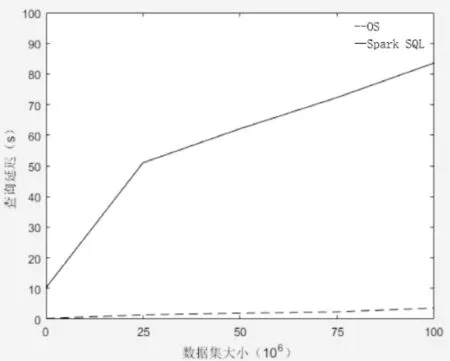
图5 数据集大小对于查询延迟的影响
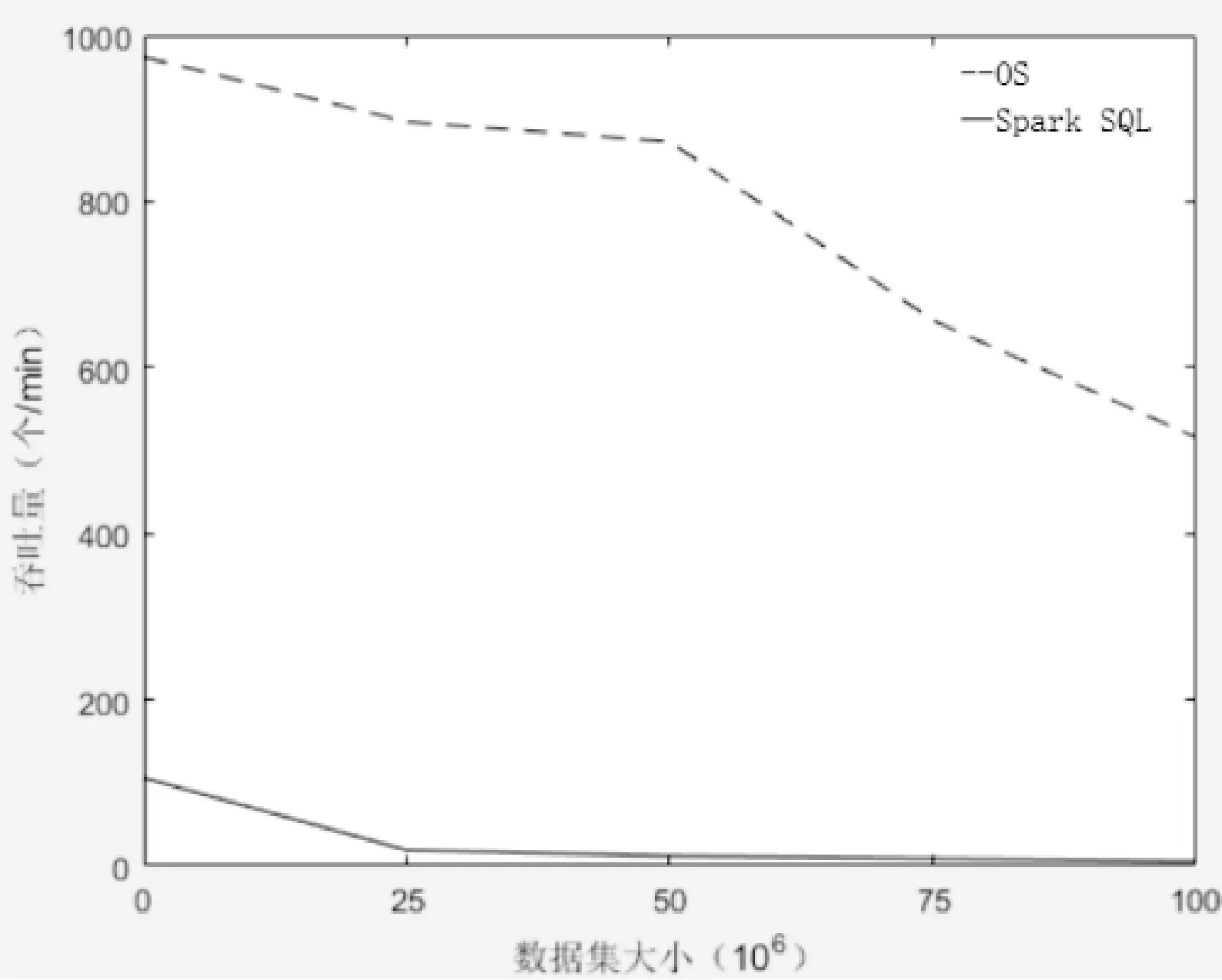
图6 数据集大小对于吞吐量的影响
对空间范围查询中,通过比较在不同数据量大小的情况下原生Spark系统与OS系统的查询延迟时间与吞吐量判断系统的性能差异。首先需要生成一个落在全局空间范围的空间标识,基于泰森多边形将整个查询空间划分为多个多边形区域。空间范围查询类似于空间点查询,OS系统的查询操作时依旧保证全局过滤和分区查询两部分优化,如图7、图8所示,在执行空间范围查询时,本系统的查询效率依旧同样优于原生Spark SQL查询策略。
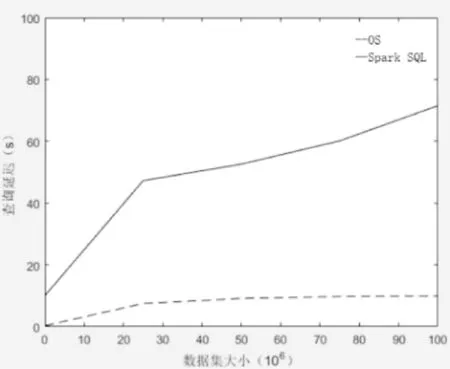
图7 数据集大小对于查询延迟的影响
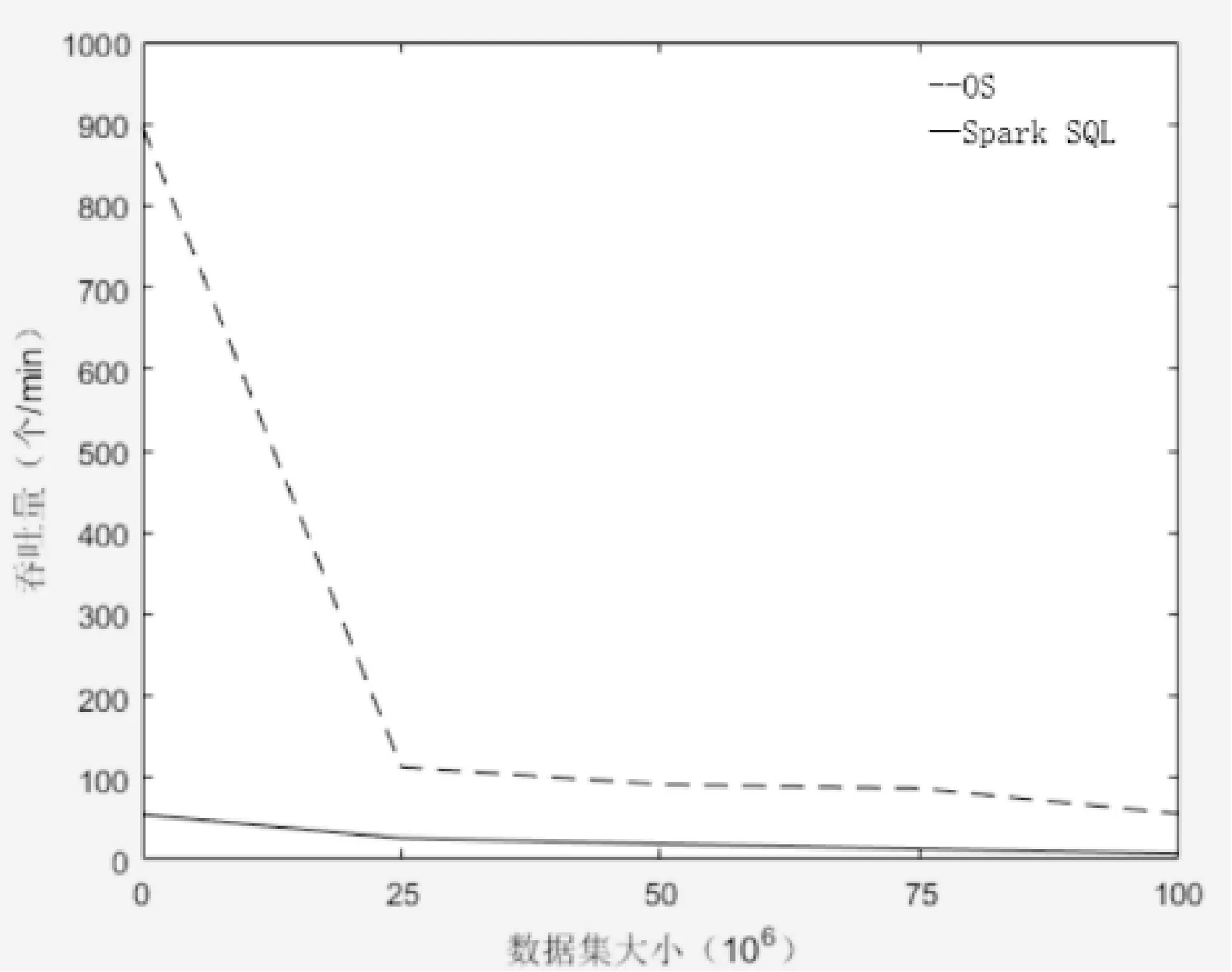
图8 数据集大小对于吞吐量的影响
当分区较大时,空间查询的结果集可能覆盖多个分区,可以通过固定数据集大小测试不同分区数量的情况下两个系统的效率。如图9、图10所示,为不同分区下两个系统的查询延迟和吞吐量变化。由图9、图10可以观察得出,OS系统在一定分区大小范围内,随着分区数量的增大,查询延迟呈现降低趋势,吞吐量大小增长。