
基于改进的Ap riori算法和遗传算法的股市挖掘模型
2018-04-16 08:08何云峰
计算机与数字工程 2018年3期
何云峰
(泉州医学高等专科学校 泉州 362100)
1 引言
关联规则挖掘是数据挖掘中的一个重要分支,在数据挖掘中占有重要的地位。它对数据库中数据进行分析处理,从而发现数据之间的各种关系。而关联规则挖掘中最为经典、基本的算法则是Apriori算法[1],众多学者对Apriori算法本身进行了各种改进,更有学者把该算法与其他算法混和使用来改进该算法的效率[2~4]。大家公认的,首先,Apriori算法的最大弊端是其需要多次扫描数据库和过多的IO接口操作,使其需要耗费过多大量的时间和空间。本文的工作之一就是先对Apriori算法进行改进。其次,Apriori算法挖掘出的关联规则存在如下一些显著问题:规则的数量太多,其中也含有一些误导规则和弱关联规则。如何从中提取出强关联规则是需要解决的问题。这个过程是一个全局搜索的过程,而遗传算法是一种偏向全局解优化算法,虽然有时容易发生“早熟”以及在进化后期搜索效率低等缺点,但总体上还是有效地避免了搜索过程的局部最优解问题。因此,将遗传算法用于关联规则的进一步提取上在理论上是可行的。该点则是本文的第二个工作。
2 Apriori算法中的几个定义和改进的Apriori算法
2.1 Apriori算法中的几个定义
Apriori算法中有几个与本文相关而且在后续的遗传算法中要用到的定义。
支持度:是指在事物数据库中,包含 X∪Y事物的条数占整个事务条数的比例,记为

式中,σ(N)表示事务的总条数,σ(X∪Y)表示同时包含X和Y的事务条数。
置信度:是指在事物数据库中,包含X∪Y事物的条数占含有项集X的事务条数的比例,记为

式中,σ(X)表示包含项目X事务的总条数,置信度越高表示X与Y关联程度越大。
2.2 改进的Apriori算法
Apriori算法每次都要扫描数据库,很是费时费力。本文以空间换时间的角度来对算法进行改进,即空间上生成大量的项目,而在时间上的节约则体现在仅扫描若干次数据库。由于要产生巨量的项目组合,所以不可能把这些组合一次放入机器内存中处理。于是产生了这样一种想法,即:在Apriori算法每次扫描数据库时,检测在每次遍历的末尾处集合Ck的大小是否能装入内存,且本次遍历产生的大型候选比前次要少,那么就停止使用Apriori算法,转而使用把集合Ck放入内存的改进型Apriori算法。曾经的实验表明传统的Apriori算法在生成频繁k(通常小于4)项集时占用时间最多,几乎占到该算法的3/5时间,而这种转入内存的Apriorii算法所耗时间远比Apriori多,于是本文主要对生成频繁k(通常小于4)项集部分进行相关改进。对于一些不是很复杂,且数据库不是巨型的来说,通常生成频繁3项集后就因为项集里的项目数剧减,而可以转入内存。所以本文在使用改进型的Apriori算法形成频繁3项集后无需要再设置判断条件即转入内存,再次使用传统的Apriori算法思路,而因为使用了空间工具,使得后期所用的Apriori算法在查找数据时不必再扫描原始数据库,从而节约了数据库扫描次数。
改进思路:做一个行名、列名相同的2维数组用来存储候选频繁2项集C2的所有元素。例如第一条事务为(A,B,C),3个项目,则用图1表示C2。这个数组称为:2项集支持度矩阵。分别把顺序号1,2,3赋予A,B,C,这样就可以使用下标(i,j)访问到候选频繁2项集中的任何一项,比如使用(2,3)就可以访问到AB的坐标。先对矩阵清零,第一边扫描数据库时就能确定C2中各项的支持度。把每一条交易按交易项目排序,生成所有可能的顺序2项组合。比如第二条交易事务为(A,B,C,E,F),则所有的顺序2项组合为{A,B}、{A,C}、{A,E}、{A,F}、{B,C}、{B,E}、{B,F}、{C,E}、{C,F}、{E,F},那么它们相应的矩阵元素的计数加1,就完成了对第二条交易事务的处理。处理完2条事务的矩阵如图2。接着再扫描完数据库的所有交易,并作相应处理。再设置一个数组M[i]用以记录事务中项目个数的,以备计算置信度和消减数据库使用。