当分区数量增大,分区大小过小时,空间范围查询覆盖大量的分区,那么需要遍历的数据量将会增多,因为导致了查询延迟的增长,吞吐量下降,查询性能的降低。原生Spark系统的查询延迟和吞吐量的变化与分区数量无明显关系,因为使用原生Spark系统进行查询需要对整个数据集进行遍历,因此分区大小的改变不会对查询性能产生影响。
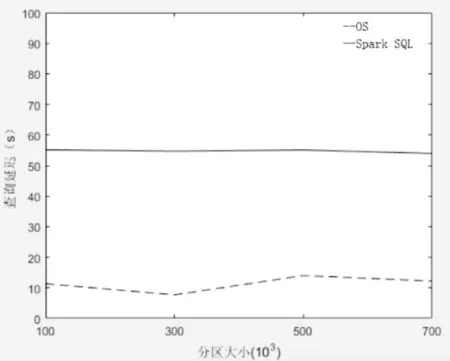
图9 分区大小对于查询延迟的影响
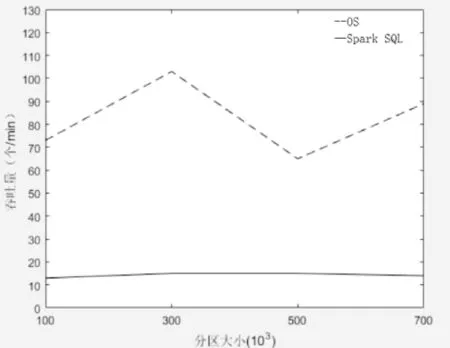
图10 分区大小对于吞吐量的影响
实验主要分为三组对比实验,第一组图5、图6,针对不同大小的数据集,在执行空间查询时OS系统与Spark SQL的执行效率对比;第二组图7、图8,针对不同大小的数据集,在执行空间范围查询时OS系统与原生Spark SQL程序的执行效率对比;第三组图9、图10,针对不同大小的分区数量,在执行空间查询时本系统与原生Spark SQL程序的执行效率对比。
5 结 语
本文提出了基于Spark的空间查询扩展系统OS,基于OS完成空间范围查询。使用Spark系统中的Spark Catalyst组件的SQL解析器的操作方式进行查询。在Spark 中嵌入索引管理机制,将其封装在RDD内,用于提高查询效率。通过建立线段树存储数据的方式提高数据检索的效率。对于数据预处理时采用RangePartitioner分区策略的方式对数据进行分区,基于全局过滤和局部索引进行查询。保证该系统在进行查询操作时能够保持高吞吐量和低延迟特性,提高查询效率。
将在OS与Spark下进行查询实验的性能进行比较,由实验结果分析,随数据集大小的增加,基于该拓展系统(OS)完成的查询操作在查询延迟与吞吐量检测上均优于原生Spark系统,当分区数量发生变化时,该拓展系统(OS)在性能上依旧优于原生Spark系统。
虽然该拓展系统取得了初步的研究成果,但是在未来的工作当中,本系统仍有较多需要拓展改进的部分,在系统中可以增加时态查询,时态查询也是时空数据库中的研究重点。与此同时,系统优化也是未来的研究中不可或缺的部分,通过嵌入更多的优化策略提高索引的效率与性能。
[1] Zaharia M,Chowdhury M,Das T,et al.Resilient distributed datasets:a fault-tolerant abstraction for in-memory cluster computing[C]//Usenix Conference on Networked Systems Design and Implementation.USENIX Association,2012:2-2.