在获得候选频繁2项集的支持度后,接着查找矩阵的第二行,找出所有支持度大于等于min_sup,比如为2的项,再用第一项与第二项组合生成3项集,并且记下第一项与第二项分别所在的列号,于是查找由这两个列号组成的矩阵元素的值,若大于等于min_sup,则用第一项与第二项组合生成的3项集就是频繁3项集,其支持度即为第一项和第二项这两项的2个列号组成的矩阵元素的支持度和第一项及第二项的支持度,三者的最小值。比如组合AB和AC两项,形成ABC项,而项的支持度则是AB的支持度2,AC的支持度2,BC的支持度2中最小值2。依次组合矩阵第二行的其他项,再接着处理矩阵的其他行。该方法可直接产生频繁3项集以及其支持度,无需生成候选频繁3项集。
另外,本文在数据库条目数的消减上也采取了一些方法。若一条事务包含k频繁项集,那么在产生这个k(>3)候选频繁项集时,就只需查看数组M[i]的值大于k的事务。
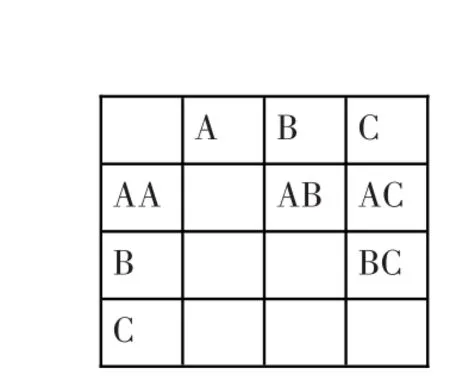
图1 候选频繁2项集

图2 2项集支持度矩阵
3 遗传算法
遗传算法是一种模拟生物界自然选择、遗传机制,基于群体的进化算法,具有很强的随机性、鲁棒性和隐含并行性。它处理的是参数集合的编码,即给定的字符串,所以较为方便,省时;能够搜索空间的多个点,因而有效地进行全局优化搜索从而找到全局解,对大规模数据集的处理是种有效的方法。遗传算法的主要步骤有三:第一,编码,形成初始种群。第二,定义一个适应度函数用以评价、引导、检验种群进化程度,适应度越高说明种群里的个体越好,而不满足适应度的种群逐渐将被淘汰。第三,遗传操作,结束时用适应度函数或设置的终止条件检验,若不满足,继续遗传操作[5~10]。
3.1 编码
前述改进的Apriori算法中已经产生了大量的关联规则。所以此时的编码方式宜选Michigan编码,即对每一条规则编码成一条染色体。例如数据集中有n个属性,则前i个属性称为规则的前因,后n-i个属性称为规则的后果。例如,股票部分属性的数据集,如表1。一条规则:单日K线形态=跳空大阳线,单日成交量=放量,MACD=白线上穿0轴®趋势=上涨,这条规则的编码即为“12#11”,编码“#”表示不需要该属性。
对已经形成的关联规则进行编码后,则形成了一个遗传算法所需的初始种群。

表1 股票属性数据集
3.2 适应度函数
为了检测群种的每个个体是否满意,一般要根据目标设置一个函数用以检测。这个函数即为适应度函数,它为群体进化的方向提供了依据。放到本文中,则是要检测每条已挖掘出的规则的有效性的问题上。所以打算从实用性、确定性、理解性来考量,即支持度、置信度、理解度。前两者之前已经定义过。现定义理解度和适应度函数。
理解度:用来衡量规则的简洁性。规则过长,即包含了大量的前因,这种情况不易用户理解和操作。我们这样定义:

式中,|Y|表示后果中包含的属性个数,|X∪Y|表示某一规则中属性的总量。
适应度函数可定义为

式中,Z1,Z2,Z3是根据用户需要定义的权重。某项值越大说明该项度量越重要。
3.3 遗传操作
遗传操作是遗传算法的重要组成部分,包括选择、交叉、变异三个步骤。
1)选择算子。选择操作的作用就是把优胜的个体直接或通过交叉产生的个体遗传到后代,再以个体适应度函数值的评判通过一些方法将个体从父辈中抽取出来,再复制到下一代。本文采用传统的轮赌法选择算子。
2)交叉。子代总是同时要继承父母代的基因。交叉则是把一对父母个体的部分基因用以重组后产生新的个体基因。交叉运算主要有:一点交叉、两点交叉、多点交叉等操作。本文使用最简单的一点交叉操作。以随机的方式选取交叉位置,在由父母代生成的交配池中以交叉概率Pi选取两个个体X,Y,并在某个交叉点交叉,交叉前形如X=(X1,X2,…,Xn),Y=(Y1,Y2,…,Yn),交叉后形如 X=(X1,X2,…,Xk,Yk+1,Yk+2,…,Yn),Y=(Y1,Y2,…,Yk,Xk+1,Xk+2,…,Xn)。
3)变异。对群种里的个体的某个基因进行改变,就形成了变异操作。变异可以使群种中的抗体变多,从而使搜索范围扩大,进而在更大范围内找到更优的个体。交叉运算使得遗传算法有了全局搜索功能,而变异操作使得它具有了局部搜索能力。常见的变异方法有:基本变异算子、逆转算子、自适应变异算子。本文采用基本变异算子策略,在群中的基因序列中随机选择N个基因位置,再对这N个基因值以概率Pm进行变异,即1变成0,0变成1。
4 实验
4.1 股市数据预处理
选取时间段2014年5月5日至2016年8月18日的沪深交易所2000支股票的相关基本数据。之所以选这个时间段,一是就近原则,二是这段时期股市经历了大幅上涨,大幅下跌,震荡这几种情况,而这几种情况完全反映了股市里的各种情况,也就是说数据源很客观,很全面。基本的股票数据信息太多,太杂乱,如果直接从中提取关联规则,显然会无的放矢。所以需要提取甚至组合一些数据。依照现今股票技术分析模型,以时间序列的模式模型,从长线属性,中短线属性,短线属性和趋势,这四个方面定义股票属性[11~16]。长线属性主要是长期股价构造形态(一般是1到若干个月数据组成的模式,取值若干),相关成交量的组合形态(取值若干),长期均价线形态。中短线属性主要是K线组合形态(比如3连阳等,取值若干),相关成交量的组合形态,中期均价线形态,一些中短期技术指标(比如BOLL等指标,选取3个)。短线属性主要当日K线形态(比如黄昏之星,跳空缺口等,取值若干),当日成交量,一些短期技术指标(比如MACD,KDJ等指标,选取3个)。趋势就是五种情况:大幅上涨、中幅上涨、区域震荡、中幅下跌、大幅下跌。总共17个属性。一支股票2年多的基本数据可以转化成若干个关于5种趋势的模式,即若干条基因。股票基本数据转换成模式时,采用的是时间序列的模式匹配的方法。即按照当今股市中的技术指标提前创建定义好若干模式,比如三角形整理、圆弧底,等等[17~20]。之后,把股票基本数据分时段转换成的模式与这些定义好的模式比较,看是否匹配。至于没有匹配的模式,则把这种模式定义成一个新模式,让其他的模式再与它比较,也就检验了这种新模式到底成立不。这样股票的基本数据就转变成了17个属性的数据库。数据库规模上,一支股票2年多的的数据至少能转化出5条基因,那么数据库规模至少是上万条的。实际上,股市数据预处理的时间和代价很大,远远超过Apriori算法和遗传算法的总用时。
4.2 对股票数据库用改进的Apriori算法和遗传算法加以运行
首先,用改进的Apriori算法对17个属性的数据库进行挖掘。在i7—6700k处理器的计算机中运行,得到537条关联规则。在时间上,改进的Apriori算法因为前期创建使用了额外空间,所以费时较多,而后期因减少了数据库的扫描时间,所以节约了大量时间。总体耗时为15.7s,而传统的Apriori算法耗时23.7s。改进的Apriori算法用时占传统Apriori算法用时的66%。其次,用遗传算法对挖掘出的关联规则再进行提炼,精简。主要参数为:变异概率Pm=0.1,交叉概率Pc=0.8,最小支持度Sup=0.7,最小可信度Con=0.1。537条关联规则被筛选掉了124条弱关联规则和误导规则,剩下了413条。比如用改进的Apriori算法挖掘出了这样2条规则,第一条,MACD指标里的白线刚好穿越0轴向上(短线属性),当日中阳线且穿越最近的2根均线,比如5日和10日(短线属性),成交量较大(短线属性),不是处于下跌趋势中(中短线属性),则后面有一段上涨。第二条,MACD指标里的白线刚好穿越0轴向上(短线属性),当日大、中阳线(短线属性),成交量较大(短线属性),60日均线已走平或趋势已向上(中线属性),则后面有一段上涨。这2条规则就被合成1条,MACD指标里的白线刚好穿越0轴向上(短线属性),当日大、中阳线(短线属性),成交量较大(短线属性),中期趋势不差(中线属性),则后面有一段上涨。从而实现了去掉弱关联规则。