[2] 高官涛,郑小盈,宋应文,等.基于Spark MapReduce框架的分布式渲染系统研究[J].软件导刊,2013,12(12):26-29.
[3] Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[C]//Conference on Symposium on Opearting Systems Design & Implementation.USENIX Association,2008:10-10.
[4] Chu C T,Kim S K,Lin Y A,et al.MapReduce for machine learning on multicore[C]//Conference and Workshop on Neural Information Processing Systems,NIPS,2006,6:281-288.
[5] Zaharia M,Das T,Li H,et al.Discretized streams:fault-tolerant streaming computation at scale[C]//Twenty-Fourth ACM Symposium on Operating Systems Principles.ACM,2013:423-438.
[6] Xie D,Li F,Yao B,et al.Simba:Efficient In-Memory Spatial Analytics[C]//International Conference on Management of Data.ACM,2016:1071-1085.
[7] 张宇,程久军.基于MapReduce的矩阵分解推荐算法研究[J].计算机科学,2013,40(1):19-21.
[8] Scott M L,Peterson L L.Proceedings of the 19th ACM Symposium on Operating Systems Principles 2003,SOSP 2003,Bolton Landing,NY,USA,October 19-22,2003[C]//Acm Symposium on Operating Systems Principles,2003(53):113-126.
[9] 赵宇兰,柳欣.基于连接依赖信息的分布式连接查询优化算法[J].现代电子技术,2016,39(460):28-32.
[10] 金澈清,钱卫宁,周敏奇.数据管理系统评测基准:从传统数据库到新兴大数据[J].计算机学报,2015,38(1):18-34.
[11] Xin R S,Gonzalez J E,Franklin M J,et al.GraphX:a resilient distributed graph system on Spark[C]//International Workshop on Graph Data Management Experiences and Systems.ACM,2013:1-6.
[12] Armbrust M,Xin R S,Lian C,et al.Spark SQL:Relational Data Processing in Spark[C]//ACM SIGMOD International Conference on Management of Data.ACM,2015:1383-1394.
[13] Zhong Y,Zhu X,Fang J.Elastic and effective spatio-temporal query processing scheme on Hadoop[C]//ACM Sigspatial International Workshop on Analytics for Big Geospatial Data.ACM,2012:33-42.
[14] Tan H,Luo W,Ni L M.CloST:a hadoop-based storage system for big spatio-temporal data analytics[C]//ACM International Conference on Information and Knowledge Management.ACM,2012:2139-2143.
猜你喜欢
环球时报(2022-03-29)2022-03-29 17:14:11
当代陕西(2019年13期)2019-08-20 03:54:22
知识经济·中国直销(2018年7期)2018-07-27 02:49:52
集装箱化(2016年11期)2017-03-29 16:15:48
集装箱化(2016年12期)2017-03-20 08:32:27
电测与仪表(2015年8期)2015-04-09 11:50:16
电测与仪表(2015年7期)2015-04-09 11:40:16
集装箱化(2014年2期)2014-03-15 19:00:33
测绘科学与工程(2014年5期)2014-02-27 07:06:14
广东造船(2013年6期)2013-04-29 16:34:55