5 结语
本文通过空间换时间的思路,对传统的Apriori算法进行了改进,并对股票数据库进行了建模与挖掘。而后又用遗传算法对挖掘出的关联规则进行了优化,得到了大量、实用的股市规则,对股民买卖股票起着良好的指导作用。在遗传算法中因为加入了理解度这个概念,从而使得挖掘出的规则在理解和操作上显得不是那么困难。同时,也消除了弱关联规则和误导规则。
[1]R.Agrawal and R.Srikant,Fast Algorithms for Mining Association Rules in Large Databases[C]//In Research Report RJ 9839,IBM Almaden Research Center,San Jose,Califomia,1994.
[2]何云峰.Apriori改进算法综述[J].微型机与应用,2013,32(6):1-3.HE Yunfeng.A Survey of Improved Apriori Algorithm[J].Microcomputer&ItsApplications,2013,32(6):1-3.
[3]秦吉胜,宋瀚涛.关联规则挖掘AprioriHybird算法的研究和改进[J].计算机工程,2004,17(30):7-9.QIN Jisheng,SONG Hantao.Study and Improvement of AprioriHybird Algorithm in Mining Association Rules[J].Computer Engineering,2004,17(30):7-9.
[4]何云峰.一种改进的Apriori算法及在计算机一级等级考试的应用[J].数字技术与应用,2016(6):147-149.HE Yunfeng.An Improved Apriori Algorithm and Its Application in National Computer First Rank Examination[J].Digital Technology&Application,2016(6):147-149.
[5]Anandhavalli M,Sudhanshu SK,Kumar A,et al.Optimized Association Rule Mining Using Genetic Algorithm[J].Advances in Information Mining,2009,1(2):1-4.
[6]马永杰,云文霞.遗传算法研究进展[J].计算机应用研究,2012,29(4):1201-1206.MA Yongjie,YUNWenxia.Research Progress of Genetic Algorithm[J].Application Research of Computers,2012,29(4):1201-1206.
[7]欧阳桃红,任彧.一种基于遗传算法的关联规则改进算法[J].杭州电子科技大学学报(自然科学版),2015,35(5):79-83.OUYANG Taohong,REN Yu.An Improved Algorithm for Mining Association Rules Based on Genetic Algorithm[J].JournalofHangzhou DianziUniversity(Natural Sciences),2015,35(5):79-83.
[8]詹芹,张幼明.一种改进的动态遗传Apriori挖掘算法[J].计算机应用研究,2010,27(8):2929-2930.ZHAN Qin,ZHANG Youming.Improved Dynamic Genetic Apriori Mining Algorithm[J].Application Research of Computers,2010,27(8):2929-2930.
[9]韩宏博.基于遗传算法的关联规则数据挖掘技术研究[D].西安:西安电子科技大学硕士学位论文,2010.HAN Hongbo.The Study of Association Rules Data Mining Based on Genetic Algorithm[D].Xi'an:Master's thesis of Xi'an Electronic and Science University,2010.
[10]刘建文,丁洁玉,潘坤,等.基于个体相似度的改进自适应遗传算法研究[J].青岛大学学报(工程技术版),2016,31(1):16-19.LIU Jianwen,DING Jieyu,PAN Kun.Improved Adaptive Genetic Algorithm Based on Individual Similarity[J].Journal of QingDao University(E&T),2016,31(1):16-19.
[11]何云峰,杨燕.基于模糊时间序列——股票走势的建模与应用[J].微机算计信息,2006,22(11):253-255.HE Yunfeng,YANG Yan.Modeling and Application of Stock Trend Based on Fuzzy Time Series[J].Microcomputer Information,2006,22(11):253-255.
[12]邓强强.基于Agent的股市建模与市场分形特征研究[D].南京:南京信息工程大学硕士学位论文,2015.DENG Qiangqiang.Agent-based Stock MarketModeling and Market Fractal Property Research[D].Nanjing:Master's thesis of Nanjing University of Information Science and Technology,2015.
[13]戎容,吴萍.基于遗传算法的股票市场选择模型[J].计算机工程与应用,2016,52(18):167-172.RONG Rong,WU Ping.Stock Market Selection Model Based on Genetic Algorithm[J].Computer Engineering and Applications,2016,52(18):167-172.
[14]潘明刚.基于遗传算法的模糊分类系统在股票分析中的应用[D].北京:中国地质大学硕士学位论文,2016.PAN Minggang.Application of Fuzzy Classification System Based on Genetic Algorithm in Stock Analysis[D].Beijing:Master's thesis of China University of Geosciences,2016.
[15]黄智翔.数据挖掘技术在股价分析中的应用研究[D].云南:云南大学硕士学位论文,2016.HUANG Zhixiang.Research on the Application of Data Mining in Stock Price Analysis[D].Yunnan:Master's thesisofYunnan University,2016.
[16]张在红.基于基本分析与技术分析的股票投资研究[D].兰州:兰州大学硕士学位论文,2016.ZHANG Zaihong.Based on Fundamental Analysis and Technical Analysis for Stock Investment Research[D].Lanzhou:Master's thesis of Lanzhou University,2016.
[17]梁挺,孙金金.技术投资方法在股票实战中的应用分析[J].商业经济,2016(4):146-148.LIANG Ting,SUN Jinjin.An Analysis of Application of Technology Investment in Stock[J].Shang Ye Jing Ji,2016(4):146-148.
[18]贾云朋.数据挖掘在股票曲线趋势预测中的研究及应用[D].吉林:吉林大学硕士学位论文,2015.JIA Yunpeng.Research and Application of Data Mining in the Prediction of Trends of the Curves in Stock[D].Jilin:Master's thesisof Jilin University,2015.
[19]宋嘉辉.股票市场技术分析的理论与实践[D].兰州:兰州大学硕士学位论文,2015.SONG Jiahui.The Stock Market Technical Analysis Theory and the Practice[D].Lanzhou:Master's thesis of Lanzhou University,2015.
[20]证券之星 www.stockstar.Com[EB/OL].
猜你喜欢
计算机仿真(2022年8期)2022-09-28
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
今日农业(2021年12期)2021-11-28
青岛大学学报(自然科学版)(2020年3期)2020-09-30
初中生世界·八年级(2019年6期)2019-08-13
计算机技术与发展(2019年7期)2019-07-23
当代旅游(2016年10期)2017-04-17
小学生导刊(低年级)(2016年9期)2016-10-13
小学生导刊(低年级)(2016年6期)2016-07-02
财经理论与实践(2015年2期)2015-04-16
